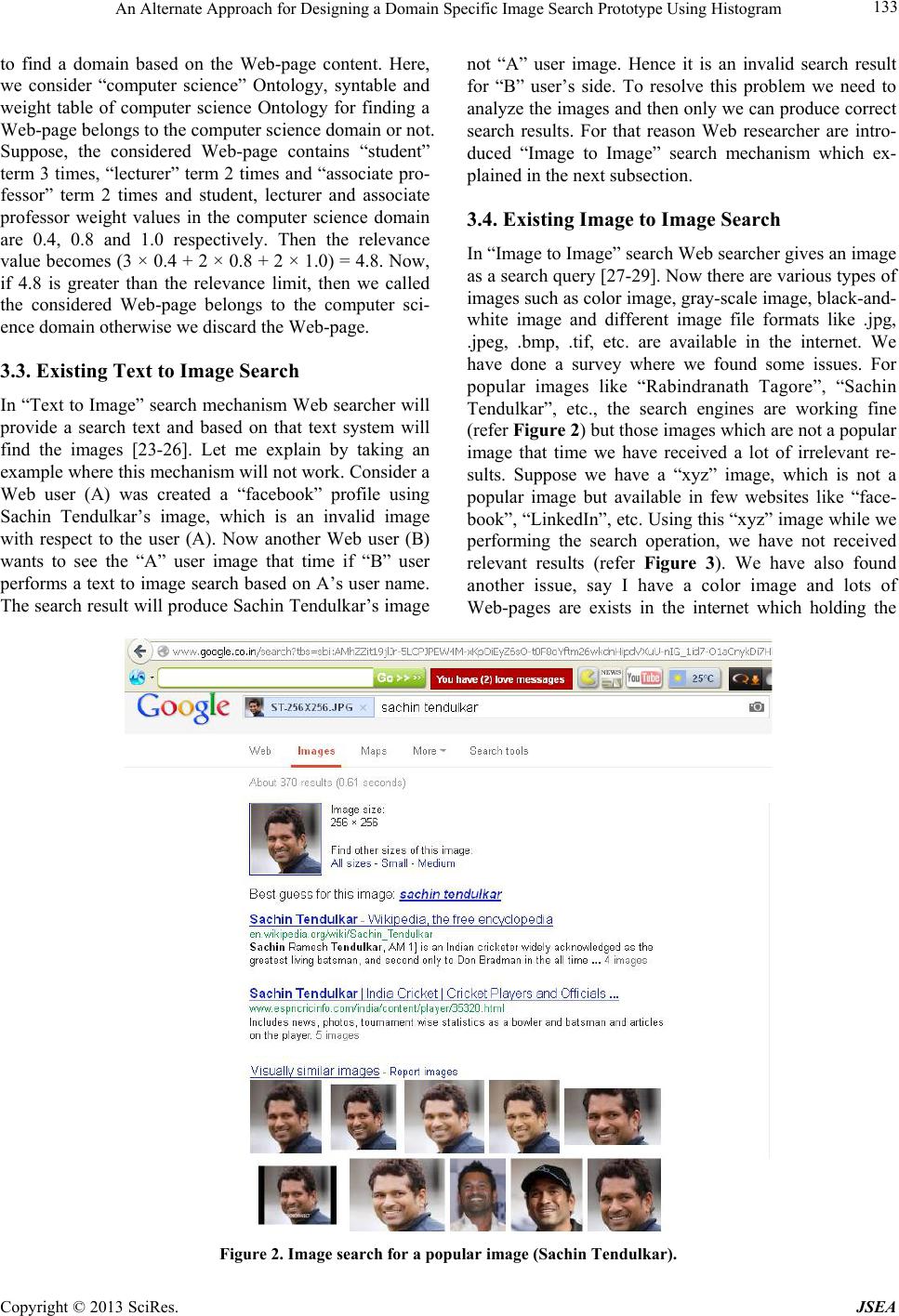
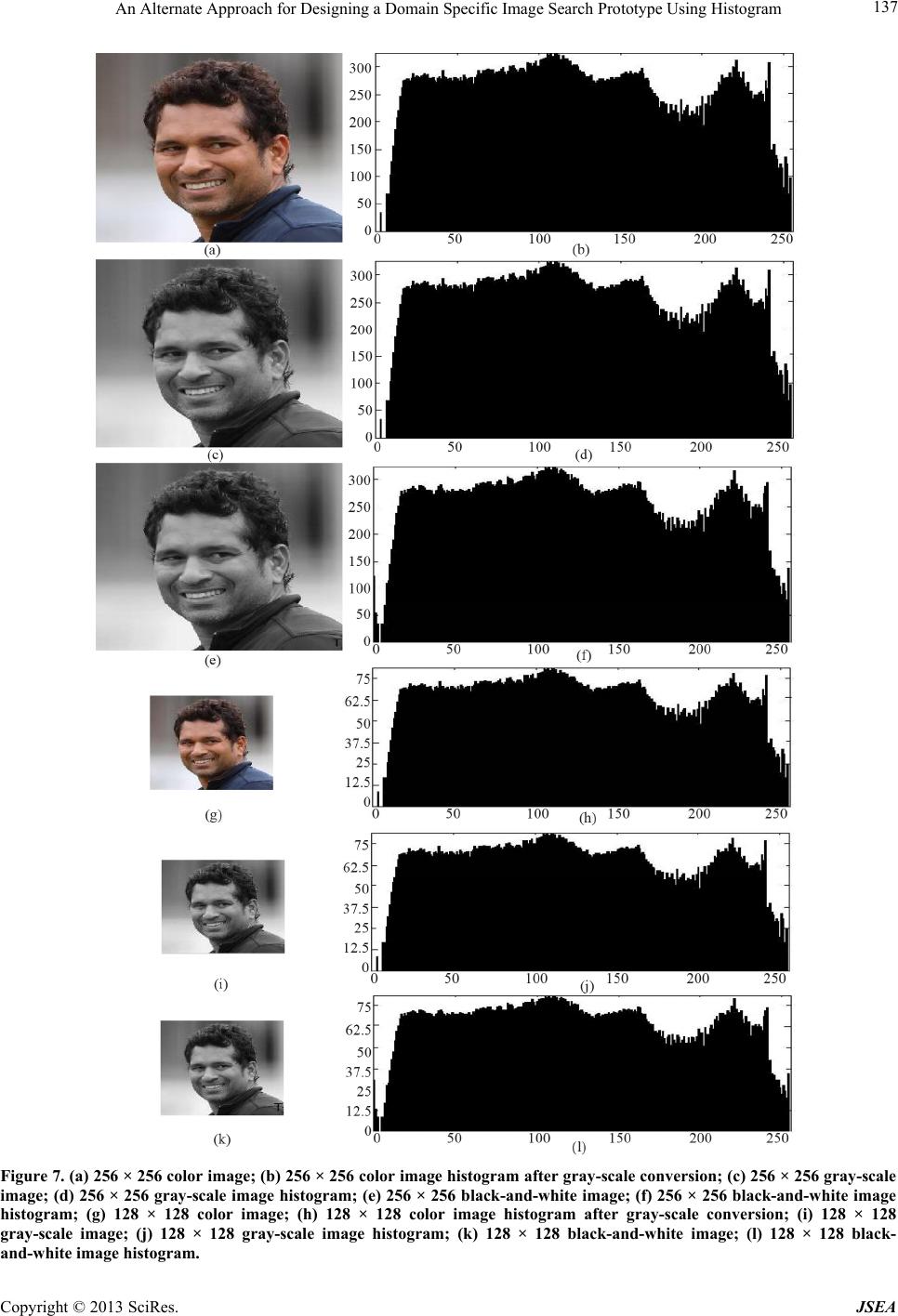
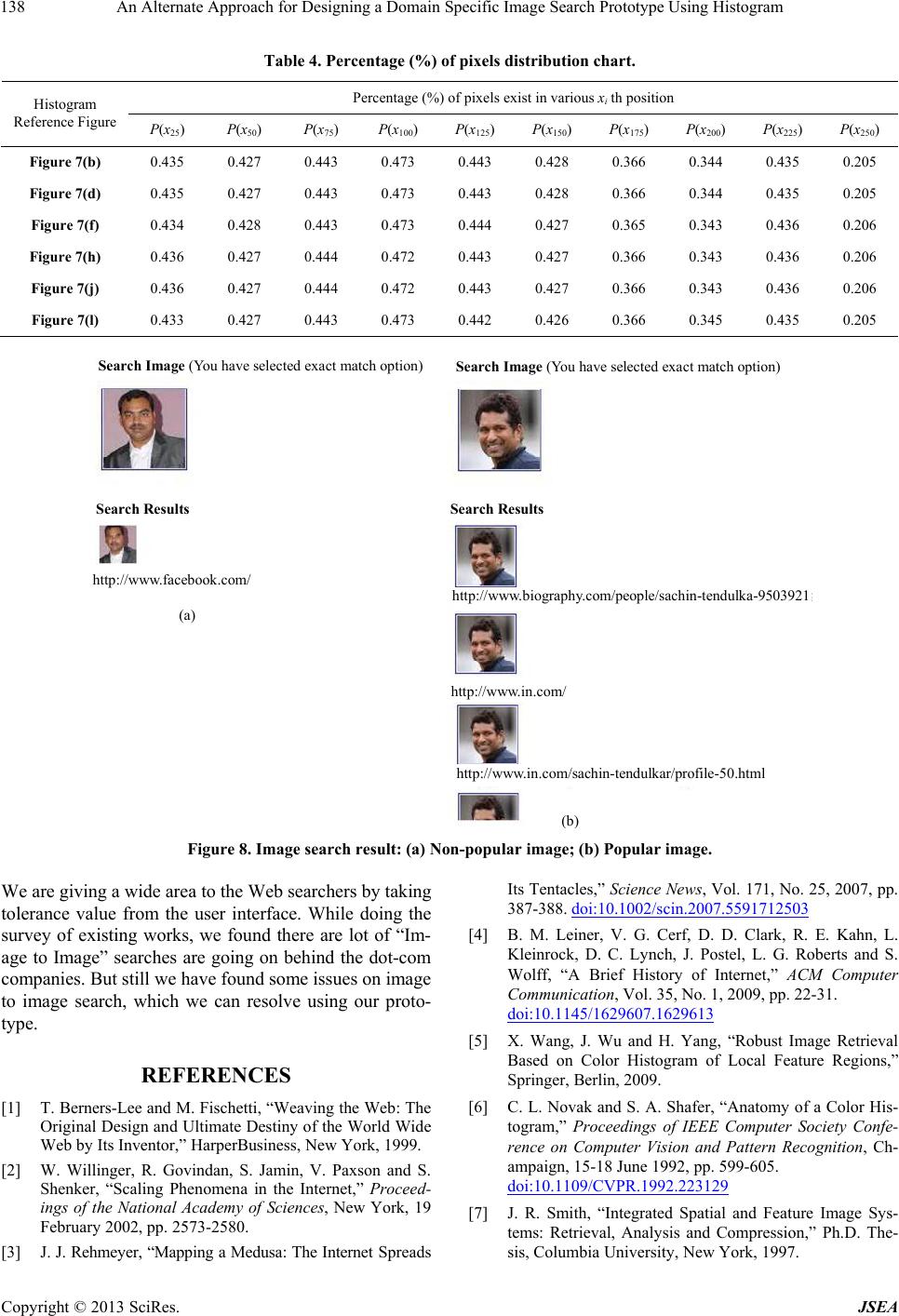
An Alternate Approach for Designing a Domain Specific Image Search Prototype Using Histogram 139
[8] E. A. Bashkov and N. S. Kostyukova, “Effectiveness
Estimation of Image Retrieval by 2D Color Histogram,”
Journal of Automation and Information Sciences, Vol. 8,
No. 11, 2006, pp. 74-80.
[9] E. A. Bashkov and N. S. Shozda, “Content-Based Image
Retrieval Using Color Histogram Correlation,” Graphi-
con proceedings, Nizhny Novgorod, 16-21 September
2002, pp. 458-461.
[10] L. Vincent, “Morphological Grayscale Reconstruction in
Image Analysis: Applications and Efficient Algorithms,”
IEEE Transactions on Image Processing, Vol. 2, No. 2,
1993, pp. 176-201.
[11] D. Mukhopadhyay, A. Biswas and S. Sinha, “A New
Approach to Design Domain Specific Ontology Based
Web Crawler,” The 10th International Conference on In-
formation Technology, Orissa, 17-20 December 2007, pp.
289-291.
[12] S. Chakrabarti, M. Berg and B. E. Dom, “Focused
Crawling: A New Approach to Topic-Specific Web Re-
source Discovery,” Proceedings of the 8th International
World Wide Web Conference, Toronto, 11-14 May 1999,
pp. 545-562.
[13] D. Bergmark, C. Lagoze and A. Sbityakov, “Focused
Crawls, Tunneling, and Digital Libraries,” Proceedings of
the European Conference on Digital Libraries, Vol. 2458,
Rome, 16-18 September 2002, pp. 91-106.
[14] M. Diligenti, F. Coetzee, S. Lawrence, C. L. Giles and M.
Gori, “Focused Crawling Using Context Graphs,” The
26th International Conference on Very Large Databases,
Cairo, 10-14 September 2000, pp. 527-534.
[15] N. Tyagi and D. Gupta, “A Novel Architecture for Do-
main Specific Parallel Crawler,” Indian Journal of Com-
puter Science and Engineering, Vol. 1 No. 1, 2008, pp.
44-53.
[16] A. Kundu, R. D. Dattagupta and D. Mukhopadhyay,
“Mining the Web with Hierarchical Crawlers—A Re-
source Sharing Based Crawling Approach,” International
Journal on Intelligent Information and Database Systems,
Vol. 3, No. 1, 2009, pp. 90-106.
doi:10.1504/IJIIDS.2009.023040
[17] A. Kundu, R. Dutta, D. Mukhopadhyay and Y. C. Kim,
“A Hierarchical Web Page Crawler for Crawling the In-
ternet Faster,” Proceedings of the International Confer-
ence on Electronics and Information Technology Con-
vergence, Republic of Korea, 20 December 2006, pp.
61-67.
[18] D. Mukhopadhyay, S. Mukherjee, S. Ghosh, S. Kar and Y.
C. Kim, “Architecture of a Scalable Dynamic Parallel
Web Crawler with High Speed Downloadable Capability
for a Web Search Engine,” Proceedings of the 6th Inter-
national Workshop, Republic of Korea, 20 November
2006, pp. 103-108.
[19] A. Gangemi, R. Navigli and P. Velardi, “The Onto-
WordNet Project: Extension and Axiomatization of Con-
ceptual Relations in WordNet,” Proceedings of Interna-
tional Conference on Ontologies, Databases and Appli-
cations of Semantics, Catania, 3-7 November 2003, pp.
820-838.
[20] D. N. Antonio, M. Michele and N. Roberto, “A Software
Engineering Approach to Ontology Building,” Informa-
tion Systems, Vol. 34, No. 2, 2009, pp. 258-275.
doi:10.1016/j.is.2008.07.002
[21] T. Gruber, “Toward Principles for the Design of Ontolo-
gies Used for Knowledge Sharing,” International Journal
of Human-Computer Studies, Vol. 43, No. 5-6, 1995, pp.
907-928. doi:10.1006/ijhc.1995.1081
[22] M. Ehrig and A. Maedche, “Ontology-Focused Crawling
of Web Documents,” Proceedings of the ACM Sympo-
sium on Applied Computing, Melbourne, 9-12 March
2003, pp. 1174-1178.
[23] B. Luo, X. G. Wang and X. O. Tang, “World Wide Web
Based Image Search Engine Using Text and Image Con-
tent Features,” Proceedings of SPIE Electronic Imaging,
Vol. 5018, Santa Clara, 20 January 2003, pp. 123-130.
[24] Z. Su, H. Zhang, S. Li and S. Ma, “Relevance Feedback
Content-Based Image Retrieval: Bayesian Framework,
Feature,” IEEE Transactions on Image Processing, Vol.
12, No. 8, 2003, pp. 924-937.
[25] K. P. Yee, K. Swearingen, K. Li and M. Hearst, “Faceted
Metadata for Image Search and Browsing,” Proceedings
of the ACM Digital Library, Fort Lauderdale, 5-10 April
2003, pp. 401-408.
[26] C. W. Niblack, R. Barber, W. Equitz, M. Flickner, E.
Glasman, D. Pektovic, P. Yanker, C. Faloutsos and G.
Taubin, “The QBIC Project: Querying Images by Content
Using Color, Texture, and Shape,” Proceedings of Stor-
age and Retrieval for Image and Video Databases, San
Jose, 31 January 1993, pp. 173-187.
[27] D. N. D. Harini and D. L. Bhaskari, “Image Retrieval
System Based on Feature Extraction and Relevance Feed-
back,” Proceedings of the CUBE International Informa-
tion Technology Conference, Pune, 3-5 September 2012,
pp. 69-73.
[28] A. K. Jain and A. Vailaya, “Image Retrieval Using Color
and Shape,” Pattern Recognition, Vol. 29, No. 8, 1996,
pp. 1233-1244.
[29] D. Patra and J. Mridula, “Featured Based Segmentation of
Color Textured Images Using GLCM and Markov Ran-
dom Field Model,” World Academy of Science, Engi-
neering and Technology, Vol. 53, No. 5, 2011, pp. 108-
113.
Copyright © 2013 SciRes. JSEA