Advances in Pure Mathematics
Vol.05 No.08(2015), Article ID:57075,13 pages
10.4236/apm.2015.58042
High Performance Novel Square Root Architecture Using Ancient Indian Mathematics for High Speed Signal Processing
Arindam Banerjee, Aniruddha Ghosh, Mainuck Das
Department of ECE, JIS College of Engineering, Kalyani, India
Email: banerjee.arindam1@gmail.com, ghoshani19@gmail.com, mrmainuckdas@gmail.com
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 22 April 2015; accepted 8 June 2015; published June 2015
ABSTRACT
Novel high speed energy efficient square root architecture has been reported in this paper. In this architecture, we have blended ancient Indian Vedic mathematics and Bakhshali mathematics to achieve a significant amount of accuracy in performing the square root operation. Basically, Vedic Duplex method and iterative division method reported in Bakhshali Manuscript have been utilized for that computation. The proposed technique has been compared with the well known Newton- Raphson’s (N-R) technique for square root computation. The algorithm has been implemented and tested using Modelsim simulator, and performance parameters such as the number of lookup tables, propagation delay and power consumption have been estimated using Xilinx ISE simulator. The functionality of the circuitry has been checked using Xilinx Virtex-5 FPGA board.
Keywords:
Vedic Mathematics, Bakhshali Mathematics, Duplex, Yavadunam Sutra

1. Introduction
Arithmetic circuits are indispensable in DSP and image processing applications. Many researchers have already designed different arithmetic circuits like adder, subtractor, multiplier, divider, squarer, square root architecture etc. [1] -[9] , but those techniques exhibit more propagation delay and power consumption. Square root design is a very challenging work in modern research area. Newton-Raphson’s (N-R) method of square root computation has been the most efficient approach so far. After N-R method, there has been no remarkable approach for square root computation so far. We are showing an efficient technique using ancient Indian mathematics.
In ancient times, mathematicians made calculations based on 16 Sutras (Formulae). The idea for designing the square root processor has been adopted from ancient Indian mathematics “Vedas” [10] [11] . The well known duplex method is an ancient Indian method of extracting the square root. The algorithm incorporates digit by digit method for calculating the square root of a whole or decimal number one digit at a time. As per the proposed algorithm, the square root of any number is obtained in one step which reduces the iterations. Bakhshali method is used for finding a proximal square root described in ancient Indian mathematical manuscript called the Bakhshali manuscript. A prototype of 16 bit square root processors has been implemented and their functionality has been experimented on a Virtex-5 FPGA board. For calculating integer part of a number, we have used the Vedic method and for calculating the floating point part, we have adopted Bakhshali method. Many researchers have used the most popular Newton-Raphson’s method for computing square root of a number. In our methodology, we are combining both Vedic duplex and Bakhshali approximation to generate more accurate result with comparatively less time and power consumption.
The paper has been organized as follows. Section 2 describes the back ground mathematics for calculating the square root. Section 3 gives the architectural description of the proposed technique. Section 4 describes the error calculation and accuracy analysis of the proposed technique. Result analysis has been described in Section 5 and Section 6 is the conclusion.
2. Square Root Algorithm
Square root technique using Division method was introduced by ancient Indian Mathematicians and the procedure has been lucidly discussed in “Vedas”. The technique stands upon the execution by mere observation. Square root of a perfect square can be easily determined by the Division method. But for those numbers, which are not perfect square, Division method is not enough to compute with high precision. In this paper an iterative method described in Bakhshali Mathematics of Quran has been proposed to achieve high speed and high precision square root calculation. The mathematical formulation of the iterative approach is shown below.
Consider a number X whose square root is to be calculated. The Bakhshali manuscript approach computes the square root of the perfect square which is nearest but less than the number X by the method of observational inspection. Consider A is the above mentioned perfect square whose square root is R.
So it can be expressed as
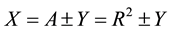 (1)
(1)
where Y is the residue.
Equation (1) can be reformulated as
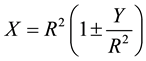 (2)
(2)
So the square root of X can be written as
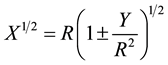 (3)
(3)
Using binomial expansion and the mathematical formulae of Bakhshali manuscript, Equation (3) can be expressed as
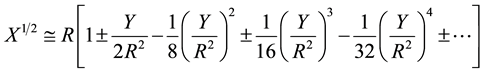 (4)
(4)
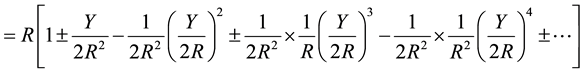 (5)
(5)
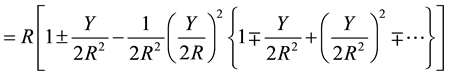 (6)
(6)
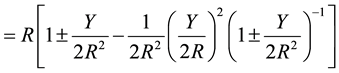 (7)
(7)
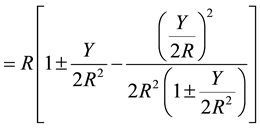 (8)
(8)
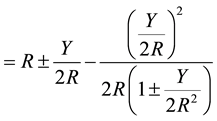 (9)
(9)
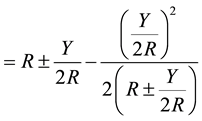 (10)
(10)
Equation (10) is the modified Bakshali expression for computing the square root of non-squared numbers.
In modified Bakshali approach the accuracy is more as comparable to in Bakshali approach which is shown in the table. So in respect of accuracy modified Bakshali approach is beneficial. Also Bakshali methodology contains some drawbacks mentioned below:
1) Bakshali approach does not gives the idea for computing the nearest squared number and its squareroot. To obtain thenearest square number and its square root we have to go for Vedic approach.
2) The division method for calculating the square root using Vedic mathematics is based on “Vilokanam” (Inspection) method which incorporates an extra squaring and extra subtraction operations.
The modified Bakshali approach eliminates the extra squaring and subtraction operations. thus the technique reduces the stage delay.
The square root determination technique combining the Vedic Duplex and Bakhshali approach is shown in the flow chart of Figure 1.

Figure 1. Architecture for square root determination technique.
2.1. Integral Square Root Determinant Using Vedic Methodology
Mathematical Modeling of the Algorithm to Calculate Perfect Square Root
Consider X is an N bit number whose square root is to be determined. X can be expressed as
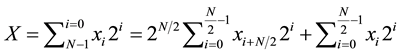 (11)
(11)
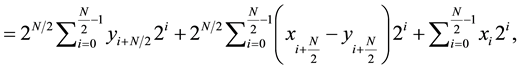 (12)
(12)
Considering 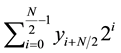 to be the nearest perfect square number of
to be the nearest perfect square number of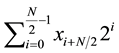 . Now assume that the square root of
. Now assume that the square root of 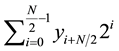 is
is . Then, Equation (12) can be rewritten as
. Then, Equation (12) can be rewritten as
 (13)
(13)
Now consider
 , (14)
, (14)
where Q is the quotient and R is the remainder. Inserting Equation (14), Equation (13) can be reformulated as
 (15)
(15)
Equation (15) can be rewritten as
 (16)
(16)
Assume . Then X can be represented as,
. Then X can be represented as,
 (17)
(17)
 (18)
(18)
 (19)
(19)
 (20)
(20)
The procedure to calculate the square root by division method can be described in the following steps:
Step 1: Obtain the nearest square root of the N/2 Most Significant Bits (MSB). Assume that the output is Z.
Step 2: Determine the square of Z by combining Yavadunam and Duplex methodology.
Step 3: Subtract the squared output from N/2 MSB.
Step 4: Obtain the double of Z.
Step 5: Combine the output of the subtractor and the next N/4 bits. Divide the combination by 2Z. Assume the quotient as Q and the remainder as R.
Step 6: Determine the square of Q and subtract Q2 from . If the residue (p) is zero then X is
. If the residue (p) is zero then X is
the perfect square number whose square root is (Z + Q) otherwise (Z + Q) is the square root of the perfect square nearest to X. Again if “p” is positive then the nearest perfect square number is less than the given input else if “p” is negative then the nearest perfect square number is greater than the input.
Step 7: Compute  by Straight Division (“Dhvajanka”) methodology.
by Straight Division (“Dhvajanka”) methodology.
Step 8: Determine the square of .
.
Step 9: Compute  by add/sub unit.
by add/sub unit.
Step 10: Finally subtract  from
from  to obtain the exact square root.
to obtain the exact square root.
Step 11: Compute the maximum power of first left most “1” of  by left shifting operation.
by left shifting operation.
3. Proposed Architecture
Square Root architecture following the methodology given in Step 1 to Step 6, consists of four sub sections: 1) Nearest Square Root Generation Unit (NSRGU) for first N/2 numbers; 2) Squaring Unit; 3) Sub-tractor; 4) Divider. Figure 2 exhibits a fully optimized system level architecture for square root generation using Duplex method adopted by ancient Indian mathematicians. In this architecture all the left shifters are N/4 bit left shifters. Quotient register is used to store the fixed point or integral result of the square root. The most significant two bits fed to the doubler whose output is fed to the subtraction unit.
3.1. Nearest Square Root Generation Unit
In ancient Indian Mathematics, the nearest square number for a given number and its square root was calculated by the method of inspection. In this paper an easy and efficient architecture has been provided to compute the nearest square root generation. It is obvious that  in “Equation (12)”, the number bits in square root
in “Equation (12)”, the number bits in square root

Figure 2. System level architecture for Integral part of Square root generator, N indicating number of input bits.
must be of N/4 bits. The architecture of the nearest square root generation unit is same as the figure depicted in Figure 2. The above mentioned Step 1 to Step 6 are needed to obtain the nearest square root for N/2 bit number.
3.2. Squaring Unit
Squaring algorithm and the corresponding architecture was implemented with the aid of “Yavadunam Sutra”.
Mathematical Formulation of Yavadunam Sutra
If a number X is between 2n − 1 and 2n then the average of 2n − 1 and 2n is . If X > A
. If X > A
then 2n is chosen as radix and if  then 2n − 1 is the selected radix.
then 2n − 1 is the selected radix.
In Binary mathematics, the number  can be reformulated as,
can be reformulated as,
 (21)
(21)
 (22)
(22)
From Equation (21), the square of the number X can be expressed as,
 (23)
(23)
 (24)
(24)
Similarly, the expression of X2 that can be obtained from Equation (22) is given as,
 (25)
(25)
Equation (24) and Equation (25) are the mathematical formulations of Yavadunam Sutra in Binary mathematics.
The architecture of squaring algorithm using “Yavadunam Sutra” is shown in Figure 3. The basic building blocks of the architecture are 1) RSU, 2) Subtractor, 3) Add-Sub unit and 4) Duplex squaring architecture. The test bench waveform of RSU is shown in Figure 4. The Subtractor architecture using “Nikhilam” sutra has been elucidated in sub-section-(C).
The input bits X (of length n) is fed to the RSU. The RSU produces proper radix and exponent for the input. The radix is subtracted from the input and the result is added to or subtracted from the input again depending upon the control signal generated from the borrow output of the sub-tractor. The output of add/sub unit is the residue which is again squared by duplex operation discussed in [1] and it is also fed to the left shifter which shift the data depending upon the exponent value. Finally the outputs of duplex squarer and left shifter are added to obtain the squared result.
3.3. Subtractor
Mathematical Modeling of “Nikhilam” Sutra for Binary Subtraction
The Subtraction method has been implemented using normal binary arithmetic. It is a bit wise subtraction method. The rule is mathematically expressed in Equation (26). Consider the number,  is to be subtracted from the number
is to be subtracted from the number . So, it can be written as
. So, it can be written as

Figure 3. Architecture of squaring algorithm using “Yavadunam” sutra.

Figure 4. Test bench window for VHDL implementation of RSU.
 (26)
(26)
There is a borrow bit generated at the end of operation which signifies that the result is positive or negative.
3.4. Divider Using “Dhvajanka” Sutra (“On Top of the Flag”)
3.4.1. Mathematical Modeling of Division Operation
Consider the number  to be divided by
to be divided by  assuming that both the numbers are of same length (here the length is (n/2) − 1) and x is the radix. To execute the division operation easily and efficiently by “Dhvajanka” sutra (“On top of the flag”) methodology described in the ancient Indian Vedic Mathematics, Dividend must have greater length than Divisor. Consider again a number A' which can be represented
assuming that both the numbers are of same length (here the length is (n/2) − 1) and x is the radix. To execute the division operation easily and efficiently by “Dhvajanka” sutra (“On top of the flag”) methodology described in the ancient Indian Vedic Mathematics, Dividend must have greater length than Divisor. Consider again a number A' which can be represented
as .
.  can be mapped with
can be mapped with  where the condition of mapping is
where the condition of mapping is . The quotient Q can be determined as
. The quotient Q can be determined as
 (27)
(27)
The term , where x is the radix is to be extracted by Exponent Extraction Unit (EEU). In Binary number system, the radix “x” is equal to 2. Then from Equation (27), it is obvious that the result of
, where x is the radix is to be extracted by Exponent Extraction Unit (EEU). In Binary number system, the radix “x” is equal to 2. Then from Equation (27), it is obvious that the result of  is needed to be
is needed to be
shifted right by n/2 terms which has been shown in Figure 5, to get the actual quotient. The mathematical modeling of division operation by “Vertically and Crosswise” methodology has been described in the following subsection.
The architecture shown in Figure 6 consists of some elementary building blocks like left shifter, right shifter, incrementer and demultiplexer. Incrementer calculates the exponent of the number which is controlled by the shifted bit. The clock applied to the shifter is also controlled by the shifted bit. If the shifted bit is “1” then the shifters stops further shifting.
3.4.2. Mathematical Modeling of “On Top of the Flag” Sutra
Consider the number  is divided by
is divided by . So A' can be expressed in terms of B' as
. So A' can be expressed in terms of B' as

Figure 5. RTL representation of exponent extraction unit.

Figure 6. Divider architecture using “Dhvajanka” sutra.
 (28)
(28)
 (29)
(29)
Here “x” signifies the radix.
Figure 6 shows the architectural description of division operation using “On top of the flag” Sutra. The Dividend of N bits is divided into two equal N/2 bits. The most significant part is fed to the subtractor which is of N/2 + 1 bits size. Single bit zero padding is done in subtractor module to the left. The division procedure incorporated here is non-restoring type of division. The carry output after the subtraction is fed to the quotient array register as quotient.
The quotient array register stores the quotients based on the iterated value which is used as position signal. The value N/2 + 1 is stored in the decrementer initially to count and check the specified iteration. After each iteration, both the left shifters are updated by shifting until the decremented value reaches zero.
The Divider architecture combining the exponent extraction and the “Dhvajanka” Sutra is shown in Figure 7. The basic building blocks of the architecture are 1) Exponent Extraction Unit, 2) Divider using “Dhvajanka”

Figure 7. Divider architecture combining exponent extraction and “Dhvajanka” sutra.
sutra, 3) Subtractor, 4) Quotient Array Register and 5) Bidirectional Shift Register. Zero padding is needed to represent a number to higher number of bits. For example if a four bit number “0111” is represented in eight bit format then the representation becomes “00000111”. Here, zero padding has been executed based on the requirement. Bidirectional shift register performs the operation of shifting both to the left or right depending upon the control signal “carry” from the second subtractor. If carry = 0 then the input bits are shifted to the left and if carry = 1 then input bits are shifted to the right. The result of the second subtractor is fed to the shifter to control number shifting. The contents of the Quotient Array Register are the input to the Bidirectional Shift register.
Illustration: Consider a fourth order function  and a second order function
and a second order function
 . We have to compute
. We have to compute  with the help of “On top of the flag” sutra. Now,
with the help of “On top of the flag” sutra. Now,

where,  and
and 
3.4.3. Adder-Subtractor Unit Using “Nikhilam” Sutra for Subtraction
From Equation (5), it is obvious that to achieve the final result an Adder-Subtractor unit is required which has been designed with the help of well-known binary addition/subtraction methodology. The architecture of Adder- Subtractor unit is shown in Figure 8. The carry signal from the square root determinant shown in Figure 2 is fed to the adder-subtractor unit at the control pin to assign the type of operation (addition/subtraction). If the carry signal is low then addition operation is executed else subtraction operation is executed.
4. Error Calculation and Accuracy Analysis
The exact expression for square root can be recapitulated from Equation (3) as,
 (30)
(30)
The approximated expression for the square root can be expressed as,
 (31)
(31)
So the computational error (ec) in determining the square root can be expressed as,
 (32)
(32)
The percentage of error in calculating the square root is,
 (33)
(33)

Figure 8. 8 bit binary adder-subtractor architecture.
If , then can easily be shown that
, then can easily be shown that .
.
So, . It is obvious that the error is minimum if and only if
. It is obvious that the error is minimum if and only if  that is if Y = 0. Putting Y = 0 in Equation (33), the expression becomes
that is if Y = 0. Putting Y = 0 in Equation (33), the expression becomes . Table 1 exhibits the comparative study of the computational error in proposed algorithm with respect to “Bakshali” algorithm.
. Table 1 exhibits the comparative study of the computational error in proposed algorithm with respect to “Bakshali” algorithm.
5. Result Analysis
The square root architecture has been implemented using VHDL and verified using Modelsim simulator which is shown in Figure 9 and tested in Xilinx simulator with Xilinx Vertex-5 FPGA using XC5VLX30 device with a package FF676 at a speed grade (−3). Table 2 shows the comparative study of the N-R method and the proposed method with respect to LUT count, delay and power consumption. The power has been measured using Xilinx Xpower Analyzer tool.

Table 1. Coefficients of the quotient expression.
Table 2. Comparison of LUT count, delay and power of two methods.

Figure 9. Test bench window of VHDL implementation of square root architecture.
6. Conclusion
From the result analysis, it is obvious that the architecture provides comparatively more accuracy than the well- known N-R approximation. Moreover, the proposed architecture produces less amount of propagation delay than N-R method and the power consumption is also very less as shown in Table 2. The area with respect to LUT count is also less than N-R method. It has also less circuit complexity than N-R technique which has been elucidated in the result analysis.
Acknowledgements
We would like to thank our dear colleagues for their precious support to execute the research in the department.
References
- Oberman, S.F. and Flynn, M.J. (1997) Design Issues in Division and Other Floating Point Operations. IEEE Transactions on Computers, 46, 154-161.
- Pineiro, J.A. and Bruguera, J.D. (2002) High-Speed Double-Precision Computation of Reciprocal, Division, Square Root, and Inverse Square Root. IEEE Transactions on Computers, 51, 1377-1388.
- Kwon, T.J. and Draper, J. (2008) Floating-Point Division and Square Root Implementation Using a Taylor-Series Expansion Algorithm with Reduced Look-Up Tables. 51st Midwest Symposium on Circuits and Systems, Knoxville, 10- 13 August 2008, 954-995.
- Park, I. and Kim, T. (2009) Multiplier-Less and Table-Less Linear Approximation for Square and Square-Root. IEEE International Conference on Computer Design, Lake Tahoe, 4-7 October 2009, 378-383.
- Ramamoorthy, C., Goodman, J. and Kim, K. (1972) Some Properties of Iterative Square-Rooting Methods, Using High-speed Multiplication. IEEE Transaction on Computers, C-21, 837-847.
- Thakkar, A.J. and Ejnioui, A. (2006) Design and Implementation of Double Precision Floating Point Division and Square Root on FPGAs. IEEE Aerospace Conference, Big Sky.
- Ye, M., Liu, T., Ye, Y., Xu, G. and Xu, T. (2010) FPGA Implementation of CORDIC-Based Square Root Operation for Parameter Extraction of Digital Pre-Distortion for Power Amplifiers. 6th International Conference on Wireless Communications Networking and Mobile Computing, Chengdu, 23-25 September 2010, 1-4.
- Ercegovac, M.D. and McIlhenny, R. (2009) Design and FPGA Implementation of Radix-10 Algorithm for Square Root with Limited Precision Primitives. Conference Record of the Forty-Third Asilomar Conference on Signals, Systems and Computers, Pacific Grove, 1-4 November 2009, 935-939.
- Wang, X., Zhang, Y., Ye, Q. and Yang, S. (2009) A New Algorithm for Designing Square Root Calculators Based on FPGA with Pipeline Technology. 9th International Conference on Hybrid Intelligent Systems, 1, 99-102.
- Maharaja, B.K.T. (1994) Vedic Mathematics. Motilal Banarasidass Publisher, Delhi.
- Saha, P., Banerjee, A., Bhattacharyya, P. and Dandapat, A. (2011) High Speed ASIC Implementation of Complex Multiplier using VEDIC Mathematics. Proceeding of the 2011 IEEE Students’ Technology Symposium, Kharagpur, 14-16 January 2011, 237-341.