Journal of Mathematical Finance
Vol. 3 No. 1A (2013) , Article ID: 29274 , 12 pages DOI:10.4236/jmf.2013.31A015
Uses and Misuses of the Black-Litterman Model in Portfolio Construction*
1School of Management, University of San Francisco, San Francisco, USA
2Department of Economics, Konkuk University, Seoul, Korea
Email: chincarinil@hotmail.com, kimdaewan@hotmail.com
Received December 19, 2012; revised January 22, 2013; accepted February 6, 2013
Keywords: Black-Litterman; Bayes Rule; Portfolio Construction; Econometric Techniques; Simulations
ABSTRACT
The Black-Litterman model has gained popularity in applications in the area of quantitative equity portfolio management. Unfortunately, many recent applications of the Black-Litterman to novel aspects of quantitative portfolio management have neglected the rigor of the original Black-Litterman modelling. In this article, we critically examine some of these applications from a Bayesian perspective. We identify three reasons why these applications may create losses to investors. These three reasons are: 1) Using a prior without “anchoring” the prior to an equilibrium model; 2) Using a prior and an equilibrium model that conflict with one another; and 3) Ignoring the implications of the estimation error of the variance-covariance matrix. We also quantify the loss first analytically and also numerically based on historical data on 10 major world stock market indices. Our conservative estimate of the loss is around a 1% reduction in the annualized return of the portfolio.
1. Introduction
The Black-Litterman model is a powerful tool in the portfolio construction process. It has gained popularity among practitioners for the past two decades, and its applications to various aspects of the portfolio construction process have been discussed in the literature. We believe, however, that some of the applications adopted by practitioners and discussed in the literature deserve more critical examination. In this paper, we will highlight the uses of the Black Litterman model that we find problematic, or at least lacking the vigor of the original formulation of the Black-Litterman model. We will present numerical examples to make our case stronger and, where appropriate, will propose alternative approaches.
Black and Litterman [1,2] saw two strengths of their approach:
1) The subjective views of the investors can be easily incorporated in the portfolio construction process.
2) The Black-Litterman mean-variance optimization does not produce unreasonable solutions, as the standard mean-variance framework does.
The first of these two comes from the feature of the model that investors’ subjective views are expressed as linear combinations of expected returns of assets, rather than as expected returns of individual assets. That is, the subjective view need not be an exact value of the expected return of an individual asset, but rather can be expressed as the expected return of two assets or more in relation to each other. This type of formulation is easier for investors to apply. The second strength comes from the model’s feature that the investors’ subjective views are combined with an equilibrium model that tilts the portfolio weights away from the market capitalization weights based on the relative uncertainty in the investor’s views. This anchors the portfolio weights towards the implied market capitalization weights, thus not allowing for extreme weights due to differences in expected returns.
Out of these two features, the first feature is less essential to the Black-Litterman model. It is relatively easy to come up with an alternative way of specifying investors’ subjective views.1 The spirit of the Black Litterman model can be retained from a variety of subjective prior specifications. The second feature, however, is much more significant. An attempt to modify this feature of the model is likely to introduce inconsistencies. The reason is that there is really only one right way to combine investors’ subjective views with a given model, and there is no other correct alternative. One may choose different views or different models, but once the views and a model are chosen, there is only one way to combine them according to Bayes’ rule.
Some applications of the Black-Litterman model by other authors have attempted to modify the second feature of the model, and, in doing so, they have lost the mathematical rigor of the original Black-Litterman model. Other applications have simply ignored the nature of the subjective view and mixed it up with the model in an inconsistent manner.
In this paper we discuss three representative (mis-) uses of the Black-Litterman model in portfolio construction. We will attempt to quantify the possible losses created by the misuse of the model and, where appropriate, propose an alternative.2 The first application we consider was discussed in Jones, Lim, and Zangari [4].3 We will argue that their approach could create a loss to investors because the prior is not “anchored” to an equilibrium model. More specifically, the estimate of the mean return from the model is not included in the process, making the prediction of the mean return less than optimal. The second application we consider was discussed in Fabbozi, Forcardi, and Kolm [5]. We will argue that their approach could create losses to investors if the prior and the equilibrium model conflict each other. The third application we consider is the so called reverse optimization, which is quite popular among practitioners. We will argue that this reverse optimization could have surprisingly large errors in the resulting mean estimates.
In this article, we take a Bayesian perspective. A Bayesian perspective allows us to quantify the losses of investors without too many complications in the analysis. We borrow the framework of Satchell and Scowcroft [6], and extend it so that investors’ loss can be discussed.
The paper is organized as follows: Section 2 discusses the use of the Black-Litterman technique without an equilibrium model, and the potential losses associated with that methodology; Section 3 discusses the use of the Black-Litterman model with data based priors that conflict with the model, and the loss associated with that methodology; Section 4 discusses the use of the BlackLitterman approach as a reverse optimization and the implication of using an estimated variance-covariance matrix; and Section 5 concludes the paper.
2. Using the Black Litterman Approach without an Equilibrium Model
2.1. How It Is Usually Done
Jones, Lim, and Zangari (2007; henceafter JLZ) presented a way in which the Black Litterman model can be used to incorporate a factor-based view in a structured equity portfolio.
Let 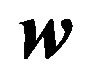 be an
be an 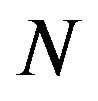 -dimensional portfolio weight vector, where the
-dimensional portfolio weight vector, where the 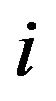 -th element
-th element 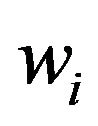 is the portfolio weight of asset
is the portfolio weight of asset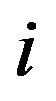 . Let
. Let  be an
be an 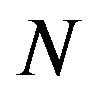 -by-
-by-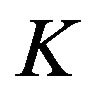 factor exposure matrix, where
factor exposure matrix, where 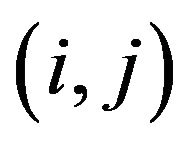 element
element 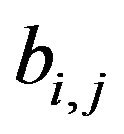 is the exposure of stock
is the exposure of stock 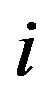 to factor
to factor .4 Then the factor exposure of the portfolio is
.4 Then the factor exposure of the portfolio is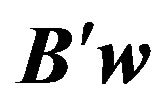 . A portfolio manager’s factor view can be expressed as a
. A portfolio manager’s factor view can be expressed as a 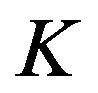 -dimensional vector
-dimensional vector , which is the portfolio manager’s desired value of
, which is the portfolio manager’s desired value of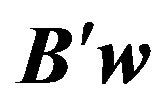 .5 JLZ suggest the following steps for the portfolio construction:
.5 JLZ suggest the following steps for the portfolio construction:
1) Specify the factor view vector .
.
2) Calculate the optimal tilt portfolio weight, i.e. the weight of the portfolio that is optimal given the factor view vector. That is, solve:
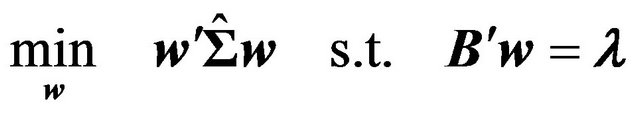 (1)
(1)
where  is an
is an 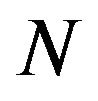 -by-
-by-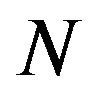 variance-covariance matrix estimate of asset returns. The solution to this problem is
variance-covariance matrix estimate of asset returns. The solution to this problem is
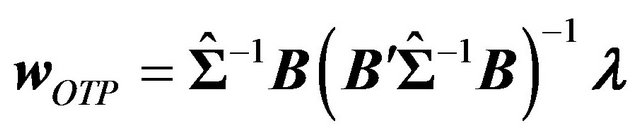 (2)
(2)
where OTP is an acronym for optimal tilt portfolio.6
3) Compute the Black Litterman alpha, i.e. the expected return that produces the optimal tilt portfolio identified in the previous step. That is, solve the following equation for :
:
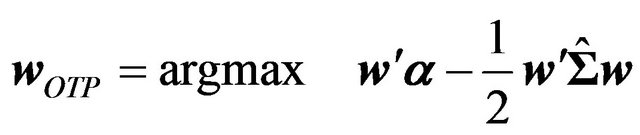 (3)
(3)
The solution to this problem is7
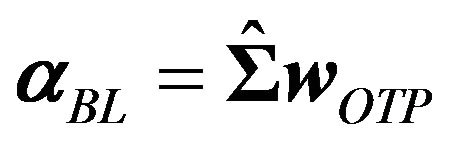 (4)
(4)
4) Find an optimal portfolio based on the Black Litterman alpha, 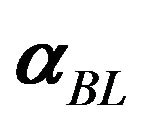 , and any other constraints using a standard mean variance optimization. For example, an optimal portfolio can be found by solving the following quadratic programming problem:
, and any other constraints using a standard mean variance optimization. For example, an optimal portfolio can be found by solving the following quadratic programming problem:
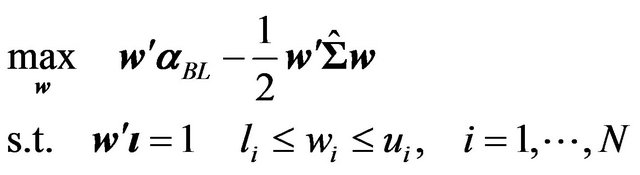 (5)
(5)
where 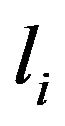 and
and 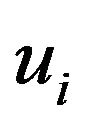 are lower and upper bounds on asset
are lower and upper bounds on asset 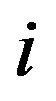 weights.8
weights.8
In the four step procedure described above, no explicit reference is made to an equilibrium model, which is an integral component of the original Black-Litterman model. In fact, there is no explicit reference to any model of stock returns.
Implicitly, though, the above procedure requires a model to produce an estimate . Even when one decides to use a historical variance-covariance matrix for
. Even when one decides to use a historical variance-covariance matrix for , one is using a model. The implicit model is that the historical variance-covariance matrix is a good estimator of the true variance-covariance matrix.
, one is using a model. The implicit model is that the historical variance-covariance matrix is a good estimator of the true variance-covariance matrix.
Using a model to produce an estimate  and using the estimate in calculating the Black Litterman alpha,
and using the estimate in calculating the Black Litterman alpha, 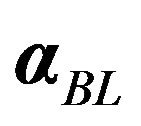 , however, is not equivalent to “combining a subjective view with an equilibrium model” as is done in the original Black Litterman model. The problem with this approach is that the model is used only to produce an estimate of the variance-covariance matrix. This approach ignores the information in the data about the mean return.9 The consequence is that a subjective view is combined with a model, but only partially and incompletely. The incompleteness does create a problem, as will be shown in the next sub-section.
, however, is not equivalent to “combining a subjective view with an equilibrium model” as is done in the original Black Litterman model. The problem with this approach is that the model is used only to produce an estimate of the variance-covariance matrix. This approach ignores the information in the data about the mean return.9 The consequence is that a subjective view is combined with a model, but only partially and incompletely. The incompleteness does create a problem, as will be shown in the next sub-section.
2.2. The Cost of Ignoring Mean Estimates
The JLZ procedure calculates the Black Litterman alpha, 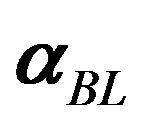 , based on a view and a model. The view is summarized in
, based on a view and a model. The view is summarized in  and the model is summarized in an estimate of
and the model is summarized in an estimate of . As mentioned above, however, the view and the model are not combined in an efficient way. In particular, the mean component of the model is ignored. This creates some loss, the magnitude of which we will quantify in this subsection.
. As mentioned above, however, the view and the model are not combined in an efficient way. In particular, the mean component of the model is ignored. This creates some loss, the magnitude of which we will quantify in this subsection.
We first discuss our measures of loss. In order to measure an investor’s loss, we need to develop a formal model of returns and investor views. In the subsequent text, we discuss a measure of loss based upon a formal model of returns and views.
2.2.1. A Measure of Loss
One can quantify the loss generated in a portfolio construction process in terms of the Sharpe ratio, the information ratio, or an investor’s utility. For the purpose at hand, the most natural choice is to use the investor’s utility implicit in the Black Litterman approach, which is
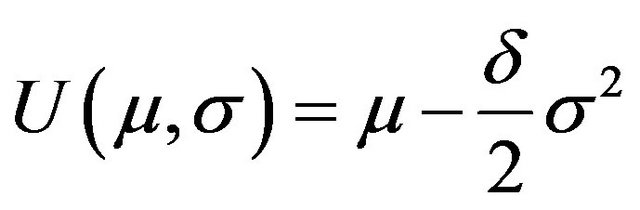 (6)
(6)
where 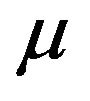 is the mean return of the portfolio and
is the mean return of the portfolio and  is the standard deviation of the portfolio return. In particular, we will set the value of
is the standard deviation of the portfolio return. In particular, we will set the value of 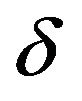 to
to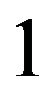 , as was done in the JLZ procedure.10 Given the utility function, we can calculate the highest utility one can achieve given the model and the view, and we can also calculate the utility that one actually achieves. The difference is our measure of the loss.
, as was done in the JLZ procedure.10 Given the utility function, we can calculate the highest utility one can achieve given the model and the view, and we can also calculate the utility that one actually achieves. The difference is our measure of the loss.
To compute the utility, we will use the predictive mean and variance based on the model and the view. This is justified as our primary interest is in the investor’s portfolio construction strategy, not the validity of the investor’s belief. In addition to this, the predictive mean and variance are the only mean and variance that the investor can actually calculate. It would not make sense to define the investor’s utility in terms of the quantities that are not known to the investor.11
If a portfolio construction process combines the model and the view efficiently, then by construction the loss is zero. This is true in the original Black Litterman approach. It is not possible to improve the utility given the model and the view. In the JLZ procedure, however, it is possible to improve the utility given the model and the view. It is possible to do so by adding the mean component of the model, as we will show below.
2.2.2. The Model and the View
Consider the following model:
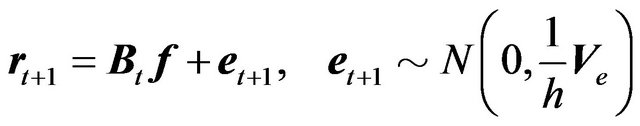 (7)
(7)
where 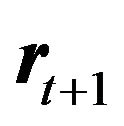 represents the vector of stock returns,
represents the vector of stock returns, 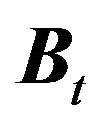 represents the
represents the 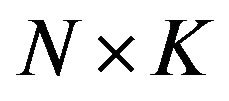 matrix of factor exposures for
matrix of factor exposures for 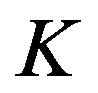 factors and
factors and 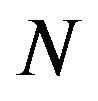 stocks, and
stocks, and  is a
is a 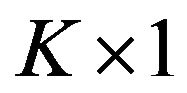 vector of factor premiums,
vector of factor premiums, 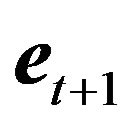 is the error vector, and
is the error vector, and 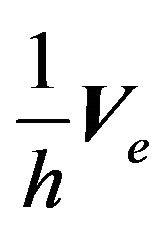 is the covariance matrix of the error. We include a scalar
is the covariance matrix of the error. We include a scalar 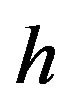 that affects the overall volatility of the market.
that affects the overall volatility of the market.
While this model is not explicitly stated in the four step procedure outlined in the previous section, this is probably the most natural model for the JLZ investor, if he were forced to adopt one. (Recall that the lack of an explicit model is one weakness of the JLZ procedure.) Without a model of this kind, it would be hard to motivate a factor tilted portfolio using the JLZ procedure.12
The variables 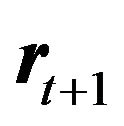 and
and 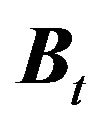 are observable, while
are observable, while 
and 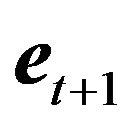 are not observable. The error variance
are not observable. The error variance 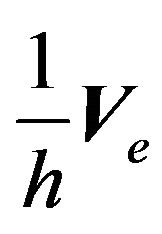 is not known either. Before creating a portfolio for
is not known either. Before creating a portfolio for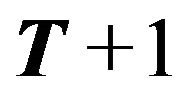 , the investor observes
, the investor observes 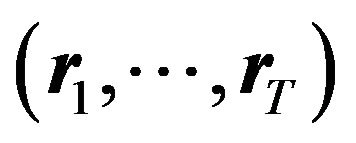 and
and 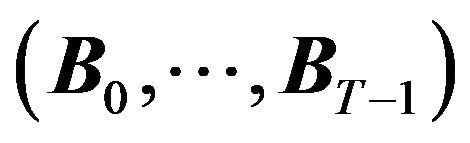 and also
and also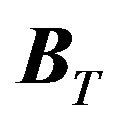 . With these data, the investor must determine the distribution of
. With these data, the investor must determine the distribution of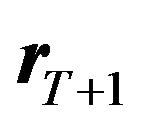 , by estimating
, by estimating ,
, 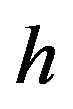 , and
, and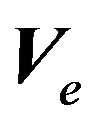 , or by updating his belief about these quantities.
, or by updating his belief about these quantities.
The JLZ procedure introduced  to capture the investor’s belief.
to capture the investor’s belief.  is the desired tilt to specific factors, which depends on the investor’s belief about factor returns. Rather than consider the prior of (i.e. distribution of possible values of)
is the desired tilt to specific factors, which depends on the investor’s belief about factor returns. Rather than consider the prior of (i.e. distribution of possible values of) , we consider the prior of factor returns. While this approach may seem like an unnecessary detour, it makes the analysis much more tractable.
, we consider the prior of factor returns. While this approach may seem like an unnecessary detour, it makes the analysis much more tractable.
We interpret  in the context of the following prior of
in the context of the following prior of  and
and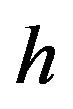 :
:
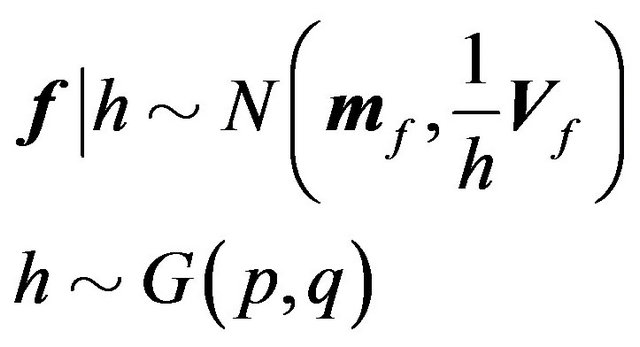 (8)
(8)
That is,  has a multivariate normal distribution conditional on
has a multivariate normal distribution conditional on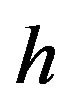 , and
, and 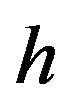 has a Gamma distribution.13
has a Gamma distribution.13
By including 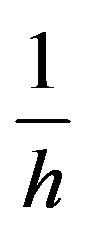 in the variance of
in the variance of , we are assuming that the overall uncertainty of the factor premium is proportional to the overall market volatility.14 This is the simplest prior one can adopt, and is general enough for our purpose. Satchell and Scowcroft (2000) also use this prior when they interpret the Black Litterman model. Note also that this prior allows for the noninformative prior as a special case, as will be shown in the next section.
, we are assuming that the overall uncertainty of the factor premium is proportional to the overall market volatility.14 This is the simplest prior one can adopt, and is general enough for our purpose. Satchell and Scowcroft (2000) also use this prior when they interpret the Black Litterman model. Note also that this prior allows for the noninformative prior as a special case, as will be shown in the next section.
It is easy to show that  is related to the parameters in Equations (7) and (8) in the following way:
is related to the parameters in Equations (7) and (8) in the following way:
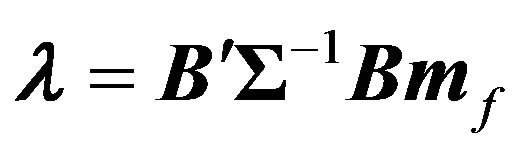 (9)
(9)
where 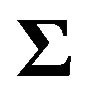 is the variance-covariance matrix of
is the variance-covariance matrix of , i.e.,
, i.e.,
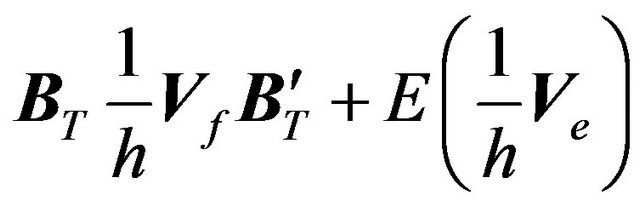 .15
.15
Equation (7) represents the model, and Equation (8) represents the investor’s view. And together, they describe the belief system of the JLZ investor completely.
Let us be clear about our distinction between the model and the view. The model specifies the relationship among variables that we observe. The view is about the quantities that we do not observe. In particular, the view specifies the relationship among parameters of the model. The view has hyper-parameters, whose values investors choose on their own. In Equation (7), there are three parameters: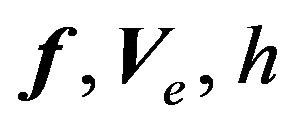 . In Equation (8), there are four hyper-parameters:
. In Equation (8), there are four hyper-parameters: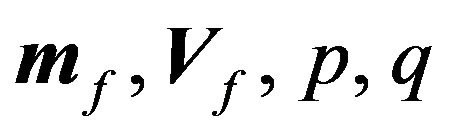 . The distinction between the parameters and the hyper-parameters can be made clearly: parameters are a part of the model, while hyper-parameters are a part of the view.
. The distinction between the parameters and the hyper-parameters can be made clearly: parameters are a part of the model, while hyper-parameters are a part of the view.
These concepts might be clearer if we describe them in a series of steps.
1) All the equations are known to everyone;
2) At the beginning of our portfolio formulation stage, God decides the value of the hyper-parameters 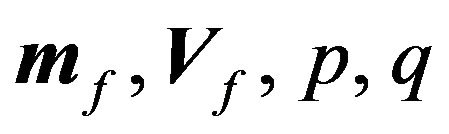 . God announces this decision to every investor;
. God announces this decision to every investor;
3) On day 1, God draws parameters 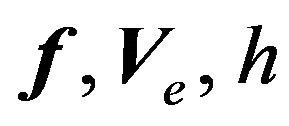 using Equation (8). These quantities are never known to the investor;
using Equation (8). These quantities are never known to the investor;
4) On day 2, God draws data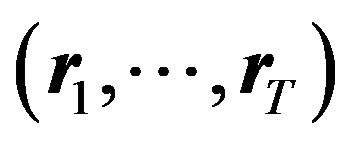 ,
, 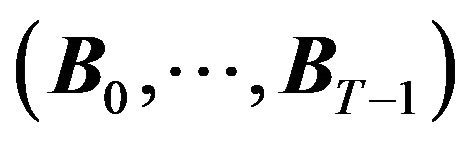 , and also
, and also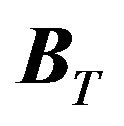 , and shows them to the investor;16
, and shows them to the investor;16
5) After observing data, the investor estimates the parameters, makes a prediction of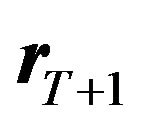 , and creates a portfolio;
, and creates a portfolio;
6) On day 3, God draws 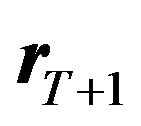 using Equation (7);
using Equation (7);
7) After observing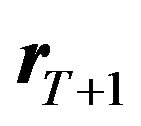 , the investor calculates his portfolio return.
, the investor calculates his portfolio return.
In this scheme, one could think of a number of different expectations and variances of the portfolio return. Let us consider three of them. First, we can think of “God’s expectation,” which is conditional on the true value of parameters ,
, 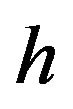 , and
, and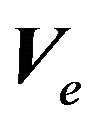 . Since only God knows the value of
. Since only God knows the value of ,
, 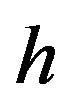 , and
, and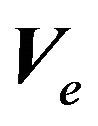 , this expectation is probably not very interesting to our hypothetical investor. Second, we can think of the “predictive expectation,” which is conditional on the data as well as on the hyperparameters, but not on the true value of the parameters. That is, it is the expectation based on the investor’s best prediction given the information available. This is something rational investors can calculate. Third, we can think of “an economist’s expectation,” which is conditional only on the hyper-parameters
, this expectation is probably not very interesting to our hypothetical investor. Second, we can think of the “predictive expectation,” which is conditional on the data as well as on the hyperparameters, but not on the true value of the parameters. That is, it is the expectation based on the investor’s best prediction given the information available. This is something rational investors can calculate. Third, we can think of “an economist’s expectation,” which is conditional only on the hyper-parameters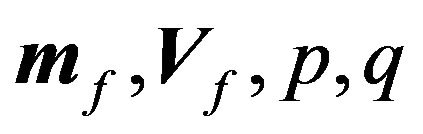 . This is the expectation one obtains by imagining many different worlds where different parameters could have been chosen from the same hyper-parameters. To investors who live only once, this concept is not particularly interesting. Their utility does not depend on what could have happened in other worlds. This concept, however, could be interesting to economists who want to make general statements about certain decision making schemes. Note also that “an economist’s expectation” is obtained if we integrate the data out of the “predictive expectation.”17
. This is the expectation one obtains by imagining many different worlds where different parameters could have been chosen from the same hyper-parameters. To investors who live only once, this concept is not particularly interesting. Their utility does not depend on what could have happened in other worlds. This concept, however, could be interesting to economists who want to make general statements about certain decision making schemes. Note also that “an economist’s expectation” is obtained if we integrate the data out of the “predictive expectation.”17
Our analysis is based on the “predictive expectation” and similar concepts, as we are working with a utilitybased measure of loss. Predictive expectation is conditional on the value of the hyper-parameters. Thus, an analysis of predictive expectation can be influenced by the choice of hyper-parameter values. In our numerical analysis, we vary the values of the hyper-parameters to make sure that our results are robust, and that they are not peculiar to the chosen values of the hyper-parameters.
We provide the formula for the predictive mean and the predictive variance-covariance matrix of the returns here without proof.18 The predictive mean and the predictive variance-covariance matrix of returns are obtained by applying statistical operators to the model and then using the Bayesian updating formula (see Zellner [7] and Koop [8]). Let us denote the predictive mean of the return as 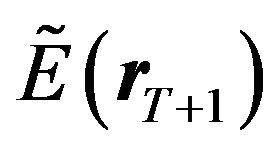 and the predictive variance-covariance matrix of the return as
and the predictive variance-covariance matrix of the return as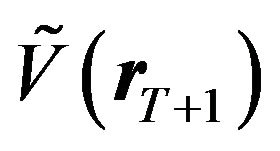 . Then
. Then
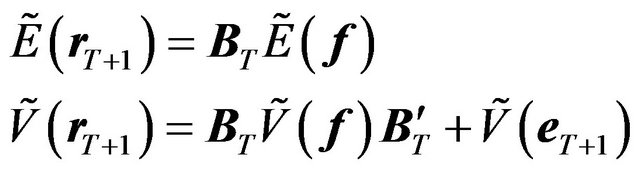 (14)
(14)
The predictive mean of the factor premium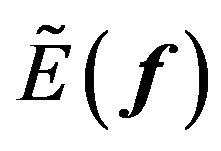 , the predictive variance-covariance matrix of the factor premium
, the predictive variance-covariance matrix of the factor premium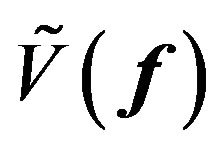 , and the predictive variance-covariance matrix of the error
, and the predictive variance-covariance matrix of the error 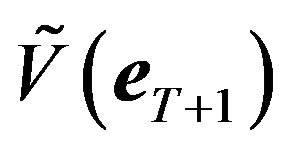 are determined by the Bayesian updating formula:
are determined by the Bayesian updating formula:
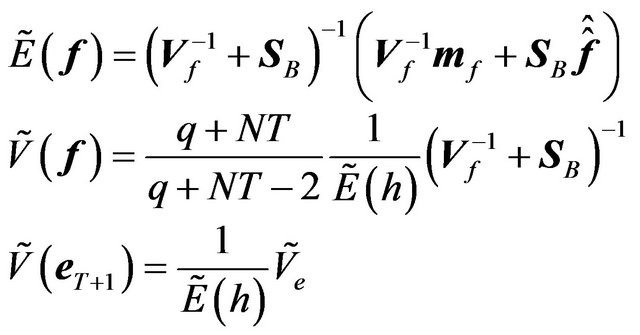 (15)
(15)
The first equation simply says that the predictive mean of the factor premium is a “precision-weighted” average of the prior mean 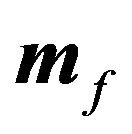 and the GLS estimator
and the GLS estimator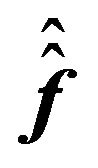 . The second and the third equation simply break down the components of the variance-covariance matrix. The predictive mean of the error precision parameter
. The second and the third equation simply break down the components of the variance-covariance matrix. The predictive mean of the error precision parameter 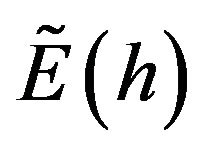 can be expressed as follows:19
can be expressed as follows:19
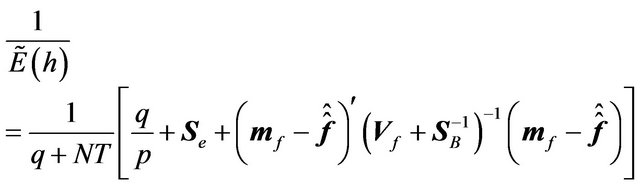 (16)
(16)
2.2.3. An Analytic Formula for Loss
Now we are ready to compare the utility of an investor who follows the JLZ procedure (the JLZ investor) to the utility of a rational investor who combines all information efficiently (the RTL investor), both having the same view and the same model. We first discuss the utility of the two investors in general form. Then we examine a special case where we can provide an analytic solution for loss.
Let us first characterize the utility of the RTL investor. As noted before, the investor would not consider 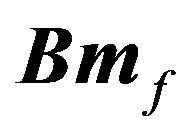 to be the best estimate of the mean return, nor would he consider the Black Litterman alpha implied by the optimal tilted portfolio to be the best estimate of the mean return. Using the Black Litterman alpha would be equivalent to not using any information from the estimation about the mean return. Instead, the RTL investor would estimate the mean and the variance-covariance matrix of returns using all the information available, and then choose a portfolio based on these estimates.
to be the best estimate of the mean return, nor would he consider the Black Litterman alpha implied by the optimal tilted portfolio to be the best estimate of the mean return. Using the Black Litterman alpha would be equivalent to not using any information from the estimation about the mean return. Instead, the RTL investor would estimate the mean and the variance-covariance matrix of returns using all the information available, and then choose a portfolio based on these estimates.
The best estimates of the mean and of the variancecovariance matrix of the returns are the predictive mean and the predictive variance-covariance matrix described above. Given the predictive mean and the predictive variance-covariance matrix of the return, the rational investor will choose the portfolio by solving the optimization problem comparable to Equation (5). Then his utility is determined as:20
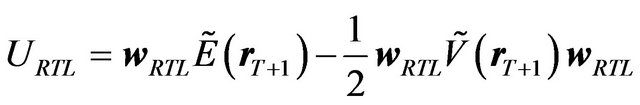 (17)
(17)
where
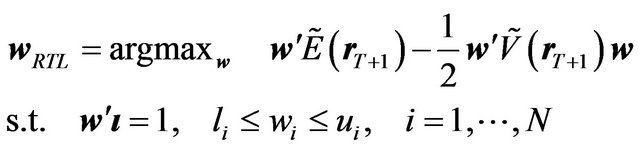 (18)
(18)
Now let us consider the utility of the JLZ investor. The JLZ investor would follow the four steps specified in the previous section. Thus, her portfolio is the solution to Equation (5), and her utility is determined from the mean and the variance of her portfolio. That is,
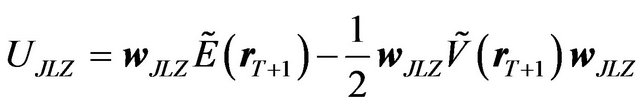 (19)
(19)
where
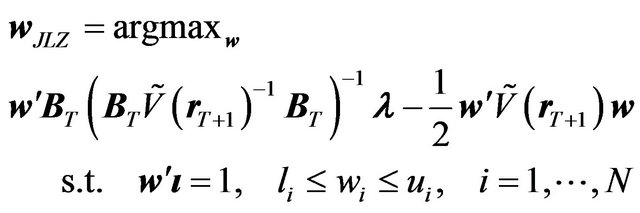 (20)
(20)
Computation of the loss based on the above utility can be done numerically, which we explain in the next subsection. For now, we will present an analytic solution for the special case where there are no constraints in the optimization. Although, this is not a realistic way of constructing an optimal portfolio, it will help illustrate some key concepts.
Let us start with the rational investor. When there are no constraints, the solution to the optimization problem in Equation (18) is simply
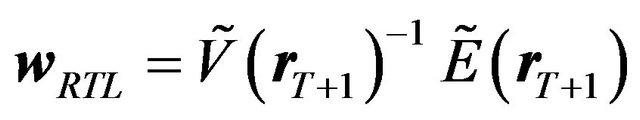 (21)
(21)
Then the utility is given by
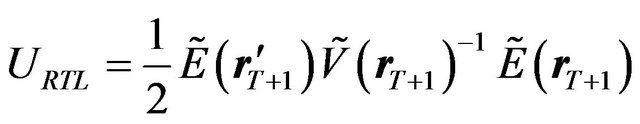 (22)
(22)
Now let us calculate the utility of the JLZ investor. When there are no constraints, the portfolio of the JLZ investor is simply the optimal tilted portfolio of Equation (2). Combining Equation (2) and Equation (9), we get
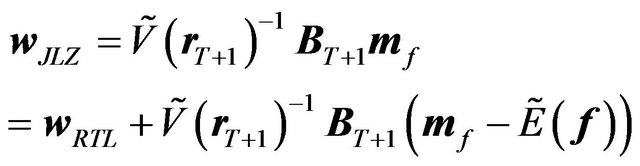 (23)
(23)
Note that we made one simplifying assumption to get the above formula. Firstly, we assumed that the JLZ investor’s covariance estimate of returns  is identical to the rational investor’s covariance estimate of returns
is identical to the rational investor’s covariance estimate of returns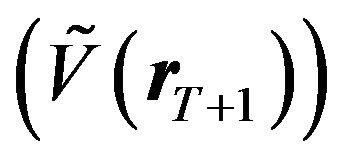 . Since we did not specify how the JLZ investor obtains
. Since we did not specify how the JLZ investor obtains , we chose the one that was the best and most advantageous to the JLZ investor. In other words, by doing this we eliminated one mistake that the JLZ investor made, i.e. using an inferior estimate of the error covariance.
, we chose the one that was the best and most advantageous to the JLZ investor. In other words, by doing this we eliminated one mistake that the JLZ investor made, i.e. using an inferior estimate of the error covariance.
Now we can express the utility of the JLZ investor in the following way:
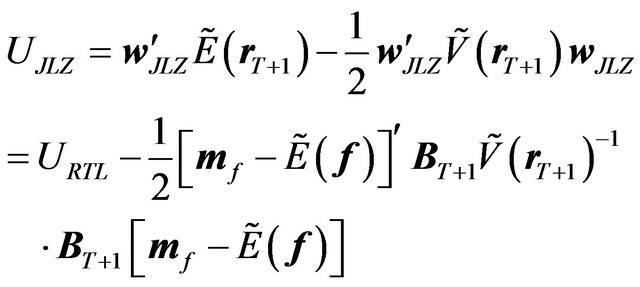 (24)
(24)
The above formula shows that the difference in utility between the JLZ investor and the RTL investor, i.e. the loss, is quadratic in the difference between the prior mean and the posterior mean of the factor premium. This can be understood intuitively. When one ignores the mean estimates, the portfolio weights deviate from the optimal weights and the deviation is linear in the difference between the prior mean and the posterior mean. The utility, however, depends on the second moments of the portfolio returns, so the loss is quadratic in the difference between the prior mean and the posterior mean.
2.2.4. Investor Simulations
In order to quantify the losses from an incorrect procedure, we perform a numerical simulation.
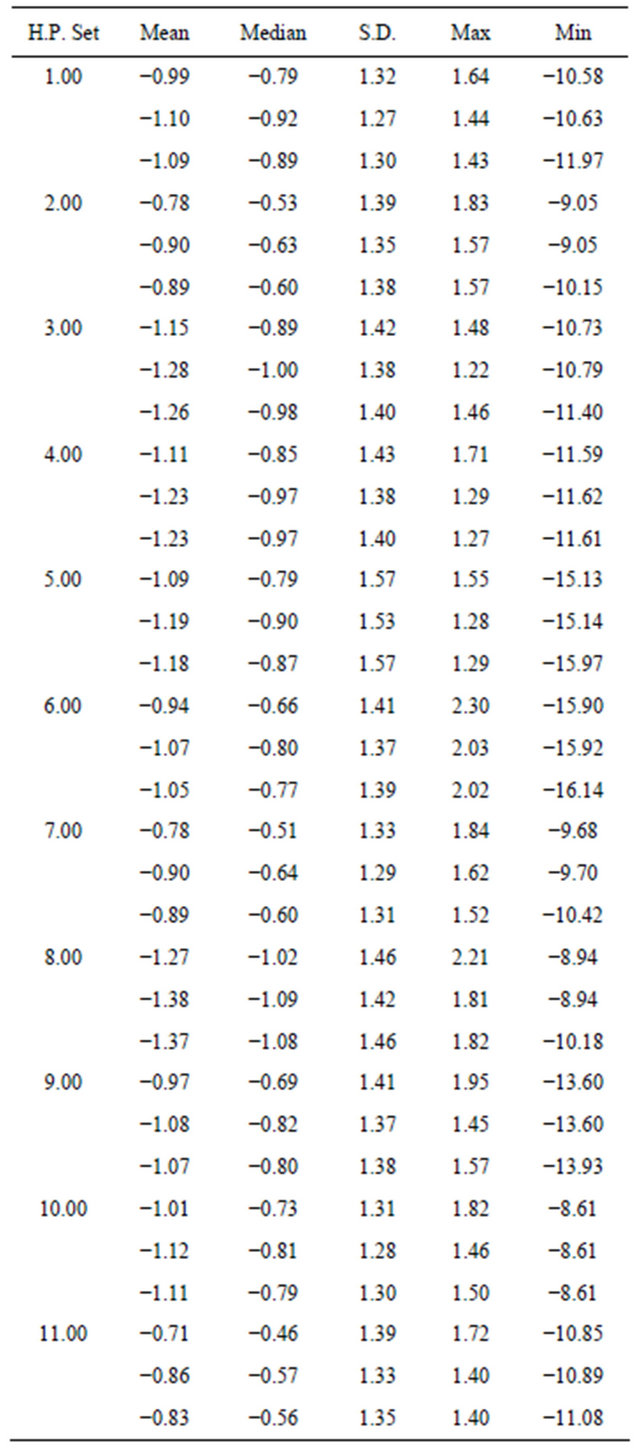
The simulation is based on the monthly returns and other characteristics of the MSCI country indices.21 Specifically, we select the top 10 countries by market capitalization. We used the price-to-earnings ratio, 6 months momentum return, and the market capitalization of the indices as factors in our factor model. Our data set spans the 7-year period from September 2001 to August 2008. The summary statistics of the variables for each country are presented in Table 1.
For the simulation, we use the Chi-square distribution for the error precision parameter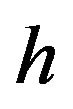 . The Chi-square distribution is a special case of the Gamma distribution, and all the formulas presented above are still applicable. The model and the prior now look as follows:
. The Chi-square distribution is a special case of the Gamma distribution, and all the formulas presented above are still applicable. The model and the prior now look as follows:
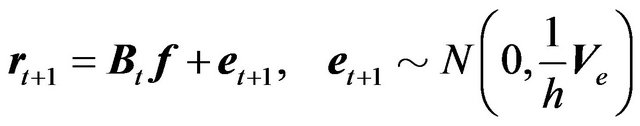 (25)
(25)
and
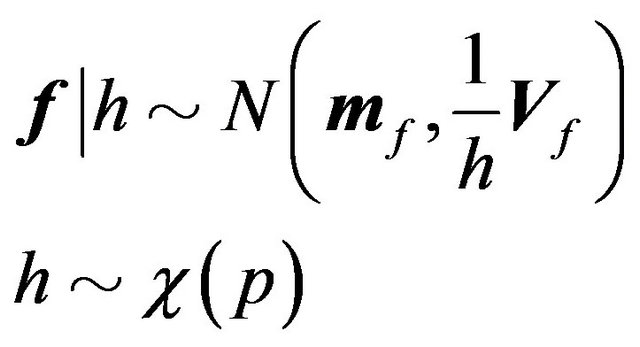 (26)
(26)
The simulation proceeds according to the following steps.22
1) We choose a reasonable value for the hyper parameters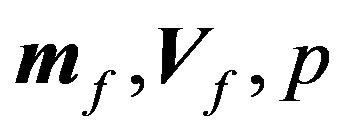 ;
;
2) We draw a single value of parameters  and
and 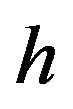 using the hyper parameters above. We use the OLS estimator for the remaining parameter
using the hyper parameters above. We use the OLS estimator for the remaining parameter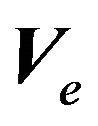 ;
;
3) We draw 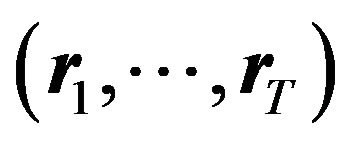 from the parameters determined above. For the factor exposures
from the parameters determined above. For the factor exposures 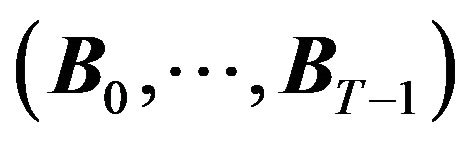 and
and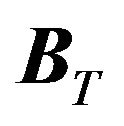 , we use historical values;
, we use historical values;
4) Given the values above, we determine the portfolio of the JLZ investor and the RTL investor;
5) We calculate the loss;
6) We repeat Steps 2 to 5 a 1000 times, without changing the hyper parameters. Then we obtain a distribution of losses, which will allow us to make general statements about the JLZ investor’s decision making process;
7) We repeat the above six steps by making small perturbations to the hyper parameter values.
The outcome of the simulations is summarized in Tables 2 and 3. A figure of the actual losses in 1000 simulations is shown in Figure 1. The magnitude of the loss is fairly stable across various sets of hyper parameter values. The mean loss is between 0.10 and 0.15, while the median loss is between 0.06 and 0.11. As the loss is the difference in the quadratic utility, we could interpret the loss as a reduction in the expected monthly return. That is, the loss of the JLZ investor amounts to about a 0.1% reduction in the expected monthly return. This would imply a fairly conservative estimate of the return loss as 1.2% annually.23
Table 1. Summary Statistics of Returns and Factor Exposures.
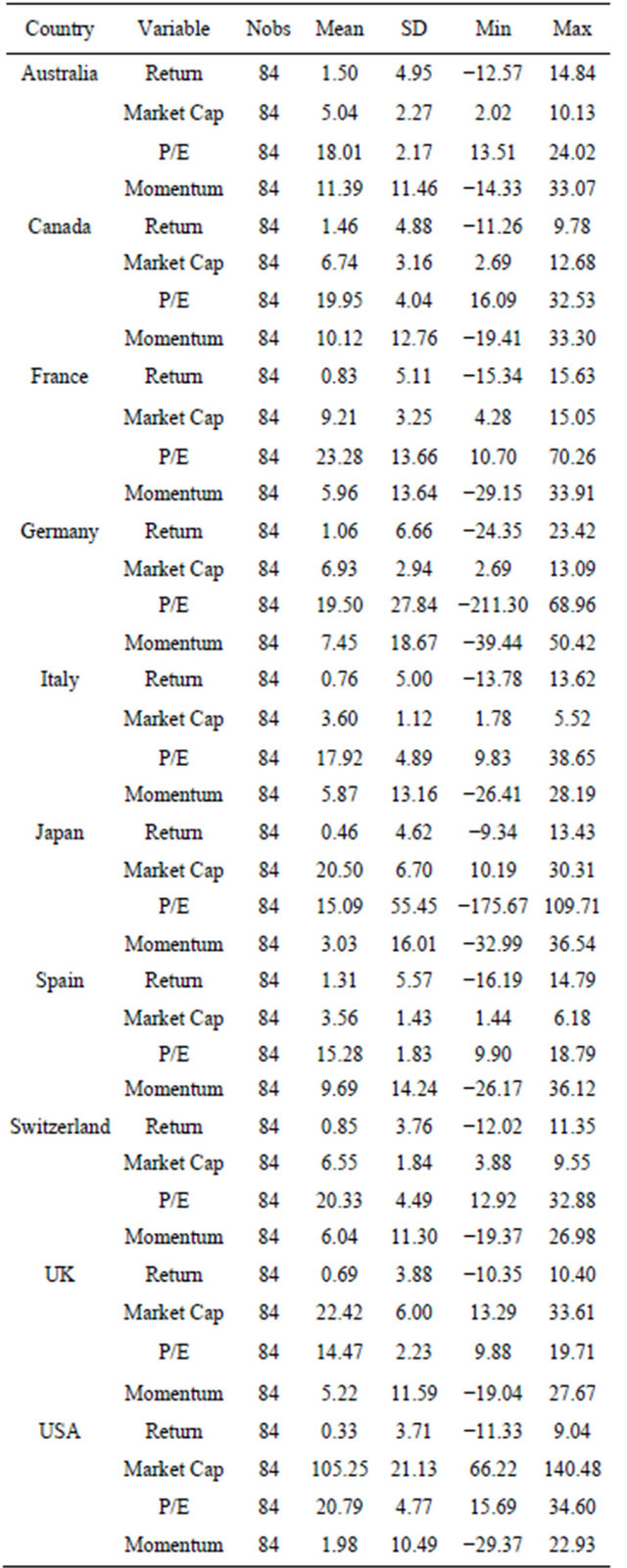
Note: Return is the monthly percentage return. Market cap is the market capitalization in hundred of billions of US dollars. P/E is the price-toearnings ratio as calculated by MSCI. Momentum is latest 6 month return.
Table 2. Utility of the JLZ, FFK, and Rational Investor from Various Values of 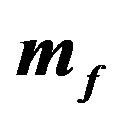 and
and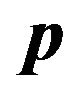 .
.
Note: The H.P. is for Hyper-Parameter set. Sets 1 - 11 alter the value of vector 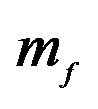 and
and 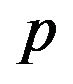 and as follows: [1 1 1 1 1; 1.1 1 1 1 1; 0.9 1 1 1 1; 1 1.1 1 1 1; 1 0.9 1 1 1; 1 1 1.1 1 1; 1 1 0.9 1 1; 1 1 1 1.1 1; 1 1 1 0.9 1; 1 1 1 1 0.9; 1 1 1 1 1.1]. Each set is separated by a semi-colon. For example, set 1 is the baseline case where
and as follows: [1 1 1 1 1; 1.1 1 1 1 1; 0.9 1 1 1 1; 1 1.1 1 1 1; 1 0.9 1 1 1; 1 1 1.1 1 1; 1 1 0.9 1 1; 1 1 1 1.1 1; 1 1 1 0.9 1; 1 1 1 1 0.9; 1 1 1 1 1.1]. Each set is separated by a semi-colon. For example, set 1 is the baseline case where 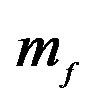 is not altered. Set 2 alters
is not altered. Set 2 alters 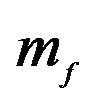 by multiplying the 2nd element of
by multiplying the 2nd element of 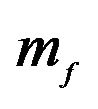 by 1.1 and so on and so forth. Each row in the table within each set represents the utility for a particular investor. The first row is Rational, the second row is the JLZ, and the third row is the FFK investor.
by 1.1 and so on and so forth. Each row in the table within each set represents the utility for a particular investor. The first row is Rational, the second row is the JLZ, and the third row is the FFK investor.
Table 3. Utility Losses to the JLZ and FFK Investors from Various Values of 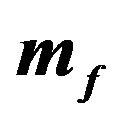 and
and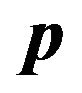 .
.
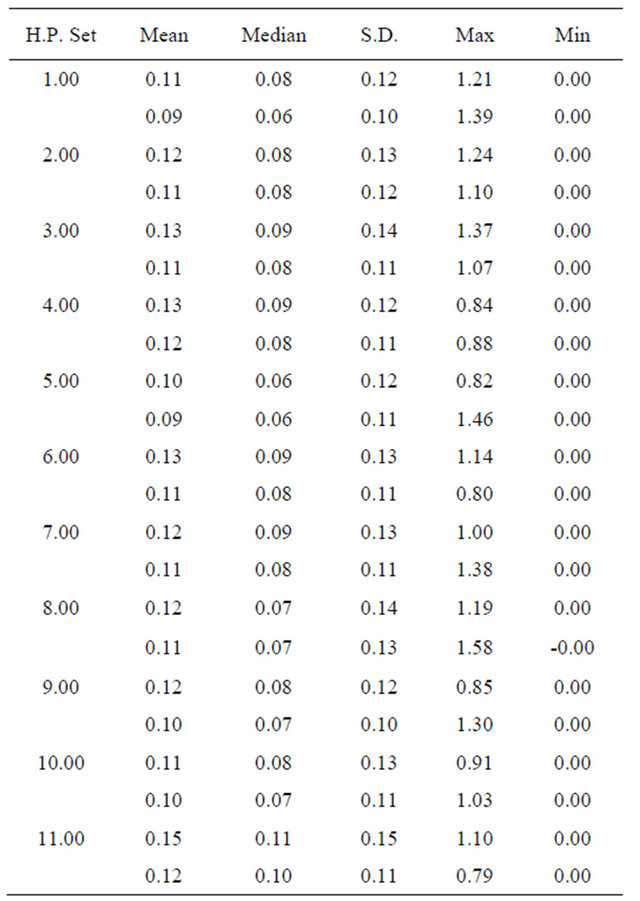
Note: The H.P. is for Hyper-Parameter set. Sets 1 - 11 alter the value of vector 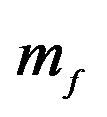 and
and 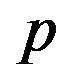 and as follows: [1 1 1 1 1; 1.1 1 1 1 1; 0.9 1 1 1 1; 1 1.1 1 1 1; 1 0.9 1 1 1; 1 1 1.1 1 1; 1 1 0.9 1 1; 1 1 1 1.1 1; 1 1 1 0.9 1; 1 1 1 1 0.9; 1 1 1 1 1.1]. Each set is separated by a semi-colon. For example, set 1 is the baseline case where
and as follows: [1 1 1 1 1; 1.1 1 1 1 1; 0.9 1 1 1 1; 1 1.1 1 1 1; 1 0.9 1 1 1; 1 1 1.1 1 1; 1 1 0.9 1 1; 1 1 1 1.1 1; 1 1 1 0.9 1; 1 1 1 1 0.9; 1 1 1 1 1.1]. Each set is separated by a semi-colon. For example, set 1 is the baseline case where 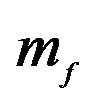 is not altered. Set 2 alters
is not altered. Set 2 alters 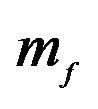 by multiplying the 2nd element of
by multiplying the 2nd element of 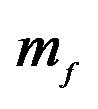 by 1.1 and so on and so forth. The first row represents the utility loss to the JLZ investor and the second row represents the utility loss to the FFK investor for each hyper parameter set.
by 1.1 and so on and so forth. The first row represents the utility loss to the JLZ investor and the second row represents the utility loss to the FFK investor for each hyper parameter set.
3. Using the Black-Litterman Approach with a Data Based Prior
3.1. How It Is Usually Done
Fabozzi, Forcardi, and Kolm (2006; henceafter FFK) suggested that one could incorporate a trading strategy, possibly based on a factor model, as a prior in the Black Litterman approach. The portfolio construction process might look as follows.24
1) Estimate the factor model that represents the portfolio manager’s belief, and specify the “prior” from the estimates of the model. Suppose that the factor model can be written in the following form
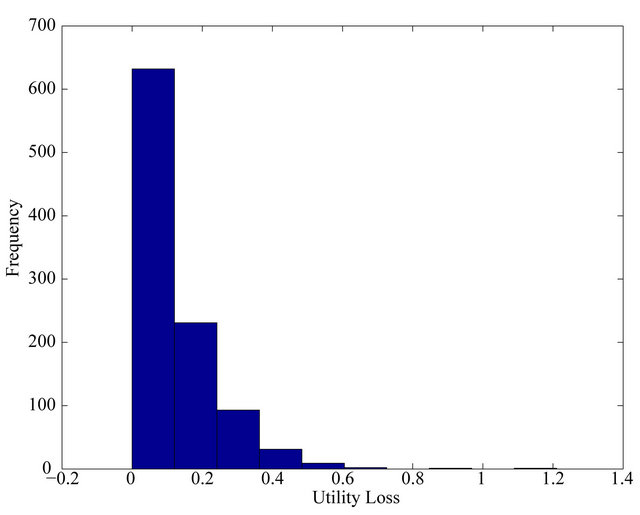
Figure 1. Utility Losses from 1000 Simulations for the JLZ Investor.
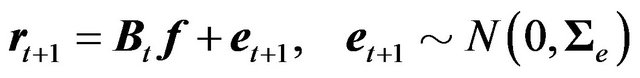 (27)
(27)
Given the estimate 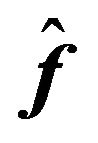 and
and , the “prior” for the mean of the future return,
, the “prior” for the mean of the future return, 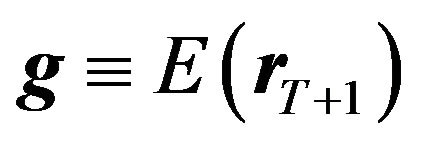 , can be specified as:25
, can be specified as:25
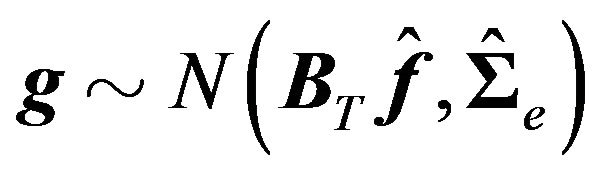 (28)
(28)
2) Let  be the estimate of the “equilibrium return” implied by the Capital Asset Pricing Model. Assume the following “model” for
be the estimate of the “equilibrium return” implied by the Capital Asset Pricing Model. Assume the following “model” for :
:
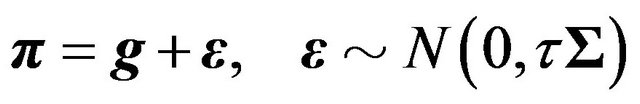 (29)
(29)
where 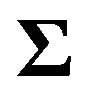 is the variance-covariance matrix of future returns, i.e.,
is the variance-covariance matrix of future returns, i.e., 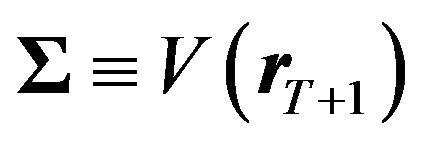 , and
, and  is a known constant. Note that
is a known constant. Note that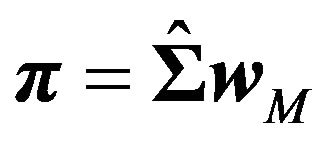 , where
, where  is an estimate of
is an estimate of .26 From this value of
.26 From this value of , one can get an estimate of
, one can get an estimate of 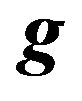 and also get a variance-covariance matrix estimate of the estimator:
and also get a variance-covariance matrix estimate of the estimator:
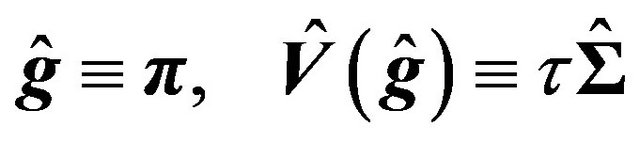 (30)
(30)
3) Combine the “prior” with the likelihood of the “model” according to Bayes rule. The posterior of the mean returns 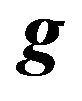 is specified by27
is specified by27
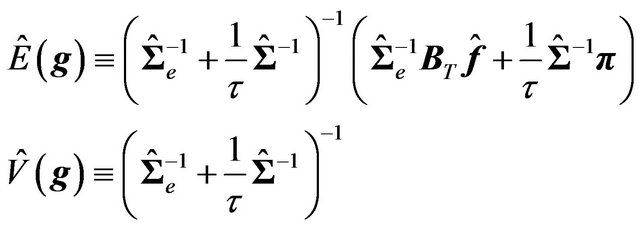 (31)
(31)
The posterior mean 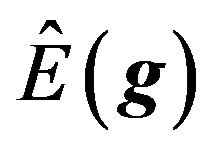 is sometimes referred to as the “Black Litterman alpha”.
is sometimes referred to as the “Black Litterman alpha”.
4) Find the optimal portfolio from a mean variance optimization using the posterior mean 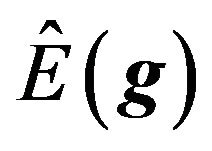 and the posterior variance-covariance matrix of stock returns
and the posterior variance-covariance matrix of stock returns .28 That is, solve
.28 That is, solve
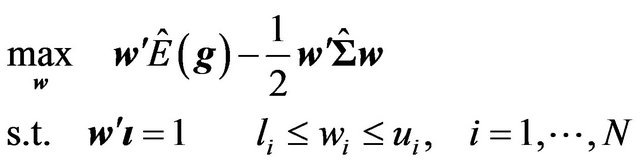 (32)
(32)
where 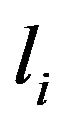 and
and 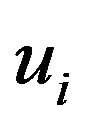 are lower and upper bounds on asset
are lower and upper bounds on asset 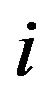 weight.
weight.
This procedure takes care of the problem identified in the previous section. The Black Litterman alpha is derived from an equilibrium model as well as from a prior. Information on the mean returns is not discarded, removing the potential for the type of loss identified in the previous section.
This procedure, however, introduces a new type of problem. It is based on two models that are contradictory to each other. The prior is built on the belief that a factor model is the underlying data generating process, while the likelihood is based on the belief that a CAPM is the underlying data generating process. Both beliefs cannot be true at the same time. As the procedure is based on two beliefs, the procedure cannot be optimal regardless of which belief is accurate.29 In the following subsection, we will show the magnitude of the loss arising from adopting this procedure.
3.2. The Cost of Using Contradictory Models
3.2.1. The Model and the View
We will assume that the factor model in Equation (27) is the true data generating process, and we will show that using the FFK procedure creates a loss. Our argument is independent of what the true model is.
In the previous section, we already discussed the factor model in Equation (27), a prior for this model, and the resulting predictive mean and the variance. The only difference is that in Equation (27) we have 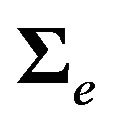 instead of
instead of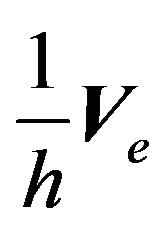 . We will also make one modification to the prior in this section. We will assume that the investor does not have any prior opinion. This modification not only makes the calculation much simpler, but it also makes our comparison more relevant. If we suppose that the investor who follows the FFK procedure has a certain prior opinion, then this investor is making twice as many mistakes. The first mistake is ignoring his prior opinion, and the second mistake is not using the factor model exclusively. Thus, by assuming that the investor does not have any prior opinion, we are eliminating one possible mistake that the investor could commit by following the FFK procedure.
. We will also make one modification to the prior in this section. We will assume that the investor does not have any prior opinion. This modification not only makes the calculation much simpler, but it also makes our comparison more relevant. If we suppose that the investor who follows the FFK procedure has a certain prior opinion, then this investor is making twice as many mistakes. The first mistake is ignoring his prior opinion, and the second mistake is not using the factor model exclusively. Thus, by assuming that the investor does not have any prior opinion, we are eliminating one possible mistake that the investor could commit by following the FFK procedure.
Formally, the non-informative prior can be expressed as
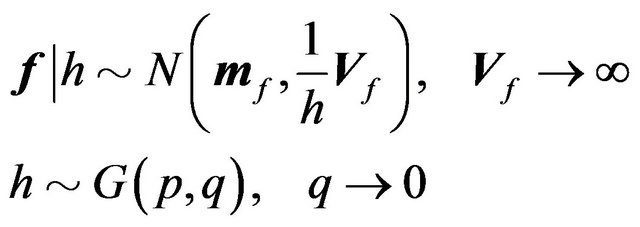 (33)
(33)
This is rather intuitive as it says that the noninformative prior is just the prior distribution of the factor premium as the variance of the factor premium converges to infinity. The formula for the posterior must be modified as well. The new formulae are:30
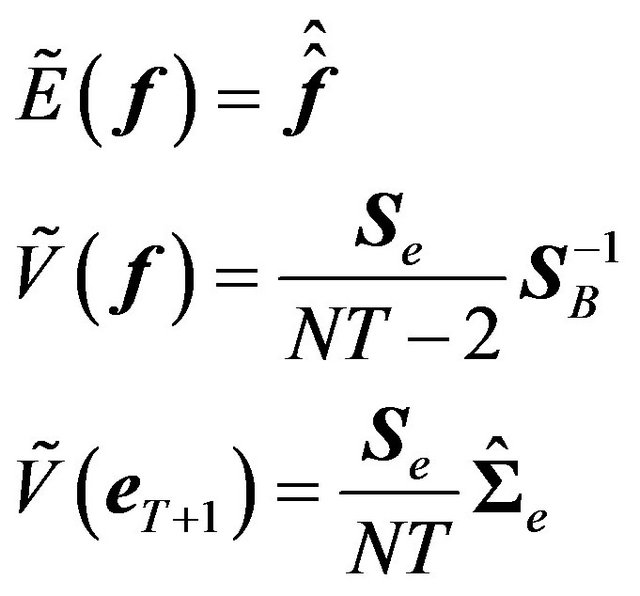 (34)
(34)
The predictive mean and the predictive variance-covariance matrix of the returns are then:
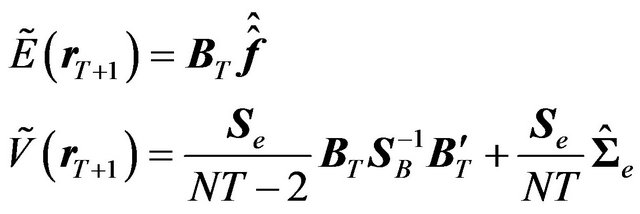 (35)
(35)
3.2.2. An Analytic Formula for Loss
Consider two investors. One investor, called the FFK investor, follows the FFK procedure as described in the previous subsection. The other investor, called the RTL investor, makes rational decisions based on the factor model.
The RTL investor’s portfolio can be specified as
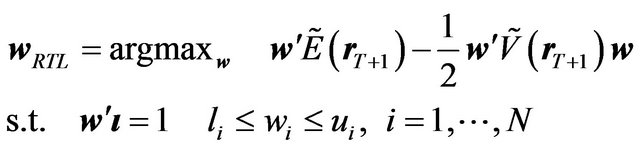 (36)
(36)
and the RTL investor’s utility can be written as
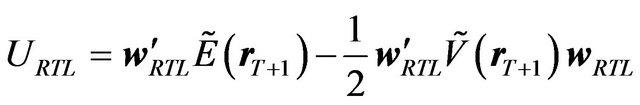 (37)
(37)
The FFK investor’s portfolio can be specified as
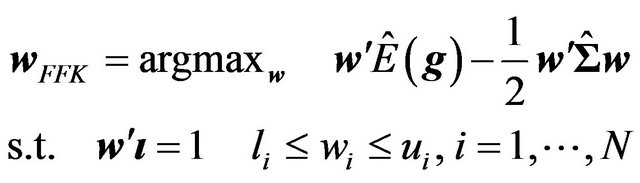 (38)
(38)
and the FFK investor’s utility can be written as
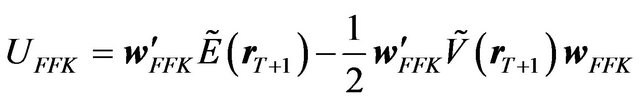 (39)
(39)
As in the previous section, we calculate the loss analytically for the simplest case, i.e. the case where there are no constraints in the optimization. If there are no constraints in the optimization, the RTL investor’s portfolio weight and his utility are identical to those presented in the previous section, i.e.
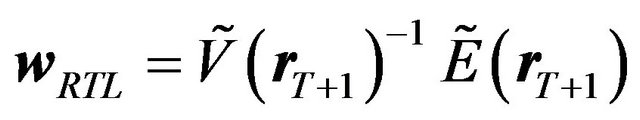 (40)
(40)
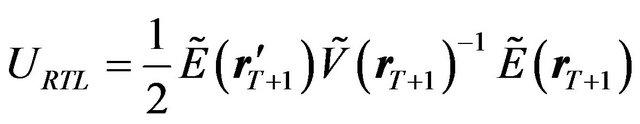 (41)
(41)
The FFK investor’s portfolio weight, on the other hand, is:
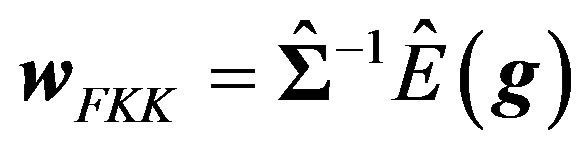 (42)
(42)
For simplicity, let us assume that the FFK investor’s estimate of the variance-covariance matrix 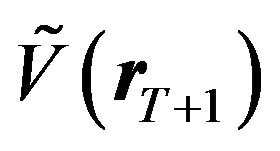 is not very different from the predictive variance-covariance matrix
is not very different from the predictive variance-covariance matrix 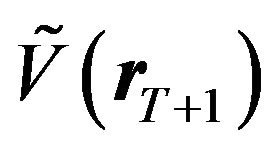 of the RTL investor.31 Then we could write
of the RTL investor.31 Then we could write
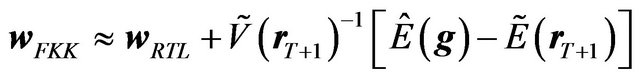 (43)
(43)
and
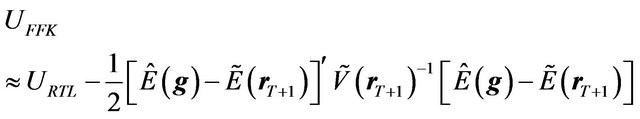 (44)
(44)
Thus, the loss is approximately quadratic in the difference between the FFK investor’s posterior mean and the RTL investor’s posterior mean.
Let us consider the difference between the FFK investor’s posterior mean and the RTL investor’s posterior mean further. Assuming that the difference between the OLS estimator 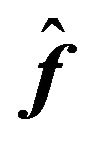 and the GLS estimator
and the GLS estimator 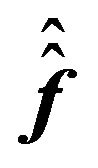 is not large32, one can write
is not large32, one can write
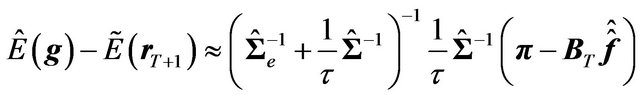 (45)
(45)
Thus, the loss depends on the difference between the multifactor model estimates and the CAPM estimates. This is a rather obvious result, considering that the very source of the problem was the use of the CAPM, which is not the correct model in our example.
3.2.3. Investor Simulations
We follow the procedure identical to that of the previous section to numerically calculate the magnitude of the loss.33 Tables 2 and 3 summarize the simulation results. The actual distribution of losses for the FFK investor for 1000 simulations is shown in Figure 2. The mean loss for the FFK investor is between 0.09 and 0.12, while the median loss is between 0.06 and 0.10. As before, we might interpret this loss as a reduction in the expected return of the investor. A conservative estimate would be a loss of around 0.09% in expected return per month or 1.08% on an annualized basis.
One may notice that the loss of the FFK investor is somewhat smaller than the loss of the JLZ investor. This is what we could have expected. The loss of the JLZ investor is a quadratic function of the error in the mean estimate, while the loss of the FFK investor is a linear function of the difference in mean estimates of the two models.
4. Using the Black-Litterman Approach as a Reverse Optimization Technique
Practitioners often use the Black-Litterman approach as a tool to extract implied expected returns for a given portfolio weight vector. Step 3 of the JLZ procedure discussed in Section 2 of this paper is an example of this.
Given a portfolio weight vector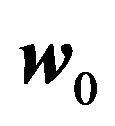 , one can derive the implied expected return by assuming that the portfo-
, one can derive the implied expected return by assuming that the portfo-
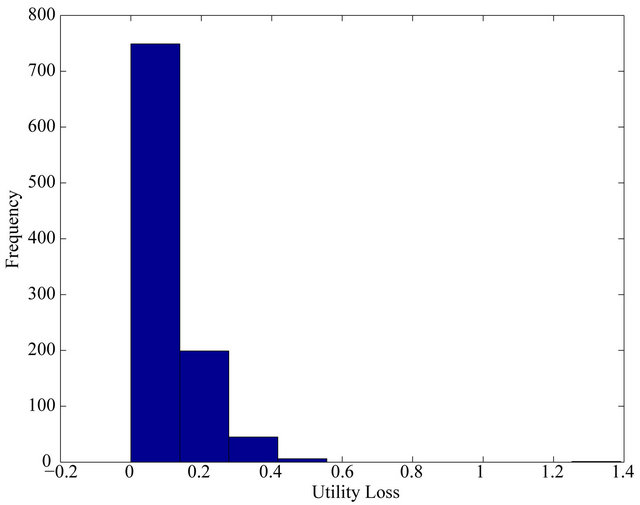
Figure 2. Utility Losses from 1000 Simulations for the FFK Investor.
lio weight vector is a solution to the following optimization problem:
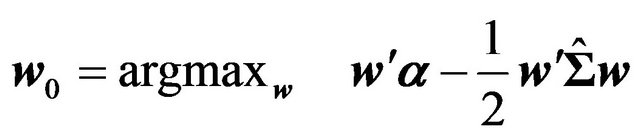 (46)
(46)
As we have shown in Section 2, the solution is given as
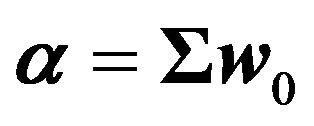 (47)
(47)
where 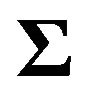 is the variance-covariance matrix of returns.
is the variance-covariance matrix of returns.
One aspect that is often ignored in the “reverse optimization” is that the validity of the implied expected return depends on the validity of the variance-covariance matrix used.34 To the extent that the variance-covariance matrix includes an error, the implied expected return also includes the error.
Let 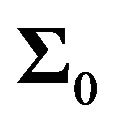 be the true variance-covariance matrix. Let
be the true variance-covariance matrix. Let 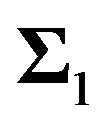 be our estimate of the variance-covariance matrix. Then the error in the implied expected return is
be our estimate of the variance-covariance matrix. Then the error in the implied expected return is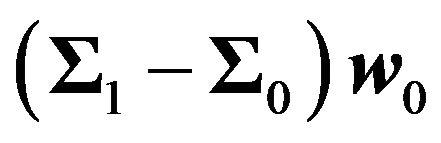 .
.
To have a more intuitive sense of the magnitude of the error, we focus on the implied market return, which is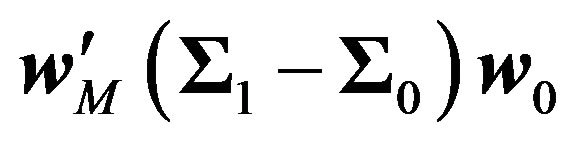 , where
, where 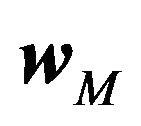 is the market capitalization weight. We present typical values of this bias in Table 4, which were calculated from a simulation.35 When
is the market capitalization weight. We present typical values of this bias in Table 4, which were calculated from a simulation.35 When 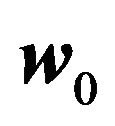 reflects a value weight portfolio , the 80% range of the error is from −2.6 to 2.75. That is, excluding the 20% worst cases, the error in the expected monthly market return can be as high as 2.75%. When
reflects a value weight portfolio , the 80% range of the error is from −2.6 to 2.75. That is, excluding the 20% worst cases, the error in the expected monthly market return can be as high as 2.75%. When 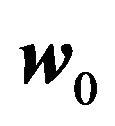 reflects an equal-weighted portfolio, the same error can be as high as 3.52%. This magnitude of the error can be compared to the long-term average return of the market, which is around 2%. This is a large error in relative terms.
reflects an equal-weighted portfolio, the same error can be as high as 3.52%. This magnitude of the error can be compared to the long-term average return of the market, which is around 2%. This is a large error in relative terms.
5. Conclusions
The Black-Litterman model has been used extensively in
Table 4. Bias in the Implied Expected Monthly Market Returns.
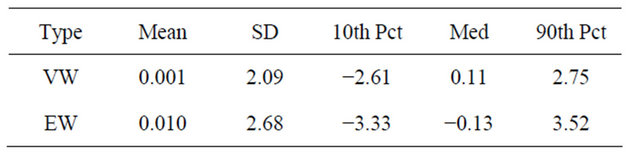
Note: VW represents the reverse optimization bias for value-weighted portfolio, while EV represents the reverse optimization bias for an equalweighted portfolio in percentage terms.
asset allocation and in recent years, a number of people have proposed applications of it to areas such as trading and quantitative portfolio management. Some of these methods have necessitated a transformation or adaptation of the Black-Litterman model to the specific application. Unfortunately, these transformations could be associated with unintended consequences. In this paper, we discuss three applications of the Black Litterman model that result in unnecessary costs to the investor.
The first type of application creates a portfolio out of a prior and an estimate of the variance-covariance matrix, but fails to utilize the mean estimate. Not using the mean estimate amounts to ignoring a valuable piece of information present in the data. Our conservative estimate of the loss from neglecting the mean is about a 1% reduction in expected annual returns. Although it is well known that means are not estimated as reliably as variance and covariances, ignoring the mean estimate cannot be an optimal solution. For even if the mean estimate is not extremely precise, it is still better to use this estimate than to entirely ignore it.
The second type of application creates a portfolio out of two conflicting models of security returns, e.g. the CAPM and a multi-factor model. Assuming that the multi-factor model is the true model of stock returns, we estimate the loss to an investor that chooses to combine both a CAPM model and a multi-factor model in his portfolio construction. We find the magnitude of this loss to be around a 1% reduction in expected annual returns. One might justify the use of two models if the portfolio manager has no idea regarding which model is more likely to be true. In most practical situations, it would be unlikely that the portfolio manager or analyst did not have a clear idea about which model they believed represented the behavior of stock returns. Thus, it makes it hard to justify using two contradictory models of stock returns.
The third application is the so-called reverse optimization technique. That is, practitioners often use the weights of an index and reverse optimize to obtain the implied expected returns of the market. Since the variance-covariance matrix is estimated with error, the implied expected returns of such a procedure will also be estimated with error. We quantify the magnitude of the errors associated with this technique. We found this error to be quite high, in some cases as high as 3.5% per month and much higher if the original benchmark was an equal-weighted benchmark. This brings into question how useful this reverse optimization technique really is.
No doubt the Black-Litterman model brought a new tool to aid asset allocators, portfolio managers, and traders with the construction of optimal portfolios. In particular, it provided a theoretical framework upon which an investor’s prior views about asset markets or stocks could be combined with the actual historical data in order to construct optimal investments. The main application of the Black-Litterman model has been to asset allocation across broad asset classes. Recent research has tried to integrate the Black-Litterman model in the trading framework and the quantitative equity portfolio framework. These advances are inspiring as they improve the tool set for quantitative managers, unfortunately some of the applications have side effects which we must be aware of. In this paper, we have discussed some of the potential side effects of these applications of the Black-Litterman model. Our estimates of the losses associated with these side effects are large from a portfolio management perspective. We also suggest a straightforward way to apply the Black-Litterman model without this bias in the portfolio construction process.
REFERENCES
- G. L. He and R. Litterman, “The Intuition Behind the Black-Litterman Model Portfolios,” Goldman Sachs Working Paper, 1999.
- F. Black and R. Litterman, “Global Portfolio Optimization,” Financial Analysts Journal, Vol. 48, No. 5, 1992, pp. 28-43. doi:10.2469/faj.v48.n5.28
- L. B. Chincarini and D. Kim, “Quantitative Equity Portfolio Management,” McGraw-Hill, New York, 2006.
- R. C. Jones, T. Lim and P. J. Zangari. “The Black-Litterman Model for Structured Equity Portfolios,” Journal of Portfolio Management, Vol. 33, No. 2, 2007, pp. 24-43. doi:10.3905/jpm.2007.674791
- F. J. Fabozzi, S. M. Focardi and P. Kolm, “Incorporating Trading Strategies into the Black-Litterman Framework,” Journal of Trading, Vol. 1, No. 2, 2006, pp. 28-37.
- S. Satchell and A. Scowcroft, “A Demystification of the Black-Litterman Model: Managing Quantitative and Traditional Portfolio Construction,” Journal of Asset Management, Vol. 1, 2000, pp. 138-150. doi:10.1057/palgrave.jam.2240011
- A. Zellner, “An Introduction to Bayesian Inference in Econometrics,” John-Wiley and Sons, Hoboken, 1971.
- G. Koop, “Bayesian Econometrics,” John-Wiley and Sons, Hoboken, 2003.
NOTES
*We would like to especially thank Josh Ruben for research assistance. We also thank Frank Fabozzi for comments.
1The Black Litterman model allows an expression of subjective views such as “the sum of asset A return and asset B return will be positive.” That is, it allows the investor to make a statement on a linear combination of many asset returns. If this type of statement is not allowed, one may have to be more explicit. An example is: “asset a return is likely to be around 10% while asset B return is likely to be around 5%.”
2Chincarini and Kim [3] examined other situations in which improper portfolio construction led to utility losses to the investor.
3We are not implying that the researchers we cite were unaware of the problems we are raising. In fact, the applications we discuss were not the main point of their articles, which explains why the problems we discuss now did not receive full attention in their article.
4In many applications,  is a matrix of observable characteristics.
is a matrix of observable characteristics.
5Portfolio managers may determine the value of 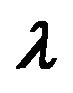 based on their expectation of “factor returns.” For example, if they expect the size of return to be high, they may choose a large value for the size exposure.
based on their expectation of “factor returns.” For example, if they expect the size of return to be high, they may choose a large value for the size exposure.
6The derivation of this result and other results is included in an appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id = 2191278.
8Without the constraints, the solution to this optimization would be the optimal tilt weights, .
.
9One might argue that means are typically not estimated accurately, and that ignoring the mean estimate is not a big deal. However, a variance estimate does not have the same meaning if one ignores the mean estimate. Recall that the variance measures the deviation from the mean. Without specifying a mean, a variance is an incomplete concept. One might end up making a decision as if the true mean is zero, which can be worse than using an imprecisely estimated mean.
10Our main arguments are not affected by the value of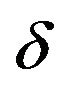 , nor by the choice of how loss is measured.
, nor by the choice of how loss is measured.
11See the discussion preceeding Equation (14) for an example of alternatives that we did not take.
12JLZ do mention this model and even suggest to use it to determine the view. We will discuss the problem of using a data based view in the next section. For now, we interpret the view as completely independent from the data.13The Gamma distribution makes the analysis tractable. The Gamma distribution, when used with normal distribution, has the property that the posterior will be of the same type of distribution as the prior. Due to this property, the Gamma-Normal prior is called a conjugate prior, and is widely used in Bayesian analysis. We follow the parameterization of the Gamma distribution used by Koop (2003). The pdf of the above distribution is
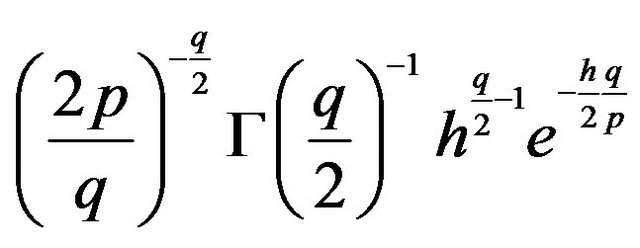
14This aspect of the prior is required for a conjugate prior, i.e. a prior that leads to a posterior of the same distribution. Using a conjugate prior makes our analysis simple, but the conclusion of our analysis does not depend on a conjugate prior.
15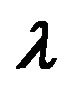 is the factor tilt implied by the investor’s view and the model. Thus, we can find an optimal portfolio given the investor’s view and the model, and determine the factor tilt of that portfolio, which should be
is the factor tilt implied by the investor’s view and the model. Thus, we can find an optimal portfolio given the investor’s view and the model, and determine the factor tilt of that portfolio, which should be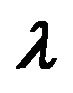 . Given the investor’s view and the model, the unconditional distribution of
. Given the investor’s view and the model, the unconditional distribution of 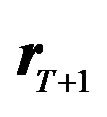 is
is
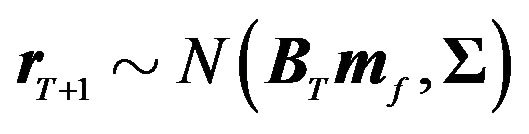 (10)
(10)
where 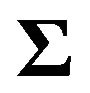 is the variance-covariance matrix of
is the variance-covariance matrix of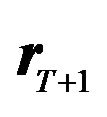 , i.e.,
, i.e.,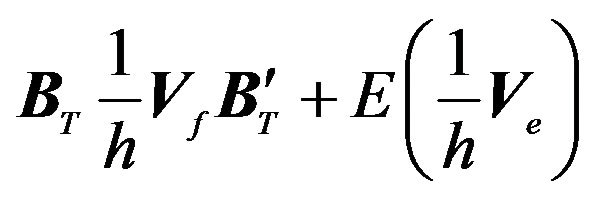 . If the investor has the utility function specified in Equation (6) with
. If the investor has the utility function specified in Equation (6) with 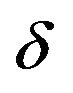 equal to 1, then the optimal portfolio, given the above distribution, can be found from the following optimization:
equal to 1, then the optimal portfolio, given the above distribution, can be found from the following optimization:
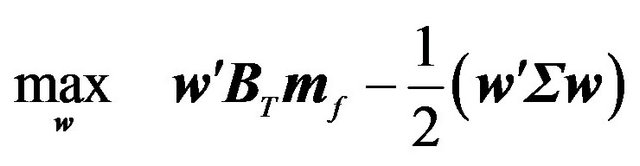 (11)
(11)
The solution to the above problem is
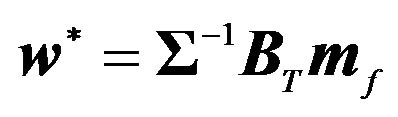 (12)
(12)
From the factor tilt of this portfolio, we can obtain Equation (9). This comes from the second equation in the maximization problem, that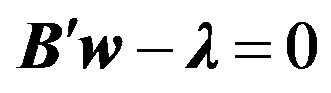 . Thus, substitution of Equation 12 gives
. Thus, substitution of Equation 12 gives 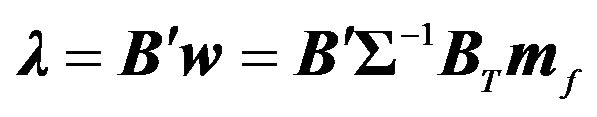 .
.
16Note that, in our analysis, ’s are matrices of observable characteristics, not estimates of factor loadings. Estimation error does not arise as far as
’s are matrices of observable characteristics, not estimates of factor loadings. Estimation error does not arise as far as ’s are concerned.
’s are concerned.
17That is, (13)
 (13)
(13)
where 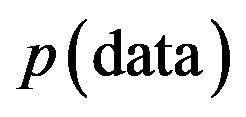 is the probability density function of the data. The integration is taken over the data. In other words, if we average the predictive expectation over all the possible values of the data, then we get an economist’s expectation.
is the probability density function of the data. The integration is taken over the data. In other words, if we average the predictive expectation over all the possible values of the data, then we get an economist’s expectation.
18The derivation of this result is included in an appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278.
19The GLS estimator of the factor premium 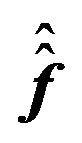 is
is , its precision matrix
, its precision matrix 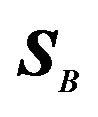 is
is 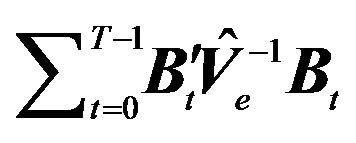 , and the error sum of square matrix
, and the error sum of square matrix 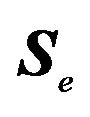 is
is 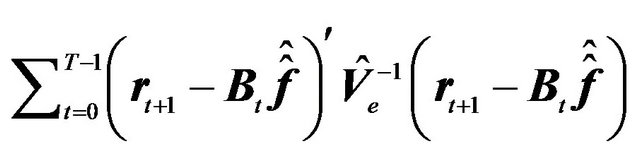 , where
, where 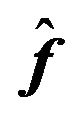 is
is 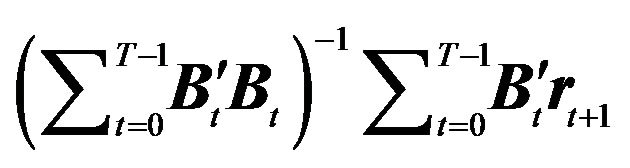 , and
, and 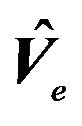 is
is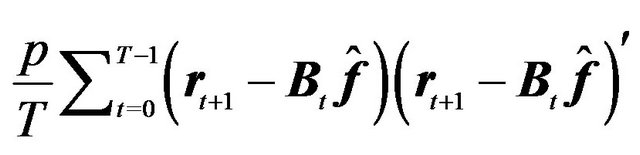 .
.
20Recall that we evaluate the utility in terms of predictive mean and variance.
21We could have carried out the simulations at the individual stock level. All our formulas would work at the individual stock level as well.
22Further details about the simulation procedure are provided in an appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278.
23This estimate is fairly conservative, as we allow the JLZ investor to use the “correct” variance-covariance matrix of errors.
24See p. 32 of Fabbozi, Forcardi, and Kolm (2006).
25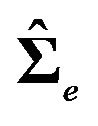 is an estimate of the error variance, not an estimate of the uncertainty of the mean estimate. In some special cases, however,
is an estimate of the error variance, not an estimate of the uncertainty of the mean estimate. In some special cases, however, 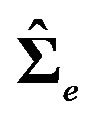 can be interpreted as as estimate of the uncertainty of the mean estimate, for example, if there is only one variable on the right hand side of the model.
can be interpreted as as estimate of the uncertainty of the mean estimate, for example, if there is only one variable on the right hand side of the model.
26See the section entitled “The Derivation of the CAPM Equilibrium Return ” in the appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278 for a detailed explanation.
” in the appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278 for a detailed explanation.
27See the appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278 for the proof.
28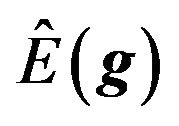 is the posterior mean of the stock return, as it is the posterior mean of the mean returns.
is the posterior mean of the stock return, as it is the posterior mean of the mean returns.
29Meucci’s [9] extension of BL has a similar feature. That is, it is based on two inconsistent models. Meucci, however, provides an alternative, more appealing justification of his approach based on the idea of relative entropy. Thus, our criticism has limited relevance to Meucci’s approach.
30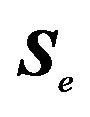 ,
, 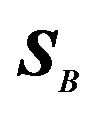 ,
, 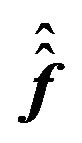 ,
, 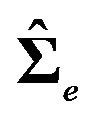 need to be modified as well.
need to be modified as well.
31That is, we are assuming that the FFK investor is using the best estimator of the variance-covariance matrix. This assumption is of course more favorable to the FFK investor.
32This happens when the error covariance is close to an identity matrix, i.e. homeskedatic and no serial correlation.
33See the appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278 for more details.
34That one recovers the expected return vector rather than the variance-covariance matrix from the reverse optimization may reflect the belief that estimating the variance-covariance matrix is easier than estimating the expected return vector. Even if such a belief is reasonable, one shouldn’t forget that the implied expected return is an estimate.
35See the appendix available at http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2191278 for details of the simulation.