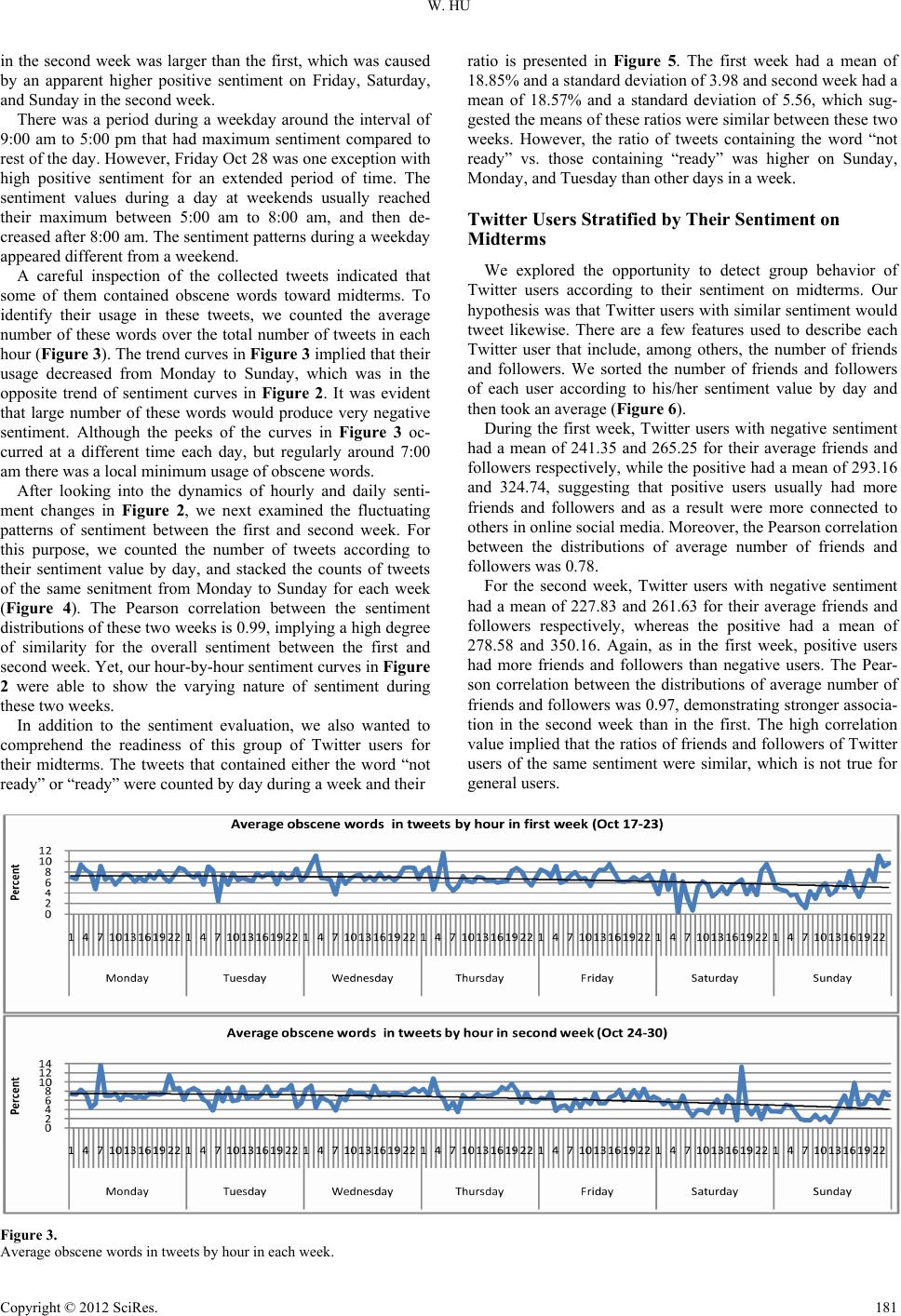
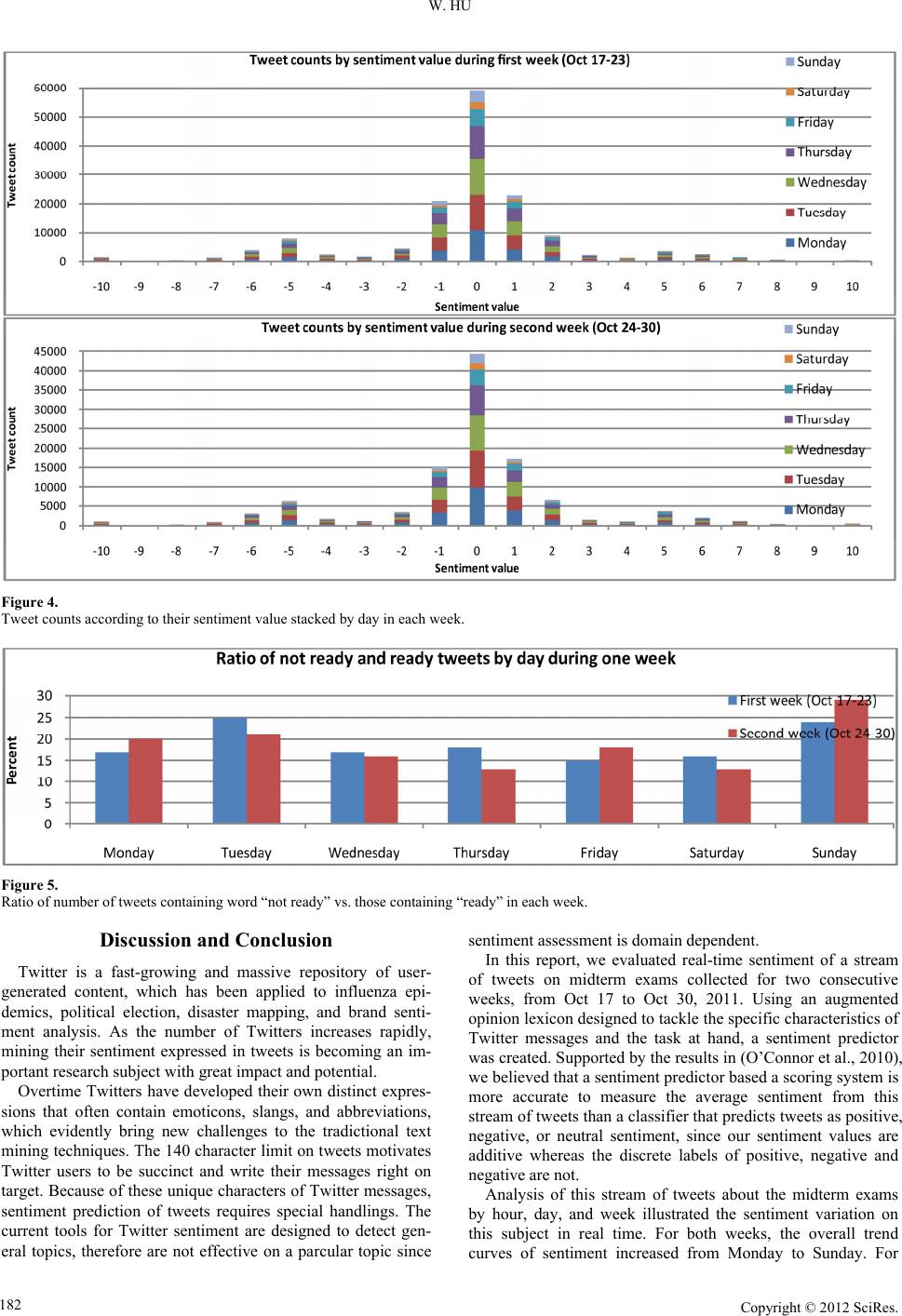
W. HU
data to predict the class of sentiment (positive, negative, or neu-
tral). Obtaining large size of training data annotated by experts
is difficult, and sometimes human judgment of the sentiment
expressed in text is not as accurate as an automated approach.
To overcome these difficulties, recently there were reports that
combined both techniques (Lu &Tsou, 2010; Tan et al., 2008).
Using movie reviews as data, machine learning techniques
were found to be more effective in sentiment collection than
human produced baselines. But they didn’t predict as well on
sentiment as on traditional topic based classification, implying
that the sentiment classification was more challenging (Pang,
2008). To improve the performance of the machine learning
approach in (Pang, 2008), a novel technique of finding mini-
mum cuts in graphs was proposed to extract the subjective por-
tions of the document, thus removing the irrelevant text while
keeping the subjective portion (Pang et al., 2002).
Due to the 140 character limitation on tweets, Twitterers
have adopted abbreviated and slang expressions to overcome
this limit. Thus, they have created a language of different flavor
in this social media than the one used in traditional texts.
Tweets also contain misspellings, and are shorter and more
ambiguous than other sentiment data such as reviews and blogs.
Another feature of tweets is that they cover a variaty of topics
unlike other blogging sites that are more focused on one or a
few topics. Consequently, it is not straightforward to detect the
sentiment of tweets.
People typically use Twitter for daily chatter, conversation,
information sharing, and news reporting (Java et al., 2007). A
study showed that 19% of tweets mention a certain brand, and
20% of them contain a sentiment (Jansen et al., 2009). In gen-
eral, these massages could be classified into two groups: about
Twitter users themselves and information sharing. In both cases,
tweets contain information about the mood of their writers
(MorNaaman & Boase, 2010). With six dimensions of mood
(tension, depression, anger, vigor, fatigue, confusion), the pub-
lic mood patterns learned from Twitter data were found to be
related to real offline events, such as changes in the stock mar-
ket and the oil price, and the outcome of a political election
(Bolle et al., 2011). To find the connection between public
opinions from polls and the sentiment from Twitter messages
(O’Connor et al., 2010), positive and negative words were de-
fined by a subjectivity lexicon, a set of words containing about
1600 and 1200 words marked as positive and negative, respec-
tively. A message was defined as positive if it contained any
positive word, and negative if it contained any negative word.
This allowed for messages to be both positive and negative.
The results from (O’Connor et al., 2010) showed that the senti-
ment from Twitter data was highly correlated with the polls.
Sentiment detection of tweets is one of the fundemental
components in the applications using Twitter data. There are
several sentiment tools developed for Twitter data such as
Twendz, Twitter Sentiment, TweetFeel, and Viralheat, but most
of them are still lacking the expected accuracy due to the
unique characteristics of tweets.
In this report, we sought to examine a stream of text mes-
sages from students on Twitter to gather real-time sentiment
toward midterm exams. Our main interest was to discover the
fluctuation in sentiment about midterms from this particular
group of Twitter users by hour, day and week, thus our investi-
gation could disclose the sentiment at different levels of tem-
poral granularity. Twiter Stream API made it possible to ana-
lyze sentiment for this topic as they arose in real-time.
Though many colleges allow students to evaluate their
courses, Twitter provides a venue for them to express opinions
on their midterm exams. Students have different feelings about
the midterm exams. They can have high confidence in the
coming exams because they have studied and prepared well,
otherwise, they may feel uncertain, uneasy, afraid, scared, and
anxious. They also can express the feelings to their teachers,
exams in general, and their grades from these exams.
Materials and Methods
Twitter Data
Twitter is a service for information network and communica-
tion, which produces more than 200 million tweets a day.
Twitter offers three APIs to access its corpus of data and sup-
port developers to build applications using Twitter data. The
Search API allows a user to query for Twitter content, and the
REST API enables the access to some of the core primitives of
Twitter including timelines, status updates, and user informa-
tion. Finally, the Streaming API is the real-time sample of the
Twitter Firehose with a long-lived HTTP connection to retrieve
tweets by user ids, keywords, random sampling, geographic
location, etc. This API is best for building data mining applications.
Using Twitter Stream API (https://dev.twitter.com/docs/strea
ming-api) and Twitter4J (http://twitter4j.org), we collected a cor-
pus of 260,749 tweets on midterm exmas during a period of
two consecutive weeks, from Oct 17 to Oct 30, 2011. The de-
tailed information for the numbers of tweets collected by day is
presented in Table 1.
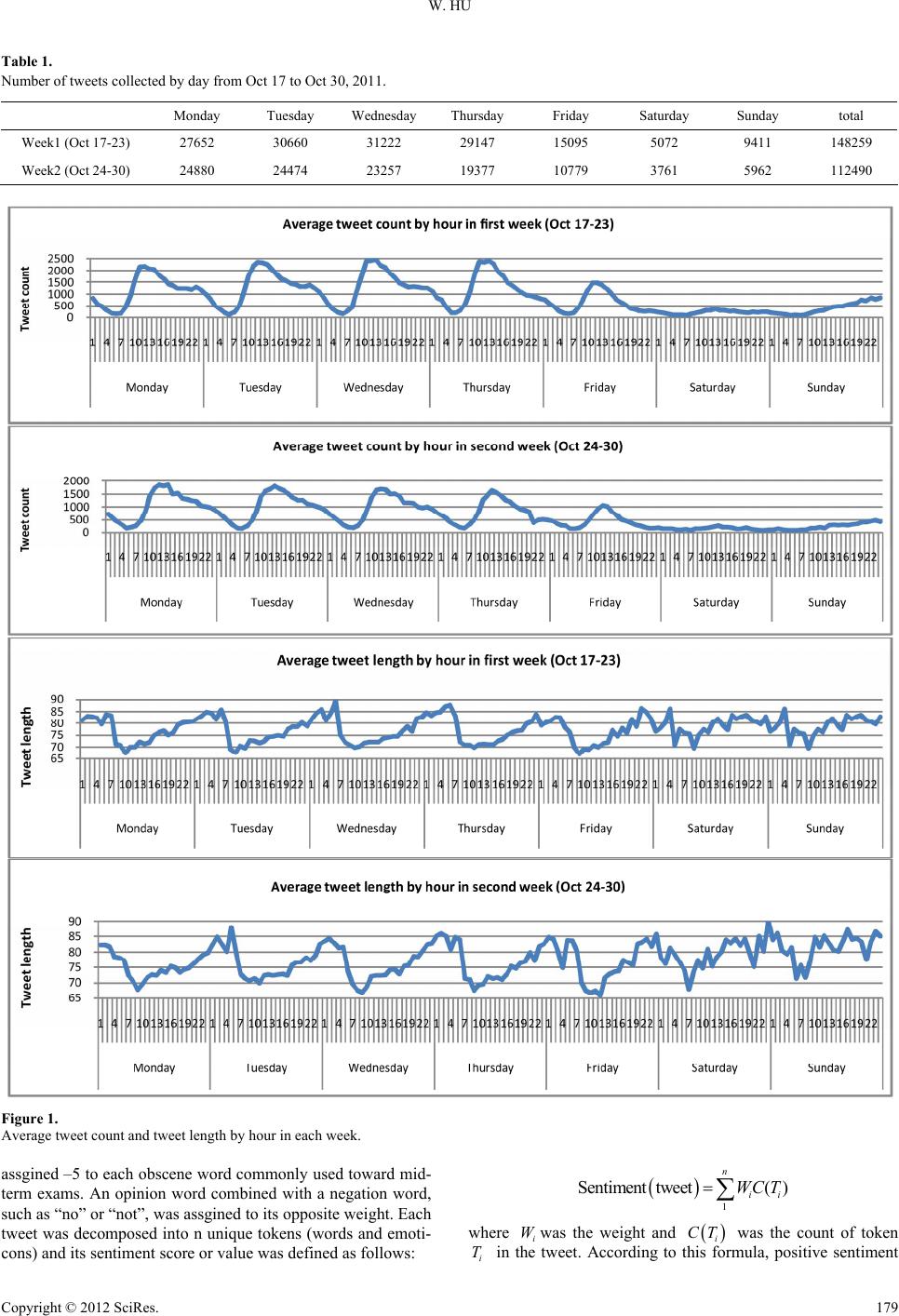
To gain a preliminary view of our tweet data, we calculated
the average tweet count and tweet length by hour during these
two weeks (Figure 1). Amazingly, some group patterns of
these student Twitters were detected from the random behavior
of each individual. The lowest average tweet count was always
around 5:00 am-6:00 am each day, and the maximum count was
around 1:00 pm except Sunday. Remarkably, the minimum
average length was regularly around 9:00 am and the maximum
length was around 4:00 am.
Sentiment Predictor
In the present study, we employed an opinion lexicon (Hu &
Bing, 2004) of around 6800 words to build our sentiment pre-
dictor. Several opinion lexicons exist, but a web derived lexi-
con like the one from (Hu & Bing, 2004) could improve lexi-
con-based sentiment evaluation (Velik o v ich et al., 2010).
Considering the nature of midterm exams, we augmented the
opinio lexicon from (Hu & Bing, 2004) with some domain
specific words such as “bombed”, and “aced”, and removed
some negative words such as “criminal”, “fall”, and “break”
from this lexicon since “criminal” in our context can be part of
the name of an exam like “criminal justice midterm”, “fall”
could mean fall semester, and “break” could mean a college
break that students look forward to.
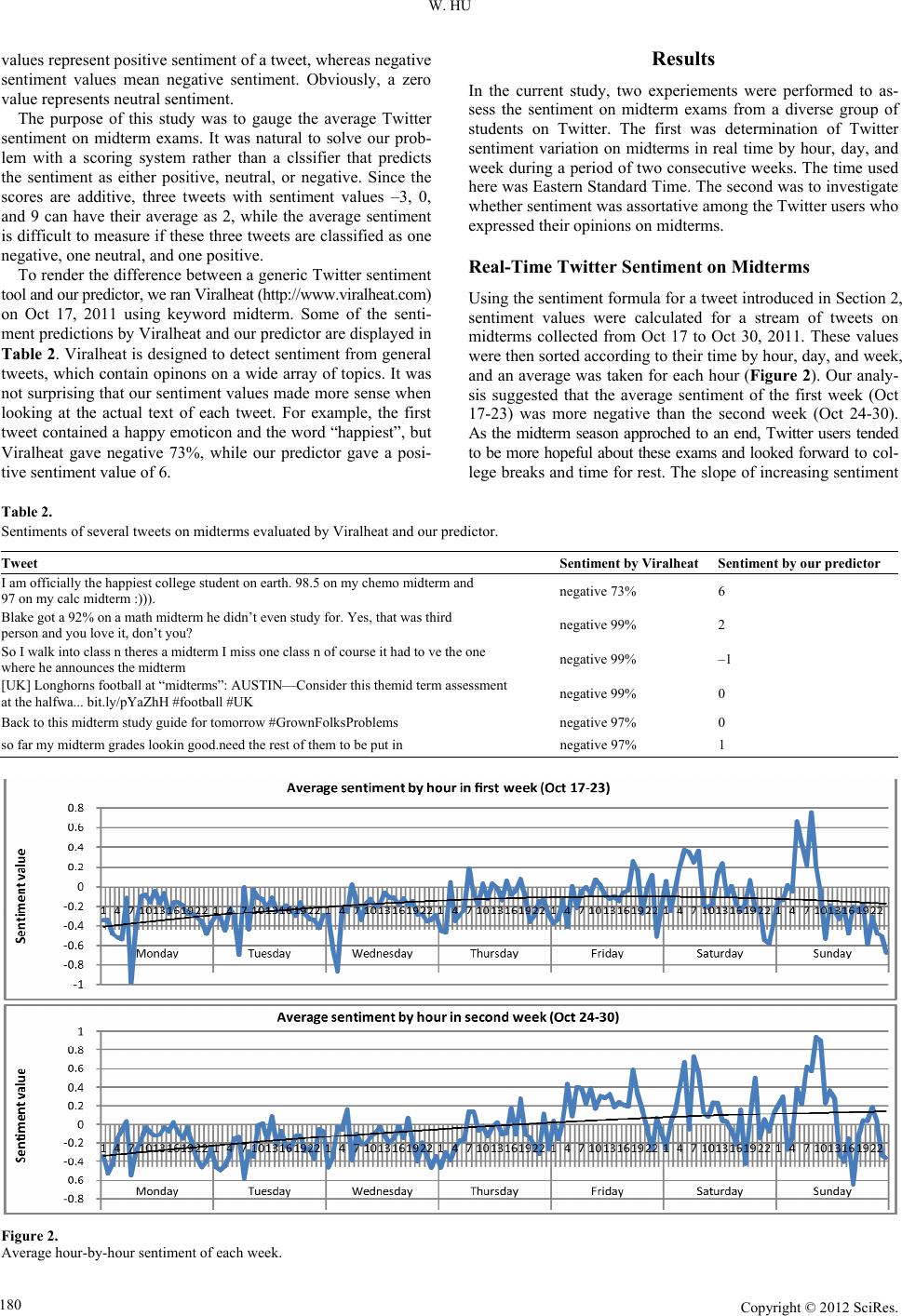
Encouraged by the results in (O’Connor et al., 2010), we
adopted their approch in our study to count instances of posi-
tive and negative words and emoticons, when evaluating the
sentiment of a tweet on midterms using an opinion lexicon.
Considering the characteristics of tweets, a weight +1 was ass-
gined to a positive word, –1 to a negative word, +5 to a positive
emoticon, and –5 to a negative emoticon, since emoticons are
key non-verbal sentiment indicators in tweets. Furthermore, we
Copyright © 2012 SciRes.
178