Low Carbon Economy
Vol.3 No.2(2012), Article ID:20447,10 pages DOI:10.4236/lce.2012.32006
Economic Impacts of Climate Change on Secondary Activities: A Literature Review
![]()
1Department of Business Economics, South Campus, University of Delhi, New Delhi, India; 2Economics Program, Debre Berhan University, Debre Berhan, Ethiopia.
Email: {surender672, amsalueth}@gmail.com
Received March 2nd, 2012; revised May 1st, 2012; accepted May 8th, 2012
Keywords: Climate Change; Economic Impacts of Climate Change; Non-Agriculture Industries; Manufacturing Sector; Repercussion Effects; Labor Productivity
ABSTRACT
The fast growing literature on economic impacts of climate change is inclined to assessing the impacts on agricultural production and productivity and on human health. The economic impacts of climate change however, go beyond these sectors. In this paper, we attempted to review the scarcely available literature on the economic impacts of the change in the climate of the earth on some selected non-agricultural secondary and tertiary level of economic activities. It is attempted to summarize the ways through which the climate change can affect non-agriculture economic activities. The discussion on the literature can be synthesized as showing the impacts on secondary and tertiary level of economic activities are wide and complex and eventually may be larger than on the impacts on agriculture for those middle and high-income countries where the share of agriculture in national GDP is low.
1. Introduction
Climate change is unequivocal [1]. The change alters all sustainable development dimensions (i.e. economic, social, and environmental), and hence the potential development path ways [2,3] for a given nation or region. It even is claimed that climate change to be the “mother” of all problems to show its irreversible impacts [4]. The set of mechanisms in which climate change affects economic and environmental outcomes are too vast and complex to investigate comprehensively. Therefore, it is intellectually daunting to deal with it [4].
Partially because of its bio-physical dependence on the two metrological variables, precipitation and temperature, among others, and partially due to relatively quantifiable impacts on it; the literature on economic impacts of climate change so far, however, is inclined to production and productivity on agricultural sector. Even on this line we do have very limited literature assessing the indirect impacts accruing to change in price and comparative advantage. Next to agriculture, the fast growing literature on the impacts of climate change has made attempts to assess the impacts of climate change on human health.
In reality, however, the economic impacts of change in the earth climate go beyond the agriculture sector. Reference [5], for example, found the impacts on (non-agricultural) industries and investment to be high and statistically significant on poor countries which eventually is associated with a 1.1% fall in economic growth in poor countries for each additional 1˚C. Reference [6] documents a –2.2% production change in the transportation and communication sector for a unit of additional degree Celsius in 28 Caribbean and Latin American countries. Reference [7] showed the positive correlation between climate shocks and export performance. Ignoring the production and productivity impacts of climate change on other economic sectors, therefore, will understate the economic impacts of climate change which in turn affects the mitigation and adaption responses.
Motivated by this gap, this paper attempted to review the scarcely available literature on the economic impacts of climate change on some selected non-agriculture industries. It was attempted to derive the ways through which climate change can affect the non-agricultural industries. Though climate change can also positively affect the non-agriculture industries (e.g. through new taste and preferences for some goods; new markets for technologies) we were biased towards the negative aspects. Add to this, the paper is based on some selected case studies on some geographical areas as illustrative examples.
2. Ways through Which Climate Change May Affect Non-Agriculture Industries
Reference [5] which used annual variation in temperature and precipitation over 50 years (1950-2003) on 136 panel of world countries reported that there is deleterious effect by climate change on economic growth (in poor countries particularly). Accordingly, there was significant loss in industrial output too. They found that +1˚C increase in temperature reduces growth in poor countries (but not in rich countries) by 1.1 percentage points. The cumulative growth effects will even grow to –1.3% and –1.5% to –2.01% if we include one and three, five, or ten lagged temperature effects respectively. A 1˚C higher temperature in poor countries is not only associated with 2.44 percentage points lower growth in industrial output but also with –3% growths in investment again in poor countries in addition to increased probability of political instability (riots and protests).
The economic impacts of climate change won’t end by reducing production in both agricultural and non-agricultural [6], growth of national output and industrial output [5], and exports [7]. It also extends to distributional effects. National per capita income is observed that, based on 2000 year cross-section data, to fall by 8.5% per one degree Celsius increase in temperature [8]). In fact, [8] documented, temperature alone can explain 23% of the variation in cross-country income today.
Reference [6], which looked at 28 countries of Caribbean-basin reported that the output loss in non-agricultural (wholesale, retail, restaurants, hotels, mining and utilities, and other service sectors) production to be 2.4% compared to a 0.1% loss in agricultural production (agriculture, fishing and hunting) for a unit degree Celsius increase in temperature. Though statistically insignificant, [6] documented that the loss in non-agricultural production is 29 times than that of loss in agricultural production. There is even difference among the non-agricultural business included in [6]. While wholesale, retail, restaurants, and hotels respond significantly (–6.1%); mining and utilities, and other services respond –4.2% and –2.2% respectively for one degree Celsius increase in temperature. The response of agricultural production (agriculture, fishing and hunting), however, was moderate (–0.8%) in Central and Latin America. Reference [6], further, draws our attention to an interesting point that the loss even will be magnified if we do look at the relative economic contribution of the industries in the region. While the industries with tremendous loss (wholesale, retail, restaurants, other service sectors) constitute on average 55.4% of the region’s value added GDP; the agri-business (agriculture, fishery and hunting) contributes only 10.5% of GDP in the region. One, then, can easily estimate the economywide loss due to impacts on non-agricultural production compared to agricultural production. Twenty-nine folds it is [6].
The studies above suffice us to conclude that the economic impacts of climate change on non-agriculture production and productivity is also immense and quantifiable so that should be given attention. Assessing and quantifying the impacts on secondary and tertiary level of economic activities, however, is too complex and tiresome. Partially, it needs understanding the inter linkage between the primary industries and secondary and tertiary level of economic sectors and the product, financial, and factor markets of these industries. Add to these, assessing the impacts on economic activities other than agriculture are complex as ways through which climate change affects these economic activities are many and can’t easily be modelled.
Herein below, we have depicted the conceptual framework in which the climate change may affect the nonprimary industries (i.e. manufacturing and service industries) based on the literature followed by discussions on some selected industries on each channels under Section 3. Though we should acknowledge that Figure 1 is very simplified representation, we do believe that it will give a sense for the reader two main messages. First, the ways through which climate change affects non-agriculture sectors are many compared to channels on agriculture and human health. Second, the ways are interdependent and are at multi-stages. Both of these make the assessments as well as reviews complex and tiresome.
2.1. Impacts through Labour Productivity
Labour is a crucial element in every production process. Both of its quantity (say numbers of working hours) and quality (skill and productivity) are essential. Any factor that affects these two characteristics of labour (quantity and quality) affects production and profitability of the industry. To be productive a labour should be healthy enough both mentally and physically. Any impact on labour health (mortality and/or morbidity), therefore, is transmitted to the non-agricultural industries. These can be seen as direct effects of labour productivity due to climate change.
There are four main lines in which climate change affects human health: 1) increase in mean temperature by itself results/exacerbate some diseases such as kidney stone [9]; 2) extreme weather events (such as heat waves, cold waves, and storms) increase prevalence of some diseases such as cardiovascular and heat stress [10]; 3) temperature, precipitation, and wind variability affects the reproduction, spatial and seasonal distribution of some disease causing vectors (such as mosquito) and bacteria (as in food poisoning to cause salmonella) [11, 12]; and 4) indirect effects through drought (escalating water scarcity and malnutrition), flooding (death and personal injuries), and tropical cyclones (death and injuries). Shortly, climate change contributes to both mortality and morbidity rate of human beings which in turn has critical role on labour productivity (in economic terms)
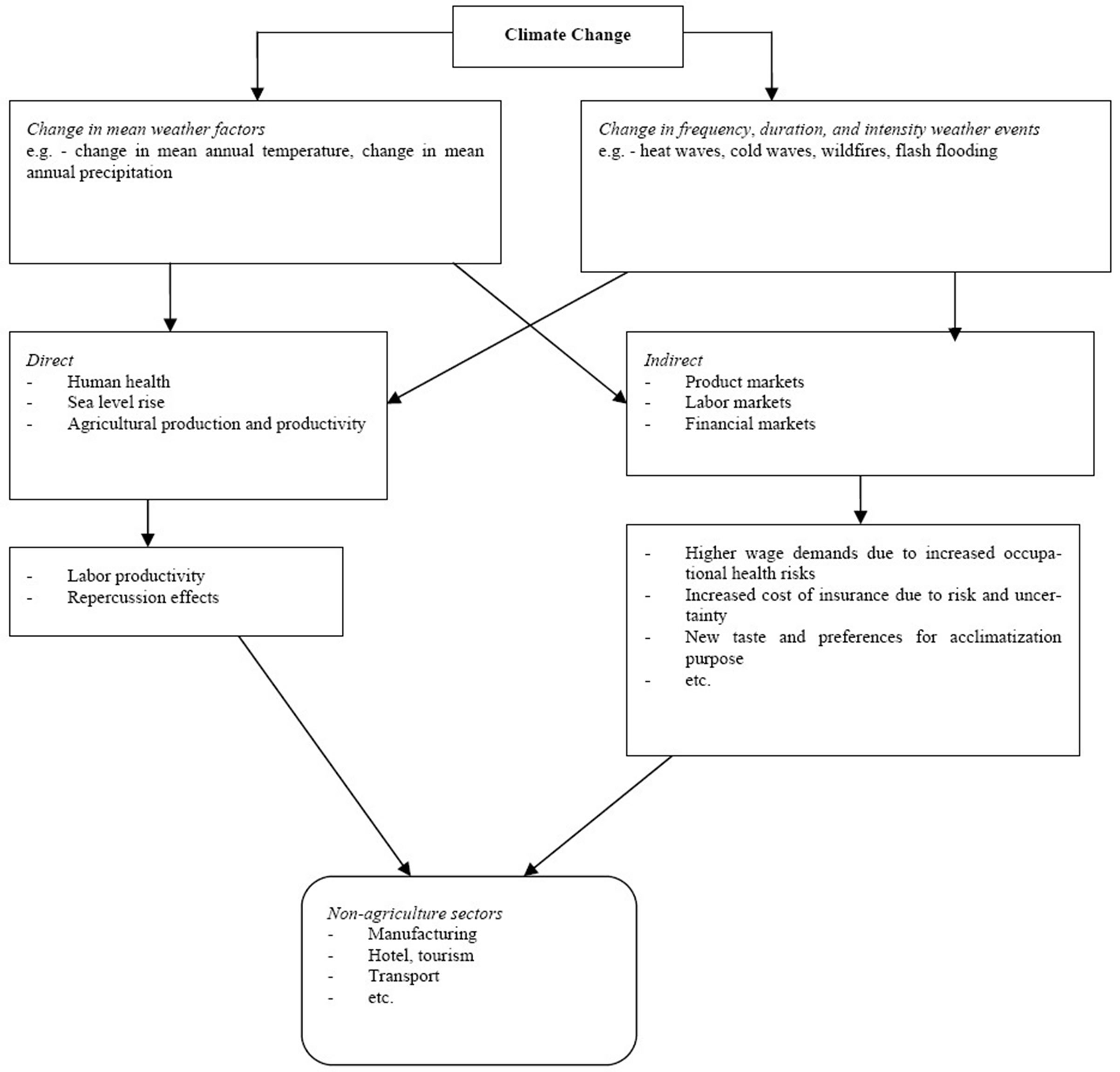
Figure 1. The ways through which climate change may affect the secondary and tertiary level of economic sectors.
and work capacity (in psychological sense) [13].
If body temperature, for example, is not being balanced by external cooling device, heatstroke (if greater than 39˚C) and a threat to life (if greater than 40.6˚C) may happen [13]1. Moreover, most ergonomic studies, based on laboratory and observational surveys, agree that most forms of human performance deteriorate under levels of thermal stress beyond a threshold [6]. This concern is especially important for the manufacturing sector which involves working with machines which themselves let heat out in factories. According to [14] any extended peak heat stress period with and more than 35˚C wet bulb temperature will result hyperthermia in humans and other mammals which perturbs the metabolic system. Heat stress may eventually alter life style and working hours and days [14]. There are also syndromes associated with excessive fluid loss. Low urine, which leads to kidney stone, is one of such diseases. A study by [9] has discussed climate-related increase in the prevalence of urolithiasis in the United States. The study has reported in the same paper that there will be expansion in “kidney stone belt” which bring up the fraction of US population under risk of kidney stone disease from 40% in 2000 to 56% and 70% in 2050 and 2095 respectively. Under intermediate severity warming scenario, SRESa1b, climate change related increase in prevalence of nephrolithiasis (kidney stone) will reach 1.6 to 2.2 million lifetime cases by the year 2050 which in turn breeds additional expenditure of USD 0.9 to 1.3 billion (at 2000 price) per annum. One can imagine the opportunity cost of such extra costs associated with a single case. An interesting study by [6] which looked at the impact of thermal stress, due to increased mean temperature, on labour productivity and hence on output production and productivity based on 28 Caribbean-basin countries (Caribbean and Latin American countries) summed up that the significant loss in wholesale, retail, hotels, and other services (–2% from the economy-wide loss of –2.5%), which is more than 20-fold compared to losses in agriculture, fishing, and hunting (–0.1%), shows the centrality of loss in labour productivity in explaining fall national output due to climate change in contrast to the dominant view that the later always happen due to fall in agricultural production which in turn has repercussion effect to the whole economy. Production’s weak dependence to temperature transits to strong dependence occurs around 27˚C - 29˚C daily average temperature (which roughly corresponds to ‘wet bulb globe temperature-WBGT’, > 25˚C, under normal sea level) [6]. This is a threshold level of thermal stress in which human performance starts to deteriorate as evidenced by many ergonomic studies [6]. Reference [6] also reported that in regions where the daily average regularly exceeds the WBGT labour-intensive industries exhibit greater economic loss. As a result, it is reported that the response of output growth to a change in temperature is similar to labour productivity [5,6].
Reference [12] which briefly discussed the impacts of climate change for UK in the 2050s reported heat related death in UK may increase to 2800 cases per year though it may be offset by decrease in deaths related to cold waves. The heat wave in August 2003 in Europe has caused 1500 extra deaths in Northern France and 2000 extra deaths in England and Wales [12]. The death toll is reported to be about 50,000 in the whole Europe (Bruker, 2005 as cited in [10]). The damages owing to storms and tornados are also formidable. Debris and falling trees and buildings will increase personal injuries. The Hurricane Katrina of 2005 in the US caused about 1800 deaths while 700 fatalities are reported due to the 1995 heat wave in Chicago [10]. Heat waves in 2006 have killed around 200 and 1000 peoples respectively in the US and the Netherlands [10]. Mortality and morbidity associated with heat waves are also most common in India [10,11].
Flooding, ultraviolet radiations and droughts another class of consequences of climate change, is also reported to cause mental health deteriorations mainly associated with personal and economic stress. The probability of diseases such as skin cancer and cataracts will also increase with ultra violet radiation (UVR) which is due to ozone depletion. Climate change also affects the reproduction, and spatial and seasonal movement of some vectors (such as mosquito) which in turn increases the incidence of vector-borne diseases such as malaria and dengue. There may be re/establishment of malaria in currently malaria free regions. Reference [12] has documented such threat for UK. High temperature may also increase the possibility of food poison to which effect cases related to salmonella infection each year increases.
All these, indirectly, cause the private as well as the public sector to incur additional cost of providing information, surveillance programmes, increase expenditure on inbuilt environment, increase in health and social service infrastructure (and hence increase in opportunity cost of health investment), and further research and policy consultancy on the issue.
If the stress and fall in performance continues many industries will lose in long run as it does need either to hire new employees (which bring extra cost of recruitments and training) or fall in gross revenue due to less productivity of labourers. Under A2 climate change scenario, [13] documented, the absolute loss in population-based work capacity will range from 11% to 27% in South East Asia, Andean, Central America and the Caribbean.
In closing, climate change through its effects on mean temperature and precipitation, frequency of extreme weather events, droughts, flooding, and wind storms, will pose a real challenge to labour productivity and hence any sector which uses labour. Presuming that labour is being paid based on its productivity in the primary sectors, as in a standard macro and labour economic analysis, the manufacturing and service sector will be affected not only due to mortality and morbidity to labourers engaged within the sector only but also due to fall in productivity of labourers in the primary sector. Put another way, by presuming labour will be paid based on its marginal productivity, as in any standard economic analysis, demand for manufactured goods and services will fall due to fall in farm/agricultural income.
2.2. Repercussion Effects
Climate change does also affect the non-agricultural industries through its effects on the climate dependent primary economic activities. Food and brewery, textile, and other natural resource dependent (e.g. timber and pulp and fishery) are among such industries through which climate change can have repercussion effects on nonagriculture economic activities. Because the production process in these industries is also (more of unskilled) labour intensive, the impacts, are double—through both labour productivity and repercussions. See Sections 3.2 and 3.3 for more on repercussion effects.
2.3. Indirect Impacts through Markets
Climate change also affects the manufacturing industry through markets. It affects through both product and financial markets.
Our consumption, dressing, and other ways of life will always be shaped by our physical environment. Climate change, thus, affects taste and demand of goods and services. If temperature increases, for example, the taste for wool product will fall. Reference [15] which assessed the economic impacts of climate change on Australian wool industry has reported both wool production and prices have been falling since 1987. Climate change generally affects life style [14]. Of course, there are gains, too, to the industry through increased taste and preference for some products—for example, Air Conditioner, Heater, light clothes, and likes. New market opportunities are available too. We have seen construction industry will benefit from reconstruction and relocation after destructions caused by cyclones and flooding. Again the market also needs now new design and engineering.
It is plain fact the any industry needs financial loan and insurance for its business. The manufacturing industry, too, needs insurance for the risks and uncertainty associated with the industry. The more risky and uncertain the industry you are engaged with the higher is risk premium needed to be paid. Therefore, those industries which are highly affected by weather changes (e.g. construction and housing industry); produce perishable goods and services (e.g. hotels, restaurants, food and brewery); tourist destinations (e.g. beach) will be subjected to high risk premium which in turn affects the production cost for the industries. It will also be very difficult for industries (whose business is sought as risky and uncertain) getting financial loans.
We can also look at the labour market. Increased risks and uncertainties associated with working environment does mean increased occupational health risks which in turn provokes workers to seek better wages and salaries to reduce gross profit of manufacturing industry. On the other hand, non-agriculture industries particularly those using unskilled labour may benefit from cheap labour due to increased rural-urban migration which is pushed by fall in agricultural production and productivity due to climate change.
3. Some Selected Non-Agriculture Industries: For Illustration
3.1. On Construction and Housing Industry
Climate change alters the magnitude, intensity and frequency of climate variables. The magnitude, pattern, intensity and loads of mean annual temperature, precipitation, wind (moisture, movements, direction) will be different with change in the earth climate. These events, in turn, affect those industries whose operation is highly associated with the climate variables.
Construction and housing industry is among them. The construction and housing industry consists of general (such as residential and commercial buildings), heavy or civil engineering (such as bridges, high ways), and industrial (which involves building and/or assembling infrastructure, such as electric power works) constructions.
Significant variations in variables of climate (temperature, precipitation, and wind) have tangible effect on the process and engineering of construction. A rainy winter, hot summer, and windy spring affect the construction process. Such events, for instance, delay the contractual period which in turn breeds additional costs to the contactor. The delays in turn affect the reputability and goodwill of the real estate firms. On the other hand, coastal erosion, subsidence, flooding, and change in draining systems influence the choice of construction site to which effect geological survey costs increase. Add to these, increase in temperature and extreme weather events increase the depreciation rate (wear and tear of buildings) of existing structures. Both have an immense implication to a businessman running in real estate. For instance, significant loss in production of construction (–2.2%) in hottest season (September, October, and November) was reported in Caribbean and Latin American countries [6].
The other impacts to this industry come through adaptation costs. The first is that the construction and housing industry needs to reengineer and/or put new designs to make the buildings resilient to loads from extreme climatic events. The increase in occupational health risk also decrease the profitability of the industry through increased wage to compensate the risks associated with it. The industry, moreover, will be subjected to high risk premium. If the impacts are being again immense and unpredictable there is no ground for lenders not to decline to avail funds to the construction industry as the former do always prefer risk-free business than risky one.
But, as some studies documented, the construction industry is also beneficiary from climate change mainly due to construction, reconstruction and rehabilitation of mass destructions to infrastructure, houses and new settlements which are mainly due to misfortunes due to climate change such as flooding and hurricanes. Because of the role of reconstruction, [6] documents, construction output expands +1.4% and +1.4% the year following for the unit SD2 increases in the Caribbean and Latin American countries.
3.2. On Food and Brewery Industries
Unlike the case of construction and housing industries where the impacts primarily owe to the change in climate variables and increased possibility of extreme weather events; the impacts on food and brewery industries primarily owe to repercussion effects of climate change through agricultural production and productivity. Note that by food and brewery we do mean industries which depend on crop and/or livestock production. Livestock production is affected due to both the quality and amount of forage from grasslands and direct effects on livestock due to higher temperature. Hence, not only the food industry that depends on it (e.g. milk production) but also those which depend on skin and hide (e.g. leather textile industry) are highly affected. The impact on the food and brewery industry still is not even. It depends on the climate sensitivity of the raw materials they are using.
Needless to say, the agriculture is the most vulnerable sector as climate change is the primary determinant of agricultural productivity [2,16-18]. It affects both farm income and food security. Reference [5], which looked at the association between climate change and economic growth using annual variation in temperature and precipitation over the past 50 years to examine the economic impacts of climate change on world economic activities, found that a 1˚C increase in temperature lowers agricultural output growth rate by 2.37% in poor countries. One can imagine what the repercussion effects might be if agricultural output growth falls by such magnitude. A fall in agricultural output is a fall in inputs for food, brewery, and textile industries. Reference [7] findings consolidate the same.
Reference [7] used international trade data to examine the effects of climate shocks on economic activities running panel data regressions relating the annual growth rate of a country’s exports in a particular product category to the country’s weather in that year (i.e., its average temperature and precipitation). Accordingly, though the impacts of developed countries’ export is almost nil, one degree Celsius warmer in a given year reduces the growth of a poor country exports by between 2.0 and 5.7 percentage points. We know, of course, what poor countries are exporting mainly. Furthermore, they found that among the top five export items in the United States in which climate change affects significantly and negatively, the four were in food and brewery and textile Industries—dairy products and eggs, leather, foot wear, and cereals and preparations.
Taken together, the impacts of climate change on agricultural production and productivity is not only confined to the annual agricultural output and income. It rather go beyond the agricultural sector and the impacts, through repercussion effects stretches to other industries whose raw materials directly and/or indirectly is obtained from agriculture. Rather than widening our discussion over many industries, we picked here the wine and sugar industries as example. We, however, should acknowledge that two sectors are not sufficient enough. One, therefore, can find many studies on the economic impacts of climate change on agriculture, especially on crop production, in many countries.
Wine (whose raw material, grape, mainly grows between 30˚N - 50˚N and 30˚S - 40˚S) will be affected much as grapes are highly climate sensitive crops [19]. The same study, basing the European, North American, and Australian wine industries document that an increase in temperature as what is reported in the Fourth Assessment Report of Intergovernmental Panel on Climate Change (IPCC, 2007: 1.5˚C to 5˚C) will result significant shift in grapes and wine viticulture growing regions so does wine production [19]. This particularly may affect low latitude countries. Reference [19] further went to show that the impact on the vine and wine composition. By presuming a quadratic effect of temperature on wine quality in some regions (25 regions out of 30) and fruit variety (red) show positive gain while some other regions (5 out of 30) and fruit type (white variety) loses at current temperature. Therefore, [19] argue, many wine producing regions may be being benefited from [theoretically] optimum temperature these days. A further increase in temperature, however, does imply fall in quality of wine production. It, however, may create new business opportunities for new (higher latitude) areas. For example, a study by [20] which measures the effect of year to year changes in the weather on wine prices and winery revenue in the Mosel Valley in Germany, a well-known wine growing region between 49.61˚ and 50.34˚ latitude, found that a 1˚C temperature would increase wine growing farmers’ income by 30% using the Ricardian approach.
Rainfall, radiation and temperature are the three major determinants of sugar cane production. In countries like Fiji, where sugar industry is a prominent sector in an economy, the impacts of climate shocks (such as droughts) will be tremendous and will shock the whole economy. For instance, the production of sugar in the same country fell from 293,653 tons to 255,703 tons due to droughts [21].
In sum, many studies, on both crop and livestock production, have showed that climate change affects any form of agriculture though the degree, direction, and the ways it affect may vary from crop to crop; from region to region; and from season to season. The impacts, however, won’t end there. Climate changes through its repercussion effects of agriculture will affect the production and productivity of food and brewery industries. With increasing world population, the impacts on such industries are of special interest of research.
3.3. On Timber, Fishery and Mining and Quarrying
Timbering, fishing, and mining are other major economic sectors whose production and productivity highly hinges on the health of the ecosystem. These economic sectors are also primary economic activities by level of production even though are different in their nature of production. Therefore, a comprehensive review on the economic impacts on these industries should incorporate from the direct bio-physical relationship between climate change to the final supply of goods and services which directly or indirectly take the resources produced by these sectors as raw materials for further processing. For example, any impact on fishing will be transmitted to the fish food industries as we discussed in the earlier sub-section. Impacts on timber production can also be taken as a proxy for impacts on furniture and pulp industries. Such comprehensive studies, assessing the impacts from the biophysical relationship to the supply and price of final goods and services, however, were hardly available. The discussions herein below, therefore, are based on the impacts based on bio-physical dependence of the sectors with the climate and climate change.
The impacts of climate change on the timber industry have been being assessed since a decade ago. The findings of the studies, however, are mixed depending on the region of study and the way in which climate change may affect the timber industry. The net effect to a specific region hinges on the balance between the impact of climate change on existing forest stocks (due to dieback, outbreak of pests and diseases, forest fire, and extreme events) and gain in productivity (due to warmer temperature, longer growing seasons, and increased CO2 concentration) [22-24]. See, for example, [25] for more on the negative impacts of climate change (through spread of plant insects, hurricanes and heat waves, and increased likelihood of forest fires) in the USA, Canada, Europe and Australia. Add to this, many ecological and economic literature on the arena found that climate change will shift geographical distribution of tree species and alter productivity. While high latitude forest may move to tundra; mid latitude forests are affected due to dieback and change tree species; low latitude forests, however, gain due to increase in productivity as short rotation is there [23]. There is one thing in common, however. Climate change increases forest productivity and hence there will be more global timber supply to which effect world consumers will benefit from lower timber price which in turn may increase welfare increase may range from 2% to 8% [23]. Note that impacts of climate change on other forest product dependent industries (e.g. pulps and paper) follow the same track.
Another natural resources dependent sector is fishery. Climate change has both direct and indirect impacts on fishing sector. Future production of both inland and marine fish is likely to be affected by the increased frequency and intensity of extreme climate events [26]. Climate change affects the physiology, behaviour, growth, development, reproductive capacity, mortality and movement of fish. It may also help to competitor species, such as Pacific oyster (Crassostrea gigas), and pathogenic species to spread [26]. Reduced precipitation and increased evaporation of inland lakes is detrimental to fish production. The uncertainty and lack of data to capture the impacts coupled with difference in impacts on different regions and fish species, and change in socioeconomic factors (population, fishing activity, and consumer demand) make the argument incomplete to substantiate and quantify climate change related threats for future fishery production and supply. Changes in fish production can be addressed with policies that have elements of flexibility, adaptability to new information about the marine system, reflexivity (i.e. continuous evaluation of the consequences of management in relation to targets), and transparency in the use of information and governance [26].
Climate change has an implication for another primary resource industry—mining and quarrying. The change in climate affects extraction, production and shipping process in the mining and quarrying industry. It does also affect exploration and discovery efforts [27]. Reference [27], citing previous studies, document that climate change affects operation process of mining (through water scarcity, for water dependent mining such as sodium sulphate). The increased temperature and humidity add more to the concern. Warmer temperature; change in rainfall patterns; frequent extreme events; and sea level rise, inter alia, will increase the occupational health risks associated with mining. Such effects in turn affect the mining and quarrying industry through labour markets (i.e. increased wage demand) and financial markets (i.e. higher risk and insurance premiums) [27]. The shipping of the freights, for example, will be affected in those regions where ice transportation is being used. For instance, in Diavik diamond mine in the Northwest Territories spend about $11.25 million extra on transporting 15 million litters of fuel air due to premature closing of their ice road due to unreasonably high temperatures [27]. As the mining processing operations are water intensive, the processing operations are also climate change vulnerable. An increase in climate-related hazards (such as forest fires, flooding, windstorm and likes) will affect the viability of mining operations and potentially increase operating, transportation, and decommissioning costs [28, 29]. Worse is that, as it is reported for the case of Canada, most mine infrastructure was built based on presumption of climate won’t change which in turn make adaption plans limited [27,30,31].
4. Limitations of the Study
The review of the existing literature on the economic impacts of climate change on non-agriculture industries was biased to negative impacts. An increase in mean annual temperature may reduce the taste and preference (and the demand) for wool products but it will increase the demand for such light and nylon clothes. It may affect the sheep production and productivity negatively but positively the cotton production and productivity. Adaptation is natural to human beings. Adaptation, however, at both firms and national level, was not taken into account here. The paper does also focus only on some randomly selected non-primary industries as illustrative examples. We, therefore, disclaim that the paper is comprehensive review on the economic impacts of climate change on the secondary and tertiary industries as such. It merely is intended to provide alternative insight on the economic impacts of climate change on economic sectors other than agriculture.
5. Conclusions and the Research Need
Climate change is a leading agendum today. Its impacts, vulnerability and adaptation issues have drawn many scholars from the political, academic, and research sphere [4,5]. The economic literature on the impacts of climate change, however, is inclined to the impacts on agricultural production and productivity. There is also thin but growing literature on the impacts of climate change on human health. This, however, make the economic impacts due to climate change incomplete as non-agriculture industries (manufacturing and services industries) are also being affected. Moreover, impacts on these sectors are high in absolute terms as the two industries contribute to more to national GDP in absolute terms than agriculture in many countries [6].
This review paper was motivated by this gap in the literature. It was aimed at providing a general highlight on the ways in which climate change may affect the nonagriculture industries rather than providing a detailed, technical, quantitative, and comprehensive analysis. Among others, the case of construction and housing industry; food and brewery industry; textile industry; timber and pulp industry; fishery; mining and quarrying industries were reviewed. Accordingly, there are four main lines in which climate change challenge the non-agriculture industries: 1) direct (through variations in climate variables); 2) supply of raw materials from primary sector, agriculture and natural resources; 3) through changes in labour productivity; 4) and indirectly through markets (through risk and insurance premium, new market opportunities, and new taste and demand, and labour markets). Apparently, like in the case of impacts on agriculture and human health, there are likely regional winners and losers from climate change.
Future research on the topic, however, should identify and quantify the immediate and direct impacts of climate change (particularly in long-run) on wealthy nations along with transmission mechanisms of impacts from poor to rich countries. World, in reality, is more integrated than ever. Either negative or positive effects in poor countries soon will be transmitted to the whole world. World oil price is a good example here. Its supply shock, if it happens, will affect the whole globe. Transmission mechanisms; from local to national, from nation to region and then globe, sector to economy wide, of course, should explicitly be indentified. A loss in agriculture production and productivity, for example, may increase population movement say from poor to developed countries which in turn has political, social and economic implication.
The research so far on the arena is more or less concentrated on the impacts of increased temperature on output production and/or factor productivity. But, temperature is only one of climate variables. There are few studies on the impacts of climate change via altered precipitation amount and pattern. The economic impacts of increased frequency of extreme weather events such as hurricanes and flooding are less assessed compared to that of temperature. Earlier studies are also more of sector-wise than economy-wide impacts: on agriculture, on human health, on crop production, on livestock production, on forestry, on fishery, on water, and likes. Future studies shall concentrate on economy-wide impacts as it will increase the concern on climate change among stake holders and will have better policy implication.
Again, future researches should concentrate on longrun than simply working on short-run implications of increase in temperature and/or precipitation. Studies should concentrate on long term time framework not only for the sake of calibrating the lagged effects but also economies usually recovery slowly which in turn implies negative economic growth [5] and/or loss of property due to cyclones, for example, will have far reaching consequences. Increased temperature, for example, was found to affect investment [5,6] and political instability [5] both of which are critical for sustainable economic growth and welfare improvement. Reference [6] even showed that the sum total of (indirect) effects for the remaining (infinity) years to be 22.5% if the production loss in this year to be 2.5 % (direct) presuming that output in the year t is approximately 0.9 of year t-1 with a unit increase in temperature. Reference [5] has put two limitations of depending of short-run fluctuations data. They pinpointed the results may be different if someone considers the long-run as there may be adaptation. They also documented that the cumulated effect of temperature becomes stronger as more lags are added which in turn suggests the effects of temperature shocks strengthen over time rather than diminish [5]. The other con of focusing on short run is that it will understate the physical impacts of climate change and it won’t consider the interplay between the physical impacts themselves. Therefore, uncertainty in interplay and relative size (contribution) of each climate factor to be assessed well; the time horizon should be stretched out. Again focusing in short-run impacts leaves only the poor countries to be the main losers.
In closing, therefore, future research on the topic should indentify the transmission mechanisms—from regions to regions, from sector to sector, from sector to economywide; should focus on the long run too; and should indentify the interplay and relative contribution of different climate factors (temperature, precipitation, wind storms). Put another way, studies on the economic impacts of climate change should be stretched out to gauge some more economic activities; possible long term effect; and some more channels through which climate change impose challenges to human beings. It is through this that the impacts can be estimated better; reports echoing only poor nations will be affected can get lesser and lesser; and can enhance political commitment on mitigation and adaptation activities.
REFERENCES
- Intergovernmental Panel on Climate Change (IPCC), “Summary for Policymakers. Climate Change 2007: The Physical Science Basis,” In: Contribution of Working Group I to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change, Cambridge University Press, Cambridge, 2007.
- A. Iglesias, “Climate Change and Agriculture,” CGE HandsOn Training Workshop on V&A Assessment of the Asia and the Pacific Region, Jakarta, 20-24 March 2006.
- S. N. Seo, R. Mendeloshn and M. Munasinghe, “Climate Change and Agriculture in Sri Lanka: A Ricardian Valuation,” Environment and Development Economics, Vol. 10, No. 5, 2005, pp. 581-596. doi:10.1017/S1355770X05002044
- J. M. Griffin, “Introduction: The Many Dimensions of the Climate Change Issue,” In: J. M. Griffin, Ed., Global Climate Change: The Science, Economics, and Politics, Edward Elgar Publishing, Cheltenham, pp. 1-24.
- M. Dell, B. F. Jones and B. A. Olken, “Climate Change and Economic Growth: Evidence from the Last Half Century,” NBER Working Papers 14132, National Bureau of Economic Research, 2008.
- S. M. Hsiang, “Temperatures and Cyclones Strongly Associated with Economic Production in the Caribbean and Central America,” Proceedings of the National Academy of Sciences, Vol. 107, No. 35, 2010 pp. 15367-15372. doi/10.1073/pnas.1009510107
- B. F. Jones and B. A. Oklen, “Climate Shocks and Exports,” American Economic Review, Vol. 100, No. 2, 2010, pp. 454-459. doi:10.1257/aer.100.2.454
- M. Dell, B. F. Jones and B. A. Olken, “Temperature and Income: Reconciling New Cross-Sectional and Panel Estimates,” American Economic Review, Vol. 99, No. 2, 2010, pp. 198-204. doi:10.1257/aer.99.2.198
- T. H. Brikowski, Y. Lotan and M S. Pearle “ClimateRelated Increase in the Prevalence of Urolithiasis in the United States,” Proceedings of the National Academy of Sciences, Vol. 105, No. 28, 2007, pp. 9841-9846. doi_10.1073_pnas.0709652105
- F. Ackerman and E. Stanton, “Can Climate Change Save Lives? A Comment on “Economy-Wide Estimates of the Implications of Climate Change: Human Health,” Working Paper No. 06-05, Global Development and Environment Institute, 2006.
- U. Confalonieri, B. Menne, R. Akhtar, K. L. Ebi, M. Hauengue, R. S. Kovats, B. Revich and A. Woodward, “Human Health. Climate Change 2007: Impacts, Adaptation and Vulnerability,” In: M. L. Parry, O. F. Canziani, J. P. Palutikof, P. J. van der Linden and C. E. Hanson, Eds., Contribution of Working Group II to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change, Cambridge University Press, Cambridge, 2007, pp. 391-431.
- Parilimatray Office of Science and Technology, “UK Health Impacts of Climate Change,” No. 232, Parilimatray Office of Science and Technology, 2004.
- T. Kjellstrom, R. S. Kovats, S. J. Lloyd, T. Holt and R. S. Tol, “The Direct Impact of Climate Change on Regional Labor Productivity,” Archives of Environmental & Occupational Health, Vol. 64, No. 4, 2009, pp. 217-227. doi:10.1080/19338240903352776
- S. C. Sherwood and M. Huber, “An Adaptability Limit to Climate Change Due to Heat Stress,” Proceedings of the National Academy of Sciences, Vol. 107, No. 21, 2009, pp. 9552-9555. doi/10.1073/pnas.0913352107
- K. J. Harle, S. M. Howden, L. P. Hunt and M. Dunlop, “The Potential Impact of Climate Change on the Australian Wool Industry by 2030,” Agricultural Systems, Vol. 93, No. 1-3, 2006, pp. 61-89. doi:10.1016/j.agsy.2006.04.003
- R. M. Adams, B. H. Hurd, S. Lenhart and L. Neil, “Effects of Global Climate Change on Agriculture: An Interpretative Review,” Climate Research, Vol. 11, No. 1, 1998, pp. 19-30. doi:10.3354/cr011019
- O. Deschenes and M. Greenstone, “The Economic Impacts of Climate Change: Evidence from Agricultural Output Random Fluctuations in Weather,” American Economic Review, Vol. 97, N0. 1, 2007, pp. 354-385. doi:10.1257/aer.97.1.354
- W. R. Cline, “Global Warming and Agriculture: Impact Estimates by Country,” Center for Global Development and Peterson Institute for International Economics, Washington DC, 2007.
- H. R. Schultz and G. V. Jones, “Climate Induced Historic and Future Changes in Viticulture,” Journal of Wine Research, Vol. 21, No. 2, 2010, pp. 137-145. doi:10.1080/09571264.2010.530098
- O. Ashenfelter and K. Storchmann, “Using Hedonic Models of Solar Radiations and Weather to Assess the Economic Effect of Climate Change: The Case of Mosel Valley Vineyards,” Review of Economics and Statistics, Vol. 92, No. 2, 2010, pp. 333-349. doi:10.1162/rest.2010.11377
- J. Gawander, “The Impact of Climate Change on Sugar Cane Production in Fiji,” WMO Bulletin, Vol. 56, No. 1, 2007, pp. 34-39.
- B. Sohngen and R. Mendelshon, “Valuing the Impact of Large-Scale Ecological Change in a Market: The Effect of Climate Change on US Timber,” The American Economic Review, Vol. 88, No. 4, 1998, pp. 686-710.
- B. Sohngen, R. Mendelsohn and R. Sedjo, “A Global Model of Climate Change Impacts on Timber Markets,” Journal of Agricultural and Resource Economics, Vol. 26, No. 2, 2001, pp. 326-343.
- G. Buchanan, C. Tulloh and M. Ford, “The Potential Impacts of Climate Change on the Forest and Wood Products Manufacturing Sector in Australia,” Garnaut Climate Change Review, Australian Bureau of Agricultural and Resource Economics (ABARE), Canberra, 2007.
- A. P. Kirilenko and R. A. Sedjo, “Climate Change Impacts on Forestry,” Proceedings of the National Academy of Sciences, Vol. 104, No. 50, 2007, pp. 19697-19702. doi_10.1073_pnas.0701424104
- K. M. Brander, “Global Fish Production and Climate Change,” Proceedings of the National Academy of Sciences, Vol. 104, No. 50, 2007, pp. 19709-19714. doi_10.1073_pnas.0702059104
- T. Pearce, J. Ford, et al., “Climate Change and Mining in Canada,” Climate Change and Mining in Canada, Vol. 16, No. 3, 2011, pp. 347-368. doi:10.1007/s11027-010-9269-3
- Deloitte and Touche, “Smart Risk Managers Think Broadly about Climate Change,” 2008. http://www.deloitte.com/dtt/artciles/
- C. Furgal and T. Prowse, “Northern Canada,” In: D. Lemmen, F. Warrent, E. Bush and J. Lacroixj, Eds., From Impacts to Adaptations: Canada in Changing Climate 2007, Government of Canada, Ottawa, 2008.
- J. D. Ford, T. Pearce, J. Prno, F. Duerden, L. B. Ford, B. Maude and T. Smith, “Perceptions of Climate Change Risks in Primary Resource Use Industries: A Survey of the Canadian Mining Sector,” Regional Environmental Change, Vol. 10, No. 1, 2010, pp. 65-81. doi:10.1007/s10113-009-0094-8
- J. D. Ford, T. Pearce, J. Prno, F. Duerden, L. B. Ford, T. Smith and B. Maude, “Canary in Coal Mine: Perceptions of Climate Risks and Response Option among Canadian Mine Operations,” Climatic Change, Vol. 109, No. 3-4, 2011, pp. 399-415. doi:10.1007/s10584-011-0029-5
NOTES
1See the same paper for detailed estimation of change in labor productivity across regions under A2 scenario for the periods 2020s, 2050s, and 2080s in which trends towards less labor-intense work and no specific adaptation of workplace conditions to climate change are assumed.
2SD measures exposure of countries for (normalized) dissipated wind energy per unit area.