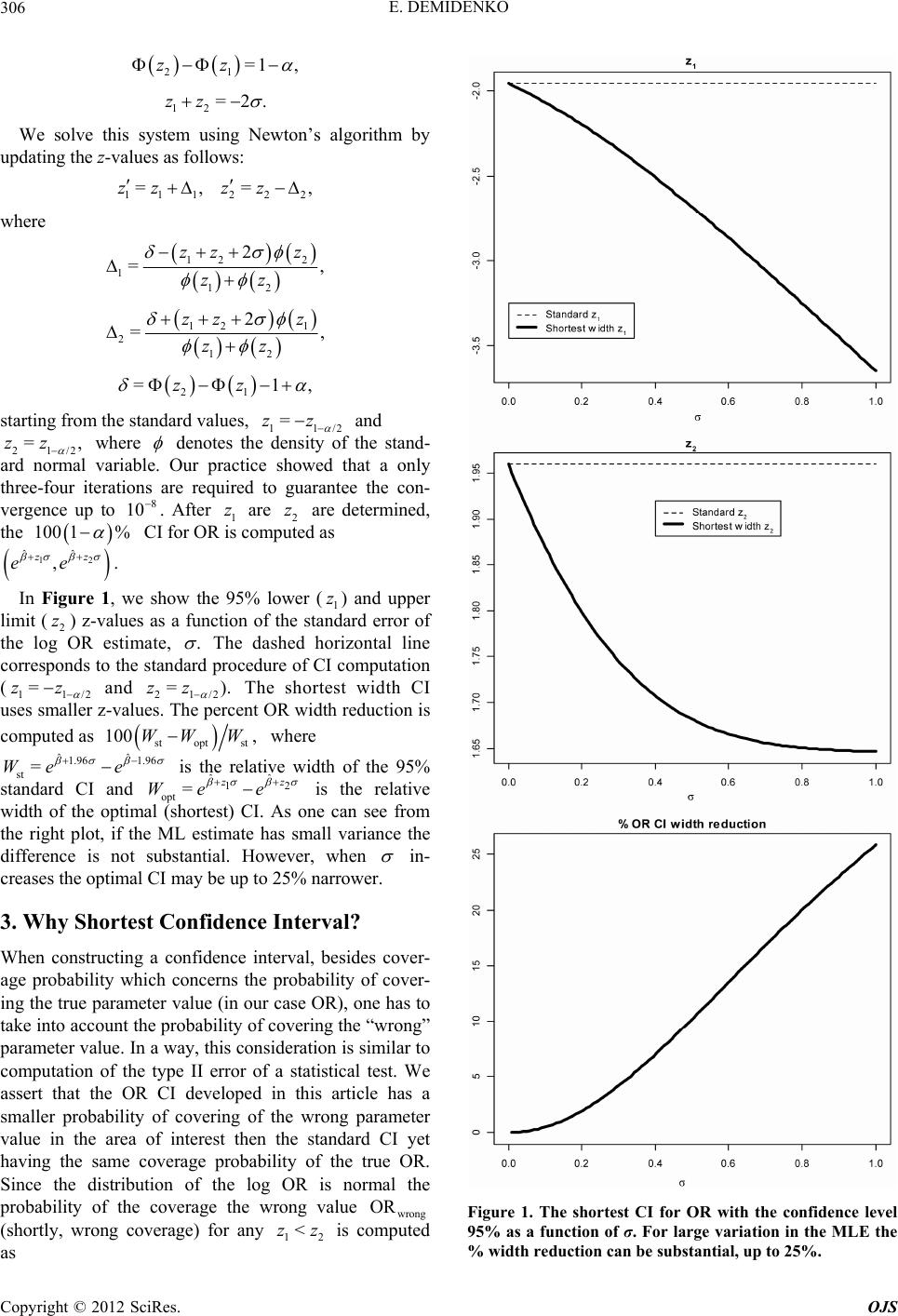
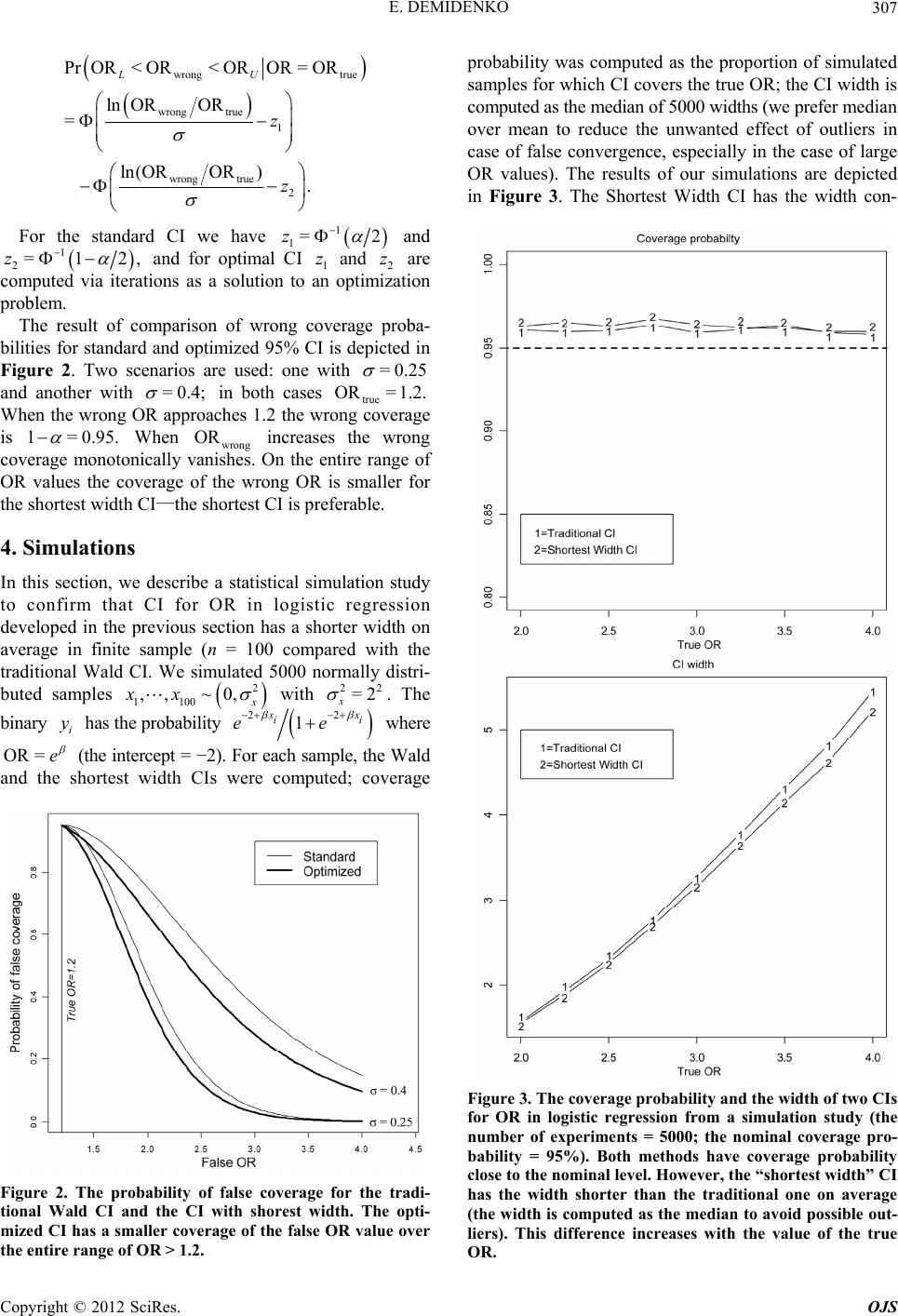
Open Journal of Statistics, 2012, 2, 305-308
http://dx.doi.org/10.4236/ojs.2012.23037 Published Online July 2012 (http://www.SciRP.org/journal/ojs)
The Shortest Width Confidence Interval for Odds Ratio
in Logistic Regression
Eugene Demidenko
Section of Biostatistics and Epidemiology, Geisel School of Medicine at Dartmouth, Hanover, USA
Email: eugened@dartmouth.edu
Received May 16, 2012; revised June 18, 2012; accepted July 2, 2012
ABSTRACT
The shortest width confidence interval (CI) for odds ratio (OR) in logistic regression is developed based on a theorem
proved by Dahiya and Guttman (1982). When the variance of the logistic regression coefficient estimate is small, the
shortest width CI is close to the regular Wald CI obtained by exponentiating the CI for the regression coefficient esti-
mate. However, when the variance increases, the optimal CI may be up to 25% narrower. It is demonstrated that the
shortest width CI is favorable because it has a smaller probability of covering the wrong OR value compared with the
standard CI. The closed-form iterations based on the Newton’s algorithm are provided, and the R function is supplied.
A simulation study confirms the superior properties of the new CI for OR in small sample. Our method is illustrated
with eight studies on parity as a preventive factor against bladder cancer in women.
Keywords: Bladder Cancer; Coverage Probability; Logistic Regression; Newton’s Algorithm
1/2 1/2
ˆˆ
,
zz
1. Introduction
Odds ratio, as the exponentiated logistic regression co-
efficient, is a popular measure of association in medicine,
epidemiology and biostatistics. Routinely, the confidence
interval (CI) for odds ratio (OR) in logistic regression is
computed by exponentiating the CI for the beta-co-
efficient (log OR, hereafter denoted as
), [1,2]. While
it is true that if a CI for
has coverage probability
1
the exponentiated CI for OR has the same
coverage probability, such CI does not have the shortest
width and therefore can be improved. The goal of this
note is to demonstrate how to compute the shortest CI for
OR using a theorem proved in [3]. Previously, [4] sug-
gested to find the shortest confidence interval for OR
using the same approach but their procedure of minimi-
zation of the interval’s width was just an approximate
solution. In this paper, we find the exact minimum via
Newton’s iterations.
2. The Method
Let the coefficient of logistic regression
be estimated
by maximum likelihood (ML) so that
2
ˆ,
OR =
in
large sample. We want to construct the shortest CI for
e
based on ˆ
assuming that its variance 2
is known. In practice, this variance is not known but
usually the sample size is large enough, so that one can
assume that 2
is fixed. Routinely, one first constructs
the CI for
100 1
%
as
and then exponentiates it to ob-
100 1%
CI for OR as tain the
1/2 1/2
ˆˆ
,,
zz
ee
1/2
z
where is the
12
th
quantile of the standard normal cdf,
1
=12,z
=0.05
1/2
where is the cdf of the stand-
ard normal distribution. For example, if
we
have 1/2
This CI will be refered to as the
(traditional) Wald CI with symmetric z-values.
=1.96.z
1,
The idea of the shortest CI is to chose asymmetric
z-values such that the coverage probability is the same,
but the length of the CI is minimum. Thus we
seek CI for OR in the form
12
ˆˆ
,
zz
ee
12
<zz
(1)
where are such that
21
=1zz .
21
=zz
(2)
. Clearly, the standard CI has the form (1) with
Since the width of interval (1) is OR we
21
,
zz
ee
arrive at the following optimization problem:
21
min zz
ee
(3)
under restriction (2). As was shown by Dahiya and Guttman
(1982), this optimization problem reduces to the solution
of the following system of equations for z1 and z2:
C
opyright © 2012 SciRes. OJS