 A Journal of Software Engineering and Applications, 2012, 5, 88-93 doi:10.4236/jsea.2012.512b018 Published Online December 2012 (http://www.scir p.org/journal/jsea) Copyright © 2012 SciRes. JSEA Evaluating Relational Ranking Queries Involving Both Text Attributes and Numeric At t ri b u t es Liang Zhu1, Zhaoliang Xie1, Qin Ma2 1Key Laboratory of Machine Learning and Computational Intelligence, School of Mathematics and Computer Science, Hebei University, Baoding, Hebei 071002, China; 2Department of Foreign Language Teaching and Research, Hebei University, Baoding, Hebei 071002, China Email: zhu@hbu.edu.cn, xiezhaoliang533@163.com, maqin@hbu.edu.cn Received October 12, 2012 ABSTRACT In many database applications, ranking queries may reference both text and numeri c attr ib utes, whe re t he ra nki ng f unc- tions are based on both sema ntic distance s/similarities for text attributes and numeric d istances fo r numeric attributes. In this paper, we propose a new m eth od for evaluating such t yp e o f ranking queries over a relational database. By statis tic s and training, this method builds a mechanism that combines the semantic and numeric distances, and the mechanism can be used to balance the effects of text attributes and numeric attributes on matchin g a give n query a nd tuple s in da- tabase search. The basic idea of the method is to create an index based on WordNet to expand the tuple words semanti- cally for te xt attribute s and on the i nformation o f numeric attributes. The ca ndidate results for a query are retrie ved by the index and a simple SQL selection statement, and then top-N answers are obtained. The result s of extensive experi- ments indica te that the performance of this new strategy is efficient and effective. Keywords: Relational Datab ase; Ranking Query; Sema ntic Dista nce; N umeric Distance; WordNet 1. Introduction A r elati onal ran king q uer y (or top-N query) is to find the N tupl es that satisf y the quer y cond ition t he best but not necessarily completely, and the results are sorted ac- cording to a given ranking function. Researches on top-N queries have intensified since late 1990s [1-3], and most of the researches involve numeric attributes and use a numeric distance function (say, Lp-norm dis- tances, p =1 , 2 , and ∞) to reduce a massive result set of a conventional query to a few of the most relevant an- swers . However, there are many applications where ranking queries involving both text attributes and nu- meri c attributes are available for processing. Example 1. Consider a database of used books with schema: Books(id#, title, pr i ce, year,…). Suppose a customer wants to buy a used book with title on “film”, price around “$50” and year about “2000”, where title is a text attribute with semantics, and pri ce and yea r are two numeric attributes. Obviously, a book on “algebra” with price = “$50” and year = “2000” is not the desired result for the cus tomer though the values for pric e and year exactly match that of the query respectively. Another book on “movie”, however, with pri ce = “$53” and year = “2001” maybe satisfy the need of the cus- tomer . Ipum99 Occ50 idx A29 A40 A50 num occ50 87197 42 2 20000 2 Airplane pilots and navigators 6505 28 3 25000 3 Architects 80789 51 930 33000 930 farm, and 10860 9 999 999999 999 N/A (blank) Figure 1 . Parts of IPUMS Census Database. Exa mple 2. As shown in F igure 1, database IPUMS has two relations Ipum99 and Occ50, which come from [4]. In relation Occ50(num, occ50), its primary key num is the value label of occ upation1950. Relatio n Ipum99 has 61 nu meric attributes where A29 is age, A50 means income, and A40 is the foreign key referencing Occ50.num. Furthermore, Ipum99 is added an attribute idx by us as ide nti fier . A user is looking for the informa- tion of “a horticultu rist with age about 50” from IPUMS. Since there is no such word “horticulturist” in Occ50.occ50, the answer will be nothing by using the  Evaluating Relational Ranking Queries Involving bot h Text Attributes and Numeric Attributes Copyright © 2012 SciRes. JSEA traditional SQL selection statement. In fact, there is a tuple (“Gardeners, except farm, and groundskeepers”, age = 51, …) (with gray color) in IPUMS may be an answer for the user. Word Ne t::Similarity [5] is an open source Perl mod- ule for measuring the semantic distance/similarity be- tween two words; however, it is not easy for us to use the source dir e ctly to evaluate ranking que ries [6]. Researches on semantic search in IR and SW (sema n- tic web) have gained attention since 1990s. Taking the- saurus ontol ogy na vigati on as a step i n query expansion, many query expansion techniques are employed in key- word search, say, query ter ms are expanded to WordNet synonyms and meronyms, using the Boolean OR opera- tions available i n most web search engines [7]. Different from the above query expansion techniques in IR and SW, we discuss semantic match between query words and tuple words in relational databases via tu p le expan- sion. In recent years, ontologies have been used to build applicatio ns in database com munity [8, 9]; however, it i s a challenging jo b to construct efficient ontologies [9, 6]. Our method is different from the ontology-based tech- niques. Firstly, instead of dealing with the challenge of constructing ontology, we create a simple table main- tained by RDBMS, and store information of index and ranki ng funct ion into the table. Secondly, our strategy is more general since it is based on WordNet. Finally, our techniques are more efficient than the above ontolo- gy-based methods due to the efficiency of RDBMS. Another different yet related research topic is key- word search in relational databases [10-12], which sup- ports free-form keyword search in relational databases without necessarily requiring the users to know the da- tabase schema. Keyword search may be suitable for any text attribute, but it is exact search without dealing with semantic match. For instance, it cannot return the books on “movie” for the quer y keyword “film”. If query words match exactly tuple words, the results of semantic search will contain those of keyword search, and improve the effecti v eness of keyword search b y us ing our metho d. There are t wo challe n gi ng p ro b lems for evaluating the type of relatio nal ranking queries i n this p aper. The first is how to design a good semantic distance function that measure the semantic simila r ity between the query words and the tuple words, [6] presented a solution for this problem. The second is how to combine the seman- tic and numeric distances. We empl oy statistics and training to solve the problem, and create an index to process ranking queries in terms of semantic and nu- meric matching in database search. Moreover, this work is a continuation of the work in [6], which studied the processing of rela tional ranking queries only with text attributes, witho ut numeric attr ibutes. 2. Problem Definition and Ranking Function Assume that R0(idx, A, B1, B2, …, Bm, …) is a relation with identi fier idx, where A is a text attribute with natu- ral l angua ge semantics and B1, B2, …, Bm are m numeric attributes. Using the project operatio n π A(R0) (duplicate tuples are eliminated), we get a new relation R(tid, A) with ident ifie r tid. Furthermore, R0 is added by an attribute FKid that is the foreign key referencing R.tid, and the n the schema of R0 becomes R0(idx, A, B1, B2, …, Bm, …, FKid). Or, let R(tid, A) and S(idx, B1, B2, …, Bm, …, FKid) be two relations and S.FKid be the fore ign key referencing R.tid, then R0 = R S with S.FKid = R.tid. Let t be a tup le in R0, then t[A] = (tw1, tw2, …, twn) is the word -stri ng with n wor ds o n the te xt attribute A, a nd t[Bj] = bj is the numeric value on t he attribute Bj (1 ≤ j ≤ m). For simplicity, we de note t = (tA, b1, b2, …, bm) where tA = (tw1, tw2, …, twn), and call twi a tuple word and bj a tuple value (1 ≤ i ≤ n, 1 ≤ j ≤ m). As defined in [6], given a tuple word w, its kinship words include the five kinds of words in WordNet: (1) word w itself, (2) morph, (3) synonyms, (4) the imme- diate hyponyms (subordinates), and (5) the immediate hypernyms (superordinates). The s et of all kinship wo rds of w is denoted by K(w). For instance, the kinship word set of “computers” is K(computers) ={computers, com- puter, data processor, machine, internet site, calcula- tor, …}. Consider a ranking query q = (qA, q1, q2, …, qm), where qA = (qw1, qw2, …, qwk) is a wo rd-st ring with k query words, and qj is a numeric value (1 ≤ j ≤ m). For tuple t = (tA, b1, b2, …, bm) in R0, denote pj = |qj − bj| (1 ≤ j ≤ m), and dA = d(qA, tA) that is the se man tic distance between qA and tA defined by Definition 1 to 3 in [6]. Moreover, dA belongs to the interval (0, 1]. We need to find a mechanism c o mbi ni ng t he s e ma nti c and numeric distances dA and pjs, which can be used to evaluate the query q over the relation R0, i.e., to define a ranking function d(q, t ) = ψ (dA, p1, p2, …, pm). Intuitively, the ranking function d(q, t) should satisfy the fo llowing: First, a smaller d(q, t) indicates closer the pair (q, t). Second, d(q, t) needs to balance the effects of dA and pjs i n matc hi ng q wit h t. Finall y, it sho uld be easy to implement. To obtain d(q, t), we use the statistics of the domain s of B1, B2, …, Bm and training. Since the semantic di stance dA ∈ (0, 1], we normalize it by scientific notation, dA = α ×10 − h, where 1.0 ≤ α <10.0, and h is a no nnegative number (i.e., h≥ 0, if h = 0,  Evaluating Relational Ranking Queries Involving both Text Attributes and Numeric Attributes Copyright © 2012 SciRes. JSEA 90 we define −0 = 0), say, dA = 0.001041 = 1.041×10 − 3. W e will see that h (the ab solute value of the expo nent) p lays an important r ole in the ranking function d(q, t). In collecting statistics, there is a step of cleaning data and removing outlier, and then we get Min(Bj) and Max(Bj) of numeric attribute Bj (1 ≤ j ≤ m). Based on the semantics of attribute Bj, we obtain its reasonable unit Zj >0, say, Zyear= 1 for attrib ute year and Zprice = 0 .01 for price respectively in database BOOK. Let Mj = Max(Bj) − Min(Bj) = β j × 10 , where 1.0 ≤ β j <10.0 (Mj ≥ 0, obviously. If Mj = 0, let Mj := Zj then Mj > 0 ). If Mj ≥ 1, we have cj ≥ 0, else if 0<Mj <1, let Mj := Mj /Zj, and pj:= pj /Zj, then Mj ≥ 1 and cj ≥ 0. Let ej := cj + 1 ≥ 1, for 1 ≤ j ≤ m. By using the sta tis- tics and t rainin g in our experiments, we obtain the rank- ing function d(q, t) = ψ (dA, p1, p2, …, pm) below. d(q, t) = dA + Σ (pj/Mj) For example, in our experiments for relation Books (title, price, year,…) with 56180 tuples. price is in (0, 1000] (except 633 tuples with price > 1000), and year belongs to [1958, 2008] (except 651 tuples with year < 1958). Let attribute A, B1 and B2 be title, price and year respectively, then M1 = 1000 − 0 = 1000 = 1.0 ×103, M2 = 2008 − 1958 = 50 =5.0×101, and the n c1 = 3, c2 = 1, e1 = c1+1 = 4 and e2 = c2+1=2. Thus, d(q, t) = dA + ( p1/1000)h/4 + (p2/50) h/2. For query q, we will return dis-N tuples defined in [6] to replace top-N ones. Let T be a set of tuples, a tuple t∈T is called a dis-N tuple of q, if d(q, t) ≤ minN {d(q, ti) | ti ∈T}, whic h means the Nth minimum value in the set {d(q, ti) | ti ∈T }. 3. Creation of sn-Index We extend w-index in [ 6] to sn-index ( stand s for seman- tic and numeric index) in t his s ection. 3.1. Information Stored in sn-Index A relation is employed to store the information in sn-index, which is called IndexTable with schema In- dexTable(id#, Word, Size, dbNSize, DBValue, BValue, bSize), say, (2490, nights, 2, 2, '47898,0,3,1;2413,0,…', '47898,8185,10.80,1997;…', 3) is a tuple in IndexTable for database BOOK. The attribute Word indicates the kinship word of tuple words, and the relevant information will be stored in the attribute DBValue. The value of DBValue is a string wi th f orm “ tid,d,n ,f ;tid,d,n,f;…;” where “tid,d,n , f ;” is a node, d = 0 , 1 , . . . , 5 , “d = i” is the subscript i of s eman- tic distance di defined by Definition 1 in [6] , n is the number of tuple words in the tuple with tid, and f is the frequency in the set of kinship words of the tuple. The attribute Size is the number of tids associated with kw, and the duplicate tids are counted repeatedly. The attribute dbNSize means the number of nodes in DBVa- lue. Attribute BValue is a string as “tid,id x , b1,b 2,…,bm; tid,idx,b1,b2,…,bm;…;”, where “ tid,idx, b 1,b 2,…,bm;” is a node, tid is the identifier of a tuple in the relation R(tid, A), and idx is that in R0(idx, …). The attrib ute bSize means the number of nodes in BValue. 3.2. Procedure of Creating sn-Index Reconstructing w-index in [6], we obtain sn-index as sho wn i n Figure 2. Sn -index consists of four parts: (1) a hash table wi th a hash function h(), its each bucket con- tains a pointer pWnPointer which points to a node in wn-list; (2) one wn-list, its node has struc ture {iRow, kw, size, dbNSize, bSize, pDBList, pBList}; (3) s db-lists, the structure of the node is {tid, d, n, f}; (4) s b-lists, node structure {tid, idx, b1, b2, …, bm}. The main difference between sn-index and w-index in [6] is that b-lists (i.e., Bij’s in Figure 2) are added. The algorithm of creating sn-index is sho wn as follows: D 11 ^ B 11 ^ D 21 ^ B 21 ^ Ds1 ^ B s1 ^ D 12 D 22 Ds2 B 12 B 22 B s2 ^ ^ ^ ^ ^ ^ W 1 ^ W 2 W s ^ . . . …… …… … … … hash tablewn-list db-list and b-list Figure 2. Structure of sn-index. Step 1. For the special character string tA = (tw1, …, twn), calculate its hash value h=h(tA); check the pointer pWnPointer in the bucke t of t he hash t able , and wn-list, (1) If pWnPointer is NULL, or (tw1, …, twn) is not in wn-list, (a) Create a new db-list, and a dbNode as tid = tA.tid, d := −1 (means the special case), n := 1 and f :=1. Insert the dbNode into the db-list. (b) Using tid above, search (idx, b1, b2, …, bm) from R0 (or from S) b y the fol l o win g the SQ L selection statement Select idx, B1, B2, …, Bm from R0 where FKid = tid  Evaluating Relational Ranking Queries Involving bot h Text Attributes and Numeric Attributes Copyright © 2012 SciRes. JSEA Let z be the size of the result set {(idx, b1, b2, …, bm)}, Create a new b-list, and z bNode(s), insert the bNode(s) into the b -list. (c) Create a wnNode for wn-list, kw:= (tw1, …, twn), and dbNSize:=1 and bSize:= z. Insert the wnNode into wn-list according to t he alphabet order of kw. (d) Get the pointers pDB L i st, pBList and pWnPointer. (2) Else if the string t is found out in wn-list, then in- crease dbNSize by 1 in the wnNode with t, create a dbNode as above, and let it be the first node of the db-list. Additionally, by the SQL selection statement as (b) above, get a result set {(idx, b1, b2, …, bm)} with siz e z ≥ 1. Create z bNode(s), in- sert the node(s) into the b-list, and increase bSize by z. Step 2. For each tuple word twi ∈ t, and eac h kinship word kw of twi, get h=h(kw), check pWnPointer in the bucket of the hash table, and wn-list, (1) If pWnPointer is NULL, or kw is not in wn-list, do the same jobs as the above (1) in Step1 ex- cept for replacing tA by kw and defining d = k, k ∈ {0, 1, …, 5} such that dk is d(kw, twi) in De- finition 1 in [6]. (2) Else if kw has be en in wn -list, then get its db -list and b-list. There are two cases. Case 1, in the db-list, there is a dbNode with dbNode.tid = t.tid, replacing d by the smaller if the two distances are different, and increasing f by 1, that is OK. Case 2, if no dbNode in the db-list satisfies dbNode.tid = t.tid, increase dbNS i ze by 1 in the wnNode with kw, creat e and insert a new dbNode into the db-list according to the increasing order of distance d. In addi- tion, by the SQL selection statement as (b) above, get a result set {(idx, b1, b2, …, bm)} with size z ≥ 1. Create z bNode(s), insert the node( s) into the b -li s t , and bSize:= z. Step 3. Storing sn-index. To evaluate query q, we use two storing strate g ie s. Strategy-1, the entire sn-index is in main memory. Strategy-2 will store db-lists and b-lists in fixe d d i sk a nd only load the hash table and wn-list into main memory. 4. Evaluation of Ranking Query For query q = (qA, q1, q2, …, qm), firstly, matching the query words with kinship words of R(tid, A) via sn-index, we obtain the set T (= {tid}) of identifiers of candidate tuples, and compute the semantic distances between q and its candidate tuples, and then ge t the set L of information of numeric attributes by each identifier tid in T; secondly, compute d(q, t) = ψ (dA, p1, p2, …, pm) between q and each of its cand idate tuples, and then ob- tain {idx}, which is the sorted set of identifiers of dis-N results according to d(q, t); finally, we retrieve the dis-N tupels from underlying database and display the ranked answers. To get the set T is an important step for query processing. The intermediate results are stored in a tem- porary list, denoted by T-List. Its node has the structure {tid, d[K], dA} where K is the maximum number of query words for qA = (qw1,…, qwk). If k > K, let qA = (qw1, …, qwK) (K = 30 in our implementatio n s). The intermediate results for obtaining set L are saved in a temporary list L-List, and the str uct ur e of i ts node is {dA, p1, p2, …, pm, d, tid, idx} We discuss Strate g y-2 of storage first (i.e., we only load the hash tab le and wn-list in main memory). (1) No r malization of qA. We remove some symbols, character strings or stop words, and replace some of them by normal strings for qA. Denoted again by qA = (qw1, …, qwk). (2) For each qwi ∈ qA (i= 1, …, k), calculate hash value h=h(qwi), and check qwi in wn-list. If qwi is found out, we get the wnNode in wn -lis t, and t he n use the SQ L selection statement select ∗ from IndexTable whe re id# = wnNode.iRow to obtain dbNode(s). For each dbNode, we save the val- ues i nto T-List , and co mpute dA= d(qA, tA), then obtain T. (3) If above T≠∅, for each tid∈T, we get its corres- ponding bNode(s) by using select statements from In- dextable, store them into L-List, compute d := ψ (dA, p1, …, pm), and then obtain the set L (={idx}) of candi- date dis-N tuple identifiers. (4) Given a po sitive inte ger N, we get the set of dis-N tuple identifiers LN ⊆ L; then, we ob tain t he d is-N tuples of the query q by using the SQL selection sta tement as the followin g format: Select R0.*, R.A from R0, R where (R0.FKid = R.tid) and (R.idx in LN) and … (5) Display the dis-N tuples sorted by d(q, t). Next, we discus s Strategy-1 of stor age, i.e., t he entire w-index is saved into main memory. The query processing is similar to the above situations, except for steps (2) and (3), we can get dbNode(s) and bNode(s) from sn-index directly, without using select statements. Thus, the response time of Strategy-1 will be smaller than that of Strategy-2. Example 2 (cont.). For the dis-5 query “a ho rticu l- turist with age=50 and income=30000” against IPUMS, the answers with f o rm (idx, tA, age, income, d(q, t)) are t1: (80789, tA, 51, 33000, 0.609496), t2: (07296, tA, 48, 25000, 0.729997), t3: (77380, tA, 37, 30600, 0.747815), 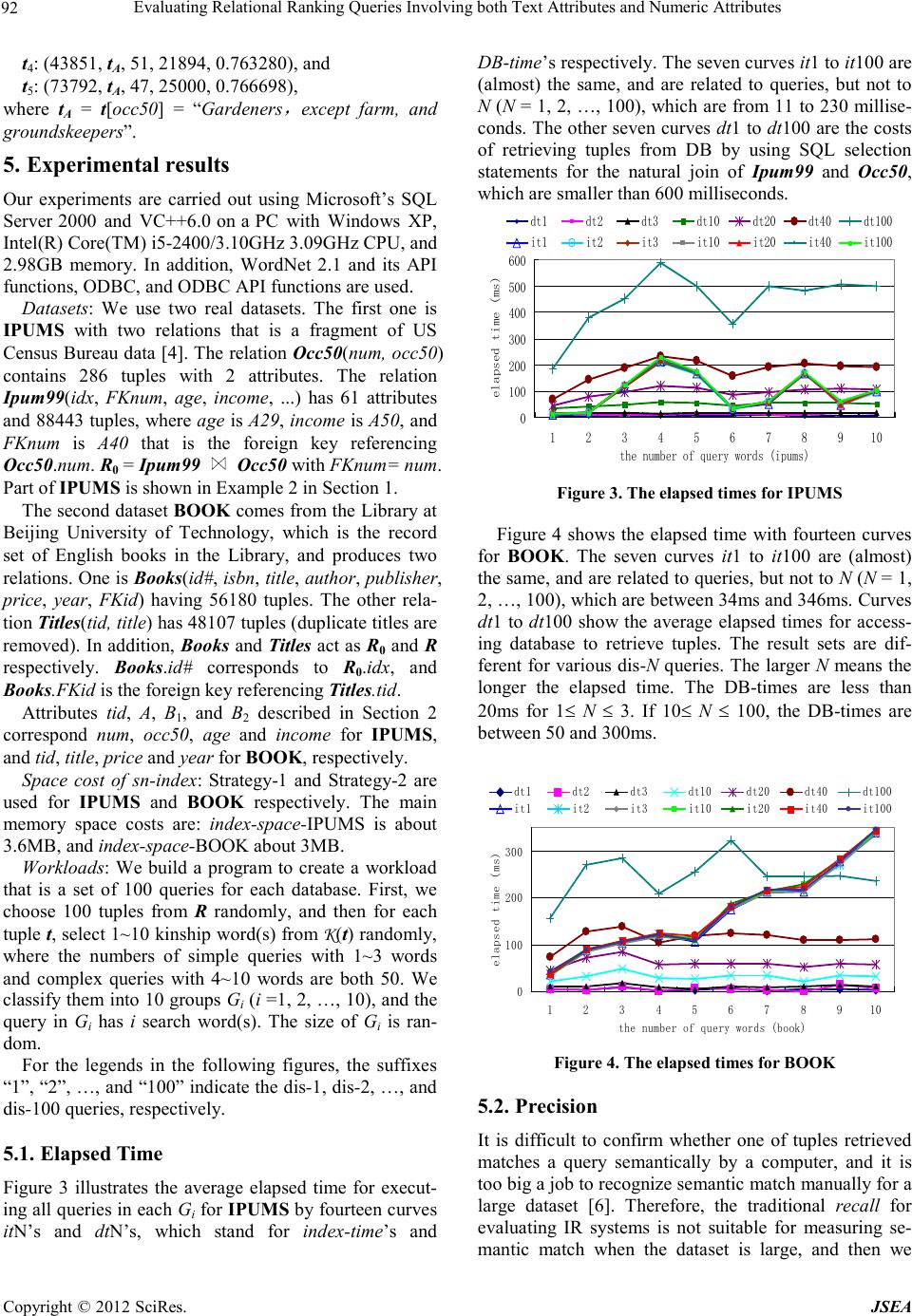 Evaluating Relational Ranking Queries Involving both Text Attributes and Numeric Attributes Copyright © 2012 SciRes. JSEA 92 t4: (43851, tA, 51, 21894, 0.763280), and t5: (73792, tA, 47, 25000, 0.766698), where tA = t[occ50] = “Gardeners , except farm, and groundskeepers”. 5. Experimental results Our experiments are carried out using Microsoft’s SQL Server 2000 and VC++6.0 o n a P C with Windows XP, Intel(R) Core(TM) i5-2400/3.10GHz 3.09GHz CPU, and 2.98GB memory. In addition, WordNet 2.1 and its API functi ons, ODBC, and OD BC API functions are use d. Datasets: We use two real datasets. The first one is IPUMS with two relations that is a fragment of US Censu s Bureau data [4]. T he relation Occ50(num, occ50) contains 286 tuples with 2 attributes. The relation Ipum99(idx, FKnum, age, income, ...) has 61 attributes and 88443 tuples, where age is A29, income is A50, and FKnum is A40 that is the foreign key referencing Occ50.num. R0 = Ipum99 Occ50 with FKnum= num. Pa rt of IPUMS is shown in Example 2 in Section 1. The second dataset BOOK comes from the Library at Beijing University of Technology, which is the record set of English books in the Library, and produces two relations. One is Books(id#, isbn , title, author, publisher, price, yea r, FKid) having 56180 tuples. The other rela- tion Titles(tid , title) has 48107 tuples (duplicate titles are removed). In addition, Books and Titles act as R0 and R respectively. Books.id# corresponds to R0.idx, and Books.FKid is the foreign ke y referencing Titles.tid. Attributes tid, A, B1, and B2 described in Section 2 correspond num, occ50, age and income for IPUMS, and tid , title, price and year for BOOK, respectively. Space cost of sn-index: Str ate g y-1 and Strateg y-2 are used for IPUMS and BOOK respectively. The main memory space costs are: index-space-IPUMS is about 3.6MB, and index-space-BOOK about 3MB. Workloads: We build a program to create a workload that is a set of 100 queries for each database. First, we choose 100 tuples from R randomly, and then for each tuple t, select 1~10 kinship word (s) from K(t) randomly, where the numbers of simple queries with 1~3 words and complex queries with 4~10 words are both 50. We classify t hem int o 10 groups Gi (i =1, 2, …, 10 ), and the query in Gi has i search word(s). The size of Gi is ran- dom. For the legends in the following figures, the suffixes “1”, “2”, …, and “100” indicate the dis-1, dis-2, …, and dis-100 queries, respectively. 5.1. Elapsed Time Figure 3 illustrates the average elapsed time for execut- ing all queries in eac h Gi for IPUMS by four teen curves itN’s and dtN’s, which stand for index-time’s and DB-time’s respectively. The seven curves it1 to it100 are (almost) the same, and are related to queries, but not to N (N = 1, 2, …, 100), whic h are from 11 to 230 millise- conds. The other seven curves dt1 to d t100 are the costs of retrieving tuples from DB by using SQL selection statements for the natural join of Ipum99 and Occ50, which are smal l er than 600 milliseconds. 0 100 200 300 400 500 600 12345678910 the number of query words (ipums) dt1 dt2 dt3 dt10 dt20 dt40 dt100 it1 it2 it3 it10it20it40it100 Figure 3. The elapsed times for IPUMS Figure 4 shows the elapsed time with fo urteen curves for BOOK. The seven curves it1 to it100 are (almost) the same, and are related to queries, b ut not to N (N = 1 , 2, …, 100), which are between 34ms and 346ms. Curves dt1 to dt100 show the average elapsed times for access- ing database to retrieve tuples. The result sets are dif- ferent for various dis-N queries. The larger N means the longer the elapsed time. The DB-times are less than 20ms for 1≤ N ≤ 3. If 10≤ N ≤ 100, the DB-times are between 50 and 300ms. the number of query words (book) dt1 dt2 dt3 dt10dt20dt40 dt100 it1it2it3it10it20 it40 it100 Figure 4. The elapsed t imes for BOOK 5.2. Precision It is difficult to confirm whether one of tuples retrieved matches a query semantically by a computer, and it is too big a job to recognize se mantic match manuall y for a large dataset [6]. Therefore, the traditional recall for evaluating IR systems is not suitable for measuring se- mantic match when the dataset is large, and then we  Evaluating Relational Ranking Queries Involving bot h Text Attributes and Numeric Attributes Copyright © 2012 SciRes. JSEA report only precision . Figures 5 and 6 illustrate the av- erage precision for IPUMS and BOOK respective ly. We can see that a smaller N has a larger precision; therefore, a smaller N indicates more matching tuples appear in its dis-N results. The precisions for IPUMS are 1, 0.93, 0.90, 0.73, 0.62, 0.5 2, and 0.44 for N = 1, 2, 3, 10, 20, 40, and 100, respectivel y. The precisions for BOOK are 0.93, 0.86, 0.78, 0.63, 0.55, 0.45, and 0.34 for N = 1, 2, 3, 10, 20, 40, and 100, respectively. 0 0.2 0.4 0.6 0.8 1 12345678910 the number of query words (ipums) Figure 5. Precisions for IP U MS 0 0.2 0.4 0.6 0.8 1 12345678910 the number of query words (book) Figure 6. Precisions for BOOK 6. Conclusions We proposed a new method to evaluate relational ra nk- ing queries that reference both text attributes and nu- meri c attributes. The meth od builds a ranking function combining the semantic and numeric distances, and creates an index based on WordNet to expand the tuple words semantically for a text attribute and on the infor- mation of numeric attributes. Thus, the results for a query are retrieved by the index and a simple SQL se- lection statement for the natural join of relations, and ranked accord ing to the ranking function. We conducted extensive experiments to measure the performance of this new technique using two real datasets. The results of experiments demonstrated that our strategy is efficient and e ffective. 7. Acknowledgements T hi s wo r k is supported in part by NSFC ( 61170039) and the NSF of Hebei Province (F2012201006). The authors would also like to express their gratitude to Professor Weiyi Meng for providing many helpful suggestions. REFERENCES [1] M. Carey, and D. Kossmann, “On saying ‘enough al- read y!’ in SQL,” SIGMOD 1997 Proceedings ACM in- ternational conference on management of data, Vol. 26 No. 2, 1997, pp. 219-230. [2] I. F Ilyas, G. Beskales, and M. A. Soliman, “A survey of top-k query processing techniques in relational database s yst em s,” ACM Computing Surveys, Vol. 40, No. 4, 2008, Article 11. [3] L. Zhu, W. Meng, C. Liu, W. Yang, and D. Liu, “Processing top-N relational queries by learning,” Jour- nal of Intelligent Information Systems. Vol.34, No.1, 2010, pp.21-55, doi:10.1007/s10844-009-0078-7. [4] IPUMS Census Database, “ipums.la.99.gz”, 1999, http://kdd.ics.uci.edu/databases/ipums/ipums.html [5] T. Pedersen, “WordNet::Similarity,” 2008, http://www.d.u mn.edu/~tpederse/similarity.html [6] L. Zhu, Q. Ma, C. Liu, G. Mao and W. Yang. “Seman- tic-distance based evaluation of ranking queries over re- lational databases,” Journal of Intelligent Information Systems, Vol. 35, No. 3, 2010, pp. 415-445. [7] D. Buscaldi , P. Rosso, and A. E. Sanchis, “A word- net-based query expansion method for geographical in- formation retrieval,” Working Notes for the CLEF Workshop, Vienna Austria, 2005. [8] S. Das, E. Chong, G. I. Eadon, and J. Srinivasan, “Sup- porting ontology-based semantic matching in RDBMS,” Proceedings of the Thirtieth International Conference on Very Large Data Bases (VLDB ’04), Toronto, Canada, 2004, pp. 1054-1065. [9] J. Zhang, Z. Peng, S. Wang and H. Niehang, “Si-SEEKER: Ontology-based semantic search over da- tabases,” Knowledge Science, Engineering and Man- agement, Guilin, China, Vol. 4092, 2006 , pp. 599-611. [10] V. Hristidis, L. Gra vano, and Y. Papakonstantinou, “Ef- ficient IR-style keyword search over relational databas- es,” In Proceedings of 29th International Conference on Very Large Data Bases (VLDB’03), Berlin, Ger many, 2003, pp. 850-861. [11] F. Liu, C. Yu, W. Meng and A. Chowdhury, “Effective Keyword Search in Relational Database,” 26th ACM SIGMOD/PODS international Conference on Manage- ment of Data/Principle of Database Systems, Chicago, Illinois , USA, 2006, pp. 563-574. [12] L. Zhu, Y. Zhu, and Q. Ma, “Chinese Keyword Search over Relational Databases,” World Conference on Science and Engineering (WCSE), Wuhan, China, Vol. 1, 2010, pp. 217 – 220.
|