Journal of Computer and Communications
Vol.03 No.09(2015), Article ID:59425,8 pages
10.4236/jcc.2015.39002
Personalized Tag Recommendation Based on Transfer Matrix and Collaborative Filtering
Shaowu Zhang1,2, Yanyan Ge1
1School of Computer Science and Technology, Dalian University of Technology, Dalian, China
2School of Computer Science and Engineering, Xinjiang University of Finance and Economics, Urumqi, China
Email: zhangsw@dlut.edu.cn
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 30 July 2015; accepted 4 September 2015; published 7 September 2015
ABSTRACT
In social tagging systems, users are allowed to label resources with tags, and thus the system builds a personalized tag vocabulary for every user based on their distinct preferences. In order to make the best of the personalized characteristic of users’ tagging behavior, firstly the transfer matrix is used in this paper, and the tag distributions of query resources are mapped to users’ query before the recommendation. Meanwhile, we find that only considering the user’s preference model, the method cannot recommend new tags for users. So we utilize the thought of collaborative filtering, and produce the recommend tags based on the query user and his/her nearest neighbors' preference models. The experiments conducted on the Delicious corpus show that our method combining transfer matrix with collaborative filtering produces better recommendation results.
Keywords:
Tag Recommendation, Collaborative Filtering, Transfer Tensor

1. Introduction
With the rapid growth of the web and social networks, more and more people like to share their information on the Internet, including pictures, videos and even political opinions. This leads to the flourish of the web data, and increases difficulties for people to organize and search resources they want. In order to address this challenge, social tagging has attracted more attentions. Delicious, Bibsonomy, Flickr, and Last.fm are all the popular social tagging online services recently.
Tagging allows users to label content by assigning freely chosen keywords (tags). In such open environment, tagging has proven a superior alternative to traditional categorization techniques due to its flexibility that enable users to choose labels that match their real tastes. And the increase of the descriptive keywords on resources is convenient for people to search, especially in the case of multimedia. Different online tagging service distinguishes in the resource type, but they are similar in essence, such as Delicious supports the tagging on webpages, Bibsonomy allows to tag webpages and journal papers, and people can tag pictures and the music in Flickr and Last.fm, respectively [1] . This kind of community services that centers on the tagging of resources is also called folksonomies. These communities have become a valuable source of information, since they bundle the interests, preferences of thousands or millions of users.
Tag recommenders support a user during the posting process by suggesting potentially relevant tags. Because of the stability of a user’s tag vocabulary, it is effective to predict the future tagging behavior of a user according to the past. Previous works have showed that the description of the same object is different due to users’ customs and knowledge. So in the social tagging system, each user can generate a set of tags with their own preferences, which is called personalized tag vocabulary. At the same time, tags on the resources are based on the whole tagging system and called folksonomies. The tagging system builds preference models of users and tag models of resources by analyzing users’ tagging history, and generates the correlations among tags, users and resources; then recommends the top n relevant tags to users. Depending on whether consider users’ preference models or not, tag recommendation comes in two forms, personalized and non-personalized. For a resource, personalized tag recommender systems recommend different tags for different users in contrast to non-personalized tag recommenders. And for a good tag recommender system, personalized recommend should be given preference.
Wetzker et al. [2] introduce a novel tag model that allows deriving mappings between personal tag vocabularies and the corresponding folksonomies. Using these mappings, it can infer the meaning of user-assigned tags and can predict choices of tags a user may want to assign to new items. So this kind of transfer based method can meet the personalized demand of users. But it only considers the preference model and the used tags of a user, and cannot recommend new tags.
In order to solve this limitation, based on the transfer tags, we integrate the collaborative filtering technology and generate a new algorithm. First, we build the personalized transfer matrix for each user; the element in the matrix represents transfer values between personalized tags and folksonomies. Then, we determine the nearest neighbors of a user by computing their similarities. Finally, we recommend tags by considering the user and his/her nearest neighbors’ preference models and their similarities together. In addition, for similarities between users, we propose a new method based on the personalized transfer matrix.
The remainder of this paper is structured as follows. We begin with a discussion of related work in Section 2. Section 3 describes our method in detail. And then analyze the experiments in Section 4. Section 5 concludes the work of the paper.
2. Related Work
2.1. Tag Recommendation
Recently, the social tagging system has attracted a lot of attention, and the recommender system based on the social tagging also obtains much more focus.
There are many classical recommendation algorithms. Collaborative filtering based method is traditional and will be described in the next subsection. Resource content based method focuses on the texts or webpages and mainly depends on the key words extraction technology to select the tags. Zhang et al. [3] discussed that different resources and users should adopt different recommend methods, and for those new resources, resource content based method is a choice. Guan et al. [4] took the tag recommendation as a “questions and sort” problem, and proposed a graph-based ranking technology.
Symeonidis et al. [5] proposed to decompose the full folksonomy tensor and estimate missing values using Higher Order SVD (HOSVD). The authors claim reasonably good results on the task of tag recommendation. Rendle et al. [6] [7] reported some researches on applying tensor factorization methods on the tag recommendation.
Folk Rank algorithm is inspired by the seminal Page Rank algorithm [2] [8] -[10] . The basic notion is that a resource which is tagged with important tags by important users becomes important itself. Folk Rank is based on the random surfing model, considering the weight and weight-spreading of edges. The algorithm cannot be applied directly on folksonomies; it needs to be transferred into an undirected tripartite graph including users, resources, and tags.
And also there are many recommender systems consist of different methods. Zhang et al. [2] combined the content based and collaborative filtering algorithm together, the former applied to new resources, the later used to other situations. Zowl et al. [11] designed four tag recommendation strategies by combining the tag co-oc- currence, tag aggregation (including vote and sum strategies), and optimized re-ranking method.
2.2. Collaborative Filtering
Collaborative filtering is a widely used and effective recommendation technology. It gets favored by many commercial websites, such as Amazon.com. The underlying assumption of the approach is that users would have similar behavior in the future if they performed similar in the past. In the recommender systems, collaborative filtering comes in two methods, user-based and item-based. The user-based algorithm recommends a user what his/her nearest neighbors interest in. The item-based algorithm recommends a user an item by judging whether the user interests the nearest neighbors of the item.
There are many researches about applying collaborative filtering in the recommender system [12] . Previous works have summarized the approach and proposed to model social tagging systems as tripartite hypergraphs [13] -[15] . Marinho et al. [16] designed a tag recommender system with collaborative filtering method, and results show that it performs better than the other two popular methods. Xu et al. [17] proposed an iterative algorithm based on the collaborative filtering to compute the quality of tags. Koren [18] also combines the collaborative filtering and temporal dynamics in the recommendation. Gueye et al. [19] [20] . develop a network based parameter-free system to optimize the tag recommendation. Ifada et al. [21] introduce learning to rank methods from information retrieval field to optimize the DCG measure in tag-based item recommendation.
3. Transfer Matrixes Based Personalized Tag Recommendation Model
In the social tagging system, different tags are called co-occurrence if they appear in one resource. The paper first makes use of this co-occurrence among tags to build mappings between personalized user tags and folksonomies on resources, and identify the nearest neighbor set N of the user by integrating collaborative filtering technology. Then in the tag recommendation stage, we can map the tag distribution of the query resource to the distributions of tags that the query user and his/her neighbors have used.
The arrangement of the part is as follows. Subsection 3.1 gives the description of the problem. We introduce the build of the personalized transfer matrix and the identification of the nearest neighbors in subsection 3.2. Subsection 3.3 describes the method to recommend tags based on the user and nearest neighbors.
3.1. Problem Description
A social tagging system includes users, resources, and tags, and the tagging behavior of a user reflects the relationship among them. A folksonomy is a tuple F: = (U, T, R, A) where U, T, and R are finite sets, whose elements are called users, tags, and resources, respectively, and A is a ternary relation among them, i.e.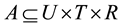 , whose elements are called tag assignments (TAS for short). A user and a resource tagged himself/herself together are called a bookmark which can be represented as
, whose elements are called tag assignments (TAS for short). A user and a resource tagged himself/herself together are called a bookmark which can be represented as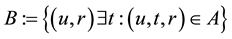 .
.
For the given user and the resource (u, r), we need to compute correlations between a tag and u and r. The higher correlation represents the higher possibility that the user u assigns this tag to the resource r. Then we can recommend the highest tags to the user.
3.2. Build Personalized Transfer Matrix
The relations between resources and tags are represented as a 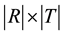 matrix X as follows:
matrix X as follows:
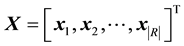 (1)
(1)
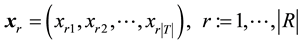 (2)
(2)
where xrt is times that the tag t assigned to the resource r, and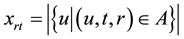 . A row vector
. A row vector 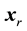 is a tag distribution of the resource r, and a column vector is a resource distribution of the tag t. After the normalization on rows of the matrix X, we get
is a tag distribution of the resource r, and a column vector is a resource distribution of the tag t. After the normalization on rows of the matrix X, we get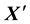 :
:
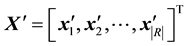 (3)
(3)
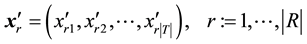 (4)
(4)
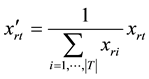 (5)
(5)
The relation between users’ personalized tags and folksonomies is built through resources. If any two tags co-occurrence on many resources, they will have a higher relation. So we set up a mapping between users’ personalized tags and folksonomies based on the co-occurrence. For a user u, 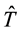 and T represent the used personalized tag vocabulary of u and the folksonomy, respectively. We then can represent the mapping as a
and T represent the used personalized tag vocabulary of u and the folksonomy, respectively. We then can represent the mapping as a 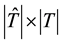 personalized transfer matrix Yu, and Table 1 is an example.
personalized transfer matrix Yu, and Table 1 is an example.
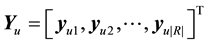 (6)
(6)
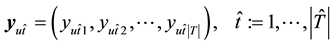 (7)
(7)
where element 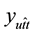 is the mapping value between a personalized tag
is the mapping value between a personalized tag  and a folksonomy t. It can be represented as Equation (8).
and a folksonomy t. It can be represented as Equation (8).
 (8)
(8)
If , it indicates the user u assigned the tag
, it indicates the user u assigned the tag  to the resource r, then
to the resource r, then  equals to 1.0, or to 0.0. Then
equals to 1.0, or to 0.0. Then
 (9)
(9)
where  represents the resources assigned with
represents the resources assigned with  by the user u.
by the user u.
3.3. Identify Nearest Neighbors
It needs to identify the nearest neighbor set after building the personalized transfer matrix. Here we use the cosine to measure the similarity, and choose the top K as the nearest neighbors of the query user. According to Marinho [16] , we compute similarities under two situations. One is based on the resources with tags assigned by users. Assuming the number of resources is M in total, a user can be represented as an M vector , and pi equals to 1.0, if the user assigned tags to the resource ri, otherwise is 0.0. The other is based on the tag space model. Assuming there are N tags, then a user is a N vector
, and pi equals to 1.0, if the user assigned tags to the resource ri, otherwise is 0.0. The other is based on the tag space model. Assuming there are N tags, then a user is a N vector , and qi is the ratio that the number of the user u use the tag ti in to the all tags used by the user, which reflects the probability that the user u use the tag ti.
, and qi is the ratio that the number of the user u use the tag ti in to the all tags used by the user, which reflects the probability that the user u use the tag ti.
In addition, we also propose a method to compute the similarity between users based on the personalized transfer matrix. If any two transfer matrixes of users have a high similarity, we can believe that the two users are

Table 1. The personalized transfer matrix of a user.
similar. If both the personalized tag vocabularies of user u and v include the tag ti, we can define the user cosine similarity based on the tag ti as follows:
 (10)
(10)
 (11)
(11)
where  and
and  in Equation (9) are the transfer vectors of user u and v based on the tag
in Equation (9) are the transfer vectors of user u and v based on the tag . In Equation (11), w(u, t) is the probability that the user u use the tag t as we defined in the subsection 3.2. N is the number of tags that both user u and v have, and the higher the N, the higher the similarity between users.
. In Equation (11), w(u, t) is the probability that the user u use the tag t as we defined in the subsection 3.2. N is the number of tags that both user u and v have, and the higher the N, the higher the similarity between users.  is a tunable parameter, and we get our best results when it sets to 3.
is a tunable parameter, and we get our best results when it sets to 3.
3.4. Tag Recommendation
For the given query user and the resource (u, r), we combine the thought of collaborative filtering with personalized transfer matrix when recommend tags. This can ensure both the personalization and the generation of new tags. For the query user u, we first get his/her nearest neighbor set N(u) by Equation (11), then mapping the tag distribution of the resource r to the tag vocabulary of user u and N(u) by the transfer matrix. Let  represents the weight of tag
represents the weight of tag  on the resource r given by the user u, and define as follows:
on the resource r given by the user u, and define as follows:
 (12)
(12)
where N(u) is the nearest neighbor set of the user u, it includes the user u itself. Let  defines as the weight of tag
defines as the weight of tag  on the resource r given by the user v, and it can be get through the tag distribution on resources and personalized transfer matrix of the user v by Equation (13).
on the resource r given by the user v, and it can be get through the tag distribution on resources and personalized transfer matrix of the user v by Equation (13).
 (13)
(13)
After the transfer through the Equation (12), we can obtain the weight distribution of tags used by the user u and N(u). The tag vocabulary would be empty if there is no co-occurrence between tags on the resource r and the user u and N(u). In order to solve this problem, and increase the weight of tags that better represent the resource, we compute the final tag weight through Equation (14), and recommend the top n tags to the query user.
 (14)
(14)
where w(r, t) is the weight of tag t on the resource r. Parameter  uses to balance the weight distribution. When
uses to balance the weight distribution. When  equals 1.0, it considers the personalized transfer matrix and collaborative filtering technology together; when
equals 1.0, it considers the personalized transfer matrix and collaborative filtering technology together; when  equals 0.0, it is reduced to the popular tag recommendation method which only recommends the maximum tags on resources to the query user.
equals 0.0, it is reduced to the popular tag recommendation method which only recommends the maximum tags on resources to the query user.
4. Experiments and Analysis
4.1. Datasets
In order to prove the efficiency of our method, we conduct experiments on the Delicious dataset. Delicious is probably the best researched folksonomy to date [1] . Our dataset is a subset of the one presented in [22] , which is publicly available upon request. Here, we only keep the records in the first 5 months from September 2003 until January 2004, and ignore the time tags of the dataset. The experiments are conducted on p-core versions of the original graphs, with p set to 5. The p-core of a folksonomy graph is its largest subgraph where all users, items, and tags appear at least p times. The resulting global dataset statistics are shown in Table 2.
4.2. Evaluations
We use two standard measures from information retrieval to measure the recommendation effectiveness: precision and recall. Meanwhile, we test our method by F1 value, which is defined as the harmonic mean of precision
Table 2. Statistics for datasets and p-cores.
and recall.



where test refers to the test set, N is the number of the (u, r) in the test set.
4.3. Experiments
In this paper, we conduct the following experiments using different methods on the same dataset.
1) The traditional collaborative filtering method, denoted as colla. Here we adopt the algorithm described by Marinho [16] , for the obtained nearest neighbor set N(u) of the query user u, the tag weight is calculated by Equation (15).
 (15)
(15)
If ,
,  equals 1.0, otherwise equals 0.0. Finally, we recommend the top n tags to the query user.
equals 1.0, otherwise equals 0.0. Finally, we recommend the top n tags to the query user.
2) The transfer tensor of the user u based personalized tag recommendation, denoted as tensor u. This method is proposed by Wetzker [1] . It has been demonstrated that it can perform better than the improved Page Rank and Folk Rank algorighms and so on. The method first builds the transfer tensor between the personalized tags and folksonomies based on the tag co-occurrence, and further to mapping the tag distribution of resources to personalized tag vocabulary of the query user. Comparing with our method, it ignores the information of neighbors of the query user.
3) The method based on the transfer matrix and collaborative filtering technology, which proposed in this paper and denoted as trans + colla. It takes both the preference models of the query user u and his/her nearest neighbors into consideration.
The similarities between users in method (1) and (3) are calculated using three methods referred in subsection 3.3. There are denoted as DV which based on the resources, TV which based on the tags, and Trans V which based on the personalized transfer matrix, respectively.
4.4. Results
The experiments are conducted on 5-core dataset in Table 2. We perform 10-fold cross validation on the dataset by dividing it into 10 subsets randomly. The final evaluations of the results are the average mean of the 10-fold cross validation.
There are two parameters need to be addressed in the three recommend methods. One is the number of the nearest neighbors K, the other is the  in Equation (14). During the regulation, it finds that when K = 10 and
in Equation (14). During the regulation, it finds that when K = 10 and , method DV can obtain the best results; when K = 5 and
, method DV can obtain the best results; when K = 5 and , method TV and TransV can get the best recommendations. When
, method TV and TransV can get the best recommendations. When , method tensor u can result the best recommendations.
, method tensor u can result the best recommendations.
We conduct the experiments with the above best parameter values, and the evaluations are shown in Figure 1, Figure 2 and Figure 3. As shown in Figure 2, the Recall is improving with the increase of recommend tags. Because evaluation Recall is the ratio of right recommend tags to the actual annotation tags, so the numerator of

Figure 1. Results evaluation by precision.

Figure 2. Results evaluation by recall.
the Recall will increase if we recommend more tags. But on the other hand, the incorrect recommend tags will also increase, and this leads to the decrease of the Precision in Figure 1. It also indicates that the evaluation Recall and Precision restrict each other.
As shown in Figure 1, Figure 2 and Figure 3, method tensor_u performs better than the method colla_* (DV, TV, TransV), and method trans + colla_* also get superior results than colla_* as a whole. It indicates that the integrating of collaborative filtering approach is effective; the preference models of the query user’s nearest neighbors also play an important role in the tag recommendation. Among the methods based on the transfer matrix, the evaluations finally tend to be the same with the increase of recommend tags, especially the Precision. The explanation here is the number of tags of a bookmark is small, that is to say, the number of tags assigned by a user to a resource is small, and the average is only 1.96. So it is important to recommend right tags when the number you can recommend is small.

Figure 3. Results evaluation by F1 value.
In addition, we can find that the results of method trans + colla_* are similar. The similarity calculated by Equation (12) and Equation (13) is not the best. Because there are many users who share the same personalized tags with the query user due to the sparse dataset, and this lead to the higher similarity of transfer vectors between the query user and his/her nearest neighbor set. So due to the noise, it would produce some uninterested tags with higher tag weight, and finally influence the recommend results.
5. Conclusions
Personalized tag recommendation can be better solved by transfer tensor, but this method limits to those used tags, and cannot find new interesting tags for users. So this paper integrates collaborative filtering technology to solve this problem. Firstly, we build the personalized transfer matrix for each user based on the co-occurrence of tags. The element of the matrix represents the mapping values between personalized tags and folksonomies. Secondly, combining the collaborative filtering approach, when recommend tags, we not only consider the preference model of query users, but also his/her nearest neighbors’ and similarities between users. Aiming at the similarity, we also propose a method based on the personalized transfer matrix.
Further, we plan to focus on the problem of solving the redundant and ambiguous tags in the tagging system by applying the semantic models in the recommender system.
Acknowledgements
This work is partially supported by grant from the Natural Science Foundation of China (No. 61277370), Natural Science Foundation of Liaoning Province, China (No. 201202031, 2014020003), State Education Ministry and The Research Fund for the Doctoral Program of Higher Education (No. 20090041110002).
Cite this paper
ShaowuZhang,YanyanGe,11, (2015) Personalized Tag Recommendation Based on Transfer Matrix and Collaborative Filtering. Journal of Computer and Communications,03,9-17. doi: 10.4236/jcc.2015.39002
References
- 1. Jäschke, R., Marinho, L., Hotho, A., Schmidt-Thieme, L. and Stumme, G. (2007) Tag Recommendations in Folksonomies. Knowledge Discovery in Databases: PKDD 2007, Springer, Berlin, 506-514.
http://dx.doi.org/10.1007/978-3-540-74976-9_52 - 2. Wetzker, R., Zimmermann, C., Bauckhage, C. and Albayrak, S. (2010) I Tag, You Tag: Translating Tags for Advanced User Models. Proceedings of the 3rd ACM International Conference on Web Search and Data Mining, New York, 2010, 71-80. http://dx.doi.org/10.1145/1718487.1718497
- 3. Zhang, N., Zhang, Y. and Tang, J. (2009) A Tag Recommendation System for Folksonomy. Proceedings of the 2nd ACM Workshop on Social Web Search and Mining, New York, 2 November 2009, 9-16.http://dx.doi.org/10.1145/1651437.1651440
- 4. Guan, Z., Bu, J., Mei, Q., Chen, C. and Wang, C. (2009) Personalized Tag Recommendation Using Graph-Based Ranking on Multi-Type Interrelated Objects. Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, 19-23 July 2009, 540-547.http://dx.doi.org/10.1145/1571941.1572034
- 5. Symeonidis, P., Nanopoulos, A. and Manolopoulos, Y. (2008) Tag Recommendations Based on Tensor Dimensionality Reduction. Proceedings of the 2008 ACM Conference on Recommender Systems, New York, 23-25 October 2008, 43-50. http://dx.doi.org/10.1145/1454008.1454017
- 6. Rendle, S., Balby Marinho, L., Nanopoulos, A. and Schmidt-Thieme, L. (2009) Learning Optimal Ranking with Tensor Factorization for Tag Recommendation. Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, 2009, 727-736. http://dx.doi.org/10.1145/1557019.1557100
- 7. Rendle, S. and Schmidt-Thieme, L. (2010) Pairwise Interaction Tensor Factorization for Personalized Tag Recommendation. Proceedings of the 3rd ACM International Conference on Web Search and Data Mining, New York, 2010, 81-90. http://dx.doi.org/10.1145/1718487.1718498
- 8. Hotho, A., Jäschke, R., Schmitz, C. and Stumme, G. (2006) Bibsonomy: A Social Bookmark and Publication Sharing System. Proceedings of the Conceptual Structures Tool Interoperability Workshop at the 14th International Conference on Conceptual Structures, Aalborg, 2006, 87-102.
- 9. Hotho, A., Jäschke, R., Schmitz, C. and Stumme, G. (2006) Folkrank: A Ranking Algorithm for Folksonomies. Vol. 1, In: Althoff, K.D., Ed., Klaus-Dieter Althoff, LWA, Hildesheim, 111-114.
- 10. Hotho, A., Jäschke, R., Schmitz, C. and Stumme, G. (2006) Information Retrieval in Folksonomies: Search and Ranking. Springer, Berlin, 411-426. http://dx.doi.org/10.1007/11762256_31
- 11. Sigurbjörnsson, B. and Van Zwol, R. (2008) Flickr Tag Recommendation Based on Collective Knowledge. Proceedings of the 17th International Conference on World Wide Web, Beijing, 21-25 April 2008, 327-336.http://dx.doi.org/10.1145/1367497.1367542
- 12. Chen, W.Y., Zhang, D. and Chang, E.Y. (2008) Combinational Collaborative Filtering for Personalized Community Recommendation. Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, 24-27 August 2008, 115-123.
http://dx.doi.org/10.1145/1401890.1401909 - 13. Golder, S.A. and Huberman, B.A. (2006) Usage Patterns of Collaborative Tagging Systems. Journal of Information Science, 32, 198-208. http://dx.doi.org/10.1177/0165551506062337
- 14. Marlow, C., Naaman, M., Boyd, D. and Davis, M. (2006) HT06, Tagging Paper, Taxonomy, Flickr, Academic Article, to Read. Proceedings of the Seventeenth Conference on Hypertext and Hypermedia, Odense, 22-25 August 2006, 31- 40. http://dx.doi.org/10.1145/1149941.1149949
- 15. Mika, P. (2005) Ontologies Are Us: A Unified Model of Social Networks and Semantics. In: Gil, Y., Motta, E., Benjamins, V.R. and Musen, M.A., Eds., The Semantic Web-ISWC 2005, Springer, Berlin Heidelberg, 522-536.
http://dx.doi.org/10.1007/11574620_38 - 16. Marinho, L.B. and Schmidt-Thieme, L. (2008) Collaborative Tag Recommendations. In: Preisach, C., Burkhardt, H., Schmidt-Thieme, L. and Decker, R., Eds., Data Analysis, Machine Learning and Applications, Springer, Berlin Heidelberg, 533-540. http://dx.doi.org/10.1007/978-3-540-78246-9_63
- 17. Xu, Z., Fu, Y., Mao, J. and Su, D. (2006) Towards the Semantic Web: Collaborative Tag Suggestions. Proceedings of the Collaborative Web Tagging Workshop at WWW, Edinburgh, 23-26 May 2006, 1-8.
- 18. Koren, Y. (2010) Collaborative Filtering with Temporal Dynamics. Communications of the ACM, 53, 89-97.http://dx.doi.org/10.1145/1721654.1721677
- 19. Gueye, M., Abdessalem, T. and Naacke, H. (2014) A Parameter-Free Algorithm for an Optimized Tag Recommendation List Size. Proceedings of the 8th ACM Conference on Recommender Systems, ACM Press, New York, 233-240.
- 20. Gueye, M., Abdessalem, T. and Naacke, H. (2013) An Efficient Trust-and Popularity-Based Tag Recommender.
- 21. Ifada, N. and Nayak, R. (2015) Do-Rank: DCG Optimization for Learning-to-Rank in Tag-Based Item Recommendation Systems. In: Cao, T., Lim, E.-P., Zhou, Z.-H., Ho, T.-B., Cheung, D. and Motoda, H., Eds., Advances in Knowledge Discovery and Data Mining, Springer International Publishing, Berlin Heidelberg, 510-521.
http://dx.doi.org/10.1007/978-3-319-18032-8_40 - 22. Wetzker, R., Zimmermann, C. and Bauckhage, C. (2008) Analyzing Social Bookmarking Systems: A Delicious Cookbook. Proceedings of the ECAI 2008 Mining Social Data Workshop, IOS Press, Amsterdam, 26-30.