Open Journal of Optimization
Vol.2 No.3(2013), Article ID:36838,11 pages DOI:10.4236/ojop.2013.23009
Two Agent Paths Planning Collaboration Based on the State Feedback Stackelberg Dynamic Game
Hydrogen Research Institute, Department of Mechanical Engineering, Université du Québec à Trois-Rivières, Trois-Rivières, Canada
Email: Sousso.kelouwani@uqtr.caca
Copyright © 2013 Sousso Kelouwani. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Received May 31, 2013; revised June 31, 2013; accepted July 12, 2013
Keywords: Robotic Architecture; Share Control; Stackelberg Game; Cooperative Control; Collaborative Control
ABSTRACT
Autonomous Navigation Modules are capable of driving a robotic platform without human direct participation. It is usual to have more than one Autonomous Navigation Modules in the same work space. When an emergency situation occurs, these modules should achieve a desired formation in order to efficiently escape and avoid motion deadlock. We address the collaboration problem between two agents such as Autonomous Navigation Modules. A new approach for team collaborative control based on the incentive Stackelberg game theory is presented. The procedure to find incentive matrices is provided for the case of geometric trajectory planning and following. A collaborative robotic architecture based on this approach is proposed. Simulation results performed with two virtual robotic platforms show the efficiency of this approach.
1. Introduction
When multiple autonomous robotic platforms are involved in common task, the team coordination is usually an important control aspect. Robots in the team make their own decisions, which may be in conflict with other teammate’s decisions [1,2]. In particular, the coordination problem must be efficiently handled when two Autonomous Navigation Platforms, which are sharing the same configuration space, need to achieve a team formation in order to avoid a motion dreadlocks during a task execution such as moving through a single way point, cleaning floor, transporting load or tracking a common target [3]. Two Autonomous Navigation Platforms that should pass trough an emergency door in order to escape from a dangerous situation is such an example.
The motion deadlock avoidance problem has been studied for robot soccer game. The fuzzy logic approach was used to derive each robotic platform teammate action [4]. The use of fuzzy logic was motivated by the fact this problem could be easy solve in a similar manner as human beings [5]. Since this approach relies mainly on the accurate representation of a human being decisionmaking in similar situation, any misrepresentation may lead to a poor control decision for each teammate. Although this approach was tested in simulation, no experimentation was performed on real robotic platforms. Harunori [6] proposed a deadlock-free navigation scheme based on a centralized coordination approach for a team of robots. In order to assign a move task to one robot, the proposed scheme required a global path planning to be constructed in the configuration space for each robot. This operation is time consuming. Since this approach is centered on a single main component, the individual teammate decision is inhibited.
Among well known framework for studying robotic platform team collaboration is the game theory. When no natural decision making hierarchy can be established among teammates, Nash’s equilibrium approach is often used [7]. On the other hand, when this hierarchy exists, the Stackelberg theory is a good candidate in order to study the decision problem. Hence, robot team obstacle avoidance methods based upon these theories were recently proposed in [8,9]. In [8], the team coordination used a semi-cooperative Stackelberg equilibrium point [10]. However, the implicit assumption of no static feedback is done, and the equilibrium point is found only for one stage. In real life, this assumption is weak since each team has access to state feedback for other teammates.
This paper studies two autonomous agents collaboration using the game theory framework approach. The agents are heterogeneous Autonomous Navigation Modules that are sharing a common workspace [11]. From their initial configuration, they can move to a common place: this is a rendez-vous. The configuration of the team is therefore obtained by taking into account everyone position and orientation. From this point, we consider that one agent is acting as the leader (the other teammates are acting as followers) and the team must move according to the leader motion planning even if each follower can have its own planned trajectory. The rendez-vous problem is not considered for this paper. Instead, we focus on the team trajectory planning problem.
As stated before, the game theory offers a clear formulation for finding equilibrium point in situation where many decision makers (agents) are involved [12]. In this study, only two Autonomous Navigation platforms are involved, and it is assumed that a natural hierarchy exists between them [13]. By hierarchy, we mean that one platform (the leader) makes its decision and then advertises this decision to the other platform (the follower) [14-16]. One platform is clearly designed to act as the leader when a motion deadlock is detected [17,18]. In realistic navigation environment, both platform states need to be taken into account in a close loop manner [19,20]. Hence, state feedback controllers are required. The state feedback Stackelberg game theory is selected as the framework in order to solve collaborative decision problems [21,22].
This paper provides two contributions. We proposed a method for finding the solution of an important class of discrete-time two-agent non zero-sum dynamic games with linear state dynamic and quadratic cost functional. Our solution is an extension of the solution proposed by [10]. The main difference is that Ming [10] approach is related to the class of regulator controllers whereas the method presented here is related to the class of reference trajectory tracking. The second contribution of this works is related to the design of a robotic architecture based on the proposed method for deadlock avoidance when two robotic platforms are sharing the same workspace. This collaborative robotic architecture is based on the threelayer architecture concept [23]: the deliberative, the sequencer and the execution layer.
The rest of the paper is organized as follows. The path planning problem in linear space and the methodology based on Stackelberg game theory are presented in Section 2. In Section 3, reactive robotic architecture is presented. The simulation results and the conclusion are presented in Section 4 and Section 5, respectively.
2. Path Planning in Linear Space
2.1. Problem Formulation
Consider a system with the configurations of two Autonomous Navigation Modules (ANM). Given the following state equation:
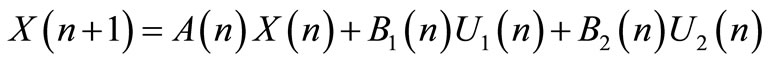 (1)
(1)
where:
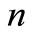 is the current stage;
is the current stage; 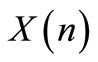 is a
is a 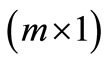 state vector of the system, at stage
state vector of the system, at stage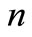 ;
; 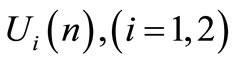 are
are  control signals or strategies generated respectively by agent 1 (ANM 1) and agent 2 (ANM 2), at stage
control signals or strategies generated respectively by agent 1 (ANM 1) and agent 2 (ANM 2), at stage ; it is assumed that both control signals have the same dimensions;
; it is assumed that both control signals have the same dimensions; 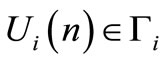 where
where  is the admissible set of strategies for agent
is the admissible set of strategies for agent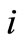 ;
; 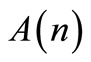 is a
is a 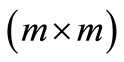 transition matrix of the system, at stage
transition matrix of the system, at stage ;
;  are
are  control matrices respectively for agent 1 and agent 2.
control matrices respectively for agent 1 and agent 2.
Given the following functional:
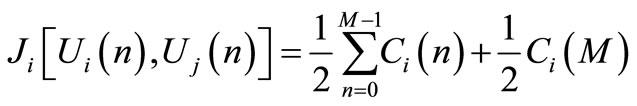 (2)
(2)
 (3)
(3)
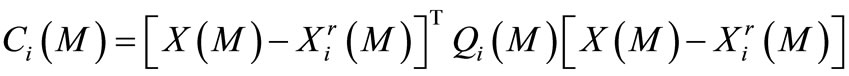 (4)
(4)
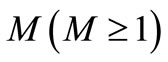 is the finit optimization horizon; Subscripts
is the finit optimization horizon; Subscripts  and
and 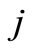 with
with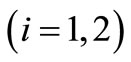 ,
, 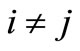 represent different agents;
represent different agents;  is a
is a  vector of the reference trajectory that is followed by agent
vector of the reference trajectory that is followed by agent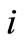 at stage
at stage ;
;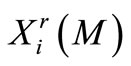 is a
is a 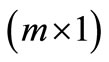 vector of the reference trajectory that is followed by agent
vector of the reference trajectory that is followed by agent 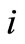 at the end of optimization horizon;
at the end of optimization horizon; 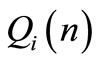 is a
is a 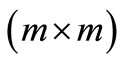 symmetric and positive semi-definite matrix that penalises the state vector and the reference vector deviation at stage
symmetric and positive semi-definite matrix that penalises the state vector and the reference vector deviation at stage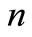 ;
;  is a
is a 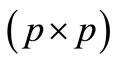 symmetric and positive definite matrix that penalises agent i control signal at stage
symmetric and positive definite matrix that penalises agent i control signal at stage  within its functional;
within its functional; 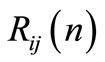 with
with  is a
is a 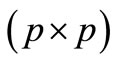 symmetric and positive definite matrix that penalises agent j control signal at stage
symmetric and positive definite matrix that penalises agent j control signal at stage 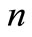 within the functional of agent i.
within the functional of agent i.
We consider only the case where the state vector is fully accessible by all agents and the initial state vector  is completely known. Furthermore, we assume that agent 1 is the leader and agent 2 is the follower.
is completely known. Furthermore, we assume that agent 1 is the leader and agent 2 is the follower.
At stage , each agent selects its strategy
, each agent selects its strategy  such that the functional
such that the functional 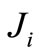 is minimized. In a state feedback Stackelberg game formulation, the leader wishes to influence the follower so that the selected strategies minimize its functional. Strategies of the leader
is minimized. In a state feedback Stackelberg game formulation, the leader wishes to influence the follower so that the selected strategies minimize its functional. Strategies of the leader 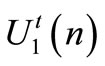 and the follower
and the follower 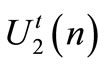 that minimize the leader functional
that minimize the leader functional  are considered by definition as the team optimal strategies. The state vector obtained by applying these strategies is represented by
are considered by definition as the team optimal strategies. The state vector obtained by applying these strategies is represented by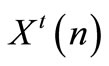 . To influence the follower strategy selection, we assume that the leader is using a linear incentive function represented by the following equation [10]:
. To influence the follower strategy selection, we assume that the leader is using a linear incentive function represented by the following equation [10]:
 (5)
(5)
The problem is to find at each stage  the two matrix gains
the two matrix gains 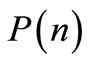 and
and  such that the state feedback control achieves a Stackelberg solution. In next sections of the paper, the terms control signal and strategy are considered equivalent.
such that the state feedback control achieves a Stackelberg solution. In next sections of the paper, the terms control signal and strategy are considered equivalent.
2.2. Methodology
General Stackelberg Solution
In general, for two agents involved in a dynamic Stackelberg game, a solution concept is a pair of strategies from both agents that minimizes both functionals at each stage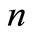 . This notion of equilibrium is extended to allow the definition of the feedback Stackelberg solution [18]. Hence, according to Jose [18], for each leader strategy
. This notion of equilibrium is extended to allow the definition of the feedback Stackelberg solution [18]. Hence, according to Jose [18], for each leader strategy , the follower selects a strategy
, the follower selects a strategy  where
where 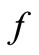 is a mapping from
is a mapping from 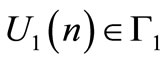 to
to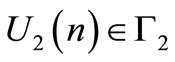 . The selection of
. The selection of 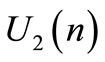 is done as followed:
is done as followed: ,
,
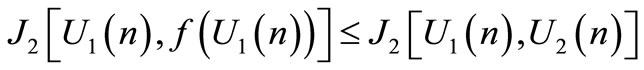 (6)
(6)
The strategy of the leader is chosen so that 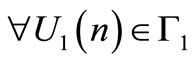 ,
,
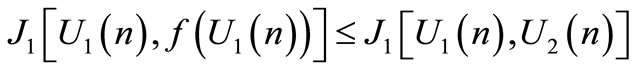 (7)
(7)
The pair of strategies from Equations (6) and (7) is the Stalkelberg solution with agent 1 as the leader. We consider that the mapping 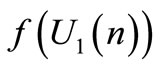 is a linear function represented by Equation (5). In order to completely define this function, matrix gains
is a linear function represented by Equation (5). In order to completely define this function, matrix gains 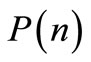 and
and  should be determined based on the optimal control theory.
should be determined based on the optimal control theory.
2.3. Team Optimal Solution
Since the goal of the leader is to induce the follower to choose a strategy that minimizes its functional, we need to determine these two strategies called team optimal strategy. The team optimal strategies 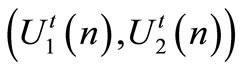 is defined as:
is defined as:
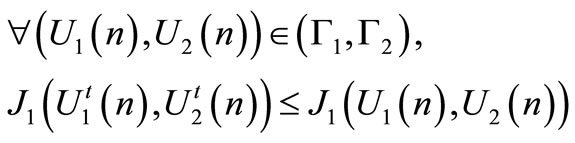 (8)
(8)
2.4. Incentive Matrix Gains
Assuming that the leader knows the follower functional. In order to incite the follower to adopt , the leader uses the strategy represented by Equation (5). The follower, in order to minimize its own functional and find its strategy, takes into account the previously mentioned leader strategy. This is a usual optimization problem from the follower side. Since the two matrix
, the leader uses the strategy represented by Equation (5). The follower, in order to minimize its own functional and find its strategy, takes into account the previously mentioned leader strategy. This is a usual optimization problem from the follower side. Since the two matrix 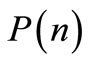 and
and 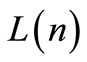 are parts of the optimal strategy of the follower, the leader needs to provide them. This is not a simple optimization problem because the leader should take into account the expected rational strategy of the follower.
are parts of the optimal strategy of the follower, the leader needs to provide them. This is not a simple optimization problem because the leader should take into account the expected rational strategy of the follower.
2.5. Solving Optimal Tracking Problem
Team Optimal Solution
It is assumed that both agents minimize the leader functional  represented by Equation (2). To find the pair of strategies
represented by Equation (2). To find the pair of strategies  that minimized
that minimized , the optimal control theory is applied.
, the optimal control theory is applied.
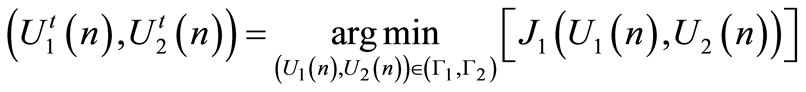 (9)
(9)
where 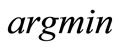 stands for the arguments that allow the functional to attain its minimum value. The team Hamiltonian of the system is given by:
stands for the arguments that allow the functional to attain its minimum value. The team Hamiltonian of the system is given by:
 (10)
(10)
where:
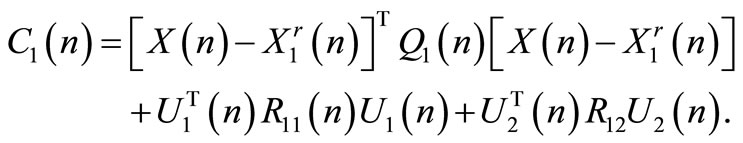 (11)
(11)
Using the minimum principle, we obtain the following expressions:
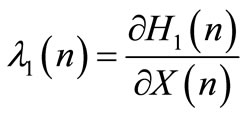 (12)
(12)
and
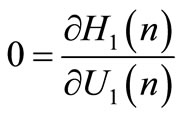 (13)
(13)
and
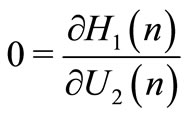 (14)
(14)
Equation (12) becomes:
 (15)
(15)
with the boundary condition:
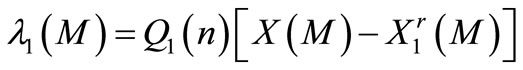 (16)
(16)
From Equations (13) and (14) the following expressions are obtained:
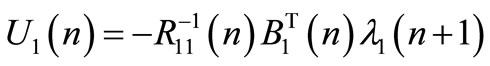 (17)
(17)
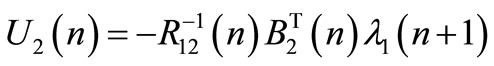 (18)
(18)
The state Equation (1) becomes:
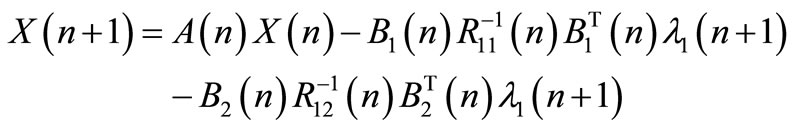 (19)
(19)
From the boundary condition (16), it seems reasonable to assume that for all :
:
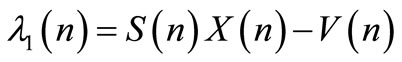 (20)
(20)
where 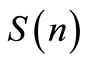 is a
is a 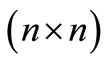 matrix and
matrix and is a
is a 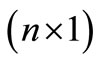 vector. By substituting
vector. By substituting 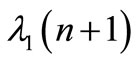 in Equation (19) with it expression (Equation (20)), the following equation is obtained:
in Equation (19) with it expression (Equation (20)), the following equation is obtained:
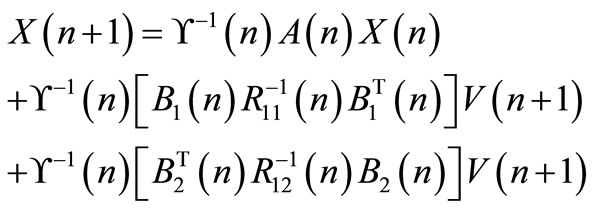 (21)
(21)
where:
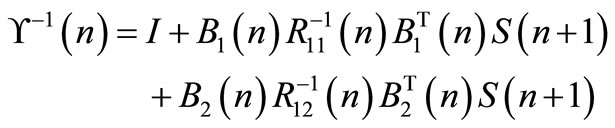 (22)
(22)
and 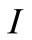 is an identity matrix with proper dimensions. From Equation (15), the following expression is obtained by substituting
is an identity matrix with proper dimensions. From Equation (15), the following expression is obtained by substituting 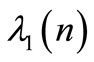 and
and 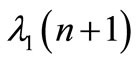 with their expressions:
with their expressions:
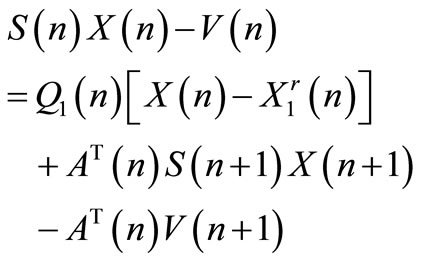 (23)
(23)
 from Equation (23) is replaced by its expression and the following expression is obtained:
from Equation (23) is replaced by its expression and the following expression is obtained:
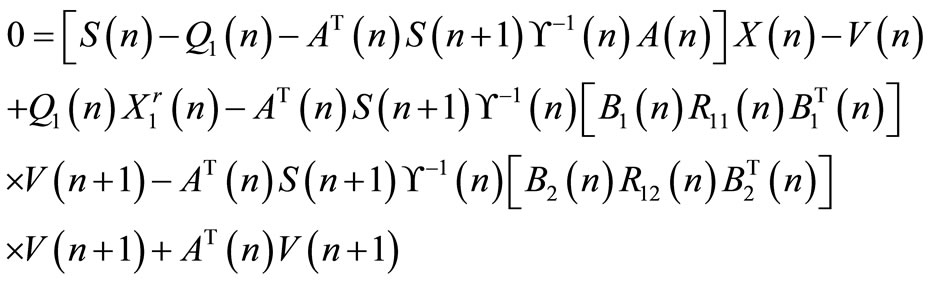 (24)
(24)
Since Equation (24) must hold for all X(n) given any X(0), we must have:
 (25)
(25)
and
 (26)
(26)
Rewriting Equations (25) and (26), the following expressions are obtained:
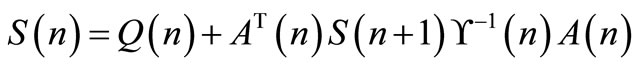 (27)
(27)
and
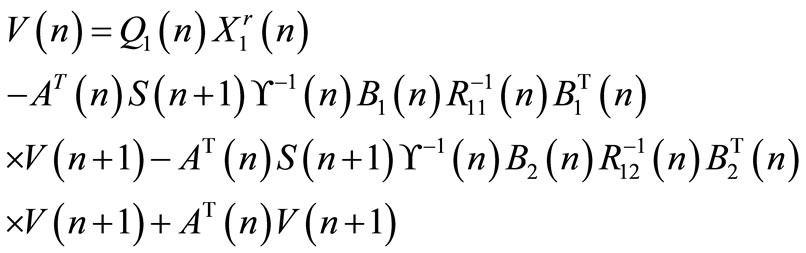 (28)
(28)
with the following boundary conditions:
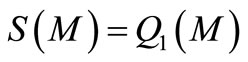 (29)
(29)
 (30)
(30)
Given the expressions of  and
and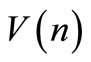 , the equation of
, the equation of  is completely determined. Hence, the team optimal strategies
is completely determined. Hence, the team optimal strategies 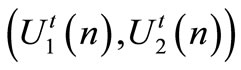 is represented by:
is represented by:
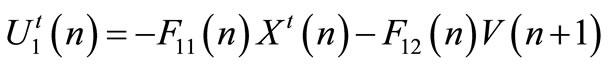 (31)
(31)
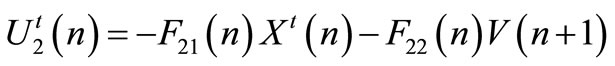 (32)
(32)
where:
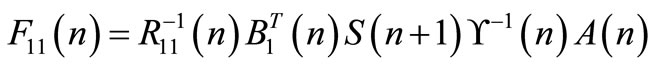 (33)
(33)
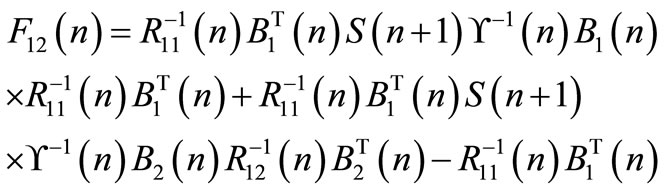 (34)
(34)
 (35)
(35)
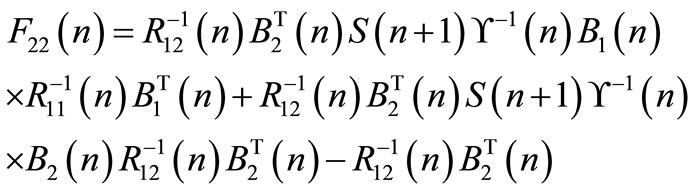 (36)
(36)
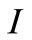 is an identity matrix with proper dimensions.
is an identity matrix with proper dimensions.
Incentive Matrix Gains To incite the follower to adopt , the leader advertises its strategy
, the leader advertises its strategy  represented by Equation (5). We assume that the leader has a full knowledge of the follower reference path. Hence, given:
represented by Equation (5). We assume that the leader has a full knowledge of the follower reference path. Hence, given:
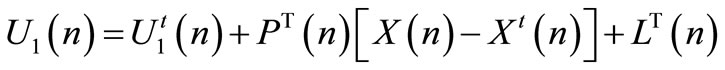 (37)
(37)
The follower reaction is found by solving its Hamiltonian:
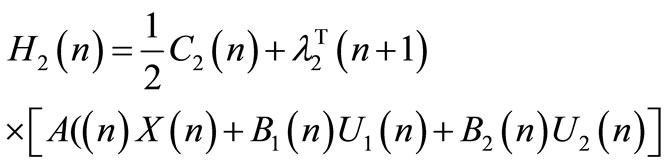 (38)
(38)
where:
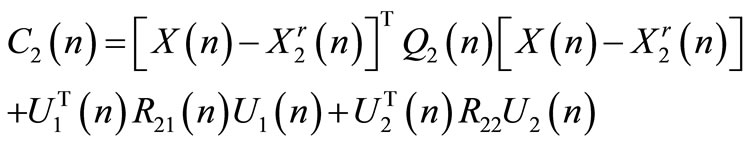 (39)
(39)
Using the minimum principle, we obtain the following expressions:
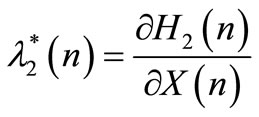 (40)
(40)
and
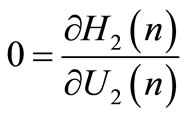 (41)
(41)
Equation (40) becomes:
 (42)
(42)
with the boundary condition:
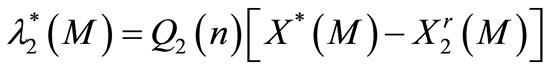 (43)
(43)
where  is the state sequence when
is the state sequence when  and
and 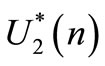 are applied to the system [10]. The expression of
are applied to the system [10]. The expression of  is given below. From Equations (41) the following expression is obtained:
is given below. From Equations (41) the following expression is obtained:
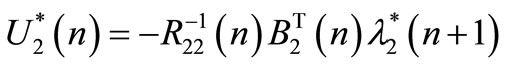 (44)
(44)
Assume that
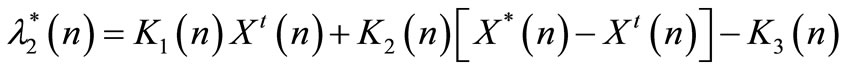 (45)
(45)
where: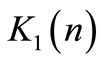 ,
, 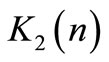 and
and  are matrices with proper dimensions;
are matrices with proper dimensions;
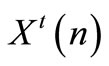 is the sequence of state vector when
is the sequence of state vector when 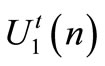 and
and 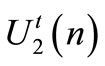 are applied on the system. We know that:
are applied on the system. We know that:
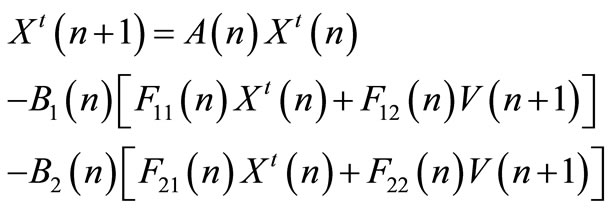 (46)
(46)
Equation (44) can be rewritten as followed, given the expression of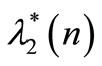 :
:
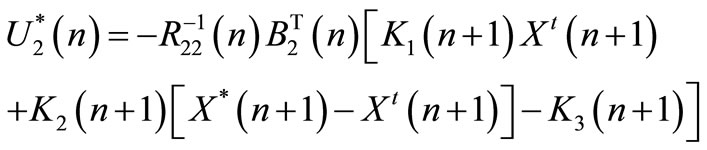 (47)
(47)
Substituting 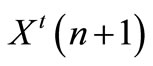 by its expression (46), the following equation is obtained:
by its expression (46), the following equation is obtained:
 (48)
(48)
If the follower acts exactly as the leader expected, 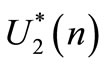 is equal to
is equal to 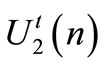 and
and  is equal to
is equal to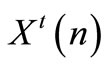 .
.
Hence, expression (46) becomes:
 (49)
(49)
If the previous equation is true for any initial state , we must have the following conditions:
, we must have the following conditions:
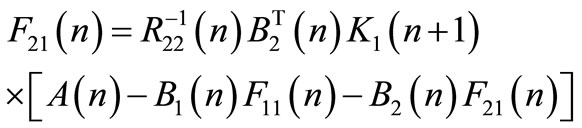 (50)
(50)
and
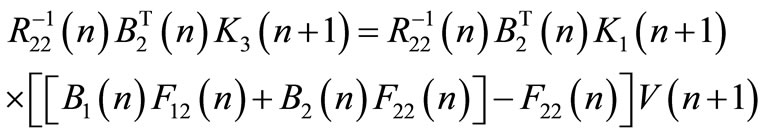 (51)
(51)
If both conditions hold, then the follower strategy 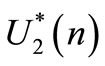 is equivalent to:
is equivalent to:
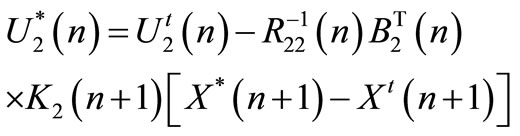 (52)
(52)
To be able to compute the follower strategy, 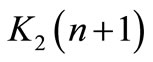 need to be evaluated. Consider the state equation when
need to be evaluated. Consider the state equation when  and
and 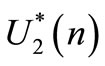 are applied:
are applied:
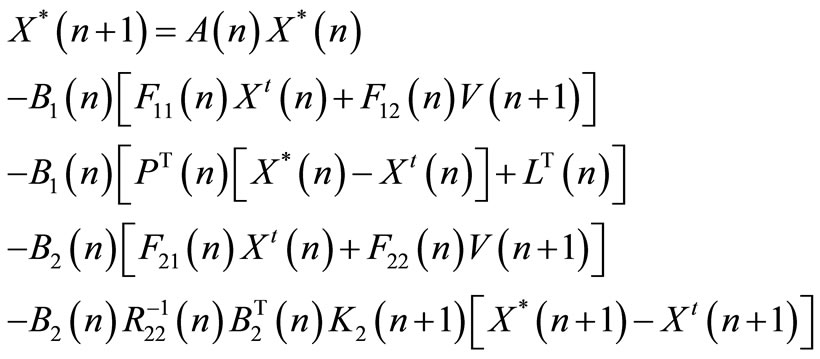 (53)
(53)
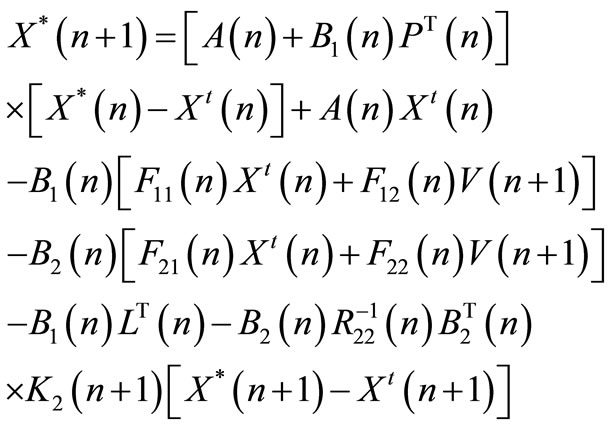 (54)
(54)
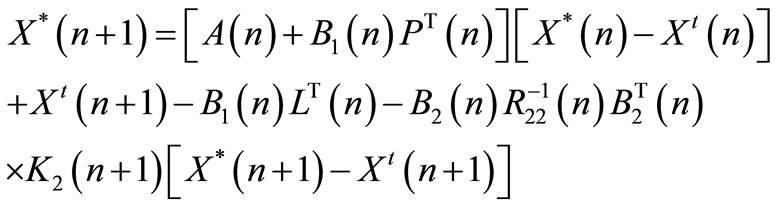 (55)
(55)
 (56)
(56)
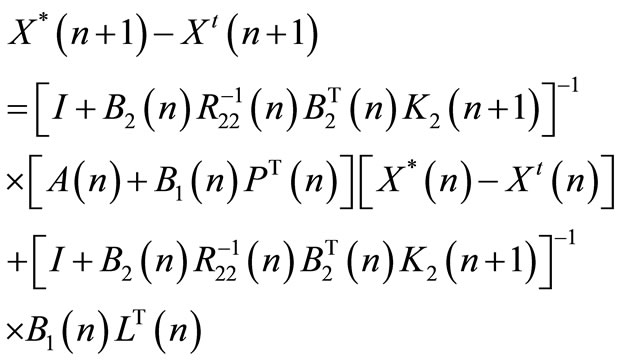 (57)
(57)
From Equation (45), the following expression is deduced:
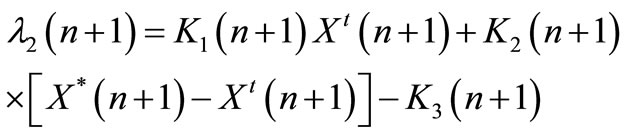 (58)
(58)
Substituting Equation (57) in Equation (58) yields:
 (59)
(59)
Substituting Equations (45), (46) and (57) in (42), we obtain the following equation:
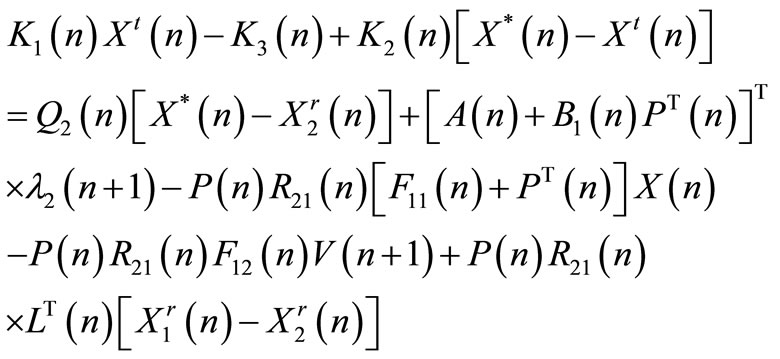 (60)
(60)
Substituting 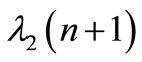 in Equation (60) by its expression (59) yields:
in Equation (60) by its expression (59) yields:
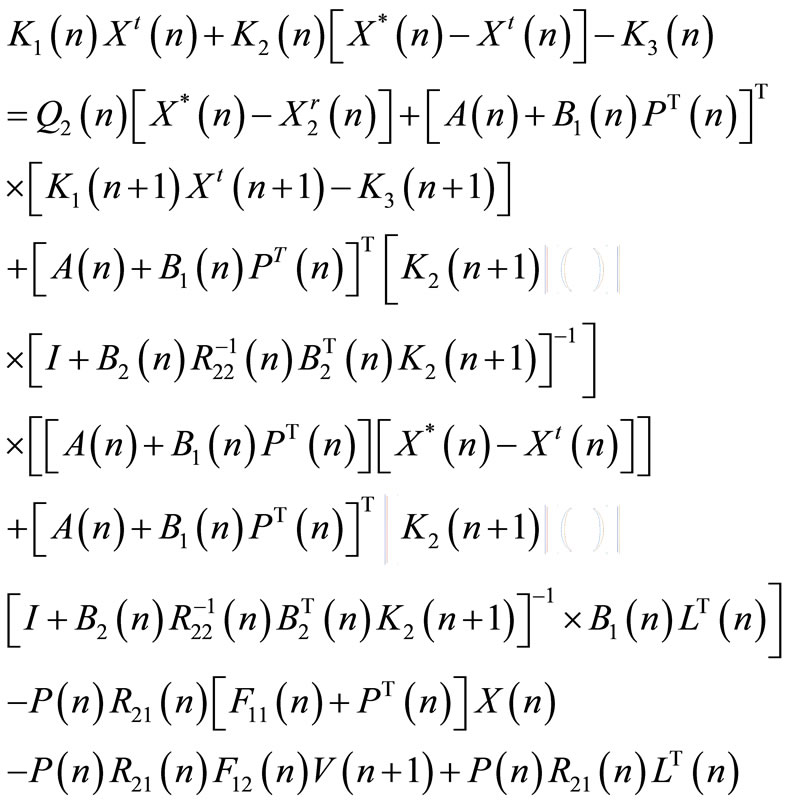 (61)
(61)
This equation is true for any 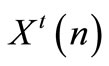 and
and 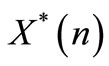 if the following conditions hold:
if the following conditions hold:
1- for all 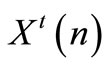
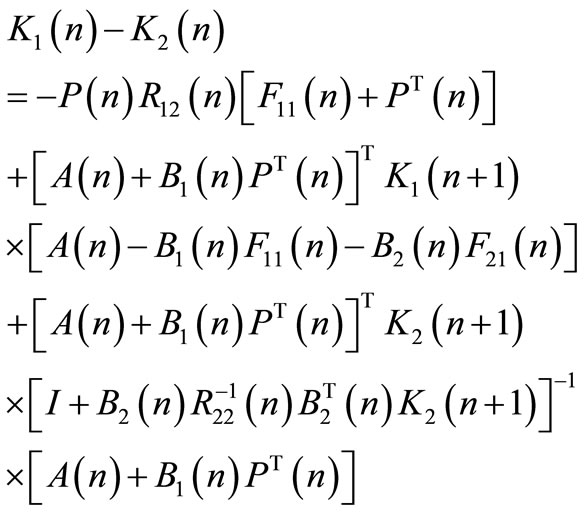 (62)
(62)
2- for all 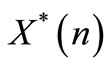
 (63)
(63)
3- for all constant values
 (64)
(64)
Substituting expression of 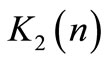 in Equation (62) yield:
in Equation (62) yield:
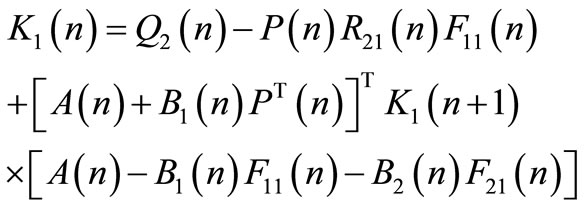 (65)
(65)
Algorithm
The algorithm to solve the feedback Stackelberg game for trajectory following is summarized as followed:
backwardd processing:
1. Find all sequences of 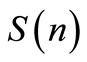 by using Equation (26);
by using Equation (26);
2. Find all sequences of 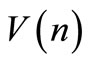 by using Equation (27); forward processing: At each step
by using Equation (27); forward processing: At each step ,
,
1. find 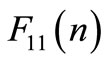 by using Equation (33);
by using Equation (33);
2. find 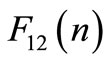 by using Equation (34);
by using Equation (34);
3. find 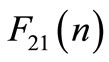 by using Equation (35);
by using Equation (35);
4. find  by using Equation (36);
by using Equation (36);
5. find 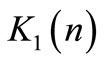 from Equation (50);
from Equation (50);
6. find 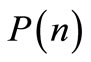 from Equation (65);
from Equation (65);
7. find  from Equation (63);
from Equation (63);
8. find 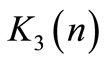 from Equation (51);
from Equation (51);
9. find 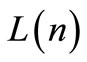 from Equation (64);
from Equation (64);
3. Reactive Robotic Architecture
Generic Architecture
The generic reactive architecture depicted on Figure 1, has three layers: the decision layer, the planning layer and the execution layer. Since the collaboration between agents is heavily goal oriented, it requires that a common goal is defined for the team. For collaborative navigation application, the common goal could be to reach a particular configuration given the current configuration. The configuration refers to the platform position and orientation measured in a reference frame. Given the common goal, a reference trajectory is generated for each agent since each of them may have its own way to drive the platform to the goal configuration. The reference trajectory for the follower could be generated according to the surrounding map with only known obstacles. Therefore, this follower doesn’t require any additional sensor to detect obstacles. The reference trajectory for the leader could be generated by taking into account unknown obstacles (obstacles that were not modeled on the follower map). The common goal specification could be part of the leader functionality. In Figure 1, after common goal specification, reference trajectories (for a specific number of stages) for the leader and the follower
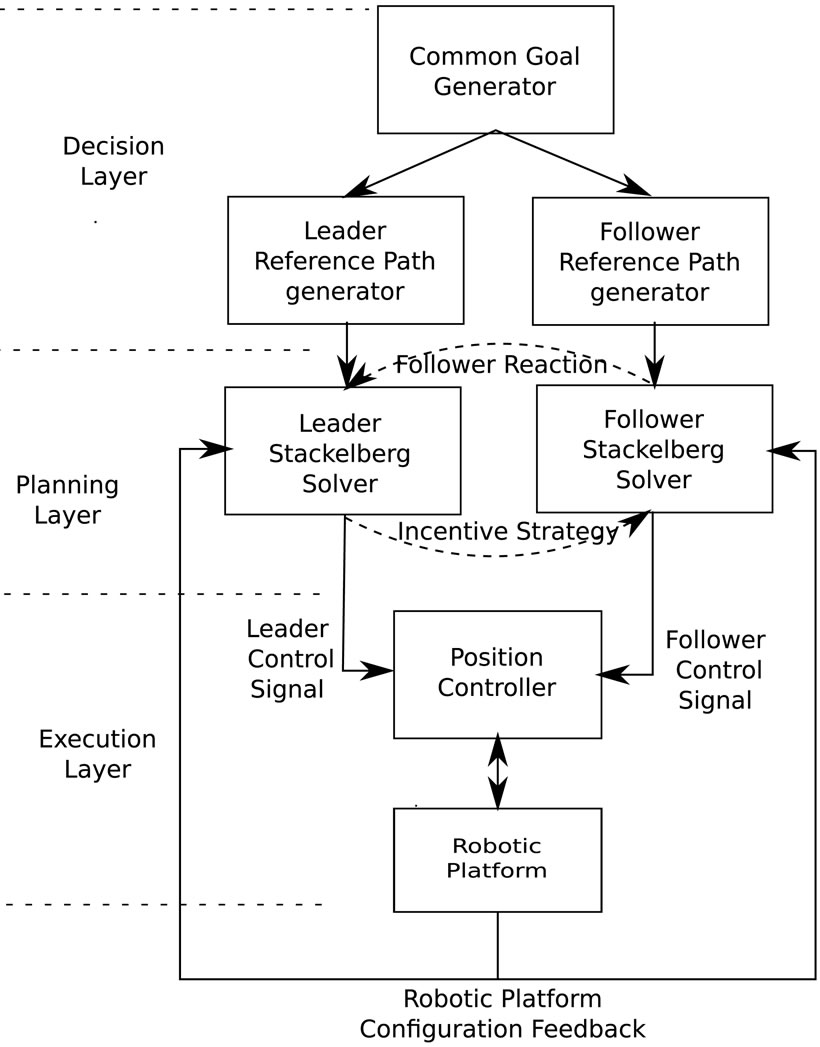
Figure 1. Stackelberg-based collaborative architecture.
are generated respectively by the leader reference path generator and the follower reference path generator.
Given the reference paths, the Stackelberg formulation can take place by considering that the leader reference path is the team reference trajectory. For the collaborative navigation application, the leader reference trajectory is the same as the follower trajectory unless an unknown obstacle is detected. As shown in Figure 1, the leader of Stakelberg model produces a control signal (if the number of stages is 1) or a sequence of control signal (for the general case) by taking into account the rationale reaction of the follower. The generated signal, based on incentive strategy, is then used by the follower when making its own planning.
For each planned stage, the two signals generated by both agents are directly given to the position controller. This module is responsible for applying required low level control signal to the platform effectors so that its configuration tends to be as close as possible to the given configuration. The position controller causes the platform to change its configuration during a stage. The obtained platform configuration is used as feedback for the two Stackelberg solver in order to generate next stage control signals.
The described architecture fulfills the minimum requirements stated by Hoc [3]. Indeed, the entire architecture is mainly goal oriented. The two agents work towards goals. Furthermore, the leader can interfere with the follower behaviour with the proposed incentive approach. The follower, by reacting rationally, allows easy and predictive interaction with the leader.
4. Application to Collaborative Robot Navigation
4.1. Simulation Scenario
To validate all required steps for collaborative control based upon the feedback Stackelberg theory, a simulation has been performed. The focus is put on the planning layer of the generic architecture presented in Figure 1, since this is the heart of this work.
Assume that the two agents are at point A. Their platforms are considered as a single team platform. The goal of the simulated collaborative navigation is to drive the team platform and to reach the point B, starting at point A, as shown in Figure 2. This can be interpreted as the common goal for the leader and the follower. Furthermore, the line shown in this figure represents the leader reference path. Hence, this reference path is considered the team reference path. The follower and leader reference paths are represented in Figure 3. By applying the procedure mentioned in the proposed methodology, we obtained the collaborative control that allows the team to follow the leader reference path at any
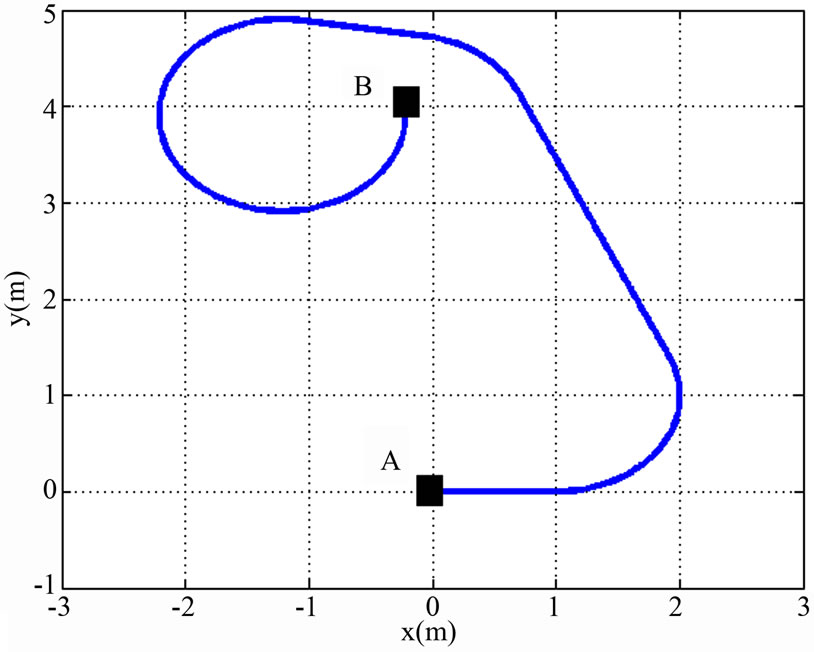
Figure 2. Team trajectory.
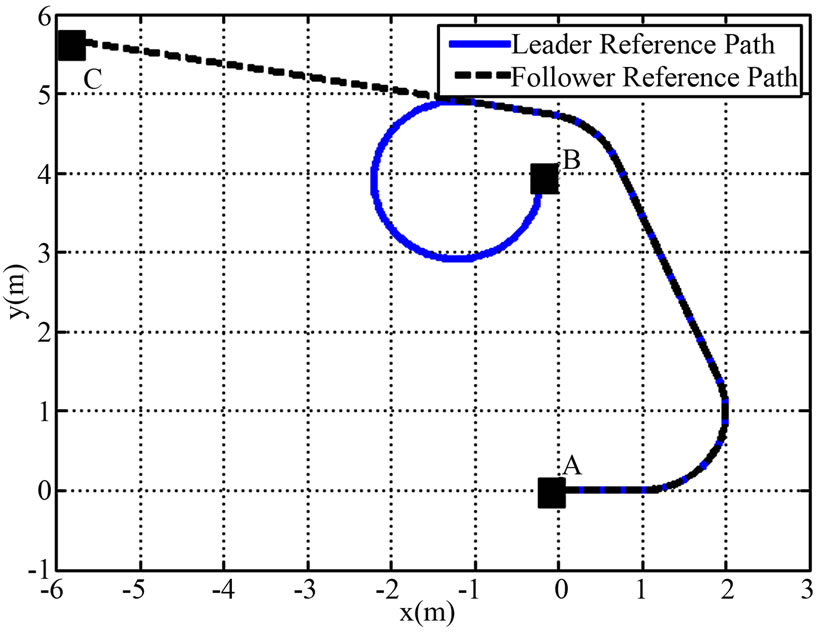
Figure 3. Leader and follower reference paths.
stage. The team platform state is designated by 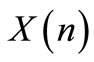 and the simulation parameters are described bellow.
and the simulation parameters are described bellow.
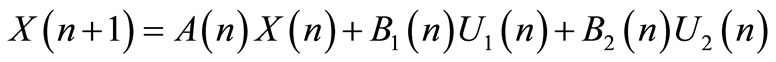 (66)
(66)
where:
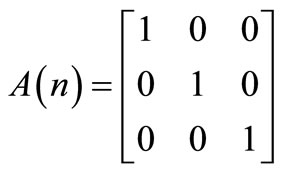 (67)
(67)
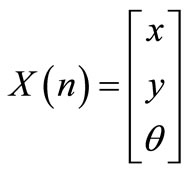 (68)
(68)
 (69)
(69)
 (70)
(70)
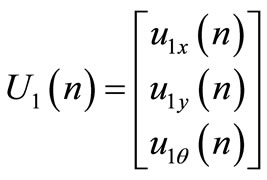 (71)
(71)
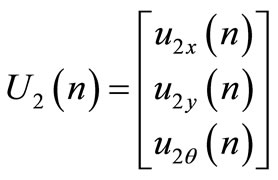 (72)
(72)
where:
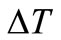 represents the system integration time step;
represents the system integration time step;
 represents the leader control signal along xaxis;
represents the leader control signal along xaxis;
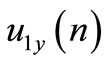 represents the leader control signal along yaxis;
represents the leader control signal along yaxis;
 represents leader control signal related to orientation;
represents leader control signal related to orientation;
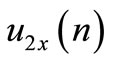 represents the follower control signal along xaxis;
represents the follower control signal along xaxis;
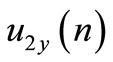 represents the follower control signal along yaxis;
represents the follower control signal along yaxis;
 represents follower control signal related to the orientation.
represents follower control signal related to the orientation.
The leader and follower functionals are represented by Equation (2). We assume that control signals are not bounded. Involved functional matrices are defined to be well dimensioned unit matrices 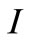 except
except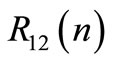 ,
, 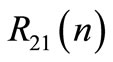 ,
,  and
and 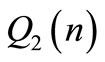 which are set to
which are set to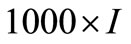 . The optimization horizon
. The optimization horizon 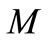 is set to the whole simulation number of stages
is set to the whole simulation number of stages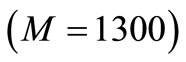 .
.
4.2. Simulation Results
In Figure 4, we observe a match between the leader reference path and the path followed by the system composed with the two ANM, although the leader and the follower have different reference paths. This result suggests that the proposed Stackelberg optimal solution is valid. In order to analyze deeply the different interactions between agent control signals, these signals are shown in the subsequent figures.
Figure 3 shows two different phases. In the first phase, both reference paths are identical, whereas in the second phase, they are different. The breaking point happened at stage .
.
Figures 5-7 show agent control signals during the first phase. Since the reference paths are identical, the leader contribution along each axis is small meaning that the incentive part in the leader control signal is also small. This result makes sense since the follower is acting as wished by the leader.
The second phase starts from stage 701. During this phase, the leader needs to make use of the incentive strategy in order to induce the follower to track the leader reference path instead of its own reference path, as shown on Figures 8-10.
5. Conclusion
A new collaborative architecture is presented in this pa-

Figure 4. Comparison between leader reference path and the team trajectory.

Figure 5. Control signal along x-axis for identical reference paths.

Figure 6. Control signal along y-axis for identical reference paths.

Figure 7. Orientation control signal for identical reference paths.

Figure 8. Control signal along x-axis for non-identical reference path.

Figure 9. Control signal along y-axis for non-identical reference path.
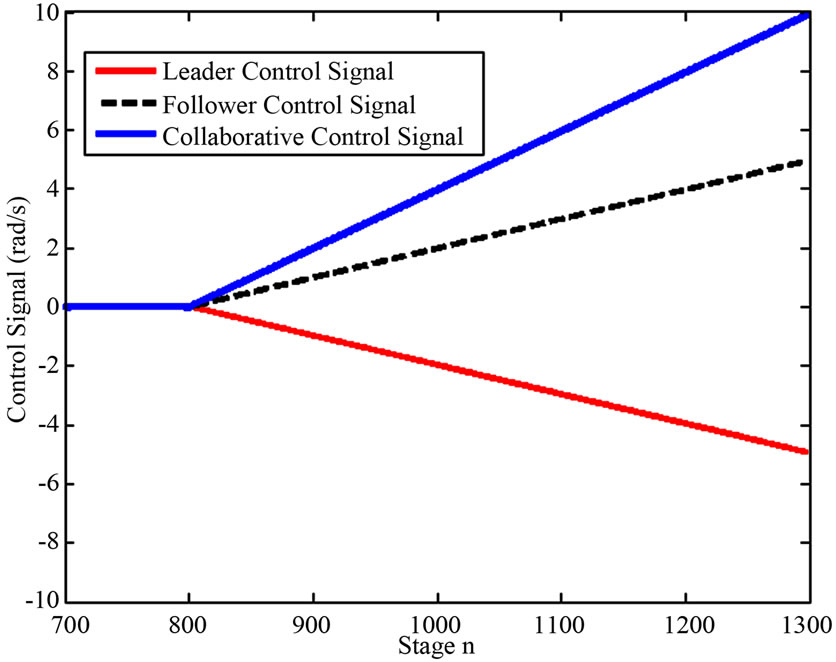
Figure 10. Orientation control signal for non-identical reference path.
per. This architecture is based upon the incentive Stackelberg game formulation and the three-layer architecture. The proposed method is suitable to applications in which there is a hierarchy between decision makers. All required conditions, and equations have been provided in order to find incentives matrices and an algorithm for solving the Stackelberg problem for a class of discretetime two-agent non zero-sum dynamic games with linear state dynamic and quadratic cost functional is also provided. The feasibility and validity of this architecture are provided through the study of collaborative path planning of two robotic platforms. In a completely deterministic framework, the results suggest that the optimal solution for this game can be obtained. The proposed method as well as the collaborative architecture could be used for smart wheelchair team and unmanned vehicle team collaborative control.
6. Acknowledgements
The author wishes to thank Prof. Paul Cohen of École Polytechnique Montréal, Québec, Canada.
REFERENCES
- M. Pantic, A. Pentland, A. Nijholt and T. S. Huang, “Human Computing and Machine Understanding of Human Behavior: A Survey,” Lecture Notes in Computer Science, 4451 NAI, Hyderabad, 2007, pp. 47-71.
- M. Chatterjee, “Design Research: Building Human-Centered System,” IEEE International Professional Communication Conference (IPCC 2007), Seattle, 1-3 October 2007, pp. 453-458.
- J.-M. Hoc, “Towards a Cognitive Approach to HumanMachine Cooperation in Dynamic Situations,” International Journal of Human Computer Studies, Vol. 54, 2001, pp. 509-540.
- H. Liu, F. Lin and H. B. Zha, “Fuzzy Decision Method for Motion Deadlock Resolving in Robot Soccer Games,” Advanced Intelligent Computing Theories and Applications. With Aspects of Theoretical and Methodological Issues, Vol. 4681, Springer, Berlin/Heidelberg, 2007, pp. 1337-1346.
- H. L. Sng, G. Sen Gupta and C. H. Messom, “Strategy for Collaboration in Robot Soccer,” The First IEEE International Workshop on Electronic Design, Test and Applications, Christchurch, 29-31 January 2002, pp. 347-351.
- H. Gakuhari, S. M. Jia, K. Takase and Y. Hada, “RealTime Deadlock-Free Navigation for Multiple Mobile Robots,” International Conference on Mechatronics and Automation (ICMA 2007), Harbin, 5-8 August 2007, pp. 2773-2778.
- G. P. Papavassilopoulos, “Solution of Some Stochastic Quadratic Nash and Leader-Follower,” SIAM Journal on Control and Optimization, Vol. 19, No. 5, 1981, pp. 651- 666.
- I. Harmati and K. Skrzypczyk, “Robot Team Coordination for Target Tracking Using Fuzzy Logic Controller in Game Theoretic Framework,” Robotics and Autonomous Systems, Vol. 57, No. 1, 2009, pp. 75-86.
- V. Isler, D. Sun and S. Sastry, “Roadmap Based PursuitEvasion and Collision Avoidance,” Proceedings of Robotics: Science and Systems, 2005.
- L. Ming, B. Jose Jr., S. Cruz and A. Marwan, “An Approach to Discrete-Time Incentive Feedback Stackelberg Games,” IEEE Transactions on Systems, Man, and Cybernetics Part A: Systems and Humans, Vol. 32, No. 4, 2002, pp. 472-481.
- H. Gakuhari, S. Jia, Y. Hada and K. Takase, “RealTime Navigation for Multiple Mobile Robots in a Dynamic Environment,” IEEE Conference on Robotics, Automation and Mechatronics, Vol. 1, 2004, pp. 113-118.
- S. Krysztof, “Control of a Team of Mobile Robots Based on Non-Coperative Equilibra with Partial Coordination,” International Journal Applied Mathematic Computer Science, Vol. 15, No. 1, 2005, pp. 89-97.
- Q. Zeng, B. Rebsamen, E. Burdet and L. T. Chee, “A Collaborative Wheelchair System,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, Vol. 16, No. 2, 2008, pp. 161-170. doi:10.1109/TNSRE.2008.917288
- C. Urdiales, A. Poncela, I. Sanchez-Tato, F. Galluppi, M. Olivetti and F. Sandoval, “Efficiency Based Reactive Shared Control for Collaborative Human/Robot Navigation,” Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, 29 October-2 November 2007.
- T. Hamagami and H. Hirata, “Development of Intelligent Wheelchair Acquiring Autonomous, Cooperative, and Collaborative Behavior,” IEEE International Conference on Systems, Man and Cybernetics, The Hague, 10-13 October 2004, pp. 3525-3530.
- T. Taha, J. V. Miro and G. Dissanayake, “Wheelchair Driver Assistance and Intention Prediction Using POMDPs,” Proceedings of the 2007 International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Melbourne, 3-6 December 2007, pp. 449-454. doi:10.1109/ISSNIP.2007.4496885
- A. Huntemann, E. Demeester, et al., “Bayesian Plan Recognition and Shared Control under Uncertainty: Assisting Wheelchair Drivers by Tracking Fine Motion Paths,” Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, 29 October-2 November 2007, pp. 3360-3366.
- J. B. Cruz Jr., “Leader-Follower Strategies for Multilevel Systems,” IEEE Transactions on Automatic Control, Vol. 23, No. 2, 1978, pp. 244-255. doi:10.1109/TAC.1978.1101716
- M. Simaan and J. B. Cruz Jr., “On the Stackelberg Strategy in Nonzero-Sum Games,” Journal of Optimization Theory and Applications, Vol. 11, No. 5, 1973, pp. 533- 555. doi:10.1007/BF00935665
- Y. C. Ho, P. Luh and G. Olsder, “Control-Theoretic View on Incentives,” Automatica, Vol. 18, No. 2, 1982, pp. 167-179. doi:10.1016/0005-1098(82)90106-6
- H. von Stackelberg, “The Theory of the Market Economy,” Oxford University Press, London, 1952.
- F. Lewis and V. Syrmos, “Optimal Control,” John Willey & Son, New York, 1995.
- E. Gat, R. P. Bonnasso, R. Murphy and A. Press, “On Three-Layer Architectures,” Artificial Intelligence and Mobile Robots, 1998, pp. 195-210.