Communications and Network
Vol.10 No.03(2018), Article ID:86029,14 pages
10.4236/cn.2018.103005
Coarse Graining Method Based on Noded Similarity in Complex Network
Yingying Wang, Zhen Jia*, Lang Zeng
College of Science, Guilin University of Technology, Guilin, China
Copyright © 2018 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: May 24, 2018; Accepted: July 15, 2018; Published: July 18, 2018
ABSTRACT
Coarse graining of complex networks is an important method to study large-scale complex networks, and is also in the focus of network science today. This paper tries to develop a new coarse-graining method for complex networks, which is based on the node similarity index. From the information structure of the network node similarity, the coarse-grained network is extracted by defining the local similarity and the global similarity index of nodes. A large number of simulation experiments show that the proposed method can effectively reduce the size of the network, while maintaining some statistical properties of the original network to some extent. Moreover, the proposed method has low computational complexity and allows people to freely choose the size of the reduced networks.
Keywords:
Complex Network, Coarse Graining, Node Similarity, Statistical Properties

1. Introduction
Many complex systems in reality can be abstracted into complex networks [1] for research. Complex network has been one of the most active tools for the study of complex systems. It has important applications in many fields such as biology, economics and finance, as well as society, electricity, transportation and so on.
Since the similar topological properties of real-world complex networks, it is a hot topic to study the commonness of networks and the universal methods to deal with them [2] - [9] . However, many networks are known to exhibit rich. It is not enough to study the dynamic properties of small-scale networks, which may only reflect some local information of large-scale networks, while direct research on large-scale networks is computationally prohibitive. For example, the World-Wide-Web produces new web links every day. If the pages on the World-Wide-Web are thought of as the nodes and the hyperlinks between them as edges, then the World-Wide-Web is a huge complex network and continues growing. It is difficult to deal with this kind of large-scale networks, coarse graining of complex networks is the latest way to overcome such difficulty in the world. Given a complex network with N nodes and E edges, which is considerably large and hard to be delt with, the coarse-graining technique aims at mapping the large network into a mesoscale network, while preserving some topological or dynamic properties of the original network. This strategy is based on the idea of clustering nodes with similar or same nature together.
In the past decade, some well-known coarse-graining methods have been proposed [10] - [21] . Historically, these methods can be classified into two categories: one is based on the eigenvalue spectrum of the network. Its main goal is to reduce the network size while keeping some dynamic properties of the network. For example, D. Gfeller et al. proposed a spectral coarse-graining algorithm (SCG) [11] [12] , Zhou and Jia proposed an improved spectral coarse-graining algorithm (ISCG), Zeng and Lü proposed a path-based coarse graining [13] [14] . All these coarse-graining methods are developed to maintain the synchronization ability. Another coarse-graining method is based on topological statistics of the network, for instance, the k-core decomposition [10] , the box-counting techniques [15] [16] , the geographical coarse-graining method introduced by B. J. Kim, et al. in 2004. And referring to literature [18] , the network reduction is related to segmenting the central nodes by implementing the k-means clustering techniques, etc. These methods can well maintain some of the original networks. In 2018, our research team proposed a coarse-graining method based on the generalized degree (GDCG) [19] . Specifically, the GDCG approach provides an adjustable generalized degree by parameter p for preserving a variety of significant properties of the initial networks during the coarse-graining processes.
In general, degree is the simplest and most important concept to describe the attributes of a single node. In undirected networks, the degree of node i is defined as the nature of nodes, is not only related to the degree of the nodes, but also to the degree of their neighbor nodes, the number of edges connected to i, i.e., the number of neighbor nodes of node i. Actually, the nature of nodes is not only related to the degree of the nodes, but also to the degree of their neighbor nodes. From the point of view of information transmission, the more common neighbors of two nodes, the more similar information they receive and the ability to receive information. From the perspective of information transfer, the more common neighbors the two nodes have, the more similar information they receive and the ability to receive information. In this paper, based on the similarity index of nodes, we introduce a new possible coarse-graining technique. According to the number of common-neighbor of nodes in the network, the algorithm describes the similarity between nodes and extracts the reduced network by merging similar nodes. The method is computationally simple, and more importantly, the size of the reduced network can be accurately controlled. Numerical simulations on three typical networks, including the ER random networks, WS small-world networks, SF networks reveal that the proposed algorithms can effectively preserve some topological properties of the original networks.
2. Definition of Node Similarity
Consider a complex network consisted of N nodes, where V is the set of nodes and E is the set of edges. The adjacency matrix describes the topology of the network. In general, indicates the presence of an edge, while stands for the absence of edges. For an undirected unweighted network, whose adjacency matrix A must be symmetric matrix, i.e. and the sum of the i’th row (or the i’th column) elements of the matrix A is exactly the degree of the node i. Here we use the Jaccard similarity index to calculate the similarity between node pairs. The similarity between any node i and node j in the network is defined as:
(1)
Let denote the set of neighbor nodes of node i, is the cardinality of the set . Mathematically, . is the common neighbor node set of node i and j, is the union of the neighbor nodes of node i and j. By Equation (1), , it shows that the similarity with the node i itself is 1. And if the node i and the node j have no common neighbor nodes, then their similarity is zero, i.e., ,so . Because describe the degree of local structure similarity between the node i and j. We treat as the local similarity index.
The similarity between the node i and other nodes in the network can be expressed by a Ndimension vector . The larger the value is, the more nodes in the network are locally similar to the node i. Therefore, we extend the Equation (1), the global similarity index for node i in the network is defined as follows:
(2)
The larger is, the more likely the node i will be the cluster center of some similar nodes.
3. Noded Similarity Coarse-Graining Scheme
It is noted that coarse-graining methods have to solve two main problems: one is the emergence of nodes, that is, to determine which nodes should be merged; And the second is how to update the edges in the process of coarse graining. In the following content, the noded similarity coarse-graining scheme is introduced from these two sides.
3.1. Nodes Condensation Based on Similarity Index
Suppose we are going to coarse grain a network containing N nodes to a smaller one with ( ) nodes. First, we need to select cluster center, perform the clustering algorithm to get the corresponding cluster, then merge nodes in the same cluster.
In order to select suitable nodes as the cluster centers, it is necessary to ensure that the extracted cluster centers have as much high global similarity as possible (with as many nodes as possible in the network). It is also required that the local similarity between the two clustering centers should not be too high (otherwise, they may belong to the same cluster, only one of them could be the clustering center).
The detailed steps for selecting clustering are shown as follows.
Step 1: Get the local similarity and the global similarity of each node in the network. The sequence of the generalized degree of N nodes has been sorted in decrease order.
Step 2: Set be the set of cluster centers. Firstly, put the node which corresponding to the maximum global similarity into , denoting . Secondly, pick the node corresponding to the second largest global similarity , if (N and are the size of the coarse-grained networks and original networks respectively, is an adjustable parameter). It indicates that the node and are not in the same cluster, so could be the second cluster center. Push into , denoting . Otherwise, if , which means that the local similarity between the node and is too high and these two nodes may belong to the same cluster. Then cannot be put into as a new cluster center. Continue to select the cluster centers in the order of , the new cluster center node has to satisfy: , . In this way, stop selecting the new cluster centers until the number of reaches , denoting .
Step 3: Take as the cluster centers respectively, their corresponding clustering sets are described as . And then cluster the remaining nodes in the network (the collection of the remaining nodes is represented as: ). In order to find the clustering set that the node of the belong to, our objective is to find:
(3)
where, ( ) is corresponding to the local similarity of the node ( ) with other nodes in the network. is the norm between nodes and , which is also called the Euclidean distance. Repeat operations until all nodes in are merged with cluster centers. Finally, we will get clustering sets.
3.2. Updating Edges of the Reduced Networks
clustering sets have been obtained from the section 3.1, merge nodes in each cluster and get coarse-grained nodes. To keep the connectivity of the reduced network, the following step is to update edges, the detailed content is as following:
Definition of weight. The set of nodes in ith cluster is defined as ( is also the ith node in coarse-grained networks). We re-encode the weight, specifically:
(4)
where, is the element in the adjacency matrix of the original network. And is the weight of the edge between node and .
Definition of edge. The edge between nodes and is defined by:
(5)
separately represent the number of the nodes in ith, jth cluster. As presented above, the framework can preserve the edges between the clusters (each cluster corresponds to a coarse-grained node) that are closely related to each other in original networks. Moreover, it can prevent the network from reducing into a fully connected network. And removing the weight of the edges, only displaying the topology structure of the coarse-grained networks, is conducive to keep some statistical properties of the original networks. In particular, if the network becomes disconnected after deleting the edge , then reconnect the edge in order to ensure the connectivity of the network. Now we can create an undirected unweighted network after two steps as described above.
3.3. A Toy Example
To better illustrate the algorithm we proposed, this section will apply the noded similarity coarse-graining scheme on the small toy network, as shown in Figure 1.
A 9-node toy example is shown in Figure 1(a). Here, we use the noded similarity coarse-graining method to reduce the network into 7 nodes, and to meet the required coarse-grained network size. First of all, calculate and sort the global similarity of nodes in decrease order as
. It can be found that: and . Intuitively, the two yellow circular nodes like the two green diamond nodes have totally equal topological roles. According to step 2 of section 3.1, put the largest global similarity node 3 into the set , namely, node 3 is the first cluster center corresponding the clustering set . Then take the node 4 to compare with the cluster center node 3. From the Equation (1),
, . Hence the node 4 cannot be placed as a

Figure 1. A toy example based on the node similarity coarse-graining method. (a) A 9-node simple network with adjacency matrix A; (b) The reduced network with adjacency matrix .
cluster center into to the set
. And so on, the set of cluster center
with the collection of the remaining nodes
can be obtained, while each element in
corresponds to the clustering sets: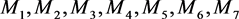 . It is not difficult to calculate
. It is not difficult to calculate
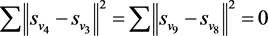 according to Equation (3). The distance between
according to Equation (3). The distance between
the node 4 and the cluster center node 3 is the smallest one, so the node 4 should be merged with the cluster center node 3 together. They belong to the same clustering set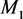 ; akin to the node 4, the node 9 and the cluster center node 8 belong to the same clustering set
; akin to the node 4, the node 9 and the cluster center node 8 belong to the same clustering set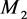 . At this point, seven coarse-grained nodes have been obtained. There are only 0, 1 or 2 three kinds of weight between the coarse grained nodes. So take the node
. At this point, seven coarse-grained nodes have been obtained. There are only 0, 1 or 2 three kinds of weight between the coarse grained nodes. So take the node 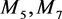 and node
and node 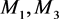 as an example to update edges. By Equation (4),
as an example to update edges. By Equation (4), 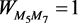 ,
, 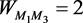 , following the
, following the
definition in Equation (3), 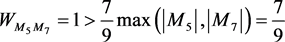 ,
,
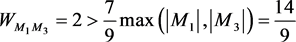 , so
, so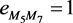 ,
,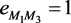 . For the nodes that are not connected in the original network, their edge weight are still set to 0 in the coarse-grained network. Then we can create the coarse grained network with adjacency matrix
. For the nodes that are not connected in the original network, their edge weight are still set to 0 in the coarse-grained network. Then we can create the coarse grained network with adjacency matrix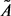 , as shown in Figure 1(b).
, as shown in Figure 1(b).
4. Numerical Demonstrations
This section is devoted to an extensive numerical demonstration to investigate several properties of the noded similarity coarse-graining networks, including the average path length, average degree and clustering coefficient. Recently, the average path length, average degree and clustering coefficient are the three most concerned topological properties in the research of complex networks. They describe more explicit information about the various aspects in the networks. Specifically, we will give a clearer definition in the following sections. And for simplicity, we main consider three typical networks (the ER random networks, the WS small-world networks and the SF scale-free networks). To better illustrate the effect of the proposed method on these topological properties. We investigate our method with different values of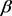 . On the other hand, under the optimal
. On the other hand, under the optimal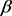 , we further investigate the effect with the structural parameters of different networks. For simplicity, we consider the ER random networks with connecting probability
, we further investigate the effect with the structural parameters of different networks. For simplicity, we consider the ER random networks with connecting probability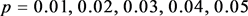 . The WS small-world network algorithm is proposed by Newman and Eatts in 1998, which is obtained by randomly rewiring each edge of the original networks on the basis of the nearest-neighbor coupled networks. We adjust the rewiring probability with
. The WS small-world network algorithm is proposed by Newman and Eatts in 1998, which is obtained by randomly rewiring each edge of the original networks on the basis of the nearest-neighbor coupled networks. We adjust the rewiring probability with 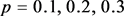 and coordinator number
and coordinator number . In terms of SF networks, the degree distribution follows the power-law distribution. When the power-law exponent
. In terms of SF networks, the degree distribution follows the power-law distribution. When the power-law exponent  increases from small to large, the power-law networks change from the highly heterogeneous networks to the highly homogeneous networks. Since
increases from small to large, the power-law networks change from the highly heterogeneous networks to the highly homogeneous networks. Since  typically lies between 2 and 3 for many real-world systems. We main consider the cases with
typically lies between 2 and 3 for many real-world systems. We main consider the cases with .
.
Additionally, for each type of the artificial complex networks, we fix the size of these networks as , and for each type of the typical complex networks, we consider
, and for each type of the typical complex networks, we consider . The results of all the illustrated experiments are the average of ten independent simulation runs.
. The results of all the illustrated experiments are the average of ten independent simulation runs.
4.1. Average Path Length
The average path length L between two nodes is defined by:
 (6)
(6)
where N is the size of the network,  is the shortest path length from i to j.
is the shortest path length from i to j.
Figure 2 & Figure 3 show the evolution of the average path length of the above mentioned networks with noded similarity coarse-graining method. From Figure 2(a), one can see that for the ER networks the average path lengths are almost the same with the adjustable parameter  varying from 0.1 to 0.6. It means that the value of
varying from 0.1 to 0.6. It means that the value of  does not have a great impact on the ER networks. Therefore, we randomly pick
does not have a great impact on the ER networks. Therefore, we randomly pick  to get the results shown in Figure 3(a). Under each p, the average path length can be well preserved, especially for
to get the results shown in Figure 3(a). Under each p, the average path length can be well preserved, especially for . For the WS networks, when
. For the WS networks, when , the larger
, the larger  is, the better effect of maintaining the average path length will be. And the curve with
is, the better effect of maintaining the average path length will be. And the curve with  has the best result. Moreover, when
has the best result. Moreover, when , the proposed method can well preserve the average path length of the original networks with
, the proposed method can well preserve the average path length of the original networks with

Figure 2. Evolutions of the average path length under different β. (a) ER network; (b) WS networks; (c) SF networks.

Figure 3. Evolutions of the average path length under different structural parameters. (a) ER network; (b) WS networks; (c) SF networks.
different rewiring probability p and coordinator number K. For the SF networks under optimal , the average path length is better maintained with
, the average path length is better maintained with  as shown in Figure 3(c).
as shown in Figure 3(c).
4.2. Average Degree
Average degree  is a critical index to weigh the relatively connectedness of the whole network. Given the adjacent matrix A of a network, the corresponding
is a critical index to weigh the relatively connectedness of the whole network. Given the adjacent matrix A of a network, the corresponding  is given by:
is given by:
 (7)
(7)
 (8)
(8)
The evolutions of average degree  versus the parameter
versus the parameter  with the node similarity coarse-graining processes for the three types of networks are shown in Figure 4. Similar to the phenomenon exists in Figure 2, ER random networks are not sensitive to different values of
with the node similarity coarse-graining processes for the three types of networks are shown in Figure 4. Similar to the phenomenon exists in Figure 2, ER random networks are not sensitive to different values of . For the WS networks, the curves under
. For the WS networks, the curves under  are obviously better than
are obviously better than  in preserving the clustering coefficient of the original networks with
in preserving the clustering coefficient of the original networks with . And the effect of keeping the clustering coefficient is better with a relatively smaller
. And the effect of keeping the clustering coefficient is better with a relatively smaller

Figure 4. Evolutions of the average degree under different β. (a) ER network; (b) WS networks; (c) SF networks.
 in the SF networks.
in the SF networks.
As displayed in Figure 5, the average degree can be preserved in three kinds of coarse-grained networks with the optimal . In ER networks, the curve of average degree is approximately linear with
. In ER networks, the curve of average degree is approximately linear with . With the increase of p, the volatility of the curve increases, but it also roughly keeps the average degree. From Figure 5(b), the average degree for all WS networks can be well preserved regardless of the structural parameters. In SF networks, the node similarity algorithm can better keep the average degree of the original networks with the increase of
. With the increase of p, the volatility of the curve increases, but it also roughly keeps the average degree. From Figure 5(b), the average degree for all WS networks can be well preserved regardless of the structural parameters. In SF networks, the node similarity algorithm can better keep the average degree of the original networks with the increase of . Moreover, the average degree of the coarse grained networks is within 1 degree relative to the average degree of original networks even the size of the original networks is reduced to half. As you can see, the SF networks are superior to the above two networks in maintaining the average degree.
. Moreover, the average degree of the coarse grained networks is within 1 degree relative to the average degree of original networks even the size of the original networks is reduced to half. As you can see, the SF networks are superior to the above two networks in maintaining the average degree.
4.3. Clustering Coefficient
The clustering coefficient measures the edge connection probability between the neighbor nodes in a network. The clustering coefficient  of node i with the
of node i with the

Figure 5. Evolutions of the average degree under different structural parameters. (a) ER network; (b) WS networks; (c) SF networks.
average degree  is defined as:
is defined as:
 (9)
(9)
where  gives actual number of edges between
gives actual number of edges between  neighbor nodes of node i. The overall level of clustering in a network is measured as the average of the clustering coefficients of all nodes:
neighbor nodes of node i. The overall level of clustering in a network is measured as the average of the clustering coefficients of all nodes:
 (10)
(10)
The result shows that the optimal parameter  corresponding to the best performance on preserving different statistical properties is the same. From the result shown in Figure 7(a), when the connecting probability p increase, the effect of maintaining the clustering coefficient in ER networks becomes more prominent. When
corresponding to the best performance on preserving different statistical properties is the same. From the result shown in Figure 7(a), when the connecting probability p increase, the effect of maintaining the clustering coefficient in ER networks becomes more prominent. When , the clustering coefficient of coarse-grained networks are in the range of 0.8 which agree with the plan of updating edges. The WS networks are typically with high clustering coefficient. The curves tend to decrease sharply with the increase of K and the decrease of the rewiring probability p. When
, the clustering coefficient of coarse-grained networks are in the range of 0.8 which agree with the plan of updating edges. The WS networks are typically with high clustering coefficient. The curves tend to decrease sharply with the increase of K and the decrease of the rewiring probability p. When  is less than the threshold value 200, all curves turn to rise. But in general, the clustering coefficient of the original networks can be effectively maintained of certain structural parameters. In Figure 7(c), different curves
is less than the threshold value 200, all curves turn to rise. But in general, the clustering coefficient of the original networks can be effectively maintained of certain structural parameters. In Figure 7(c), different curves

Figure 6. Evolutions of the clustering coefficient under different β. (a) ER network; (b) WS networks; (c) SF networks.

Figure 7. Evolutions of the clustering coefficient under different structural parameters. (a) ER network; (b) WS networks; (c) SF networks.
coincide with each other especially . Which indicate that the clustering coefficient property can be well preserved in the SF networks.
. Which indicate that the clustering coefficient property can be well preserved in the SF networks.
5. Conclusions and Discussions
The coarse-graining techniques are promising ways to study the large-scale complex networks. In this paper, we have developed a new algorithm to reduce the sizes of complex networks. This method is based on the local similarity and the global similarity of nodes, which is more suitable for the original intention of coarse graining. Particularly, we introduce a tuning parameter  in the algorithm to obtain the best effect of keeping the statistical properties. The study found that the optimal parameter
in the algorithm to obtain the best effect of keeping the statistical properties. The study found that the optimal parameter  for different types of networks was different. Specifically, the ER networks are not sensitive to
for different types of networks was different. Specifically, the ER networks are not sensitive to ; the WS networks require larger
; the WS networks require larger ; and in the SF networks, the smaller
; and in the SF networks, the smaller  is, the better the statistical properties will be maintained. Results from extensive numerical experiments indicate that the average path length, the average degree and the clustering coefficients can be preserved during the coarse-graining processes.
is, the better the statistical properties will be maintained. Results from extensive numerical experiments indicate that the average path length, the average degree and the clustering coefficients can be preserved during the coarse-graining processes.
Acknowledgements
This project is supported by National Natural Science Foundation of China (61563013, 61663006) and the Natural Science Foundation of Guangxi (No. 2018GXNSFAA138095).
Cite this paper
Wang, Y.Y., Jia, Z. and Zeng, L. (2018) Coarse Graining Method Based on Noded Similarity in Complex Network. Communications and Network, 10, 51-64. https://doi.org/10.4236/cn.2018.103005
References
- 1. Watts, D.J. and Strogatz, S.H. (1998) Collective Dynamics of “Small-World” Networks. Nature, 393, 440-442. https://doi.org/10.1038/30918
- 2. Barabási, A.L. and Albert, R. (1999) Emergence of Scaling in Random Net-works. Science, 286, 509-512. https://doi.org/10.1126/science.286.5439.509
- 3. Barabási, A.L., Albert, R. and Jeong, H. (1999) Mean-Field Theory for Scale-Free Random Networks. Physica A: Statistical Mechanics and Its Applications, 272, 173-187. https://doi.org/10.1016/S0378-4371(99)00291-5
- 4. Pan, Z.F. and Wang, X.F. (2006) A Weighted Scale-Free Network Model with Large-Scale Tunable Clustering. Acta Physica Sinica-Chinese Edition, 55, 4058-4064.
- 5. Li, H., Li, Z.Y. and Lu, J.A. (2006) Weighted Scale-Free Network Model with Evolving Local-World. Com-plex Systems and Complexity Science, 3, 36-43.
- 6. Dörfler, F., Chertkov, M. and Bullo, F. (2013) Synchronization in Complex Oscillator Networks and Smart Grids. Proceedings of the National Academy of Sciences, 110, 2005-2010. https://doi.org/10.1073/pnas.1212134110
- 7. Qin, J., Gao, H. and Zheng, W.X. (2015) Exponential Synchroniza-tion of Complex Networks of Linear Systems and Nonlinear Oscillators: A Unified Analysis. IEEE Transactions on Neural Networks and Learning Systems, 26, 510-521. https://doi.org/10.1109/TNNLS.2014.2316245
- 8. Tang, L., Lu, J. and Chen, G. (2012) Synchronizability of Small-World Networks Generated from Ring Networks with Equal-Distance Edge Additions. Chaos: An Interdisciplinary Journal of Nonlinear Science, 22, 023121. https://doi.org/10.1063/1.4711008
- 9. Zhou, T., Zhao, M. and Wang, B.H. (2006) Better Synchronizability Pre-dicted by Crossed Double Cycle. Physical Review E, 73, 037101. https://doi.org/10.1103/PhysRevE.73.037101
- 10. Alvarez-Hamelin, I., Dall’Asta, L., Barrat, A. and Vespignani, A. (2005) K-Core Decomposition: A Tool for the Analysis of Large Scale Internet Graphs. cs. NI/0511007.
- 11. Gfeller, D. and De Los Rios, P. (2007) Spectral Coarse Graining of Complex Networks. Physical Review Letters, 99, 038701. https://doi.org/10.1103/PhysRevLett.99.038701
- 12. Gfeller, D. and De Los Rios, P. (2008) Spectral Coarse Graining and Synchronization in Oscillator Networks. Physical Review Letters, 100, 174104. https://doi.org/10.1103/PhysRevLett.100.174104
- 13. Zhou, J., Jia, Z. and Li, K.-Z. (2017) Improved Algorithm of Spectral Coarse Graining Method of Complex Network. Acta Physica Sinica, 66, 060502.
- 14. An, Z. and Lv, L.Y. (2011) Coarse Graining for Synchronization in Directed Networks. Physical Review E, 83, 056123. https://doi.org/10.1103/PhysRevE.83.056123
- 15. Song, C., Havlin, S. and Makse, H.A. (2005) Self-Similarity of Complex Networks. Nature, 433, 392-395. https://doi.org/10.1038/nature03248
- 16. Goh, K.I., Salvi, G., Kahng, B. and Kim, D. (2006) Skeleton and Fractal Scaling in Complex Networks. Physical Review Letters, 96, 018701. https://doi.org/10.1103/PhysRevLett.96.018701
- 17. Kim, B.J. (2004) Geographical Coarse Graining of Complex Networks. Physical Review Letters, 93, 168701. https://doi.org/10.1103/PhysRevLett.93.168701
- 18. Xu, S. and Wang, P. (2016) Coarse Graining of Complex Networks: A K-Means Clustering Approach. 2006 Chinese Control and Decision Conference (CCDC), Yinchuan, 28-30 May 2016. https://doi.org/10.1109/CCDC.2016.7531703
- 19. Long, Y.S., Jia, Z. and Wang, Y.Y. (2018) Coarse Graining Method Based on Generalized Degree in Complex Network. Physica A Statistical Mechanics & Its Applications. https://doi.org/10.1016/j.physa.2018.03.080
- 20. Chen, H., Hou, Z., Xin, H. and Yan, Y. (2010) Statistically Consistent Coarse-Grained Simulations for Critical Phenomena in Complex Networks. Physical Review E, 82, 011107. https://doi.org/10.1103/PhysRevE.82.011107
- 21. Wang, Y., Zeng, A., Di, Z. and Fan, Y. (2013) Spectral Coarse Graining for Random Walks in Bipartite Networks. Chaos, 23, 013104. https://doi.org/10.1063/1.4773823