 Social Networking, 2013, 2, 19-31 http://dx.doi.org/10.4236/sn.2013.21003 Published Online January 2013 (http://www.scirp.org/journal/sn) Terrorist Networks, Network Energy and Node Removal: A New Measure of Centrality Based on Laplacian Energy Xingqin Qi1,4, Robert D. Duval2, Kyle Christensen3, Edgar Fuller4, Arian Spahiu2, Qin Wu5, Yezhou Wu4, Wenliang Tang4, Cunquan Zhang4* 1School of Mathematics and Statistics Shandong University (Weihai), Weihai, China 2Department of Political Science West Virginia University, Morgantown, USA 3Department of Political Science Columbus State University, Columbus, USA 4Department of Mathematics West Virginia University, Morgantown, USA 5School of IOT Engineering Jiangnan University, Wuxi, China Email: *cqzhang@math.wvu.edu Received November 8, 2012; revised November 11, 2012; accepted January 9, 2013 ABSTRACT In this work we propose a centrality measure for networks, which we refer to as Laplacian centrality, that provides a general framework for the centrality of a vertex based on the idea that the importance (or centrality) of a vertex is re- lated to the ability of the network to respond to the deactivation or removal of that vertex from the network. In particu- lar, the Laplacian centrality of a vertex is defined as the relative drop of Laplacian energy caused by the deactivation of this vertex. The Laplacian energy of network with n vertices is defined as G 2 =1 =n i i EG , where i is the eigenvalue of the Laplacian matrix of . Other dynamics-based measures such as that of Masuda and Kori and Pag- eRank compute the importance of a node by analyzing the way paths pass through a node while our measure captures this information as well as the way these paths are “redistributed” when the node is deleted. The validity and robustness of this new measure are illustrated on two different terrorist social network data sets and 84 networks in James Moody’s Add Health in-school friendship nomination data, and is compared with other standard centrality measures. G Keywords: Network; Centrality; Laplacian Energy; 9/11 Hijacking; Bali Bombing; Terrorism 1. Introduction The recent growth in the use of Social Network Analysis (SNA) to understand complex networks demonstrates the importance of the implicit connections within groups that arise from day to day social activity. Similarly, our in- creasing interest in observing, detecting and analyzing terrorist networks leads us to be extremely interested in understanding who is central to the functionality of these groups that form around the common goal of engaging in terrorist activities. As a result, researchers and analysts from several areas have a strong interest in understanding centrality within networks for both academic and opera- tional reasons. SNA provides us tools for mapping and measuring re- lationships and flows between people, groups, organiza- tions, computers, URLs, and many other connected bits of information/knowledge. The vertices in political net- works, of which terrorist networks have emerged as one of the most salient, are typically people, organizations, or groups while the edges show relationships, connections, or flows between the vertices. SNA provides both a vis- ual and a mathematical analysis of these interrelation- ships. Recent studies of networks in political science range from such diverse topics as international conflict [1], terrorism [2] and policy networks [3] to disciplinary introspection about job placement in political science [4]. To understand network structure and the entities being studied, we often start with an evaluation of their loca- tion relative to all other actors in the network. For net- works, the most readily examined measure of location means how close is the object to the center, or centrality. The finding of some important vertices with high central- ities in order to characterize the properties of the net- works has significant uses in many fields. These include synchronization transition, the spread of epidemics, and the transmission of information. For example, in diffu- sive systems the vertices with large degree play a crucial role, which are decisive in resolving the traffic jam at a bottleneck [5]. The ability to measure centrality in social networks *Corresponding author. C opyright © 2013 SciRes. SN  X. Q. QI ET AL. 20 has been a particularly useful development. These ideas have materialized in many well known centrality meas- ures such as degree centrality, along with closeness, be- tweenness, eigenvector, subgraph centrality, Katz pres- tige and Bonacich centrality, etc. These measures are certainly not the only measures of centrality, and it is clear that these measures capture different aspects of the positioning of the nodes [6]. Given how varied networks can be, it is not surprising that there are many different ways of viewing position, centrality or power in a net- work. But note that these standard methods also have their own weakness. For example, as have been stated, “The simplicity of degree method is an advantage and also is an disadvantage: only the local structure around a vertex is calculated and it does not take into considera- tion the global structure of the network; for example, although a vertex might be connected to many others, it might not be in a position to reach others quickly to ac- cess resources, such as information or knowledge [7]”; “Betweenness method considers the global network structure and also can be applied to networks with dis- connected components, but it is not without limitations; for example, vertices in a network that generally do not lie on a shortest path between any two other vertices will receive the same score of zero [7]”. Katz prestige and Bonacich centrality both depend on the choice of pa- rameters heavily. Besides, these existing measures de- scribe either the local environment around a vertex (e.g., degree centrality) or the global position of a vertex in the network (e.g., closeness, betweenness and subgraph cen- trality). For example, from its definition, “subgraph cen- trality” tends to find the center (s) of an entire network when in fact we are really interested in finding the center for each community within the network. If the network consists of more than two communities with dramatically different sizes, the nodes in the smaller community would exhibit lower “subgraph centrality” ranks than the ones in larger community, so that the leader in smaller community will not rank highly overall. Thus, an inter- mediate (between local and global) characterization of the vertex centrality has been claimed as a necessity for the study of, for example, the food web in [8,9] if species to community relations are to be understood. An inter- mediate centrality approach is also suggested to be the most appropriate if the relative importance of vertex is to be quantified in social networks. In this paper, based in part on the basic idea of spectral graph theory, we present a novel centrality method that takes into account the Laplacian energy of the graph, a quantity introduced in [10] which reflects the graph's internal connectivity. In particular, the Laplacian central- ity of a vertex is defined as the relative drop of Laplacian energy in the network caused by the deactivation of this vertex from the network. Theorem 1 makes precise the way in which the Laplacian centrality of a vertex can be used to reveal its importance in a network. This result says that the Laplacian centrality of a vertex not only takes the local environment around it into account but also the larger environment around its neighbors, making it an intermediate between the global and local charac- terizations of the position of a vertex in a network. We investigate the validity and robustness of this new meas- ure by illustrating this method on three social network data sets of strong theoretical and substantial policy in- terest. Examining two terrorists networks (those involv- ing the Bali Nightclub bombing in 2002 [11] and the 9/11 hijackers network [12]) and all the 84 networks in the Add Health in-school friendship nomination data from James Moody, we compare the results of our Laplacian centrality measure to other standard centrality measures and show its reliability. This paper is organized as follows. We first give some notations and terminology in Section 2. In Section 3, we introduce the new measure—Laplacian centrality, whose simple calculation is presented in Section 4 based on some structural studies of graph theory. Analytical and numerical results on two different networks will be shown in Section 5, where the rankings of vertices for different centrality measures are presented. By compar- ing with outputs of other methods, the effectiveness of Laplacian centrality method is supported by both known facts (intelligence information) and statistical analysis (consensus comparison), see both Section 5 and Section 6. The computational complexity of various centrality methods are further compared and discussed in Section 7, which will show that Laplacian method has the lower time complexity making it quite advantageous for large scale networks. Conclusions will be reported in Section 8. 2. Graph Theory Notation and Terminology In most contexts, a social network can be effectively represented by a graph where the vertices are the indi- viduals, and the edges represent the social links (connec- tion). In this paper, we consider the symmetric case where social networks are represented by undirected graphs. Let be an undirected graph, consisting of a set of vertices G n 12 =,,,n VGvvv and a set of edges. The number of edges that are incident to a vertex is called the degree of the vertex. Let m , = ij nn AG a be the adjacency matrix of the graph , where the ele- ment equals 1 if there is an edge between vertices and , and 0 if there is not. G ,ij aji Copyright © 2013 SciRes. SN  X. Q. QI ET AL. 21 3. Laplacian Centrality In the following, we will first introduce the definition of Laplacian matrix and Laplacian energy for a graph, then define the Laplacian centrality for a vertex. Let G be a simple graph (without graph loops or mul- tiple edges) of vertices, and n 1 2 12 00 00 =,,,= .... 00 n n d d DGdiagd dd d be the diagonal matrix with the vertex degrees of its vertices 12 . Define as the Laplacian matrix of the graph (note that the adjacency matrix 12 ,,, n dd d =LG DG G ,,,n vv v AG G is defined in Section 2). The following is a short list of some properties about the Laplacian matrix [13]. LG Properties 1) is symmetric, singular and positive semi- definite. LG 2) All eigenvalues i are real and nonnegative. 3) The smallest eigenvalue =0 n . 4) The multiplicity of zero eigenvalues equals the number of connected components of . G Definition 1 If G is a graph of vertices, and 12 n ,,,n are the eigenvalues of its Laplacian matrix. The Laplacian energy of is defined as the following invariant: G 2 =1 = n i i EG . Lemma 1 [10] For any graph G on vertices with vertex degrees , we have n 12 ,,,n dd d 2 =1 = n ii i EGd d. Lemma 2 [10] If H is an arbitrary subgraph of a graph G, then . LL EH EG We will see from the above lemmas Laplacian energy reflects the internal connectivity of a network. Thus, the relative drop of Laplacian energy in the network caused by the deactivation of this vertex from the network can be easily regarded as a “signal” to show the importance of the removing vertex in the whole network . Definition 2 If is a graph on vertices 12 , let Gn {,,, }n vv v be the graph obtained by remov- ing vertex from . The Laplacian centrality i v G i C of vertex is defined as i v == L iL i CEEGEH L Obviously, by Lemma 2, must be nonnegative. LL EG EH 4. Calculation of Laplacian Centrality, a Graph Theory Result 4.1. Graph Theoretical Descriptions Theorem 1 If is a graph of vertices, then the Laplacian centrality with respect to is Gnv 2 == 2 L vGG vvNv i CEdv dvdv Gi , where Nv is the set of neighbors of in G and v iG dv is the degree of in . i v G Proof. Assume that the vertex set of is 12 , and there are edges in . It is well known that . Then G ,,, n vv vm mG nn =1 =2 n Gi idv 22 =1 1 ==2 Gi GiGi ii EGdvdvmdv . Without loss of generality, assume 1 = Gv. Note that there are 1 n vertices and 2,,n vv 1 G md v edges in . 2 2 2 12 2 LH iHi i n GH i EHd vd v md vdv n i Let 1 Nv be the neighborhood of vertex in G, the following is obvious: 1 v 1 0, =1; =1, ,. Hi Gii Gi if i dv dvifvNv d votherwise ; So 11 2 1 22 12 22 1 2 2 2 L n Gi i n GGi i GGi vNvvNv ii EG mdv md vd v md vd vd v 2 Gi and 11 11 2 12 22 1 22 1 2 2 21 L n GHi i GHiHi vNvvNv ii GGi vNvvNv ii EH md vdv mdvd vd v md vd vd v Gi Thus, the drop of Laplacian energy with respect to is 1 v Copyright © 2013 SciRes. SN  X. Q. QI ET AL. 22 1 1 1 1 2 22 11 211 2111 () 1 211 21 221 22 2 LL GGGi Gi vNv i GG Gi vNv i GGGGi vNv i GG Gi vNv i E EG EH dvdvdv dv dv dvdv dvdv dvdv dv dvdv From Theorem 1, we notice the following facts: First, the Laplacian centrality agrees with the standard measures on assignment of extremes. For example, it gives the maximum value to the central vertex of a star, and equal value to the vertices of a cycle or a complete graph. Second, it is well known that the degree centrality of only considers the information contained in the num- ber of vertices which can be reachable from directly. The Laplacian centrality of a vertex involves the infor- mation of vertices that can be reachable to within two steps and as a result the Laplacian centrality of a vertex takes not only the local environment around it into ac- count but also the larger immediate environment around its neighbors. It is thus an intermediate measure between global and local characterizations of the position of a vertex within networks. Because of this we should an- ticipate that it will reveal differences in network structure that emerge out of significant local influence upon areas of the graph. Intuitively, this means that we should ex- pect the Laplacian centrality to yield a more useful vertex characterization when the overall graph structure has subgroups that contribute disproportionately to the over- all goals of the network. Hence we should see an increase in the relative importance of actors whose removal from the network would do the most damage to the graph structure. In the case of monitoring terrorist groups, La- placian centrality may offer significant operational coun- terintelligence benefits due to its strong association with vertex inactivation. These expectations have been veri- fied by the experimental results in Section 5. vv v 4.2. Comparison with Local and Global Centrality Methods In this section, we will give two simple examples to show the differences between Laplacian methods with the popular existing centrality measures respectively. Here, degree method and subgraph method are chose to represent local and global standard method respectively. Please see Figure 1 for the first example. Based on degree centrality, has higher ranking than v be- cause the degree of is 4 while the degree of is 3. uu v Figure 1. Example 1 for comparison of degree centrality and Laplacian centrality method. But based on Laplacian method, would have higher ranking than because v u 223 GG Gi uvNu i Edudu dv 6 224 GG Gi vvNv i Edvdv dv 2 Please see Figure 2 for the second example. Centrality method based on global characterization of network tends to find the center(s) of whole network. But at the most time what we are really interested is to find the center for each community in the network. If the network is consist of more than two communities and with dra- matically different sizes, the nodes in smaller community would get lower ranks than the ones in larger community, so that the leader in smaller community will not come up with high rank. We specify this fact by the example in Figure 2. The network is consisting of two communities with centers 60 and 10 respectively. From the following table, we will see that based on Laplacian method, we always can find the two communities’ centers (#10 and 60), but with subgraph centrality method, all nodes in the left bigger community all get higher ranks than nodes in right smaller community, which will regard node 11 as the second center of the network wrongly. # # node# Laplacian method subgraph method 60 1st 1st 10 2nd 51st 11 3rd 2nd Here we only present particular examples which show that sometimes local or global centrality methods can not give the reliable results. Thus in practice, we need inter- mediate method often. 5. Applications and Experimental Results To demonstrate the effectiveness of Laplacian centrality, we will test it on two terrorist networks: the Jemaah Islamiyah Network collected by Stuart Koschade [11], Copyright © 2013 SciRes. SN  X. Q. QI ET AL. Copyright © 2013 SciRes. SN 23 Figure 2. Example 2 for comparison of subgraph centrality and Laplacian centrality method. and the 9/11 hijacker network assembled by Valdis Krebs [12], and all the 84 networks in the Add Health in-school friendship nomination data. We compare the Laplacian results with the most classical methods in- cluding degree, closeness, eigenvector and betweenness centrality methods except Katz prestige and Bonacich centrality methods, because the latter two all depend on the parameters users choice heavily, which means dif- ferent choice of parameter would affect the results sig- nificantly. 5.1. Data set 1: Jemaah Islamiyah Graph—Bali 2002 Terrorist Attack Th e Jemaa h Is lamiya h ne twork is co mpri sed of 17 mem- bers of the group that participated in the nightclub bomb- ing on December 2002, Bali, Indonesia. The network is a good example of a tight network with two clear clusters (cliques) and a significant actor with strong measures of betweenness and closeness. This terrorist attack was also studied intensively in [14]. 5.1.1. Output Analysis Based on Known Evidence The information provided by the four standard centrality measures and our Laplacian centrality measure as applied to the 17 members of the terrorist group directly involved in the operation are provided in Table 1, where the cen- trality scores are normalized (dividing by the highest score of each method). We also list the rank for each terrorist. Note that frequently actors will exhibit the same scores for a number of measures. In the case when ties occur, we usually assign them the same rank. For exam- ple, Sarijo, Imron, Dulmatin, Azahari, Patek and Ghoni all get the same Laplacian score 0.5778, thus we will rank all of them No. 3 since there are only two scores 1.000 0 ( S a mudra ) and 0.6 222 (I dr i s) greater than 0.5778. The terrorist Samudra, in fact, provides the only link between the bomb makers and Team Lima, the group setting off the bombs (see Figure 3), and not surprisingly scores rather high based on Laplacian and all other four standard centrality methods. Idris, in his role as logistics commander, yielded a high centrality score also, al- though it is not as significant as that of Samudra. He is ranked as the second most central actor in the network based on Laplacian, degree, closeness and betweenness centrality methods, but is ranked 8 th on eigenvector cen- trality. And we also find that the members in the bomb construction team (for example, Sarijo, Imron, Dulmatin, etc.) also get high scores based on Laplacian centrality, which support Koschade’s conclusion that “the members of the Palau Manjangan residence (bomb construction team) seemingly the center of the operation [11]”. We also find that Mubarok is given the lowest rank on Laplacian method, which is consistent with the conclu- sion in [11] that “the lowest centrality scores were re- served for the contingency members who were kept to the periphery except when called upon for assistance. Mubarok had the lowest scores as he was kept very iso- lated and did not play any significant part in this stage of the operation.” Lastly, the two actual suicide bombers, Feri and Arnasan, have their highest combined rank us- 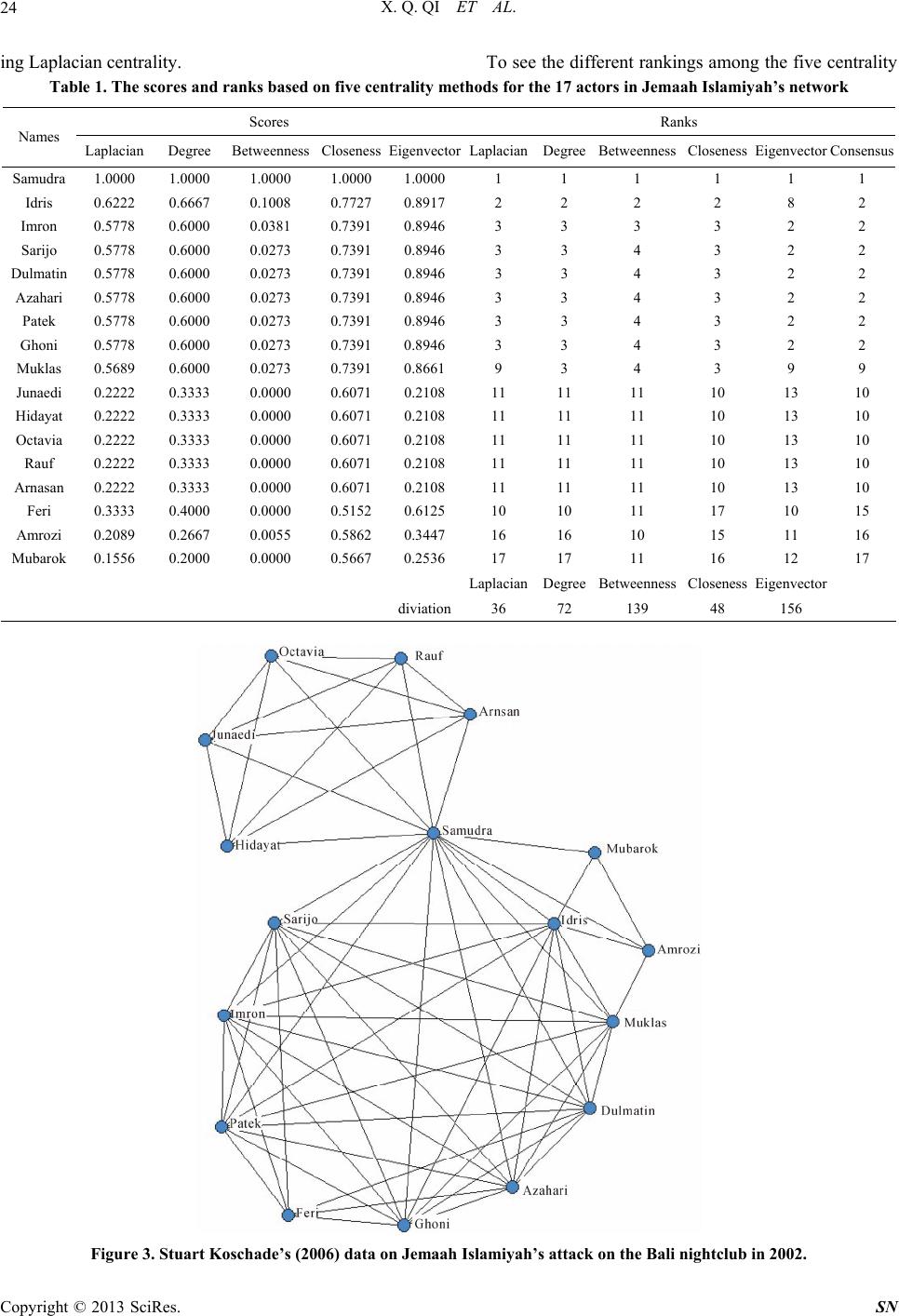 X. Q. QI ET AL. 24 ing Laplacian centrality. To see the different rankings among the five centrality Table 1. The scores and ranks based on five centrality methods for the 17 actors in Jemaah Islamiyah’s network Scores Ranks Names Laplacian Degree Betweenness ClosenessEigenvectorLaplacianDegreeBetweenness Closeness EigenvectorConsensus Samudra 1.0000 1.0000 1.0000 1.0000 1.0000 1 1 1 1 1 1 Idris 0.6222 0.6667 0.1008 0.7727 0.8917 2 2 2 2 8 2 Imron 0.5778 0.6000 0.0381 0.7391 0.8946 3 3 3 3 2 2 Sarijo 0.5778 0.6000 0.0273 0.7391 0.8946 3 3 4 3 2 2 Dulmatin 0.5778 0.6000 0.0273 0.7391 0.8946 3 3 4 3 2 2 Azahari 0.5778 0.6000 0.0273 0.7391 0.8946 3 3 4 3 2 2 Patek 0.5778 0.6000 0.0273 0.7391 0.8946 3 3 4 3 2 2 Ghoni 0.5778 0.6000 0.0273 0.7391 0.8946 3 3 4 3 2 2 Muklas 0.5689 0.6000 0.0273 0.7391 0.8661 9 3 4 3 9 9 Junaedi 0.2222 0.3333 0.0000 0.6071 0.2108 11 11 11 10 13 10 Hidayat 0.2222 0.3333 0.0000 0.6071 0.2108 11 11 11 10 13 10 Octavia 0.2222 0.3333 0.0000 0.6071 0.2108 11 11 11 10 13 10 Rauf 0.2222 0.3333 0.0000 0.6071 0.2108 11 11 11 10 13 10 Arnasan 0.2222 0.3333 0.0000 0.6071 0.2108 11 11 11 10 13 10 Feri 0.3333 0.4000 0.0000 0.5152 0.6125 10 10 11 17 10 15 Amrozi 0.2089 0.2667 0.0055 0.5862 0.3447 16 16 10 15 11 16 Mubarok 0.1556 0.2000 0.0000 0.5667 0.2536 17 17 11 16 12 17 LaplacianDegreeBetweennessCloseness Eigenvector diviation36 72 139 48 156 Figure 3. Stuart Koschade’s (2006) data on Jemaah Islamiyah’s attack on the Bali nightclub in 2002. Copyright © 2013 SciRes. SN 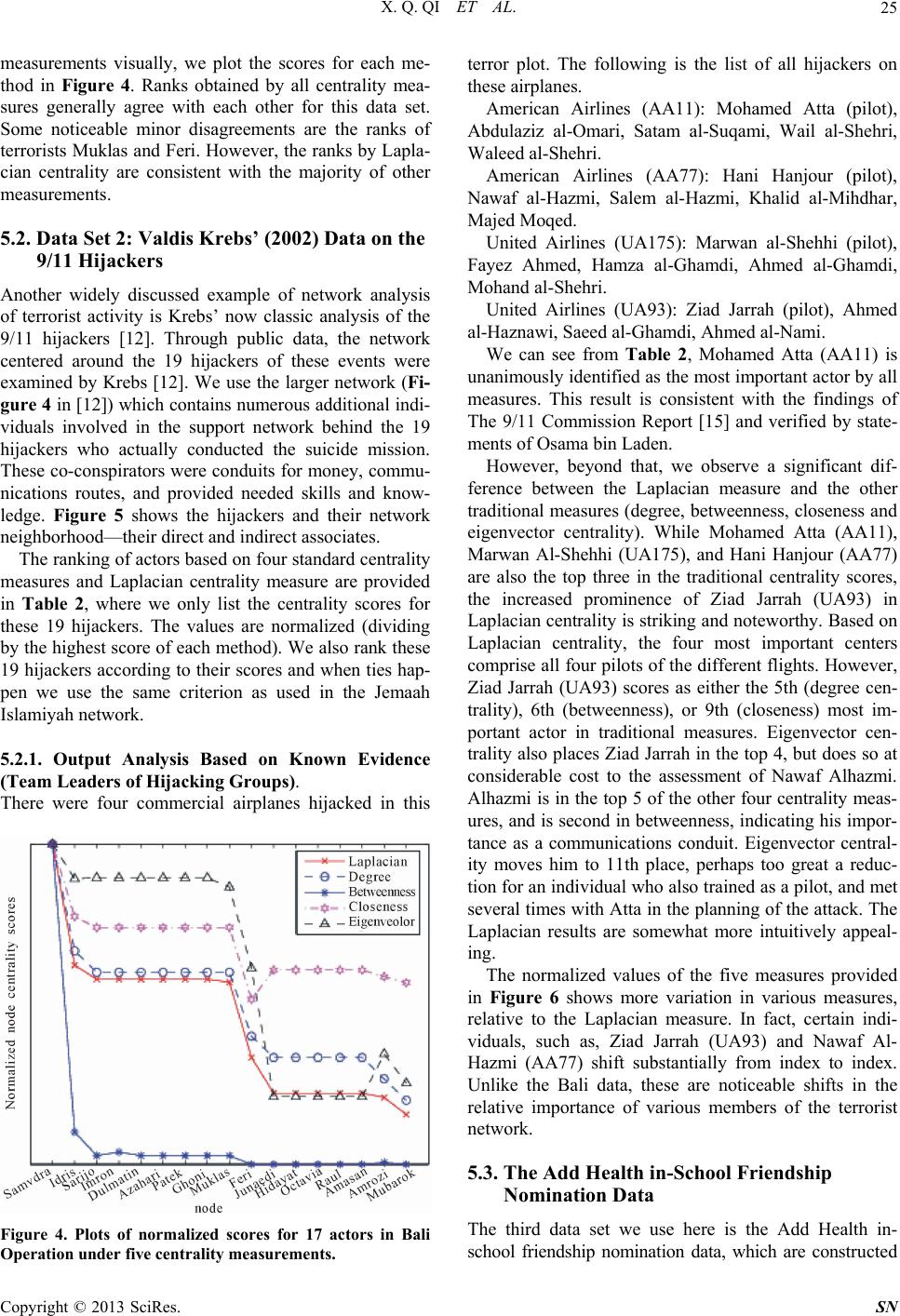 X. Q. QI ET AL. 25 measurements visually, we plot the scores for each me- thod in Figure 4. Ranks obtained by all centrality mea- sures generally agree with each other for this data set. Some noticeable minor disagreements are the ranks of terrorists Muklas and Feri. However, the ranks by Lapla- cian centrality are consistent with the majority of other measurements. 5.2. Data Set 2: Valdis Krebs’ (2002) Data on the 9/11 Hijackers Another widely discussed example of network analysis of terrorist activity is Krebs’ now classic analysis of the 9/11 hijackers [12]. Through public data, the network centered around the 19 hijackers of these events were examined by Krebs [12]. We use the larger network (Fi- gure 4 in [12]) which contains numerous additional indi- viduals involved in the support network behind the 19 hijackers who actually conducted the suicide mission. These co-conspirators were conduits for money, commu- nications routes, and provided needed skills and know- ledge. Figure 5 shows the hijackers and their network neighborhood—their direct and indirect associates. The ranking of actors based on four standard centrality measures and Laplacian centrality measure are provided in Table 2, where we only list the centrality scores for these 19 hijackers. The values are normalized (dividing by the highest score of each method). We also rank these 19 hijackers according to their scores and when ties hap- pen we use the same criterion as used in the Jemaah Islamiyah network. 5.2.1. Output Analysis Based on Known Evidence (Team Leaders of Hijacking Groups). There were four commercial airplanes hijacked in this Figure 4. Plots of normalized scores for 17 actors in Bali Operation under five centrality measurements. terror plot. The following is the list of all hijackers on these airplanes. American Airlines (AA11): Mohamed Atta (pilot), Abdulaziz al-Omari, Satam al-Suqami, Wail al-Shehri, Waleed al-Shehri. American Airlines (AA77): Hani Hanjour (pilot), Nawaf al-Hazmi, Salem al-Hazmi, Khalid al-Mihdhar, Majed Moqed. United Airlines (UA175): Marwan al-Shehhi (pilot), Fayez Ahmed, Hamza al-Ghamdi, Ahmed al-Ghamdi, Mohand al-Shehri. United Airlines (UA93): Ziad Jarrah (pilot), Ahmed al-Haznawi, Saeed al-Ghamdi, Ahmed al-Nami. We can see from Table 2, Mohamed Atta (AA11) is unanimously identified as the most important actor by all measures. This result is consistent with the findings of The 9/11 Commission Report [15] and verified by state- ments of Osama bin Laden. However, beyond that, we observe a significant dif- ference between the Laplacian measure and the other traditional measures (degree, betweenness, closeness and eigenvector centrality). While Mohamed Atta (AA11), Marwan Al-Shehhi (UA175), and Hani Hanjour (AA77) are also the top three in the traditional centrality scores, the increased prominence of Ziad Jarrah (UA93) in Laplacian centrality is striking and noteworthy. Based on Laplacian centrality, the four most important centers comprise all four pilots of the different flights. However, Ziad Jarrah (UA93) scores as either the 5th (degree cen- trality), 6th (betweenness), or 9th (closeness) most im- portant actor in traditional measures. Eigenvector cen- trality also places Ziad Jarrah in the top 4, but does so at considerable cost to the assessment of Nawaf Alhazmi. Alhazmi is in the top 5 of the other four centrality meas- ures, and is second in betweenness, indicating his impor- tance as a communications conduit. Eigenvector central- ity moves him to 11th place, perhaps too great a reduc- tion for an individual who also trained as a pilot, and met several times with Atta in the planning of the attack. The Laplacian results are somewhat more intuitively appeal- ing. The normalized values of the five measures provided in Figure 6 shows more variation in various measures, relative to the Laplacian measure. In fact, certain indi- viduals, such as, Ziad Jarrah (UA93) and Nawaf Al- Hazmi (AA77) shift substantially from index to index. Unlike the Bali data, these are noticeable shifts in the relative importance of various members of the terrorist network. 5.3. The Add Health in-School Friendship Nomination Data The third data set we use here is the Add Health in- school friendship nomination data, which are constructed Copyright © 2013 SciRes. SN 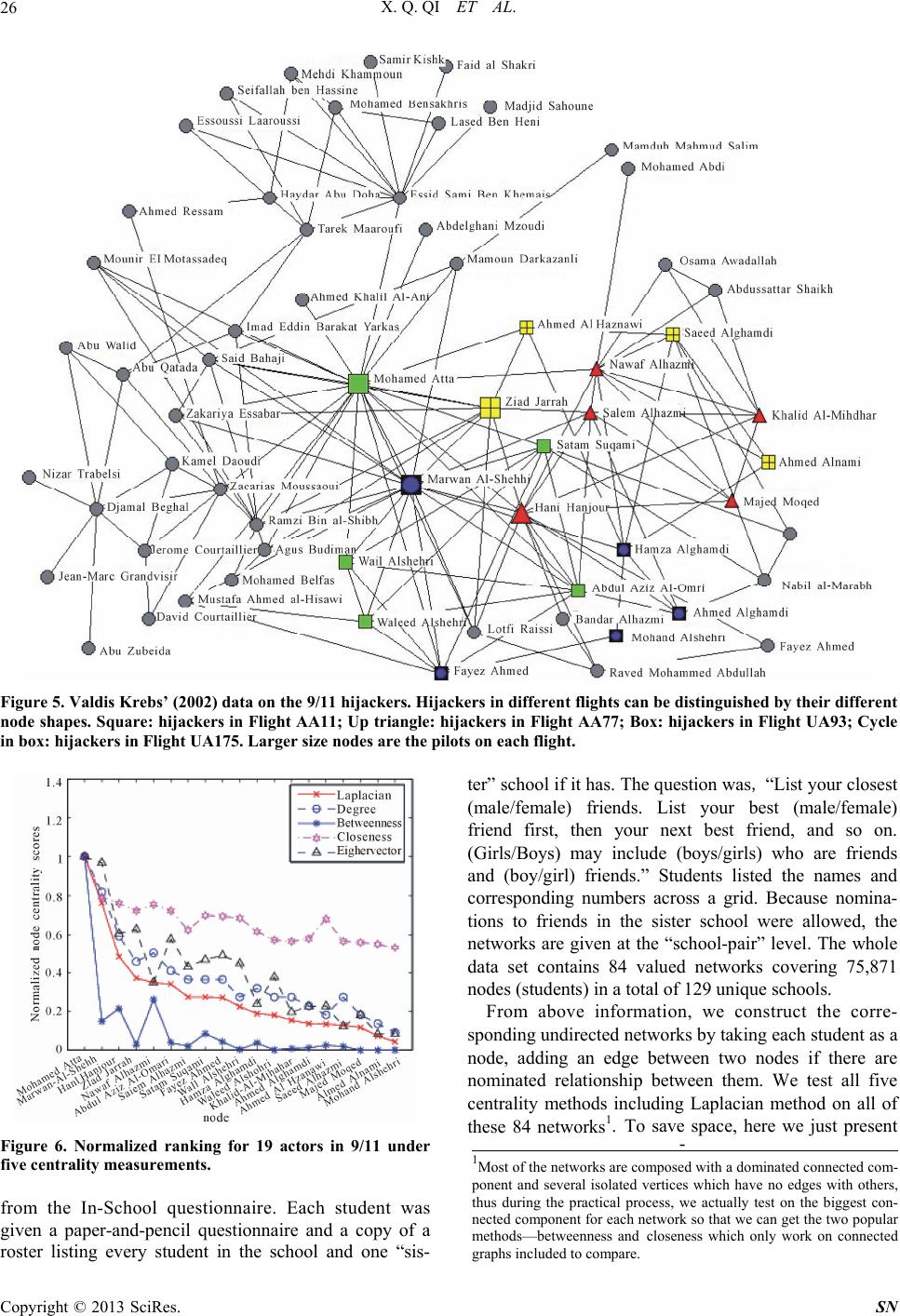 X. Q. QI ET AL. 26 Figure 5. Valdis Krebs’ (2002) data on the 9/11 hijackers. Hijackers in different flights can be distinguished by their different node shapes. Square: hijac kers in Flight AA11; Up triangle: hijackers in Flight AA77; Box: hijackers in Flight UA93; Cycle in box: hijackers in Flight UA175. Larger size nodes are the pilots on each flight. Figure 6. Normalized ranking for 19 actors in 9/11 under five centrality measurements. from the In-School questionnaire. Each student was given a paper-and-pencil questionnaire and a copy of a roster listing every student in the school and one “sis- ter” school if it has. The question was, “List your closest (male/female) friends. List your best (male/female) friend first, then your next best friend, and so on. (Girls/Boys) may include (boys/girls) who are friends and (boy/girl) friends.” Students listed the names and corresponding numbers across a grid. Because nomina- tions to friends in the sister school were allowed, the networks are given at the “school-pair” level. The whole data set contains 84 valued networks covering 75,871 nodes (students) in a total of 129 unique schools. From above information, we construct the corre- sponding undirected networks by taking each student as a node, adding an edge between two nodes if there are nominated relationship between them. We test all five centrality methods including Laplacian method on all of these 84 networks1. To savere we just present space, he - 1Most of the networks are composed with a dominated connected com- onent and several isolated vertices which have no edges with others, thus during the practical process, we actually test on the biggest con- nected component for each network so that we can get the two popula methods—betweenness and closeness which only work on connected graphs included to c ompare. Copyright © 2013 SciRes. SN 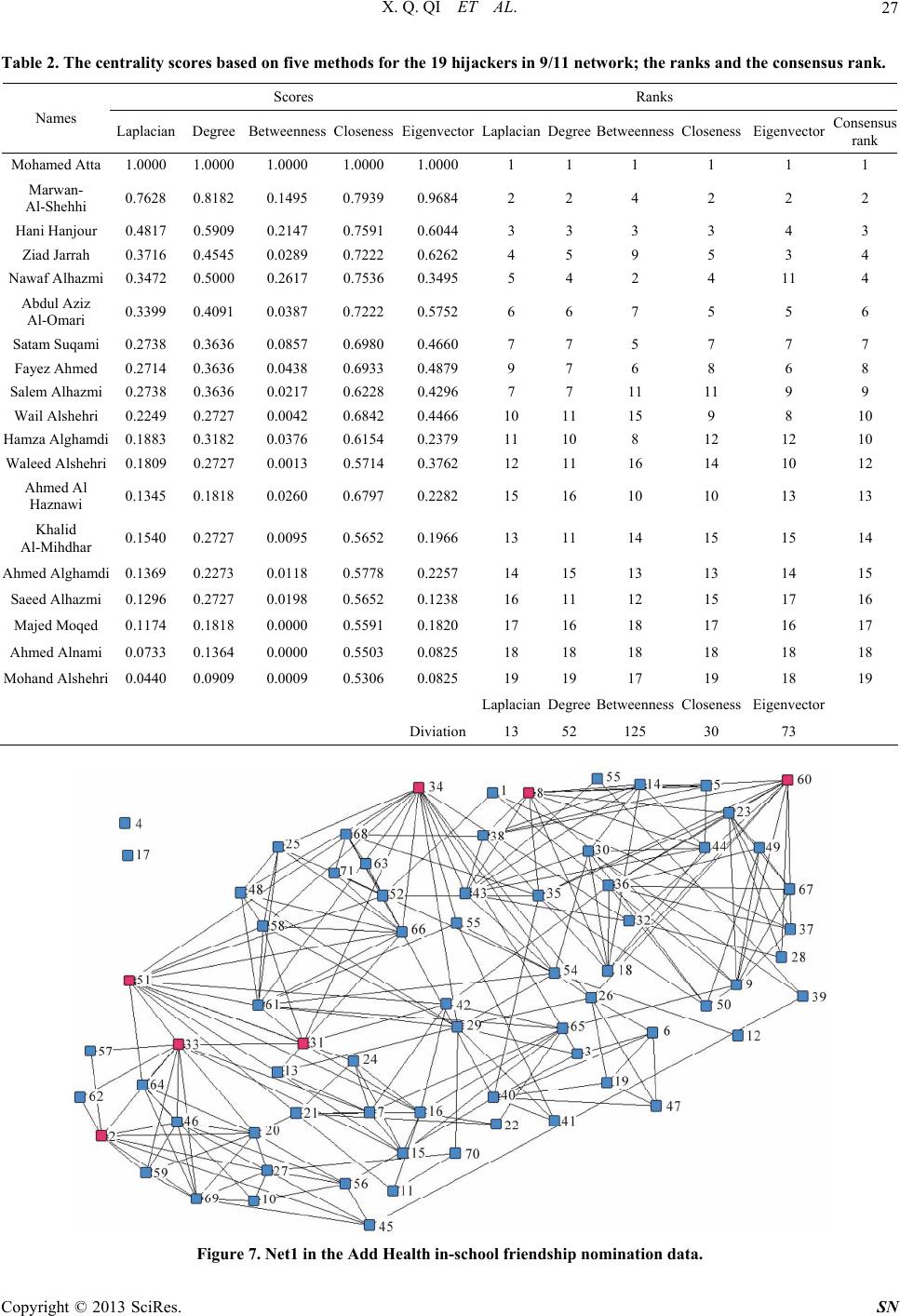 X. Q. QI ET AL. 27 Table 2. The centrality scores based on five methods for the 19 hijackers in 9/11 network; the ranks and the consensus rank. Scores Ranks Names Laplacian Degree Betweenness ClosenessEigenvectorLaplacianDegreeBetweennessCloseness Eigenvector Consensus rank Mohamed Atta 1.0000 1.00001.0000 1.0000 1.0000 1 1 1 1 1 1 Marwan- Al-Shehhi 0.7628 0.81820.1495 0.7939 0.9684 2 2 4 2 2 2 Hani Hanjour 0.4817 0.59090.2147 0.7591 0.6044 3 3 3 3 4 3 Ziad Jarrah 0.3716 0.45450.0289 0.7222 0.6262 4 5 9 5 3 4 Nawaf Alhazmi 0.3472 0.50000.2617 0.7536 0.3495 5 4 2 4 11 4 Abdul Aziz Al-Omari 0.3399 0.40910.0387 0.7222 0.5752 6 6 7 5 5 6 Satam Suqami 0.2738 0.36360.0857 0.6980 0.4660 7 7 5 7 7 7 Fayez Ahmed 0.2714 0.36360.0438 0.6933 0.4879 9 7 6 8 6 8 Salem Alhazmi 0.2738 0.36360.0217 0.6228 0.4296 7 7 11 11 9 9 Wail Alshehri 0.2249 0.27270.0042 0.6842 0.4466 10 11 15 9 8 10 Hamza Alghamdi 0.1883 0.31820.0376 0.6154 0.2379 11 10 8 12 12 10 Waleed Alshehri 0.1809 0.27270.0013 0.5714 0.3762 12 11 16 14 10 12 Ahmed Al Haznawi 0.1345 0.18180.0260 0.6797 0.2282 15 16 10 10 13 13 Khalid Al-Mihdhar 0.1540 0.27270.0095 0.5652 0.1966 13 11 14 15 15 14 Ahmed Alghamdi 0.1369 0.22730.0118 0 .5778 0.2257 14 15 13 13 14 15 Saeed Alhazmi 0.1296 0.27270.0198 0.5652 0.1238 16 11 12 15 17 16 Majed Moqed 0.1174 0.18180.0000 0.5591 0.1820 17 16 18 17 16 17 Ahmed Alnami 0.0733 0.13640.0000 0.5503 0.0825 18 18 18 18 18 18 Mohand Alshehri 0.0440 0.09090.0009 0.5306 0.0825 19 19 17 19 18 19 LaplacianDegreeBetweennessCloseness Eigenvector Diviation13 52 125 30 73 Figure 7. Net1 in the Add Health in-school friendship nomination data. Copyright © 2013 SciRes. SN  X. Q. QI ET AL. 28 Table 3. The centrality scores based on five methods for top 15 vertices in Net 1; their ranks and consensus rank in all 69 vertices. Scores Ranks Node number Laplacian Degree Betweenness ClosenessEigenvectorLaplacianDegreeBetweenness Closeness EigenvectorConsensus #34 1 1 0.8902 0.9869 1 1 1 2 2 1 1 #51 0.9306 0.9286 1 1 0.8879 2 2 1 1 3 2 #66 0.7269 0.7857 0.4303 0.9379 0.8048 5 4 7 4 4 3 #61 0.7546 0.7857 0.3080 0.9379 0.9034 3 4 19 4 2 4 #33 0.7546 0.8571 0.7181 0.8118 0.5134 3 3 3 17 11 5 #29 0.5787 0.7143 0.3812 0.8728 0.6311 9 7 10 6 7 6 #31 0.6204 0.6429 0.3219 0.9497 0.7546 7 10 18 3 6 7 #54 0.5278 0.6429 0.4113 0.8629 0.5562 13 10 8 9 10 8 #43 0.5185 0.6429 0.4357 0.8436 0.3713 14 10 6 14 13 9 #60 0.6759 0.7857 0.3557 0.8297 0.3157 6 4 13 16 20 10 #16 0.4815 0.6429 0.1666 0.8032 0.4308 19 10 24 18 12 11 #35 0.4630 0.5714 0.4587 0.8678 0.2510 20 19 5 8 32 12 #8 0.6157 0.7143 0.2147 0.7947 0.2948 8 7 21 23 26 13 #26 0.3935 0.5000 0.3599 0.8629 0.3558 25 25 12 9 16 14 #36 0.5509 0.7143 0.3395 0.7989 0.2422 10 7 15 21 35 15 LaplacianDegreeBetweennessCloseness Eigenvector Diviation3314 4071 7182 5267 5854 the results for the first network Net1, which contains 71 nodes totally (a big component with 69 vertices and two isolated vertices), detailed see Figure 7. Table 3 shows all the centrality scores and ranks for 15 of these 71 ver- tices. Since we are lacking of the background information of this school, it is hard for us to discuss these centrality results from known evidence. Thus in next section, we will use “deviation from consensus rank” for each cen- trality method to evaluate its performance. The outper- formance of Laplacian method is illustrated in Table 3—the smallest deviation. For example, degree method can not distinguish the importance between node and since they have the same number of immediate neighbors, but they are distinguished by Laplacian me- thod because Laplacian method considers the bigger en- vironment (neighbors with 2 steps) around them. #66 #61 6. Consensus Analysis and Degree of Deviation Consensus analysis of outputs is a widely used method in bioinformatics for finding “consensus DNA or RNA (sub) sequence(s)” [16,17]. A similar consensus method is adapted here to evaluate the performence of various methods and, therefore, to verify the validity of Lapla- cian centrality method. Outputs from several standard methods are taken in consideration, and would be further compared with the consensus result. A method is re- garded as more robust and has greater confidence if its output is closer (smaller deviation, or better matching) to the consensus result. Here, to save space, we demonstrate the consensus analysis only for the 9/11 hijackers. 6.1. Consensus Rank Different from DNA sequences whose terms are nucleo- tides ,,, CGT2. The ranking of hijackers are nu- merically scored (natural numbers). Hence, the subjects for consensus are rather different. In this research project, we adapt the similar ideas and principles of consensus applied in bioinformation in the ranking study of social networks. The consensus ranks are calculated as follows. At first, for each terrorist, we calculate the mean of its five ranks from various methods. For example, Marwan Al-Shehhi (UA175) gets ranks from five 2,2,4,2,2 2Abbreviations of nucleotides: = adenine , , =Ccytosine =Gguanine , . =Tthymine Copyright © 2013 SciRes. SN  X. Q. QI ET AL. 29 centrality methods respectively, thus its mean of rank is 2.4 (a fractional number); secondly, we sort the mean values of these 19 hijackers from smallest to largest, the output of order is defined as the consensus rank of these 19 hijackers. Note that when ties happen (i.e., more than one hijackers have the same mean value) we follows the same criterion as used in Jemaah Islamiyah network and 9/11 network. We list the consensus rank of these 19 hijackers at the last column of Table 2. 6.2. Deviation of Each Method from Consensus Result To further analyze, we use the following “deviation” score to numerically evaluate the distance from the out- put based on each centrality method to the consensus rank: 19 2 =1 = C i deviation Crankiconsensus i where is the rank of -th terrorist based on centrality measurement ( {Laplacian, degree, closeness, betweenness, eigenvector centrality}), and is the consensus rank of -th terrorist. C rank i ensus i i C C cons i Clearly, the smaller the deviation, the better is the output. A method with the smallest deviation is regarded as the one with “the best fit”. The deviations for all cen- trality methods are presented at the last two rows of Ta- ble 2, which shows that Laplacian method has the small- est deviation. That is, Laplacian centrality method has the best fit to the consensus ranking results, which is a further evidence of its effectiveness and reliability to identify major players in social network. We apply the same strategy on the Jemaah Islamiyah data set, and find that Laplacian method also has the smallest deviation, see Table 1. We also apply the same strategy on all the 84 networks in the Add Health in-school friendship nomination data. We find that Laplacian method’s deviations for all these 84 networks are always the minimum, which imply Laplacian method is the most fit centrality method for all these 84 networks. This is another strong evidence that shows the Laplacian method’s advantages. Remark The validity and robustness of Laplacian centrality measure have been illustrated on two different terrorist social network data sets and 84 networks in James Moody’s Add Health in-school friendship nomi- nation data, and is compared with other standard central- ity measures. Note that this method also could be applied on large networks (e.g. number of nodes ) with high effectiveness (and low time-consuming) because Laplacian centrality measure has low computational complexity, and we will see in the following Section 7. >1000 7. Computational Complexity In this section, we discuss the computational complexity of Laplacian centrality method. By glancing at the defi- nition of Laplacian centrality (Definition 2), one might initially guess that the computational complexity would be relatively high since it involves the calculation of ei- genvalues. However, by applying an algebraic graph theory result (Theorem 1), we are able to design a very fast algorithm. Theorem 1 provides a structural result that graphically describes the Laplacian centrality. For the sake of comparison, we first present the com- plexity of all standard methods. Let be a graph with vertices and edges. The data structure of the in- put graph is the adjacency list of , which presents the adjacency relation of all edges of the input graph . G nm GG Closeness and Betweeness Centralities. The most basic step in these two algorithms is the search for the shortest paths between every pair of vertices. Computing the shortest paths between any two vertices is the necessary step. Its fastest algorithm is Floyd-Warshall algorithm whose time complexity is [18]. Hence, the total time complexity for either closeness method or between- ness method is at least 3 On 3 On . Eigenvector Centrality. Given a graph, there are sev- eral approaches for estimating the eigenvector. One of the most popular approaches involves the inverses of matrices. Computational complexity is at least 3 On for the computation of inverses [19]. Laplacian centrality. The degrees of all vertices and the corresponding neighborhood are estimated by scan- ning the adjacency list. That is, the time complexity for this step is at most Om. Then, by Theorem 1, Lapla- cian centralities for each one vertex needs v 2 dv additive operations and 2 multiplication operations, thus the computations of centrality scores for all vertices can be finished in 4n2Om units of time. Thus, the computational complexity of Laplacian method is Om. Degree Centralities. Though degree measuring is rather intuitively heuristic and its processing is pretty straightforward, the time complexity remains Om, not smaller than that of Laplacian centrality. To summary, we present the following table showing the time complexity of each method. We would see that Laplacian centrality offers substantial advantages to the other measures when examining large scale networks. We admit that degree method run faster than Laplacian method, but it only supplies us very local information for each vertex, which is less reliable. time complexity laplacian Om eigenvalue 3 On betweenness 3 On closeness 3 On degree On Copyright © 2013 SciRes. SN  X. Q. QI ET AL. 30 8. Concluding Remarks In this final section, we survey some properties of the new method: its balanced global/local measurement quai- lties, its accuracy and effectiveness, efficiency, and its future applications. The review is conducted from several very different angles: graph structure, verification of known facts from experimental testing, and the consen- sus for comparison. From the graph theoretical point of view, graph cen- trality measurements can be roughly classified as two types: local or global. Degree centrality is a typical ex- ample of local measurement since it only considers the information of the number of vertices which are reach- able from directly, while betweeness, closeness and eigenvector, are more global. Laplacian centrality reveals more connection information beyond its immediate sur- rounding neighborhood, thus serves as an intermediate between global and local characterizations. v Centrality measurement based on shortest path calcu- lations (such as, betweeness, closeness, etc.) are powerful tools for the detection of bottlenecks in networks—the cut-vertices of connected graphs. Consequently, these types of vertices are scored more favorably if global con- nectivity is relatively low. In these lower connectivity examples, Laplacian centrality will provide a more ba- lanced measurement, which takes both bottleneck infor- mation and local density information into account. As we discussed above, from a graph theoretical point of view different methods reveal different measurements of im- portance due to their different structural emphasis. Test results from some benchmark data sets also sup- port the conclusion that Laplacian centrality is a balanced global/local measurement. It is able to identify not only the cut point of the network of the connection, but also the leaders or key personnel in each cluster, such as the team pilot of each 911 hijacking group and the suicide bombers of bomb delivery group in the Bali nightclub attack. Applying the new method along with other popularly used methods to two terrorist networks and all 84 friend- ship networks yields strong evidence that the Laplacian method provides a better performance as a network ana- lysis tool. This is supported by two different approaches: confirmation of analyses based on known intelligence information, and consensus comparison, where the study shows that the Laplacian method has the smallest devia tion from the consensus result, providing additional evaluation of the reliability of Laplacian centrality. In situations where scarce resources must be commit- ted to counterterrorism programs, diversion of monitor- ing and surveillance from one actor to another may be a critical decision. A relatively effective and reliable me- thod is needed for such analysis and decision making. Based on our graph theore tical analysis, testing of bench- mark data, and statistical comparisons, this newly de- signed method is a potentially significant candidate for a reliable tool to be used in the identification of major players in future terrorist attacks. We have illustrated the similarities and dissimilarities with respect to the standard measures adopted in socio- metry by considering some important examples of po- litical networks. As we know, for any particular research project we will have to identify which centrality measure is most meaningful or useful. It remains to be seen, in the light of further empirical work, if and in which cases the new measure is clearly more appropriate than the others. Yet at this preliminary exposition, Laplacian centrality provides results that seem potentially compelling in cer- tain situations where the overall degradation of the net- work based on vertex deletion may yield superior results. Network analysis in support of counterterrorism might well be an area where Laplacian centrality rises to such importance. 9. Acknowledgements This research project is partially supported by a WV EPSCoR grant and an NSA grant H98230-12-1-0233. This work is also su pported partly by Sh andong Pro vince Natural Science Foundation of China with No. ZR2010AQ018 and No. ZR2011FQ010, partly by Inde- pendent Innovation Foundation of Shandong University with No. 2010ZRJQ005, Q. Wu’s wo rk is also suppo rted by National Natural Science Foundation of China (NO. 61202312). REFERENCES [1] Z. Maoz, D. Kuperman, L. Terris and I. Talmud, “Struc- tural Equivalence and International Conflict: A Social Networks Analysis,” Journal of Conflict Resolution, Vol. 50, No. 5, 2006, pp. 664-689. doi:10.1177/0022002706291053 [2] M. Sageman, “Understanding Terror Networks,” Phila- delphia, University of Pennsylvania Press. 2004. [3] J. T. Scholz, R. Berardo and B. Kile, “Do Networks En- hance Cooperation? Credibility, Search, and Collabora- tion,” Journal of Politics, Vol. 70, No. 2, 2008, pp. 393-406. [4] J. Fowler, B. Grofman and N. Masuoka, “Social Net- works in Political Science: Hiring and Placement of Ph. Ds, 1960-2002. Political Science: 2007, pp. 727-739. [5] S. Sreenivasan, R. Cohen, E. Lopez, Z. Toroczkai and H. E. Stanley 2007. Phys. Rev. E 75, 036105. doi:10.1103/PhysRevE.75.036105 [6] M. O. Jackson, “Presenting and Measuring networks,” Chapter 2, Social and Economic Networks, Princeton University Press, Princeton, 2008. [7] T. Opsahl, F. Agneessens and J. Skvoretz, “Node Cen- trality in Weighted Networks: Generalizing Degree and Copyright © 2013 SciRes. SN  X. Q. QI ET AL. Copyright © 2013 SciRes. SN 31 Shortest Paths,” Social Networks, Vol. 32, No. 3, 2010, pp. 245-251. doi:10.1016/j.socnet.2010.03.006 [8] F. Jordan and I. Scheuring, “Network Ecology: Topo- logical Constraints on Ecosystems Dynamics,” Physics of Life Reviews, Vol. 1, No. 3, 2004, pp. 139-172. doi:10.1016/j.plrev.2004.08.001 [9] F. Jordan, W. C. Liu and A. J. Davis, “Topological Key- stone Species: Measures of Positional Importance in Food Webs,” Oikos, Vol. 112, No. 3, 2006, pp. 535-546. doi:10.1111/j.0030-1299.2006.13724.x [10] M. Lazic, “On the Laplacian Energy of a Graph,” Cze- choslovak Mathematical Journal, Vol. 56, No. 131, 2006, pp. 1207-1213. [11] S. Koschade, “A Social Network Analysis of Jemaah Islamiyah: The Applications to Counterterrorism and In- telligence,” Studies in Conflict and Terrorism, Vol. 29, No. 6, 2006, pp. 559-575. doi:10.1080/10576100600798418 [12] V. Krebs, “Uncloaking Terrorist Networks,” First Mon- day, Vol. 7, No. 4, 2002, 1st April. [13] F. Chung, “Spectral Graph Theory,” American Mathe- matical Society, USA1997.. [14] J. Magouirk, S. Atran and M. Sageman, “Connecting Terrorist Networks,” Studies in Conflict and Terrorism, Vol. 31, No. 1, 2008, pp. 1-16. [15] T. H. Kean et al., “The 9/11 Commission Report,” W. W. Norton and Company, New York, 2004. [16] M. Hamada, K. Sato and K. Asai, “Improving the Accu- racy of Predicting Secondary Structure for Aligned RNA Sequences,” Nucleic Acids Research, 1-10. 2010. [17] M. Xu, Z. Su, “Computational Prediction of cAMP Re- ceptor Protein (CRP) Binding Sites in Cyanobacterial Genomes,” BMC Genomics, 10-23. 2009. [18] S. Pemmaraju and S. Skiena, “All-Pairs Shortest Paths and Transitive Closure and Reduction. In: Computational Discrete Mathematics: Combinatorics and Graph Theory in Mathematica. Cambridge, England, Cambridge Uni- versity Press, 2003. pp. 330-331 and 353-356. [19] B. C. Csaji, R. M. Jungers and V. D. Blondel, “Pagerank Optimization by Edge Selection,” The Computing Re- search Repository abs/0911.2280. 2009.
|