Communications and Network
Vol.6 No.2(2014), Article
ID:45716,7
pages
DOI:10.4236/cn.2014.62009
Internet as a Growing and Dynamic Network: An Economic View
Pasquale Lucio Scandizzo1, Alessandra Imperiali2
1University of Rome Tor Vergata, Center for Economic and International Studies, Rome, Italy
2University of Rome Tor Vergata, Rome, Italy
Email: scandizzo@uniroma2.it, Alessandra.Imperiali@uniroma2.it
Copyright © 2014 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 21 September 2013; revised 31 October 2013; accepted 30 November 2013
ABSTRACT
The past few decades have witnessed renewed interest and research efforts on the part of the scientific community. After spending decades to disassemble nature, focusing the attention on its components, scientists have shifted their attention on complex networks. These basic structures constitute a wide range of systems in nature and society, but their design is irregular, evolves dynamically over time and their components can fit in a large multiplicity of alternative ways. Nevertheless, the most recent studies of networks have made remarkable progresses by investigating some critical issues of structure and dynamics, thereby improving the understanding of the topology and the growth processes of complex networks. From an economic point of view, networks are especially interesting because they can be considered as a problem of allocation of a critical resource, information, under multiple constraints. They can also be viewed as forms of poliarchies that reproduce, for many aspects, the market paradigm, with surprising properties of self-organization and resilience, which go much beyond the characteristics that are generally attributed to general equilibrium structures. In this paper we first address the major results achieved in the study of complex network and then focus our attention on two specific, highly dynamic and complex networks: Internet and the World Wide Web.
Keywords:Network Analysis, Internet, Social Networks

1. Introduction
Since the 60’s, the desire to understand the properties of the networks has prompted scientists from different fields to investigate the mechanisms that determine the topology of a variety of systems, ranging from biology to the structure of social relations. In the past two decades the availability of large databases on the topology of various real networks and the increased availability of computing power have offered scientists the chance to investigate networks of millions of nodes. Motivated by these circumstances, many new and important concepts about the topology of the interactions between different components have been proposed.
In the words of E. O. Wilson [1] :
“The greatest challenge today not just in cell biology and ecology but in all of science, is the accurate and complete description of complex systems. Scientists have broken down many kinds of systems. They think they know most of the elements and forces. The next task is to reassemble them, at least in mathematical models, that capture the key properties of the entire ensemble.”
In our analysis, we first introduce the basic framework for the treatment of complex networks and then investigate the mechanism determining the structural properties and topologies of real networks.
2. Graph Theory
Graph Theory is the natural framework for the treatment of complex networks, since a graph can be considered the natural representation of the topology of a complex network [2] . Leonhard Euler, one of greatest mathematicians of all time, pioneered graph analysis and made important discoveries both from the point of view of its theory and its applications. Euler spent most of his life in the city of Konigsberg, Prussia, which was set on the Pragel River and included two large islands, connected to each other and the mainland by seven bridges. In 1776 Euler solved the famous Konigsberg Bridge problem, consisting in finding a path that traversed each of the seven bridge of the Prussian city of Konigsberg exactly once and returned to the starting point. He offered a rigorous mathematical proof that the problem had no solution [3] . This result is considered the first theorem of graph theory, specifically of “planar graph theory”. Since then, graph theory has undergone many more interesting developments and today represents the basis for the thinking about real networks.
In order to better understand graph theory, we must define some of its basic concepts. A graph is composed by a pair of sets G = (V,E), where V is a set of n vertices (also called points or nodes) and E is a set of K edges (links or lines) which connects two elements of the V. The graphs are constituted by a set of dots, which represents the nodes, and where two dots may be joined together by a line representing a link. In graph theory how these dots and lines are drawn is irrelevant, the only thing that matters is which pairs of nodes form a link and which do not. While it is clear that a graph may represent a network as a set of nodes and links, concepts such as arcs, paths and a number of other characteristics have been developed and superimposed, so to say, to the definition of the original definition of a graph. In this regard, a graph can be considered also a representation of a “structure”, a more general concept, which more naturally lends itself to be described by additional, more abstract properties.
Graphs are also representations of market structures, in that they may depict trade flows, or other systems of individuals and linkages that have economic relevance. Contractual relations, for example, can be represented as connections among contracting partners, and can be analyzed through graphs that represent not only bilateral obligations, but also the interdependencies that are created, as a consequence of bilateral deals, in a system of production and exchange.
3. Hierarchical Clustering
Lin (1999) [4] noticed that hierarchical position and network location facilitate the access to embedded resources such as wealth, status and power of social ties. As an alternative to community networks, hierarchical clustering appears to be also a powerful basis of organization and power in social networks according to two distinct strategies: 1) agglomerative clustering and 2) divisive clustering. The agglomerative model provides for a series of fusions of the single nodes into groups. It can be defined as the result of a “bottom up” approach, where each node starts in its own cluster and then pairs of clusters are merged as one moves up the hierarchy. Divisive methods, on the other hand, separate the single objects and correspond to a “top down approach”, where all nodes start in one cluster and then splits are performed as one by one they move down the hierarchy. The hierarchical structure of clusters can be graphically represented by dendograms, or hierarchical trees, which are often used to display the clusters which are produced at each step of agglomeration.
The importance of clusters for economic theory arises from Coase’s approach to the theory of the firm. According to Coase (1988) [5] , in fact, the existence of the firm is the attempt to reorganize contracts of exchange in alternative to the market, by economizing on transaction costs. The value of the firm thus derives from a peculiar configuration of “rights”. This depends on its “dedicated hierarchical nature”, that is, its specialized cluster structure, which is the consequence of both agglomerative and divisive clustering, and the assignment of different “rights” to its various stakeholders [6] , with ownership and control embedded into residual “rights” of shareholders. Because most economic activities can be interpreted as “enterprises”, i.e. as business ventures of a sort, the Coasian approach and the further developments of the neo-institutional school imply that the cluster paradigm (the enterprise as a cluster of contracts) may be applied to a wide variety of situations and, in particular, to the configuration of different actors presented by Internet and WWW. The concept of the enterprise as a cluster of contracts and of the parties involved as stakeholders has forced economists to face the issue of the plurality and heterogeneity of economic agents, especially in the new forms of “user based” enterprises.
4. Short Path Lengths
While the random graph model is the basis for the study of the formation of long-range connectivity in random systems (which is studied by percolation theory), it does not consider the random growth of complex structures, consisting of different points and connections of different types to obtain more complex real growth processes. In its original formulation [7] , furthermore, it only considers static networks in which the number of vertices is fixed, thus neglecting the fact that in reality many networks evolve with the continuous addition of new elements to the system. For any given network, however, the random graph model has the merit of identifying an underlying random structure which can be very useful to establish some basic properties that do not depend on complexity and/or on growth.
The so called “small world property” is the most important network property in this respect. It was discovered by Milgram (1967) [8] , who proposed an experiment, where randomly selected people in Nebraska would be asked to send letters to a distant individual in Boston, identified only by name, occupation and rough location, so that the letter could only be sent to someone presumably closer to him. Milgram was tracking the letters and found a surprising result. The average number of links needed to find the targeted person was found to be only six. This result is called “the six degrees of separation” and is the consequence of the fact that two individuals who don’t know each other may nevertheless be linked by a common acquaintance.
The small world property is important because it reveals properties of the performance of a given action that depend on the underlying structure rather than on any special procedure of optimization. It also shows that local information may be conducive to global success and that social networks, regardless of their size and complexity, exhibit two key characteristics: 1) a plurality of short path lengths and, 2) a structure that enables individuals to find short path lengths even in absence of a global knowledge of the network. These aspects are very important not only for social systems, but also for the World Wide Web, the traffic way-finding in a city, and the transport of information packets on the Internet and the diffusion of signaling molecules in biological cells [2] . The small world property also suggests that whereas complexity may make more difficult to comprehend the properties of a network, it carries with itself an increase in connectivity that makes easier to cover seeming longer distances with relatively short paths. This property is the basis, for example, of the so called strength of weak ties. This argument, put forward by Granovetter (1973) [9] , asserts that “Our acquaintances (weak ties) are less likely to be socially involved with one another than are our close friends (strong ties). Thus the set of people made up of any individual I and his or her acquaintances comprises a low-density network (one in which many of the possible relational lines are absent) whereas the set consisting of the same individual and his or her close friends will be densely knit (many of the possible lines are present)”. Complex networks can thus be conceived as sets of simpler closely connected networks of strong ties (such as cliques) loosely connected by weak ties. The small world property would be the result of this local-global structure, whereby weak ties would be the means to bridge the gaps between two or more densely connected “strongly tied” networks.
5. Small-World Networks
The small world property (SWP) was the object of different analysis on the structure of real networks, especially in biological and technological networks. Watts and Strogatz (1998) [10] extensively analyzed SWP in their “Collective dynamics of small-world networks”, where they found the existence of a relationship between the “small-world” networks and a high value of the clustering coefficient. Analytically, the clustering coefficient is a parameter introduced by the authors in 1999, to characterize the structure of complex networks. It represents a measure of the degree to which nodes in a graph tend to cluster together. Two versions of this measure exist: a local and a global clustering coefficient. The local clustering coefficient gives an indication of the clustering around a single node inside the network, while the global clustering coefficient is used to define an overall indication of the clustering inside the network.
The small-world property is also important for economics, where technological development, trade growth and the so called globalization phenomenon can be interpreted, as a consequence of “global clustering”, as reducing the distance between people and make the world smaller. Goyal, van der Leij and Moraga-Gonzalez (2005) [11] studied the evolution of social distance among economists who publish in journals in the period from 1997 to 2000, to show that, despite the fact that the number of economists has more than doubled in this period, the distance between any two of them has declined.
6. Post-Structuralism and Hypertexts
Complex networks find their most recent and egregious incarnation in Internet and the World Wide Web, two constructs whose complexity, because of their continuous, never ending growth, appear boundless. It is an extreme level of present and expected convexity that, paradoxically, stimulates the search for paradigm that cut across the intricacy and multiplicity of links, to discover drastic simplifications. The small world property is one of these, but a more pervasive idea is that of the personal classification embedded in the so called hypertext. This and other ideas appear to incarnate many of the intuitions of the so called post-structuralism, a strain of thought concentrating on a set of themes on the transmission of meaning through language, the role of networks of signification, and the perpetuation of power. These themes parallel and to some extent predict hypertexts and some other features of Internet and the World Wide Web and, in particular, share with the originators of hypertext and the Web the notions about the structure and workings of text, and of the network as the coordinating principle behind the transmission of meaning through texts. Post-structuralist theory challenges the assumption that organizing structures can be imposed on information in a neutral and objective fashion. This is a similar mistrust to discrete set approaches to information organization and retrieval influencing the innovators of hypertext and the Web.
Post structuralism economics may also be interpreted as an extension of Coase’s theory (1988) [7] , which sees the power of the firm arising from its capacity to tie its stakeholders in a multiplicity of explicit and implicit contractual knots. As in a post-structuralist Foucault, 1980 [12] in the case of language and power, the neo-institutional school that emerged after Coase’s work interprets economic power as the cause, rather than the consequence of the economic structure. Thus, for example, as Coase firmly establishes, in the presence of transaction costs, the distribution of property rights, by empowering one particular set of stakeholders rather than another one, determines the ensuing structure of the market and, as such, the particular clustering of contracts that characterizes the firms and their relations. This approach has also caused a “new theory of corporations” to emerge [13] in the school of law and legal analysis, whereby corporations are considered networks that lock in equity investors’ initial capital contributions by making it far more difficult for those investors to subsequently withdraw assets from the firm.
These characteristics of economic enterprises and their networks appear also important to understand the poststructuralist nature of much of the World Wide Web. Foucault, [12] as a key theorist of the post-structuralist movement, describes the properties of an interdependent system by exploring the role of power within a special category, which he calls “discourse”. Discourse for Foucault is a framework through which knowledge is transmitted and exploited, and, what is more, a framework regulated by power relations. Those power relationships are evident both between individuals, and more importantly between groups. Through language, customs, classifications and other more subtle means that impose a structure on knowledge, discourse therefore manifests its power by delimiting what it is acceptable and even possible to say about given subjects at given times. Contrary to Bacon who believed that knowledge was essentially empowering, Foucault argued that power defines what can be considered knowledge.
As a hypertext defined by essentially free associative relations, which can be traced by constructing a highly personalized and unpredictable chain of links among texts of different levels, the WWW appears an apparently successful attempt to overcome the dictatorship of an exogenously established discourse, which determines the extent and the nature of the knowledge that can be gained. The WWW is free from the arbitrary and tendentious nature of the classifications used to index and navigate the system of traditional texts and lends itself to be explored, without having to use the scaffolding of analogical categories that are the base of all dictionaries, encyclopedias and library classification systems.
The economic side of this analysis resides in the nature of the World Wide Web as a system of information management, which arose from Enquire, a personal information retrieval system developed by Tim Berners-Lee, [14] , who recognized its potential as a global information system [14] from the outset. Berners-Lee attempted to overcome the formal hierarchical structures imposed on information management solutions, because of their essential sub-optimality in retrieving and organizing information. The basic idea of the new system, which has important economic implications, is very remindful of the emergence of Coase’s enterprise, and consists in the intuition that self-organizing clusters of knowledge would come more efficiently from textual networks connected by semantic and associative relationships. Contrary to the formal structures dominating traditional text indexing and retrieval algorithms, hypertext and the Web could thus progressively emerge from an underlying loser structure of random networks, by creating dynamic clusters of associative relationships emerging from the texts of an information collection. This would in turn give rise to self-organizing associative networks of information, which would dynamically optimize information search and retrieval.
7. Scale-Free Networks
The year 1999 can be considered a turning point in the analysis of complex networks because scientists found that networks don’t show static scale-free graphs but expand continuously by the addition of new vertices. The network models discussed by Erdos and Renyi and by Watts and Strogatz assume that the number of vertices inside the network remains fixed. In this way, static scale-free graphs are models in which growth or aging processes do not play a dominant role in determining the structural properties of the network. [2] In reality many real networks are ruled by the dynamical evolution of the whole system. In this respect, Barabasi and Albert [15] observed that most real networks are open systems which grow by the continuous addition of new nodes.
The Barabasi and Albert (BA) [16] model was inspired by the topology structure of the World Wide Web that constitutes a network in continuous evolution and where the number of sites increases dynamically. By exploring several large databases describing the topology of large networks, AB found that, for most large networks, the degree distribution deviates from the Poisson law and that, in most of cases, it follows a power-law for large K. Since power-laws are independent of the unit of measure, these networks are called “scale-free” [17] [18] . This topological characteristic is determined by two mechanisms that interact inside the network: growth and preferential attachment. In contrast with the static models, the scale-free model describes a dynamic system which grows by the continuous addition of new vertices, as for example does the World Wide Web, which grows by the continuous addition of new Web pages. So, growth means that the number of nodes increases over time. The algorithm of this mechanism can be represented as an algorithm which starts with a small number of nodes 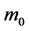 and at each time step, adds new nodes with
and at each time step, adds new nodes with 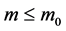 edges, with each new node being linked to the m nodes that are already present in the system. The algorithm is also non-random in the connectivity for a node inside the network, and dependent on the node’s degree. This means that, when choosing the vertices to which the new node connects, the probability that a new node will be connected to node i depends on the degree
edges, with each new node being linked to the m nodes that are already present in the system. The algorithm is also non-random in the connectivity for a node inside the network, and dependent on the node’s degree. This means that, when choosing the vertices to which the new node connects, the probability that a new node will be connected to node i depends on the degree 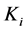 (the number of nodes already connected) of this node. New vertices attach preferentially to already well connect ones. An example of preferential attachment is represented by the hyperlinks of the Web page that will have a higher probability to include links to the more popular documents than to less-known ones. New pages link preferentially to hubs, very well-known sites such as Google, rather than to less-known pages. In this way, older vertices increase their connectivity, leading to a rich-gets-richer phenomenon that can easily be identified inside real networks.
(the number of nodes already connected) of this node. New vertices attach preferentially to already well connect ones. An example of preferential attachment is represented by the hyperlinks of the Web page that will have a higher probability to include links to the more popular documents than to less-known ones. New pages link preferentially to hubs, very well-known sites such as Google, rather than to less-known pages. In this way, older vertices increase their connectivity, leading to a rich-gets-richer phenomenon that can easily be identified inside real networks.
Growth and preferential attachment represent two important mechanisms of the networks, and both lead to the discovery of the networks with a power-law degree distribution [2] :
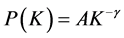 (1)
(1)
The exponent takes different values with respect to different networks, within a relatively narrow range (2.1 to 4): for example for the World Wide Web the value is approximately 3. K stands for the average degree of a node i, that is the number of edges incident with the node, while P stands for the probability that a node chosen at random has degree K.
BA investigated two different variants of the model: one with growth and no preferential attachment and one with preferential attachment without growth. In both cases no scale free structure emerged. Thus, both properties are needed to empower the network to self-organize according to a stationary power law distribution. The scale-free nature of networks, which has been widely accepted by most scientists, forces us to acknowledge that networks constantly change over time. The evidence comes from better maps and data sets but also from the agreement between the empirical data and the analytical models that predict the network structure. In his book “Linked” (2002), Barabasi [3] states that “power-laws are at the heart of some of the most stunning conceptual advances in the second half of the twentieth century, emerging in fields like chaos, fractals and phase transitions. Spotting them in networks signaled unsuspected links to other natural phenomena and placed networks at the forefront of our understanding of complex systems in general. The fact that the networks behind the Web, Hollywood, scientists, the cell, and many other complex systems all obey to a power law allowed us to paraphrase Pareto and claim for the first time that perhaps there were laws behind complex networks.”
It was the well know Italian economist Wilfredo Pareto who, at the end of the nineteenth century, noticed that a few quantities in nature follow a power law. As a careful observer of economic inequalities, Pareto noticed that 80 per cent of the money is earned by 20 per cent of the population and also that 80 per cent of his peas were produced by only 20 per cent of the peapods. Pareto’s rule is a power-law degree distribution and appears to approximately hold for many networks, including the World Wide Web, where around 80% of the links on the Web point to only 15% of the Webpages. As Barabasi [19] (2000) puts it, “power laws mathematically formulate the fact that in most real networks the majority of the nodes coexist with a few big hubs, nodes with an anomalously number of links. The few links are not sufficient to connect the entire network, but this function is secured by the rare hubs.”
8. Conclusions
The analysis of complex and dynamic networks is at the heart of several new fields of scientific inquiry and the basis of an interpretation of reality that cuts across several disciplines. As a method to understand Internet and its economic significance, modern network theory appears especially relevant, even though most of its disciplinary and interdisciplinary connections are yet to be discovered. The Social Accounting Matrix and the input output systems are an early application of network theory, even though their development in economics has been autonomous and mostly centered on the quantitative implications of impact analysis. On a different front, as information management systems, both Internet and the Web are environments of enterprise creation that recall Coase’s original theories and the subsequent outgrowth of institutional economics. The basic idea here is that markets can be viewed as a loose network of connections with the ensuing emergence of denser sub-networks as hierarchical clusters of contracts and other types of relationships. In this respect, both the Internet and the Web enlarge the horizons of Coase’s original theory much beyond the classical concept of the firm to the idea of an enterprise that can be recursively and completely defined in terms of its internal and external relations, and whose organization and production is largely dependent on the contribution of a plurality of users/stakeholders.
A second important element of Internet as a social and economic system, which is related to its clustered nature, is the fact that it is a system of small worlds, or, to cite a phrase that has become popular also in other contexts, a system of strong and weak ties that make possible communications of different types and intensities within and across communities. While the determinant factor of strong and weak ties for internet is built in its physical configuration, the small world characteristics of the web depend on its nature of a dynamic clustering system and the scale free property of the distribution of its links. This property is most intriguing, because it seems to denote a form of accumulation of “network capital”, whose distribution is based on a more than proportional connection reward to the nodes that already have a higher number of connections. The Web seems thus characterized by increasing benefits of accumulating information in a few privileged hubs, without correspondent increases in congestion costs. As in Coase’s model, this property may be itself the consequence of the tendency of self-organizing clusters to reduce transaction costs.
As an information management tool, the Web presents itself as a network of relations clustering around the principle of cognitive gain from free association. The hypertext results from the possibility to navigate among different texts without the limitations imposed by external classifications. As such, it is a source of allocative efficiencies that deserves further analysis. In principle, not only it allows exploiting more fully the information contained in the texts examined, but it also frees the reader from the dictatorship of the framework superimposed by any existing authority, which may effectively assert its power by limiting the extent and the form of knowledge that can be acquired.
References
- Strogatz, S.H. (2001) Exploring Complex Networks. Nature, 410, 268-276. http://dx.doi.org/10.1038/35065725
- Boccaletti, S., Latora, V., Moreno, Y., Chavez, M. and Hwang, D.-U. (2006) Complex Networks: Structure and Dynamics. Physics Reports, 424, 175-308.
- Barabasi, A.L. (2002) Linked: the New Science of Networks. Perseus Books Group, New York City.
- Lin, N. (1999) Building a Network Theory of Social Capital. Connections 22, 28-51.
- Coase, R. (1988) The Firm, the Market, and the Law. University of Chicago Press, Chicago.
- Ackerman B.A. and Alstott, A. (1999) The Stakeholder Society. Yale University Press, New Haven.
- Erdos, P. and Renyi, A. (1959) On Random Graphs. Publicationes Mathematicae (Debrecen), 6, 290.
- Milgram S. (1967) The Small World Problem. Psychology Today, 160.
- Granovetter, M.S. (1973) The Strength of Weak Ties. Sociol., 78, 1360.
- Watts D.J. and Strogatz, S.H. (1998) Collective Dynamics of Small-World Networks. Nature, 393, 440-442.
- Goyal, S. Van der Leij, M. and Moraga-Gonzàlez, J.L. (2005) Economics: An Emerging Small-World. Journal of Political Economy, 114, 403-412.
- Foucault, M. (1980) War in the Filigree of Peace Course Summary . Oxford Literary Review, 4, 15-19.
- Stout, L. (2004) On the Nature of Corporations. Deakin Law Review, 9, 775-789.
- Berners Lee, T.J. and Fiaschetti, M. (1999) Weaving the WEB, Harper, San Francisco.
- Albert, R. and Barabasi, A.L. (2002) Linked: How Everything Is Connected to Everything Else and What It Means for Business, Science and Everyday Life. Plumes, New York City.
- Albert, R. and Barabasi, A.L. (2002) Statistical Mechanics of Complex Networks. Review of Modern Physics 74, 47- 97. http://dx.doi.org/10.1103/RevModPhys.74.47
- Barabasi, A.L. and Albert R. (1999) Emergence of Scale in Random Networks. Science, 286, 509. http://dx.doi.org/10.1126/science.286.5439.509
- Barabasi, A.L. Albert, R. and Jeong, H. (1999) Scale Free Characyeristics of Random Networks: The Topology of the World Wide Web. Physica A, 272, 173.
- Albert, R. and Barabasi, A.L. (2000) Topology of Evolving Networks: Local Events and Universalities. Physical Review Letters 85, 5234. http://dx.doi.org/10.1103/PhysRevLett.85.5234