Circuits and Systems
Vol.05 No.09(2014), Article ID:49256,11 pages
10.4236/cs.2014.59024
The Load Balancing Network Service in Cloud Data Centre Environments Risk and Vulnerability Analysis
Mohammad A. Al-Rababah
Northern Border University, Arar, KSA
Email: hamzehamerah@yahoo.com
Copyright © 2014 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 6 July 2014; revised 8 August 2014; accepted 15 August 2014
ABSTRACT
Data centre is the consolidation point for provisioning multiple services that drive an enterprise business processes. A discrete event based process model of a reengineered data centre communication network comprising of four data centre LAN nodes with an inclusion of a virtualization server for creating virtual instances of resources and applications for DCN nodes was analyzed and presented. This is reflected in the response of the two options: crash recovery (DCN) disaster recovery and cloud in the cloud data centers data centre networks. Based on the results of this study, it was observed that the former have 99% of the bandwidth of the index and, at a later date. Present work is about the load balancing network service in cloud data centre environments using throughput metric index. There is some related technical knowledge discussed such as cloud application framework and load balancing methods. And at last throughput responses are evaluated by experiments.
Keywords:
Cloud-DCN, Traffic, Throughput, Web, Service, Load, Data Centers Simulation

1. Introduction
Cloud computing, has worn off, leaving those that are required for cloud computing implementation of the directive, in this sense, in the Valley of despair. When the advertising fat free from cloud computing―private, public or hybrid―left a large, virtual data centre with him, ranging from limited to nonexistent in private cloud deployments, it maintains some control, but as all the architectural parameters of management to systems were creatures use clouds. A public cloud is not one stitch of a cloud infrastructure within the framework of organizational management, the implementation of a joint work, of course, suffers both limited in various ways. The relationship was with a business process, rather than on the details of the access layer, traffic balancing in order to gain a competitive advantage from their network systems. In the business process of our previous proposals on EETACP as shown in Figure 1 their criteria using public deployment, critical for mission-critical applications are fault tolerance in a cloud environment.
Although work has been on a large scale network computing such congestion data center management (TCP/ IP network) and fault tolerant designs [1] [2] , the clouds are intended to drive the design of next-generation data center architectures as network services virtual hardware, database, user interface, application logic, so that users can access and deployment of applications from anywhere in the world at the best price on request depends on the quality of service requirements [3] . Developers of innovative ideas for new Internet services no longer required a large investment in equipment to deploy their service or individual account.
Cloud balancing: the evolution of global server load balancing of this future is not so far away as it may seem [4] .
Global server load (GSLB) and global DNS functionality, which was in place for a very long time, given the right architecture, is also valid in the cloud balancing. The essence of both is to present a single DNS for different locations and determine the best place to service your application when the client connects. Consider the scenario of a simple web application that must be available 24 × 7 and must be filed as soon as possible. Customers enter personal Information (PII) in the application, so that the data should be guaranteed regardless of where he lives [5] .
1) Consumer/broker: cloud consumers or their brokers to submit service requests from anywhere in the world in cloud. It is important to note that it can be the different between cloud consumers and users of deployed services. The consumer can be a company to deploy a web application that presents different loads and the number of “users”, and accesses to it.
2) Green negotiator: talks with customers/brokers completing the CCA with the price and punishment (for violating SLA) between the cloud provider and consumer depending on the quality of service requirements of consumers and energy-saving schemes. In the case of web applications, such as QoS metrics can be 95% of the requests people he served in less than 3 seconds.
・ The service analyser: interprets and analyses the requirements of service which has been requested before deciding whether to accept or reject it. Therefore it needs to load the latest information and energy from energy monitor and System Centre Virtual Machine Manager respectively.
・ Profiler users: collects the specific characteristics of the consumers, to ensure that mission-critical users can be granted with special privileges and discounts on other consumers.
・ Price: decides how to manage service requests and computing resources and demands help to prioritize the allocation of rooms effectively.
・ Energy monitor: monitors and determines which physical machines need to be powered on/off.
・ Scheduler service: assigns requests to VMs and determines the material resources for the selected virtual machine. He also decides when virtual machines are added or deleted to meet the demand.

Figure 1. Automated cloud balancing.
3) Physical Machines: basic physical computing servers providing the hardware infrastructure for creating virtualized resources to meet the needs of the service [6] [7] .
1.1. Research Hypothesis, System Design and Assumptions
1) Research Hypothesis. There is a significant variation in the throughput index of a cloud datacenter network with a failure recovery service compared to the one with no failure recovery service.
2) System Model and Description. The users X1∙∙∙Xn+1 utilize a single gateway to reach the Internet. In this model, the gateway f(x) and f(y) are multilayer series switches where f(x) represents the client gateway, and f(y) represents the server gateway; however, a Layer-3 router can serve same purpose as it can be used interchangeably with multilayer switch. The server gateway represents a single point of failure on this network. In the absence of a fault tolerate gateway, if that gateway fails, users will lose access to all resources beyond that gateway. This lack of redundancy in such networks is unacceptable on business-critical systems that require maximum uptime [8] . Detailed discussion on server load balancing, otherwise referred to as clustering service is discussed below as shown in Figure 2.
1.2. Server Load Balancing (SLB)
1) SLB provides the IP address of the virtual server to which clients can connect, representing a group of actual physical servers in the server farm. The basic concept of SLB. A client contacts a “virtual” logical server (IP address v. v. v. v), that exists only within the Catalyst 6500 configuration SLB. A group of physical servers are “real” (IP address x. x. x. x, y, y, y y and z. z z. z) is configured in the server farm. Traffic flows between the client and the virtual server are distributed through a set of real servers, transparently to the clients.
2) Hot Standby Router Protocol (HSRP).
3) Virtual Router Redundancy Protocol (VRRP).
1.3. Gateway Load Balancing Protocol (GLBP)
To overcome flaws in HSRP and VRRP, Cisco has developed anOh so your own gateway loads balancing protocol (GLBP). Routers or multilayer switches are added to the Group.
GLBP but unlike HSRP/VRRP, all routers are active. Thus, redundancy and load balancing is achieved. GLBP uses the multicast address 224.0.0.102.As with HSRP and VRRP, GLBP routers are placed in groups (1 - 255). Routers are assigned a priority (default is 100) router with high priority becomes the active virtual gateway (AVG). If priorities are equal, the router with the highest IP ADDRESS on the interface will be the AVG.
Routers, GLBP group are assigned a single virtual IP address. Host the device will use the virtual address of

Figure 2. System model for cloud datacenter network.
the default gateway and will broadcast an ARP request to determine the MAC address of the virtual IP address. Elected AVG router listens for ARP requests. In addition to the AVG up to three other routers can be elected as Active Virtual forwarders (APF). AVG assigns each AVF (including the virtual MAC address), for a maximum total of 4 virtual MAC addresses. When a client makes a request of ARP, AVG will provide customer with a virtual MAC address. Thus load balancing can be achieved. Not restricted to the four GLBP routers. Any router, the APF will be elected not secondary virtual forwarder (SVF) and wait for the standby mode until the APF cannot be.
1.4. Advantages of GLB in Cloud-DCN
Some of the identified benefits of GLB in the Cloud computing environment include:
1) Efficient use of network resources: several ways upstream of the locks can be used simultaneously.
2) Improved accessibility: GLBP provides advanced redundancy, eliminating the single point of failure of the first-hop gateway. Advanced tracking features of objects can be used with GLBP for redundancy implementation reflects the capabilities of the network. This same feature is also available to HSRP and VRRP.
3) Automatic load balancing: Off-net traffic is distributed among the available host-based gateways, under a certain load-balancing algorithm.
4) Reduce the cost of administration: because all nodes on a subnet can share gateway by default, while still load balancing, administration of multiple groups and gateways are not required.
5) Easier access layer design: more efficient use of resources is possible now without configuring additional virtual LANs and subnets. GLBP may be used if the IP hosts on the local network have a default gateway configured or learned via DHCP. This enables them to send packets to nodes on other network segments during the balancing of traffic among multiple gateways [9] [10] .
2. System Design
In designing a fault tolerant cloud datacenter, the main goal is to maintain high throughput with near zero downtime. It should be stable and robust. In the following, goals are explained in details [11] :
・ High Throughput: Since the demand for data exchange and resources in cloud environment is enormously high compared with other networks, throughput maximization is indispensable, and this is characterized by maximized link utilization.
・ Stability: The stability of a system in general depends on the control target [12] . Since, server centric datacenters are involved in high speed computations; our design objective must consider the respective individual flows and convergence rates of the links in active states.
・ Low Queuing Delays: Since, the server’s supports and runs mission critical applications, the higher the throughput, the higher the link utilization which often leads to long queuing delays. As such, to avoid or maintain the delays within the lowest threshold while achieving, high utilization, the load balancer must be configured to optimize these variables.
Assumptions/Design Specifications
Our design will focus on the two layers: access layer and GLB/speed redundancy layer. Recall that MLS is the major component in the GLB/speed redundancy layer, while servers interconnected through gateway, are the major components of the GLB/Speed core layer. The Cloud-DCN port architectural model overview is shown in Figure 3. Thiswill facilitatethe understanding of the model specifications described [13] . The model specifications are as follows:
・ Let C_DCN be an acronym chosen for the Cloud-DCN. C_DCN was designed to have four subnets (subnet 1 - 4) which were called C_DCNsa, C_DCNsb, C_DCNsc, C_DCNsd. where s is a subnet factor such that s > 0. Each C_DCN uses High Performance Computing (HPC) servers and a Multi-Protocol Label Switch (MLS) layered in linearly defined architecture. Since our designing of datacenter network is for efficient server load balancing and application integration, we will need one (4-port) MLS switch and few servers, hence, the choice of four subnets. Virtual server instances running on the HPC servers made up for further need of hardware servers in the network.
・ Servers in C_DCNs are connected to MLS port of the load balancer corresponding to it, and owing to the

Figure 3. Network NET1 (192.168.0.0/24), a network of NET2 (10.0.2.0/24), you want to create the balancing routers R1 and R2 through virtual IP GLBP 192.168.0.254 network NET1and NET2 network 10.0.2.254.
running virtual instances Vi, a commodity 4-port switch with 40 GB/s per port serve the design purpose. Also, each of the C_DCNs is interconnected to each other through the MLS switch ports.
・ The virtualized server used in this work has two ports for redundancy (in Gigabytes). Each server is assigned a 2-tuple [a1, a0] in consonance with its ports (a1, a0 are the redundant factors) together with a VLAN ID (1 to 1005).
・ Cisco Ws-C3560-44Ps-E IOS version 12.2 was the MLS used in this work, hence, the number 1005 is the maximum number of VLAN that can be created in it. The switch is a multilayer commodity switch that has a load balancing capability. This capability together with its VLAN capability was leveraged upon to improve the overall Cloud-DCN stability.
・ Each server has its interface links in Cloud-DCNs. One connects to an MLS, and other servers connects as well but all segmented within their subnets its VLAN segmentation, see figure
・ C-DCNs servers have virtual instances running on it and are fully connected with every other virtual node in the architecture.
3. Cloud-DCN Construction Algorithm
The C-DCN recursive construction algorithm has two sections. The first section checks whether C-DCNs is constructed. If so, it connects all the n nodes to a corresponding multi-label switch (MLS) port and ends the recursion. The second section interconnects the servers to the corresponding switch port and any two servers are connected with one link. Each server in the C-DCNs network is connected with 10GB links for all VLANid. The C-DCN physical architecture with the VLAN segmentation while the linear construction algorithm is depicted in Algorithm 1 below, In the C-DCN physical structure, the servers in one subnet are connected to one another through one.
Of the MLS ports that is dedicated to that subnet. Each server in one subnet is also linked to another server of the same order in all another subnets.
As such, each of the servers has two links, with one, it connects to other servers in the same subnet (intra server connection) and with the other it connects to the other servers of the same order in all other subnets (inter server connection). Apart from the communication that goes on simultaneously in the various subnets, the inter server connection is actually a VLAN connection. This VLAN segmentation of the servers logical isolates them for security and improved network performance. Together with server virtualization which ultimately improves the network bandwidth and speed, this VLAN segmentation gives each C-DCNs (subnet) the capacity to efficiently support enterprise web applications (EETACP, Web Portals, Cloud applications such as software as a service) running on server virtualization in each MLS.
Algorithm 1: C_DCN Construction Algorithm.
/* l stands for the level of C_DCNs subnet links, n is the number of nodes in a C_DCNs,
pref is the network prefix of C_DCNs s s is the number of servers in a C_DCNs,*/
Build C_DCNs (l, n, s)
Section I: /* build C_DCNs*/
If (l = = 0)
For (inti = 0; i< n; i++) /* where n is=4*/
Connect node [pref, i] to its switch;
Return;
Section II: /*build C_DCNs servers*/
For (inti = 0; i< s; i++)
Build C_DCNs ([pref, i], s)
Connect C_DCNs (s) to its switch;
Return;
3.1. Logical Isolation of Cloud-DCN Architecture
In order to achieve this, each server and nodes in Cloud-DCNs is assigned virtualization identity,  and VLAN identity (Vlid) between 1 and 1005, where
and VLAN identity (Vlid) between 1 and 1005, where  is the virtualization instances on C_DCNs servers. As such each server can be equivalently identified by a unique Vlid in the range Vlid ≤ 1005*.
is the virtualization instances on C_DCNs servers. As such each server can be equivalently identified by a unique Vlid in the range Vlid ≤ 1005*.
Hence the total of Vlid for servers in the Cloud-DCNs is
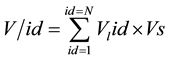 (1.1)
(1.1)
where N is the maximum number of VLAN, and Vs is the virtual instances in the C-DCNs.
The mapping between a unique Vlid and the C-DCNs servers considering that there are four C-DCNs is given in Equation (1.2)
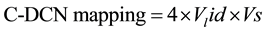 (1.2)
(1.2)
Following the Cloud-DCN architecture in Figure 4, in order to minimize broadcast storms and reduce network traffic/demand density, a VLAN mapping scheme of the servers in the Cloud-DCNs.
Consider Cloud-DCNsa, Cloud-DCNsb, Cloud-DCNsc and Cloud_DCNsd with servers S1 to Sn. The servers in each of the Cloud-DCNs are mapped into different VLANs with their corresponding ids as follows:
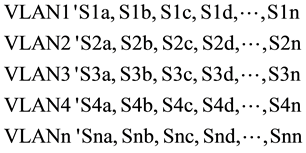
where S1a, S2a, S3a, S4a are the servers in Cloud_DCNsa
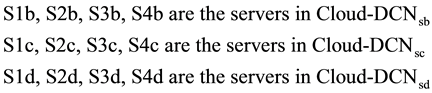
With this VLAN mapping scheme, a logical isolation of the Cloud-DCN architecture was achieved as shown in the mode of Figure 4. This make for fluid flexibility, improved network security, agility and control of traffic flow in the Cloud-DCN architecture.
3.2. Traffic Manager Stability for Cloud-DCN
Request or demand arrives randomly in the multilevel switch, not necessarily in a deterministic fashion. This work assumed that the packet arrival follows the stochastic process such that the packet size is exponentially distributed, and the system is considered as an M/M/1 queuing system. An M/M/1 queue represents the queue length in a system having a single server, where the arrivals are determined by a stochastic process and the job service time has an exponential distribution. The buffer size of the switch (MLS) is of infinite size.
For the system (C_DCN), capacity management and optimum utilization will address broadcast oscillation (congestion) and instability. To address this situation, adapting Little’s law which takes care of the system response time and scheduling distribution will optimize traffic flow.
If the average arrival rate per unit time is denoted by λp (pps) and μp is the average service rate per unit time, then from Little’s law, the average delay (in seconds), D is given by:

Figure 4. In one pass, traffic detection and stream selection in hybrid optical and electrical circuit packet network.
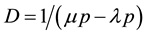 (1.3)
(1.3)
And the traffic demand, a (referred to as offered load or offered traffic in C_DCNs), is given by a = λp ´ Μp (1.4).
The system is considered stable only if λp < μp. If on the other hand, the average arrivals happen faster than the service completions (λp > μp), the queue will grow indefinitely long and the system will not have a stationary distribution (the system is unstable).
3.3. Cloud-DCN Algorithm (GLB)
The Traffic algorithm in Cloud-DCN architecture is modeled for effective fault tolerance and failure suppression which makes for greater efficiency in web application integration. The Cloud-DCN algorithm is shown in Algorithm 2.
The procedure in algorithm normalizes and stabilizes traffic flow in the proposed DCN. In initialization, the rate controller and Ethernet interfaces are initialized while enabling the bus arbitration in ports. In the ports the peripheral component interconnect extension and the MAC are defined while calling the subroutine for more addition of ports in the DCN switch. For each subnet, traffic scheduling is asserted true while enabling the maximum bandwidth for the medium of traffic propagation. On the switch, MAC address mapping is assigned multiplexer switch arbitration bus which suppresses collision types (uncast, broadcast, and multicast). For Round Trip Time (RTT), uncast data flows with their frame sizes and packet length are scheduled for two-way handshake (transfer). At the instance of correspondence between a scheduled destination address and rate controller buffer, data, and packet length from the port are established for transfers. The process is repeated throughout the entire period of the DCN traffic initiation. At each point, normalization of the rate controller, the data length, and the buffer sizes is carried out while consistently suppressing collision forms in the DCN [14] .
Conventionally, in DCN flooding of packets from an active port to destination addresses is done with a compromise to the DCN resources. With GLB beside collision suppression, fair scheduling and sharing of resources is an optimal feature that will enhance service availability and reliable throughput. Hence, with GLB as an improvement to CSMA/CD, utilization of resources by heavy web application servers will maintain dynamic stability without compromise to other QoS metrics.
Algorithm 2: Cloud_DCN Traffic Algorithm.
Procedure: traffic Controller: Public {SERVER 1:N}
{Set Normalization UiXi ==TAMP==0
Rate Controller ==0
Server Ethernet = = Ethernet Initialization
Define Arbitration Bus {Ports}
Define PCIx MAC (TF)
Add ports(Cloud-DCNports);
Data Packets:è MAC Address []
Cloud-DCN.Subnet(1),transferScheduled(True)
{intuploadData() const { return MAC Address};
setUploadLimit(int bytes Per Second)
{upLimit = 10 Gbps; }
Map MacAddres: è Multiplexer Switch Abitration Bus
SetDownloadLimit(intbytesPerSecond);
Dataç: Public Unicast data:
Assign Data bytes:è Length (L);
ScheduleTransfer();
};IfCloud_DCN BUFFER &&RateController == Destination Address)
{Connect(L,Data (readyToTransfer());
CompleteScheduledTransfert->setReadBufferSize();
Output.Networkbuffer(port);
ScheduleTransfer();
}For (i =0;i++)
Clou-DCN BUFFER==RateControllerèUiXi
{Normalize(PortContention,Collision,Saturation&SwitchPoison)
SIGNAL(readyToTransfer()),
C-DCN->setReadBufferSize(0);}
Proposed dynamic traffic scheduling as indicated in Figure 3.
The first step is to detect changes in traffic. This first step allows you to avoid having to calculate the coefficient of the bottleneck every time it is computationally expensive and classified by categories of NP-hard problems.
4. Design Context
As for the simulation test bed used for Cloud-DCN simulation, a generic template for running C-DCN was developed using OPNET IT guru as a simulation tool [15] .
・ The N number of C-DCN subnets with their Media Access Control (MAC) controller and their application data blocks.
・ The MLS switch model comprising of the First-In-First-Out (FIFO) queue, connecting a server farm gateway with a Gigabit Ethernet link.
・ The http IP Cloud and Entity sources end users.
Before the simulation, link consistence tests were carried out randomly to ascertain any possibility of failure in all cases. A randomly selected nodes and servers routes packets in a bidirectional way from the access layer to the core layer and vice versa. In context, an investigation on both the path failure ratio and the average path length for the found paths was carried out and all the links found satisfactory. All links and nodes passed the test in all cases. Figure 5 shows OPNET screenshot for simulation sequence used in the analysis. In all the simulations, we enabled the essential attributes for each of the two scenarios on the template. Simulation completed successfully and the results collated in the global and object statistics reports.
4.1. Simulation Results/Hypothesis Validation
For further validation of our C-DCN, we used the design parameters obtained from our experimental tasted to develop a generic template in OPNET modeler (a simulation tool). Based on some experimental measurement carried out on the test bed, we used the throughput metric for performance evaluations of fault tolerance throughput index. On the generic OPNET template shown in Figure 5, two scenarios were created, one for

Figure 5. Simulation test bed for Cloud-DCN validation.
Cloud-DCN Fault tolerance and one for Cloud-DCN No Fault tolerance. For each of the scenarios, the attributes of the three architectures were configured on the template and the simulation was run. Afterwards, the OPNET engine generates the respective data for each of the QoS investigated in this work. The C-DCN used only a low-end MLS with the gateway load balancing functions. It also uses traffic routing algorithms viz: VLAN, feedback mechanisms, server virtualization, and convergence with randomization. The experiment only used the throughput parameter for fault-tolerance analysis against the two scenarios. The load balancer can detect when a server fails and remove that machine from the server pool until it recovers. In this scenario, server 3 fails 5 minutes into the simulation. 30 minutes later, the server recovers.
4.2. Throughput Response Evaluations
Throughput being the data quantity transmitted correctly starting from the source to the destination within a specified time (seconds) is quantified with varied factors including packet collisions, obstructions between nodes/terminal devices between the access layer and the core layer and more importantly at the core layer of the cloud-DCN. During the simulation, throughput as a global statistics was being measured and compared. The average throughput in a network with load balancing service has highest throughput compared with the average throughput in a network without a fault tolerant service. The main reason for this is stems from GLB layer 2 introduced in C_DCN design leveraging its advantages as discussed previously.
Again, in all cases, the introduction of a load balancer was expected to balance the traffic at the core, but it was observed that the network model of C_DCN as well as its topological layout had a significant effect on the throughput. Again, this work attributes this observation to the fact that the three-tier topology is communicating on the basis of reduced policy implementation. This makes for efficiency and as such the total load of the network is divided among the two-tier only on 40% (access layer): 60% (core) leading to lesser collisions and
lesser packet drops which could likely occur. From Figure 6, the Cloud-DCN with failure mechanism offered 99% throughput index while without (Global Load Balancing (GLB), it yielded 97%. This result validates our research hypothesis stated earlier in this work. We argue that in all ramifications, cloud datacenter environments with no fault tolerance mechanisms will fail in the face of mission critical applications being hosted therein.

Figure 6. Throughput index analyses for C_DCN.
5. Security Gateway Risk and Vulnerability Analysis
・ Data Center in the future, as defined by the software, it is a dynamic and substantive.
○ A new software security architecture provides automated orchestration for more flexible, Sustainable and efficient operation. Agent less AV through the integration of VMware NSX service composer)
Symantec Data Canter security: Server
・ The threat landscape is changing and server protection strategy.
○ New security technologies provide additional layers of protection for already best in class solutions (for example, protected copies of white listing and isolation)
Browse Architecture Server & Server Advanced as shown in Figure 7.
The configured security policies and monitoring; the “light” agent, to reduce the effect on the system
・ Full protection;
・ Monitoring Oracle database logs and MS SQL. Server
・ Monitoring developments in Active Directory;
・ Protection of operating personnel.
・ Ability to monitor key files on servers
・ Ability to control updates/configuration changes
6. Conclusions
This paper has presented a throughput index metric in Cloud-DCN for efficient web application integration. Apart from the literature review carried out and the study, we also developed the system model with mathematical model for scalability, and logical isolation of Cloud-DCN load balancer MLS architecture. The advantages of GLB were outlined. Using the OPNET simulator, we simulated Cloud-DCN and compared the results of the two-case fault scenarios. Our discovery showed that C_DCN performed much better (99%) under fault tolerance mechanism compared with the case with no fault tolerance mechanism (97%) thereby validating our stated hypothesis.
This work has made significant contributions to the body of knowledge in the following areas:
・ Cloud-DCN model is very efficient with respect to web application integration, scalable, service-oriented, and responsive to business needs; rapid service delivery has been realised.
・ Responsive to business needs, rapid service delivery has been realized.
・ An enhanced throughput index comparison between a two-case fault tolerance scenario to validate a stated hypothesis is made.
・ Traffic control issues in DCNs have been handled through the analytical model proposed in this work.
Our conclusion therefore, is that the proposed cloud data center architecture will be very efficient, scalable,

Figure 7. Integration with new technologies VM ware.
cost effective, service-oriented, and responsive to business needs, with rapid service delivery, and one that can provide tighter alignment with business goals. Hence we recommend the Cloud-DCN to enterprise organizations for greater efficiency in web application integration vis-à-vis their data center network. This will form the basis of our implementation of EETACP as well as the TCP communication protocol into the data center in our future works.
References
- Chan, W., Leung, E. and Pili, H. (2012) Enterprise Risk Management for Cloud Computing. The Committee of Sponsoring Organizations of the Treadway Commission (COSO), Chicago. http://www.coso.org/documents/Cloud%20Computing%20Thought%20Paper.pdf
- Buyya, R., Beloglazov, A. and Abawajy, J. (2010) Energy-Efficient Management of Data Center Resources for Cloud Computing: A Vision, Architectural Elements, and Open Challenges. http://arxiv.org/ftp/arxiv/papers/1006/1006.0308.pdf
- Nagaty, K.A. (2009) Hierarchical Organization as a Facilitator of Information Management in Human Collaboration. IGI Global, Egypt, Chapter IV.
- Jarschel, M., Schlosser, D., Scheuring, S. and Hossfeld, T. (2011) An Evaluation of QoE in Cloud Gaming Based on Subjective Tests. International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Seoul, 30 June-2 July 2011, 330-335.
- Wu, H.T., Lu, G.H., Li, D., Guo, C.X. and Zhang, Y.G. (2009) MDCube: A High Performance Network Structure for Modular Data Center Interconnection. CoNEXT’09, Rome, 1-4 December 2009, 25-36.
- Huang, F., Lu, X.C., Li, D.S. and Zhang, Y.M. (2012) A Fault-Tolerant Network Architecture for Modular Datacenter.
- International Journal of Software Engineering and Its Applications, 6, 93-106. http://www.scribd.com/doc/103863757/A-Fault-Tolerant-Network-Architecture-for-Modular-Datacenter
- Wang, Y., Wen, X., Sun, Y., Zhao, Z., Yang (2011) The Content Delivery Network System Based on Cloud Storage. 2011 International Conference on Network Computing and Information Security (NCIS), 1, 98-102.
- Li, D., Guo, C.X., Wu, H.T., Tan, K. and Zhang, Y.G., et al. (2009) FiConn: Using Backup Port for Server Interconnection in Data Centers. IEEEI NFOCOM 2009, Rio de Janeiro, 19-25 April 2009, 2276-2285.
- Liao, Y., Yin, J.T., Yin, D. and Gao, L.X. (2012) DPillar: Dual-Port Server Interconnection Network for Large Scale Data Centers. Elsevier Computer Networks, 56, 2132-2147. http://dx.doi.org/10.1016/j.comnet.2012.02.016
- Armbrust, M. et al. (2009) Above the Clouds: A Berkeley View of Cloud Computing. Technical Report No. UCB/ EECS-2009-28, University of California, Berkley.
- Barroso, L., Dean, J. and HÄolzle, U. (2003) Web Search for a Planet: The Google Cluster Architecture.
- Ghemawat, S., Gobio, H. and Leung, S. (2003) The Google File System.
- http://www.textroad.com/pdf/JBASR/J.%20Basic.%20Appl.%20Sci.%20Res.,%202(5)5070-5080,%202012.pdf
- Udeze, C.C, Okafor Kennedy, C., Ugwoke, F.N. and Ijeoma, U.M. (2013) An Evaluation of Legacy 3-Tier DataCenter Networks for Enterprise Computing Using Mathematical Induction Algorithm. Computing, Information Systems, Development Informatics & Allied Research, 4, 1-10.
- Juniper Networks (2011) Design Considerations for the High-Performance enterprise Data Center LAN. Whitepaper.