Open Journal of Statistics
Vol.06 No.01(2016), Article ID:63398,11 pages
10.4236/ojs.2016.61003
Hypothesis Testing of Population Percentiles via the Wald Test with Bootstrap Variance Estimates
William D. Johnson*, Jacob E. Romer
Department of Biostatistics, Pennington Biomedical Research Center, Louisiana State University, Baton Rouge, LA, USA
![]()
Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 2 December 2015; accepted 11 February 2016; published 14 February 2016
ABSTRACT
Testing the equality of percentiles (quantiles) between populations is an effective method for robust, nonparametric comparison, especially when the distributions are asymmetric or irregularly shaped. Unlike global nonparametric tests for homogeneity such as the Kolmogorv-Smirnov test, testing the equality of a set of percentiles (i.e., a percentile profile) yields an estimate of the location and extent of the differences between the populations along the entire domain. The Wald test using bootstrap estimates of variance of the order statistics provides a unified method for hypothesis testing of functions of the population percentiles. Simulation studies are conducted to show performance of the method under various scenarios and to give suggestions on its use. Several examples are given to illustrate some useful applications to real data.
Keywords:
Bootstrap, Hypothesis Testing, Nonparametric Methods, Percentile Profiles, Wald Test

1. Introduction
When comparing the distributions of a random variable observed under different conditions, there often is interest in testing equality of the parameters that circumscribe the respective central tendency of the condition-depen- dent observations. Thus, a standard t-test is often used when the data are (approximately) normally distributed, although under certain conditions, other parametric models may be used. Parametric tests may be adequate under some conditions, but there are many situations where the underlying distributions have irregular forms and parametric approaches to testing for distribution equality are inappropriate. When the underlying parametric distribution is unavailable or ignored, nonparametric methods such as the Mann-Whitney U test or Kolmogorov- Smirnov (KS) test are often employed to test the null hypothesis that the sample data come from random variables that have identical distributions, regardless of the imposed circumstance. Tests for equality of location may be too narrow in that they test a single parameter and ignore other aspects that often distinguish the distributions. On the other hand, global tests of equality such as the KS test are too broad and do not specifically portray where the distributions have significant discrepancies. Use of percentiles (quantiles) may be uniquely informative for comparing skewed distributions that do not have similar shapes.
For instance, suppose a treatment causes a substantial shift in only one segment of the population, such as those with biomarker levels in the range of the 90th percentile or above, and is virtually ineffective for those with levels below the 90th percentile. A location test may be less likely to detect this difference. Testing the equality of several, pre-specified percentiles (a percentile profile) along the entire range of the distribution will be insightful. In this paper, we illustrate the use of the Wald test employing variance estimates obtained via bootstrap samples to test for equality of population percentiles. In this way, it is possible to test the statistical significance of differences along the entire range of the distribution. Similarly, we can construct confidence intervals for the population-level differences for each percentile between the respective distributions. Statistical inferences based on percentile estimation are also advantageous in that the methods are robust to outliers and can be used when the data have complexly-shaped distributions.
A motivating example (which we explain in detail in Section 5) comes from the National Health and Nutrition Examination Surveys (NHANES), a program of studies to monitor the health of adults and children in the United States (http://www.cdc.gov/nchs/nhanes.htm). One variable of interest is C-reactive protein (CRP) in adults―mainly, whether the distribution of CRP differs with diabetes diagnosis. Plotting the empirical density of log(CRP) for adults who are normal (do not have prediabetes or diabetes), adults who have prediabetes, and adults who have diabetes clearly reveals differences in distribution and hence percentiles (Figure 1). A median test or Mann-Whitney U test will detect some change in the median location between diabetes diagnosis groups, but this may be insufficiently informative due to the unusual shape of the data. To truly understand the differences, we require comparisons spanning the entire domain of a relevant biomarker for diabetes.
Johnson et al. [1] developed an extension of the median test to simultaneously test the homogeneity of any number of percentiles between groups. In this procedure, the samples from all groups are combined and com-

Figure 1. Kernel density estimates of log(CRP) of normal, prediabetes, and diabetes groups for males and females.
mon percentile estimates are found (as in the median test). These percentile estimates are used as cutoff points to sort the data from the respective comparative groups into columns of a contingency table where each row contains categorized data for a specific group. The authors then applied Pearson’s chi-square test to assess the homogeneity of the groups with respect their percentile profiles. The procedure proposed in [1] provides a heuristic and easy to use approach for performing overall joint tests of equality of a set of percentiles among multiple distributions, but it is limited by awkward methods for testing sub-hypotheses and constructing confidence intervals on differences and other functions of the percentiles of interest. Formulating the problem as a Wald statistic and using bootstrap estimates of the covariance matrix of the population percentiles provides unified methods for statistical testing and confidence interval construction.
There has been extensive work in quantile estimation and estimation of variance of quantiles with use of bootstrap resampling [2] -[7] . Bootstrapping is an invaluable tool to obtain estimates of variance of statistics, such as sample quantiles/order statistics, that are difficult to estimate without model parametrization. Wilcox [8] outlined a similar procedure for comparing quantiles of two independent samples by utilizing bootstrap estimates of variance. Hutson and Ernst [9] derived closed-form solutions for the exact bootstrap mean and variance of L-estimators, which could be applied to the present problem. In this paper, we formulate the statement of a general linear hypothesis in terms of linear functions of a population vector of percentile profiles. We also formulate a Wald statistic for testing this general hypothesis. This test statistic has a distribution that approaches that of a chi-square when the original sample sizes are sufficiently large. One advantage of the Wald test is it provides the ability to test multiple parameters jointly and construct contrasts on the functions of the population percentiles in terms of vectors and matrices. It can also be used with estimates from any percentile estimator and bootstrapping plan (n out of n, m out of n, etc.). This flexibility and ease of use make the Wald test a natural method for testing equality of percentiles and constructing confidence intervals on functions of percentiles. Its practicality is evident in large-sample applications, as illustrated by examples.
The paper is organized as follows: Section 2 explains the details of the procedure as well as a brief numerical tutorial. Section 3 provides some details of bootstrap sampling methods with respect to sample percentile covariance estimation. Results of selected simulation studies are presented in Section 4 followed by an illustrative example in Section 5 in which we explore the motivating example (differences in CRP distribution among diabetes groups) by testing several hypotheses. Section 6 is left for concluding remarks and discussion of further research.
2. Methods
2.1. Inference for a Single Percentile
Suppose we wish to construct a confidence interval for a population percentile which is defined as the value of the quantile function Q(∙) evaluated at some u. Thus, Q(u) is a quantile of interest and q(u) is its sample estimator. Note that Q(u) can be estimated a number of ways (we henceforth refer to q(u) and Q(u) as simply q and Q,
respectively). We define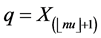 , where X is the sample, n is the number of observations, ⌊∙⌋ denotes the floor function, and X(r) denotes the rth sample order statistic. By this definition, estimation of the population
, where X is the sample, n is the number of observations, ⌊∙⌋ denotes the floor function, and X(r) denotes the rth sample order statistic. By this definition, estimation of the population
percentile and estimation of the percentile variance are equivalent to estimating the expected value and variance of the sample order statistics. With this in mind, it is possible to use linear combinations of sample order statistics as percentile estimators, though here we only focus on using single order statistics. We can obtain an estimate of the variance of Q by generating B bootstrap samples and obtaining q for each bootstrap sample, which is simply the (⌊nu⌋ + 1)th order statistic in the bootstrap sample. Without loss of generality, let 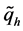 denote the estimate of Q for the hth bootstrap sample. The usual variance estimator v is
denote the estimate of Q for the hth bootstrap sample. The usual variance estimator v is
![]()
where B is the number of bootstrap samples and ![]() is the mean of the bootstrap estimates of Q. The
is the mean of the bootstrap estimates of Q. The ![]() confidence interval for Q can be calculated as
confidence interval for Q can be calculated as![]() . Note that if q is defined as a linear combination of the sample order statistics the appropriate covariance must be used.
. Note that if q is defined as a linear combination of the sample order statistics the appropriate covariance must be used.
If a second sample is available from an independent population and we wish to construct a confidence interval on Q1 − Q2, the difference of Q between the populations, we follow a similar procedure. First, obtain the sample estimates of Q for the first and second population: q1 and q2, respectively. Similarly, generate B bootstrap samples from each of the respective samples and calculate the variance of the![]() ’s (
’s (![]() ) for each population (as above). Let v1 and v2 denote the bootstrap variance estimate of the first and second populations, respec-
) for each population (as above). Let v1 and v2 denote the bootstrap variance estimate of the first and second populations, respec-
tively. The ![]() confidence interval for Q1 − Q2 can be calculated as
confidence interval for Q1 − Q2 can be calculated as ![]() (as-
(as-
suming the populations are independent and![]() ).
).
2.2. Comparing p Percentiles from K Populations
Suppose we are given a random sample from each of K independent groups and we wish to test the equality of the K groups with respect to their percentile profiles, where each profile consists of a set of p percentiles. Denote the percentiles to be tested as ![]() where
where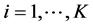 . The method proceeds as follows:
. The method proceeds as follows:
Step 1. Estimate the percentile profile of interest for each of K populations, where the estimate is denoted as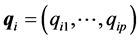 . Recall that the jth percentile estimate may be a single sample order statistic corresponding to ⌊nuj⌋ + 1 (
. Recall that the jth percentile estimate may be a single sample order statistic corresponding to ⌊nuj⌋ + 1 ( ) or a combination of multiple order statistics.
) or a combination of multiple order statistics.
Step 2. Arrange the percentile estimates in a Kp column vector, q, where .
.
Step 3. Generate B bootstrap samples from each of the original samples and estimate Q, the set of percentiles of interest, on each bootstrap sample. Let  denote the estimate of the percentile profile Q for the hth bootstrap sample from the ith population (
denote the estimate of the percentile profile Q for the hth bootstrap sample from the ith population ( and
and ). Further, let
). Further, let  be the B × p matrix of bootstrap percentile estimates from the ith population. There is no restriction on the bootstrap sampling plan; we illustrate the method with standard n out of n sampling.
be the B × p matrix of bootstrap percentile estimates from the ith population. There is no restriction on the bootstrap sampling plan; we illustrate the method with standard n out of n sampling.
Step 4. Compute the p × p covariance matrix  for
for  where IB is
where IB is
the identity matrix of dimension B and 1 is the column vector of ones of length B. Then, arrange the variance- covariance matrices in an overall block-diagonal covariance matrix, V, of dimension Kp × Kp where the off- diagonal matrices are 0:

Step 5. Consider the c × Kp contrast matrix A where 1 ≤ c ≤ (Kp − 1). To test the null hypothesis H0: Aq = 0, calculate the Wald test statistic
 (1)
(1)
Step 6. The  confidence interval for any linear function of a set of percentiles, say, aq, where a is a 1 × Kp vector of constants, is calculated by
confidence interval for any linear function of a set of percentiles, say, aq, where a is a 1 × Kp vector of constants, is calculated by
 (2)
(2)
where z1−a/2 is the 1 − a/2 critical value of the standard normal distribution. In general, A is chosen to jointly test the hypotheses of interest and each a, which could be an individual row of A, is taken separately to construct confidence intervals on the individual population percentiles corresponding to the linear combinations created by A. The level of α in Equation (2) may be adjusted for multiple tests using a method such as Bonferroni adjustment. The following numerical example illustrates some potential choices of a for generating confidence intervals of interest.
2.3. A Numerical Example for Two Populations
For illustrative purposes, consider the following example with simulated data with hypothetical values of q and V. We are given two independent samples (K = 2) and wish to test the equality of three percentiles (p = 3) between them, which we will refer to as the percentile profile Q = (Q1, Q2, Q3). Suppose that we are interested in the 25th, 50th, and 75th percentiles; i.e., u = (0.25, 0.5, 0.75). Let q1 = (5.04, 8.38, 11.21) and q2 = (4.00, 6.28, 9.95) be the estimates of the first and second populations’ percentile profiles, respectively. Arranging the sample estimates in a column vector q, we find

Next we obtain B bootstrap sample estimates of Q for each population and calculate the variance-covariance matrix of the bootstrap sample estimates. Then we calculate V, which is a Kp × Kp block-diagonal matrix with zeros (imposed by the assumption of independence) on the off diagonal blocks. In our example simulated data, we calculated V equal to

If we are interested in testing the equality of percentile profiles (H0: q1j = q2j for ), we choose A = [Ip| −Ip]. With point estimates of the percentile profiles, q, and estimated covariance matrix V, we have everything necessary to jointly test the hypothesis H0: Q1 = Q2 as in Equation (1) and construct confidence intervals for Q1 - Q2 as in Equation (2). The Wald statistic is W = 4.97 with 3 degrees of freedom so we conclude the differences between the percentile profiles are not statistically significant. To construct confidence intervals on the differences of the percentiles between the groups, we follow Equation (2). Let ai be the necessary constant vector to construct the confidence interval for the difference between the ith percentiles of the two populations. We have
), we choose A = [Ip| −Ip]. With point estimates of the percentile profiles, q, and estimated covariance matrix V, we have everything necessary to jointly test the hypothesis H0: Q1 = Q2 as in Equation (1) and construct confidence intervals for Q1 - Q2 as in Equation (2). The Wald statistic is W = 4.97 with 3 degrees of freedom so we conclude the differences between the percentile profiles are not statistically significant. To construct confidence intervals on the differences of the percentiles between the groups, we follow Equation (2). Let ai be the necessary constant vector to construct the confidence interval for the difference between the ith percentiles of the two populations. We have ,
,  , and
, and ; i.e., the rows of A. Using a Bonferroni adjustment on each estimate, the 95% confidence intervals are [−0.99, 3.07] for Q11 − Q21, [−0.17, 4.37] for Q12 − Q22, and [−1.78, 4.30] for Q13 − Q23.
; i.e., the rows of A. Using a Bonferroni adjustment on each estimate, the 95% confidence intervals are [−0.99, 3.07] for Q11 − Q21, [−0.17, 4.37] for Q12 − Q22, and [−1.78, 4.30] for Q13 − Q23.
Testing the equality of percentiles q1j = q2j for  is just one of many possible contrasts we could construct. For example, we could test the equality of the inter quartile range (IQR), the difference of the 75th and 25th percentiles, between the two populations. To test this, we simply specify a different contrast matrix A, which would be a 1 × Kp vector, where
is just one of many possible contrasts we could construct. For example, we could test the equality of the inter quartile range (IQR), the difference of the 75th and 25th percentiles, between the two populations. To test this, we simply specify a different contrast matrix A, which would be a 1 × Kp vector, where . Let
. Let  and
and  denote the estimate of the first and second population’s IQR and the difference as
denote the estimate of the first and second population’s IQR and the difference as . The variance estimate of
. The variance estimate of  is equal to
is equal to

This calculation is completed via matrix computations as in Equations (1) and (2). For the example above,
 and
and . The calculation using Equation (1) yields a W of 0.03 so we would conclude that the IQR of the populations are not significantly different.
. The calculation using Equation (1) yields a W of 0.03 so we would conclude that the IQR of the populations are not significantly different.
To test the equality of the IQR for K populations we generalize the above results. Let  be the 1 × p vector containing the contrast of interest. For testing the equality of the IQR with Q = (25, 50, 75),
be the 1 × p vector containing the contrast of interest. For testing the equality of the IQR with Q = (25, 50, 75), . For 2 populations, only one comparison is necessary and A is of dimension 1 × Kp. However, for K > 1, we require K − 1 comparisons, with A in the form of
. For 2 populations, only one comparison is necessary and A is of dimension 1 × Kp. However, for K > 1, we require K − 1 comparisons, with A in the form of

where 0 is the 1 × p row vector of zeros. In this case, A is a (K − 1) × Kp matrix where the non-zero 1 × p vectors are  and
and  for
for .
.
3. Simulation Studies
3.1. Accuracy of Bootstrap Variance Estimates
The convergence of bootstrap variance estimators of order statistics to the true variance has been demonstrated by Ghosh et al. [10] and Babu [11] , with the exact rate of convergence and coverage error of confidence intervals shown by Hall and Martin in [5] and [6] . Empirical studies in the present paper demonstrate this behavior for the normal and gamma distributions. Two million replicate samples were generated and the (⌊nu⌋ + 1)th order statistics corresponding to the values of u listed in Table 1 (for comparing N(0,1) distributions) and Table 2 (for comparing gamma(shape = 2, scale = 1)) were found as the empirical estimate of the variance/covariance of the particular order statistics, denoted as . The normal distribution and gamma distributions were chosen to investigate differences in the bootstrap covariance estimation between symmetric and highly-skewed distributions. The particular parameters chosen for the gamma distribution yields relatively large values of skewness, which is desired. These empirical estimates were compared to bootstrap variance/covariance estimates (denoted as
. The normal distribution and gamma distributions were chosen to investigate differences in the bootstrap covariance estimation between symmetric and highly-skewed distributions. The particular parameters chosen for the gamma distribution yields relatively large values of skewness, which is desired. These empirical estimates were compared to bootstrap variance/covariance estimates (denoted as ) of the same order statistics following steps 1 - 4 from Section 2 using B = 1000. All simulations were programmed and run in R 3.1.2.
) of the same order statistics following steps 1 - 4 from Section 2 using B = 1000. All simulations were programmed and run in R 3.1.2.
In general, the relative error of the bootstrap variance/covariance estimates decreases as sample size increases. In some instances (in small sample sizes, such as 20) the variance increases as sample size increases. This occurs in the extreme percentiles in both the normal and gamma samples. This likely occurs because the order statistics used for Q(0.05) and Q(0.95) are close to 1 and n. In bootstrap resampling, this causes artificially low estimates of variance when sample sizes are small due to the limited number of unique values that the particular

Table 1. Error relative to empirical expected value of bootstrap variance-covariance estimates from N(0,1).
Table 2. Error relative to empirical expected value of bootstrap variance-covariance estimates from gamma (2,1).
bootstrap order statistic may take. In these situations (Q(0.05) in normal samples, Q(0.05) and Q(0.95) in gamma samples) the expected behavior resumes at around n = 50. Also, it is important to note that all estimates of the variance of a single order statistic (excluding the 95th percentile estimate of gamma with n = 20) have positive bias while all estimates of covariance of two order statistics (excluding those that are arbitrarily small) have negative bias. It can be seen from Table 1 and Table 2 that the covariance estimates are considerably closer to being accurate than the variance estimates in terms of relative error. It would seem that because of the inflated bootstrap variance estimates that this would cause issues with the Wald test. In the next section further studies are shown to investigate the effects of the error of bootstrap variance and covariance estimates.
3.2. Performance of the Wald Test
Simulation studies were performed in which the Wald statistic was calculated for several percentile profiles that ranged from one up to nine equally-spaced percentiles. Other profiles were tested that included unevenly spaced percentiles with extreme percentiles in the tails of the distribution, referred to as Q1 = (0.05, 0.95), Q2 = (0.05, 0.25, 0.5, 0.75, 0.95), and Q3 = (0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.95), which specify the values of u in q(u). For example, testing one equally-spaced percentile would equate to the 50th percentile, or u = 0.5. Testing four percentiles would equate to testing the 20th, 40th, 60th, and 80th percentiles, or u = 0.2, 0.4, 0.6, 0.8. These percentile profiles, particularly ones with more than one percentile, are chosen to compare the populations across the entire sample space. Although the Wald statistic will vary depending on the profile chosen for a given sample, selecting a profile with similar values of u will cause only slight changes in the results of the test (more details later).
Again, the standard normal and gamma (2,1) distributions were used for empirical Type I error estimates to examine differences between symmetric (normal) and highly-skewed (gamma) distributions. As can be seen from the empirical type I error in Table 3 and Table 4, the shape of the distribution has little effect on the asymptotic behavior of the test as empirical Type I error is roughly the same under both scenarios. Also, the error of the bootstrap estimate of percentile variance appears to be substantially moderated when used in the Wald test. For example, the normalized error of the bootstrap variance estimate of the 5th percentile (the sixth order statistic for n = 100) in N(0,1) is 0.226 (from Table 1). It is assumed that the 95th percentile is roughly the same due to symmetry of the distribution though not exact due to the particular order statistics used. However, the empirical type I error of the Wald test comparing the 5th and 95th percentiles between the populations is 0.0483, which is unexpected considering the magnitude of the error of the bootstrap variance estimates. In another example, the normalized error of the bootstrap variance estimates of Q1 = (0.05, 0.95) for n =100 from gamma (shape = 2, scale = 1) are 0.185 and 0.310, respectively (from Table 2). However, the Wald test yields an empirical type I error of just 0.0475.
The results in Table 1 through Table 4 indicate that the Wald test is robust to large error of the bootstrap variance estimates of the percentiles, at least in the sense that type I error is less than the target value, 0.05 in this case. Also, profiles with more percentiles require greater sample size before convergence to the theoretical alpha
Table 3. Empirical Type I error (10,000 replicates) of Wald Test from N(0,1).
Table 4. Empirical Type I error (10,000 replicates) of Wald Test with from gamma (shape = 2, scale = 1).
level. For the parameters chosen in Table 3 and Table 4, the empirical type I error is adequate for samples as few as 20 in most cases, and for profiles with extreme percentiles (i.e. 5th and 95th) the type I error is adequate between sample size 40 and 60. As a general rule of thumb, sample sizes of at least 50 will give reliable results for profiles of any size and any percentile.
As mentioned previously, the primary purpose of the test is to compare the distributions of random variables among populations along the variable’s entire domain but have the added precision of testing the equality of specific parameters, i.e., the percentiles. With certain percentile profiles, the test has similarities of both: (1) tests that are designed to detect any difference between distributions, such as the KS test, and (2) tests on specific population parameters, such as the t-test for means. For comparative purposes, there is no procedure to the authors’ knowledge that explicitly tests a set of percentiles among populations. Rank or location tests as well as global tests of equality are not appropriate comparisons; nevertheless, we used the KS test as a benchmark of the power under various distributions.
For each set of parameters for the distributions listed in Table 5 and Table 6, the sample size necessary for the KS test to achieve a power of 0.8 was found (based on 100,000 replicate samples). With the same sample size for the particular distributions, the proposed test was performed for various percentile profiles and the empirical power calculated based on 10,000 replicate samples. Results of the simulations that test equally-space percentile profiles are listed in Table 5 and unequally-spaced profiles are in Table 6. The test is competitive with the KS in most of the scenarios tested. With some distributions and percentile profiles, the test has greater power than the KS test. For equally-spaced percentiles, the profiles with 1, 2, 3, and 4 percentiles perform similarly, with the 2 and 3 percentile profiles having slightly greater average power across all scenarios. For unequally-spaced percentile profiles, profile Q2 performed the best while the profile containing only the upper and lower extremes, Q1, performed the worst. These simulation results outline a general strategy for using this procedure.
In general, there is not likely interest in a specific value of u, but there may be such interest in arbitrary values in the small neighborhood around u. For instance, in a test involving the median, we may not be really interested in the actual value at which half the observations are above and half below, but rather some measure of the general “center” of the distribution by which we could compare the two populations. Similarly, we could choose to test the equality of 25th or 20th percentile, not necessarily because this is a specific parameter of interest, but merely some measure of the lower half of the distribution. If we were to construct confidence intervals at each value of q(u), we could examine the extent of the differences at these exact locations, but likely interpret them as just a sample of the relationship between the distributions in the segment near q(u). Essentially, we are systematically sampling along the domain of the populations to detect differences between the distributions. Therefore, if there is not a specific profile of interest to be tested, the percentile profile should be selected to adequately cover the entire domain, particularly in the tails of the distributions where discrepancies frequently exist.
4. Illustrative Example: C-Reactive Protein and Diabetes
We demonstrate the use of the procedure with an illustrative example involving C-reactive protein (CRP) levels
Table 5. Simulation results compared to Kolmogorov-Smirnov test at 80% power with equally-spaced percentiles.
Table 6. Simulation results compared to Kolmogorov-Smirnov test at 80% power with unequally-spaced percentiles.
and diabetes using data from the 2009-2010 National Health and Nutrition Examination Surveys (NHANES). CRP is found in blood plasma and serves as a biomarker for inflammation. Physicians find it informative to monitor patients who are ill because CRP levels tend to rise with injury or disease progression and decline with healing or disease regression. Suppose we wished to test for differences in the distribution of CRP between groups based on diabetes status determined by plasma fasting glucose (PFG). Individuals with PFG (mg/dL) of 99 or below are classified as “normal”, between 100 and 125 are classified as “prediabetes”, and 126 or above as “diabetes”, as designated by the American Diabetes Association (http://www.diabetes.org/diabetes-basics/diagnosis/). We used the procedure to test that the 5th, 10th, 25th, 50th, 75th, 90th, and 95th percentiles were equal between (1) normal males and males with diabetes and (2) normal females and females with diabetes (Only data on adults between the ages of 18 and 79 were analyzed).
For males, there were 533 within the normal group and 160 in the diabetes group. The difference in percentile profiles between normal males and diabetes males is highly significant with a Wald test statistic of 42.9 with seven degrees of freedom (p < 0.0001). For females, there were 867 within the normal group and 123 in the diabetes group with a Wald statistic of 14.0 (p = 0.0517), indicating there is likely a difference between the groups’ percentile profiles. It is important to remember that alternate profiles will result in different values of Wald statistics from the differences in the sample order statistics as well as the distribution of the order statistics within the sample. Due to this uncertainty of estimates, a more informative analysis likely involves confidence intervals as seen in Table 7.
Let d represent the vector of differences between population percentile estimates, equal to qꞌAꞌ where q is the combined vector of population percentile estimates and A = [Ip| − Ip]. Let di = qiD − qiN be the estimated difference between the ith percentile of the diabetes and normal groups. Recall from Equation (2) that the confidence interval for the difference is  where ai is the ith row of A. In this case, with four comparisons, it would be appropriate to adjust z1−α/2 for each di to ensure the family−wise error rate does not exceed 0.05; thus a Bonferroni correction was made. Estimates and confidence intervals are presented Table 7. By examining the differences and calculating confidence intervals at specified percentiles that span the entire domain, better insight into the differences between populations is possible. For both males and females, it is not a simple shift in location of CRP between normal and diabetes groups; there appears to be increasing differences as the percentile increases.
where ai is the ith row of A. In this case, with four comparisons, it would be appropriate to adjust z1−α/2 for each di to ensure the family−wise error rate does not exceed 0.05; thus a Bonferroni correction was made. Estimates and confidence intervals are presented Table 7. By examining the differences and calculating confidence intervals at specified percentiles that span the entire domain, better insight into the differences between populations is possible. For both males and females, it is not a simple shift in location of CRP between normal and diabetes groups; there appears to be increasing differences as the percentile increases.
5. Conclusions
The Wald test provides a natural framework for testing equality of linear combinations of percentiles among multiple groups. Although estimating percentiles and obtaining estimates of variance via bootstrap samples has been previously investigated, the use of the Wald test for hypothesis testing has not been proposed. As shown with simulation studies, the procedure has excellent asymptotic properties and is readily implemented in practical applications as illustrated in this paper. The selection of a percentile profile, coupled with the ability to construct various contrasts, allows us to compare populations across the entire domain in detail and detect important differences at multiple locations.
The test may have limited use in some circumstances as the test relies on large-sample assumptions. Some profile/distribution combinations may yield inaccurate bootstrap estimates of percentile variance for small sample sizes. As shown in simulation studies, variance estimates of extreme percentiles (order statistics) near 1 and n are inaccurate in small sample sizes. However, these errors seem to have limited effect on the performance of the Wald test. With reasonable sample sizes, it is an excellent nonparametric procedure for population comparison and testing and is competitive with standard nonparametric tests for testing equality of distributions, specifically the two sample Kolmogorov-Smirnov test.
Another important aspect of the procedure is the choice of percentiles to be tested. If the exact percentiles are not important, a profile (with equally- or unequally-spaced percentiles) along the entire domain of the distribution is effective as an overall nonparametric test of global inequality, but can also be used to test the equality of linear combinations of the percentile profiles to obtain specific estimates at these locations. More research can be done to determine the optimal allocation of percentiles within a profile, perhaps based on features of the data.
Table 7. Estimates of C-reactive protein differences in percentiles between diabetes and normal groups for males and females.
Further work can investigate the sample size limitations and distribution effect upon the bootstrap estimates of variance how this in turn affects the Wald test.
Acknowledgements
This research was supported by 1 U54 GM104940 from the National Institute of General Medical Sciences of the NIH, which funds the Louisiana Clinical and Translational Science Center. William D. Johnson also receives support from the National Center For Complementary & Integrative Health and the Office of Dietary Supplements of the National Institutes of Health under Award Number 3 P50AT002776 which funds the Botanical Research Center of Pennington Biomedical Research Center and the Department of Plant Biology and Pathology in the School of Environmental and Biological Sciences (SEBS) of Rutgers University. The content of this manuscript is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Cite this paper
William D.Johnson,Jacob E.Romer, (2016) Hypothesis Testing of Population Percentiles via the Wald Test with Bootstrap Variance Estimates. Open Journal of Statistics,06,14-24. doi: 10.4236/ojs.2016.61003
References
- 1. Johnson, W.D., Beyl, R.A., Burton, J.H., Johnson, C.M., Romer, J.E. and Zhang, L. (2015) Use of Pearson’s Chi-Square for Testing Equality of Percentile Profiles across Multiple Populations. Open Journal of Statistics, 5, 412-420.
http://dx.doi.org/10.4236/ojs.2015.55043 - 2. Maritz, J.S. and Jarrett, R.G. (1978) A Note on Estimating the Variance of the Sample Median. Journal of the American Statistical Association, 52, 13-30.
http://dx.doi.org/10.1080/01621459.1978.10480027 - 3. Efron, B. (1979) Bootstrap Methods: Another Look at the Jackknife. The Annals of Statistics, 7, 1-26.
http://dx.doi.org/10.1214/aos/1176344552 - 4. Bickel, P.J. and Freedman, D.A. (1981) Some Asymptotic Theory for the Bootstrap. The Annals of Statistics, 9, 1196-1217.
http://dx.doi.org/10.1214/aos/1176345637 - 5. Hall, P. and Martin, M.A. (1988) Exact Convergence Rate of Bootstrap Quantile Variance Estimator. Probability Theory and Related Fields, 80, 261-268.
http://dx.doi.org/10.1007/BF00356105 - 6. Hall, P. and Martin, M.A. (1991) On the Error Incurred Using the Bootstrap Variance Estimate When Constructing Confidence Intervals for Quantiles. Journal of Multivariate Analysis, 38, 70-81.
http://dx.doi.org/10.1016/0047-259X(91)90032-W - 7. Cheung, K.Y. and Lee, S.M. (2005) Variance Estimation for Sample Quantiles Using the m out of n Bootstrap. Annals of the Institute of Statistical Mathematics, 57, 279-290.
http://dx.doi.org/10.1007/BF02507026 - 8. Wilcox, R.R. (1995) Comparing Two Independent Groups via Multiple Quantiles. Journal of the Royal Statistical Society, Series D, 44, 91-99.
http://dx.doi.org/10.2307/2348620 - 9. Hutson, A.D. and Ernst, M.D. (2000) The Exact Bootstrap Mean and Variance of an L-Estimator. Journal of the Royal Statistical Society, Series B, 62, 89-94.
http://dx.doi.org/10.1111/1467-9868.00221 - 10. Ghosh, M., Parr, W.C., Singh, K. and Babu, G.J. (1985) A Note on Bootstrapping the Sample Median. The Annals of Statistics, 12, 1130-1135.
http://dx.doi.org/10.1214/aos/1176346731 - 11. Babu, G.J. (1986) A Note on Bootstrapping the Variance of Sample Quantile. Annals of the Institute of Statistical Mathematics, 38, 439-443.
http://dx.doi.org/10.1007/BF02482530
NOTES

*Corresponding author.