Open Journal of Modern Hydrology
Vol.06 No.03(2016), Article ID:69048,17 pages
10.4236/ojmh.2016.63013
Parameter Estimation of a Distributed Hydrological Model Using a Genetic Algorithm
Jasmin Boisvert1, Nassir El-Jabi1, André St-Hilaire2, Salah-Eddine El Adlouni3
1Faculty of Engineering, Department of Civil Engineering, Université de Moncton, Moncton, Canada
2INRS, Centre Eau-Terre-Environnement, Québec City, Canada
3Department of Mathematics and Statistics, Faculty of Sciences, Université de Moncton, Moncton, Canada

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 3 March 2016; accepted 23 July 2016; published 26 July 2016
ABSTRACT
Water is a vital resource, and can also sometimes be a destructive force. As such, it is important to manage this resource. The prediction of stream flows is an important component of this management. Hydrological models are very useful in accomplishing this task. The objective of this study is to develop and apply an optimization method useful for calibrating a deterministic model of the daily flows of the Miramichi River watershed (New Brunswick). The model used is the CEQUEAU model. The model is calibrated by applying a genetic algorithm. The Nash-Sutcliffe efficiency criterion, modified to penalize physically unrealistic results, was used as the objective function. The model was calibrated using flow data (1975-2000) from a gauging station on the Southwest Mira- michi River (catchment area of 5050 km2), obtaining a Nash-Sutcliffe criterion of 0.83. Model validation was performed using flow data (2001-2009) from the same station (Nash-Sutcliffe criterion value of 0.80). This suggests that the model calibration is sufficiently robust to be used for future predictions. A second model validation was performed using data from three other measuring stations on the same watershed. The model performed well in all three additional locations (Nash- Sutcliffe criterion values of 0.77, 0.76 and 0.74), but was performing less well when applied to smaller sub-basins. Nonetheless, the relatively strong performance of the model suggests that it could be used to predict flows anywhere in the watershed, but caution is suggested for applications in small sub-basins. The performance of the CEQUEAU model was also compared to a simple benchmark model (average of each calendar day). A sensitivity analysis was also performed.
Keywords:
Hydrological Modeling, Genetic Algorithm, CEQUEAU Model, Beta Function, Miramichi River

1. Introduction
Water is an essential part of life. Living organisms require this resource for sustenance. As such, the health of an ecosystem and that of the environment are highly dependent on water availability. In addition to consumption, human beings use water for a multitude of other purposes, such as personal hygiene, washing/cleaning, and food preparation. Irrigation, aquaculture, energy production and several industries are also important consumers of the resource. These many uses of a single resource can cause problems for those who must manage it, particularly if there is a shortage, such as during a drought. On the other hand, an excess of water can be dangerous. Floods can potentially cause a lot of damage, and even fatalities. In order to minimize or even prevent such damages, it becomes important to prepare for such an event. Assuming a particular river or watershed is of interest, knowing how it behaves on a regular basis, and how it reacts to certain situations, events, or even physiographic changes is of great importance to water resource managers. A useful tool to accomplish this is by modeling discharge at different locations on the watershed. The present study aims to do this for a significant watershed in New Brunswick: The Miramichi River watershed. This particular watershed was chosen for its importance in the province (2nd largest in the province, after the Saint John River watershed), and the abundance of data available, including many hydrometric gauging stations and meteorological stations located on or near the watershed, along with plenty of physical data describing elevation, land use, etc.
A model is a simplified theoretical representation of a system, whose goal is to not only understand and explain the system, but also to predict its behavior. A hydrological model is thus very useful in water resource management. There are many models with different capacities and levels of complexity. The choice of model to represent a system must be made in accordance with these properties. Two broad categories of models can be defined: statistic and deterministic. Statistic models attempt to identify the relation between independent variables and explained variables without explicitly accounting for the physical process. On the other hand, deterministic models use mathematical representation of physical processes, such as energy or mass balance. The model used in the present study is the CEQUEAU model [1] , which belongs to the latter category. The model has been applied to many rivers and watersheds in Québec, Canada, and internationally [2] . In New Brunswick, the model has been applied on the Catamaran Brook, a sub-basin of the Little Southwest Miramichi River [3] .
Deterministic models can use multiple functions to represent multiple phenomena. This can lead to a large number of parameters that need to be estimated, potentially causing an over-parameterization [4] . On the other hand, [5] argue that rigorous parameterization can aid in the calibration of a distributed model. In either case, one must be careful when deciding what needs to be calibrated and what can be estimated.
Since models require calibration, this implies an optimization of an objective function as a function of varying parameter values. This can be a complex and time consuming task, especially for high dimensional spaces. One must also be careful in deciding what method to use for parameter optimization. One still common method is to adjust the parameters manually. This can be time consuming and requires a certain level of understanding of modeled processes in order to adjust parameters logically. Another method is to apply an optimization algorithm. There are many different algorithms, each with its advantages and disadvantages.
For this study, the primary objective is to adapt an efficient calibration method for the selected model. as such an optimization algorithm will be applied. A genetic algorithm is selected for the optimization of the CEQUEAU parameters. This choice was made because it is an efficient algorithm when the number of parameters to be optimized is large, which is the case for the CEQUEAU model (29 parameters). A genetic algorithm was chosen, and will be adapted for use with the CEQUEAU model and applied in order to estimate its parameters. This is the first time that such an algorithm will be used in conjunction with the CEQUEAU model. The modeling objectives listed below will determine if the model’s performance is acceptable, which will in turn determine if the calibration was successful.
The objectives of the modeling are as follows:
- To model the hydrological cycle of the Miramichi River watershed, including all the components of the water balance equation (precipitation, surface flow, evapotranspiration, and storage). The model must be validated using existing data;
- To verify the performance of the applied model at different locations on the watershed. The model must be capable of predicting flows at different stations and for water courses of different sizes. Although this verification is limited to gauged locations, a good model performance at multiple gauged locations would suggest that it could also be applied at ungauged locations as well.
2. Methodology
2.1. CEQUEAU Model
The CEQUEAU model is a semi-distributed hydrological model. This implies that spatial variability is taken into account for a number of hydrological processes. However, certain parameters and physical variables are considered constant throughout the basin. Spatially distributed data include both the physiographic properties of the study area and the input meteorology. The study area (watershed) must therefore be divided into Elementary Representative Areas (ERA) The CEQUEAU model requires two different divisions: whole squares and partial squares. The first division (into whole squares), attempts to divide the watershed into relatively homogenous ERAs. All whole squares have the same size, creating a grid overlapping the watershed. For each square, certain characteristics must be defined: percentages of forest cover, lake area, and marsh area, as well as altitude. The second division (into partial squares) subdivides the whole squares according to drainage divides. The purpose of this division is to use it to define the drainage network (routing) of the watershed. Figure 1 shows an example of these divisions.
Water movement calculations throughout the system can be separated into two categories: The production function and the transfer function. The production function deals with the vertical movement of water on each individual whole square. Figure 2 shows the different components of the production function.

Figure 1. Example of watershed division into whole squares (ERAs) and partial squares (sub- basin limits) [4] .

Figure 2. Conceptual schema of the CEQUEAU model [4] .
As this figure indicates, three interconnected reservoirs are used in the production function. The outflows of these reservoirs have their own discharge coefficient. Precipitation can either be in the form of rain or snow. In the latter case, a snowmelt model based on degree-days [6] is applied. Evapotranspiration is also calculated for the three reservoirs by using the Thornthwaite equation. The transfer function quantifies the movement of water from one square to another (routing). [1] describe both of these functions and their components in detail. In total, there are 29 parameters that need to be optimized.
2.2. Parameter Estimation
Some of the parameters of the production function and heat budget can be calculated or estimated based on the known physical processes underlying these functions, whereas the rest must be optimized. This implies that the user must assign values to these parameters whose “actual” values are unknown in order to produce the best possible simulation. This typically means that the output of the model (simulation time series) is compared to the corresponding observation time series for a set calibration period. For the CEQUEAU model, the variation of the parameters has been typically done manually. This requires a great deal of time and a certain level of expertise. For example, the model could overestimate the flows every spring, and the user must be knowledgeable enough of the physical processes that influence this flow to understand which parameters may be responsible for the overestimation, then to adjust it accordingly. In addition, because each region and each watershed is different, this potentially lengthy process must be repeated for each individual watershed to be analyzed. Instead of utilizing this inefficient method, an automatic calibration algorithm was adapted and applied to the CEQUEAU model in this study in order to optimize the parameters. In using an optimization algorithm, the hope is that it will not only be applicable to any watershed, but that it would also save time and be usable with minimal preparation or expertise.
2.3. Genetic Algorithm
The optimization algorithm that was applied to the CEQUEAU model was based primarily on a genetic algorithm, developed by [7] , and later revised by [8] . This type of optimization algorithm has been applied in many fields, including biology, chemistry, civil, mechanical and electrical engineering. There exists two types of genetic algorithms: binary encoding and real value encoding. Real value encoding: vectors containing real numbers are used to represent parameter sets. Each element of the vector represents a parameter, and can possess any value within a range defined by the user, For example, one of the parameters used by CEQUEAU is the rain- snow threshold (STRNE). The user could define a logical range for this value, say between −3˚C and 3˚C, while the optimized value could be of 1.234˚C. In this study, due to the complexity of the problem and the CEQUEAU model, only real value encoding is used and discussed. Figure 3 presents the flowchart of the genetic algorithm used in this study.

Figure 3. Flowchart of the genetic algorithm used to optimize the CEQUEAU model parameters.
The first step in applying a genetic algorithm is defining an objective function. This function is used to evaluate the performance of a particular set of parameters. In the context of the CEQUEAU model, a set of parameters will generate a simulation (flow), and this simulation will be compared to observed data to rate the performance of the simulation. There are many different ways to quantify the performance, such as Pearson's correlation coefficient (r), the Kling-Gupta efficiency (KGE), Willmott’s index of agreement (d), or the Nash-Sutcliffe efficiency criterion (NSE). Weighted and logarithmic versions of these also exist [9] . With all these options available, the choice of function becomes important. It is this function that the algorithm will attempt to maximize or minimize, depending on the case. In this study, the NSE is used, but slightly modified by including the possibility of applying a penalty to the value. The NSE is presented in Equation (1).
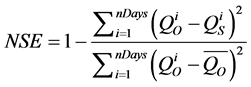 (1)
(1)
where:
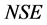 : Nash-Stutcliffe Efficiency Criterion, ranging from
: Nash-Stutcliffe Efficiency Criterion, ranging from 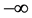 (bad simulation) to 1 (perfect simulation)
(bad simulation) to 1 (perfect simulation)
 : Length of the simulation period (days)
: Length of the simulation period (days)
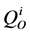 : Daily observed flow (m3/s)
: Daily observed flow (m3/s)
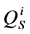 : Daily simulated flow (m3/s)
: Daily simulated flow (m3/s)
 : Average of all observed daily flows (m3/s)
: Average of all observed daily flows (m3/s)
The idea behind applying a penalty to the NSE is to avoid solutions which produce good NSE values, but are not physically plausible. Given the region and the size of the watershed being studied, three situations were identified as being implausible: an empty water table, empty lakes and marshes, and the principal water course being almost completely dry. Equations (2) to (4) present the penalties applied in the three different cases.
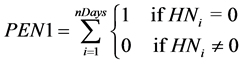 (2)
(2)
where:
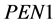 : Penalty applied for an empty water table
: Penalty applied for an empty water table
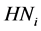 : Height of water in the Lower Zone reservoir (water table) on day i (mm)
: Height of water in the Lower Zone reservoir (water table) on day i (mm)
 (3)
(3)
where:
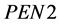 : Penalty applied for empty lakes or marshes
: Penalty applied for empty lakes or marshes
 : Height of water in the Lakes and Marshes reservoir on day i (mm)
: Height of water in the Lakes and Marshes reservoir on day i (mm)
 (4)
(4)
where:
 : Penalty applied for a almost dry water course
: Penalty applied for a almost dry water course
 : Minimum observed flow during the simulation period (m3/s)
: Minimum observed flow during the simulation period (m3/s)
The total applied penalty (PENAPP) is the average of PEN1, PEN2, and PEN3, multiplied by the magnitude of the penalty. In this study, a magnitude of 0.00333 was applied. This implies that a simulation which possesses, on average, a single day per year in which each of the three penalties is applied (not necessarily all on the same day), would incur a penalty of 0.01 to the NSE value. To distinguish between the original NSE and the penalized NSE, NSEPEN is used as the objective function for the genetic algorithm while optimizing the flow model. The relation between NSE and NSEPEN is shown in Equation (5).
 (5)
(5)
where:
 : Total applied penalty
: Total applied penalty
 : NSE criterion with applied penalty
: NSE criterion with applied penalty
As pointed out by [10] , the NSE is dependent on the strength of the annual cycle. In order to properly judge whether or not a model performed well, a baseline or “benchmark” model should be evaluated. Say, for example, that while calibrating a model, such as the CEQUEAU model, we obtain a NSE value of 0.80. We might be inclined to state that the model preformed well, since this value is close to the maximum of 1. However, if we examine the same data using a benchmark model, such as the use of the inter-annual mean flow per calendar day as a model ( In Equation (1)), we could obtain a NSE value of 0.75. The high NSE value of the benchmark model would indicate that there is little variation in flow between years. The fact that the calibrated model barely outperforms the benchmark model could indicate that the calibrated model correctly modeled the seasonal variation (e.g. high flow during snowmelt, low flow during summer droughts), just as the benchmark model did, but failed to capture additional smaller-scale variability that the benchmark model would not have. The model could therefore be ineffective, if this was in fact its purpose. As such, the high NSE value would be misleading. On the other hand, if the benchmark model obtained an NSE value of 0.4 instead of 0.75 while the calibrated model still obtained a NSE value of 0.8, then it would be much clearer that the calibrated model performed well, since there is a lot of variability in the data and the model managed to capture that variability reasonably well.
In Equation (1)), we could obtain a NSE value of 0.75. The high NSE value of the benchmark model would indicate that there is little variation in flow between years. The fact that the calibrated model barely outperforms the benchmark model could indicate that the calibrated model correctly modeled the seasonal variation (e.g. high flow during snowmelt, low flow during summer droughts), just as the benchmark model did, but failed to capture additional smaller-scale variability that the benchmark model would not have. The model could therefore be ineffective, if this was in fact its purpose. As such, the high NSE value would be misleading. On the other hand, if the benchmark model obtained an NSE value of 0.4 instead of 0.75 while the calibrated model still obtained a NSE value of 0.8, then it would be much clearer that the calibrated model performed well, since there is a lot of variability in the data and the model managed to capture that variability reasonably well.
The next step in applying the genetic algorithm to the CEQUEAU model is defining the range of values that each respective parameter can take. This is done to ensure that the parameters stay within physically plausible limits. For example, the rain-snow threshold (STRNE) would certainly not be 10˚C. It would therefore be reasonable to limit the value to between −3˚C and +3˚C, or something similar.
Once the range of each parameter is defined (see Table 2), the next step of the genetic algorithm is the initialization. This consists of creating the initial population of individuals. An individual is a vector whose elements each represent a different parameter. The length of the vector is equal to the number of parameters to be optimized (NPAR). The initialization assigns random values to each of the parameters (within its limits) to each of the individuals of the population. The result is a population of individuals, each with its own unique set of random parameters. Each of the individuals is then evaluated using the objective function. The size of the population (NIND) is somewhat arbitrary, and can be based on the number of parameters to be optimized, on the expertise of the user, on the choice made in similar problems, or by trial and error.
2.4. General Loop
After the initialization, the initial population passes through the general loop of the genetic algorithm. This loop contains the following elements: Selection crossover and mutation. Each repetition of the loop is called a generation. This loop is repeated until a maximum number of generations (NGMAX) is reached, an acceptable value of the objective function is reached, or the population becomes stagnant (no change for a large number of generations).
The selection process consists of choosing two individuals to continue to the crossover function. The method proposed by [11] is used in this study, although many other methods exist. This method can be likened to a weighted roulette, where the better performing individuals (according to their NSEPEN) have a better probability of being selected.
The method suggested by [12] is used for the crossover function. The first step is to generate a random number, between 0 and 1. If this number is smaller than a user determined crossover probability (PCROSS), then the crossover function is applied. Otherwise, crossover is skipped, and the algorithm moves onto the next section (mutation). PCROSS is typically close to 100%, but is ultimately the user’s choice. The objective of the crossover function is to create new individuals (offspring) by modifying the parents chosen by the selection process, P1 and P2. Three offspring (R1, R2, and R3) are created, each are a copy of one of the parents, but with random parameters modified in a way specific to each offspring. The two best performing offspring are kept and replace the parents in the population.
The methodology described by [13] is used for the mutation function. Similar to the crossover function, a probability of mutation (PMUTA) is defined, typically close to 0%. If a random number, between 0 and 1, is smaller than PMUTA, than the mutation function is applied. Otherwise, it is skipped for the generation. If there is mutation, then a random individual is selected from the population. A random parameter is selected from this individual. This parameter is modified in the way described by [13] , before returning to the population, thus completing a generation.
At the end of each generation, potentially three individuals differ from the original population: Two from crossover, one from mutation. Repeating this process simulates the evolution of the population, which should get stronger with time. In other words, as the generations go by, better performing individuals should start replacing worse performing individuals. Eventually, the population should converge towards an optimum solution, or at least very close to it.
2.5. Sensitivity Analysis
The main objective of this sensitivity analysis is to integrate the uncertainty on the estimated parameters in the prediction process. The uncertainty on the parameters is estimated by the separate calibration of several overlapping periods of identical length (1975-1984, 1976-1985, 1977-1986, etc.). This creates a sample of calibrated parameter sets. In other words, the years 1975-1984 (10 years) would be calibrated resulting in a set of parameters. The years 1976-1985 (also 10 years) would be calibrated separately as well, resulting in another set of parameters, most likely with at least slightly different values from the first. The same is done for 1977-1986, 1978-1985, etc. This results in several sets of parameters, from which the mean and standard deviation of each parameter is calculated. Given that the support of each parameter is physically bounded (belong to the interval [x min, x max]), a Beta distribution (Equation (6)) is assumed to represent each parameters’ distributions. This would give 29 different Beta distribution, one for each parameter of the CEQUEAU model.
 (6)
(6)
where:
Beta(x): Beta probability density function
p1: Parameter (>0) of the Beta distribution
p2: Parameter (>0) of the Beta distribution
xmin: Inferior limit of the variable x
xmax: Superior limit of the variable x
The parameters of the Beta distributions are estimated by the method of the moment based on the mean and the variance. A bootstrap approach [14] is then used to simulate a large population of possible combinations of the parameter vector. Random values for each parameter are generated from its corresponding Beta distribution. This population is evaluated by the objective function, allowing an evaluation of the sensitivity of the objective function to the variations of each parameter.
3. Case Study
The study area is the Miramichi River watershed. It is situated in central New Brunswick (Figure 4). It is the second largest watershed in the province with a drainage area of approximately 14,000 km2, second only to that

Figure 4. Map of the Miramichi River watershed and the sub-basins corresponding to the hydrological gauging stations used in this study.
of the Saint John River. Its maximum dimensions are approximately 190 km east-west and 95 km north-south. There are two major sub-basins: the Northwest Miramichi (3900 km2) and the Southwest Miramichi (7700 km2) [15] .
The study period is separated in two:
- Calibration period: January 1st, 1975 to December 31st, 2000 (26 years). This time period is used to optimize the model’s parameters.
- Validation period: January 1st, 2001 to December 31st, 2009 (9 years). This time period is used to verify the model’s performance.
3.1. Physiographic Characteristics
The southeast region of the watershed is part of the New Brunswick plains, whereas the northwest region is in the highlands. The extreme northwest is part of the mountainous region that contains Mount Carleton, the province’s highest point, at 817 m. The two major tributaries, the Northwest and Southwest Miramichi, run principally from west to east. These two tributaries meet and form the Miramichi River, which runs for approximately 25 km before it discharges into its estuary of approximately 300 km2. A few smaller rivers also discharge into this estuary, combing for around 1400 km2 of the watershed. Although there are very few large lakes in the watershed, the highlands contain several small lakes. The plains region of the watershed contains a significant amount of wetlands. Around 90% of the watershed is covered by forest.
3.2. Division of the Watershed
For the application of the CEQUEAU model, the watershed was divided into 128 whole squares of 12 km × 12 km. These whole squares were then divided into 328 partial squares. The percentages of these squares covered by lakes, wetlands and forests are determined using GIS data available from Natural Resources Canada.
3.3. Meteorology
On average, the watershed receives precipitation 160 days per year [16] . The mean annual rainfall is approximately 1130 mm [17] . November has the highest average precipitation at 109 mm [17] . The mean annual air temperature is 4.3˚C [16] , with the mean monthly temperatures varying between 11.8˚C in January to 18.8˚C in July [17] . Ten meteorological stations were used in this study. For whole squares without meteorological stations, an interpolation of the data measured at the nearest three stations is done.
3.4. Hydrology
The mean annual flow of the Miramichi River is estimated at 317 m3/s and the median at 158 m3/s [17] . The runoff associated with a 5 year recurrence flood is 23.9 mm and that of a 5 year recurrence drought is 0.16 mm [17] . This represents a flow at the river outlet of 3 870 m3/s and 25 m3/s respectively. Maximum flows typically occur in April or May, largely due to snowmelt [16] . The lowest flows occur in winter and summer.
Four hydrometric gauging stations are active on the watershed. The largest of the four, with a drainage area of 5050 km2, is located on the Southwest Miramichi at Blackville. This station is used for the calibration. The other three stations are used as a spatial validation. In other words, they are used to see if the parameters determined by the optimization at one location can be used elsewhere on the watershed. The data used were obtained from the HYDAT database [18] . Table 1 presents information regarding these stations.
4. Results
The allowed range for each parameter and its optimized value are presented in Table 2. The parameters seem to have taken physically logical values and do not seem to be limited by either the maximum or minimum limit. The parameters of the algorithm itself (NIND, PCROSS, PMUTA, and NGMAX) were chosen to be 400, 85%, 1%, and 10,000 respectively. However, when NGMAX was reached, the population was still evolving, therefore the algorithm was allowed to run for an additional 5000 generations, which allowed the population to converge to an optimum solution, and thus become stagnant. The optimal solution was obtained after slightly more than 12,000 generations (of the total 15,000 that were run). In other words, no change in the optimum solution was

Table 1. Hydrological gauging stations information.
Table 2. Parameters of the CEQUEAU model optimized by genetic algorithm.
obtained in the last 3000 generations. This was deemed a sufficient amount to consider the population as stagnant, with the optimum solution having been obtained.
For the calibration period (1975-2000), using the station on the Southwest Miramichi River, both the NSE and NSEPEN are 0.83, and NSEBM is 0.50. For the validation period (2001-2009, same station), both the NSE and NSEPEN are 0.78, which is slightly lower than that of the calibration period. The NSEBM for the validation period is 0.53. The flow duration curve (FDC) for these periods are shown in Figure 5. It should be noted that the NSEPEN and NSE values are identical every year for both the calibration and validation. For this reason, only the NSEPEN will be shown in remaining tables.
Figure 5(a) shows that the lowest simulated flows (surpassed 90% - 100% of the time) are similar to those observed, but slightly overestimated, with an average bias of 3.1 m3/s (13.8%). The low and medium flows (surpassed 30% - 90%) are generally overestimated, with an average bias of 10.1 m3/s (22.3%). The higher flows (10% - 30%) were underestimated, with an average bias of −13.2 m3/s (7.6%). The highest simulated flows (0% - 10%) are similar to the observed flows, with an average bias of 16.25 m3/s (3.1%). The simulated median (75.8 m3/s) is higher than the observed median (64.0 m3/s). The FDC for the validation period (Figure 5(b)) resembles the FDC of the calibration period, with similar comments to be made.
4.1. Annual Decomposition
To better visualize the results, each year was analyzed individually. Table 3 shows the NSE and NSEPEN of each individual year. The year 1997 had the best performance (NSEPEN = 0.96, NSEBM = 0.52), whereas 1992 had the worst performance (NSEPEN = 0.41, NSEBM = 0.33), both of which are during the calibration period.
Figure 6(a) and Figure 6(b) present the hydrograph and FDC of 1992 respectively, while Figure 6(c) and Figure 6(d) present the hydrograph and FDC of 1997 respectively. During the validation period, the year with the best performance is 2003, with an NSEPEN of 0.87 and NSEBM of 0.68, whereas the worst performing year is 2006, with an NSEPEN of 0.46 and NSEBM of −0.12.
The 1997 hydrograph shows that the spring and summer flows were very well simulated, but the winter and fall flows were not quite as well simulated. It is also noticeable that no significant fall peak was observed, which is not typical for the region. The FDC is similar to the FDC of the entire period, with similar tendencies of over and underestimation. On the other hand, the 1992 hydrograph shows that although the fall and winter flows were well simulated, the spring floods were significantly overestimated. The observed spring peak was on April 22nd (522 m3/s), while the simulated peak was on April 23rd (774 m3/s). This is an error for the intensity of the peak of 42.5%, while the timing of the peak was off by a day. On average, the daily flow was overestimated by 40.4 m3/s during the spring; an average error of 24.9%. Smaller peaks were also observed and underestimated in the summer. These peaks are not typical in the region.
 (a) (b)
(a) (b)
Figure 5. Observed and simulated FDCs of the Southwest Miramichi gauging station for both (a) the calibration period and (b) the validation period.

Figure 6. Year with the worst performing simulation’s (a) hydrograph and (b) FDC, and the year with the worst performing simulation’s (c) hydrograph and (d) FDC.
4.2. Spatial Validation
Spatial validation was done using three additional hydrological gauging stations: Northwest Miramichi River (NWM), Little Southwest Miramichi River (LSWM) and Catamaran Brook (CAT) (see Table 1 and Figure 4). The NSEPEN and NSEBM values of the three stations for their respective validation periods is presented in Table 4. The NSE values were not presented in this table because they are all identical to the NSEPEN values.
All three stations have inferior performances to that of the calibration station, which is to be expected. However, the difference is not large, and the performances are still good. The best performing station seems to be the largest of the three, whereas the worst performing stations is the smallest of the three. For the sake of brevity, the FDCs or hydrographs are not shown. It should however be noted that they are similar to those of the calibration.
Table 3. Nash-Sutcliffe Efficiency criterion with penalty (NSEPEN) and benchmark (NSEBM) for each year of calibration (1975-2000) and validation (2001-2009).
Table 4. Nash-Sutcliffe Efficiency criterion with penalty (NSEPEN) and benchmark (NSEBM) per year for each gauging station used for spatial validation.
4.3. Sensitivity Analysis
A population of 2 000 parameter sets was created using the fitted Beta distribution of each parameter. A histogram of NSEPEN is presented in Figure 7.
Most of the NSEPEN values are greater than 0, with a good portion of these being greater than 0.5. A value of 0 indicates a simulation that is equivalent to using a single constant value, the mean of all observed values, as a simulation. A value of 0.5 indicates that the simulations is approximately equal to the benchmark model used, and is therefore a decent simulation, but no better than a very basic model. The maximum NSEPEN value obtained during the analysis was 0.74. This is less than the 0.83 obtained during the model calibration, which is to be expected. The minimum NSEPEN value obtained (−3.75) is very low. There are a few other bad simulations as well in the population of 2 000. 29% of the population have an NSEPEN greater than 0.5, and are thus an improvement on the benchmark model, and are therefore fairly good simulations. 47% of the population have an NSEPEN between 0 and 0.5. These are decent simulations in the sense that they are better than using just a single mean value as a model, but perform worse than the benchmark model. The remaining 24% have an NSEPEN smaller than 0, and are thus poorly performing simulations. There does not appear to be a particular value (or small range of values) of any one parameter that consistently produces these bad simulations. This indicates that no one parameter is sensitive enough to be responsible for most or all of the bad simulations. It is more likely that particular combinations of parameter values would cause these bad simulations. For example, a simulation with a high snowmelt rate might have a low NSEPEN value if the soil (Upper Zone) parameters didn't allow for much absorption into the reservoir or gradual discharge out of the reservoir. This could cause excessive spring floods, whereas a simulation with the same high snowmelt rate might provide a much better simulation if the soil parameters allowed for a better modeling of the spring flood.
It would appear that the scatter plots of NSEPEN as a function of the parameter value (one plot per parameter) can be categorized into three different categories, shown in Figure 8, as follows:
- A maximum value of NSEPEN with a high variance near the center of the point mass. Left and right extremities with less variability, but with lower values of NSEPEN (Figure 8(a));
- An asymmetric distribution, concentrated near one of the limits of the parameter. The variability of NSEPEN is higher at this limit than elsewhere on the plot (Figure 8(b));
- Very little correlation between NSEPEN and the value of the parameter. There can be a maximum or areas of high or low variability (Figure 8(c)).
As can be seen in Figure 8, there is a lot of variability in the scatter plots. This implies that there is a lot of uncertainty in the parameters. In other words, the 17 different calibrations of 10 year periods did not produce the same parameter sets as one another.

Figure 7. Histogram of the NSEPEN values of the sensitivity analysis.
 (a) (b) (c)
(a) (b) (c)
Figure 8. Different scatter plot distribution categories found in the sensitivity analysis. (a) STRNE; (b) HINT; (c) EXXKT.
5. Discussion
The study showed that the optimization of the CEQUEAU model using a genetic algorithm appeared to be successful. The NSE (without penalty) and NSEPEN (with penalty) of 0.83, and the NSEBM (benchmark model) was of 0.50. The NSEBM of 0.50 would seem to indicate that there is an annual cycle present, but that there is still a significant inter-annual variability. The CEQUEAU model improved upon this value by 0.33, a significant increase. These results show that the model performed well during the calibration, accounting for much of the variability not accounted for by the benchmark model. The model also performed well during the temporal validation, producing a NSEPEN of 0.80. This is slightly inferior to the NSEPEN value of 0.83 obtained for the calibration period. This can be explained by many different factors. The physical characteristics of the watershed can change with time, but the model considers them as being constant. For instance, some logging is known to have occurred on the drainage basin, but this was not accounted for in the physiographic data extraction. Also, there are fewer active meteorological stations during the validation period than during the calibration period. This could lead to less accurate meteorological input. By the end of the validation period, only three stations were active, which makes accurately portraying the meteorology over such a large area very difficult. Given these facts, the model still performed well, indicating that it could be used for future predictions. The NSEBM for the validation period was of 0.53, a very similar value to that of the calibration period. Similar conclusions can be drawn here as were drawn for the calibration period.
The model also performed well during the spatial validations using three stations on the watershed. These stations produced NSEPEN values of 0.77, 0.76 and 0.74 respectively. This is less than the NSEPEN value at the calibration station (0.83). This can be partially explained by the fact that the three validation stations are located on a different sub-basin than the calibration station. The latter is part of the Southwest Miramichi sub-basin, whereas the others are part of the Northwest Miramichi sub-basin. Different latitudes, meteorology, elevations, soil type, etc., could easily cause a difference in the behaviour of these sub-basins’ respective systems. For example, snowmelt could occur at a different threshold and rate for the two regions, or the ground could be less permeable for one of the regions, implying different infiltration and discharge coefficients. It should also be noted the NSEBM values of the entire period for each station were 0.52, 0.50, and 0.50 respectively. These are similar to the values obtained for the calibration station (Southwest Miramichi, calibration and validation periods). This is to be expected, since the stations are in the same region, and should be subject to the same inter-annual variability (e.g. a unusually wet autumn would most likely be observed at all the stations, and not just one). It is also interesting to note that the difference between the NSEPEN and NSEBM for these stations (approximately 0.25) is smaller than that noted for the calibration station (033). This could be due to the reasons listed above, but could also be influenced by the size difference between the watersheds. Smaller watersheds tend to be less stable and more susceptible to perturbation. As such there may be smaller time scale variability that is not present in the larger watershed. Therefore, when the larger watershed was being calibrated, there was no need for the algorithm to attempt to model the kind of smaller scale variation that is present in small watersheds. Consequentially, this become unaccounted for, resulting in smaller NSEPEN values.
It should be noted that for both the calibration and validation periods, the NSE and NSEPEN are always nearly identical. This implies that the penalty was sufficient in directing the algorithm away from implausible solutions (empty lakes, wetlands, water table or river). It would be interesting to use different magnitudes of penalties to verify the effect on the algorithm. It should also be noted that the algorithm was applied using on the raw NSE value in a separate attempt to calibrate the model. The results were similar in terms of NSE values, but there was a difference between the two calibrations. The raw NSE calibration would tend to simulate flows near 0 m3/s during low flow periods, but would slightly more accurately model the peak flow periods. This is most likely because of the definition of the NSE itself, where the error between the observation and simulation is squared. That would mean that an error of 200 m3/s on an observed peak of 2000 m3/s would have a much larger negative impact on the NSE value than simulating a flow of 0 m3/s for an observed flow of 20 m3/s. As such, it was deemed that the application of a penalty was useful, because it kept the calibration from producing unrealistic simulations. It should also be noted that the algorithm can have difficulty distinguishing between two or more excellent solutions. Consequently, the algorithm may return a solution that is not optimum, but close to optimum. For the present application, this is deemed acceptable.
Observing the FDCs, it is noticeable that there seems to be a tendency to overestimate low flows and underestimate high flows with the optimized model. Reference [19] showed in order to maximize the NSE, the variance must be underestimated. This is probably the cause of the overestimated low flows and underestimated high flows. In addition, the NSE criterion compares simulated results to one specific value (mean). Consequentially, time series with more variations tend to be more penalized than those without these variations (long droughts, for example).
The results show that there is a high variability in the yearly NSE values, with some being close to 1, while others were below 0.5. This can be partially explained by the differences in the hydrographs between years. Some years there are very strong periods of high flow in the fall, perhaps even higher than those in the spring. Other years there may be no fall floods at all. The freeze and thaw may not happen at the same time every year, or may happen several times in a year. This is often reflected in the NSEBM of that year. The years that differ from the typical annual cycle would have lower NSEBM because the benchmark model is based on average values. In general, a low NSEBM is accompanied by a low NSEPEN for the same year. The opposite is also true, with a high NSEBM being generally accompanied by a high NSEPEN. It seems that the Little Southwest Miramichi (LSWM) station does always follow this pattern. For example, the year 1987 was an atypical year, with almost no spring peak (300 m3/s). This is reflected in the NSEBM value for that year (−0.62). However, the NSEPEN value was still very good (0.85). There are also two years (1982, 1995) where the NSEBM values were higher than the NSEPEN values, and several others where the two values were close. This does happen at other stations, but not frequently. This could perhaps indicate that the parameters calibrated at the Southwest Miramichi station suit its own annual cycle well, but not that of the Little Southwest Miramichi. Another possible explanation would be that there are significant differences in the regime at the Little Southwest Miramichi, and that there is maybe a cause of variability present at that basin that is not present at the Southwest Miramichi basin, or vice-versa. A more detailed analysis should be conducted to determine if this is the case. There could be localized storm events, which may not be properly measured by the meteorological stations, causing high observed flows where the model has little or no input precipitation. The best performing year, 1997 (see Figure 6), had generally few flow variations, with the exception of a typical spring flood. Winter and summer flows were fairly constant, and fall did not see any particularly high flows either. In contrast, the worst performing year, 1992 (see Figure 6), had a very small spring flood, with a fall flood that saw almost the same peak flows. There were also multiple smaller peaks during the summer months. This is not typical of the region. Observations on individual years, however, should be made carefully. A particular year is dependent on the previous ones. For example, a year that is well simulated, save for the last few days would have a high NSE, but those last few badly simulated days could carry over to the next year and cause a bad NSE for that year.
Similarly to this study, [3] studied the Catamaran Brook using the CEQUEAU model. This is particularly interesting, since this gauging station is used to validate the model in this study. In this study, the NSE value found while calibrating manually using the Catamaran Brook discharge data was close to 0.61 (from 1990-1995). In the present study, the value was found to be 0.70 for the same time period. Since this was only used as a validation, if the station would have been used to calibrate, it is logical to assume that the NSE would have been even higher. [20] also applied the CEQUEAU model to a small watershed (70 km2), obtaining NSE values between 0.40 and 0.78. [21] analyzed a semi-arid watershed (1442 km2) with long periods of drought and a dam, obtaining NSE values of above 0.89. The NSE found in the present study (0.83) is within these ranges of values. Of course it is difficult to compare NSE values of different areas with different variability and cycles, so evidently the results of other studies should be taken lightly.
The sensitivity analysis showed that the NSEPEN values were mostly greater than 0.5. This implies that the model is not sensitive to the point where random individuals produce bad results. There is doesn't seem to be any particular parameter that is solely responsible for the poorly performing simulations; i.e. good performing simulations can be found throughout the entire range of each parameter. The inverse is also true, where bad performing simulations can be found throughout the entire range of each parameter. There was also a significant gap between the maximum value of the sensitivity analysis and the value optimized by the genetic algorithm. This indicates that the algorithm was beneficial in finding an optimum solution. This means that even with a large amount of individuals generated randomly, with a good portion of them having similar parameters to the optimized values found by the algorithm (parameters producing an NSEPEN of 0.83), these random individuals did not match the optimized value. This indicates that the model is sensitive to small perturbations in the parameters. Given this, and the fact that the entire range of each parameter can produce good performing simulations, it would seem to indicate that it is more important that the parameters work well together as opposed to there being one perfect value for each parameter. It should be noted that there is a large variability in the scatter plots, indicating uncertainty in the parameters. This is probably caused by the small sample size (17). Consequentially, the Beta distributions used to model each parameter distribution allows an important variability in the parameters, which is reflected in the NSEPEN values. It could also be caused by variability in the hydrographs from year to year. This would cause the different samples of 10 years to be calibrated differently, causing higher variability in the random values produced by the Beta distribution. Some parameters have a stronger correlation to the NSEPEN then others, implying they have a greater impact on the latter.
These results indicate that the model performed well, implying that the genetic algorithm was successful in calibrating it. However, it should not be forgotten that the efficiency of the genetic algorithm can be influenced by several factors, such as: population size, crossover probability, mutation probability, and stopping criterion. Different combinations of these should be tested to see the impact on the algorithm.
6. Summary and Conclusions
A deterministic approach using the CEQUEAU model was used to model water flow and temperature of the Miramichi River watershed. As is the case with many deterministic models, parameter optimization can be challenging. A genetic algorithm was used for the calibration of the CEQUEAU model in order to optimize its parameter values. These results were compared to the results obtained by using a simple benchmark model (average flow per calendar day). The results show that the calibrated flow model performed well during the calibration period, the temporal validation period, and while using the three spatial validation gauging stations. This implies that the model can be used for predictions at multiple locations on the watershed. The fact that the calibrated CEQUEAU model performs well indicates that the genetic algorithm also performed well. There is no guarantee that the calibrated model is in fact the best solution possible, it does however appear that the algorithm at the very least provides a good solution.
It would be interesting for further studies to use the genetic algorithm applied in this study on different watersheds and different situations in order to better explore its strengths and weaknesses, and potentially improve the algorithm. In particular, different objective functions should be considered, since the Nash-Sutcliff Efficiency seemed to be at least partially responsible for the underestimation of high flows and overestimation of low flows. Different types and magnitudes of penalties could also be explored in order to better understand their effect on the algorithm and the calibrated model.
Acknowledgements
The authors would like to thank M. Daniel Caissie and Ms. Loubna Benyahya for their respective contributions to the study. The authors would also like to acknowledge the funding provided by the Université de Moncton, the New Brunswick Innovation Foundation (NBIF) and the Association of Professional Engineers and Geoscientists of New Brunswick (APEGNB).
Cite this paper
Jasmin Boisvert,Nassir El-Jabi,André St-Hilaire,Salah-Eddine El Adlouni, (2016) Parameter Estimation of a Distributed Hydrological Model Using a Genetic Algorithm. Open Journal of Modern Hydrology,06,151-167. doi: 10.4236/ojmh.2016.63013
References
- 1. Morin, G. and Paquet, P. (2007) Modèle Hydrologique CEQUEAU, INRS-ETE: Rapport de Recherche No R000926. INRS-ETE, Québec City.
- 2. INRS-ETE (2015) Modèle Hydrologique CEQUEAU.
http://ete.inrs.ca/ete/publications/modele-hydrologique-cequeau - 3. St-Hilaire, A. (2000) Modélisation de la Température de l’Eau et des Solides Dissous en Rivière sur un Petit Bassin Versant Forestier. Ph.D. Thesis, Université de Québec (INRS-EAU), Québec City.
- 4. Beven, K.J. (1996) A Discussion of Distributed Hydrological Modelling. In: Abbott, M.B. and Refsgaard, J.C., Eds., Distributed Hydrological Modelling, Springer, Netherlands, 255-278.
- 5. Refsgaard, J.C. and Storm, B. (1996) Construction, Calibration, and Validation of Hydrological Models. In: Abbot, M.B. and Refsgaard, J.C., Eds., Distributed Hydrologic Modeling, Kluwer Academic Publishers, Dordrecht, 41-54.
- 6. US Army Corps of Engineers, North Pacific Division (1956) Snow Hydrology; Summary Report of the Snow Investigation. Portland, Oregon.
- 7. Holland, J.H. (1975) Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. MIT Press, Cambrige.
- 8. Goldberg, D.E. (1989) Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley, Reading.
- 9. Krause, P., Boyle, D.P. and Base, F. (2005) Comparison of Different Efficiency Criteria for Hydrological Model Assessment. Advances in Geosciences, 5, 89-97.
http://dx.doi.org/10.5194/adgeo-5-89-2005 - 10. Schaeflie and Gupta (2007) Do Nash Values Have Value? Hydrological Processes, 21, 2075-2080.
http://dx.doi.org/10.1002/hyp.6825 - 11. Davis, L.D. (1991) Handbook of Genetic Algorithms. Van Nostrand Reinhold, Bloomington.
- 12. Wright, A.H. (1991) Genetic Algorithms for Real Parameter Optimization. In: Rawlin, G.J.E, Ed., Foundations of Genetic algorithms, Morgan Kaufmann, San Mateo, 205-218.
http://dx.doi.org/10.1016/b978-0-08-050684-5.50016-1 - 13. Michalewicz, Z. (1992) Genetic Algorithms + Data Structures = Evolution Programs. Springer-Verlag, New York.
http://dx.doi.org/10.1007/978-3-662-02830-8 - 14. Chernick, M.R. (1999) Bootstrap Methods: A Practitioner’s Guide. John Wiley and Sons, Inc., Toronto.
- 15. MREAC (Miramichi River Environment Assessment Committee) (2007) State of the Environment Report for the Miramichi Watershed - 2007. Environment Canada.
- 16. Chiasson, A.G. (1995) Miramichi Bay and Estuary: An Overview. In: Chadwick, E.M.P, Ed., Water, Science, and the Public: The Miramichi Ecosystem. NRC Research Press, Ottawa, 11-27.
- 17. Caissie, D. and El-Jabi, N. (1995) Hydrology of the Miramichi River Drainage Basin. In: Chadwick, E.M.P., Ed., Water, Science, and the Public: The Miramichi Ecosystem. NRC Research Press, Ottawa, 83-93.
- 18. Environment Canada (2015) HYDAT Database. https://www.ec.gc.ca/rhc-wsc/default.asp?lang=En&n=9018B5EC-1
- 19. Gupta, H.V., Kling, H., Yilmaz, K.K. and Martinez, G.F. (2009) Decomposition of the Mean Squared Error and NSE Performance Criteria: Implications for Improving Hydrological Modelling. Journal of Hydrology, 377, 80-91.
http://dx.doi.org/10.1016/j.jhydrol.2009.08.003 - 20. Martin, S. (1995) Modélisation Pluie-Débits en Régions Semi-Arides: Cas du Bassin Muwaqqar. M.Sc.A. Thesis, Université de Moncton, Moncton.
- 21. Ayadi, M. and Bargaoui, Z. (1998) Modélisation des écoulements de l’Oeud Miliane par le Modèle Cequeau. Hydrological Sciences Journal, 43, 741-758.
http://dx.doi.org/10.1080/02626669809492170