Journal of Mathematical Finance
Vol.08 No.02(2018), Article ID:85004,19 pages
10.4236/jmf.2018.82030
A Co-Integration Analysis of the Interdependencies between Crude Oil and Distillate Fuel Prices
Jane Aduda1, Patrick Weke2, Philip Ngare2
1Department of Statistics and Actuarial Sciences, Jomo Kenyatta university of Agriculture and Technology, Nairobi, Kenya
2School of Mathematics, University of Nairobi, Nairobi, Kenya
Copyright © 2018 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: October 16, 2017; Accepted: March 28, 2018; Published: March 31, 2018
ABSTRACT
The co-evolution and co-movement of financial time series is of utmost importance in contemporary finance, especially when considering the joint behaviour of asset price realizations. The ability to model interdependencies and volatility spill-over effects introduces interesting dimensions in finance. This paper explores co-integrating relationships between crude oil and distillate fuel prices. Existence of multivariate co-integrating relations and bidirectional Granger-Causality is established among the series. It is also established that even after fitting a full VECM, the residuals are not necessarily multivariate normal suggesting the noise could as well be multivariate GARCH.
Keywords:
Co-Integration, Futures and Spot Prices, Granger-Causality, ECM, VECM, Volatility Spill-Over, Johansen’s Test, Engle-Granger Test

1. Introduction
In empirical finance, most realistic applications are actually multivariate in nature. The co-evolution and covariation between the prices of financial assets is essentially important in Finance. Often, the interest is not merely in the behaviour of a single stock but rather in the joint behaviour of several stocks, and such joint behaviour is described using multivariate distributions. Multivariate analysis provides a framework for describing the properties of individual series as well as any possible correlations among series that are interrelated both contemporaneously and across time lags [1]. Co-integration, which provides a sound methodology for modelling both short-run and long-run dynamics in a system, has emerged as a powerful technique for investigating common trends in multivariate time series [2]. It was developed as a means of modelling dynamic co-dependencies in multivariate time series [3] and it deals with the common behaviour of a multivariate time series where each component series may be non-stationary, but certain linear combinations of these components are stationary [3].
Co-integrated processes are characterized by short-term dynamics and long-run equilibria. Economic theory supposes a long term pricing relationship between prices of crude oil and revenues from distillate fuels. This implies that profit spreads tend to converge to a long term average. Co-integration theory, is useful in estimating and testing long-term equilibrium relationships among non-stationary asset prices and making meaningful statistical inference. Co-integrated series have stationary co-integrating residuals, and various spreads will be stationary [4]. This study uses co-integration to analyse the long-term equilibrium relationship between the prices of crude oil and the distillate fuels. The findings from this study will aid in gaining insights into the interdependencies between energy input and output products, information which is useful in portfolio diversification from the refiner’s perspective, both for purposes of profit maximization and risk management.
The positive correlation of price variations or volatility clustering, evidenced in speculative markets motivated the introduction of the autoregressive conditional heteroscedastic (ARCH) process by Engle [5] , and it’s generalization to the generalised autoregressive conditional heteroscedastic (GARCH) by Bollerslev [6] later. Given their univariate nature, these models neglect the possibility of any further information embedded in multiple measurements with temporal and cross-sectional dependence in empirical stock price variation and the contemporaneous cross correlation implied by economic theory, such as a set of asset prices, exchange and interest rates, stock market indices among other macroeconomic variables.
For dynamic volatilities, multivariate models provide the natural framework to account for cross sectional information. Haigh and Holt [7] employ a Multivariate GARCH (MGARCH) model that allows direct incorporation of the time to maturity effect in accounting for the time-varying volatility spill overs between related markets when considering the possibility of hedging crude oil, unleaded gasoline and heating oil price risk simultaneously in a time varying setting. Their results show the importance of cross market linkages between crude oil, unleaded gasoline and heating oil markets. Veiga and McAleer [8] use the vector autoregressive moving average asymmetric generalised autoregressive conditional heteroscedasticity (VARMA-AGARCH) model of Hoti et al. [9] to show the existence of volatility spillovers between the Standard & Poor’s 500 Index (S & P 500), the Financial Times Stock Exchange 100 Index (FTSE 100) and Nikkei 225.
This study builds on the work of Aduda et al. [10] in detailing empirical analysis of financial time series data. Official daily closing prices from the trading floor of the New York Mercantile Exchange (NYMEX) for a specific delivery month for Cushing Oklahoma West Texas Intermediate (OK WTI), Reformulated Blendstock for Oxygenate Blending (RBOB), and the number 1 heating oil futures contracts are considered. The existence of co-integration is established and causal relationships are investigated. The analysis is done using MATLAB [11] and R. The rest of the document is organized as follows: Section 2 discuses the methods used in empirical analysis, Section 3 gives a brief discussion of the data used, and the empirical analysis and the results obtained and finally Section 4 gives a summary of the work and the findings.
2. Methodology
In this section, we test for cointegration using the trace test, fit a full VECM and test for Grangercausality. The Durbin-Watson (D-W) is also used to check for spurious regression.
2.1. Co-Integration
The error processes from two non-stationary series can be represented as a combination of two cumulated error processes. These cumulated error processes form stochastic trends which produce another non-stationary process if combined. If two series, say xt and yt, are related, they would be expected to move together and their two stochastic trends would be similar. If when combined, it would be possible to find a combination of them which eliminates the non-stationarity, then the two series would be co-integrated.
Co-integrated series evolve together, staying close to each other, even if individually, their systems drift about. If the series are not co-integrated, then, their spreads can deviate without bounds and spread trading for risk management would not be optimal [4]. If spreads are mean-reverting, and asset prices are tied together by a common stochastic trend in the long-term, then, the prices are said to be co-integrated. This means there are system feedbacks that keep variables mutually aligned [12]. Co-integration simply augments correlation analysis to include a first stage where the price data are analysed and a second stage that includes dynamic analysis of correlations which inform about any lead-lag behaviour between returns [13].
According to Engle and Granger [14] , two series {xt} and {yt} are co-integrated if 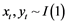 but there exists α such that
but there exists α such that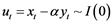 . Generally, the variables in a k-dimensional process {pt} are called co-integrated of order (d,b), written briefly as,
. Generally, the variables in a k-dimensional process {pt} are called co-integrated of order (d,b), written briefly as, 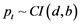 , if all components of {pt} are I(d) and there exists a linear combination
, if all components of {pt} are I(d) and there exists a linear combination 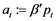 with
with 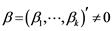 such that
such that 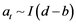 [15]. It is possible to have up to n − 1 linearly independent co-integration vectors.
[15]. It is possible to have up to n − 1 linearly independent co-integration vectors.
Co-integration analysis seeks to detect any common stochastic trends in price data and use these trends for dynamic analysis of correlations in returns, through, the error correction model (ECM). If two variables are I(1) and co-integrated, they can be modelled as having been generated by an ECM which corrects the deviations from the long-run equilibrium [2]. Multivariate time series are best considered as components of some vector-valued process {pt}, which has both serial dependence within each component of the series {pti} and interdependence between different components {pti} and {ptj}, for 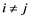 [3] [16].
[3] [16].
For a k−dimensional time series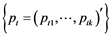 , the mean vector is defined by
, the mean vector is defined by 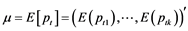 and the covariance matrix
and the covariance matrix 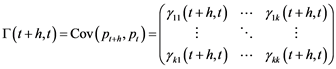 where
where 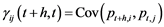 .
.
This which can be written in compact form as
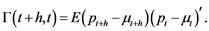 (1)
(1)
The diagonal elements of the matrix in equation (1) are the auto-covariance functions of the univariate series {pti}, whereas the off-diagonal elements are the cross-covariances between pt+h,i and pt,j,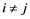 . Note also that
. Note also that 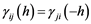
and the autocorrelation matrix is then defined as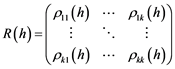 , where the cross-correlation function
, where the cross-correlation function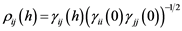 . Unlike
. Unlike
the case of univariate stationary time series for which the auto-covariances of lag h and lag −h are identical, one must take the transpose of a positive-lag cross-covariance matrix to obtain the negative-lag cross-covariance matrix.
The cross-covariance matrices Γ(h) and cross-correlation matrices ρ(h) are positive definite since 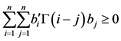 for all positive integers n and all k−dimensional vectors
for all positive integers n and all k−dimensional vectors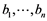 , which follows since
, which follows since .
.
2.2. Error Correction Model
The time paths of co-integrated variables are influenced by the extent of any deviation from long-run equilibrium. In any case, for the system to return to the long-run equilibrium, the movements of at least some of the variables must respond to the magnitude of the disequilibrium. These movements are captured using an ECM. When two random walk I(1) variables are co-integrated, an ECM can be formulated to study their short-run dynamics as influenced by the deviations from equilibrium [17]. An ECM is a dynamic model in which the movement of a variable in any period is related to the previous period’s departure from the long-run equilibrium. In such a model, the changes in a variable depend on the deviations from some equilibrium relation [15].
Consider a simple long-term equilibrium model
 (2)
(2)
A simple dynamic model of short-run adjustment is given by
 (3)
(3)
where , γ0 denotes the short-term reaction of yt to changes in xt. This implies that in the long run elasticity between y and x, assuming
, γ0 denotes the short-term reaction of yt to changes in xt. This implies that in the long run elasticity between y and x, assuming , is
, is . However, with this form of the dynamic model, there are several
. However, with this form of the dynamic model, there are several
potential problems including the likelihood of a high level of correlation between current and lagged values of a variable, which will result in problems such as multicollinearity, non-standard distributed parameter estimates and spurious correlation [18]. These problems could be solved by estimating the first differences of Equation (3) to obtain . This, however, introduces problems of loss of information about the long-run equilibrium. A more suitable approach is to adopt the ECM, which is set up by subtracting yt − 1 from both sides of the short-run model in Equation (3) and further subtracting γ0xt − 1 from both sides of the resulting equation and then re-parametrizing to give
. This, however, introduces problems of loss of information about the long-run equilibrium. A more suitable approach is to adopt the ECM, which is set up by subtracting yt − 1 from both sides of the short-run model in Equation (3) and further subtracting γ0xt − 1 from both sides of the resulting equation and then re-parametrizing to give
 (4)
(4)
if we take  and
and . This representation now incorporates
. This representation now incorporates
both short-run and long-run effects so that should the equilibrium hold, then the term  indicating a period of disequilibrium will equal 0. The introduction of this equilibrium error of the previous period as an explanatory variable in this representation allows movement into a new equilibrium. The term
indicating a period of disequilibrium will equal 0. The introduction of this equilibrium error of the previous period as an explanatory variable in this representation allows movement into a new equilibrium. The term  measures the speed of adjustment back to the long-term equilibrium depicted by Equation (2). For the system to converge to equilibrium, the coefficient of zt − 1 must be negative. If the values of
measures the speed of adjustment back to the long-term equilibrium depicted by Equation (2). For the system to converge to equilibrium, the coefficient of zt − 1 must be negative. If the values of , it indicates that economic agents eliminate large percentages of disequilibrium in each period, if
, it indicates that economic agents eliminate large percentages of disequilibrium in each period, if , it indicates that adjustment is slow and values close to 2, indicate an overshooting of economic equilibrium. Positive values would imply that the system diverges from the long-run equilibrium path. zt here is the disequilibrium error or the co-integrating residual. The expected value of zt defines a long term equilibrium relationship between xt and yt and the periods of disequilibrium occur as the observed value of zt varies around its expected value.
, it indicates that adjustment is slow and values close to 2, indicate an overshooting of economic equilibrium. Positive values would imply that the system diverges from the long-run equilibrium path. zt here is the disequilibrium error or the co-integrating residual. The expected value of zt defines a long term equilibrium relationship between xt and yt and the periods of disequilibrium occur as the observed value of zt varies around its expected value.
All terms in the ECM are stationary, so standard regression techniques are valid, assuming co-integration and that we have estimates for β0 and β1 [18]. According to Engle and Granger [14] , if , then an ECM must exist, and conversely, the ECM generates a co-integrated series.
, then an ECM must exist, and conversely, the ECM generates a co-integrated series.
The ECM can also be specified in multivariate form. In order to do this, we consider vector autoregressive and moving average (VARMA) or multivariate autoregressive and moving average (MARMA) models. A general V ARMA (pq) is written as
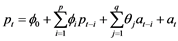 (5)
(5)
with p and q ≥ 0, ϕ0 = k-dimensional constant vector, ϕi and θj = k × k constant matrices and . Using the back shift operator, we can write
. Using the back shift operator, we can write  where
where  and
and  are matrix polynomials in B. In a vector autoregressive (VAR) model, each variable is expressed by its own lagged values and the lagged values of all the other variables in the system. If the variables are co-integrated vector autoregressive (CVAR), we also include the co-integrating vectors that pull the entire system towards a long run equilibrium. When the variables of a VAR model are co-integrated, we use a vector error correction model (VECM).
are matrix polynomials in B. In a vector autoregressive (VAR) model, each variable is expressed by its own lagged values and the lagged values of all the other variables in the system. If the variables are co-integrated vector autoregressive (CVAR), we also include the co-integrating vectors that pull the entire system towards a long run equilibrium. When the variables of a VAR model are co-integrated, we use a vector error correction model (VECM).
Co-integrated variables are generally unstable in their levels, but exhibit mean-reverting “spreads” (generalized by the co-integrating relation) that force the variables to move around common stochastic trends. Modification of the VAR model to include co-integrated variables balances the short-term dynamics of the system with long-term tendencies. For the general VAR(p) model,
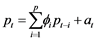 , then,
, then, 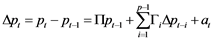
where
 and
and  If the rank r of the matrix Π is zero, there is no co-integration, no stable long-run relationship between variables and VECM is not possible, only VAR in first differences, so
If the rank r of the matrix Π is zero, there is no co-integration, no stable long-run relationship between variables and VECM is not possible, only VAR in first differences, so
that the equation  reduces to a VAR model for the differences
reduces to a VAR model for the differences . If the matrix is full rank i.e. r = k, then all the variables in
. If the matrix is full rank i.e. r = k, then all the variables in . If 0 < r < k, there are r co-integrating vectors describing the long-run relationships between variables. In this case VECM suffices, and the k × k matrix Π can be written as
. If 0 < r < k, there are r co-integrating vectors describing the long-run relationships between variables. In this case VECM suffices, and the k × k matrix Π can be written as
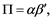 (6)
(6)
where α and β are k × r matrices, though this representation is of course not unique. For interpretations, it is often convenient to normalize or identify the co-integrating vectors by choosing a specific coordinate system in which to express the variables. An arbitrary normalization, suggested by Johansen [19] , is to solve for the triangular representation of the co-integrated system. The elements of β'pt − 1 may be interpreted as equilibrium relations and the elements of α, as adjustment coefficients which multiply the co-integrating relationship β'pt − 1 to help counterbalance the deviations from the equilibrium. α can also be considered a loading matrix since it determines into which equation the co-integrating vectors enter and with what magnitudes. Normally, these coefficients would be expected to be negative. Suppose pt is I(1) with E[pt] = 0, then Equation (6) represents a VECM and the rank r of the matrix Π determines the number of co-integrating relationships.
The ECM also satisfies the assumptions of classical normal linear regression model (CNLRM) which include a linear regression model, normally distributed residuals, no serial autocorrelation of residuals, and no multicollinearity. As such, diagnostic tests must be carried out to ensure these assumptions are not violated. Among the tests employed are Jarque-Bera (JB) [20] to determine the normality of the ECM, Lagrange multiplier (LM) [21] test for ARCH effects and Ljung-Box (LB) [22] for serial autocorrelation or cross correlation in the residuals.
2.3. Estimation and Testing for Co-Integration
Testing for co-integration is necessary in checking if the models being built are empirically meaningful. With no evidence of co-integration, time series data is considered in differences. Spurious regression can also occur when completely unrelated time series appear to be related [23]. According to [23] , an R2 > d where d is the Durbin-Watson (D-W) [24] [25] statistic can be a good signal of a spurious regression. The D-W statistic tests for autocorrelation in the residuals from a regression analysis. It lies between 0 and 4. A value of 2 implies no autocorrelation in the sample. Small values of d indicate that successive error terms are positively correlated.
Co-integration allows for the regression of one integrated series over other integrated series [26]. Testing for co-integration implies testing the existence of a long run relationship between two or more non stationary series. Because of this, it is important that a sufficiently long period of data is used, in order to detect the common long term trends among the series under consideration [13]. The two most common methods used for testing co-integration among series are the Engle-Granger (E-G) [14] test, which is based on an ordinary least squares (OLS) regression model, and [27] test, also found in [28] [29] , which is based on eigenvalue analysis.
2.3.1. Engle-Granger (E-G) Test for Co-Integration
The residual based E-G test [14] follows in two steps. The first step involves fitting the static OLS regression (after confirming that the series are I(1)) which captures any potential long-run relationship between the series and then carrying out a stationarity test on the residuals of this OLS regression. The second step describes the dynamic adjustment of the series towards an equilibrium. Since the E-G method produces only one co-integrating vector, it involves pairwise comparison of two co-integrating regressions and it is affected by the choice of the dependent variable. Testing for co-integration using the E-G test is essentially equivalent to testing for unit roots in the estimated residual series using the augmented Dickey-Fuller (ADF) test. If the unit root hypothesis is rejected then xt and yt are co-integrated.
2.3.2. Johansen’s Test for Co-Integration
The Johansen [27] test provides a means for testing for co-integration in a multivariate context. It allows for more than one co-integrating vector since the variables in the model might form several equilibrium relationships. The procedure builds co-integrated variables directly on maximum likelihood estimation (MLE) instead of just relying on the OLS estimates. If the variables are I(1), the Johansen maximum likelihood procedure can be used to determine the existence of a stable long-run relationship between variables and the number of co-integrating vectors present. Generally, there will be a possible k − 1 vectors, where k is the number of variables included in the model.
This test is based on the examination of the long-run coefficient matrix Π = αβ’, described in Equation (6), so that testing for co-integration between variables is achieved by examining the rank of Π through the eigenvalues. These Johansen tests are the likelihood ratio test based on maximal eigenvalue of the stochastic matrix and the test based on the trace on the stochastic matrix. Before estimating the parameters of aVECM, you must choose the number of lags in the underlying VAR, the trend specification, and the number of co integrating equations.
The basic steps in Johansen’s methodology include 1) testing the order of integration of all variables, 2) setting the appropriate lag length of the model, 3) choose an appropriate model with regard the deterministic components in the multivariate system, 4) Construct likelihood ratio tests for the rank of Π to determine the number of co-integrating vectors, 5) impose normalization and identifying restrictions on the co-integrating vectors, and 6) given the normalized co-integrating vectors estimate the resulting co-integrated VECM by maximum likelihood (ML). The test procedure produces two statistics useful in determining the number of co-integrating vectors.
The trace statistic
The trace test is a test whether the rank of the matrix Π = r. The null hypothesis of the trace statistic is that there are no more than r co-integrating relations. Restricting the number of co-integrating equations to be r or less implies that the remaining k − r eigenvalues are zero, where k is the maximum number of possible co-integrating vectors. Johansen [27] derives the distribution of the trace statistic
 (7)
(7)
where T is the number of observations and the  are the k − r estimated eigenvalues. For any given value of r, large values of the trace statistic are evidence against the null hypothesis that there are r or fewer co-integrating relations in the VECM. Note: The test is not based on the trace of Π.
are the k − r estimated eigenvalues. For any given value of r, large values of the trace statistic are evidence against the null hypothesis that there are r or fewer co-integrating relations in the VECM. Note: The test is not based on the trace of Π.
The maximum eigenvalue statistic
To test the null hypothesis of r co-integrating vectors versus the alternative of (r + 1) co-integrating vectors the test statistic is
 (8)
(8)
where T is is the number of observations and  is the ith largest canonical correlation.
is the ith largest canonical correlation.
2.4. Granger-Causality
If two or more time-series are co-integrated, then there must be Granger causality between them―either one-way or in both directions. However, the converse is not true. Co-integration usually indicates the existence of a long-run relationship between variables. Even when the variables are not co-integrated in the long-run, they could still be related in the short-run. If the prediction of one time series is improved by incorporating the knowledge of a second time series, then the latter is said to have a causal influence on the first. Granger [30] proposed a time-series data based approach that can be used to determine causality. Specifically, two autoregressive (AR) models are fitted to the first time series― with and without including the second time series―and the improvement of the prediction is measured by the ratio of the variance of the error terms. A ratio larger than one signifies an improvement, hence a causal connection. At worst, the ratio is 1 which signifies causal independence from the second time series to the first. The Granger causality test is based on a standard F-test which seeks to determine if changes in one variable cause changes in another variable.
3. Data and Results
This study explores the co-integration relationships and interdependencies between the Cushing OK WTI and RBOB and the number 1 heating oil traded in the NYMEX, for the period running from 2nd January 2006 to 22nd May 2015. The data was obtained from the U.S. Energy Information Administration (EIA), the principal agency of the U.S. Federal Statistical System responsible for collecting, analysing, and disseminating energy information [31]. EIA can be accessed at http://www.eia.gov/petroleum/data.cfm.
Spot and futures prices of crude oil and distillate fuels are non-stationary and integrated of order one [10] , and therefore co-integration analysis is suitable. We use the E-G method to test for the existence of a co-integrating relationship between the six series. In this test, we take the crude futures CF series as the dependent variable and obtain the results summarised in Table 1.
Though the R2 = 0.9994, the D-W statistic is 0.7545 signalling a spurious regression. The null hypothesis of no co-integration is rejected with a p-value < 0.001 implying that indeed these series are co-integrated with the single co-integrating vector given by
 (9)
(9)
and the long-run relationship given by
 (10)
(10)
The co-integrating residuals which give the co-integrating relation are given by the representation
 (11)
(11)
and the plot of the co-integrating relations (the error correction term), which depicts stationarity, is shown in Figure 1. Testing for stationarity using the ADF test gives a p-value < 0.001 indicating we reject the null hypothesis of existence of unit roots. However, as has been discussed previously, one of the main drawbacks of the E-G technique of testing for co-integration is that it identifies only a

Table 1. Results obtained from the E-G test.

Figure 1. Co-integrating residuals for the co-integrating relationship in the six series taking crude futures prices as the dependent variable.
single co-integrating relation, among what might be many such relations. When we consider more than two series, we will have a different co-integrating relationship for every dependent variable specified as shown in Figure 2 where each of the six price series under consideration is taken as the dependent variable. These relations are not unique and change according to how the dependent variables are chosen. In all the six relationships, we reject the null hypothesis of no co-integration with p-values < 0.001 in all the six instances indicating six co-integrating relations.
For the Johansen co-integration trace test, we examine whether the rank of the matrix Π = r. As such, testing proceeds sequentially for  and the first non-rejection of the null is taken as an estimate ofsmallest lag for which we obtain a rank of r. In our case this happens for r = 4 at 44, making this the optimal lag length. The trace test indicates 4 lags with a p-value of 0.0746 as shown in Table 2. Lag 4 is the co-integrating equations at the α = 0.05 level and * denotes
and the first non-rejection of the null is taken as an estimate ofsmallest lag for which we obtain a rank of r. In our case this happens for r = 4 at 44, making this the optimal lag length. The trace test indicates 4 lags with a p-value of 0.0746 as shown in Table 2. Lag 4 is the co-integrating equations at the α = 0.05 level and * denotes

Figure 2. Six co-integrating relations obtained when all six series are considered as dependent variables.
Table 2. Results obtained from Johansen co-integration test.
rejection of the null hypothesis at the 0.05 level.
The co-integrating relations are as shown in Figure 3 and the resultant parameters from MLE are the co-integrating speed parameters
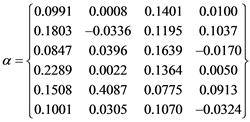
and the vector of co-integrating relations
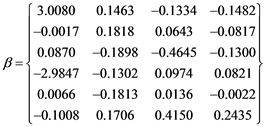
so that for most cases, the 6 ´ 6 matrix Π represented in Equation (6) would be
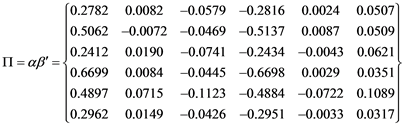 (12)
(12)

Figure 3. Four co-integrating relations obtained using the Johansen’s trace test.
 (13)
(13)
where α and β are given as above,  ,
,  are intercepts in the co-integrating relations,
are intercepts in the co-integrating relations,  , and at are the shocks or innovations associated with each of the relations,
, and at are the shocks or innovations associated with each of the relations,



and

 represents the error correction term.
represents the error correction term.
After fitting this model, an analysis of the residuals show that they are not white noise. Figure 4 shows plots for the residuals from the VECM. They do not seem to be multivariate normal, and this is confirmed by the results shown on Table 3 which reports the multivariate extensions of the JB residual normality test, which is a test of the hypothesis that the skewness of the underlying distribution is zero, and the kurtosis is three. This test also compares the third and fourth moments of the residuals to those from the normal distribution. These two measures allow one to test the hypotheses that are compatible with the assumption of multivariate normality.

Figure 4. Residuals from the full VECM.
This test is applicable since individual variables from a set of variables that are jointly multinomial distributed are also normally distributed, although if a number of variables are normally distributed individually, they are not necessarily also multivariate normal [32]. The test statistic is given by equation (14) below where Sˆ and Kˆ represent the sample skewness and sample kurtosis respectively.
 (14)
(14)
The null hypothesis for this test is that the residuals are multivariate normal and this is rejected as can be seen from the p-values reported in Table 3.
A visual inspection of Figure 4 suggests the presence of volatility clustering. Further investigation of the residual series reveals the presence of arch effects as shown in Table 4. The null hypothesis of no ARCH effects is rejected. The noise is therefore MGARCH.
For this study, the results for Granger-causality in levels are reported in Table 5 and results for causality in differences are recorded in Table 6.
From Table 5, we see bidirectional causality between almost all the series except for gasoline futures which doesn’t Granger cause gasoline spot though gasoline spot Granger causes gasoline futures. This result is confirmed by the joint
Table 3. Multivariate normality test on residual series.
Table 4. Test for ARCH effects on residual series.
test also. This actually shows the presence of spillover effects across the series. From Table 6, we see, returns from gasoline futures do not Granger cause gasoline spot returns and we also note that gasoline spot returns only Granger causes heating oil futures and maybe heating oil spot returns.
4. Discussion
In this study, both the E-G test [14] and Johansen’s test [27] are used to explore the presence of co-integrating relations between the daily prices of crude oil and distillate fuels. Given the multivariate nature of the data under consideration, Johansen’s test becomes more efficient given its ability to test for co-integration
Table 5. Results obtained from Granger-causality (F) test in levels.
p-values are indicated in the parenthesis.
Table 6. Results obtained from Granger-causality (F) test in differences.
p-values are indicated in the parenthesis.
in a multivariate context.
Under the E-G test, the null hypothesis of no co-integration is rejected and this result is backed by the DW statistic. Similarly, Johansen’s test results reveal up to 4 co-integrating vectors with an optimal lag length of 4 if all six series are considered simultaneously. After fitting the full VECM, a residual analysis is carried out and it suggests some heteroscedasticity in the noise process, contravening the Gaussian assumption on the residuals. Tests reveal ARCH effects in the residuals, and the JB hypothesis of multivariate normality is rejected. This suggests a VECM with GARCH errors could have been better. For noise that is MGARCH, fitting a VEC-GARCH. This involves writing the VEC part as a seemingly unrelated regression (SUR) model and combining to obtain SUR-GARCH model. That is however not covered in this study.
Causal relationships are also explores and bidirectional Granger-causality is exhibited for all cases except for the gasoline futures which do not seem to Granger cause gasoline spot prices. This underscores the importance of the spill-over effects in the volatilities of these price series. It confirms the presence of cointegrating relations and hence spill-over effects.
Cite this paper
Aduda, J., Weke, P. and Ngare, P. (2018) A Co-Integration Analysis of the Interdependencies between Crude Oil and Distillate Fuel Prices. Journal of Mathematical Finance, 8, 478-496. https://doi.org/10.4236/jmf.2018.82030
References
- 1. Reinsel, G.C. (1993) Elements of Multivariate Time Series Analysis. Springer US. https://doi.org/10.1007/978-1-4684-0198-1
- 2. Alexander, C., Giblin, I. and Weddington, W. (2002) Co-Integration and Asset allocation: A New Active Hedge Fund Strategy. ISMA Centre Discussion Papers in Finance Series.
- 3. Chan, N.H. (2011) Time Series: Applications to Finance with R and S-Plus. John Wiley & Sons, Hoboken.
- 4. Girma, P.B. and Paulson, A.S. (1999) Risk Arbitrage Opportunities in Petroleum Futures Spreads. Journal of Futures Markets, 19, 931-955. 3.0.CO;2-L>https://doi.org/10.1002/(SICI)1096-9934(199912)19:8<931::AID-FUT5>3.0.CO;2-L
- 5. Engle, R.F. (1982) Autoregressive Conditional Heteroscedasticity with Estimates of the variance of United Kingdom Inflation. Econometrica, 50, 987-1007. https://doi.org/10.2307/1912773
- 6. Bollerslev, T. (1986) Generalized Autoregressive Conditional Heteroscedasticity. Journal of Economics, 31, 307-327. https://doi.org/10.1016/0304-4076(86)90063-1
- 7. Haigh, M.S. and Holt, M.T. (2002) Crack Spread Hedging: Accounting for Time-Varying Volatility Spill Overs in the Energy Futures Markets. Journal of Applied Econometrics, 17, 269-289. https://doi.org/10.1002/jae.628
- 8. Veiga, B. and McAleer, M. (2004) Multivariate Volatility and Spillover Effects in Financial Markets. https://scholarsarchive.byu.edu/iemssconference/2004/all/26/
- 9. Hoti, S., Chan, F., McAleer, M., et al. (2002) Structure and Asymptotic Theory for Multivariate Asymmetric Volatility: Empirical Evidence for Country Risk Ratings. Australasian Meeting of the Econometric Society, Brisbane. https://core.ac.uk/download/pdf/6390132.pdf
- 10. Aduda, J., Weke, P., Ngare, P. and Mwaniki, J. (2016) Financial Time Series Modelling of Trends and Patterns in the Energy Markets. Journal of Mathematical Finance, 6, 324-337. https://doi.org/10.4236/jmf.2016.62027
- 11. The MathWorks (2013) MATLAB Version 7.14.0.739 R2013a. The MathWorks Inc., Torrance.
- 12. Rachev, S.T., Mittnik, S., Fabozzi, F.J., Focardi, S.M. and Jasic, T. (2007) Financial Econometrics: From Basics to Advanced Modeling Techniques. John Wiley & Sons, Hoboken.
- 13. Alexander, C. (2008) Practical Financial Econometrics. Wiley, Hoboken.
- 14. Engle, R.F. and Granger, C.W.J. (1987) Co-Integration and Error Correction: Representation, Estimation, and Testing. Econometrica: Journal of the Econometric Society, 55, 251-276. https://doi.org/10.2307/1913236
- 15. Lütkepohl, H. (2007) New Introduction to Multiple Time Series Analysis. Springer Science & Business Media, Berlin.
- 16. Tsay, R.S. (2013) Multivariate Time Series Analysis: With R and Financial Applications. Wiley, Hoboken.
- 17. Enders, W. (2008) Applied Econometric Time Series. John Wiley & Sons, Hoboken.
- 18. Harris, R.I.D. and Sollis, R. (2003) Applied Time Series Modelling and Forecasting. John Wiley & Sons, Hoboken.
- 19. Johansen, S. (1995) Identifying Restrictions of Linear Equations with Applications to Simultaneous Equations and Co-Integration. Journal of Econometrics, 69, 111-132. https://doi.org/10.1016/0304-4076(94)01664-L
- 20. Jarque, C.M. and Bera, A.K. (1987) A Test for Normality of Observations and Regression Residuals. International Statistical Review/Revue Internationale de Statistique, 55, 163-172.
- 21. Engle, R.F. (1984) Wald, Likelihood Ratio, and Lagrange Multiplier Tests in Econometrics. In: Handbook of Econometrics, Vol. 2, North Holland, New York, 775-826.
- 22. Ljung, G.M. and Box, G.E.P. (1978) On a Measure of Lack of Fit in Time Series Models. Biometrika, 65, 297-303. https://doi.org/10.1093/biomet/65.2.297
- 23. Granger, C.W.J. and Newbold, P. (1974) Spurious Regressions in Econometrics. Journal of Econometrics, 2, 111-120. https://doi.org/10.1016/0304-4076(74)90034-7
- 24. Durbin, J. and Watson, G.S. (1950) Testing for Serial Correlation in Least Squares Regression: I. Biometrika, 37, 409-428.
- 25. Durbin, J. and Watson, G.S. (1951) Testing for Serial Correlation in Least Squares Regression. II. Biometrika, 38, 159-178. https://doi.org/10.1093/biomet/38.1-2.159
- 26. Fabozzi, F.J., Focardi, S.M. and Kolm, P.N. (2006) Financial Modelling of the Equity Market: From CAPM to Co-Integration. Wiley, Hoboken.
- 27. Johansen, S. (1988) Statistical Analysis of Co-Integration Vectors. Journal of Economic Dynamics and Control, 12, 231-254. https://doi.org/10.1016/0165-1889(88)90041-3
- 28. Johansen, S. and Juselius, K. (1990) Maximum Likelihood Estimation and Inference on Cointegration with Applications to the Demand for Money. Oxford Bulletin of Economics and Statistics, 52, 169-210. https://doi.org/10.1111/j.1468-0084.1990.mp52002003.x
- 29. Johansen, S. (1991) Estimation and Hypothesis Testing of Co-Integration Vectors in Gaussian Vector Autoregressive Models. Econometrica, 59, 1551-1580. https://doi.org/10.2307/2938278
- 30. Granger, C.W.J. (1969) Investigating Causal Relations by Econometric Models and Cross-Spectral Methods. Econometrica, 37, 424-438. https://doi.org/10.2307/1912791
- 31. EIA (2015) U.S. Energy Information Administration. http://www.eia.gov/about/
- 32. Von Eye, A. and Bogat, A.G. (2004) Testing the Assumption of Multivariate Normality. Psychology Science, 46, 243-258.