Paper Menu >>
Journal Menu >>
 Technology and Investment, 2013, 4, 27-30 Published Online Febr uary 2013 (http://www.SciRP.org/journal/ti) Copyright © 2013 SciRes. TI Based on ODE and ARIMA Modeling for the population of China Xiaohua Hu, Min Yu School of Mathematics and Statistics, Hainan Normal University, Haikou, China Email: 1241957415@qq.com Received 2012 ABSTRACT The economic data usually can be also composed into a deterministic part and a random part. We establish ordinary differential equations (ODE) model for the deterministic part from a purely mathematical point of view, via the prin- ciple of integral and difference, establishing ()ARIMAp dq,, model for the random part, to combine the two estab- lished models to predict and control the original series, then we apply the method to study the population of China from 1978 to 2007, establishing the corresponding mathematical model, to obtain the forecast data of the population of China in 2008(1.3879503 billion), finally we make further stability analysis. Keywords: Natural Asse t; Financial Value; Neural Network 1. Introduction A lot of time series (as economic data) can be regarded as a discretization of continuous-time process. if a time series Y possesses biology back gr o und , we can establish a differential equations model for Y in accordance with the growth rate, for example, suppose that constant L is the growth limit of the variable Y , the rate of growth dY dt/ is proportional to Y or LY− ; suppose that the relative rate of growth ()dY dtY// is proportional to ()LY L−/ or ln lnLY− ; some simple growth models can be established respectively, such as the Logistic model, Gompertz model[1] and so on, they are called the growth mechanism models. In general, a time series 01 t Qt n,=, ,...,, can be decom- posed into two parts[2]: a deterministic part t F and a random part 01 t ht n,=, ,..., , or 01 t tt Q Fhtn=+,=, ,..., (1) where t F is usually described by the trend, seasonal and cyclic term, and t h is described by a more complex sto- chastic approach. In this paper, we ignore specific eco- nomic backgrounds of variable, from a purely mathe- matical point of view, to establish differential equations model for the discrete-time series t F on some condi- tions, while t h can be described by ()ARIMAp dq,, model[3]. 2. Principles or technology of d ifferential equations modeling Suppose that ()0yt t,≤< +∞ , is a continuous function, t F is regarded as the discretised value of ()yt . Set 0 () ()() t X tytdtytt= ≈∆ ∑ ∫ ()()( ()())X tytXttXtt ′=≈+∆ −/∆ , as t∆ is small. Now let’s consider the discrete case (time series) and let 1t∆= (unit time). It follows that ()()()()( 1)()XtytX tytXtXt ′ ≈,=≈ +− ∑ Denoting that () () tt yytXX t= ,= , if given a original time series ()01 t yyt tn=,=, ,..., ,its cumulative sum series t X can be generated as 0 01 t tk k Xytn = =,=, ,..., ∑ ,so that, if we can find the relationship between the original series t y and its cumulative sum series t X as below, () 001 t tt Fy Xtn ε ,,= ,= ,,..., where t ε is a residual term, a random variable, sati sfie s 2 () 0()0 tt ED εε σσ =,= ,> .We now vi e w () ()ytX t, as continuous, because of () ()X tyt ′= , ignoring t ε , cor- responding to the one-order differential equation model can be established as follows. ( ()())0()(())FXtX torXtf Xt ′′ ,= = (2) We just need to solve out ()Xt from (2), so, 0 ()()( 1)()(0)(0) t yyt XtXtXty yX ′ ==≈+−, ==, . 1tmm n= ,...,.≥ ( whe re m is a positive integer) .  X. HU, M. YU Copyright © 2013 SciRes. TI In the same way, ()01 t XXt tn=,=, ,...,. is viewed as a new time series, we can generate its cumulative sum se- ries () ()Zt Xt=∑ , or, the second cumulative sum of t y ,denote () t Z Zt= . ( )()(1)()Z xXtZtZt ′=≈ +− .we consid- er to establish the relationship of three series t tt yXZ ,,, if there exists the relationship as follows () 001 tt tt Fy X Ztn ε ,,,= ,=,,..., where t ε is the same with the previously mentioned. We now view () ()ytX t, as a continuous case, because of ()() ()ZtX tyt ′′ ′ = = , ignoring t ε ,the two-order differen- tial equation model can be established. (()() ()) 0 ()( ()()) FZtZtZt orZtfZ tZt ′′ ′ ,, = ′′ ′ = , (3) we just need to solve out ()Zt from (3), so, ()()(1)() ()()(1)() (0)(0)(0) 1 t t XXt ZtZtZt yyt Xt XtXt yXZtmm n ′ ==≈ +−, ′ ==≈+−, ==,= ,...,.≥ . In a general way, suppose that the original time series is 0 ()Xt . If 0 ()Xt is not pure random data, its value ’s change on unit time is not random, or data has a trend. its the first cumulative sum series is 1 ()Xt , ..., the p -th cu- mulative sum series is ()1 p X ttn,= ,..., ,where p is a positive integer, if we can find the relationship of 01 () ()() p XtXtX t, ,..., as belo w 01 (()()())001 pt FXtX tXttn ε ,,...,,= , =,,..., where t ε is the same as previous, ignoring t ε ,the p -order differential equation model can be established. 1 1 ()() () (( ))0 pp p pp p pp dXtd XtdXt F Xt dt dtdt − − ,,...,, = 1 1 ()() () (( )) pp p pp p pp dXtd XtdXt orfX t dtdt dt − − =,..., , We just need to solve out () p Xt , so 11 ()( 1)()111 ii i Xt XtXtiptmmn ++ =+−,=,...,−,= ,...,.≥ 01 (0) (0)(0) p XX X==... = It is usually difficult to find Ff, ,but, we can consider to establish the multiple linear (or nonlinear) regression model. Given a significance level α (for exam- ple, 0 05 α = . ),if the significance test for the regression equation can be established, we can find the correspond- ing differential equations at 1- α confidence level, which can explain the reasonable degree for the established differential equations. The adjusted R-squared ( 2 R ) or goodness-of-fit can describe the fitting degree of good or bad. We call 0F= the main model. for the residual se- ries t ε ,we test that it is or isn’t random by some test methods, if it isn’t a pure random series(such as white-noise series[4]), it shows that there exists some valuable information hid in residual series, the informa- tion should be extracted out from the residual series by making use of the B-J method[5], at this time, we shall establish the model for residual series, It is called as the auxiliary model. Finally, we combine the main model and the auxiliary model to forecast. 3. Empirical Analysis Application We study the Chinese population data[6] from 1978 to 2007, the total number of sample observations is 21, see Table 1 Data of the population of China(unit:ten thousand) 1978 1980 1985 1990 1991 1992 1993 1994 1995 1996 1997 9625 9 9870 5 1058 51 1143 33 1158 23 1171 71 1185 17 1198 50 1211 21 1223 89 1236 26 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 1247 61 1257 86 1267 43 1276 27 1284 53 1292 27 1299 88 1307 56 1314 48 1321 29 We use the sample data from 1978 to 2005 to model, leaving two sample data of 2006 and 2007 as a reference to assess the short-term forecast to see the accuracy of the established model. 3.1. Analyse the Relationship Between the Original Series and its Cumulative Seri es Let the original sample time series be ()0 120 t ytyt=,=,,..., , the time range to model is from 1978 to 2005.that is 0 118t=, ,..., , the first cumulative sum series of t y is () t X XtX= = , see fig.1,fig.2. We generate new series tt ZR, via tt yX, as follows ()() ln() t tt t y ZZtRRtX t X == ,== The scatter plot of t Z and t R is such as fig.3.We es- tablish regression model below 2 (1) (2)(3) t tt Zcc RcR=++. (4) By making use of least-squares method and EViews6.0, it is easy to obtain the estimation value of parameters (1)(2)(3)cc c,, , see fig.4 and Tab.2. 2 22 19772308771470 107731 t tt Z RR= .−.+. (5) Table 2. Results of estimate and test (significance level α =0.05) Vari able C oef fici ent Std. Error t-Statistic Prob. c(1) 22.19772 1.334405 16.63491 0.0000 c(2) -3.0877147 0.202384 -15.25674 0.0000 c(3) 0.107731 0.007644 14.09369 0.0000 The adjusted R2 = 0.986264.The t-statistics of three re- gression coefficients (1)(2)(3)cc c,, in (4) are respec- 28 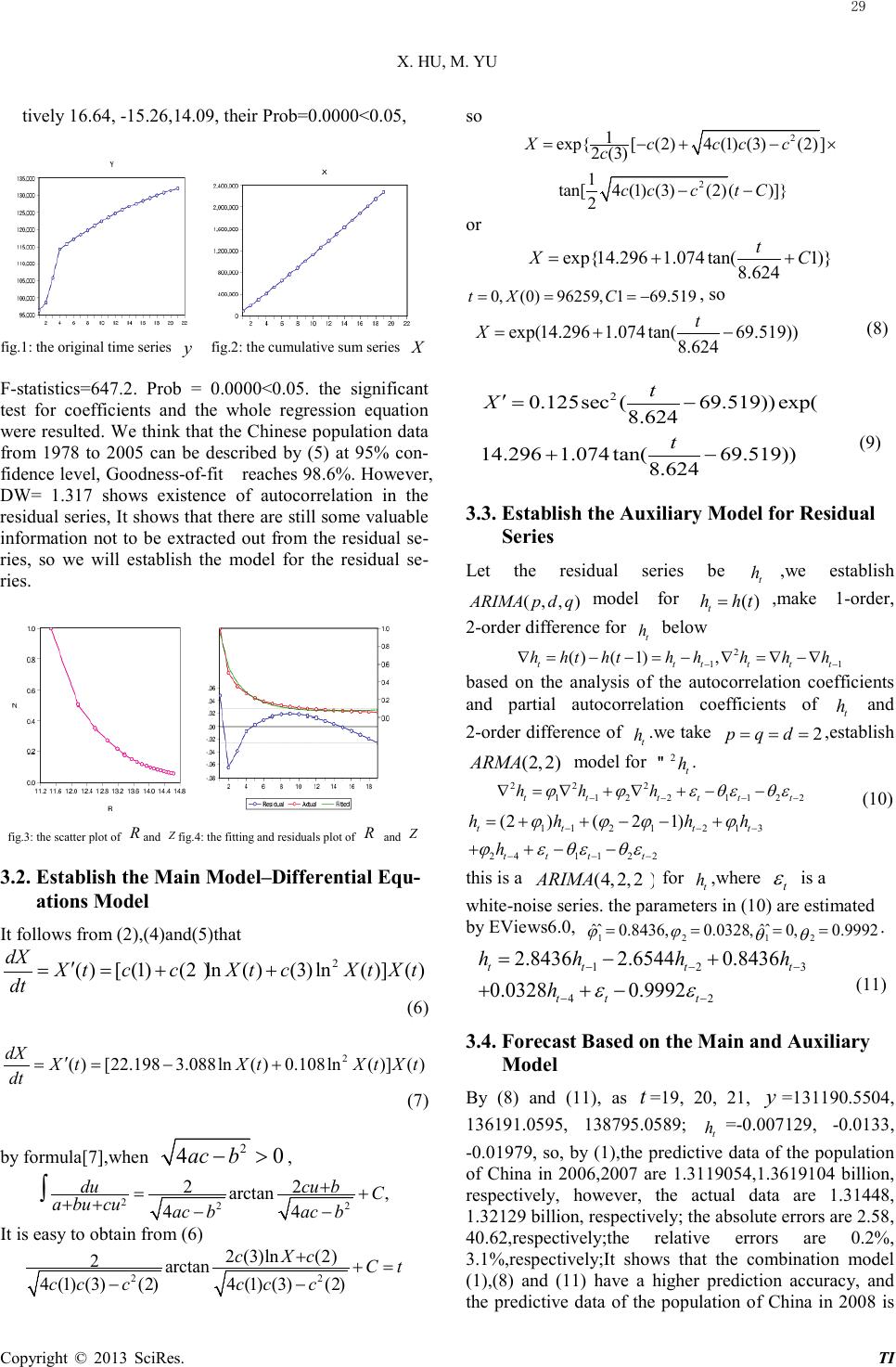 X. HU, M. YU Copyright © 2013 SciRes. TI tively 16.64, -15.26,14.09, their Prob=0.0000<0.05, fig.1: the original time series y fig.2: the cumulative sum series X F-statistics=647.2. Prob = 0.0000<0.05. the significant test for coefficients and the whole regression equation were resulted. We think that the Chinese population data from 1978 to 2005 can be described by (5) at 95% con- fidence level, Goodness-of-fit reaches 98.6%. However, DW= 1.317 shows existence of autocorrelation in the residual series, It shows that there are still some valuable information not to be extracted out from the residual se- ries, so we will establish the model for the residual se- ries. fig.3: the scatter plot of R and Z fig.4: the fitting and residuals plot of R and Z 3.2. Establish the Main Model–Differential Equ- ations Model It follows from (2),(4)and(5)that 2 ()[ (1)(2)ln()(3)ln()]() dX X tccXtcXtXt dt ′ ==++ (6) 2 ( )[221983088ln( )0108ln()]( ) dX X tXtXtXt dt ′ == .−.+. (7) by formula[7],when 2 40ac b−> , 222 2 2arctan 44 ducu bC a bu cuac bac b + = +, ++ −− ∫ It is easy to obtain from (6) 22 2 (3)ln(2) 2arctan 4 (1) (3)(2)4(1) (3)(2) c XcCt cc ccc c ++= −− so 2 2 1 exp{[(2)4 (1)(3)(2)] 2 (3) 1 tan[4(1) (3)(2)()]} 2 Xccc c c c cctC =−+− × −− or exp{14 2961 074tan(1)} 8 624 t XC=. +.+ . 0(0)96259169 519tX C=,=,=−. , so exp(14 2961 074tan(69 519)) 8 624 t X=.+.− . . (8) 2 0 125sec(69 519))exp( 8 624 14 2961074tan(69 519)) 8 624 t X t ′=. −. . .+.−. . (9) 3.3. Establish the Auxiliary Model for Residual Series Let the residual series be t h ,we establish ()ARIMAp dq,, model for () t h ht= ,make 1-order, 2-order difference for t h below 2 11 ( )(1) ttttt t hhththhhhh −− ∇=−−=−,∇=∇−∇ based on the analysis of the autocorrelation coefficients and partial autocorrelation coefficients of t h and 2-order difference of t h .we take 2pqd= == ,establish (2 2)ARMA , model for 2 t h" . 22 2 11221122ttttt t hh h ϕϕε θεθε − −−− ∇ =∇+∇+−− (10) 1 121213 2 4112 2 (2)(21) t ttt ttt t h hhh h ϕ ϕϕϕ ϕε θεθε − −− − −− =++−− + ++− − this is a (422)ARIMA ,, for t h ,where t ε is a white-noise series. the parameters in (10) are estimated by EViews6.0, 12 12 ˆˆ ˆˆ 0 84360032800 9992 ϕϕ θθ =., =.,=,=. . 123 42 2 84362 65440 8436 0 03280 9992 tt tt tt t hh hh h εε −− − −− =. −.+. +.+− . (11) 3.4. Forecast Based on the Main and Auxiliary Model By (8) and (11), as t =19, 20, 21, y =131190.5504, 136191.0595, 138795.0589; t h =-0.007129, -0.0133, -0.01979, so, by (1),the predictive data of the population of China in 2006,2007 are 1.3119054,1.3619104 billion, respectively, however, the actual data are 1.31448, 1.32129 billion, respectively; the absolute errors are 2.58, 40.62,respectively;the relative errors are 0.2%, 3.1%,respectively;It shows that the combination model (1),(8) a nd (11) have a higher prediction accurac y, and the predictive data of the population of China in 2008 is 29  X. HU, M. YU Copyright © 2013 SciRes. TI 1.3879503 billion. We also find that predictive value of the auxiliary model (11) is little impact on the total pre- dictive value. the total predictive value mainly depends on the main model (8),or, mainly depends on the predic- tive value of the differential equations model (7).So, we can see that the short-term forecast accuracy is very high based on differential equations modeling for the time series on some condition. We further consider the stability of equilibrium point of (6) or (7). Let 2 [(1) (2)ln()(3)ln()]()()0 dX ccXtcXtXtf X dt =++ == 2 0[(1)(2)ln()(3)ln()]0XccXt cXt≠, ++= , when 2 (2)4 (3) (1)0c cc−> , there are two real roots, denoted by 12 uu ,.there are two equilibrium points 12 XX, , 1 122 exp( )exp()X uXu= ,= . on the other hand, 2 ()(1)(2)((1)2(3)) ln(3) lnfXccccX cX ′=++ ++, When 2(2)4 (3)(1)0c cc− >, 2 1 2 2 12 ()(2)4 (3) (1) () (2)4(3)(1)()0()0 fXccc fXcc cfXfX ′=−, ′ ′′ =−−.>,< The equilibrium point 2 X of (6) is stable, or, 2 t XX→ +∞,→ .the equilibrium point 1 X of (6) is unstable, or, tX→+∞,→ +∞ . so, we must control those factors that impact (1)(2)(3)ccc,, in (6),such that 2 (2)4(3) (1)0c cc−> . otherwise, tX→ +∞,→ +∞ However, in fact, for model (7), 2 (2)4 (3) (1)0c cc−< ,it show that there is no equilibrium point in (7), it is ob- viously from (9),as /8 62469 5192 t π . −.→, or 613ty→,→ +∞ . it show that China’s population will tend to infinity after 613 years, so, the model (7) is only suitable for short-term prediction. 4. Acknowledgemen ts Acknowledgements: the author is grateful to the ano- nymous referees for his helpful comments and sugges- tions. REFERENCES [1] Zhu Minhui. Fitting Gompertz Model and Logistic Mod- el.J. Mathematics in Practice and Theory,2003;2:705-709. [2] Peter J.Brockwell et al. Time series: theory and methods (2nd edn).China Higher Education Press Beijing and Springer-Verlag Berlin Heidelberg:Beijing,2001;75. [3] Yi Danhui.Data analysis and Eviews application. China Statistics Press:Beijing,2002;66-70. [4] Zhang Shiying.The financial time series analysis. Tsing- hua University Press:Beijing,2008;90-93. [5] Philip Hans Franses.Time Series Models for Business and Economic Forecasting[M].Beijing: Chinese People’s University Press.2002. [6] http//www.cpachn.org.cn/chinese/Teaching/Information.a sp?,2009-05-02. [7] Tongji University Department of Applied Mathematics. Advanced Mathematics (5th edn), Beijing: Higher Educa- tion Press.2004. 30 |