S. S. LEE, Z. F. FAN
0.021 0.022 0.023 0.024 0.025
0.021 0.022 0.023 0.024 0.025
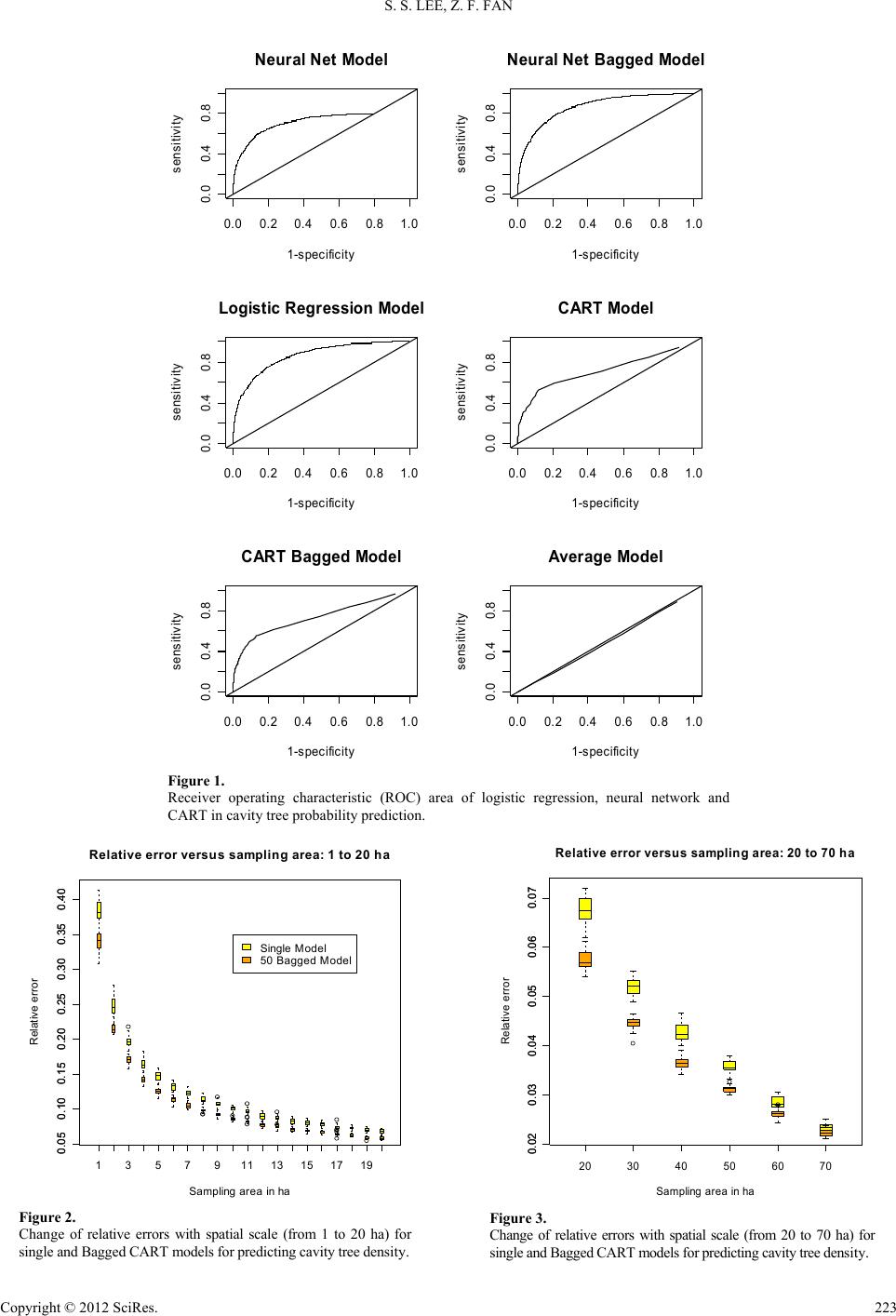
Sampling Area is 70 ha
50 Bagged Model Relative Error
Single Mo del Relative Erro r
t test p-value < 10^-9
Figure 4.
Scatter plot of relative errors of single and 50 Bagged models at a
spatial scale of 70 ha.
Conclusion
This study constructs three classes of tree-level models to es-
timate probabilities of cavity presence: logistic regression, neu-
ral networks, and CART. The estimated probabilities are com-
bined with known tree counts within covariate classes to predict
mean cavity tree density at different spatial scales, with or
without bootstrap aggregation (bagging). Although logistic
regression was the best model to predict cavity probabilities at
the individual tree level, the bagged CART outperformed other
models in predicting mean cavity tree density at the landscape
scale (e.g., >10 ha). Prediction accuracy, measured in terms of
relative error continues to decrease with spatial scale and the
difference between the bagged CART ensemble and single
CART model remains significant statistically at largest spatial
scale (70 ha) tested in the study. This is largely due to the
non-stationary nature of CART. In addition, the tree profile and
explicit deposition of important covariates in a one-after-an-
other manner of CART make it more useful for landscape level
cavity tree mapping.
Acknowledgements
Mr. Randy Jensen from Missouri Department of Conserva-
tion provided cavity tree data used for these analyses. Dr.
Stephen R. Shifley from USDA Forest Service Northern Re-
search Station reviewed the first draft of this paper. Dr. Michael
K. Crosby from the Department of Forestry, Mississippi State
University helped formatting and reviewing the revised version
of this paper. We thank them all.
REFERENCES
Breiman, L. (1995). Stacked regressions. Machine L e a rn i ng , 24, 49-64.
doi:10.1007/BF00117832
Breiman, L. (1996). Bagging predictors. Machine Learning, 26, 123-
140. doi:10.1007/BF00058655
Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984).
Classification and regression trees. Monterey, CA: Wadsworth and
Brooks.
Brookshire, B. L., & Shifley, S. R. (Eds.) (1997). Proceedings of the
missouri ozark forest ecosystem project symposium: An experimental
approach to landscape research, St. Louis, 3-5 June 1997.
Carey, A. B. (1983). Cavities in trees in hardwood forests. Snag habitat
management symposium. General Technical Report GTR-RM-99,
US Department of Agriculture Forest Service, 167-184.
Eskelson, B. N., Temesgen, H., & Barrett, T. M. (2009). Estimating ca-
vity tree and snag abundance using negative binomial regression
models and nearest neighbor imputation methods. Canadian Journal
of Forest Research, 39, 1749-1765. doi:10.1139/X09-086
Fan, Z., Larsen, D. R., Shifley, S. R., & Thompson III, F. R. (2003a).
Estimating cavity tree abundance by stand age and basal area, Mis-
souri, USA. Forest Ecolog y an d Ma nagement, 179, 231-242.
doi:10.1016/S0378-1127(02)00522-4
Fan, Z., Lee, S., Shifley, S. R., Thompson III, F. R., & Larsen, D. R.
(2004a). Simulating the effect of landscape size and age structure on
cavity tree density using resampling technique. Forest Science, 50,
603-609.
Fan, Z., Shifley, S. R., Spetich, M. A., Thompson III, F. R., & Larsen,
D. R. (2003b). Distribution of cavity trees in Midwestern old-growth
and second-growth forests. Canadian Journal of Forest Research, 33,
1481-1494. doi:10.1139/x03-068
Fan, Z., Shifley, S. R., Spetich, M. A., Thompson III, F. R., & Larsen,
D. R. (2005). Abundance and size distribution of cavity trees in sec-
ond-growth and old-growth central hardwood forests. Northern
Journal of Applied Forestry, 22,162-169.
Fan, Z., Shifley, S. R., Thompson III, F. R., & Larsen, D. R. (2004b).
Simulated cavity tree dynamics under alternative timber harvest re-
gimes. Forest Ecology and Management, 19 3, 399-412.
doi:10.1016/j.foreco.2004.02.008
Hand, D. J. (1997). Construction and assessment of classification rules.
New York, NY: Wiley.
Harrell Jr., F. E., Lee, K. L., & Mark, D. B. (1996). Multivariable prog-
nostic models: Issue in developing models, evaluating assumptions
and adequacy, and measuring and reducing errors. Statistics in Medi-
cine, 15, 361-387.
doi:10.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM168>3.
0.CO;2-4
Hertz, J. A., Krogh, A. S., & Palmer, R. G. (1991). Introduction to the
theory of neural computation. Redwood City, CA: Addison-Wesley.
Jensen, R. G., Kabrick J. M., & Zenner, E. K. (2002). Tree cavity esti-
mation and verification in the Missouri Ozarks. General Technical
Report GTR-NC-1227, US Department of Agriculture Forest Service,
114-129.
Johnson, R. A., & Wichern, D. W. (1992). Applied Multivariate Statis-
tical Analysis. Upper Saddle River, NJ: Prentice Hall.
Lawler, J. J., & Edwards, T. C. (2002). Landscape patterns as predictors
of nesting habitat: Building and testing models for four species of
cavity-nesting birds in the Uinta Mountains of Utah, USA. Land-
scape Ecology, 17, 233-245. doi:10.1023/A:1020219914926
McClelland, B. R., & Frissell, S. S. (1975). Identifying forest snags
useful for hole-nesting birds. Journal of Forestry, 73, 414-417.
Myers, R. H. (1990). Classical and Modern Regression with Applica-
tions. Boston: PWS Publishing Company.
Ripley, B. D. (1996). Pattern recognition and neural networks. Cam-
bridge: Cambridge University Press.
Sheriff, S. L. (2002). Missouri ozark forest ecosystem project: The ex-
periment. General Technical Report GTR-NC-227, US Department
of Agriculture Forest Service, 1-25.
Sheriff, S. L., & He, Z. (1997). The experimental design of the Missouri
Ozark Forest Ecosystem Project. General Technical Report GTR-
NC-193, US Department of Agriculture Forest Service, 26-40.
Titus, R. (1983). Management of snags and cavity trees in Missouri—A
process. Snag habitat management symposium. General Technical
Report GTR-RM-99, US Department of Agriculture Forest Service,
51-59.
Venables, W. N., & Ripley B. D. (1994). Modern applied statistics with
S-plus. New York: Springer-Verlag.
Wolpert, D. (1992). Stacked generalization. Neural Networks, 5, 241-
259. doi:10.1016/S0893-6080(05)80023-1
Copyright © 2012 SciRes.
224