Theoretical Economics Letters
Vol.05 No.01(2015), Article ID:54077,22 pages
10.4236/tel.2015.51018
Modeling Spatial Data Pooled over Time: Schematic Representation and Monte Carlo Evidences
Jean Dubé1, Diego Legros2
1Laval University, Québec, Canada
2University of Burgundy, Dijon, France
Email: mailto:jean.dube@esad.ulaval.ca, mailto:diego.legros@u-bourgogne.fr
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 24 January 2015; accepted 11 February 2015; published 15 February 2015
ABSTRACT
The spatial autocorrelation issue is now well established, and it is almost impossible to deal with spatial data without considering this reality. In addition, recent developments have been devoted to developing methods that deal with spatial autocorrelation in panel data. However, little effort has been devoted to dealing with spatial data (cross-section) pooled over time. This paper endeavours to bridge the gap between the theoretical modeling development and the application based on spatial data pooled over time. The paper presents a schematic representation of how spatial links can be expressed, depending on the nature of the variable, when combining the spatial multidirectional relations and temporal unidirectional relations. After that, a Monte Carlo experiment is conducted to establish the impact of applying a usual spatial econometric model to spatial data pooled over time. The results suggest that neglecting the temporal dimension of the data generating process can introduce important biases on autoregressive parameters and thus result in the inaccurate measurement of the indirect and total spatial effect related to the spatial spillover effect.
Keywords:
Spatio-Temporal Data, Data Generating Process, Spatial Econometric, Weights Matrices, Monte Carlo Experiment

1. Introduction
Spatial dependence and spatial correlation among observations have been suspected for many years [1] . Anselin and Bera (1998) [2] define spatial autocorrelation as “the coincidence of value similarity with locational similarity”. The particularity of spatial autocorrelation lies in its multidirectional effect. Its complexity explains why spatial autocorrelation has received such attention since spatial data are now widely available and used. Spatial auto- correlation among residuals of a statistical model can have various consequences on estimated coefficients and variances, depending on sample size [3] -[5] .
Spatial autocorrelation is also the starting point of the development of spatial econometrics begun at the end of the decade 1970 [6] . The most recent development in the field focuses on spatial panel models and the deve- lopment of an appropriate estimation procedure [7] . Most of the literature now focuses on how it can be possible to take into account the spatial characteristics of the data, while using the temporal source of variability as well. Essentially, these approaches apply very well to data representing given geometric delimitation, such as a region, provinces, states and countries. However, there are many databases that do have both dimensions, spatial and temporal, but are clearly different from the panel case.
Spatial, or cross-sectional, databases pooled over time can represent sale prices (real estate), business opening (or)/closings, crime location, innovation, and so on. For these databases, the panel procedures cannot be applied since a given spatial observation (located at a point) is only observed once1 over time. In short, spatial data collected over time can clearly be different from the spatial panel case. Since panel applications fail to adequately model spatial data pooled over time, the easy solution for researchers is normally to apply the usual spatial econometric methods and models. However, such applications implicitly assume that time dimension has no effect on the data generating process. Even worse, this approach assumes that future observations can influence the determination of past values of the dependent variable [8] .
Recent developments have proposed a simple way to adequately control the temporal dimension while accounting for spatial dimension influencing the data generating process [8] -[11] when data consist of spatial obser- vations pooled over time. However, very few have investigated the effect of adopting spatial econometric tech- niques for such data. Thus, there is a real need to determine the exact effect of applying spatial econometric models and spatial autocorrelation detection tests on spatial data pooled over time.
The paper endeavours to determine the impact of using spatial econometric models and tests when data consist of individual spatial units pooled over time. More specifically, the paper presents a realistic representation of the data generating process (DGP) for spatial data pooled over time by decomposing the possible relations for the dependent variable and for the error term. A Monte Carlo experiment formalizes this DGP and investigates the effects of neglecting the temporal dimension when estimating spatial autoregressive models. The results clearly suggest that neglecting the temporal dimension of the DGP can generate biases on the autoregressive coefficient as well as on the coefficient related to the independent variable which can lead to erroneous inter- pretation of the indirect and total marginal effect related to spatial characterization [4] .
The paper is divided into five sections. The first section formally addresses the characteristics of spatial data pooled over time through a visual presentation of the DGP. Particular attention is paid to the ties and relationship (unidirectional and multidirectional) that can arise from spatial data pooled over time. The second section presents the way a weights matrix can be adapted and decomposed to deal simultaneously with the spatial and temporal dimensions. The third section presents a simple Monte Carlo framework used to evaluate the impact of neglecting the temporal dimension of the DGP on the estimation of the coefficients as well as on the general Moran’s 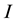 [12] index used to detect spatial autocorrelation. The estimation procedure is briefly discussed. The fourth section presents the results and discusses the possible biases of neglecting the temporal dimension. Lastly, the paper concludes with a summary of the main results.
[12] index used to detect spatial autocorrelation. The estimation procedure is briefly discussed. The fourth section presents the results and discusses the possible biases of neglecting the temporal dimension. Lastly, the paper concludes with a summary of the main results.
2. Data Generating Process of Spatial Data Pooled over Time
The data generating process of spatial data pooled over time is based on a three dimensional representation: the dimension 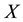 representing the east-west location of a given point, the dimension
representing the east-west location of a given point, the dimension 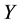 representing the north- south location of the point and the dimension
representing the north- south location of the point and the dimension 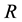 indicating the time period the point was collected (Figure 1). It is no longer based on a two dimensional configuration as is the case for spatial data (Figure 2). The three dimensional representation complicated the application of the usual spatial models and tests [8] . Since an addi- tional dimension is added on the DGP, the relations are not necessarily multidirectional for all observations. In fact, the possible relation among the variables depends on the nature of the variables considered.
indicating the time period the point was collected (Figure 1). It is no longer based on a two dimensional configuration as is the case for spatial data (Figure 2). The three dimensional representation complicated the application of the usual spatial models and tests [8] . Since an addi- tional dimension is added on the DGP, the relations are not necessarily multidirectional for all observations. In fact, the possible relation among the variables depends on the nature of the variables considered.
If one assumes that the spatial autoregressive process is based on the dependent variable, then the multidirec-

Figure 1. Schematic representation of the spatio-temporal distribution of the observations.

Figure 2. Schematic spatial representation of the spatio-temporal distribution of the observations.
tional spatial relations are only possible for a given time period2. Otherwise, it supposes that the future can be
perfectly anticipated so that actual realizations of the dependent variable,  , can influence the realizations of another dependent variable, but occurring some period before,
, can influence the realizations of another dependent variable, but occurring some period before,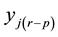 . Usual multidirectional links between observations will implicitly assume that future realizations,
. Usual multidirectional links between observations will implicitly assume that future realizations, 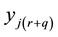 , can influence past or actual realizations,
, can influence past or actual realizations, 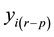 or
or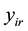 , which is a strong assumption based on the fact that perfect anticipation of future realizations is
, which is a strong assumption based on the fact that perfect anticipation of future realizations is
always right. This assumption is particularly criticized when working with a considerable temporal dimension. For this reason, spatial multidirectional relations need to be limited to the same time period, as indicated with the bidirectional arrow, which only occurs between the black points (Figure 3).
Of course, the prior realizations can also influence the actual realizations of the dependent variable. However, the relation is no more multidirectional, but rather unidirectional: the past observations can influence the actual realizations, but the inverse is not possible. The temporal unidirectional constraints of the links can be used to introduce new relations among observations. The unidirectional relations are represented through a unidirec- tional arrow, indicating that the flow of the relations becomes truncated in one direction between the grey points and the black points (Figure 4).
Of course, the DGP can also be influenced by some (latent) fixed spatial effects. This component, usually refered to as the omitted variable problem, is usually hidden through the error term. This effect can be multi- directional if the spatial structure is assumed to be constant (and unchanged) over time. The model then assumes that the autoregressive specification is decomposed through the error component [13] . This is the essence of the geo-statistical approaches that assume that latent structure, represented here by the dotted arrow, is constant and present in all time periods, but limited to a delimited or local vicinity (Figure 5). The latent structure leads to multidirectional relations, as expressed by the bidirectional arrows (Figure 6), between observations collected at different time periods.

Figure 3. Schematic representation of the multidirectional spatial effect for a given time period and a particular point.

Figure 4. Schematic representation of the unidirectional spatial effect for a given time period and a particular point.
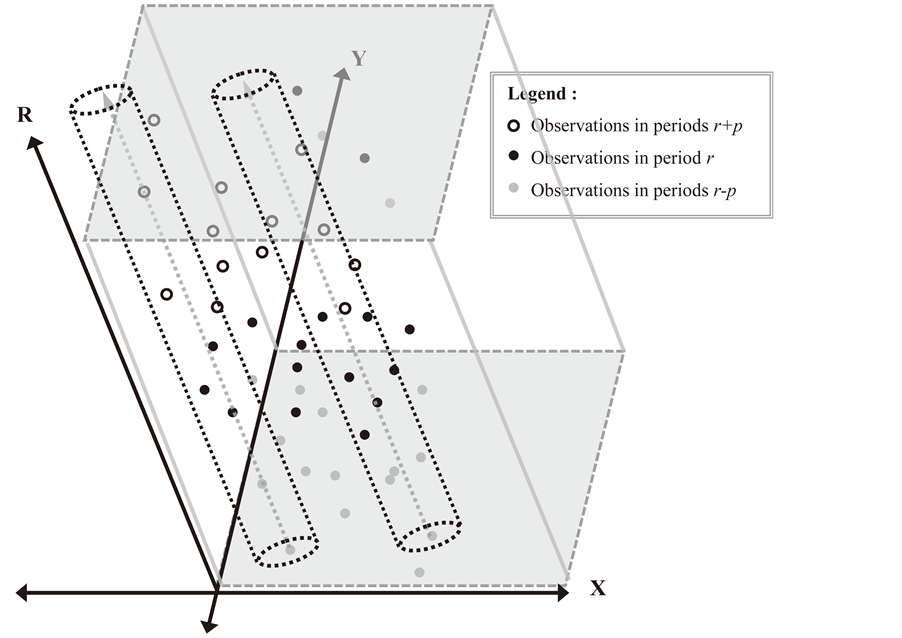
Figure 5. Local influence of the spatial unobservable component.

Figure 6. Multidirectional effect of the spatial unobservable component.
Considering temporal constraints related to spatial links among dependent (and independent) variables as well as full multidirectional relations hidden through latent spatial structure gives a completely different represen- tation of the possible links between observations (points) considering the autoregressive process assumed. To some extend, these restrictions to modeling strategies were previously highlighted by what Legendre (1993) [14] calls the new paradigm of spatial autocorrelation.
This representation of the DGP for spatial data pooled over time underlines the pertinence, as mentioned in the literature, of thinking about how the database structure should be analyzed before doing any mechanical construction of the weights matrix. According to some authors, the weights matrix should be based on a-priori theoretically-defendable knowledge [15] [16] . This idea is also supported by the work of Pinske and Slade (2010) [17] who suggest that approaches should be developed from an empirical perspective and by McMillen (2010) [18] who stresses that what really matters when working with spatial data is the relative position of the observa- tions.
As can be seen, the DGP of spatial data pooled over time is clearly different from the classic spatial case since relations among the observable variables incorporate constraints on the way one needs to consider the autoregressive process. In short, the DGP for spatial data pooled over time is different from the spatial case, where all relations are multidirectional, and different from the panel case, where individual observations are repeated in each time period. It is then necessary to consider the possible complex schema to make sure that one captures the correct (spatial and temporal) effects.
It is also necessary to develop an adapted notation when data consist of spatial individual units pooled over time. In the spatial case, the total sample is usually denoted by , while in the spatial panel case, the total sample is denoted by
, while in the spatial panel case, the total sample is denoted by , where
, where  is the number of spatial observations and
is the number of spatial observations and  is the number of time periods considered. Since the spatial panel case reports the same number of observations in each time period,
is the number of time periods considered. Since the spatial panel case reports the same number of observations in each time period,
 , the sum of
, the sum of  over the total time period,
over the total time period,  time period is simply equal to
time period is simply equal to . How-
. How-
ever, in the case of spatial data pooled over time, the total number of observations in a given time period , is noted
, is noted . The sample size can be different in each time period so that the total sample size is simply given by
. The sample size can be different in each time period so that the total sample size is simply given by
the sum of the sample size in each time period, .
.
Summarized, the techniques from the spatial panel data case cannot be applied when individual spatial units are not repeated over time. Moreover, the spatial econometric techniques implicitly assume that temporal di- mension has no effect on the DGP, which is a strong and possibly false assumption. However, these techniques may be applied if the weights matrix accounts correctly for possible relations among the individual units. To do so, it is necessary, before turning to the Monte Carlo experiment, to determine the possible form of the weights matrix for spatial data pooled over time. The next section discusses the construction of such weights matrices expressing the multidirectional effect among observations for a given time period as well as the unidirectional relations coming from a previous time period.
3. Building an Appropriate Weights Matrix
The usual spatial weights,  , among two observations
, among two observations  and
and  is built using information on the geogra- phical location of both observations, given by the couples
is built using information on the geogra- phical location of both observations, given by the couples  and
and . The distance separating the
. The distance separating the
two points, noted , can be calculated using the Pythagorean theorem (Equation (1))3.
, can be calculated using the Pythagorean theorem (Equation (1))3.
 (1)
(1)
Next, a mathematical transformation to these individuals distance is applied to make sure that the final spatial relations, or weights, summarize the idea behind the first law of geography [19] : everything is related to every- thing else, but closer things more so. Without loss of generality, it is possible to cite the three most empirically used transformation function related to distance, : i) the inverse, or square inverse, distance function (Equation (2)); ii) the exponential negative function of the distance (Equation (3)); iii) the nearest neighbors function (Equation (4)).
: i) the inverse, or square inverse, distance function (Equation (2)); ii) the exponential negative function of the distance (Equation (3)); iii) the nearest neighbors function (Equation (4)).
 (2)
(2)
 (3)
(3)
 (4)
(4)
where  (Equation (2)) is a penalty parameter imposed on distance reflecting the inverse distance transfor- mation
(Equation (2)) is a penalty parameter imposed on distance reflecting the inverse distance transfor- mation  or the inverse square distance transformation
or the inverse square distance transformation ,
,  (Equations (2) and (3)) is a critical
(Equations (2) and (3)) is a critical
distance cut-off value limiting the spatial relation to local consideration or surroundings, and  (Equation (4)) is a critical cut-off distance value for each point
(Equation (4)) is a critical cut-off distance value for each point  ensuring that each observation has a fix number
ensuring that each observation has a fix number  of neighbors. Of course, the definition of the weights matrix can be based on a more complex specification, such as the tri-cube transformation [20] , or the gaussian transformation [21] or any other transformation drawn from the geographically weighted regression (GWR) approach [22] [23] .
of neighbors. Of course, the definition of the weights matrix can be based on a more complex specification, such as the tri-cube transformation [20] , or the gaussian transformation [21] or any other transformation drawn from the geographically weighted regression (GWR) approach [22] [23] .
In the end, the individual spatial weights,  can be summarized in a square table (or matrix), noted
can be summarized in a square table (or matrix), noted , that expresses the spatial relations among all observations (Equation (5)).
, that expresses the spatial relations among all observations (Equation (5)).
 (5)
(5)
For the case of spatial data pooled over time, the spatial weights matrix is of dimension , and needs adjustment before proceeding to any statistical test or model estimation since, as previous mentioned, relations are not necessarily multidirectional. This imposes some constraint on the individual spatial weights,
, and needs adjustment before proceeding to any statistical test or model estimation since, as previous mentioned, relations are not necessarily multidirectional. This imposes some constraint on the individual spatial weights,  in the original specification. Considering the fact that spatial relations may be limited to some spatial consideration, as pointed out by the seminal work of Hègerstrand (1970) [24] , the unidirectional effect is limited to a given spatial definition.
in the original specification. Considering the fact that spatial relations may be limited to some spatial consideration, as pointed out by the seminal work of Hègerstrand (1970) [24] , the unidirectional effect is limited to a given spatial definition.
As pointed out by some authors [8] - [11] [25] , the construction of a temporal weights matrix can help to build spatio-temporal weights matrices. However, this decomposition can also be simplified by introducing constraints on the spatial weights matrix through a block diagonal decomposition.
Assuming that the observations are previously chronologically ordered, so that the first lines in the database represent the oldest observations while the last lines represent the newest observations [26] , it is possible to isolate the effect of multidirectional spatial effect for the same time period. This decomposition is simply obtained by building  different spatial weights of a smaller dimension,
different spatial weights of a smaller dimension,  expressing the spatial relations among the observations collected in period
expressing the spatial relations among the observations collected in period . By pooling these individual weights matrices on the diagonal of the global weights matrix,
. By pooling these individual weights matrices on the diagonal of the global weights matrix,  we obtain a particular weights matrix composed of a block diagonal (Equation (6)).
we obtain a particular weights matrix composed of a block diagonal (Equation (6)).
 (6)
(6)
where each square spatial weights matrix,  , is of dimension
, is of dimension  and represents potential spatial links among observations collected in the same time period.
and represents potential spatial links among observations collected in the same time period.
Moreover, given the global spatial weights matrix representation (Equation (5)), the chronological order allows to decompose the unidirectional effect through a block triangular (lower and higher) part. The lower part represents the potential effect of past realizations on actual realizations, while the upper part represents the effect of future realizations on actual realizations. Since it is impossible (or at least strongly unlikely) to know with exactitude the future realizations, the upper triangular part can be set to zero. This constraint implies that working with spatial econometric tests and models with spatial data pooled over time assumes that the assumption of per- fection anticipation is true (or likely). This lack of constraint on the weights matrix can potentially lead to a bias in the estimation, as noted by Smith (2009) [11] , related to over-connection of the matrix.
By using only the lower triangular block of the original spatial weights matrix (Equation (7)), one can easily synthesizes the unidirectional relations linking the observation  in period
in period  to observation
to observation  in period
in period
 , synthesis in the matrix
, synthesis in the matrix .
.
 (7)
(7)
Each matrix, of dimension  synthesizes the (unidirectional) spatial relations linking previous realizations observed in period
synthesizes the (unidirectional) spatial relations linking previous realizations observed in period  to realizations occurring in period
to realizations occurring in period . The final definition of each lower diagonal block of the matrix is also based on the use of an actualization coefficients, noted
. The final definition of each lower diagonal block of the matrix is also based on the use of an actualization coefficients, noted , reflecting the temporal distance separating the realizations (Equations (6) and (8)).
, reflecting the temporal distance separating the realizations (Equations (6) and (8)).
 (8)
(8)
where:
 (9)
(9)
and
 (10)
(10)
denotes the lower triangular part of the full weights matrix . It should be noted, at this stage, that the use of the weights matrix
. It should be noted, at this stage, that the use of the weights matrix  can introduce a possible problem in the estimation process since it is not of full rank. We will come back to this point later.
can introduce a possible problem in the estimation process since it is not of full rank. We will come back to this point later.
Both information can be synthesized through a unique spatio-temporal weights matrix (Equation (11)) by adding the weights matrix for multidirectional spatial effect for a given time period (Equation (6)) to the weights matrix accounting for unidirectional spatial effect based on a previous time period (Equation (7)).
 (11)
(11)
The reader can easily show that this block decomposition leads to the same matrix as using the Hadamard product of a spatial weights matrix and a temporal weights matrix. However, the advantage of treating weights matrices as separate (Equations (6) and (7)) instead of a unique matrix (Equation (11)) is that the effect can be expressed, as in Pace et al. (1998, 2000) [26] [27] as the sum of two distinct component: i) a spatial multidirec- tional effect; and ii) a spatial dynamic unidirectional effect.
Given the choice of the users, the final specifications of the weights matrix can then be row standardized, as is common in empirical applications. The row-standardization procedure is a common practice that ensures the comparability of the usual statistic tests as well as the autoregressive estimated coefficients.
Given the structure of the weights matrix accounting for spatial and temporal dimensions of the DGP, it is now possible to test whether the use of a strictly spatial weights when dealing with spatial data pooled over time introduces bias in the detection tests of spatial autocorrelation and the estimated autoregressive coefficients. To make sure these results can be generalized, a Monte Carlo experiment is conducted.
4. A Monte Carlo Experiment
Given the DGP of the spatial data pooled over time, two general models, based on the different weights matrix specifications developed, can be used to generate data incorporating multidirectional spatial effect for the same time period as well as unidirectional spatial effect occurring from a previous period.
The first model assumes that the true model is given by a linear specification in the parameters (Equation (12)). This DGP can be seen as a given equation based on real indices, as opposed to the nominal indices, where the dependent variable  has the same base value (or definition) for all the time periods.
has the same base value (or definition) for all the time periods.
 (12)
(12)
where  is the vector of dependent variable of dimension
is the vector of dependent variable of dimension ,
,  is a vector of independent variable of dimension
is a vector of independent variable of dimension , that can be seen as resulting from a principal component analysis (PCA) summarizing all the pertinent information in a unique variable,
, that can be seen as resulting from a principal component analysis (PCA) summarizing all the pertinent information in a unique variable,  is a vector of spatially dependent error term of dimension
is a vector of spatially dependent error term of dimension  and
and  is a vector of independent and identically distributed error term of dimension
is a vector of independent and identically distributed error term of dimension .
.
Another specification of the model can be based on a nominal value instead of a real value index. In such a situation, it is common practice to introduce a time trend  variable (or a matrix of dummy variables for the full time period) to control for temporal heterogeneity and the nominal aspect of the dependent variable [28] (Equation (13)).
variable (or a matrix of dummy variables for the full time period) to control for temporal heterogeneity and the nominal aspect of the dependent variable [28] (Equation (13)).
 (13)
(13)
where  is a vector of the trend variable taking a value of 0 in the first period, a value of one in the second period, a value of 2 in the third period and so on. The
is a vector of the trend variable taking a value of 0 in the first period, a value of one in the second period, a value of 2 in the third period and so on. The  parameter is the coefficient that measures the mean growth rate over the whole sample period.
parameter is the coefficient that measures the mean growth rate over the whole sample period.
In both specifications, the weights matrices ,
,  and
and , all of dimension
, all of dimension  are, respectively, a spatial weights matrix accounting for the spatial multidirectional relations occurring in the same time period, a spatio-temporal weights matrix accounting for the spatial unidirectional relations occurring from the observa- tions collected in the previous time period and a spatial weights matrix controlling for a constant spatial latent component4.
are, respectively, a spatial weights matrix accounting for the spatial multidirectional relations occurring in the same time period, a spatio-temporal weights matrix accounting for the spatial unidirectional relations occurring from the observa- tions collected in the previous time period and a spatial weights matrix controlling for a constant spatial latent component4.
The  coefficient represents the usual spatial spillover effect for the actual time period, the
coefficient represents the usual spatial spillover effect for the actual time period, the  coefficient measures the unidirectional spatial effect, which can be seen as a (temporal) dynamic effect spatially located, while the
coefficient measures the unidirectional spatial effect, which can be seen as a (temporal) dynamic effect spatially located, while the  coefficient measures the intensity of the spatial autoregressive process related to the error term, which can be seen as an omitted spatial fixed component capturing the latent spatial structure of the DGP. Finally, the
coefficient measures the intensity of the spatial autoregressive process related to the error term, which can be seen as an omitted spatial fixed component capturing the latent spatial structure of the DGP. Finally, the  coefficient is the marginal effect of the independent variable on the dependent variable. Given the size of the vectors (or matrix) of variables (dependent and independent), all coefficients are scalars in this framework.
coefficient is the marginal effect of the independent variable on the dependent variable. Given the size of the vectors (or matrix) of variables (dependent and independent), all coefficients are scalars in this framework.
In the model, the variable  is known and assumed exogenous since it is based on previous observations. This variable synthesizes the mean outcome of the dependent variable occurring one
is known and assumed exogenous since it is based on previous observations. This variable synthesizes the mean outcome of the dependent variable occurring one  time period prior. These outcomes are, by definition, independent and strictly exogenous from the actual observation since a point is only observed once and the realizations are observed in previous period. However, as previously mentioned, the first
time period prior. These outcomes are, by definition, independent and strictly exogenous from the actual observation since a point is only observed once and the realizations are observed in previous period. However, as previously mentioned, the first  lines of this new variable are only composed of elements equal to zero (Equation (11))5 since the elements in the first
lines of this new variable are only composed of elements equal to zero (Equation (11))5 since the elements in the first  lines of the weights matrix,
lines of the weights matrix,  , are all equal to zero.
, are all equal to zero.
Isolating the dependent variable on the left hand side gives the final expression of the DGP (Equations (14) and (15)) which generates the true value of the dependent variable given the values of the independent variables and the error term.
 (14)
(14)
 (15)
(15)
where  is the identity matrix of dimension
is the identity matrix of dimension . Ultimately, the value of
. Ultimately, the value of  can be obtained if the geographical coordinates of the individual observations
can be obtained if the geographical coordinates of the individual observations  are available, if the time period of collection
are available, if the time period of collection  is known as well as the value of the dependent variable
is known as well as the value of the dependent variable  and the value of the error terms
and the value of the error terms .
.
For the exercise, the geographical coordinates  of the observations are simulated assuming that each coordinate is distributed from a uniform law (0,10). The temporal dimension variable,
of the observations are simulated assuming that each coordinate is distributed from a uniform law (0,10). The temporal dimension variable,  , is constructed from a continuous and intermediate time variable,
, is constructed from a continuous and intermediate time variable,  , also obtained from a uniform law (0,10). This intermediate variable is then split in ten different discrete time periods: if
, also obtained from a uniform law (0,10). This intermediate variable is then split in ten different discrete time periods: if  varies between 0 and 1, then
varies between 0 and 1, then , if
, if  varies between 1 and 2 then
varies between 1 and 2 then , and so on. These three variables are fundamental to build the spatio-temporal weights matrices,
, and so on. These three variables are fundamental to build the spatio-temporal weights matrices,  and
and . Finally, it is assumed that the independent variable,
. Finally, it is assumed that the independent variable,  , is normally distributed with a zero mean and a variance equal to nine (9). The independent error term,
, is normally distributed with a zero mean and a variance equal to nine (9). The independent error term,  is also normally distributed with a zero mean and a homoscedastic unitary variance.
is also normally distributed with a zero mean and a homoscedastic unitary variance.
Since the objective of the paper is to explore the effect of neglecting the temporal dimension of the DGP on the autoregressive parameter, the parameter  is set to one, while the parameter
is set to one, while the parameter  is set to 0.05. Only the autoregressive parameters,
is set to 0.05. Only the autoregressive parameters,  ,
,  and
and  can vary in the simulations.
can vary in the simulations.
4.1. The Estimation Method

4The spatial weights matrix  could also be replaced by the
could also be replaced by the  matrix as expressed in the Equation (11). However, this exercise has not been considered in the paper.
matrix as expressed in the Equation (11). However, this exercise has not been considered in the paper.
5This point will be considered in the next section since it introduces a false zero value in the estimation process and potential bias on the estimation of the  coefficient.
coefficient.
6Expressed otherwise, the total sample size can be written as .
.
Because the model uses a variable based on realizations recorded one period before,  it is necessary to assume that the first time period is exogenous in the simulation process. Thus, the observations related to the first time period are not used in the estimation process. Consequently, the model is not estimated using the
it is necessary to assume that the first time period is exogenous in the simulation process. Thus, the observations related to the first time period are not used in the estimation process. Consequently, the model is not estimated using the
whole sample size , but is, instead, based on
, but is, instead, based on  observations, where
observations, where . In the end, the
. In the end, the
final sample size is reduced by , the total number of observation in the first time period6.
, the total number of observation in the first time period6.
This modification is similar to the Cochrane-Orcutt transformation used to estimate a temporal autoregressive model. This procedure is also used when dealing with spatial panel data or panel data. Since it is impossible to have information on the initial time period , this transformation is necessary to avoid false zero values in
, this transformation is necessary to avoid false zero values in
the time lag variable for  and introduce potential bias on the
and introduce potential bias on the  parameter. Thus, the vectors of variable are now of dimension
parameter. Thus, the vectors of variable are now of dimension  and the weights matrices are of dimension
and the weights matrices are of dimension .
.
For the subsequent time period , the model can be estimated using the maximum likelihood procedure [29] . However, this procedure can have some minor effect on the precision of the estimation of the parameter
, the model can be estimated using the maximum likelihood procedure [29] . However, this procedure can have some minor effect on the precision of the estimation of the parameter  since some observations can be dropped from the full nearest neighbors matrix. However, the subtraction of about one-ten of the full sample should not be overly significant.
since some observations can be dropped from the full nearest neighbors matrix. However, the subtraction of about one-ten of the full sample should not be overly significant.
4.2. The Values of the Parameters
The results are based on 1000 simulations of 1000 observations  for the endogenous variable
for the endogenous variable 
for the two GDP (12) and (13) and imply different values of the parameters ,
,  and
and . The values of the parameter
. The values of the parameter  and
and  are set to 0.1; 0.3; 0.5 and 0.7, while the parameter
are set to 0.1; 0.3; 0.5 and 0.7, while the parameter  can take values of 0.1; 0.2; and 0.3. These values are in line with what previous study found to be the estimated values of the dynamic spatially located dependent variable [8] [9] [30] [31] , while it ensure that the sum of the autoregressive parameter on the dependent variable is still lower then one
can take values of 0.1; 0.2; and 0.3. These values are in line with what previous study found to be the estimated values of the dynamic spatially located dependent variable [8] [9] [30] [31] , while it ensure that the sum of the autoregressive parameter on the dependent variable is still lower then one .
.
For the DGP, the weights matrices are chosen as follows:
the spatial weights matrix,  , is based on the ten (10) nearest neighbors,the matrix;
, is based on the ten (10) nearest neighbors,the matrix;
the spatial weights matrix accounting for multidirectional spatial effect of the dependent variable,  , is based on a negative exponential transformation of the distances separating all observations
, is based on a negative exponential transformation of the distances separating all observations  and
and  occurring in the same time period
occurring in the same time period ;
;
the spatial weights matrix accounting for unidirectional (dynamic) spatial effect of the dependent variable,  , is also based on a negative exponential transformation of the distances separating an observation
, is also based on a negative exponential transformation of the distances separating an observation  collected in time period
collected in time period  and another observation
and another observation  occurring in the next time period
occurring in the next time period .
.
It should be noted that both spatio-temporal weights matrices,  and
and , are constructed using a general spatial weights matrix and using the block diagonal decomposition (see the previous section). Thereafter, the different models (Equations (12) and (13)) are estimated assuming that: i) the usual spatial econometric model is used and no time lag variable is introduced7; and ii) the model is estimated using the spatio-temporal con- siderations of the DGP.
, are constructed using a general spatial weights matrix and using the block diagonal decomposition (see the previous section). Thereafter, the different models (Equations (12) and (13)) are estimated assuming that: i) the usual spatial econometric model is used and no time lag variable is introduced7; and ii) the model is estimated using the spatio-temporal con- siderations of the DGP.
5. Results

7The variable  is not used and the
is not used and the  weights matrix is replaced by the usual full spatial weights matrix,
weights matrix is replaced by the usual full spatial weights matrix, .
.
8The formula for the Moran's index is:  where
where  are the residuals of the regression.
are the residuals of the regression.
The first conclusion is related to the use of the Moran’s  index8. For low values of
index8. For low values of  and
and , the results clearly suggest that these statistics are not biased toward rejection of the null hypothesis of absence of spatial autocorrelation, as previously proposed by Dubé and Legros (2013) [9] . In fact, when all the autoregressive coefficients are low, including the parameter
, the results clearly suggest that these statistics are not biased toward rejection of the null hypothesis of absence of spatial autocorrelation, as previously proposed by Dubé and Legros (2013) [9] . In fact, when all the autoregressive coefficients are low, including the parameter , the index estimated is lower using a spatial weights matrix instead of the spatio-temporal weights matrix (Table 1 and Table 2). However, the estimated variance of the Moran’s
, the index estimated is lower using a spatial weights matrix instead of the spatio-temporal weights matrix (Table 1 and Table 2). However, the estimated variance of the Moran’s  is also lower. In fact, the lower estimate variance has an important effect for high values of
is also lower. In fact, the lower estimate variance has an important effect for high values of ,
,  and
and . In this context, the low variance has an important incidence on the over estimation of the Moran's
. In this context, the low variance has an important incidence on the over estimation of the Moran's  statistic towards systematic rejection of the null hypothesis. This is where the findings of [9] really apply. The conclusions are identical given the specification used (Equations (12) and (13)).
statistic towards systematic rejection of the null hypothesis. This is where the findings of [9] really apply. The conclusions are identical given the specification used (Equations (12) and (13)).
Turning our attention to the coefficients, the effect of spatial specification in a spatio-temporal context can be
analyzed through the usual statistics such as the bias, which is defined as , where
, where  is the real value
is the real value
of the parameter of interest and  is the estimation of the parameter
is the estimation of the parameter  obtained with the Monte Carlo simu-
obtained with the Monte Carlo simu-
lations, and the mean square error (MSE), defined as . The first statistic allows to compare the
. The first statistic allows to compare the
capability of the model to return the right answer, while the MSE allows to measure the precision of the estima- tion.

Table 1. Synthesis of results for the Moran’s I index (Model 1).
Legend: Moran’s I index (first line); Variance of I in italic (second line); t-stat in bold (third line).
Table 2. Synthesis of results for the Moran’s I index (Model 2).
Firstly, the results show that according to low values of the autoregressive coefficients 
the bias is quite low when ones use spatial weights matrix instead of the spatio-temporal weights matrices, and this for both specifications (Equations (12) and (13)). However, as soon as the values of these parameters increase, the bias also increase (Table 3 and Table 4). The biases are low for the  coefficient, but quickly rise for all the other parameters. This may be quite problematic if the real specification is based on a spatial autoregressive (SAR) model since the indirect and total marginal effect are largely based on two main com- ponents: the weights matrix, and the estimated autoregressive coefficient [4] [32] .
coefficient, but quickly rise for all the other parameters. This may be quite problematic if the real specification is based on a spatial autoregressive (SAR) model since the indirect and total marginal effect are largely based on two main com- ponents: the weights matrix, and the estimated autoregressive coefficient [4] [32] .
Table 3. Synthesis of the bias on the parameter-spatial vs. spatio-temporal consideration (Model 1).
Table 4. Synthesis of the bias on the parameter-spatial vs. spatio-temporal consideration (Model 2).
Secondly, the MSE follows a pattern similar to the one of the bias (Table 5 and Table 6). The MSE is comparable within the spatial and spatio-temporal specifications with low values of ,
,  and
and , while it clearly becomes larger for spatial specifications for higher values of the autoregressive parameters.
, while it clearly becomes larger for spatial specifications for higher values of the autoregressive parameters.
There is a simple way to visualize this conclusion: building a graph of the estimated values of the parameters in each simulation according to the specification selected. Conducting this analysis reinforces the conclusions drawn before (Figures 7-10). First, there is a clear bias in the estimated  coefficient for the specification without trend (Equation (12)), even more for low values of
coefficient for the specification without trend (Equation (12)), even more for low values of  (Figure 7-left panel). For the higher value of
(Figure 7-left panel). For the higher value of , the bias is insignificant, but the precision is clearly affected. For the model introducing a trend, the conclusion is somewhat different: there is no clear bias in the estimated
, the bias is insignificant, but the precision is clearly affected. For the model introducing a trend, the conclusion is somewhat different: there is no clear bias in the estimated  coefficient, but the estimation of the parameter is clearly imprecise for high values of the autoregressive coefficients.
coefficient, but the estimation of the parameter is clearly imprecise for high values of the autoregressive coefficients.
As regards the  coefficient, the parameter is unbiased with low values of the autoregressive parameters (
coefficient, the parameter is unbiased with low values of the autoregressive parameters ( ,
, and
and ), and this, for both specifications (Figure 8). For high values of
), and this, for both specifications (Figure 8). For high values of  in the specification without trend (Equation (12)), the estimation of
in the specification without trend (Equation (12)), the estimation of  is clearly downward biased. Moreover, the estimation of the parameter is quite imprecise, as shown by the important variation of the grey line. Once again, the conclusion is different considering the specification with a trend (Equation (13)): except for the case of high values of
is clearly downward biased. Moreover, the estimation of the parameter is quite imprecise, as shown by the important variation of the grey line. Once again, the conclusion is different considering the specification with a trend (Equation (13)): except for the case of high values of  and
and , there is no evidence of bias in the estimation of
, there is no evidence of bias in the estimation of . However, for high values of the autoregressive coefficient, the imprecision of the estimation is clear.
. However, for high values of the autoregressive coefficient, the imprecision of the estimation is clear.
For the  coefficient, imprecision is noted in all scenarios (Figure 9). An important bias emerges with larger values of
coefficient, imprecision is noted in all scenarios (Figure 9). An important bias emerges with larger values of . In fact, the spatial specification is not able to distinguish between the spatial multidirectional effect, as measured by the
. In fact, the spatial specification is not able to distinguish between the spatial multidirectional effect, as measured by the  coefficient in (12) or (13), and the unidirectional spatial effect, measured by
coefficient in (12) or (13), and the unidirectional spatial effect, measured by . Thus, the important bias comes from the addition of both effect in the unique
. Thus, the important bias comes from the addition of both effect in the unique  coefficient in the strictly spatial specification. Moreover, as long as the values of the autoregressive coefficients increase, the imprecision increase. The worst case is noted in the specification (13) with high values of
coefficient in the strictly spatial specification. Moreover, as long as the values of the autoregressive coefficients increase, the imprecision increase. The worst case is noted in the specification (13) with high values of  and
and : in both cases, the
: in both cases, the

Figure 7. Distribution of the estimated coefficient.

Figure 8. Distribution of the estimated coefficient .
.

Figure 9. Distribution of the estimated coefficient .
.
Table 5. Synthesis of the mean square error (MSE) on the parameter-spatial vs spatio-temporal consideration (Model 1).
Table 6. Synthesis of the mean square error (MSE) on the parameter-spatial vs spatio-temporal consideration (Model 2).

Figure 10. Distribution of the estimated coefficient .
.
estimation of the coefficient is highly volatile and imprecise.
Finally, turning our attention to the model introducing a trend (Equation (13)), it can be explained why there is no overestimation of the  coefficient using the spatial weights matrix. The coefficient is, except for low values of autoregressive coefficients, biased towards over estimation (Figure 10). For high values of
coefficient using the spatial weights matrix. The coefficient is, except for low values of autoregressive coefficients, biased towards over estimation (Figure 10). For high values of , the
, the  coefficient is highly imprecise and upwardly biased.
coefficient is highly imprecise and upwardly biased.
In almost all cases, the estimated coefficients obtained with the strictly spatial considerations (the grey lines) are clearly wider that the estimated coefficients obtained when dealing with the spatio-temporal structure of the data (the black lines and bars). The form of the distributions is concentrated around the true value of the parameters, suggesting an absence of bias, but the distributions are clearly spread out and imprecise when only spatial consideration is accounted for. Moreover, the distributions of the autoregressive parameter  are really imprecise using the spatial weight matrix, going from negative values to unit root (and more than unit root value). Thus, neglecting the temporal dimension of spatial data pooled over time can lead to possible unit root problems, as noted by [8] , presenting an additional problem.
are really imprecise using the spatial weight matrix, going from negative values to unit root (and more than unit root value). Thus, neglecting the temporal dimension of spatial data pooled over time can lead to possible unit root problems, as noted by [8] , presenting an additional problem.
Lastly, the Monte Carlo experiments clearly underline the importance of taking into account the accumulation process of the spatial data pooled over time. Ignoring the temporal dimension of the DGP can lead to important bias in the detection of a spatial autocorrelation pattern as well as introduce large variability in the estimated coefficients and potential bias for high values of ,
,  and
and . These results are of primal importance given the fact that the usefulness of the statistical models is to evaluate the effect of a given independent variable on the dependent variable and given the fact that the marginal effect in a spatial autoregressive model can be broken down into two components: a direct effect (the usual interpretation of the
. These results are of primal importance given the fact that the usefulness of the statistical models is to evaluate the effect of a given independent variable on the dependent variable and given the fact that the marginal effect in a spatial autoregressive model can be broken down into two components: a direct effect (the usual interpretation of the  coefficient), and an indi- rect spatial spillover effect (based on the estimation of the
coefficient), and an indi- rect spatial spillover effect (based on the estimation of the , and
, and , coefficient) [4] .
, coefficient) [4] .
6. Conclusions
This paper endeavours to investigate the effect of adopting a spatial specification of a model when data consist of spatial data pooled over time. By presenting the particularities of the data generating process (DGP) of the individual spatial unit pooled over time, we present a simple way to account for the particularity of the multi- directional spatial relations for a given time period, as well as accounting for the unidirectional spatial relation from realizations observed in the time period before the actual realizations. Such decomposition can be transposed in the weights matrix to correctly capture the different relations.
Given the DGP representation, a Monte Carlo experiment framework is developed and used to evaluate the effect of adopting a purely spatial representation when data consist of individual spatial units collected over time. The results clearly conclude that using a spatial specification can lead to a potential serious problem on the estimated coefficients, as well as for the autoregressive parameters. If the inclusion of a general trend variable in the spatial specification helps to reduce potential biases on some estimated coefficients, the results show that it is far from solving all the problems. In fact, the estimation of the coefficient associated with the trend can be highly biased. This may be of primal importance if the coefficient of interest is the trend itself.
The results also confirm that, to some extent, some previous results in the literature suggesting that ignoring the spatio-temporal structure can lead to erroneous decisions on the amplitude of the detected spatial auto- correlation, while exploring the decomposition of this conclusion according to the amplitude of the autoregressive coefficients [9] . In fact, to assume that the temporal dimension of the data is neutral and doesn’t affect the detection of spatial autocorrelation among residuals is clearly false. Taking account of the spatial structure alone always leads to a strong bias towards rejection of the null assumption of absence of spatial autocorrelation. This is so because the estimation of the variance of the Moran’s  index is under evaluated, leading to the overesti- mation of the
index is under evaluated, leading to the overesti- mation of the  score statistic and to the overrejection of the null hypothesis of no spatial autocorrelation.
score statistic and to the overrejection of the null hypothesis of no spatial autocorrelation.
The exercise clearly points toward the necessity of accounting for the structure of the data generating process (DGP) when dealing with spatial data pooled over time. The effect of time is non-neutral, at least for an impor- tant temporal desegregation. Since spatial econometrics modeling is gaining in popularity and many softwares now offer packages to perform tests and estimations, these conclusions are fundamental for empirical analysis. Given the fact that the goal of the econometric applications remains the same, identifying the marginal mean effect of a given variable on a particular outcome, the conclusions drawn in this paper should be of primal importance for those who work with spatial data pooled over time, such as in real estate analysis, crime detec- tion, business startup and closings and so on.
Statistical tools are really useful for researchers, however, the conclusions of the analysis show how the performance of such tools may fail to adequately measure the desired effect when one is working with spatial data pooled over time.
However, what is less clear, for now, is to identify what happens when the independent variables are also correlated over space and time and how this spatial structure can be decomposed. There is also a lack of actual analyses on determining the effect of the length of the temporal dimension on the possible amplitude of the bias. Moreover, as it is the case with spatial data (the modifiable Areal Unit Problem-MAUP), the effect of the temporal desegregation on the results needs to be explored in detail since this can also have potential effects on the estimated coefficients.
References
- Gosset, W.S. (1914) The Elimination of Spurious Correlation Due to Position in Time or Space. Biometrika, 10, 179- 180.
- Anselin, L. and Bera, A.K. (1998) Spatial Dependence in Linear Regression Models with an Introduction to Spatial Econometrics. Statistics: Textbooks and Monographs, 155, 237-289.
- Griffith, D.A. (2005) Effective Geographic Sample Size in the Presence of Spatial Autocorrelation. Annals of the Association of American Geographers, 95, 740-760. http://dx.doi.org/10.1111/j.1467-8306.2005.00484.x
- LeSage, J. and Pace, K.R. (2009) Introduction to Spatial Econometrics. Chapman and Hall/CRC, London.
- LeSage, J.P. and Pace, R.K. (2004) Models for Spatially Dependent Missing Data. The Journal of Real Estate Finance and Economics, 29, 233-254. http://dx.doi.org/10.1023/B:REAL.0000035312.82241.e4
- Anselin, L. (2010) Thirty Years of Spatial Econometrics. Papers in Regional Science, 89, 3-25. http://dx.doi.org/10.1111/j.1435-5957.2010.00279.x
- Arbia, G. (2011) A Lustrum of SEA: Recent Research Trends Following the Creation of the Spatial Econometrics Association. Spatial Economic Analysis, 6, 377-395.
- Dubé, J. and Legros, D. (2013) Dealing with Spatial Data Pooled over Time in Statistical Models. Letters in Spatial and Resource Sciences, 6, 1-18. http://dx.doi.org/10.1007/s12076-012-0082-3
- Dubé, J. and Legros, D. (2013) A Spatio-Temporal Measure of Spatial Dependence: An Example Using Real Estate Data. Papers in Regional Science, 92, 19-30.
- Huang, B., Huang, W. and Barry, M. (2010) Geographically and Temporally Weighted Regression for Modeling Spatio-Temporal Variation in House Prices. International Journal of Geographical Information Science, 24, 383-401. http://dx.doi.org/10.1080/13658810802672469
- Smith, T. and Wu, P. (2009) A Spatio-Temporal Model of Housing Prices Based on Individual Sales Transactions over Time. Journal of Geographical Systems, 11, 333-355. http://dx.doi.org/10.1007/s10109-009-0085-9
- Moran, P. (1950) A Test for the Serial Independence of Residuals. Biometrika, 37, 178-181. http://dx.doi.org/10.1093/biomet/37.1-2.178
- Dubé, J., Thériault, M. and Des Rosiers, F. (2012) Using a Fourier Polynomial Expansion to Generate a Spatial Predictor. International Journal of Housing Market and Analysis, 5, 177-195. http://dx.doi.org/10.1108/17538271211225922
- Legendre, P. (1993) Spatial Autocorrelation: Trouble or New Paradigm? Ecology, 74, 1659-1673. http://dx.doi.org/10.2307/1939924
- Getis, A. and Aldstadt, J. (2004) Constructing the Spatial Weights Matrix Using a Local Statistic. Geographical Analysis, 36, 90-104. http://dx.doi.org/10.1111/j.1538-4632.2004.tb01127.x
- Haining, R. (2009) The Special Nature of Spatial Data. In: Fotheringham, A.S. and Rogerson, P.A., Eds., The Sage Handbook of Spatial Analysis, Sage, Thousand Oaks, 5-24.
- Pinkse, J. and Slade, M.E. (2010) The Future of Spatial Econometrics. Journal of Regional Science, 50, 103-117. http://dx.doi.org/10.1111/j.1467-9787.2009.00645.x
- McMillen, D.P. (2010) Issues in Spatial Data Analysis. Journal of Regional Science, 50, 119-141. http://dx.doi.org/10.1111/j.1467-9787.2009.00656.x
- Tobler, W. (1970) A Computer Movie Simulating Urban Growth in the Detroit Region. Economic Geography, 46, 234- 240. http://dx.doi.org/10.2307/143141
- McMillen, D.P. and McDonald, J.F. (2004) Locally Weighted Maximum-Likelihood Estimation: Monte Carlo Evidence and an Application. In: Anselin, L., Florax, R. and Rey, S.J., Eds., Advances in Spatial Econometrics: Methodology, Tools and Applications, Springer, Heidelberg, 225-240.
- LeSage, J. (2003) A Family of Geographically Weighted Regression Models. In: Anselin, L., Florax, R. and Rey, S.J., Eds., Advances in Spatial Econometrics: Methodology, Tools and Applications, Springer, Heidelberg, 241-278.
- Fotheringham, A.S., Brunsdon, C. and Charlton, M. (1998) Geographical Weighted Regression: A Natural Evolution of the Expansion Method for Spatial Data Analysis. Environment and Planning A, 30, 1905-1927. http://dx.doi.org/10.1068/a301905
- Fotheringham, A.S., Brunsdon, C. and Charlton, M. (2002) Geographically Weighted Regression: The Analysis of Spatially Varying Relationships. Wiley, Hoboken.
- Hégerstrand, T. (1970) What about People in Regional Science? Papers of the Regional Science Association, 24, 7-21.
- Dubé, J., Baumont, C. and Legros, D. (2011) Utilisation des matrices de pondérations en économétrie spatiale: Proposition dans un contexte spatio-temporel. Discussion Paper e2011-01, Laboratoire d’ Économie et de Gestion, Université de Bourgogne, Dijon.
- Pace, K.R., Barry, R., Clapp, J.M. and Rodriguez, M. (1998) Spatiotemporal Autoregressive Models of Neighborhood Effects. Journal of Real Estate Finance and Economics, 17, 15-33. http://dx.doi.org/10.1023/A:1007799028599
- Pace, K.R., Barry, R., Gilley, W.O. and Sirmans, C.F. (2000) A Method for Spatial-Temporal Forecasting with an Application to Real Estate Prices. International Journal of Forecasting, 16, 229-246. http://dx.doi.org/10.1016/S0169-2070(99)00047-3
- Wooldridge, J.M. (2001) Econometric Analysis of Cross Section and Panel Data. The MIT Press, Cambridge.
- LeSage, J. (1999) Spatial Econometrics. The Web Book of Regional Science, Regional Research Institute, West Virginia University, Morgantown.
- Des Rosiers, F., Dubé, J. and Thériault, M. (2011) Do Peer Effects Shape Property Values? Journal of Property Investment & Finance, 29, 510-528. http://dx.doi.org/10.1108/14635781111150376
- Dubé, J. and Legros, D. (2014) Spatial Data and Econometrics. Wiley-ISTE, Hoboken.
- LeSage, J. and Fischer, M. (2009) Spatial Growth Regressions: Model Specification, Estimation and Interpretation. Spatial Economic Analysis, 3, 275-304. http://dx.doi.org/10.1080/17421770802353758
NOTES

1Or very few. It is common, when one point is repeated twice, to assume that this recurrence is strictly related to hazard.

2This could also be the case for some (or all) independent variables. However, this possibility is not treated here.

3Of course, there are many definitions of the distance that can be used. We only consider the Euclidian distance here, but the demonstration can be generalized to all other distances, such as the Manhattan distance or the network distance. For computing distances between observations, we use the software MATLAB and the J. Lesage’s Spatial Econometrics library.