Paper Menu >>
Journal Menu >>
 Journal of Information Security, 2012, 3, 319-325 http://dx.doi.org/10.4236/jis.2012.34039 Published Online October 2012 (http://www.SciRP.org/journal/jis) Simultaneous Hashing of Multiple Messages Shay Gueron1,2, Vlad Krasnov2 1Department of Mathematics, University of Haifa, Haifa, Israel 2Intel Corporation, Israel Development Center, Haifa, Israel Email: shay@math.haifa.ac.il Received July 12, 2012; revised August 21, 2012; accepted August 29, 2012 ABSTRACT We describe a method for efficiently hashing multiple messages of different lengths. Such computations occur in various scenarios, and one of them is when an operating system checks the integrity of its components during boot time. These tasks can gain performance by parallelizing the computations and using SIMD architectures. For such scenarios, we compare the performance of a new 4-buffers SHA-256 S-HASH implementation, to that o f the standard serial hashing. Our results are measured on the 2nd Generation Intel® Core™ Processor, and demonstrate SHA-256 processing at effec- tively ~5.2 Cycles per Byte, when hashing from any of the three cache levels, or from the system memory. This repre- sents speedup by a factor of 3.42x compared to OpenSSL (1.0.1), and by 2.25x compared to the recent and faster n-SMS method. For hashing from a disk, we show an effective rate of ~6.73 Cycles/Byte, which is almost 3 times faster than OpenSSL (1.0.1) under the same conditions. These results indicate that for some usage models, SHA-256 is sig- nificantly faster than commonly perceived. Keywords: SHA-256; SHA-512; SHA3 Competition; SIMD Architecture; Advanced Vector Extensions Architectures; AVX; AVX 2 1. Introduction The performance of hash functions is important in vari- ous situations and platforms. One example is a server workload: authenticated encryption in SSL/TLS sessions, where hash functions are used for authentication, in HMAC mode. This is one reason why the performance of SHA-256 on modern x86_64 architectures was defined as a baseline for the SHA3 competition [ 1]. Traditionally, the performance of hash functions is measured by hashing a single message (of some length) on a target platform. For example, consider the 2nd Gen- eration Intel® Core™ Processors. The OpenSSL (1.0.1) implementation hashes a single buffer (of length 8 KB) at 17.55 Cycles per Byte (C/B hereafter). Recently, [ 2] im- proved the performance of SHA-256 with an algorithm that parallelizes the message schedule, and the use of SIMD architectures, moving the performance baseline to 11.47 C/B (code version from April 2012 is available from [ 3], and will be updated soon) on the modern proc- essors, when hashing from the cache. In this paper, we investigate the possibility of accele- rating SHA-256 for some scenarios, and are interested in optimizing the following computation: h ashing a number (k) of independent messages, to produce k different di- gests. We investigate the advantage of SIMD architec- tures for these parallelizable computations. Such workloads appear, for example, during the boot process of an operating system, where it checks the in- tegrity of its components (see [ 4] for example). This in- volves computing multiple hashes, and comparing them to expected values. Another situation that involves hash- ing of multiple independent messages is data de-dup- lication, where large amounts of data are scanned (typi- cally in chunks of fixed sizes) in order to identify dupli- cates [ 5]. In these two scenarios, the data typically reside on the hard disk, but hashing multiple independent mes- sages could also emerge in situations wh ere the data is in the cache/memory. A SIMD based implementation of hash algorithms was first proposed (in 2004) and described in detail by Aciiçmez [ 6]. He studied the computations of SHA-1, SHA-256 and SHA-512, and his investigation was car- ried out on Intel® Pentium™ 4, using SSE2 instructions. Two approaches for gaining performance were attempted: 1) Using SIMD instructions to parallelize some of the computations of the message schedule of these hash al- gorithms, when hashing a single message (see also later works (on SHA-1) along these lines, in [ 7, 8]); 2) Using SIMD instructions to parallelize hash computations of several independent messages. Aciiçmez reports that he could not improve the performance of hashing a single buffer, using the SIMD instructions (while this could not be done on the Pentium 4, we speculate that it would be C opyright © 2012 SciRes. JIS  S. GUERON, V. KRASNOV 320 possible on more recent architectures). However, he re- ports speedup by a factor of 1.71x for simultaneous hashing of four buffers, with SHA-256 (speedup by a factor of 2.3x for SHA-512 is also reported, but it is less interesting in our context, because the comparison base- line was a (slow) 32-bit implementation). In this paper we expand the study conducted by Aciiçmez, by demonstrating the performance of Simul- taneous Hashing of multiple independent messages, on contemporary processors. We detail a method for a “Si- multaneous Update” that facilitates hashing of independ- ent messages of arbitrary sizes. To account for different usages, we investigate the performance of hashing multi- ple messages (of variable sizes) from different cache hierarchies, system memory, and from the hard drive. 2. Preliminaries and Notations The detailed definition of SHA-256 can be found in FIPS180-2 publication [9]. Schematically, the computa- tional flow of SHA-256 can be viewed as follows: “Init” (setting the initial values), a sequence of “Update” steps (compressing a 64 bytes block of the message, and up- dating the digest value), and a “Finalize” step (takes care of the message padding). The padding requires either one or two calls to the Update function, depending on the message’s length (see more details in [2]). For SHA-256, the performance is almost linearly proportional to the number (N) of Update function calls, which. For a mes- sage of length bytes, the value of N is: length +2length mod 6456 64 length +1 else 64 N (1) For sufficiently long messages, we can approximate N ~ floor (length/64). For example, this approximation for a 4 KB message gives floor (length/64) = 64, while actual hashing of a 4 KB message requires 65 Update function calls (i.e., a ~ 1.5% deviati on). 3. Simultaneous Hashing (S-HASH) of Multiple Messages SIMD architectures [ 10] are designed to execute, in pa- rallel, the same operations on several independent chunks of data (called “elements”). Modern architectures have variants of SIMD instruction s that operate on elements of sizes 1, 2, 4, or 8 bytes. By the nature of the algorithms, SHA-256 (and SHA-1) requires operations on 4 bytes elements, while SHA-512 requires operations on 8 bytes elements. Figure 1 describes the Simultaneous Hashing algo- rithm (S-HASH) that hashes k messages and generates k Algorithm 1: Simultaneous Hashing (S -HAS H) Input: Buffers – a list with pointers to k buffers to be hashed. Lengths – a list with the lengths (in bytes) of the k buffer s. Hashes – a list with pointers to store the k generated hash values. Notations: The number of t-bit “words” (elements) that fit in a register is m. (for SHA-256, t=32, and with AVX, m=128/32=4). It is assumed that k > m. The number of bytes, hashed by one “Updat e” operati o n is denote d b y p. Output: k hash values of the k buffers, stored the at memory locations pointed by Hashes. Flow: Init: L[0] = Lengths[0] L[1] = Lengths[1] … L[m-1] = Lengths[m-1] B[0] = Buff e r s [0 ] B[1] = Buff e r s [1 ] … B[m-1] = Buffers[m-1] H[0] = Hashes[0] H[1] = Hashes[1] … H[m-1] = Hashes[m-1] Last[ 0] = 0 Last[ 1] = 0 … Last[m-1] = 0 HashInit(Hashes[0]) HashInit(Hashes[1]) … HashInit(Hashes[m-1]) i = m; Simultaneous Update: Repeat n = min(L)/p S-UPDATE(H, B, n) L = L – [n ×p|n×p|…|n×p] For j = 0 to m-1 If L[j]<p AND Last[j]=0 then L astBl o c k[j] = Prepar ePa d ding Blo ck(B[j] ) B[j] = LastBlock [j] Last[j] = 1 L[j] = Length(LastBlock[j]) El s e If L[ j ]<p AND La s t[j] = 1 th e n If i=k then Break Else L[ j] = Le ngths[i ] B[j] = Buffs[i] H[j] = Hashes[i] Last[j] = 0 HashInit(Hashes[i]) i++ End If End If End For End Repeat If unfinished buffers still remain, finish hashing serially Figure 1. The simultaneous hashing (S-HASH) algorithm. Copyright © 2012 SciRes. JIS  S. GUERON, V. KRASNOV 321 digests, with some hash function. Suppose that the im- plemented hash function operates on t-bit “words” (ele- ments), and that the architecture has s-bit SIMD registers. Then, the number of words that fit into a SIMD register is m = s/t, which we assume to be an integer. We also assume that k > m. Algorithm 1 starts with the Initialize step for the first m buffers. Then, it invokes the “Simul- taneous Update” function (for the specific hash function) every time there are m blocks ready for processing. This is repeated until the shortest buffer (from the m processed buffers) is fully consumed. At this point, a padding block is fed to the Simultaneous Update fun ction, to “Finalize” (that buffer). If the hash is already finalized, a block from a new buffer is fed (after the proper “Init”). Here, we use the AVX architecture [ 10], with 128-bit registers (i.e., s = 128). SHA-256 (and SHA-1) algo- rithms have t = 32, while SHA-512 has t = 64, implying m = 4 for SHA-1 and SHA-256, and m = 2 for SHA512. For our SHA-256 stud y, we can hash 4 buffer s in parallel. We call this implementation 4-buffers SHA-256 S-HASH. The near-future AVX2 architecture [ 11] has integer instructions that operate on 256-b it registers. This allows for doubling the number of independent messages that can be hashed in parallel and would lead to, for example, 8-buffers SHA-256 S-HASH or 4-buffers SHA-512 S- HASH. 4. Results This section describes the 4-buffers SHA-256 S-HASH results. 4.1. The System’s Characteristics The system that was used for generating the reported measurements had the following characteristics: An Intel® Core™ i5-2500 processor (2nd Generation Intel® Core™ Processor; Sometimes referred to as Architecture Codename “Sandy Bridge”). 8 GB RAM (DDR3 1 60 0 , 2 C han nel s ) . A RAID0 array of two Intel® SSD 320 drives, each one of 80 G B and combined throughput of 400 M B / s ec (indicated by “hdparm-t” [ 12]). Fedora 16 OS. All the runs were carried out on a system where the Intel® Turbo Boost Technology, the Intel® Hyper-Thread- ing Technology, and the Enhanced Intel Speedstep® Te- chnology , were disabled. All of the performance numbers reported here, were obtained on the same system, ran on the same processor, and under the same conditions. In particular, we point out that all of the reported hash computations include the overhead of the proper padding, as required by the SHA-256 de fi n ition [9]. The tested codes were written in assembly language, so their performance is compiler agnostic. The impact of the operating system is relevant only for hashing files from the hard disk, because some system calls (to access files/directories) are involved. However, we suggest that experiments with other operating systems would show the same performance traits that we report here. 4.2. Simultaneous Hashing of Multiple 4 KB Buffers, from Different Cache Levels and Main Memory For profiling the performance of the 4-buffers SHA-256 S-HASH, we wrote a new implementation which pro- cesses four buffers in parallel. In order to estimate the advantage of the parallelization, we compare the result- ing performance to serial implementations that hash the same amount of data. To measure the performance of hashing data that re- sides in different cache levels, or in memory, we note that the processor has ([13]): 1) First Level Data Cache of 32 KB (per core); 2) Second Level Cache of 256 KB (per core); 3) Last Level Cache of 6 MB (shared among all the cores). Therefore, For data that resides in the First Level Cache, we hashed a total of 1 6 KB of data, split to 4 chunks of 4 KB each. For data that resides in the Second Level Cache, we hashed a total of 256 KB of data, split to 64 ch unks of 4 KB each. For data that resides in the Last Level Cache, we hashed a total of 2 MB of data, split to 512 chunks of 4 KB each. For data that resides in the main memory, we hashed a total of 32 MB of data, split to 8192 chunks of 4 KB each. Prior to the actual measurements, we ran the hash, in a loop, 500 times, in order to make sure that our data re- sides in the desired cache level (or memory). For comp arison, we us ed the OpenSSL (versi on 1.0.1) SHA-256 (serial) [14] implementation, and the faster implementation, based on the n-SMS method [2] (a ver- sion from April 2012, can be retrieved from [3]; An up- date will be posted soon). The results, illustrated in Figure 2, show that hashing from all three cache levels can be performed at roughly the same performance, and there is only some small per- formance degradation when the data is hashed from the main memory. The 4-buffers SHA- 256 S-HASH method is 3.42x faster than OpenSSL (1.0.1), and 2.24x times faster than the n-SMS method. 4.3. Simultaneous Hashing of Files from the Hard-Drive The following results account for the performance of Copyright © 2012 SciRes. JIS 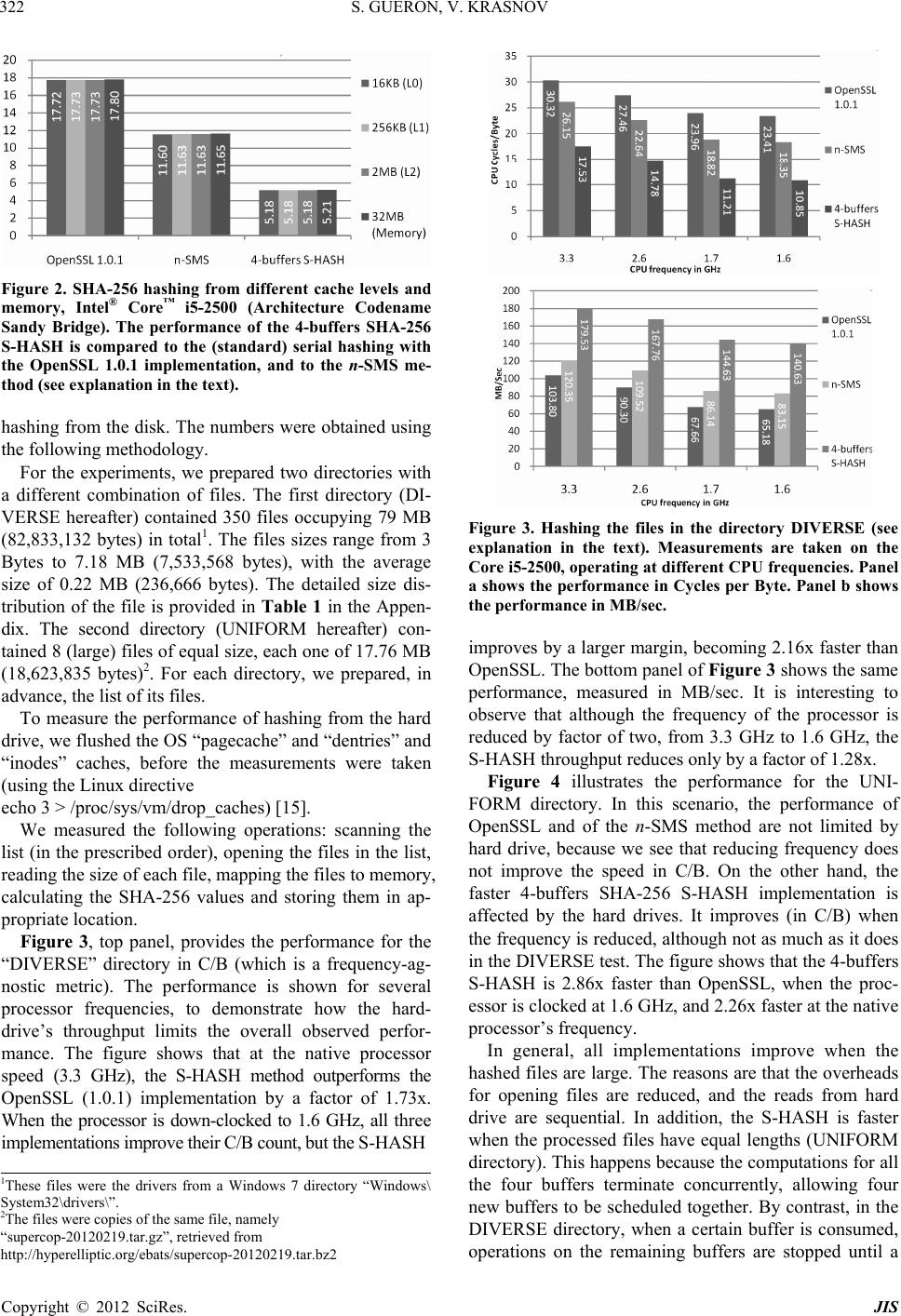 S. GUERON, V. KRASNOV 322 Figure 2. SHA-256 hashing from different cache levels and memory, Intel® Core™ i5-2500 (Architecture Codename Sandy Bridge). The performance of the 4-buffers SHA-256 S-HASH is compared to the (standard) serial hashing with the OpenSSL 1.0.1 implementation, and to the n-SMS me- thod (see explanation in the text). hashing from the disk. The numbers were obtained using the following methodology. For the experiments, we prepared two directories with a different combination of files. The first directory (DI- VERSE hereafter) contained 350 files occupying 79 MB (82,833,132 bytes) in total1. The files sizes range from 3 Bytes to 7.18 MB (7,533,568 bytes), with the average size of 0.22 MB (236,666 bytes). The detailed size dis- tribution of the file is provided in Table 1 in t he Appen- dix. The second directory (UNIFORM hereafter) con- tained 8 (large) files of equal size, each one of 17 .76 MB (18,623,835 bytes)2. For each directory, we prepared, in advance, the list of its files. To measure the performance of hashing from the hard drive, we flushed the OS “pagecache” and “dentries” and “inodes” caches, before the measurements were taken (using the Linux directive echo 3 > /proc/sys/vm/drop_caches) [ 15]. We measured the following operations: scanning the list (in the prescribed order), opening the files in the list, reading the size of each file, mapping the files to memory, calculating the SHA-256 values and storing them in ap- propriate location. Figure 3, top panel, provides the performance for the “DIVERSE” directory in C/B (which is a frequency-ag- nostic metric). The performance is shown for several processor frequencies, to demonstrate how the hard- drive’s throughput limits the overall observed perfor- mance. The figure shows that at the native processor speed (3.3 GHz), the S-HASH method outperforms the OpenSSL (1.0.1) implementation by a factor of 1.73x. When the processor is down-clocked to 1.6 GHz, all three implementations improve their C/B count, but the S-HASH Figure 3. Hashing the files in the directory DIVERSE (see explanation in the text). Measurements are taken on the Core i5-2500, operating at different CPU frequencies. Panel a shows the performanc e in Cycles per Byte. Panel b shows the performance in MB/sec. improves by a larger margin, becoming 2.16x faster than OpenSSL. The bottom panel of Figure 3 shows the same performance, measured in MB/sec. It is interesting to observe that although the frequency of the processor is reduced by factor of two, from 3.3 GHz to 1.6 GHz, the S-HASH throughput reduces only by a factor of 1.28x. Figure 4 illustrates the performance for the UNI- FORM directory. In this scenario, the performance of OpenSSL and of the n-SMS method are not limited by hard drive, because we see that reducing frequency does not improve the speed in C/B. On the other hand, the faster 4-buffers SHA-256 S-HASH implementation is affected by the hard drives. It improves (in C/B) when the frequency is reduced, although not as much as it does in the DIVERSE test. The figure shows that the 4-buffers S-HASH is 2.86x faster than OpenSSL, when the proc- essor is clocked at 1.6 GHz, and 2.26x faster at the native processor’s freque n cy. In general, all implementations improve when the hashed files are large. The reasons are that the overheads for opening files are reduced, and the reads from hard drive are sequential. In addition, the S-HASH is faster when the processed files have equal lengths (UNIFORM directory). This happens because the computations for all the four buffers terminate concurrently, allowing four new buffers to be scheduled together. By contrast, in the DIVERSE directory, when a certain buffer is consumed, operations on the remaining buffers are stopped until a 1These files were the drivers from a Windows 7 directory “Windows\ System32\drivers\”. 2The files were copies of the same file, namely “supercop-20120219.tar.gz”, retrieved from http://hyperelliptic.org/ebats/supercop-20120219.tar.bz2 Copyright © 2012 SciRes. JIS 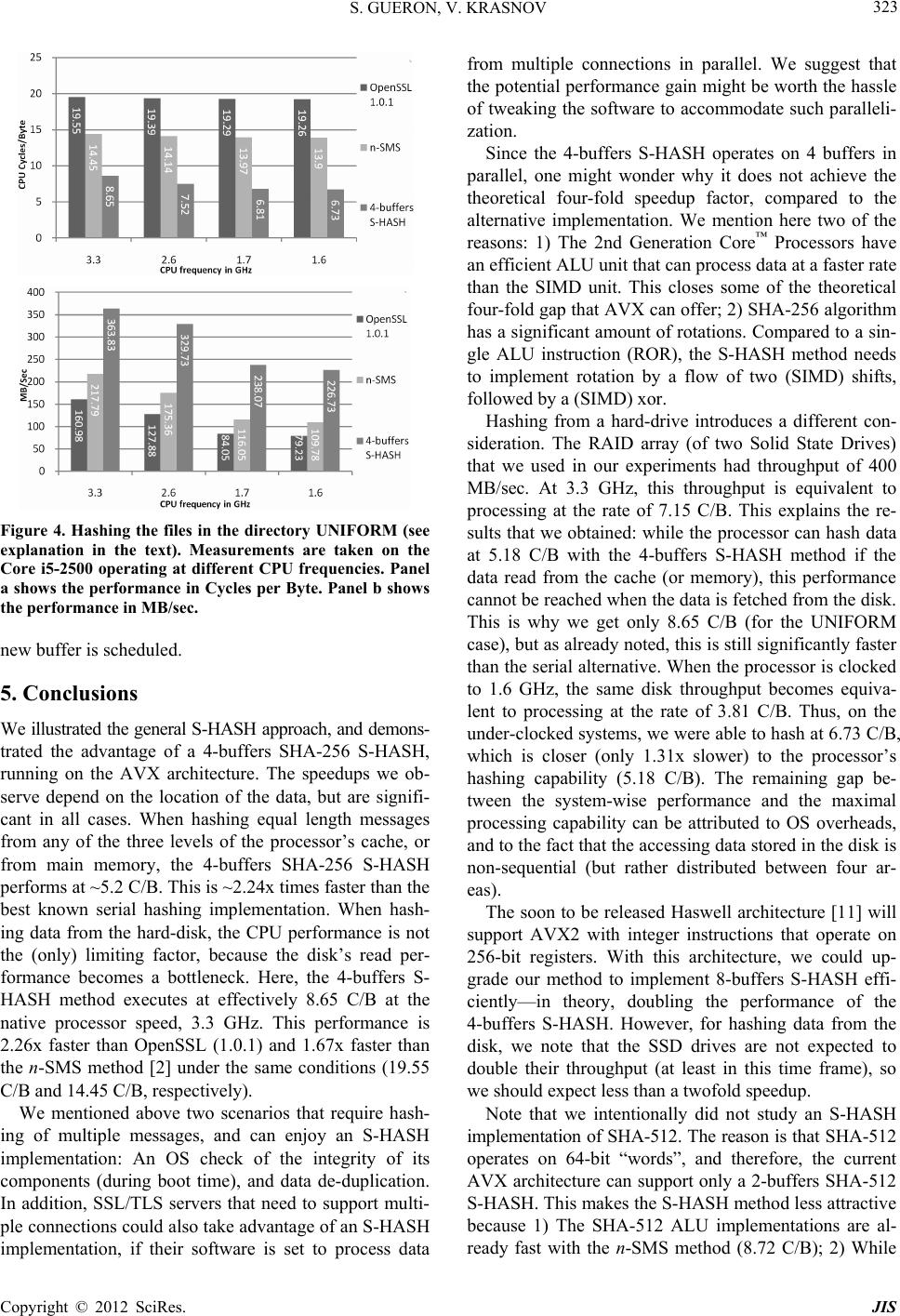 S. GUERON, V. KRASNOV 323 Figure 4. Hashing the files in the directory UNIFORM (see explanation in the text). Measurements are taken on the Core i5-2500 operating at different CPU frequencies. Panel a shows the performanc e in Cycles per Byte. Panel b shows the performance in MB/sec. new buffer is scheduled. 5. Conclusions We illustr ated the general S-HASH approach, and demons- trated the advantage of a 4-buffers SHA-256 S-HASH, running on the AVX architecture. The speedups we ob- serve depend on the location of the data, but are signifi- cant in all cases. When hashing equal length messages from any of the three levels of the processor’s cache, or from main memory, the 4-buffers SHA-256 S-HASH performs at ~5.2 C/B. This is ~2.24x times faster than the best known serial hashing implementation. When hash- ing data from the hard-disk, the CPU performance is not the (only) limiting factor, because the disk’s read per- formance becomes a bottleneck. Here, the 4-buffers S- HASH method executes at effectively 8.65 C/B at the native processor speed, 3.3 GHz. This performance is 2.26x faster than OpenSSL (1.0.1) and 1.67x faster than the n-SMS method [2] under the same conditions (19.55 C/B and 14.45 C/B, respectively). We mentioned above two scenarios that require hash- ing of multiple messages, and can enjoy an S-HASH implementation: An OS check of the integrity of its components (during boot time), and data de-duplication. In addition, SSL/TLS servers that need to support multi- ple connections could also take advantage of an S-HASH implementation, if their software is set to process data from multiple connections in parallel. We suggest that the potential performance gain might be worth the hassle of tweaking the software to accommodate such paralleli- zation. Since the 4-buffers S-HASH operates on 4 buffers in parallel, one might wonder why it does not achieve the theoretical four-fold speedup factor, compared to the alternative implementation. We mention here two of the reasons: 1) The 2nd Generation Core™ Processors have an efficient ALU unit that can process data at a faster rate than the SIMD unit. This closes some of the theoretical four-fold gap that AVX can offer; 2) SHA-256 algorithm has a significant amount of rotations. Compared to a sin- gle ALU instruction (ROR), the S-HASH method needs to implement rotation by a flow of two (SIMD) shifts, followed by a (SIMD) xor. Hashing from a hard-drive introduces a different con- sideration. The RAID array (of two Solid State Drives) that we used in our experiments had throughput of 400 MB/sec. At 3.3 GHz, this throughput is equivalent to processing at the rate of 7.15 C/B. This explains the re- sults that we obtained: while the p rocessor can hash data at 5.18 C/B with the 4-buffers S-HASH method if the data read from the cache (or memory), this performance cannot be reached when the data is fetched from the disk. This is why we get only 8.65 C/B (for the UNIFORM case), but as already noted, this is still significantly faster than the serial alternative. When the processor is clocked to 1.6 GHz, the same disk throughput becomes equiva- lent to processing at the rate of 3.81 C/B. Thus, on the under-clocked systems, we were able to hash at 6.73 C/B, which is closer (only 1.31x slower) to the processor’s hashing capability (5.18 C/B). The remaining gap be- tween the system-wise performance and the maximal processing capability can be attributed to OS overheads, and to the fact that the accessing data stored in the disk is non-sequential (but rather distributed between four ar- eas). The soon to be released Haswell architecture [11] will support AVX2 with integer instructions that operate on 256-bit registers. With this architecture, we could up- grade our method to implement 8-buffers S-HASH effi- ciently—in theory, doubling the performance of the 4-buffers S-HASH. However, for hashing data from the disk, we note that the SSD drives are not expected to double their throughput (at least in this time frame), so we should expect less than a twofold speedup. Note that we intentionally did not study an S-HASH implementation of SHA-512. The reason is that SHA -512 operates on 64-bit “words”, and therefore, the current AVX architectu re can support only a 2-buffer s SHA-512 S-HASH. This makes the S-HASH method less attractive because 1) The SHA-512 ALU implementations are al- ready fast with the n-SMS method (8.72 C/B); 2) While Copyright © 2012 SciRes. JIS  S. GUERON, V. KRASNOV Copyright © 2012 SciRes. JIS 324 each SHA-512 Update compresses 128 bytes of the mes- sage and a SHA-256 Update compresses only 64 bytes, SHA-512 involves 1.25x more rounds in the processing than SHA-256 (80 rounds versus 64). We therefore sp ecu - late that SHA-512 S-HASH implementations would be- come useful only on the AVX2 architectures (doing a 4-buffers S-HASH), but will be slower than 8-buffers SHA-256 S - HASH on that architecture. We conclude this study by stating that our results show that for some usages, SHA-256 is significantly faster than commonly perceived. Finally, we add a few related remarks on the five SHA3 finalists [1]. Skein and Keccak use 64-bit words, and the remark we made on SHA-512 holds similarly. J. H. Blake and Grostl already use SIMD instructions in their better performing implementations. Therefore, ap- plying the S-HASH method to these algorithms would create a delicate tradeoff with the S-HASH and the bene- fits of their current use of the SIMD instructions. Such optimization would be an interesting study to carry out. REFERENCES [1] NIST, “Cryptographic Hash Algorithm Competition,” 2012. http://csrc.nist.gov/groups/ST/hash/sha-3/index.html [2] S. Gueron and V. Krasnov, “Parallelizing Message Sche- dules to Accelerate the Computations of Hash Functions,” 2012. http://eprint.iacr.org/2012/067.pdf [3] S. Gueron and V. Krasnov, “Efficient Implementations of SHA256 and SHA512, Using the Simultaneous Message Scheduling Method,” 2012. http://rt.openssl.org/Ticket/Display.html?id=2784&user= guest&pass=guest [4] The Chromium Project, “Verified Boot,” 2012. http://www.chromium.org/chromium-os/chromiumos-des ign-docs/verified-boot [5] C. Y. Liu, Y. P. Lu, C. H. Shi, G. L. Lu, D. H. C. Du and D.-S. Wang, “ADMAD: Application-Driven Metadata Aware De-Duplication Archival Storage System,” Fifth IEEE International Workshop on Storage Network Archi- tecture and Parallel I/Os, 22 September 2008, pp. 29-35. [6] O. Aciicmez, “Fast Hashing on Pentium SIMD Architec- ture,” M.S. Thesis, School of Electrical Engineering and Computer Science, Oregon State University, 2004. [7] D. Gaudet, “SHA1 Using SIMD Techniques,” 2012. http://arctic.org/~dean/crypto/sha1.html [8] M. Locktyukhin, “Improving the Performance of the Se- cure Hash Algorithm (SHA-1),” 2010. http://software.intel.com/en-us/articles/improving-the-per formance-of-the-secure-hash-algorithm-1/ [9] “Federal Information Processing Standards Publication 180-2: Secure Hash Standard.” http://csrc.nist.gov/publications/fips/fips180-2/fips180-2. pdf [10] Intel, “Intel Advanced Vector Extensions Programming Reference,” 2012. http://software.intel.com/file/36945 [11] Intel (M. Buxton), “Haswell New Instruction Descrip- tions Now Available,” 2011. http://software.intel.com/en-us/blogs/2011/06/13/haswell- new-instruction-descriptions-now-available/ [12] Linux Manual, “Hdparm,” 2012. http://linux.die.net/man/8/hdparm [13] Intel, “2nd Generation Intel® CoreTM Processor Family Desktop Datasheet,” 2012. http://www.intel.com/content/www/us/en/processors/core /2nd-gen-core-desktop-vol-1-datasheet.html [14] OpenSSL, “The Open Source Toolkit for SSL/TLS,” 2012. http://openssl.org/ [15] LinuxMM, “Drop Caches,” 2012. http://linux-mm.org/Drop_Caches 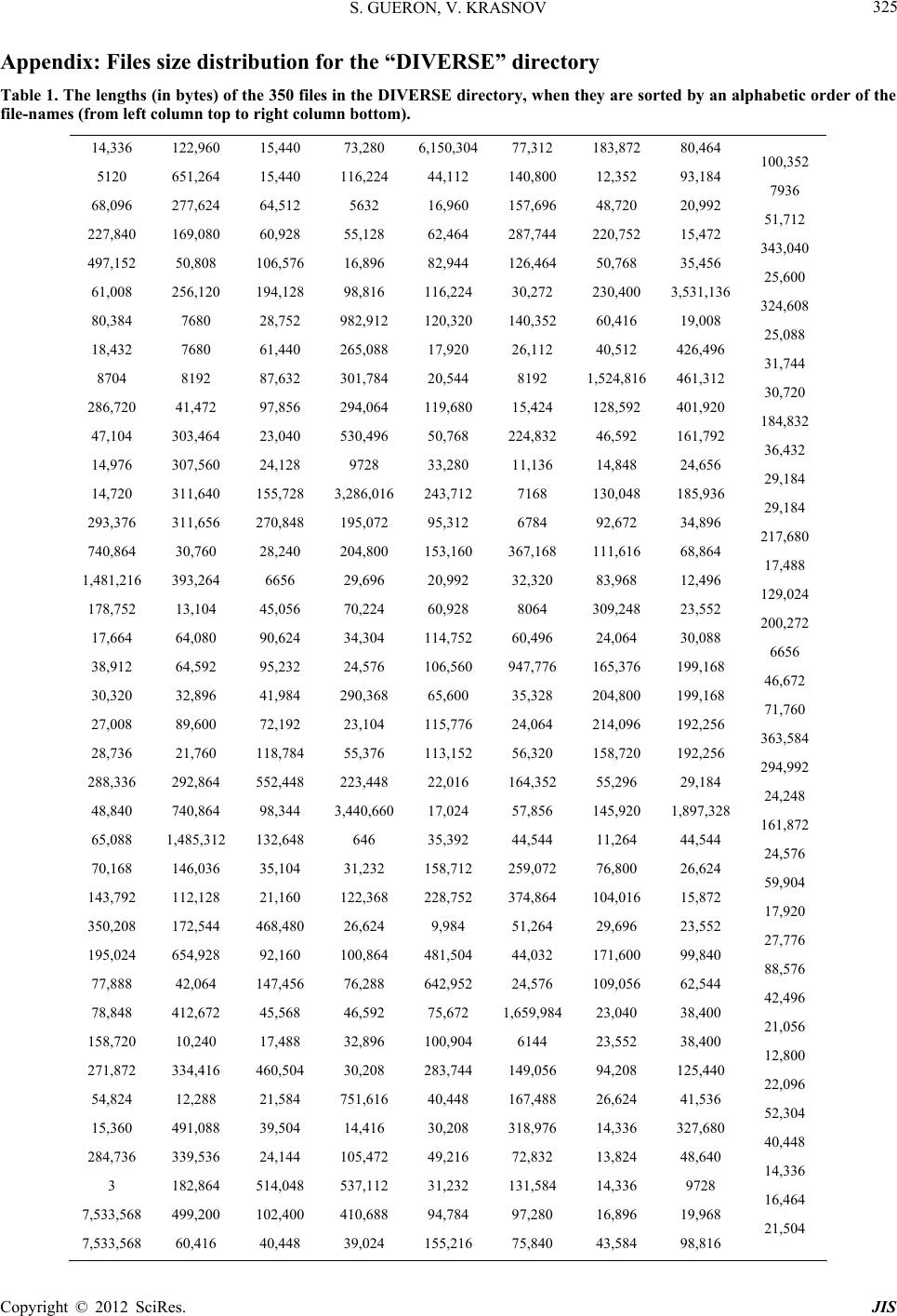 S. GUERON, V. KRASNOV 325 Appendix: Files size distribution for the “DIVERSE” directory Table 1. The lengths (in bytes) of the 350 files in the DIVERSE directory , when they are sorted by an alphabetic order of the file-names (from left column top to right column bottom). 14,336 5120 68,096 227,840 497,152 61,008 80,384 18,432 8704 286,720 47,104 14,976 14,720 293,376 740,864 1,481,216 178,752 17,664 38,912 30,320 27,008 28,736 288,336 48,840 65,088 70,168 143,792 350,208 195,024 77,888 78,848 158,720 271,872 54,824 15,360 284,736 3 7,533,568 7,533,568 122,960 651,264 277,624 169,080 50,808 256,120 7680 7680 8192 41,472 303,464 307,560 311,640 311,656 30,760 393,264 13,104 64,080 64,592 32,896 89,600 21,760 292,864 740,864 1,485,312 146,036 112,128 172,544 654,928 42,064 412,672 10,240 334,416 12,288 491,088 339,536 182,864 499,200 60,416 15,440 15,440 64,512 60,928 106,576 194,128 28,752 61,440 87,632 97,856 23,040 24,128 155,728 270,848 28,240 6656 45,056 90,624 95,232 41,984 72,192 118,784 552,448 98,344 132,648 35,104 21,160 468,480 92,160 147,456 45,568 17,488 460,504 21,584 39,504 24,144 514,048 102,400 40,448 73,280 116,224 5632 55,128 16,896 98,816 982,912 265,088 301,784 294,064 530,496 9728 3,286,016 195,072 204,800 29,696 70,224 34,304 24,576 290,368 23,104 55,376 223,448 3,440,660 646 31,232 122,368 26,624 100,864 76,288 46,592 32,896 30,208 751,616 14,416 105,472 537,112 410,688 39,024 6,150,304 44,112 16,960 62,464 82,944 116,224 120,320 17,920 20,544 119,680 50,768 33,280 243,712 95,312 153,160 20,992 60,928 114,752 106,560 65,600 115,776 113,152 22,016 17,024 35,392 158,712 228,752 9,984 481,504 642,952 75,672 100,904 283,744 40,448 30,208 49,216 31,232 94,784 155,16 77,312 140,800 157,696 287,744 126,464 30,272 140,352 26,112 8192 15,424 224,832 11,136 7168 6784 367,168 32,320 8064 60,496 947,776 35,328 24,064 56,320 164,352 57,856 44,544 259,072 374,864 51,264 44,032 24,576 1,659,984 6144 149,056 167,488 318,976 72,832 131,584 97,280 75,840 183,872 12,352 48,720 220,752 50,768 230,400 60,416 40,512 1,524,816 128,592 46,592 14,848 130,048 92,672 111,616 83,968 309,248 24,064 165,376 204,800 214,096 158,720 55,296 145,920 11,264 76,800 104,016 29,696 171,600 109,056 23,040 23,552 94,208 26,624 14,336 13,824 14,336 16,896 43,584 80,464 93,184 20,992 15,472 35,456 3,531,136 19,008 426,496 461,312 401,920 161,792 24,656 185,936 34,896 68,864 12,496 23,552 30,088 199,168 199,168 192,256 192,256 29,184 1,897,328 44,544 26,624 15,872 23,552 99,840 62,544 38,400 38,400 125,440 41,536 327,680 48,640 9728 19,968 98,816 100,352 7936 51,712 343,040 25,600 324,608 25,088 31,744 30,720 184,832 36,432 29,184 29,184 217,680 17,488 129,024 200,272 6656 46,672 71,760 363,584 294,992 24,248 161,872 24,576 59,904 17,920 27,776 88,576 42,496 21,056 12,800 22,096 52,304 40,448 14,336 16,464 21,504 2 Copyright © 2012 SciRes. JIS |