Open Journal of Applied Sciences
Vol.05 No.06(2015), Article ID:57169,7 pages
10.4236/ojapps.2015.56026
The Empirical Research of Relationship between Consumption and Income for Chinese Urban Residents
Fangfang Hou, Kefeng Ai
College of Science, University of Shanghai for Science and Technology, Shanghai, China
Email: qiexff@163.com
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 11 May 2015; accepted 13 June 2015; published 16 June 2015
ABSTRACT
This paper studied the clustering analysis of panel data, the specification test of panel data model and its parameter estimation. By carrying out clustering analysis on panel data, we finally decided to study the relationship of Chinese urban residents’ eight income levels between consumption and income from 2007 to 2012. Based on analysis of covariance in panel data model, we built the variable coefficient panel data model and then estimated the model parameters. In this work, we can identify the relationship between consumption and income in recent years. According to the estimation results, we drew the conclusion that income disparities have important influence on urban residents’ consumption behavior.
Keywords:
Panel Data, Consumption and Income, Clustering Analysis, Analysis of Covariance, Variable Coefficient, Parameter Estimation

1. Introduction
Panel data refer to two-dimensional data which are obtained in time series and cross section at the same time [1] , and that means taking multiple cross sections on time series, and selecting the sample observations on cross sections at the same time. With the development of the society, building model only on time series data or cross section data already cannot satisfy the increasingly complex economic problems. In addition, with the development of computer technology and internet, access to panel data becomes more and more easy.
There are more advantages of building model on panel data than on time series data or cross section data. First, panel data model can estimate unobservable individual effect and time effect at the same time, so the panel data model is more efficient; second, panel data provide more information, so as to improve the degree of freedom of the model, reduce the multi-collinearity among the explanatory variables, and eventually improve the accuracy of parameter estimation [2] ; third, panel data model is more suitable for complicated economic problems.
Since the 70’s of the last century, a large number of theoretical and empirical analyses of panel data have sprung up [3] [4] . The theory of the general panel data model is mature [5] -[8] . Bai [9] summarized setting, statistical test and new progress of panel data model. Many papers discussed the relationship between consumption and income [10] -[12] . But the data are not in recent years. This paper used the panel data in recent years and combined clustering analysis with panel data. So the conclusion is more consistent with the reality.
This paper preprocessed consumption panel data and income panel data of Chinese urban residents’ eight income levels from 2002 to 2012, then carried out clustering analysis on the panel data, and finally concluded that the structures of consumption and income were same from 2007 to 2012. By the analysis of covariance for panel data model, eventually we built the variable coefficient panel data model on consumption panel data and income panel data of Chinese urban residents’ eight income levels from 2007 to 2012. Then, we used Eviews 7.0 to estimate the parameters of the model, and analyzed the results.
2. Methodology
2.1. Clustering Analysis of Panel Data
The panel data 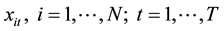 contains T cross sections. If we use the distance between the cross sections to measure the similarity, then we obtain a
contains T cross sections. If we use the distance between the cross sections to measure the similarity, then we obtain a  similarity matrix, and it is a symmetrical matrix. The similarity matrix is as follows:
similarity matrix, and it is a symmetrical matrix. The similarity matrix is as follows:

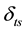 is a dissimilarity degree measure between the t-th cross section and the s-th cross section, which also is a measure of the distance. When the two time sections are very similar, its value is close to zero.
is a dissimilarity degree measure between the t-th cross section and the s-th cross section, which also is a measure of the distance. When the two time sections are very similar, its value is close to zero.
Here are several kinds of commonly used method for measuring distance between cross sections. As shown below:
1) Euclidean Distance: .
.
2) Squared Euclidean Distance: .
.
3) Minkowski Distance: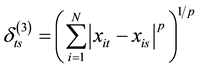 . When p = 2, Minkowski distance is the Euclidean distance.
. When p = 2, Minkowski distance is the Euclidean distance.
4) Manhattan Distance: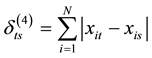 . Manhattan distance is a special case of the Minkowski distance when p = 1.
. Manhattan distance is a special case of the Minkowski distance when p = 1.
5) Chebyshev Distance: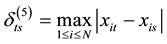 .
.
The clustering analysis of panel data can divide time sections into several divisions. Building model on one of the division can ignore unobservable time effect, which has important significance on the application. Zhu and Chen [13] studied the clustering analysis of panel data and its application, and focused on the cluster in cross section.
The basic principle of clustering analysis is: for the panel data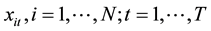 , first of all, we divide each cross section into a class, then we have a total of T classes; secondly, according to the above distance calculation, we obtain a similarity matrix of panel data, then we merge the nearest two time sections into a class, so we have
, first of all, we divide each cross section into a class, then we have a total of T classes; secondly, according to the above distance calculation, we obtain a similarity matrix of panel data, then we merge the nearest two time sections into a class, so we have  classes; again, according to the similarity matrix, we merge the nearest two time sections into a class, so we have
classes; again, according to the similarity matrix, we merge the nearest two time sections into a class, so we have 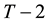 classes; by analogy, we eventually merge all T time series into a class.
classes; by analogy, we eventually merge all T time series into a class.
2.2. Analysis of Covariance
To build model on panel data, we must first determine the form of the model. General panel data model is as follows:
 (1)
(1)
Among them, 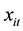 is a
is a 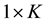 vector, and
vector, and 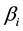 is a
is a  vector, and K is the number of explanatory variables.
vector, and K is the number of explanatory variables.  is the intercept item, and its value is related to the individual, and it is regarded as the fixed parameter to estimate here.
is the intercept item, and its value is related to the individual, and it is regarded as the fixed parameter to estimate here.  is a random error term, and it is not associated with explanatory variables, and its mean is zero, and its variance is
is a random error term, and it is not associated with explanatory variables, and its mean is zero, and its variance is , and it is independent and identically distributed.
, and it is independent and identically distributed.
The common situation of model (1) is as follows:
1) when , model (1) is called the basic model or mixed regression model;
, model (1) is called the basic model or mixed regression model;
2) when , model (1) is called the variable intercept model;
, model (1) is called the variable intercept model;
3) when , model (1) is called the variable coefficient model.
, model (1) is called the variable coefficient model.
The common test for determining the model forms is the analysis of covariance, also is called F test. The test contains two main hypotheses:
Hypothesis 1: The slopes are the same, but the intercepts are not the same. The model is:
 (2)
(2)
Hypothesis 2: The intercepts and slopes are the same in different cross sections and different time series. The model is:
 (3)
(3)
According to the method in parameter constraint test, we can construct test statistics for the above two hypotheses1. Test statistics for hypothesis 1 and hypothesis 2 respectively are:

Among them,  respectively are the sums of squared residuals for model (1), (2) and (3) under ordinary least square method.
respectively are the sums of squared residuals for model (1), (2) and (3) under ordinary least square method.
When hypothesis 1 is correct, . When hypothesis 2 is correct,
. When hypothesis 2 is correct,  . Obviously, if we accept hypothesis 2, we don’t need to test hypothesis 1, and we should build model (3). If we reject hypothesis 2, we should test hypothesis 1. If we accept hypothesis 1, we should build model (2). If we reject hypothesis 1, we should build model (1).
. Obviously, if we accept hypothesis 2, we don’t need to test hypothesis 1, and we should build model (3). If we reject hypothesis 2, we should test hypothesis 1. If we accept hypothesis 1, we should build model (2). If we reject hypothesis 1, we should build model (1).
2.3. The Parameter Estimation of Variable Coefficient Panel Data Model
For fixed effect variable coefficient model (1), it can be rewritten as:
 (4)
(4)
Among them, 
The matrix form is:
 (5)
(5)
Among them, .
.
Fixed effect variable coefficient model is also called seeming unrelated regression model. The model considers that coefficients don’t change with time for each individual. It is put forward by Zellnerin 1962. The selection of parameter estimation method depends on the random disturbance term2. If  and
and , model (4) can be estimated by ordinary least square method, which is the classic method in single equation econometric model. Namely we take each time series as sample, and use ordinary least squares method to estimate
, model (4) can be estimated by ordinary least square method, which is the classic method in single equation econometric model. Namely we take each time series as sample, and use ordinary least squares method to estimate  respectively, or adopt the generalized least square method to estimate
respectively, or adopt the generalized least square method to estimate  at the same time. The two kinds of estimation results are consistent. If
at the same time. The two kinds of estimation results are consistent. If , we can use the generalized least square method to estimate
, we can use the generalized least square method to estimate . We write
. We write , then the covariance matrix of
, then the covariance matrix of 
 is:
is:

So the generalized least square estimation of the parameters is: .
.
3. The Empirical Research
According to the consumption theory of Keynes, the total consumption is the function of total income. As we all known, there are a stable and interdependent relationship between consumption and income. Namely income is the decisive factor in influencing consumption. We can relate this kind of relationship with regression theory, and build the linear model  on consumption and income. Among them, C is the per capita consumption expenditure.
on consumption and income. Among them, C is the per capita consumption expenditure.  is the per capita disposable income.
is the per capita disposable income.  is the intercept item.
is the intercept item.  is the marginal consumption propensity, and its value is between 0 and 1.
is the marginal consumption propensity, and its value is between 0 and 1.
With the development of the society, accessing to panel data becomes more and more easily, and building panel data model becomes more and more commonly. So we can build panel data model on income panel data and consumption panel data, and study the marginal consumption propensity and the intercept item among different individuals. By the empirical analysis, we can put forward feasible suggestion.
3.1. Data Introduction and Preprocessing
The modeling data is the per capita disposable income and the per capita cash expenditure of Chinese urban residents’ eight income levels from 2002 to 20123. In order to eliminate the rising factor of price4, we regarded cpi of 2002 as 100, and recalculated cpi from 2002 to 2012. Then dividing the original data by recalculated cpi, and multiplying it by 100, finally we obtained the per capita disposable income panel data and the per capita cash expenditure panel data eliminated the rising factor of price. Using SPSS 19.0, we carried out clustering analysis of the panel data respectively. The following is the comparison of the cluster tree.
From Figure 1, we can classify the per capita disposable income from 2007 to 2012 into the same cluster. From Figure 2, we can classify the per capita cash expenditure from 2007 to 2012 into the same cluster. Therefore, we can build panel data model on the per capita disposable income and the per capita cash expenditure of Chinese urban residents’ eight income levels from 2007 to 2012.

Figure 1. Clustering tree of per capita disposable income panel data (2002-2012).

Figure 2. Clustering tree of per capita cash expenditure panel data (2002-2012).
Table 1 and Table 2 are two original panel data from 2007 to 2012. Because China’s cpi is calculated based the previous year as the base period 100, not based a certain date as the base period, we needed to recount cpi since 2007. The calculation results are shown in Table 3. We needed to eliminate the rising factor of the panel data in Table 1 and Table 2. Then it could be put into the model. Namely dividing the original data by recalculated cpi in Table 3 respectively, and multiplying it by 100.
3.2. Build Model
Due to the structure of consumption and income from 2007 to 2012 belongs to the same type, so we can set the model parameters as unaffected by time. The form is:
 (6)
(6)
Among them,  is the per capita cash expenditure of the i-th income group in the t-th year.
is the per capita cash expenditure of the i-th income group in the t-th year.  is the per capita disposable income of the i-th income group in the t-th year. The two panel data have been eliminated the
is the per capita disposable income of the i-th income group in the t-th year. The two panel data have been eliminated the

Table 1. Per capita disposable income of Chinese urban residents (RMB).
Table 2. Per capita cash expenditure of Chinese urban residents (RMB).
Table 3. Recalculated cpi values based cpi of 2007 as 100.
rising factor of price based cpi of 2007 as 100. In addition, due to the model studied each income group’s own data, so the parameters can be regarded as fixed parameters to estimate. Namely the model is the fixed effect model.
3.2.1. Model Identification
Using Eviews 7.0 to respectively calculate the sums of residual squares for variable coefficient model, variable intercept model and basic model under ordinary least square method (the calculation results is in Table 4), and putting N = 8, T = 6, K = 1 together into test statistics F2, F1, and comparing with the critical value under the significance level , thus determining the model form.
, thus determining the model form.
The values of  are calculated as follows:
are calculated as follows:


Comparing with the critical value:


By the above comparison results, we can determine the model as fixed effect variable coefficient model.
3.2.2. Parameter Estimation
Assuming that random disturbance items are irrelevant in different cross section individuals, then we can take each time series as sample, and use ordinary least squares method to estimate . The following are the parameter estimation results.
. The following are the parameter estimation results.
From Table 5, we can conclude that the marginal consumption propensity is decreasing and the intercept item is increasing with the improvement of income level. From Table 6, we can learn that the goodness of fit of the model is as high as 99.9%. It indicates that the fitting effect of fixed effect variable coefficient model is very good. Statistics F also passed the test of significance. It indicates that the regression equation is significant as a whole, and the regression coefficients are significant. It shows that income has significant effect on consumption under each income level. The value of statistic DW is close to 2, so there is no first-order autocorrelation in the random error term  5, which is consistent with the hypothesis, thus the process of modeling and the results are believable.
5, which is consistent with the hypothesis, thus the process of modeling and the results are believable.
3.3. Results Analysis
By the parameter estimation results, the following conclusions can be drawn:
1) When income levels are different, there are obvious differences in marginal consumption propensity. And the marginal consumption propensity is decreasing with the improvement of income level. It shows that income disparity exactly is the decisive factor in influencing consumption, and the higher the income is, the weaker the marginal consumption desire is. That is consistent with the saying “diminishing marginal returns” in economics.
Table 4. Sums of squared residuals of the three models.
Table 5. The estimation results of the variable coefficient model.
Table 6. The statistical results of the variable coefficient model.
2) The intercept item is increasing with the improvement of income level. It shows that the absolute consumption level of urban residents is increasing by increased income.
3) In general, the marginal consumption propensity of different income levels is over 50%. It shows that no matter what the income levels of residents are, their consumption desire is very high. But different income levels may pursue different consumption direction.
4. Conclusion
Panel data model could analyze practical problems from the angles of time and the individual, so its application is becoming wider and wider. General theory about panel data has been relatively mature, and general linear panel data model was applied in this paper. According to the intercept item and marginal consumption propensity of variable coefficient panel data model, we can distinguish the spending habits in recent years between different income levels, and then introduce different policies to stimulate consumption. But this paper didn’t subdivide consumption into different directions, such as: food, clothing, household goods, etc. If we join these aspects into the model, the results will be more beneficial for stimulating consumption. And general panel data model could finish the idea. Additionally, we still need to study nonclassical panel data models, such as: dynamic panel data model and nonlinear dynamic panel data model. Long and Zhang [14] studied theory and application of dynamic panel data model. But its parametric and nonparametric estimations still need to be studied further.
Acknowledgements
The authors would like to thank for the assistance provided by Hongfu Pan and Guoshuai Wang. They suggested us the journal and told us online submission. We finally finished the paper with their concern.
References
- Li, Z.N. and Pan, W.Q. (2010) Econometrics. 3rd Edition, Higher Education Press, Beijing.
- Yu, G. (2011) Research on the Parameter Estimation Problems of Panel Data Models. Ph.D. Thesis, Northeast Normal University, Changchun.
- Campbell, J.Y. and Mankiw, N.G. (1991) The Response of Consumption to Income: A Cross-Country Investigation. European Economic Review, 35, 723-767. http://dx.doi.org/10.1016/0014-2921(91)90033-F
- Islam, M.N. (1995) Growth Empirics: A Panel Data Approach. Quarterly Journal of Economics, 110, 1127-1170. http://dx.doi.org/10.2307/2946651
- Hsiao, C. (2003) Analysis of Panel Data. 2nd Edition, Peking University Press, Beijing. http://dx.doi.org/10.1017/CBO9780511754203
- Baltagi, B.H. (2005) Econometric Analysis of Panel Data. 3rd Edition, John Wiley & Sons Inc., New York.
- Chen, H.Y. (2006) Analysis and Application of Panel Data. M.S. Thesis, Tianjin University, Tianjin.
- Chen, H.Y. (2010) Research on the Testing Methods in Panel Data Models. Ph.D. Thesis, Tianjin University, Tianjin.
- Bai, Z.L. (2010) Setting, Statistical Test and New Progress of Panel Data Model. Statistics and Information Forum, 25, 3-12.
- Zhu, W. and Li, Y.S. (2006) Panel Data Analysis of China Urban Residents’ Consumption Structure. Application of Statistics and Management, 25, 645-648.
- Chen, H.Y., Yang, B.C. and Li, S.C. (2009) Analysis of Panel Data of Consumption Structure of Urban Residents in China .Statistics and Decision, 24, 112-114.
- Wang, L. (2012) Application of Panel Data Analysis Method in the Relationship between Income and Consumption of Our Country. M.S. Thesis, Lanzhou Jiaotong University, Lanzhou.
- Zhu, J.P. and Chen, M.K. (2007) The Cluster Analysis of Panel Data and Its Application. Statistical Research, 24, 11- 14.
- Long, Y. and Zhang, S.Y. (2010) Theory and Application Research of Dynamic Panel Data Model. Science-Technol- ogy and Management, 12, 30-34.
NOTES

1Z.N. Li (2010) involved the constrained regression in the “econometrics”. Hypothesis 1 and hypothesis 2 can be regarded as linear constraints on the model (1). Therefore, testing statistics can be constructed similarly.

2Random disturbance term is divided into relevant case and irrelevant case.
3Data is from China statistical yearbook (2003-2013).
4Because of the existence of inflation, we needed to eliminate the rising factor of price in data processing.

5The value of statistic DW is between 0 and 4. Generally speaking, when the value is close to 0, there is a positive first-order autocorrelation tendency; when the value is close to 4, there is a negative first-order autocorrelation tendency; when the value is close to 2, there is no first-order autocorrelation tendency.