Paper Menu >>
Journal Menu >>
 Modern Economy, 2012, 3, 686-689 http://dx.doi.org/10.4236/me.2012.35088 Published Online September 2012 (http://www.SciRP.org/journal/me) An Improved Fuzzy ISODATA Algorithm for Credit Risk Assessment of the EIT Enterprises* Jike Yu, Zongfang Zhou#, Hua Zhong, Huizhong Huang School of Management and Economics, University of Electronic Science and Technology of China, Chengdu, China Email: #zhouzf@uestc.edu.cn Received July 5, 2012; revised August 6, 2012; accepted August 17, 2012 ABSTRACT We proposed an improved fuzzy ISODATA algorithm for credit risk assessment of the emerging information technol- ogy enterprise in this paper. Firstly, as the uncertainty of th e EIT en terprise is relativ ely la rge, we set a reference sample and an initial clustering center matrix so that we overcame the shortcomings of traditional ISODATA algorithm and improved the reliability of fuzzy clus tering analysis. Secondly, we proposed the step s of evaluating the EIT enterprises’ credit risk with improved fu zzy ISODATA algorithm. Last but not least, we assessed 10 EIT enterprises’ credit risk of a certain city, which proved the effectiveness and op erability. Keywords: EIT Enterprise; Credit Risk; Reference Sample; ISODATA Algorithm; Fuzzy Clustering 1. Introduction Emerging Information Technology (EIT) is defined as a technology that can innovate or upgrade the function, pr o d- uct, or service of information technology by using the ba- sic principles and methods of information science, as well as with the technical characte ristics of emerging technolo - gies [1]. As there are uncertain elements like the EIT it- self, product market of the EIT enterprise and so on, the EIT enterprises are facing large credit risk [2,3]. Credit is the inevitable product of social economic de- velopment, and is also an essential part of modern social economy. Credit risk is the possibility that a bond issuer or borrower will default b y failing to repay princip al and interest in a timely manner, lead ing to a lo ss to a bank , or investors. EIT enterprises are the typical venture business. To make objective and comprehensive assessment of thei r credit risk is not only necessary foundation for a smooth financing, but also the essential part for the EIT enter- prises’ risk management. The current credit risk assessment models are Credit Metrics, Credit Risk+, KMV, multi-objective decision mak- ing, non-parametric statistical methods, neural network a nd so on. Using fuzzy clustering analysis for corporate c redit risk assessment is non-parametric statistical methods [4, 5]. It’s especially in kinds of methods are unsure of the overall distribution function, with good results. The cur- rent literatures usually no longer evalu ate the merits after classify the target objectives with fuzzy clustering me- thod, or they consider all indicators as efficiency indica- tors in the ratings analysis, and the classification is ac- cording to the properties of specific target range set. Ac- cording to this current way, it is possible that the credit rating results are different, if we cluster and rate the same EIT enterprise separately with two (or more than two) groups of the EIT enterpri ses with different qualification s as one target set. Especially in the case that there is very small number of objects in one group, the possibility tha t this situation happens is huge, which reduce the ob- jectivity of the EIT enterprise credit risk assessment. On the other hand, as an EIT enterprise is usually in initial period of foundation, there is large uncertainty of its grow- ing and development, and the index data used to assess its credit risk is usually incomplete which need to set up a corresponding reference sample system firstly. Refer- ence sample system is an objective standard for the spe- cific requirement of the EIT enterprise credit risk assess- ment, which is set as ide al value of every characteristic of every grade, used to stu dy t he targe t clu s t e ring. Curr e ntly , there are few literatures about the EIT enterprise credit risk assessment. In view of this, we’ve improved the traditional fuzzy clustering method through setting the reference sample s y s- tem of the EIT enterprises, and hav e proposed an imp r o v e d fuzzy clustering algorith m to cluster the credit risk of the EIT enterprises. Example shows that the improved algo- rithm solves the problem of insufficient ob jectivity of th e traditional fuzzy clustering method applied in the credit risk assessment in a certain extent. *This research has been supported by National Natural Science Foundation of China (No.70971015), The Special Research Foundation of PhD Program of Chin a (2011 0185110021). #Corresponding author. C opyright © 2012 SciRes. ME  J. K. YU ET AL. 687 2. Fuzzy Cluster Analysis Fuzzy ISODATA (I terative Self-Organizing Data Analy- sis Techniques Algorithm) is an interactive sel f- org ani zin g data analysis technique for fuzzy cluster [6,7]. Cluster using standard Fuzzy ISODATA works as follow, suppose classes’ number has been decided, and choose an original fuzzy cluster matrix, calculate optimal fuzzy cluster ma- tr ix a nd optimal cluster center matrix using iterative opera- tion, then classify the inspected object. The algorithm re- quires more stringent selection of original fuzzy cluster matrix. Inappropriate selection would cause distortion in iterative process. There are limitations when standard fuzzy ISODATA was used in the scene of rating of target object. The algorithm can only cluster object into specific classes, but can’t discriminate whether classes meet the “meaningful distance”. Based on this, reference sample system and investigation sample will be collected to be cluster. Improved fuzzy ISODATA algorithm steps are as follows: 1) Establish the original characteristic indicators ma- trix U* that descript each attribute value of all inspected object and r eference samples. ij is on behalf of the cha r- acteristic indicators j of object i. * u ** * , , 2) Standardize the data of original characteristic indi- cators matrix U* by range method to get U, define 12 12 ** * max ,, ;min j jjnj jjjnj M uuu muu u for column j of U*, calculate uij using formula (1) ij j ij j j um u M m 0 V0, 1,2,l l (1) 3) Start iterative operation based on original cluster center matrix of reference sample sy stem, . 4) Calculate fuzzy classified matrix using formula (2), where c is on behalf of classes number. And based on R Euclid distance, 12 2 kjij u v 1 m ki j uV , 2 L ki l kj uV uV l R 11 ,, T ll c VV 1 c l ik j r (2) 5) Modify cluster center matrix for , 11 12 ll VV , where 2 1 2 1 () () nl ij k k nl ij k ru r 1l R ik rr 1l i V (3) 6) Repeat step 2), compare and , for given l R 1ll precision ε > 0, if max ik 1l R 1l V 1ll 12 ,,,T c VVV V k uU , iterative opera- tion should be stopped and should be out- putted. In opposite condition, , repeat step 3). 7) Get fuzzy cluster based on optimal cluster center matrix discrimination principle--suppose the optimal cluster center matrix ,, if 1 min kik j jc uV uV ,,, m Ppp p , object u k should be classified to class i. 3. Assessment Steps of Integration of Rough Set and Improved Fuzzy Clustering The evaluation indicators should be screened at first w he n we assess the EIT enterprises’ credit risk. Based on indi- cators screening, the application of improved fuzzy ISO- DATA algorithm for classification of the EIT enterprises credit risk would have a better result. The following are specific steps of assessing and classifying the EIT enter- prises credit r isk with attribute reduction method from i n te - gration of rough set theory and improved fuzzy ISODATA algorithm: 1) Establish an initial set of assessment indicators and sample set to be inspected. Suppose 12 is the initial set of assessment indicators, and ,,, 12 n X xx x 0 V is the sample set. aij is the value of assessment indicator j of sample I; 2) Discretization of data aij; 3) Attribute reduction to the indicator set with applica- tion of rough set theory [8,9]; 4) Establish a proper reference sample set, and con- struct an initial clustering center matrix ; 5) Add the reference sample set into sample set to be inspected, and cluster all the samples with above-mentio- ned improved fuzzy ISODATA algorithm in order to a ch- ieve risk rating of the EIT enterprises. 4. Case Analysis We assessed credit risk of 10 EIT enterprises (denoted by A, B, C, D, E, F, G, H, I and J) in certain city. Firstly, choose 4 primary-level indicators and 15 secondary indic- ators, according to systematic, scientific, operational, obje- ctive principle as well as a combination of quantitative and qualitative principle, and referring the evaluation indexes system of emerging technology enterprise credit risk [1]. They are financial benefits status indicator (P1): ROE (P11), ROA (P12), asset maintenance and appreciation indicator (P13), OPE (P14); assets operating state indicator (P2): total asset turnover (P21), current assets turnover (P22), inventory turnover (P23), receivable accounts turnover (P24); debtpaying ability indicator (P3): asset-liability ratio (P31), acidtest ratio (P32), cash flow debt ratio (P33); development state indicator (P4): sales growth rate (P41), capital accumulation rate (P42), the average growth rate of capital (P43) and the ability of technological innovation and application (P44). The data is from the financial statements of 10 EIT enterprises, except (P44) is through experts grading. Copyright © 2012 SciRes. ME 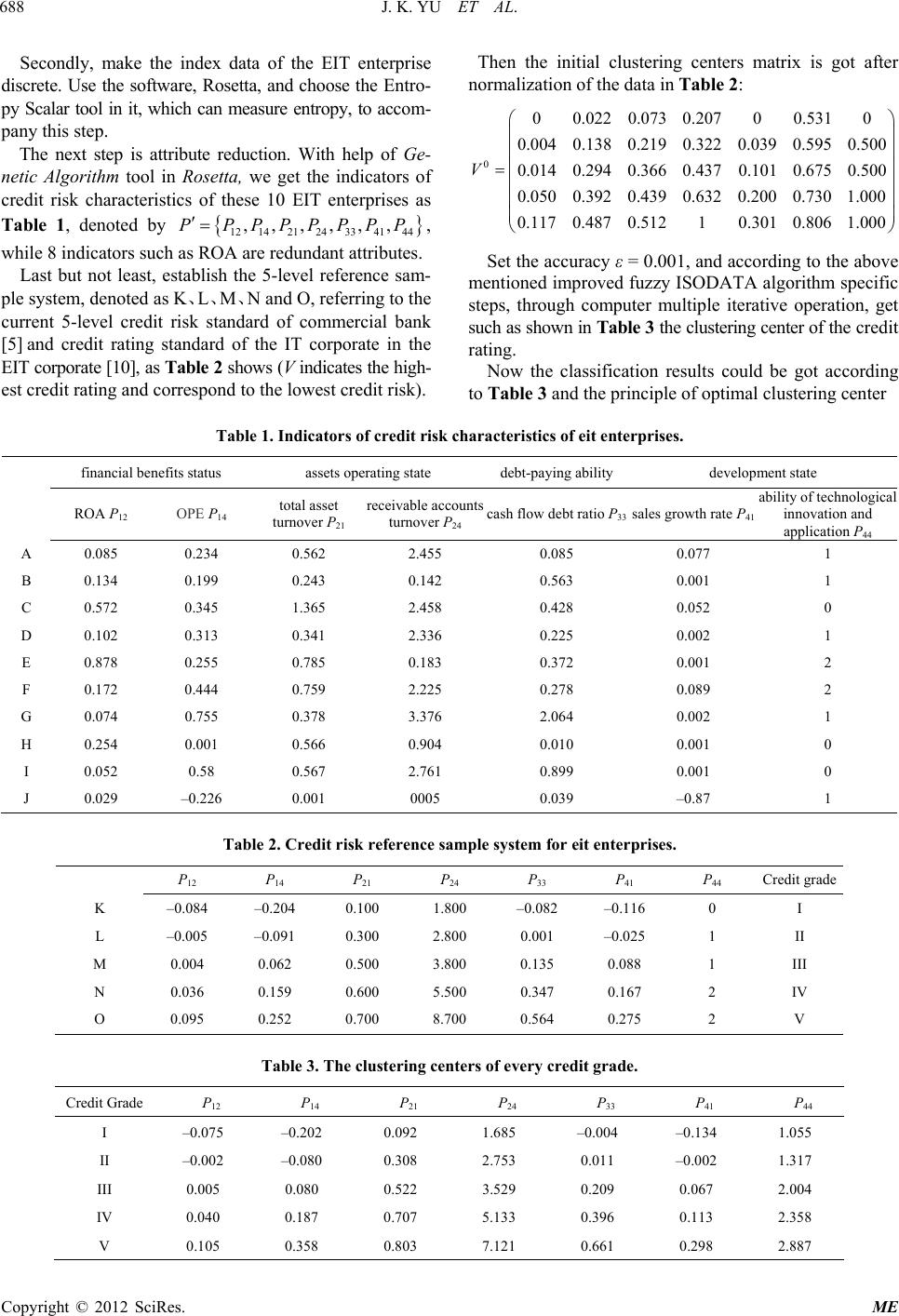 J. K. YU ET AL. Copyright © 2012 SciRes. ME 688 3341 44 ,,,PPPP 0 00.0220.073 0.20700.5310 0.004 0.138 0.219 0.322 0.039 0.595 0.500 0.014 0.294 0.366 0.4370.1010.675 0.500 0.050 0.392 0.439 0.632 0.200 0.7301.000 0.117 0.487 0.51210.3010.8061.000 V Set the accuracy ε = 0.001, and according to the above m classification results could be got according to Table 1. Indicators of credit riskharacteristics of eit enterprises. development state Then the initial clustering centers matrix is got after normalization of the data in Table 2: Secondly, make the index data of the EIT enterprise discrete. Use the software, Rosetta, and choose the Entr o- py Scalar tool in it, which can measure entropy, to accom- pany this step. The next step is attribute reduction. With help of Ge- netic Algorithm tool in Rosetta, we get the indicators of credit risk characteristics of these 10 EIT enterprises as Table 1, denoted by , while 8 indicators such as ROA are redundant attributes. 12 1421 24 ,,,PPPP Last but not least, establish the 5-level reference sam- ple system, denoted as K、L、M、N and O, referring to the current 5-level credit risk standard of commercial bank [5] and credit rating standard of the IT corporate in the EIT corporate [10 ], as Ta ble 2 shows (V indicates the high- est credit rating and correspond to the lowest credit risk). entioned improved fuzzy ISODATA algorithm specific steps, through computer multiple iterative operation, get such as shown in Table 3 the clus tering cente r of the c r edi t rating. Now the Table 3 and the principle of optimal clustering center c financial benefits status assets operating state debt-paying ability ROA P12 OPE P14 total asset turnover P21 receivable accounts cash flow debt ratio P33 sales g r owth rate P41 chnological turnover P24 innovation and application P44 ability of te A 0.085 0.234 0.562 2.455 0.085 0.077 1 B 0.134 0.199 0.243 0.142 0.563 0.001 1 C 0.572 0.345 1.365 2.458 0.428 0.052 0 D 0.102 0.313 0.341 2.336 0.225 0.002 1 E 0.878 0.255 0.785 0.183 0.372 0.001 2 F 0.172 0.444 0.759 2.225 0.278 0.089 2 G 0.074 0.755 0.378 3.376 2.064 0.002 1 H 0.254 0.001 0.566 0.904 0.010 0.001 0 I 0.052 0.58 0.567 2.761 0.899 0.001 0 J 0.029 – 0.2260.001 0005 0.039 –0.87 1 Table 2. Credit risk reference sle system for eit enterprises. P12 14 21243341P44 Credit grade amp PP P P P K – – 0 1 – – 0.0840.204.100.8000.0820.1160 I L –0.005 –0.091 0.300 2.800 0.001 –0.025 1 II M 0.004 0.062 0.500 3.800 0.135 0.088 1 III N 0.036 0.159 0.600 5.500 0.347 0.167 2 IV O 0.095 0.252 0.700 8.700 0.564 0.275 2 V Table 3. The clustering cers of every credit grade. Credit Grade P12 P14 P21 P24 P33 P41 P44 nte I –0–0.0.1.–0.–0.1..075 202 092 685 004 134 055 II –0.002 –0.080 0.308 2.753 0.011 –0.002 1.317 III 0.005 0.080 0.522 3.529 0.209 0.067 2.004 IV 0.040 0.187 0.707 5.133 0.396 0.113 2.358 V 0.105 0.358 0.803 7.121 0.661 0.298 2.887  J. K. YU ET AL. 689 le 4. The fications. Crses Tabclassi result edit Grade EIT Enterpri I B G J K II A D L III C E I M H IV F N V O matrix discrimion, shown in Table 4zzy I SOD sample system in this paper overc ome s center matrix, talculati initial classifica- REFERENCES [1] Z. F. Zhou, and Evaluation of Credit Risk fo Companies,” Sci- oject,” Journal of embership Cloud Gravity Center,” ICISE and Credit Control,” Oxford University Press, mic and Trade University ss, New York, 1981. n a,” Kluwer Academic Publishers, Dordrecht, Set Data Mining,” Microcomputer Information, icators,” ICCS 2008, inat . In this case, accord ing to the tradi tional fu algorithm that leaves out reference sampleATA Emerging Trends in Computing and Information Sciences, Unpublished. [3] J. Yu, Z. Zhou, et al., “Study on Evaluation for EIT Pro- ject Based on M system, 10 in- vestigated EIT enterprises must be assigned into 5 credit grades. In the case of V, at least one enterprise would be assigned into this highest level. Actually, only pre-set reference sample existed in grade V, and 7 property val- ues of all cluster centers are close to corresponding attri b- ute values of reference samples, more than that, 5 refer- ence samples are assign ed to correc t credit grad e after c l u s- tered with credit risk indicators of other 10 investigated EIT enterprises. Through comparative analysis, results ob- tained by the improved algorithm stated in this paper are more appropriate for EIT enterprises realities. 5. Conclusion Setting a reference Chi the situation that when a same EIT enterprise forms clus- tering set separately with other EIT enterprises with dif- ferent qualifications, it will show different assessment re- sults, and also increase the objectivity of the EIT enter- prises’ credit assessment. At the same time, it is proved that the possible distortion brought by a random selection of initial fuzzy classification matrix could be avoided, if we accord to the improved method that pre-set the refer- ence sample system and determine the initial clustering tion matrix, which increase the reliability of fuzzy clus- tering analysis for the EIT enterprise credit risk. hen cng thefuzzy et al., “The Evolution r Emerging Technology ence Press, Beijing, 2010. (in Chinese) [2] J. Yu, Z. Zhou, et al., “The Ordering Structure of Evalua- tion Indexes Sequences for the EIT Pr 2011. [4] M. Lundy, “Cluster Analysis in Credit Scoring, Credit Scoring New York, 1993. [5] H. Lin and M. Xia, “Enterprise Credit Rating of Theory and Practice,” Foreign Econo Press, Beijing, 2003. (in Chinese) [6] J. C. Bezdek, “Pattern Recognition with Fuzzy Objective Function Algorithms,” Plenum Pre [7] S. Chen, J. Chen and X. Wang, “The Fuzzy Set Theory and Its Application,” Science Press, Beijing, 2005. (i nese) [8] Z. Pawlak, “Rough Set: Theoretical Aspects of Reasoning about Dat 1991. [9] X. Xu, et al., “Based on the Fuzzy Toolbox and Rosetta’s Rough Vol. 23, No. 18, 2007, pp. 174-178. [10] Y. Zhang, Z. Zhou and H. Tang, “An Selection Method of the ETF’s Credit Risk Evaluation Ind Kraków, 2008. Copyright © 2012 SciRes. ME |