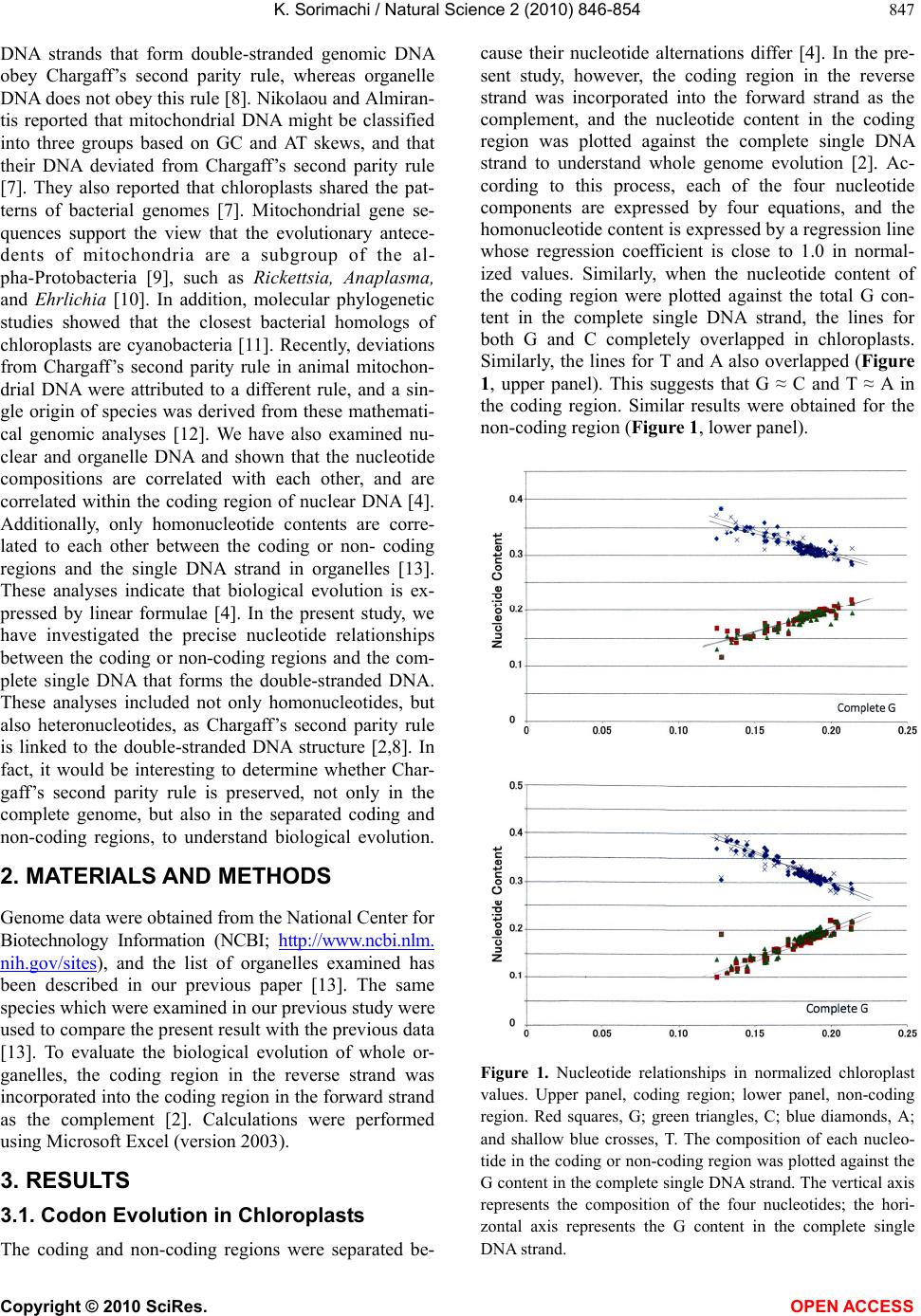
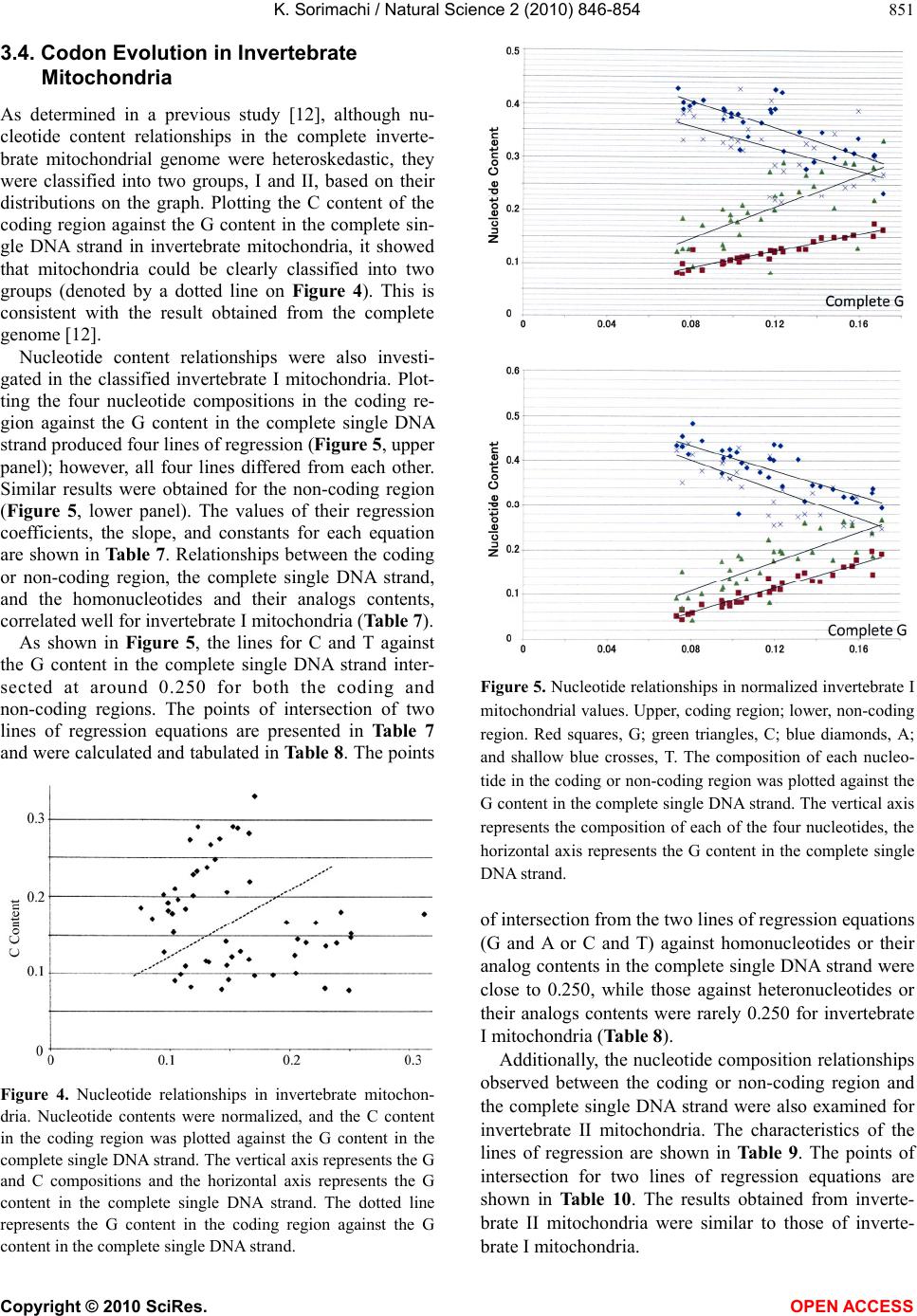
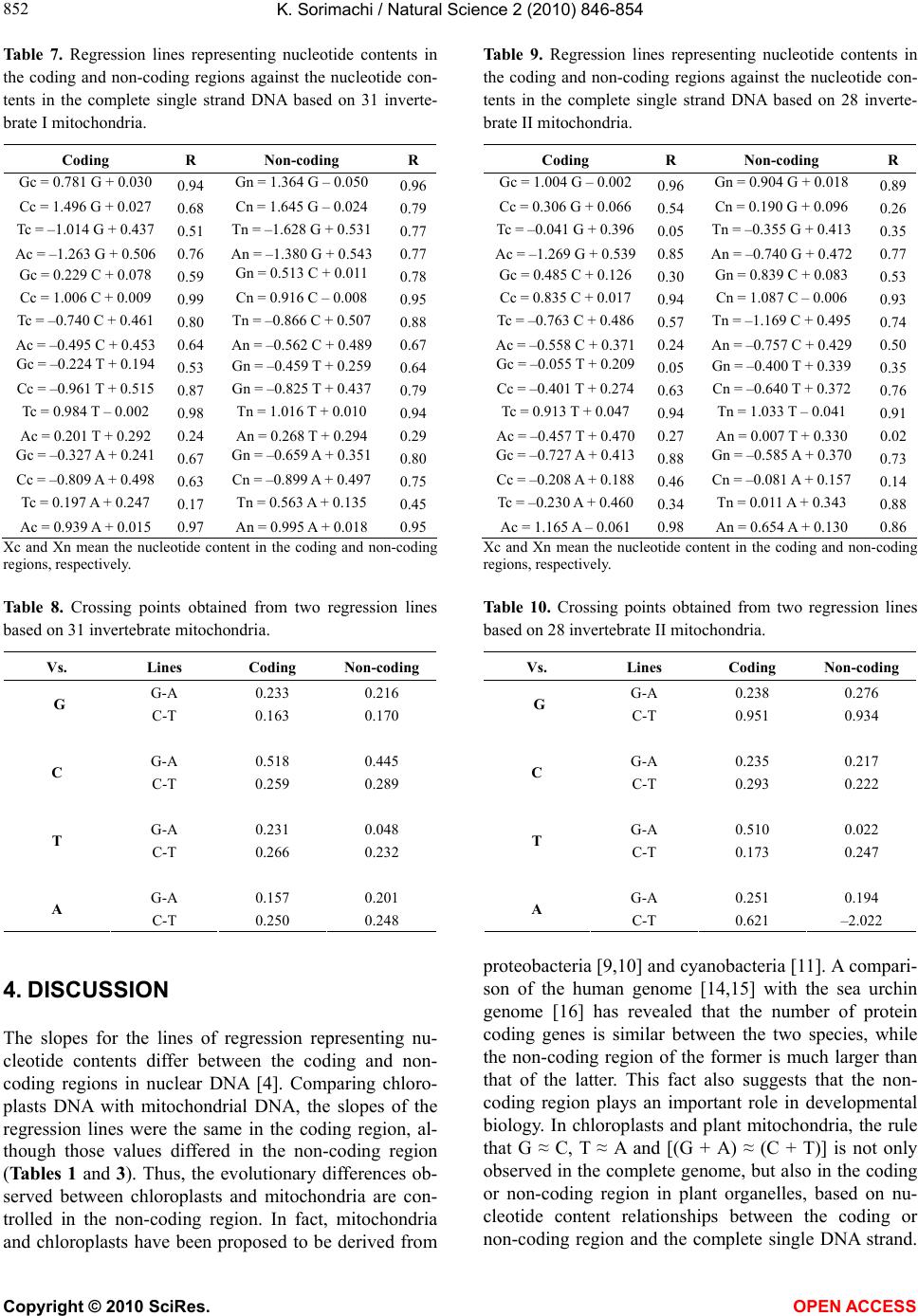
K. Sorimachi / Natural Science 2 (2010) 846-854
Copyright © 2010 SciRes. OPEN ACCESS
853
On the other hand, the nucleotide content relationships
for either the coding or non-coding regions did not obey
Chargaff’s second parity rule in nuclear genomes [4],
instead, (G + A) > (C + T) in the coding region [17]. In
addition, animal mitochondrial evolution seems to differ,
not only from nuclear, but also from plant organelles.
Plasmids, which are not compartmentalized from the
nucleus, showed codon frequencies that resemble those
of the host [18]. Thus, the compartmentalization of cel-
lular organelles is likely to strongly influence organelle
evolution.
To understand the establishment of Chargaff’s second
parity rule, the existence of both forward and reverse
strands is necessary [2,8]. Namely, it is clear that the
second parity rule is based on the double helical struc-
ture of DNA [19], where the complementary relationship
between the two strands plays a role. Primitive genomes
might be constructed by double-stranded DNA and mu-
tations that occur synchronously over the genome [20]
are governed by linear formulae [4]. In addition, Char-
gaff’s parity rules are alternated to four linear formulae
based on single nucleotide content, as shown above.
Thus, biological evolution is likely to be based on the
nucleotide contents expressed by linear formulae.
Chargaff’s first parity rule [5], G = C, A = T, and [(G
+ A) = (C + T)], is well known and uses the four nucleo-
tide contents that are normalized as follows: G + C + A +
T = 1. Therefore, 2G + 2T = 1 or 2G + 2A = 1. Finally, T
= 0.5 – G or A = 0.5 – G. Eventually, four nucleotide
contents are expressed by just G content: G = G, C = G,
T = 0.5 – G, and A = 0.5 – G. Namely, each of the four
nucleotide contents are expressed by linear formulae
based on just one nucleotide content (G). Thus lines for
G and C or for lines T and A overlap. In addition, the G
line intersects the A line at 0.250 and the C line crosses
the T line at 0.250. Thus, the four regression lines ob-
tained from the sample that obeys Chargaff’s first parity
rule cross exactly at 0.250. In addition, the four regres-
sion lines based on a sample that obeys Chargaff’s sec-
ond parity rule will intersect at around 0.250. In the pre-
sent study, four regression lines based on chloroplasts
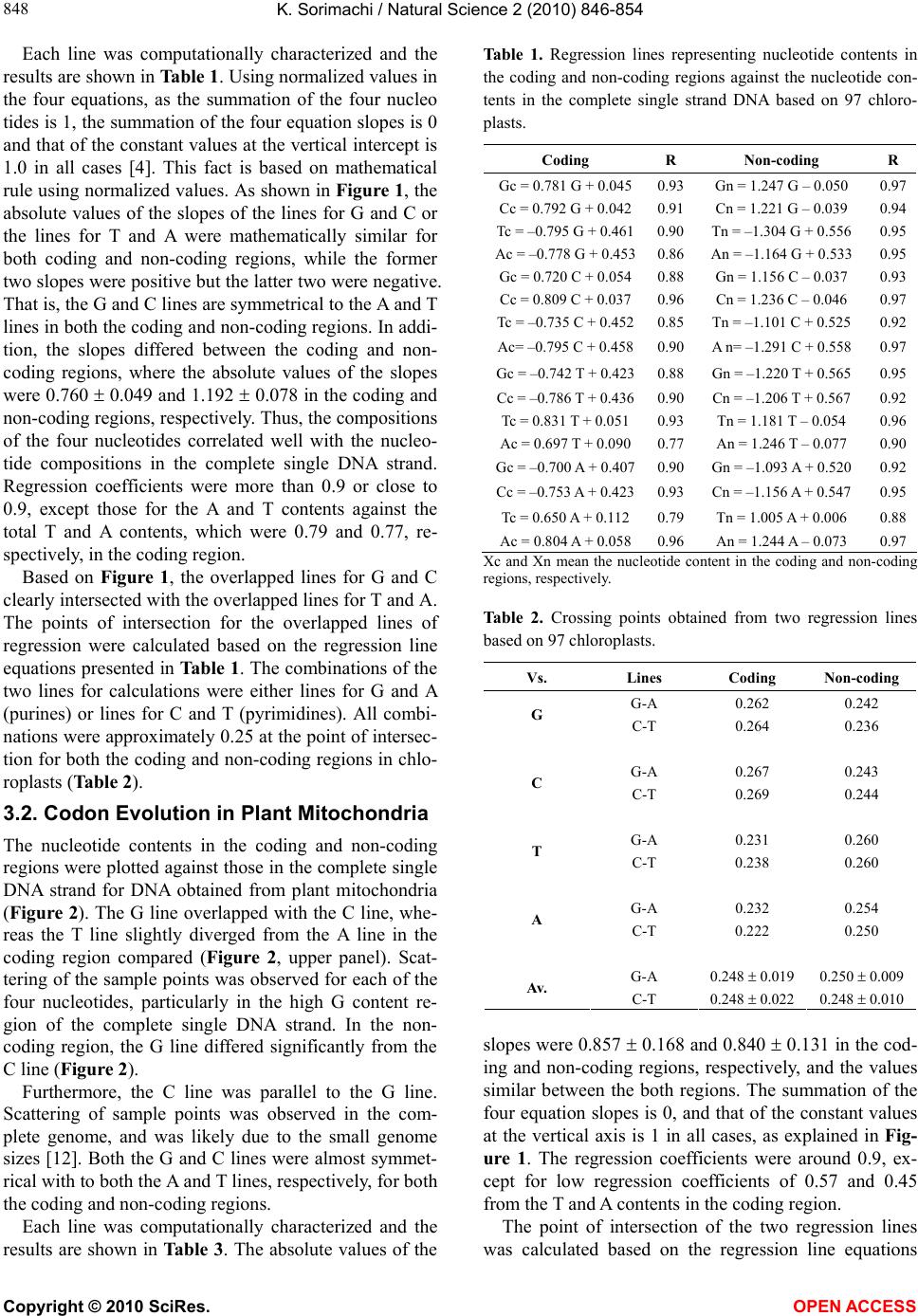
(Figure 1 and Table 1) and plant mitochondria (Figure
2 and Table 3), which both obey Chargaff’s second par-
ity rule, intersect at around 0.250 (Tables 2 and 4). On
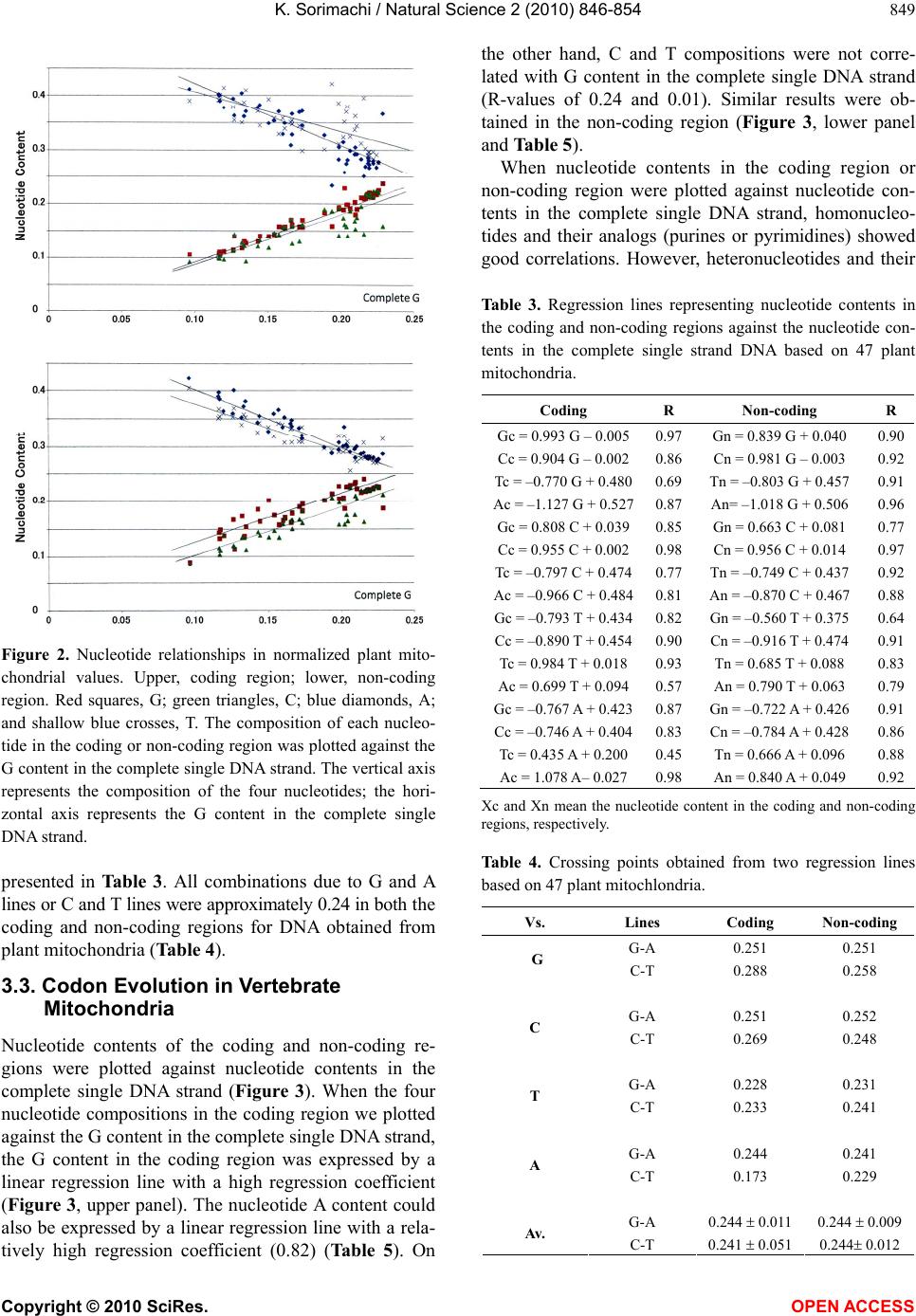
the other hand, for animal mitochondria, only two re-
gression lines due to homonucleotides or their analogs in
the complete single DNA strand intersect around 0.250,
while the other two regression lines due to heteronucleo-
tides or their analogs in the complete single DNA strand
rarely intersect at 0.250. Thus, nucleotide alternations,
not only in homonucleotides and their analogs but also
in heteronucleotides and their analogs, are strictly regu-
lated against the complete single DNA strand in samples
that obey Chargaff’s second parity rule; namely, chloro-
plasts and plant mitochondria. However, only alterna-
tions of homonucleotides and their analogs are strictly
regulated in both coding and non-coding regions against
the complete single DNA strand in animal mitochondria.
These results indicate that the evolutionary process of
animal mitochondria differs from that of chloroplasts
and plant mitochondria, possibly due to deviations from
Chargaff’s second parity rule. This is consistent with the
previous conclusion that provided evidence for a single
origin of life [12].
REFERENCES
[1] Rudner, R., Karkas, J.D. and Chargaff, E. (1968) Separa-
tion of B. subtilis DNA into complementary strands. 3.
Direct analysis. Proceedings of the National Academy
Sciences, 60(3), 921-922.
[2] Sorimachi, K. (2009) A proposed solution to the historic
puzzle of Chargaff’s second parity rule. The Open Ge-
nomics Journal, 2(3), 12-14.
[3] Sorimachi, K. and Okayasu, T. (2004) An evaluation of
evolutionary theories based on genomic structures in
Saccharomyces cerevisiae and Encephalitozoon cuniculi.
Mycoscience, 45(5), 345-350.
[4] Sorimachi, K. and Okayasu, T. (2008) Codon evolution is
governed by linear formulas. Amino Acids, 34(4), 661-
668.
[5] Chargaff, E. (1950) Chemical specificity of nucleic acids
and mechanism of their enzymatic degradation. Experi-
mentia, 6(6), 201-209.
[6] Bell, S.J. and Forsdyke, D.R. (1999) Deviations from
Chargaff’s second parity rule with direction of transcrip-
tion. The Journal of Theoretical Biology, 197(1), 63-76.
[7] Nikolaou, C. and Almirantis, Y. (2006) Deviations from
Chargaff’s second parity rule in organelle DNA insights
into the evolution of organelle genomes. Gene, 381,
34-41.
[8] Mitchell, D. and Bridge, R. (2006) A test of Chargaff’s
second rule. Biochemical and Biophysical Research
Communications, 340(1), 90-94.
[9] Yang, D., Oyaizu, Y., Oyaizu, H., Olsen, G.J. and Woese,
C.R. (1985) Mitochondrial origins. Proceedings of Na-
tional Academy Sciences, 82(13), 4443-4447.
[10] Lang, B.F., Burger, G., O’Kelly, C.J., Cedergren, R.,
Golding, B., Lemieux, C., et al. (1997) An ancestral mi-
tochondrial DNA resembling a eubacterial genome in
miniature. Nature, 387(6632), 493-497.
[11] Raven, J.A. and Douglas, A.E. (2003) Genomes at the
interface between bacteria and organelles. Philosophical
Transactions of Royal Society London. Series B, Bio-
logical Science, 358(1429), 5-18.
[12] Sorimachi, K. (2010) Genomic data provides simple
evidence for a single origin of life. Natural Science, 2(5),
521-527.
[13] Sorimachi, K. and Okayasu, T. (2008) Universal rules
governing genome evolution expressed by linear formu-
las. The Open Genomics Journal, 1(11), 33-43.
[14] Lander, E.S., Linton, L.M., Birren, B., Nusbaum, C.,
Zody, M.C., Baldwin, J., Devon, K., et al. (2001) Initial