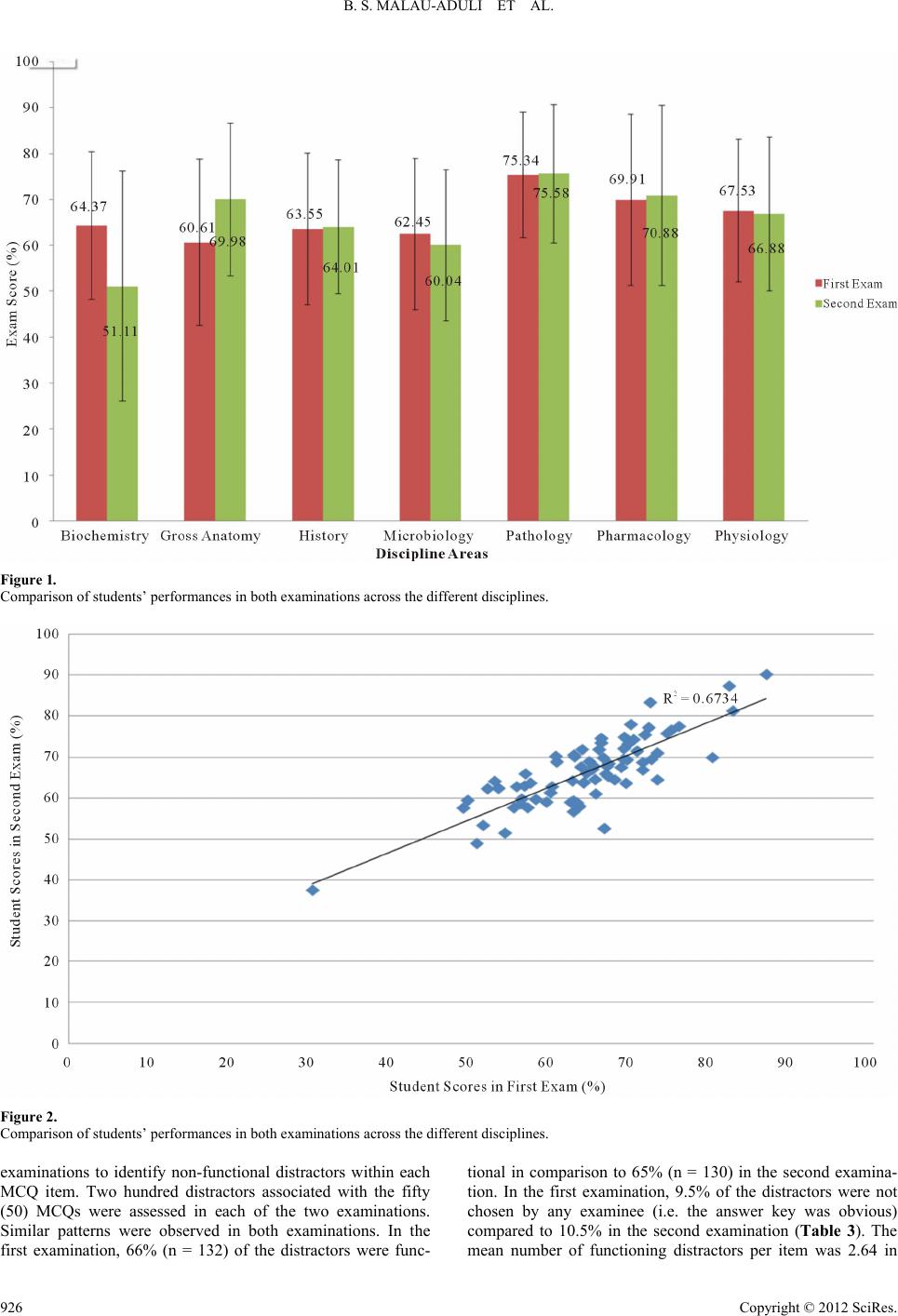
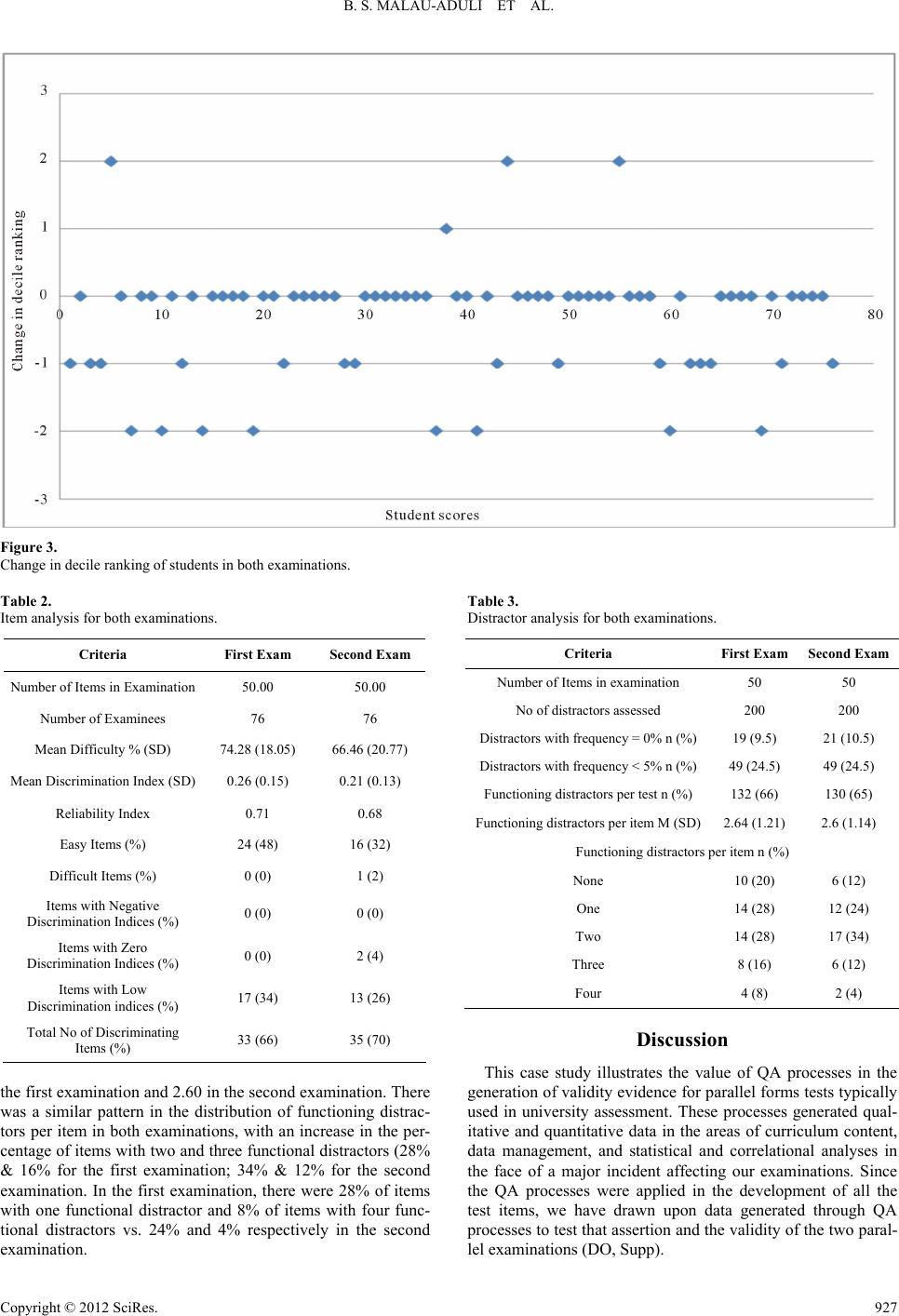
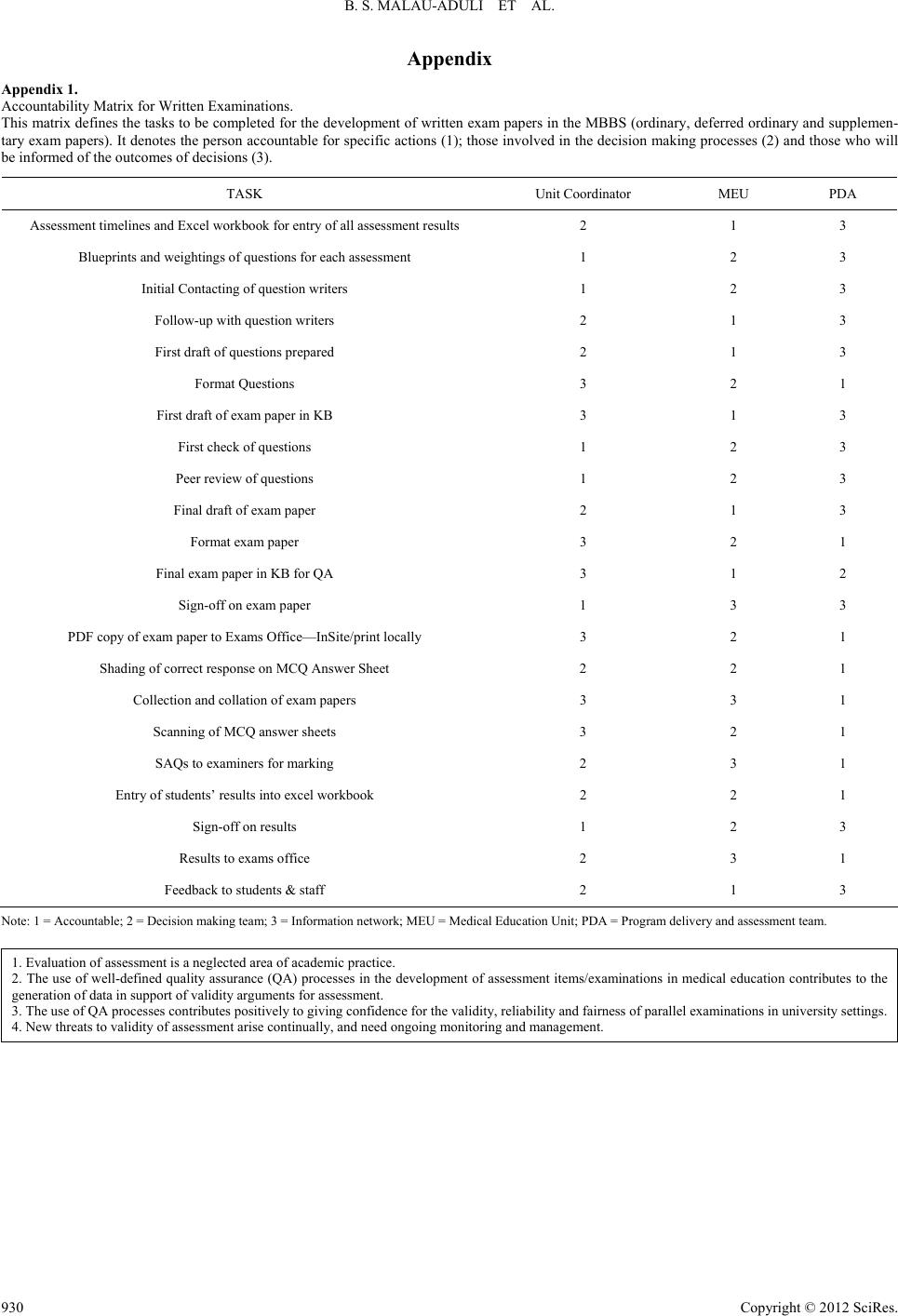
B. S. MALAU-ADULI ET AL.
cific mix of evidence needed for validation depends on the
inferences being drawn and the assumptions being made (Mes-
sick, 1989), and extends beyond the validity of the assessment
instruments that generate test score data. As assessment re-
gimes become more complex and the stakes related to assess-
ment outcomes increase, the greater the need for multiple
sources of data to support the validity of assessment. Our as-
sessment quality assurance (QA) processes were conceptualised
in line with current unitary validity theory (Kane, 2006; Down-
ing & Haladyna, 2009) to generate evidence for medium stakes
examinations. The requirement for validity evidence for as-
sessment through the early years of our medical course is mod-
est; however it peaks at the preclinical-clinical transition and
graduating examinations.
Academic staff is typically focused on writing questions
from their discipline, usually at the expense of the “bigger pic-
ture” and question quality. Curriculum content evidence for
validity relates to the selection of assessment instruments,
alignment of assessment tasks/items with intended learning
outcomes, sampling of items across domains of the curriculum,
examiner training and the quality of test items. Blueprinting
serves to guide the selection of specific assessment instruments,
strategies, and more importantly, their development through the
specification of the content to be assessed (Hamdy, 2006).
Blueprinting mitigates against two significant threats to validity,
“construct under-representation” (CU), the biased or under-
sampling of course content and “construct irrelevance” (CI). CI
may arise from a “systematic” error as a result of the poor
choice of assessment instrument for the outcomes being as-
sessed (Downing, 2002). But it may also affect a small propor-
tion of students if it arises from poor training of assessors and
role player/standardised patients such that students are not ex-
posed to the same test stimuli (e.g. at different sites) or assessed
in the same manner. In this case study, each of the examina-
tions were blueprinted to ensure representative and consistent
sampling across content domains and alignment with learning
outcomes (Jozefowicz et al., 2002; Hamdy, 2006; Hays, 2008),
assessors were trained, and internal peer review processes
(Malau-Aduli & Zimitat, 2011) were used to evaluate coverage
and to refine test items.
Ensuring the integrity of data arising from the administration
of assessment is key for any validity argument. In the first in-
stance, identity and fraud management tag assessment data to
the correct individual. The use of double data entry methods
and optical scanning forms with checking by software algo-
rithms improves the accuracy of data transfers. Software was
developed to automate some processes, particularly those re-
lated to generating psychometric reports and student feedback
increasing efficiency and decreasing chances for human error to
affect data management. The introduction of quality assurance
processes, assessment training manuals and automated report-
ing have all provided significant improvement in consistency of
data handling and greater confidence in systems.
Statistical and correlational analyses of assessment data pro-
vide important evidence to support or refute validity claims.
Item analyses—difficulty, discrimination and internal consis-
tency of the test, inter-rater reliability etc.—are routinely per-
formed as part of quality assurance processes to provide indices
of reliability (Tavakol & Dennick, 2011). Reliability refers to
the stability of test scores upon re-testing of examinees which is
a fundamental requirement for making meaningful interpreta-
tions of test data. Correlational validity evidence may be used
to assert positive relationships between performance on two
tests of similar abilities (e.g. as students progress through the
course), or conversely negative correlations between scores on
tests of different abilities. High stakes examinations have high
reliability thresholds, whereas it is moderate for many medical
course examinations except the final clinical examinations. In
our case study, statistical and correlational validity evidence are
routinely generated by the QA process.
The final type of data for validity evidence is drawn from the
decision making process and its consequences for examinees
and others. The documentation of standard setting processes,
standard error of measurement associated with cut scores and
use of coded candidate details all contribute to this evidence.
However it can also extend to correlation of assessment out-
comes with later assessments (specialty examinations) or ele-
ments of professional practice. Benchmarking of assessment
processes and graduate outcomes are more recent types of evi-
dence collected to support assertions of course quality as well
as assessment. Some of this data can be collected immediately,
and is part of our quality assurance processes, whereas data
relating to postgraduate activity falls within the realm of course
evaluation.
Context of the Case Study
The Tasmanian School of Medicine (TSoM) offers a five-
year case-based undergraduate medical degree. Vertical inte-
gration of the curriculum is promoted through a thematic struc-
ture usage in all the five years of the program. The first two
years of the course provide a systems-based introduction to the
foundations of medicine, with an early opportunity to develop
communication and clinical skills. Assessment involves forma-
tive and summative elements, with an emphasis on end of se-
mester examinations. Well-developed QA processes around
assessment (Malau-Aduli et al., 2011) were implemented at the
TSoM in 2009 by the Medical Education Unit (MEU). These
processes included blueprinting of educational objectives, se-
lecting appropriate test formats and applying assessment strate-
gies to achieve adequate levels of reliability. They also included
the implementation of appropriate standard-setting, assessor
and role-player training, decision-making procedures and peer
review of assessment items to minimise item writing flaws
prior to being administered to students (Malau-Aduli et al.
2011).
This case study refers to an examination at the end of the
second year of the medical course. QA processes were followed
and the three parallel written examination papers (OE, DO and
Supp) were developed by faculty at the same time. The univer-
sity central Examination Office set up new processes to facili-
tate automated printing of examination papers at the same time
as the TSoM established the new QA processes around assess-
ment. The independent and simultaneous introduction of the
two new systems in the TSoM and the Examination Office
resulted in the automated printing of the examination papers
(OE) with answers on them. The examination was re-adminis-
tered to all students using the DO paper. Students were also
offered the opportunity to “resit” the examination in 3 days,
using the Supp paper. On the basis of fairness, their result was
based upon the highest score achieved on either examination.
This rare occasion of administering a “repeat” examination to
the same cohort of students provided an ideal opportunity to
evaluate the School’s assessment practice, using parallel forms
Copyright © 2012 SciRes.
924