 A Journal of Software Engineering and Applications, 2012, 5, 107-112 doi:10.4236/jsea.2012.512b021 Published Online December 2012 (http://www.scirp.org/journal/jsea) Copyright © 2012 SciRes. JSEA Chinese Keyword Search by Indexing in Relational Databases Liang Zhu1, Lijuan Pan1, Qin Ma2 1Key Laboratory of Machine Learning and Computational Intelligence, School of Mathematics and Computer Science, Hebei University, Baoding, Hebei 071002, China; 2Department of Foreign Language Teaching and Research, Hebei University, Baoding, Hebei 071002, China. Email: zhu@hbu.edu.cn (L. Zhu), katharine162@126.com(L. Pan), maqin@hbu.edu.cn(Q. Ma) Received Octob e r 15, 2012. ABSTRACT In this paper, we propose a new method based on index to r ealize IR-style C hine se key word sea rch with ra nki ng str ate- gies in relational databases. This method creates an index by using the related information of tuple words and presents a ranking strategy in terms of the nature of Chinese words. For a Chinese keyword query, the index is used to match quer y search words and the tuple words in index quickl y, and to compute si milaritie s between the quer y and tuples by the ranking strategy, and then the set of identifiers of candidate tuples is generated. Thus, we retrieve top-N results of the query using SQL selectio n statements and output the ranked answers according to the similarities. The experimental resul ts show that our method is effi cient and effecti ve. Keywords: Relational Databa se; Chinese Keyword Search; Index; Ranking Strategy 1. Introduction For a database system, keyword search with the gener- al-purpo se que ry e ngine uses us er-supplied data to query the contents of string pr operties that store keywords, and then requires users to have the knowledge of database sche ma and a que r y la ng ua ge (s a y, SQ L) . I nspired by the success of free-form keyword search on information re- trieval (IR) and Web search engines, i.e., it is popular to users who need not know q uery lang uages and the struc- ture of underlying data. Researches of English keyword search with IR-style free-form in relational databases have been extensively studied since 2002[1-7]. [1] and [2] join tuples from multiple relations in the database to identify tuple trees with a ll the quer y keywords, for each enumerated join tree, both of them simply rank join se- quences according to the number of joins. ObjectRank system [3] applies authority-based ranking to keyword search in database modeled as labeled graph. [4] pro- posed a method (G-KS) for selecting the top-N candi- dates based on their potential to contain results for a given query. [5] succeeded in putting the model of com- puting similarities in IR into computing similarities be- tween a candidate answers and tuples in relational data- bases, the methods pay more attention on effectiveness of keyword search. [6] proposed a middleware free ap- pro a ch to c o mput e such m-keyword queries on RDBMSs using SQL only. In this paper, we will discuss Chinese keyword search in a relational database based on an in- dex. Chinese is totall y different from Englis h. For instance, (1) Chinese words are tighter in writing, unlike English; there is no space between words. (2) Chinese words are coded by using GB2312-80 and each Chinese word is stored in two consecutive bytes in memory, while an English word is composed of letter(s) and each letter takes one byte, say, the Chinese word “人” (means “per- son”) is 0xC8CB with two bytes in memory; however, English word “person” takes 6 b ytes. (3) Abbreviations in English are acronyms, such as “WWW” is short for “World Wide Web”; however, abbreviations in Chinese are extracted words from a phrase, say, “高代” means “高等代数” (Advanced Algebra). Example 1. As shown in Figure 1, database BOOKS has three relations/tables: Titles(tid, title, Faid, Fpid, ...), Authors(aid, name,...), and Publishers(pid, pname,...). Without loss of generality, we suppose the relationship between Aut hors and Titles is “one to many”, not “many to many”. We regard all authors of a book together as one author, since the keyword search will be processed by each Chinese word and the index will be created by using the text attributes of Entities (say, title, name,  Chinese Keyword Search by Indexin g i n Relational Databases Copyright © 2012 SciRes. JSEA 108 pname), not usin g the id’s i n rela tionships. Mor eover, the 1-to-n type relationship may be more feasible in practice in our scenarios (say, a string of Chinese words will be concatenation of names of two or more authors if there is an error of typing). For query Q = {高代; 高教社}, a user want to get the answers of “title = 高等代数, au- thor =高代(if any), publisher = 高等教育出版社 (Higher Education Press)”. Traditional DBMS cannot obtain suc h res ults, a nd it is d ifficult for us to use direct- ly the existing methods of English ke yword search mod- els in Chinese keyword query. Titles tid title Faid Fpid t1 高等代数 a1 p1 t2 环境化学 a2 p1 t3 民法教程 a3 p3 Authors Publ i sh ers aid aname pid pname a1 北京大学数学系 p1 高等教育出版社 a2 戴树桂 p2 新华出版社 a3 江平 p3 中国政法大学出版社 Figure 1. Part of BOOKS database Inspired by the technique of creating index of tuple words in [8], we present a new method to perform Chi- nese keyword search b y i ndexing. This wo rk is a co ntin- uation of [9], which studied Chinese keyword search with only one relation; however, this paper discusses a relational database with multiple rela tions, and it is more chall enging tha n the work in [9]. We will build an index based on the information of tuple words and improve the classic ranking strategy in IR. For a Chinese keyword query, its top-N answers will be obtained by the index and the improved ranking strategy. 2. Data Model and Query Model Consider a database with n relations R1, …, Rn. Each relation Ri has mi text attributes Ai1, Ai2, ..., Aimi, a primary key and possibly foreign key(s) referencing other rela- tion(s). Definition 1 (Sche ma Graph) [2 , 4]: A directed graph captures the primary key-foreign key relationsh ips in the schema of the database. It has a node for each relation Ri of the databas e an d an edg e Ri→Rj for each f oreign key to primary key relationship from a set of attributes (Aib1, … , Aibt) of Ri to a set o f attributes (Ajb1, …, Ajbt) o f Rj, where Aibk ≡ Ajbk for k =1,. . ., t. Definition 2 (Tuple Tree) [2, 5] A tuple tree T is a joining tree of tuples. Each node ti in T is a tuple in the base relation Ri. For each pair of adjacent tuples ti, tj ∈ T, where ti∈Ri, tj∈Rj, there is an edge Ri→Rj and ti tj ∈ Ri Rj. Definition 3 (Tuple Word): For each tuple t belong s to Ri and A∈{Ai1, Ai2 ,..., Aimi}, t[A] is the attrib ute value on attribute A of relation Ri, it contains single or multiple Chinese words. We define every single Chinese word as a Chinese tuple wo rd. Definition 4 (Index Table): An Index Table is com- posed of tuple words and their related information ex- tracted from the database, its schema is TupleWordTable (wordid, word, size, DBValue), where wordid is the pri- mary key, word is the tuple word, si ze is the number of text attributes that co nta in the co rr esp ondi ng tuple wor d, DBValue is a text attribute with form “cid, df, tid, tf, dl; cid, df, tid , tf, dl;…;”. In DBValue, cid is the identi fier of the attribute (or colu mn) cont aini ng the t uple word, df is the number of cells containing the tuple word in certain attribute (or column), tid is the identifier of the tuple conta inin g the t uple word, tf is the number of tuple word appears in the cell determined by tid and cid , and dl is the total number of words (counting duplicate words) in the cell determined by tuple identifier tid and attribute/column identifier cid. Definition 5 (Keyword Qu ery): A query Q = (k1, k2, ..., kp) is a set of Chinese tuple words. The results of the keyw or d qu ery are the tuple trees joined by relations. The results are ranked by a ranking strategy, and then the top-N ones will be the desired ans wers of a user. 3. Construction of Index Table In this section, we will describe how to create an index table with information of tuple words, including the de- sign and implementa tion of the i ndex. 3.1. Design of Index Table An index table which is designed as relation with schema TupleWordTable (wordid, word, size, DBValue) is con- structed to store the information of each single tuple word. Tuple words in tuples of relation Ri (1≤ i ≤ n) are extracted from Ri and are stored into the index table. For a query, we invoke an i nd ex to imple me nt the search and display the top-N answers ranked by a ranking strategy. Therefor e, it is impor tant to d ecide info rmatio n gra nular- ity of tuple words stored in index table. In this paper, we consider co lumn level of gran ularity as well as cell level. The answers for a query are tuple trees joined by differ- ent attributes, and the nature of different attributes will affect the effectiveness of the keyword query, thus,  Chinese Keyword Search by Indexin g i n Relational Databases Copyright © 2012 SciRes. JSEA attributes information in database need to be recorded individually. Cell granularity is more detailed which will create more accurate similarities between query and re- sults. In relation TupleTableWord, DBValue is used to store column level and cell lev e l information. 3.2. Implementation of Index The process of creating index table includes three steps: (1) Normalize tuples in Ri (i=1, 2, ..., n), remove useless characters and Chinese punctuation which will obstruct the pr ocessing of extracting Chinese words. (2) For each tuple word belongs to t[A], extract related information of tuple word. (3) Use the information to cre a te ind e x table. D 11 W 2 W 1 W d 。。。。。。 Hash-Table ^ Word-List Col-list Col-list … … … … … … …… …… … … … … … … T 1 T 1 T r T q D 1n m D d1 D dn m ... ... ... ... ^ ^ ^ ^ ^^ T h T 1 T 1 T u ’ tl-list tl-list tl-list tl-list Figure 2. Structure of the ind ex The structure of the index is shown in Figure 2. It has a Hash-Table and three layers of linked lists. The first layer is the Wo rd-list which stores tuple words. Node Wi (i=1, 2,…, d) in Word-list corresponds to a single tuple word and wordi d in the index table, it also has a pointer pointing to a Col-list whic h is the second layer linked list. Each node in a Col-list saves the information that corre- lates to the tuple word appeared in a certain attribute (or column). Different node in the Col-list of Wi indicates that Wi turns up in di fferent attrib ute. Like wise, one no de in the third layer tl-list stores the related information of Wi of a specific tuple. The algorithm of creating the in- dex table is described below: ______________________________________________ IndexTableCreationAlgorithm (R1, R2, … ,Rn) { 0. For each relation Ri in {R1, R2, … , Rn} 1. For each attribute Aij in { Ai1, Ai2, ..., Aimi} of Ri 2. For the value of each tuple t on attrib ute Aij // t[Aij] 3. For each tuple word z∈t[Aij]={z1 z2 …zs} 4. { If z has not been saved in word-list {add a new node Wi in word-list to save z, and sort the nodes in word-list by the code of GB212-80; create a new Col-list pointed by Wi, and add a new node Di into the Col-li st, to save column identifier (cid) and doc ument frequency (df); create a new tl-list pointed by Di, add a new node Ti into tl-list to save tuple identifier(tid), tuple frequency(tf) and data length(dl); } 5. Else {Return node Wi containing z, search the Col-list pointed by Wi; 6. If Col -list has the node Di corresponding to z.cid {update df, search the tl-list pointed by Di; 7. If the tl-lis t has node Ti with z.tid, update tf; Else add a new node of tl-list to save cid, tf, dl; } 8. Else {add a new node of Col-list to save cid and df; add a new node of tl-list to save tid, tf, dl; }// end else (8) } // end else (5) } // end if (4) } // end algorith m ______________________________________________ As an example, a part of index table is shown in Fig- ure 3 for database BOOKS in our expe ri ment. The index table contains 4506 tuple words including most level 1 and level 2 Chinese words. Figure 3 . A part of the index table for BOOKS database In order to implement the keyword search, we need to load the index table into memory, and match the key- words with tuple words. Fo r a huge ind ex ta ble , however, it is hard to load the whole index table into the memory. Therefore, we need to compress and to improve the in- dex. Firstly, we remove the stop words which are mea- ningless words such as “的” and “吗”, and the words appeared in specific attribute of most tuples, say, “出”, “版”, and ‘社’ in pname attribute of relation P ublishers, more than 95% of tuples contain these words. Secondly, it is necessary for the index table to shrink its structure. We only load the H ash-Table and Wor d-list into memo-  Chinese Keyword Search by Indexin g i n Relational Databases Copyright © 2012 SciRes. JSEA 110 ry. 4. Chinese Keyword Search 4.1. Generation of identifiers of candidate tuples For the query Q = (k1, k2, ..., kp), we match query words ki (i = 1, 2 , …, p ) with tuple wor ds b y usin g the ind ex i n memory, and obtain the set of DBValue of tuple words. We divide DBValue into pieces (cid, df, tid , tf, dl). A tuple is solely identified by its tid, so we collect tid from every piece and obtain the set of all identifiers of basic tuples matched with query words ki, denote by Rjki = {t | t = tid}, where tid means the identifier o f tuple t. Combi ning all sets Rjki (i = 1, 2, …, p), we get RjQ = Rjk1 ∪ Rjk2 ∪ ... ∪ Rjki (j=1, 2, ..., n), which are the sets of all identifiers of candidate tuples containing query words in relation Rj. In the process of collecting tid, we record the number of distinct query words of each tuple. For a tuple, the more distinct query words contained in a tuple, the closer of it gets to Q. Fo r e xa mp le , a gi ve n que r y Q ={k1, k2, k3}, tuple t1 contains one k1 and one k2 , t2 contains two k2’s, t3 conta ins o ne k1, one k2 and o ne k3. Thus, t3 is the best match for Q, and t1 is much closer to Q than t2 according to the similarities between Q and t1, t2, and t3, which can be obtained as follows. 4.2. Ranking Strategy For each candidate tuple that contains query words, we extract the information from piece and calculate the si- milarity b etween the query Q and the tuple . In t hi s p aper, based on vector space model widely used in IR ranking strategy, we improve a classic method [10, 11] to com- pute the similarities between the query Q and tuple trees. Query words and tuple trees are represented as a vector of terms, and each term may be an individual word or a multi-word phrase. The vocabulary of terms makes up a term space, and each term occupies a dimension in the space. Each element of vector is non-negative weight that measures the importance of the ter m in the text. T he similarity is: , ( , )*(, )*(,) k QT Sim Q TncSimkTweightkQ ∈ = + ∑ (1) (, )(,)* ii DT Sim kTweightkAw ∈ = ∑ (2) 1 ln(1ln())1 ( ,)*ln (1 )* i tf N weight kAdl df ss avdl ++ + = −+ (3) Equation (1) and (3) are derived from [9, 10], In Equa- tion (1), weight (k, Q) is the appearance frequency of word k in q uer y Q, tuple tree T is composed of attributes {A1, A2, …, Am}, n∗c is a ne w item for our Chi nese key- word query, c is constant (c = 10 by traini ng in o ur expe- riments), and n is the number of different tuple words contained in T. In Equation (3), s is a constant (usually set to 0.2), N is the number of tuples corresponding to th e attribute, and avdl is the average number of words in tuples corresponding to the attribute. For a query, we define E quation (2) due to the weights (or important fac- tors) of different attributes. For example, when buying a book, the title of a book is usually more important than its publisher; therefore, the weight of a ttribute Titles.t itle should be hig her than that of attribute Pub li shers.pname. Sorting the weights of different attributes, we get the se t W = {w1, w2, …, wn} and wi≥wj (i>j). According to Eq- uation (1) and (3 ), if the value s of tf, df and dl are equiv- alent, larger weights will lead to higher similarities, and the tuple trees with larger weights will rank higher. Suppose M is the maximum value of the number of distinct quer y words in a candidate tuple. After obtaining RjQ, we compute firstly the tuples that owns M distinc t query words, then M-1, M-2, down to one query words. According to the number of the distinct query words (i.e., n), we achieve the subsets Si’s of results for the query, and then the set S of all results is S = S1∪S2∪ …∪SM, Si ∩ Sj = ∅(i≠j), where Si is the collection of tuple trees whose numbers of distinct query words are i. In general, tuple trees in Sj have h ig her si mi la ri ties tha n t ho se i n Si if i < j. 4.3. Answers for queries We utilize the schema graph and RjQ (j = 1, 2, …, n) to construct SQL selection statements, and then retrieve tuple tree from the database. Query conditions of SQL statements have the relation ship of foreign key-primary key and the location of query words. For example, if the schema graph of database is R1←R2→R3, for a query Q = {k1, k2}, SQL sta tements are as below: Select * from R1, R2, R3 where R1.Pid = R2.Fid and R3.Pid = R2.Fid and R2.Pid in R2Q (S1) Select * fro m R1, R2, R3 where R1.Pid = R2.Fid and R3.Pid = R2.Fid and R1.Pid in R1Q (S2) Select * fro m R1, R2, R3 where R1.Pid = R2.Fid and R3.Pid = R2.Fid and R3.Pid in R3Q (S3) Where Pid and Fid denote Primary key and Foreign key respectively. If multiple relations (or multiple attributes) contain the query words that are in the same returned tuple trees, the above SQL statements may lead to re- dunda nt se ar c h r e sult s. In order to avoid redundancy, it is necessary to reduce the repeat selection: Let R1Q = R1Q - R12 after (S1) is executed, and R3Q = R3Q - R32 - R31 after (S1) and (S2) are executed, where R12 is the identifier set 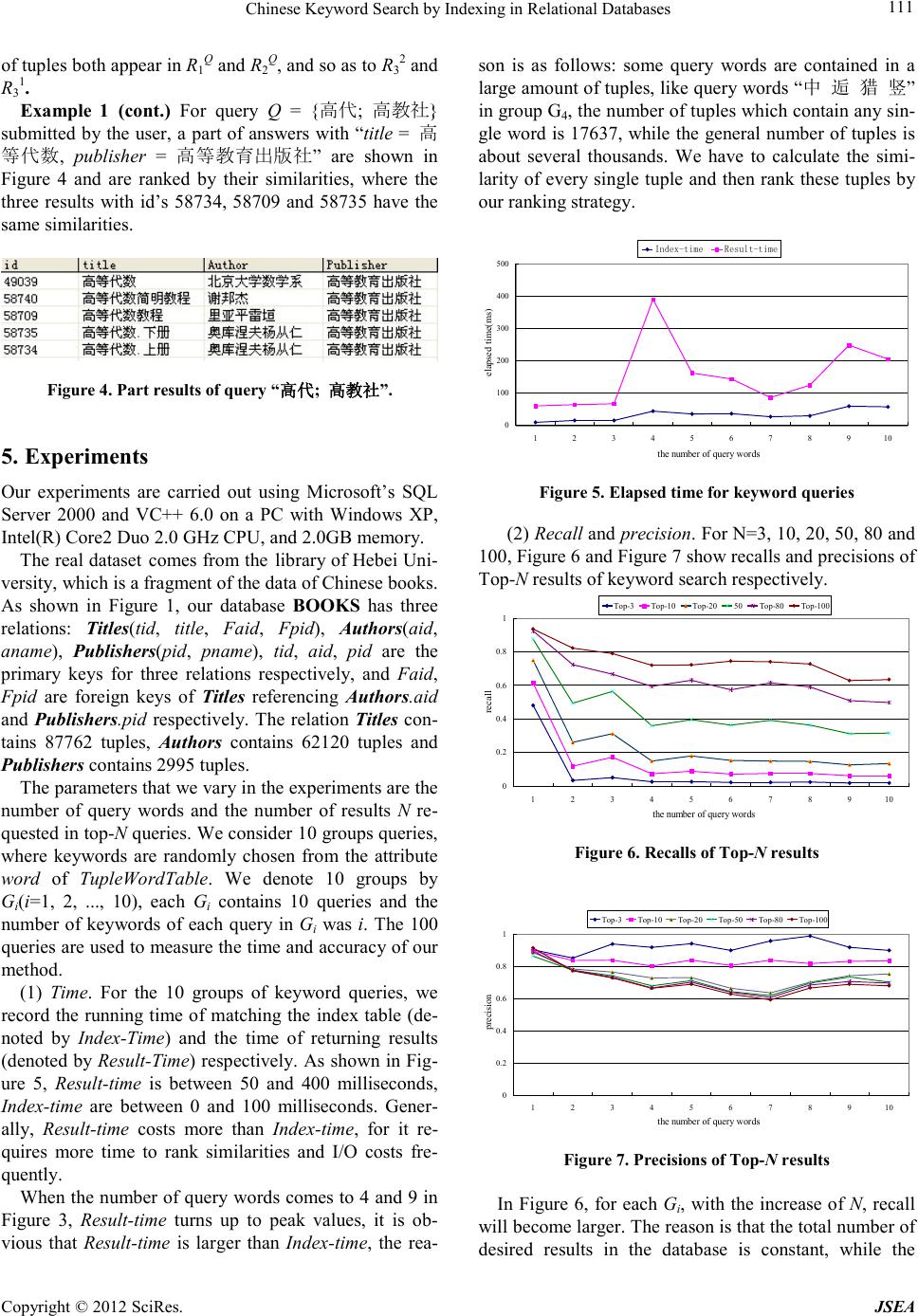 Chinese Keyword Search by Indexin g i n Relational Databases Copyright © 2012 SciRes. JSEA of tup les both appear in R1Q and R2Q, and so as to R32 and R31. Example 1 (cont.) For query Q = {高代; 高教社} submitted by the user, a part of answers with “title = 高 等代数, publisher = 高 等教育出版 社” are shown in Figure 4 and are ranked by their similarities, where the three results with id ’s 58734, 58709 and 58735 have the same similarities. Figure 4. Par t results of query “高代; 高教社”. 5. Experiments Our experiments are carried out using Microsoft’s SQL Server 2000 and VC++ 6.0 on a PC with Windows XP, Intel(R) Core2 Duo 2.0 GHz CPU, and 2.0GB memory. The real dataset co mes fr o m t he library of Hebei Uni- versity, which is a fragment of the data of Chinese books. As shown in Figure 1, our database BOOKS has three relations: Titles(tid, title, Faid, Fpid), Authors(aid, aname), Publishers(pid, pname), tid , aid, pid are the primary keys for three relations respectively, and Faid, Fpid are foreign keys of Titles referencing Authors.aid and Publi shers.pid respectively. The relation Titles con- tains 87762 tuples, Authors contains 62120 tuples and Publisher s contains 2995 tupl es. The parameters that we vary in the experiments are the number of query words and the number of results N re- quested in top-N queries. We consider 10 groups queries, where keywords are randomly chosen from the attr ibute word of TupleWordTable. We denote 10 groups by Gi(i=1, 2, ..., 10), each Gi contains 10 queries and the number of keywords of each query in Gi was i. The 100 queries are used to measure the time and accurac y of our method. (1) Time. For the 10 groups of keyword queries, we record the running time of matching the index table (de- noted by Index-Time) and the time of returning results (denoted by R esult-Time ) respectively. As sho wn in Fig- ure 5, Result -time is between 50 and 400 milliseconds, Index-time are between 0 and 100 milliseconds. Gener- ally, Result-time costs more than Index-time, for it re- quires more time to rank similarities and I/O costs fre- quently. When the number of query words comes to 4 and 9 in Figure 3, Result-time turns up to peak values, it is ob- vious that Result-time is larger than Index-time, the rea- son is as follows: some query words are contained in a large amo unt o f t upl es, li ke q ue ry words “中 逅 猎 竖” in gr oup G 4, the number o f tuples which contain any sin- gle word is 17637, while the general number of tuples is about several thousands. We have to calculate the simi- larity of ever y single tuple and then rank these tuples by our ranking strategy. 0 100 200 300 400 500 12345678910 the number of query words Figure 5. E lapsed time for keyword queries (2) Recall and precision. Fo r N=3, 10, 20, 50, 80 and 100, Figure 6 and F igur e 7 show recalls and precisions of Top-N result s of keyword search respectively. 0 0.2 0.4 0.6 0.8 1 12345678910 the number of query words Top-3 Top-10 Top-20 50 Top-80 Top-100 Figure 6. R e c alls of Top-N result s 0 0.2 0.4 0.6 0.8 1 12345678910 the number of query words Top-3 Top-10 Top-20 Top-50 Top-80 Top-100 Figure 7. Precisions of Top-N results In Figure 6, for each Gi, with the increase of N, recall will become larger. T he reason is that the total number of desired results in the database is constant, while the  Chinese Keyword Search by Indexin g i n Relational Databases Copyright © 2012 SciRes. JSEA 112 number of matching tuple tree in the Top-N results will increase as N becomes larger. For a fixed N, the overall rate of recall will decrease as the number of query words increases. In Figure 7, for each Gi, with the increase N, precision will decrease. When N≥80, the average rates of recalls and precisions are higher than 50% and 60% re- spectively. In addition, according to requirements, all ranke d results may be displayed for a query. 6. Conclusions In this paper, we proposed a new method to realize IR-style free-form Chinese keyword search over rela- tional databases. The basic idea of this method is to create an index by extracting information from relations in a database. For a given query, we use the index to ob- tain the candidate tuples and calculate the similarity of between the query and each candidate tuple through im- proved ranking strategy. The Top-N results are retrieved by SQL selection statements for the natural join of rela- tions in the database. Exte nsive experiments were carried out to measure the performance of our method based on a real dataset. Exper i ment a l r e sult s s how tha t t he a ve rage elapsed ti me including In dex-time and Result-time i s less than 500 milliseconds for queries with 1 to 10 query words. When N≥80, the average recalls and precisions are higher than 50% and 60% respectively. 7. Acknowledgements This work is supported in part by NSFC (61170039) and the NSF of Hebei Province (F2012201006). REFERENCES [1] S. Agra wal, S. Chaudhuri and G. Das, “DBXplorer: A System for Key word-Based Search over Relational Da- tabase,” Proceedings of the 18th International Confe- rence on Data Engineering, San Jose, 26 February -1 March 2002, pp. 5-16. [2] V. Hristidis, L. Gracano and Y. Papakonstantinou, “Effi- cient IR-style Keyword Search over Relational Databas- es,” Proceedings of 29th International Conference on Very Large Data Bases, Berlin, 9-12 September 2003, pp. 850-861. [3] A. Balmin, V. Hristidis and Y. Papakonstantinou: “Ob- jectRank: Authority-Based Keyword Search in Databas- es”, Proceedings of the 30th International Conference o n Very large Data Bases, Toronto, 31August-3September 2004, pp. 564 – 575. [4] Q. Vu, B. Ooi, D. Papadias and A. Tung, “A Graph Me- thod for Keyword-Based Selection of the Top-K Data- bases,” Proceedings of the ACM SIGMOD International Conference on Management of Data, Vancouver, 10-12 June 2008, pp. 915-926. [5] F. Liu, C. Yu and W. Meng, A. Chowdhury, “Effective Keyword Search in Relational Databases,” 26th ACM SIGMOD/PODS International Conference on Manage- ment of Data/Principles of Database Systems, Chicago, 27-29 June 2006, pp. 563-574. [6] L. Qin, J. Yu and L. Chang, “Keyword Search in Data- bases: The Power of RDBMS,” Proceedings of the 2009 ACM SIGMOD International Conference on Manage- ment of data, Rhode Island, 29 June-2 July 2009, pp: 681-694. [7] J. Yu , L. Qi n and L. Chang, “Keyword Search in Rela- tional Databases: A Survey,” IEEE Data Eng. Bull. Spe- cial Issue on Keyword Search, Vol. 33 No .1, 2010, pp. 67–78. [8] L. Zhu, Q. Ma and C. Liu, “Semantic-Distance Based Evaluation of Ranking Queries over Relational Dat abas- es,” J. Intell. Inf. Syst, Vol. 35 No. 3, 2010, pp. 415-445. doi: 10.1007/s10844-009-0116-5. [9] L. Zhu, Y. Zhu and Q. Ma, “Chinese Keyword Search over Relational Databases,” 2010 Second World Con- gress on Software Engineering, Wuhan, 19-20 December 2010, pp . 217-220. [10] A. Singhal, “Modern Information Retrieval: A Brief Overview,” IEEE Data Eng, Vol. 24, No. 4, 2001, pp. 35- 43. [11] A. Singhal, C. Buckley and M. Mitra, “Pivoted Document Length Normalization,” Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Zurich, 18-22 August 1996, pp. 21-29.
|