Journal of Computer and Communications
Vol.04 No.06(2016), Article ID:66915,14 pages
10.4236/jcc.2016.46002
Dynamic Hyperlinker: Innovative Solution for 3D Video Content Search and Retrieval
Mohammad Rafiq Swash, Amar Aggoun, Obaidullah Abdul Fatah, Bei Li
Department of Electronic and Computer Engineering, College of Engineering, Design and Physical Sciences, Brunel University, London, UK

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 1 March 2016; accepted 27 May 2016; published 30 May 2016
ABSTRACT
Recently, 3D display technology, and content creation tools have been undergone rigorous development and as a result they have been widely adopted by home and professional users. 3D digital repositories are increasing and becoming available ubiquitously. However, searching and visualizing 3D content remains a great challenge. In this paper, we propose and present the development of a novel approach for creating hypervideos, which ease the 3D content search and retrieval. It is called the dynamic hyperlinker for 3D content search and retrieval process. It advances 3D multimedia navigability and searchability by creating dynamic links for selectable and clickable objects in the video scene whilst the user consumes the 3D video clip. The proposed system involves 3D video processing, such as detecting/tracking clickable objects, annotating objects, and metadata engineering including 3D content descriptive protocol. Such system attracts the attention from both home and professional users and more specifically broadcasters and digital content providers. The experiment is conducted on full parallax holoscopic 3D videos “also known as integral images”.
Keywords:
Holoscopic 3D Image, Integral Image, 3D Video, 3D Display, Video Search and Retrieval, Hyperlinker, Hypervideo

1. Introduction
Three-dimensional (3D) imaging system remains an attractive topic for the scientific community, entertainment and display industry, opening a new market [1] . 3D images can be applied in broadcasting, communications and many other areas [2] . There are many technologies developed for the 3D imaging systems. Holoscopic 3D (H3D) Imaging “integral imaging” as a spatial imaging method is a strong candidate for next generation 3D imaging and display system including visualization [3] .
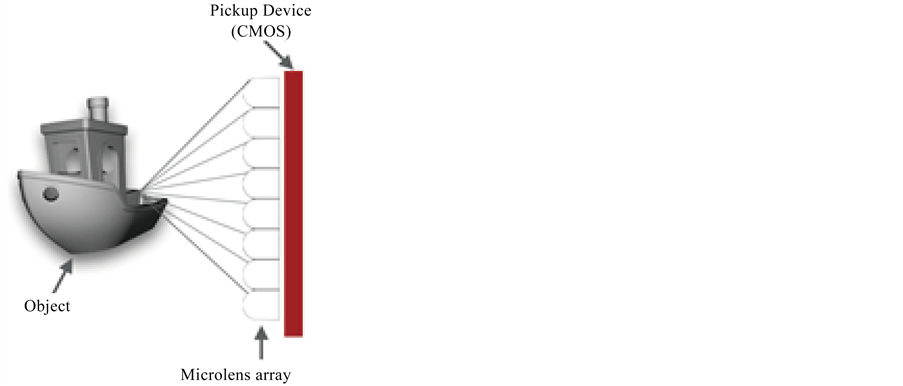
H3D imaging is first proposed by Lippmann [4] in 1908 as a very promising method for capturing and reproducing three-dimensional images [5] - [8] . This technique uses the principle of “fly’s eye” and hence allows natural viewing of objects. Unlike the stereo imaging [9] [10] , H3D imaging creates physical duplicates of light field, so it’s a true 3D technique. Compared with holographic imaging [11] , it uses incoherent radiation and forms an image that is a sampled representation of the original object space, to scale and in full color. A flat panel display for example using LCD technology can be used to reproduce the captured intensity modulated image and a microlens array (MLA) re-integrates the captured rays to replay the original scene in full color and with continuous parallax in all directions as shown in Figure 1. The 3D content can be viewed by more than one person and independently of the viewer’s position.
This paper presents the dynamic hyperlinker, which is a software tool that enables the visualization and search of a H3D multimedia repository. It simplifies and easies the H3D multimedia search and retrieval process by creating hypervideos. Hypervideos is a holoscopic 3D (H3D) video clip with an associated XML based header file which contains 3 dimensional descriptions of the H3D videos, such as positioning information, objects in the scene, search result of objects in the scene, objects annotations, related video links and several other metadata.
The XML-header file is pre-processed and prepared by multiple 3D modules, which are Centre-view, segmentation, depth map, content based search and retrieval and metadata synchronization and engineering.
2. Related Work
Digital information processing, especially search and retrieval, has been a popular research topic for the past few years. A number of EU funded projects have been completed that aimed to develop frameworks for multimodal processing, unedited multimedia indexing/annotating, and information extraction [12] - [16] . And also there has been a research focus on vertical search solutions for semantic-based search and retrieval [17] . A framework for content publishing across multiple platforms has also been developed [18] .
2D multimedia search and retrieval faces great challenges considering reliability and accuracy. Thanks to the 3D imaging technology that overcomes some of challenges such as depth, size measurement and more than a single perspective in 2D multimedia processing and also increasing the demand that accompanies many new practical applications, such as multimedia search on media asset management systems. Diverse requirements derived from these applications impose great challenges and incentives for research in the field.
3. The Proposed Dynamic Hyperlinker System
The dynamic hyperlinker is an advanced holoscopic [19] 3D video player that has hyperlinking capability to

 (a) (b)
(a) (b)
Figure 1. Principle of holoscopic 3D Imaging System: (a) Recording (b) playback.
ease the 3D search and retrieval. It links objects in the scene to similar/matching object(s) in the repository, while the video clip is being played. The user clicks on an object in the scene to search for similar objects in the repository. Also it allows professional users to add a new annotation such as object description and relevant video links. The changes are synchronized throughout the video clip for the selected objects so the user does not need to repeat the process for every frame.
As hypervideo generation involves multiple intensive 3D processing, it does pre-processing for creating hypervideos that is analyzing and annotating H3D video content and then creating and synchronization metadata to prepare a header of H3D videos in following steps:
・ Generation of center viewpoint images and 3D depth map images of H3D video images that are used by the object segmentation module to generate a segmentation mask with its bounding box.
・ Generation of metadata of H3D video images using a segmentation mask and bounding box in the content based search and retrieval module.
・ Synchronization of the generated metadata files to create an xml-header file, which is associated with the H3D video to produce a hypervideo.
・ Apply the hypervideo in the hyperlinker tool, which creates hyperlinks and easies 3D content search and visualization.
All the above processes are performed online for creating hypervideos using 3D content descriptive protocol as shown in Figure 2. The components shown in Figure 2 communicate and exchange meta-messages using the 3D content descriptive protocol, which enables to describe H3D objects in the scene using metadata descriptive languages. The metadata is later used to create a hypervideo.
Center-views and 3D depth map are generated from H3D videos that are used for segmenting 3D objects as well as creating bounding boxes for 3D objects. Then these 3D depth maps, segmentation masks, and bounding boxes related information are used to perform a content based search for associating or creating linking information “Metadata” for identical objects in the H3D videos. The content based search and retrieval module generates a single xml-indexed for every H3D video frame. The index xml file holds complete information of each frame, such as the position of objects in the scene, including object search results, as well as search result descriptions and target URL/paths. All these metadata files are fed into the metadata synchronization module, which reprocesses and merges the metadata files to create a single optimized xml-header file for the input H3D video clip. The xml-header file with H3D video are combined together to create a hypervideo, which is replayed by the hyperlinker tool to facilitate interactive 3D content search and retrieval as well as visualization, as shown

Figure 2. Architecture of the proposed dynamic Hyperlinker system.
in Figure 3. A hypervideo is a complete meta-tagged H3D video clip, which is created by associating an xml- header with a H3D video clip as shown in Figure 3. It is fed into the hyperlinker tool that facilitates interactive 3D multimedia search, retrieval and annotation.
The dynamic hyperlinker player loads the H3D video clip with the associated xml-header file. The dynamic linker module uses xml-header file to create hot links on the screen, while the H3D video is being played. It highlights clickable 3D objects with a redline box if the highlight feature is enabled in the settings. In addition, it monitors the mouse cursor movements and when a region of selectable or clickable objects are hovered over, the cursor icon is changed from default one to hand icon to alert the user that the object is clickable or hyperlinked as shown in Figure 4. On a mouse click event, it captures the mouse cursor position (X, Y) and matches it with a bounding box in the xml-header file and then it performs a search for identical objects in the repository, passing the bounding box region and content based search and retrieval batched processed the search result. These can be found in the xml-header file therefore it is just matter of matching the bounding box region to pull out the result and display it in the search result screen. The hyperlinker tool supports user feedback and offers a semi- automatic solution for annotating H3D video clips. It enables users to create a new hyperlink to an external source or remove an existing hyperlink if an irrelevant result is shown. It performs bulk synchronization so that in the case the user needs to modify any one of the H3D video frames, the system syncs the changes to the whole scene automatically. The basic functionality of the system is as follows:
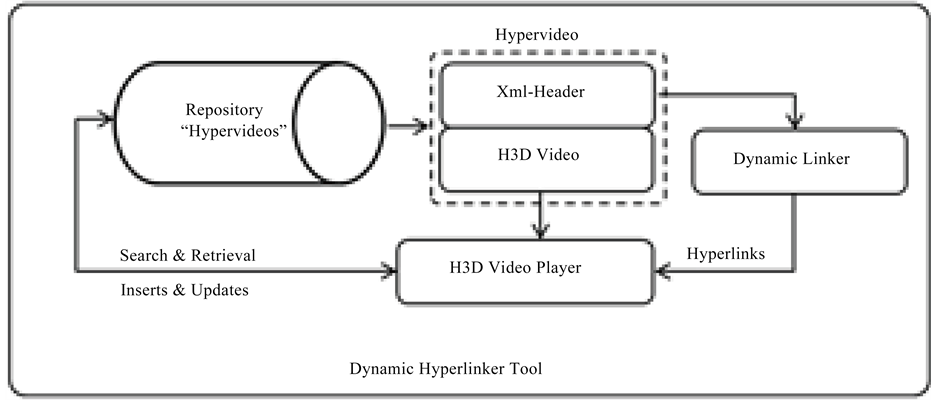
Figure 3. Block diagram of dynamic hyperlinker tool.
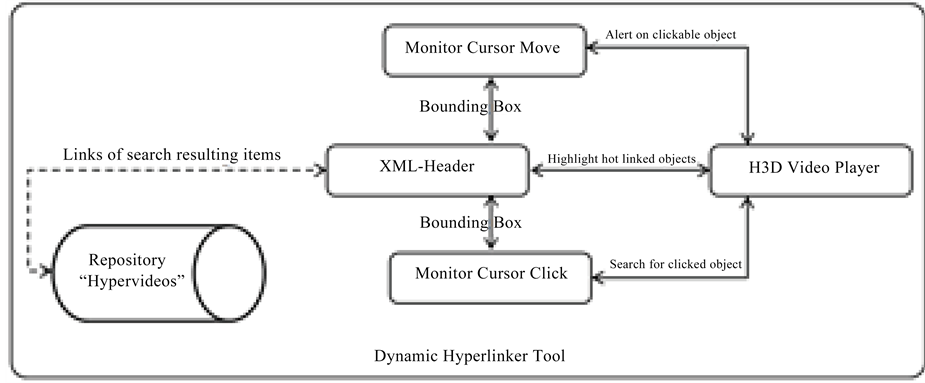
Figure 4. Action flow diagram of dynamic hyperlinking.
・ Open and play a hypervideo.
・ Play/pause/stop H3D video clip.
・ Add/remove/update the xml-header file that is automatically updated.
・ Add/remove/update title of bounding boxes.
・ Export/import/save/save-as the xml-header file.
・ Highlight selectable objects.
・ Show search and retrieval results including thumbnail.
・ Link selectable objects to any destination resource.
・ Play search result items on user click from the particular scene/frame.
・ Preview hyperlinked video.
・ User feedback e.g. adding/deleting search results.
Create a new bookmark for selectable objects that is automatically synchronized to the whole scene.
The H3D video gets paused automatically when a selectable object is clicked, as the system invokes the content-based search and retrieval and the found results appear in the list box. At this stage, the user can remove any irrelevant results from the result list if necessary or add a new bookmark for the selected object. The changes are synchronized to the xml-header automatically and saved which overwrites any existing ones, unless the “save as” feature is selected. The system re-indexes the whole sequence of frames.
The re-index works only on objects in the scene. It is valid until the object disappears from the scene. If the object goes away from scene and then comes back, the system treats it as a new object. This is because the content based search and retrieval module retrieves objects based on their visual information.
All the components process H3D video offline including the metadata engineering and synchronization. The hyperlinker tool plays a hypervideo and performs a real-time hyperlinking using the xml-header. The hyperlinker’s performance is monitored and analyzed. Table 1 shows the time taken to perform various actions such as playing, linking, loading, searching, listing, adding and removing hot links. This shows that in terms of performance requirement point of view, the hyperlinker system can be executed on any today’s PCs/laptops without the need of an especially powerful computer.
4. 3D Content Descriptive Protocol
The 3D content descriptive protocol “3DCDP” is a descriptive meta-language that describes and annotated holoscopic video images content using Extensible Markup Language “XML”. It is used for 3D video content indexing including tagging selectable objects in the video clip.
In addition, it is used for annotating H3D video content as well as meta-information exchange between components e.g. segmentation, content based search & retrieval, and hyperlinker tool which use it to exchange action-message in a single format in the system.
The proposed 3DCDP has enough elements and attributes shown in Table 2 to describe 3D video contents in a structured manner in xml tag. It uses minimum elements to annotate all possible cases which may appear in indexing a 3D video clips. More importantly, it seamlessly integrates the system components of batch and real-time processing as well as it improves 3D search & retrieval performance with interactive navigability features as objects in the scene are easily described including annotations, bounding boxes and search results. As

Table 1. The performance sheet of the hyperlinker tool.
Table 2. All elements of 3D content descriptive protocol.
seen, Table 2 shows all elements of 3DCDP that are used to fully describe both still and video H3D image content as well as embedding object(s) search results.
Figure 5 shows the hierarchical structure of 3DCDP from its root element. It is associated with a H3D video clip that has a UUID, which is unique for the video in the repository, and then it’s content with content-info element. A content element can have a single or multiple scene(s), which is given an ID and defined by start-frame and end-frame. As seen, it also allows one to add a description to the scene. A scene can have no or more annotation(s) because a scene could contain no or more clickable objects.
An annotation has a given an ID as well as start-frame and end-frame which is its validity. The attributes are used to identify the annotation if there is more than one annotation. As seen in Figure 5, an annotation is created by operator(s) “Operator-Desc” which has multiple attributes to describe the particular annotation and associate its bounding-box of one or more. An operator is not restricted to a single bounding-box because there could be two of the same object in the scene so it allows binding multiple bounding-boxes if necessary. Every object in the scene is located and annotated by a bounding-box element of minimum (X, Y) and maximum (X, Y) attributes. Its URL and description attributes are used to bookmark the bounding-box with a URL and add its description. As seen, each bounding-box has embedded search result list/item and search-result-items have a minimum information of hyperlinked destination such as content-type attributes (image, video, file), relevance (of destination source in percentage) and Item-Desc which allows one to tag a tip to it.
The proposed 3DCDP shown in Figure 6 and Figure 7 is going to be submitted to MPEG7 as an extension to cover H3D imaging formatting once it is further developed to include H3D imaging features, such as pixels per lens, microlens information, and viewpoint images. The proposed approach is effective for indexing, searching and navigating a video content and also the metadata can be used for creating statistical reports for the visualization of the video clip e.g. number of selectable objects, number of scenes and in the same manner as reported in [20] .
5. 3D Centre View Extraction
H3D image offers multi-angular views and to reduce exhausted visual processing and complexity, it is proposed to use center-view of H3D image(s) (see Figure 8). The center-view gives the best view of the scene that is from a central perspective.
In addition, supposing an extreme situation with a wide viewing angle some users might see a certain object sooner than others would, e.g. if one object appears from behind another object: while a viewer seeing the scene from the side might already see two objects, those watching from a front view would not see the object in the background. In other words, for every available perspective any given object would be visible and thus clickable

Figure 5. Hierarchical structure of 3D content description protocol.

Figure 6. Annotation element hierarchical structure of 3DCDP.

Figure 7. Bounding-Box element hierarchical structure of 3DCDP.

Figure 8. A small portion of holoscopic 3D image to illustrate the center -view position under every microlens.
at a different time. In that case it would be very difficult to determine when an object would be clickable (frame x to frame z from view A vs. frame v to frame y from view B, etc.) and as an editor could not edit the video for every possible view. It is decided to neglect this theoretically complex situation and assume a simpler situation where all viewers see any given object at roughly the same time. To this end center viewpoints were extracted, which form the basis of all subsequent steps of the hyperlinking process.
In order to extract the 2D high resolution centric-view from holoscopic 3D video image, the barrel distortion is corrected to avoid any errors in the centric-view and also this is to ensure the H3D image is distortion free.
Figure 9 shows the center-view image extraction process which uses multiple view-images to render a single HD like center-view image because H3D image has a low 3D resolution therefore a single centric-view will not be sufficient therefore; the neighboring view-images are used to enhance the center-image.
6. 3D Depth Map Extraction
The depth map is generated from H3D video images and this work has been successfully published recently in [21] . It uses viewpoint images and its center-view images of the H3D image in calculating the disparity information. H3D video frames are input/inserted into the depth map system one by one and it extracts viewpoint images with a reference-view and then it takes the advantages of the reference viewpoint to calculate the disparity binary image, which is used to generate a depth map image as shown in Figure 10.
7. Object Segmentation
The segmentation process finds objects and segments them from the other objects and background in the scene. It uses center-view images of H3D images because it simplifies the process massively, due to angular information of H3D images. In addition, it generates bounding-box metadata of the segmented objects that describe the position of object(s) in the scene and its output result is consumed by hyperlinker and content based search and retrieval module. The hyperlinker uses a bounding-box to detect user mouse hover as well as to pick up object information when the user clicks it, whereas content base search and retrieval use the segmented object(s) to perform a search for similar objects in the repository.
Figure 11 shows a block diagram of the segmentation process, which detects and segments objects with their bounding-boxes, which are later merged to create a single frame segmentation mask image with its metadata file. In the content based search & retrieval module, a segmented object mask is required for each detected object. In order to avoid passing multiple files per frame all segmented objects are encoded in a single grey scale image which maps the input image. Figure 12 shows a sample of the bounding boxes created by the segmentation that is further enhanced by the search & retrieval module, which include the search result items in the bounding box (es).
8. Content Based Search and Retrieval
The Search and Retrieval Tool is executed offline to prepare H3D video sequences metadata for interactive
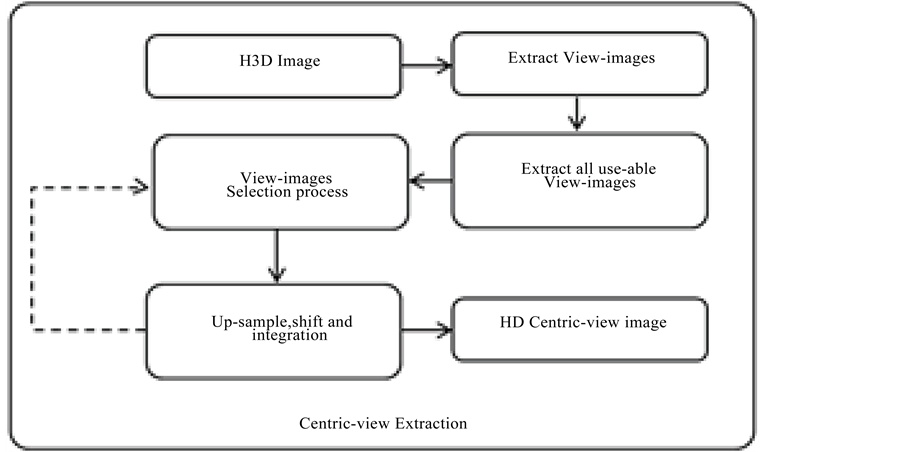
Figure 9. Block diagram of center-view extraction process.

Figure 10. Block diagram of the depth map extraction system.

Figure 11. Block diagram of segmentation and bounding box creation.
search and navigation. In particular, the search and retrieval performs low level features similarity in the multimodality level to find associated similar objects in the H3D video and generate metadata, which represent the H3D video content and this enables clicking on objects in the scene to perform a search for similar objects.
The necessary input files are: 1) the H3D video sequence; 2) the center-view images of the H3D video frames; 3) the depth maps for all H3D video frames; 4) the corresponding segmentation mask with its metadata (that contains the bounding boxes information for the clickable objects in the scene). A brief schematic overview of

Figure 12. Sample of bounding boxes created by segmentation.
the data flow is presented in Figure 13.
The input data files fall under the S&R data structure format, such as various visual data descriptions e.g. H3D images, depth map, viewpoint images, and low level features. This facilitates the easy visual parsing for the Search and Retrieval Framework.
The system analyses every frame of input H3D video clip and it generates a single metadata file for each frame. The metadata file contains a single annotation, which has one or more bounding-boxes depending on the objects in the scene. It performs a visual similarity search for object(s) and embeds the search result as an element in the bounding-box node.
9. Metadata Engineering and Synchronization
H3D videos frames are analyzed and processed by the segmentation and content based search & retrieval module, which generate a metadata file that describes H3D video frames in structured manner using 3D-CDP meta-language (see Figure 14). At this stage, a single metadata file is generated for every frame of the H3D video and the metadata file structure is presented in Figure 13 that contains a single annotation with one or more bound-boxes of the scene. The bounding-box contains the search result item of this particular object “bounding-box”.
The bounding-box is valid for a single frame as it is for video objects. Therefore object positions are in constant change from frame to frame. In addition, 3D objects in the scene will appear differently from different perspectives so the content based search and retrieval system may do the matching with the particular perspective of the object. As a result, there are hundreds of metadata files containing meta-description of scenes. To overcome this issue exhausted and complex metadata files management, we propose a multimodal metadata synchronization technique for re-engineering the metadata file to create a single optimized xml-header of H3D video. The proposed metadata synchronization aims at merging all metadata files by removing redundant sections and then putting meta-nodes in a structured way, which will not overlap each other and also it structures the meta-nodes in such way that is more manageable in terms of re-manipulating it. The process creates a single xml-header file of the H3D video and its file structure is shown in Figure 15.
It imports all frames metadata files and decomposes the file nodes as low level as annotation. It then creates a new metadata file (xml-header), which has a single scene with multiple annotations. Each frame metadata file has a single annotation; therefore it is treaded as an annotation node in a newly created file. It reforms a new scene and a new annotation with correct frame locations, which also presents statistical data such as scene-dura- tion, and annotation start/end-frame. The statistical data can be easily processed to generate a visualization graph e.g. a particular object (bound-box) live on the scene and number of objects in the scene/video as well as complexity of the video content. Also this can be used for navigating the video content without replaying the video and such video summarization techniques are widely adopted by consumers who like to view the summary of the video before they start watching it, such as movie trailer.
10. Experimental Results and Demo
The proposed tool supports holoscopic 3D videos and Figure 16 shows a H3D video clip playback result. As seen, the selectable objects are highlighted in red rectangles and this means the objects are hyperlinks. The user can click on any of the objects to search for similar objects in the repository. The search results are listed in the list box. The user can view/play the result by selecting it from the list box.
It is further developed to support editing metadata of xml-header file as well as importing/exporting and saving it as a new project, which can be later opened without losing the changes and without having to save it on its

Figure 13. Block diagram of content based search and retrieval system.

Figure 14. Metadata file structure generated by segmentation and S & R.
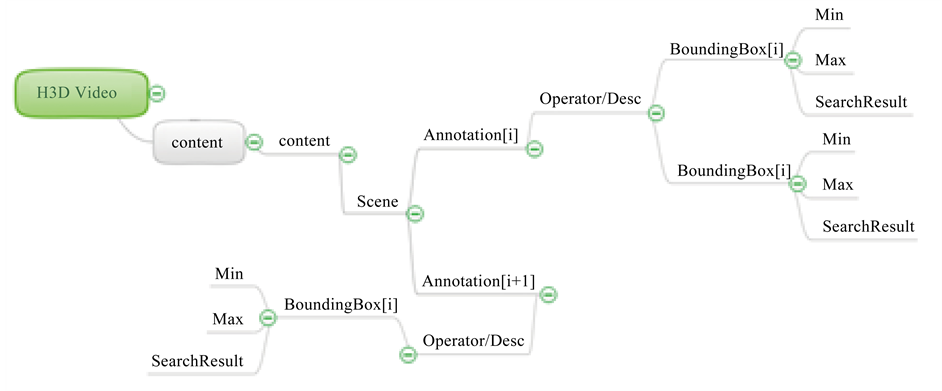
Figure 15. XML-header file structure generated by the synchronization.
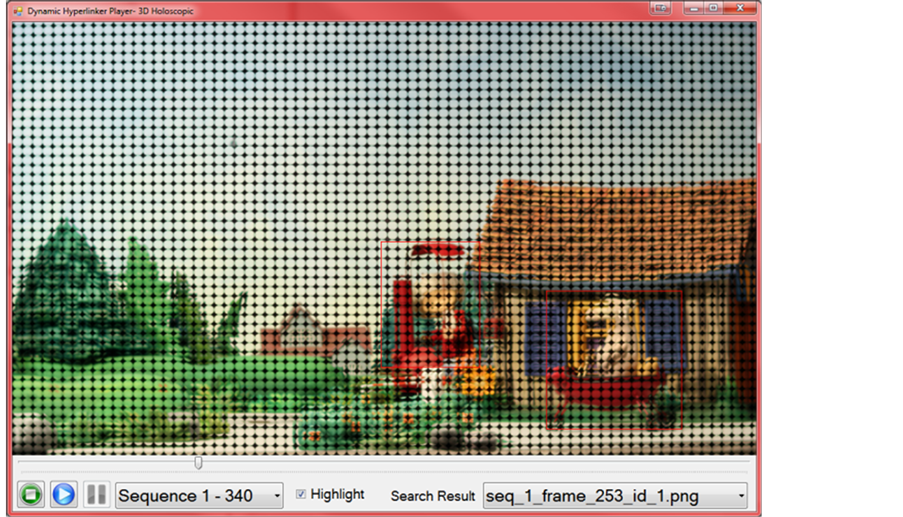
Figure 16. The proposed dynamic hyperlinker player screen.
original version. In addition, it has been revised to support center-views of H3D videos because holoscopic 3D content requires a special “H3D Display”, which is not available widely and also it opens to those who want to replay 2D version of H3D content. The screenshot of playback of centric view of H3D video is shown and as seen objects in the scene are highlight and titled if the object(s) has an associated title.
As it allows editing metadata of the H3D video, the user can select an object and add a new associated search result or delete a search result. The system propagated the changes to the whole scene automatically so next when one click on the object, the updated search result is shown. In addition, the user can back-up the changes by exporting the metadata without saving it to the original file. The exported file can be imported later if necessary. That shows the screenshot of search result screen that shows list of similar objects in the repository excluding the current video. It also shows the search results descriptions, video names and the scene frame number in which the object is found. At this stage, any of the search result items can be clicked to play it and the system will start playing the video from this particular scene/frame.
11. Conclusion
In this paper, dynamic hyperlinker which is an innovative solution for 3D video search and retrieval includes a 3D content descriptive protocol for 3D search and retrieval that enables users to search, retrieve and visualize holoscopic 3D video clips by clicking on selectable object in the scene while the video clip is being played. At this stage, the holoscopic 3D videos are preprocessed by 3D operators such as center viewpoint extraction, depth map creation, segmentation and content based search and retrieval module. The 3D operators use a 3D content descriptive protocol to exchange meta-message as well as annotating the media content. The proposed system advances user interaction and easies the multimedia content search and retrieval. The experiment is conducted on holoscopic 3D content as well as its 2D center-view content and it is applicable and scalable to any other 3D content. It is worthwhile mentioning that the dynamic hyperlinker performs well on 3D video sequences and it is an interactive tool for 3D content search and retrieval as well as visualization. Furthermore, it enhances 3D data visualization and retrieval for content providers such as broadcasters as it allows to bookmark objects and allows the insertion of tags, textual descriptions or/and links to the objects in a scene.
Acknowledgements
This work was supported by the EU under the ICT program as Project 3D VIVANT (3D LiVe Immerse Video-
Audio Interactive Multimedia) under EU-FP7 ICT-2010-248420.
Cite this paper
Mohammad Rafiq Swash,Amar Aggoun,Obaidullah Abdul Fatah,Bei Li, (2016) Dynamic Hyperlinker: Innovative Solution for 3D Video Content Search and Retrieval. Journal of Computer and Communications,04,10-23. doi: 10.4236/jcc.2016.46002
References
- 1. Aggoun, A. (2011) Compression of 3D Integral Images Using 3D Wavelet Transform. Journal of Display Technology, 7, 586-592.
http://dx.doi.org/10.1109/JDT.2011.2159359 - 2. Okano, F. (2008) 3D TV with Integral Imaging. Proc. of SPIE, Orlando, 16 March 2008, 69830N.
http://dx.doi.org/10.1117/12.786890 - 3. Onural, L. (2007) Television in 3-D: What Are the Prospects? Proceedings of the IEEE, 95, 1143-1145.
http://dx.doi.org/10.1109/JPROC.2007.896490 - 4. Lippmann, G. (1908) La photographieintegrále. Comptes Rendus de l’Académie des Sciences—Series IIC—Chemistry, 146, 446-451.
- 5. Aggoun, A. (2010) 3D Holoscopic Video Content Capture, Manipulation and Display Technologies. Proceedings of 9th Euro-American Workshop on Information Optics, Helsinki, 12-16 July 2010, 1-3.
http://dx.doi.org/10.1109/wio.2010.5582529 - 6. Aggoun, A. (2010) 3D Holoscopic Imaging Technology for Real-Time Volume Processing and Display. High-Quality Visual Experience Signals and Communication Technology, 411-428.
http://dx.doi.org/10.1007/978-3-642-12802-8_18 - 7. Davies, N., et al. (1988) Three-Dimensional Imaging Systems: A New Development. Applied Optics, 27, 4520.
http://dx.doi.org/10.1364/AO.27.004520 - 8. Martinez-Corral, M., Javidi, B., Martínez-Cuenca, R. and Saavedra, G. (2005) Formation of Real, Orthoscopic Integral Images by Smart Pixel Mapping. Optics Express, 13, 9175-9180.
http://dx.doi.org/10.1364/OPEX.13.009175 - 9. Jorke, H. and Fritz, M. (2006) Stereo Projection Using Interference Filters. Proc. SPIE 6055, San Jose, 15 January 2006, 60550G.
http://dx.doi.org/10.1117/12.650348 - 10. Zhang, L. and Tam, W.J. (2005) Stereoscopic Image Generation Based on Depth Images for 3D TV. IEEE Transactions on Broadcasting, 51, 191-199.
http://dx.doi.org/10.1109/TBC.2005.846190 - 11. Slinger, C., Cameron, C. and Stanley, M. (2005) Computer-Generated Holography as a Generic Display Technology. Computer, 38, 46-53.
http://dx.doi.org/10.1109/MC.2005.260 - 12. (2015) RUSHES—Retrieval of mUltimedia Semantic Units for enHanced rEuSability.
http://cordis.europa.eu/ist/kct/rushes_synopsis.htm - 13. (2015) BOEMIE—Bootstrapping Ontology Evolution with Multimedia Information Extraction.
http://cordis.europa.eu/ist/kct/boemie_synopsis.htm - 14. (2015) aceMedia—Create, Communicate, Find, Consume, Re-Use.
http://cordis.europa.eu/ist/kct/acemedia_synopsis.htm - 15. (2015) CARETAKER—Content Analysis and Retrieval Technologies to Apply Knowledge Extraction to Massive Recording.
http://cordis.europa.eu/ist/kct/caretaker_synopsis.htm - 16. (2015) K-Space—Knowledge Space of Semantic Inference for Automatic Annotation and Retrieval of Multimedia Content.
http://cordis.europa.eu/ist/kct/kspace-synopsis.htm - 17. (2015) Superpeer Semantic Search Engine.
http://cordis.europa.eu/ist/kct/alvis_synopsis.htm - 18. (2015) Content4All—Cross Platform Tools for Community Content Publishing.
http://cordis.europa.eu/ist/kct/content4all_synopsis.htm - 19. Aggoun, A., Tsekleves, E., Swash, M.R., Zarpalas, D., Dimou, A., Daras, P., Nunes, P. and Soares, L.D. (2013) Immersive 3D Holoscopic Video System. IEEE Transactions on Multimedia, 20, 28-37.
http://dx.doi.org/10.1109/MMUL.2012.42 - 20. Schreer, O., Feldmann, I., Mediavilla, I.A., Concejero, P., Sadka, A.H., Swash, M.R., Benini, S., Leonardi, R., Janjusevic, T. and Izquierdo, E. (2009) RUSHES—An Annotation and Retrieval Engine for Multimedia Semantic Units. Multimedia Tools and Applications, 48, 23-49.
http://dx.doi.org/10.1007/s11042-009-0375-8 - 21. Fatah, O., Aggoun, A., Nawaz, M., Cosmas, J., Tsekleves, E., Swash, M.R. and Alazawi, E. (2012) Depth Mapping of Integral Images Using Hybrid Disparity Analysis Algorithm. 2012 IEEE, 1-4.