Open Journal of Statistics
Vol.06 No.05(2016), Article ID:71413,16 pages
10.4236/ojs.2016.65073
Incorporating Uncertain Costs within a Series of Sequential Probability Ratio Tests
Conor McMeel, Brett Houlding*
Discipline of Statistics, Trinity College Dublin, Dublin, Ireland

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: August 20, 2016; Accepted: October 18, 2016; Published: October 21, 2016
ABSTRACT
We consider an extension to Sequential Probability Ratio Tests for when we have uncertain costs, but also opportunity to learn about these in an adaptive manner. In doing so we demonstrate the effects that allowing uncertainty has on observation cost, and the costs associated with Type I and Type II error. The value of information relating to modelled uncertainties is derived and the case of statistical dependence between the parameter affecting decision outcome and the parameter affecting unknown cost is also examined. Numerical examples of the derived theory are provided, along with a simulation comparing this adaptive learning framework to the classical one.
Keywords:
Adaptive Utility, Hypothesis Testing, Sequential Analysis, Sequential Probability Ratio Test

1. Introduction
Sequential Probability Ratio Tests (SPRTs) were introduced by Wald in 1945 [1] [2] as a sequential hypothesis test procedure for when data is considered in sequence rather than in entirety. They have been used in many fields of industry, for example: nuclear physics [3] , medicine [4] [5] , standardised testing [6] and radar detection [7] , to name just a few, and even though the classical theory has now been known for some seven decades, they are still the subject of research into extensions and generalisations [8] - [10] .
Generally, the objective of a SPRT is to balance the consequence of an error with the cost of acquiring further data and/or making additional observations, e.g. clinical trials, or stress tests. In this approach data is sought until the belief in the state of nature (namely the parameter controlling the decision outcome) is such that the expected cost of implementing the current optimal decision is less than that expected from seeking additional data, updating beliefs, and then implementing the (possibly different) optimal decision.
In its simplest form a SPRT consists of the following: A choice between two decisions or courses of action (here denoted 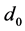 and
and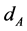 ), and a state of nature w that can take one of two possible values (
), and a state of nature w that can take one of two possible values (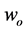 or
or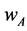 ). Depending on the decision that is selected and the true state of nature value, one of three possible losses may occur. Without loss of generality we assume a loss of
). Depending on the decision that is selected and the true state of nature value, one of three possible losses may occur. Without loss of generality we assume a loss of 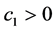 occurs if
occurs if 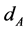 is selected when
is selected when 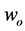 is true,
is true,  occurs if
occurs if 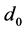 is selected but
is selected but  is true, and a loss of 0 otherwise (Table 1).
is true, and a loss of 0 otherwise (Table 1).
From the above it can be seen that the objective of the Decision Maker (DM) is to choose between 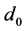 and
and  on the basis of their beliefs over the state of nature, seeking to match the decision to what they hope is its correct value. In general we denote such belief by the probability
on the basis of their beliefs over the state of nature, seeking to match the decision to what they hope is its correct value. In general we denote such belief by the probability  with
with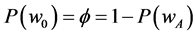 . In this sense the losses
. In this sense the losses 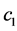 and
and 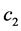 can be associated with what is commonly described as making a Type I or Type II error, and hence the connection to sequential hypothesis testing originally considered by Wald.
can be associated with what is commonly described as making a Type I or Type II error, and hence the connection to sequential hypothesis testing originally considered by Wald.
A graphic representation of this protocol is illustrated in Figure 1, where the x-axis varies over the possible value of  and the y-axis is the resulting expected loss incurred
and the y-axis is the resulting expected loss incurred

Table 1. Loss table applied within a SPRT.

Figure 1. An illustration of the losses involved within a SPRT. The x-axis varies over , the y-axis is the associated expected loss, the solid line corresponds to making a decision immediately, while the curved dashed line corresponds to collecting further information before making a decision. Finally the vertical dashed lines indicate the bounds on
, the y-axis is the associated expected loss, the solid line corresponds to making a decision immediately, while the curved dashed line corresponds to collecting further information before making a decision. Finally the vertical dashed lines indicate the bounds on  within which the DM should observe further data before making a decision.
within which the DM should observe further data before making a decision.
by a particular strategy. The solid line represents the expected cost of implementing a decision immediately, whilst the curved dash line corresponds to the expected loss of implementing a decision only after taking some further data (at a cost)concerning the correct value of the state of nature. It is included as a curve as it can be shown that the expected loss of deciding after data collection is a concave function of  (this is because we will be taking the infimum of two further choices, namely to act once the data is collected or to again choose to sample).
(this is because we will be taking the infimum of two further choices, namely to act once the data is collected or to again choose to sample).
For values of  the DM assumes for sure that they know what the state of nature will be, and hence will make a decision in the belief that they will receive a cost of 0. As
the DM assumes for sure that they know what the state of nature will be, and hence will make a decision in the belief that they will receive a cost of 0. As  varies away from these extremes however, the DM will not presume to be certain in their knowledge of the state of nature, and hence expects a risk of making either a Type I or Type II error and incurring the associated cost. This risk can be shown to increase and then decrease linearly between the extreme values of
varies away from these extremes however, the DM will not presume to be certain in their knowledge of the state of nature, and hence expects a risk of making either a Type I or Type II error and incurring the associated cost. This risk can be shown to increase and then decrease linearly between the extreme values of  (the change from increase to decrease occurring at
(the change from increase to decrease occurring at  when
when ). The dashed curve line, corresponding to making a decision only after further data collection, does not have an expected loss of 0 at
). The dashed curve line, corresponding to making a decision only after further data collection, does not have an expected loss of 0 at  because of the additional cost of collecting data. Depending on what this particular data collection cost is, the DM should either always collect further information (when the cost is 0), never collect additional information (when the cost of doing so is prohibitive compared to the cost of actually making a Type I or Type II error), or as is the case in Figure 1, either choose to collect additional data or not to depending on the value of
because of the additional cost of collecting data. Depending on what this particular data collection cost is, the DM should either always collect further information (when the cost is 0), never collect additional information (when the cost of doing so is prohibitive compared to the cost of actually making a Type I or Type II error), or as is the case in Figure 1, either choose to collect additional data or not to depending on the value of  that they assign to
that they assign to . The vertical dashed lines of
. The vertical dashed lines of
Figure 1 indicates, for the particular numerical example displayed, the range of values for  within which the DM expects it is better to collect further data before making a decision.
within which the DM expects it is better to collect further data before making a decision.
Whilst the approach described above outlines the classical way of performing a SPRT, it fails to take into account that in practice, many of the costs involved will not be known for certain. For example, in the case of an observation cost, the cost associated with undertaking clinical trials prior to deciding to market a drug may not be known for sure, or in the case of a Type I or Type II error, the reputational or financial effect of implementing a poor decision may be unknown, e.g., releasing poorly coded software when there was opportunity to have more testing to determine unknown bugs. In such instances it is then natural for us to model our beliefs and uncertainties about relevant costs according to some parameter, say , to which we only specify a prior distribution. The question then arises as to the effect this has on how we perform a SPRT, given that we may now learn between successive SPRTs, or in the case of unknown observation cost, between successive observations.
, to which we only specify a prior distribution. The question then arises as to the effect this has on how we perform a SPRT, given that we may now learn between successive SPRTs, or in the case of unknown observation cost, between successive observations.
The concept of unknown utility (utility defined to be negative loss), but which may instead be learned through experience, is the topic of adaptive utility theory first considered by Cyert and De Groot [11] . Here not only do we have uncertainty concerning decision outcome (as modelled through the unknown state of nature), but also in the preferences over those outcomes (or equivalently attitudes to risk) [12] - [14] .
In the case of only performing a solitary SPRT, and where the uncertainty relates to only the consequence of a Type I or Type II error, the appropriate procedure is equivalent to the classical one with the cost assigned to its expected value, as there is no possibility to learn about the relevant costs before implementing a decision. However, if the DM has opportunity to purchase information about such costs, e.g. by performing some market survey or enlisting the assistance of a knowledgeable expert, then the value that such information is worth may be calculated as the expected difference between the expected loss without the information, and the expected loss with it. Determining this value will be our primary interest [14] [15] :
 . (1)
. (1)
Here I is the set of information statements we could receive, i is an actual information statement, D represents the set of available decisions, d a particular decision, and  the expected loss for implementing decision d.
the expected loss for implementing decision d.
The remainder of this paper is as follows: In Section 2 we consider SPRTs with uncertain Type I or Type II error cost followed by uncertain observation cost in Section 3. In the former we consider the value of perfect information and that of noisy information, along with providing numerical examples. The details of a simulation carried out in the case of perfect information are also given. Finally we conclude in Section 4.
2. Unknown Consequence of Error
Suppose our uncertainty does not concern the cost of taking further observations, but rather the cost of a Type I or Type II error, or both (possibly with different distributions describing these). Without loss of generality assume the uncertainty is with respect the cost of a Type I error only. In this case our loss table is as in Table 2, where  represents the uncertain cost of a Type I error.
represents the uncertain cost of a Type I error.
There are three steps to perform to generate the expected value of information relating to these uncertain costs. In the case of information being perfect then these are the following:
1) Consider a SPRT when no information is learned.
2) Obtain expected loss following learning of the uncertain parameter(s).
3) Subtract to obtain the expected value of information, which can then be subtracted from the unknown loss consequence(s).
In performing step 1 we utilize the expected costs using the loss in Table 3. Hence the expected loss on making an immediate decision, as a function of , is:
, is:
 . (2)
. (2)
If a Type I or Type II error is made, we learn the value of . The process of performing an SPRT is repeated, but now with the exact value of
. The process of performing an SPRT is repeated, but now with the exact value of  rather than its prior expectation
rather than its prior expectation , resulting in a change in the expected risk profile. An expected
, resulting in a change in the expected risk profile. An expected
Table 2. Loss table with uncertain cost of Type I error.
Table 3. Loss table assuming no learning about uncertain cost .
.
Table 4. Loss table for numerical example in Section 2.1.
expected risk profile concerning how this may look depending on what is learned, based on the prior distribution of , is now determined. This is then subtracted from the original risk profile (using
, is now determined. This is then subtracted from the original risk profile (using ) to obtain the expected value of the cost information.
) to obtain the expected value of the cost information.
2.1. Perfect Information Numerical Example
As a toy example illustrating this situation consider testing if a sequence of coins are fair ( ) or biased (
) or biased ( ) meaning that
) meaning that . A Type I error corresponds to throwing away a fair coin and we suppose this has known loss of 2 units, namely the coin's value. A Type II error would correspond to accepting a biased coin, of which we have little experience. This could be very bad resulting in a loss of
. A Type I error corresponds to throwing away a fair coin and we suppose this has known loss of 2 units, namely the coin's value. A Type II error would correspond to accepting a biased coin, of which we have little experience. This could be very bad resulting in a loss of  units, or not so bad resulting in a loss of
units, or not so bad resulting in a loss of  unit. Further suppose the prior on
unit. Further suppose the prior on  is such that
is such that  and let
and let  represent the probability that the coin is fair.
represent the probability that the coin is fair.
The expected loss table is given in Table 4. From the description we see  so that if
so that if  then a priori we are indifferent between saving the coin or throwing it away. Then the expected risk of an immediate decision is:
then a priori we are indifferent between saving the coin or throwing it away. Then the expected risk of an immediate decision is:
 . (3)
. (3)
We may also consider sampling data by flipping a coin which is assumed to cost 0.1 units. We now calculate the range of  where it is beneficial to flip the coin. To do so we determine posteriors on
where it is beneficial to flip the coin. To do so we determine posteriors on  after observing the possible results of a coin flip:
after observing the possible results of a coin flip:
 (4)
(4)
 . (5)
. (5)
The predictive probability of observing heads or tails, at any point, is:
 (6)
(6)
 . (7)
. (7)
Letting  denote our posterior probability of the coin being biased after being flipped, the risk profiles of the decision following an observation is:
denote our posterior probability of the coin being biased after being flipped, the risk profiles of the decision following an observation is:
 . (8)
. (8)
Now we can relate the bounds on  to bounds on
to bounds on :
:
 (9)
(9)
 . (10)
. (10)
Suppose , then the expected loss is:
, then the expected loss is:
 . (11)
. (11)
We also need to include the cost of flipping (0.1 units) resulting with an expected loss for observing once then deciding of . To see when this risk is preferable to deciding immediately we solve the following inequalities for
. To see when this risk is preferable to deciding immediately we solve the following inequalities for :
:
 (12)
(12)
 . (13)
. (13)
Observations should continue to be taken until  leaves this interval, at which a point a decision should be made. Hence the expected risk profile is:
leaves this interval, at which a point a decision should be made. Hence the expected risk profile is:
 . (14)
. (14)
With this risk profile we now compute the expected loss assuming we know the parameter . There are two cases: when
. There are two cases: when  or
or . In each case the expected loss as a function of
. In each case the expected loss as a function of  is computed. The process is identical to the above so we just report them:
is computed. The process is identical to the above so we just report them:
For :
:
 . (15)
. (15)
For :
:
 . (16)
. (16)
Recall the prior on  was such that
was such that . Hence, the expected risk after learning
. Hence, the expected risk after learning  is:
is:
 . (17)
. (17)
Thus the expected value of perfect information is the difference between Equation (14) (without perfect information) and Equation (17) (with perfect information):
 . (18)
. (18)
This represents the maximum amount of units we should be prepared to forsake in order to be informed the true value of the cost parameter  prior to commencing the SPRT. From this we obtain a new function
prior to commencing the SPRT. From this we obtain a new function  that represents the loss resulting from the occurrence of a Type II error:
that represents the loss resulting from the occurrence of a Type II error:
 . (19)
. (19)
Equation (19) represents the expected value of the loss of making a Type II error, but discounted by the fact that we obtain information which allows more informed decisions to be made in subsequent SPRTs. A plot of (19) is given in Figure 2 where it can be observed that local minima in the expected loss occur at boundaries of indifference between choices in the initial SPRT, and that plateaus in the expected loss coincide with values of  where it is never beneficial to take an observation for any value of
where it is never beneficial to take an observation for any value of .
.
2.2. Noisy Information
Now assume we only receive noisy observations concerning  meaning that following observation we are not certain of its value. The procedure is similar to that for perfect information and again we first perform an SPRT without considering the value of the information.
meaning that following observation we are not certain of its value. The procedure is similar to that for perfect information and again we first perform an SPRT without considering the value of the information.
Denoting the true value of 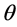 as
as  and our observation as
and our observation as  then this setting
then this setting

Figure 2. A plot of the expected loss incurred from committing a Type II error for Example 2.1 generated from Equation (19). The x-axis varies over the prior probability for the state of nature w, whilst the y-axis indicates the resulting expected loss.
means . We also allow the distribution over what is observed to depend on the true value
. We also allow the distribution over what is observed to depend on the true value  and hence generate a likelihood
and hence generate a likelihood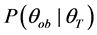 , from which a marginal distribution
, from which a marginal distribution , expected value
, expected value , and posterior distribution
, and posterior distribution  may be calculated in the usual way.
may be calculated in the usual way.
For each potential  a new expected value of
a new expected value of ,
,  , is generated. Denoting
, is generated. Denoting  as the expected loss before observation and
as the expected loss before observation and  as the expected loss after observing
as the expected loss after observing , the expected value of the noisy observation is calculated as:
, the expected value of the noisy observation is calculated as:
 . (20)
. (20)
Once this has been generated the consequence of the error will be reduced in the risk table just as was the case with perfect information, allowing a classical SPRT to be performed.
2.3. Noisy Information Numerical Example
We return to the setting of Example 2.1, but now assume that the probability that the true value is observed is only 0.8, i.e., . This results in
. This results in  and
and .
.
After observing a value for  we update its expected value to the following:
we update its expected value to the following:
 (21)
(21)
 . (22)
. (22)
Letting  represent the expected loss when
represent the expected loss when  (so, for example,
(so, for example,  is the loss from step 1 where future trials are not considered), then the value of information from our noisy observation
is the loss from step 1 where future trials are not considered), then the value of information from our noisy observation  for each
for each  is calculated as:
is calculated as:
 . (23)
. (23)
Note that each term in the above implicitly depends on the initial value assigned to . We then simply proceed as in Example 2.1 to obtain the final decision rule. The resulting loss tables are provided below for the three quantities listed in Equation (23):
. We then simply proceed as in Example 2.1 to obtain the final decision rule. The resulting loss tables are provided below for the three quantities listed in Equation (23):
 (24)
(24)
 (25)
(25)
 . (26)
. (26)
As a result the expected value of noisy information  is calculated as:
is calculated as:
 . (27)
. (27)
Now the new expected cost of a Type II error  for the noisy information example can be determined as in see Equation (26). A plot of this function is given in Figure 3 which can be contrasted with the perfect information case given in Figure 2. Note that as before the minima occur at boundaries of indifference and that plateaus occur where we would always (or never) take an observation no matter the value of
for the noisy information example can be determined as in see Equation (26). A plot of this function is given in Figure 3 which can be contrasted with the perfect information case given in Figure 2. Note that as before the minima occur at boundaries of indifference and that plateaus occur where we would always (or never) take an observation no matter the value of . Also note that in comparison to Figure 2, the result for noisy information results in a larger expected cost of Type II error when the true value of
. Also note that in comparison to Figure 2, the result for noisy information results in a larger expected cost of Type II error when the true value of  does play a role in the decision making. This is to be expected due to the weaker and less useful noisy information in comparison to what we learn from perfect information.
does play a role in the decision making. This is to be expected due to the weaker and less useful noisy information in comparison to what we learn from perfect information.
 (28)
(28)

Figure 3. A plot of the expected loss incurred from committing a Type II error for Example 2.3 generated from Equation (28). The x-axis varies over the prior probability for the state of nature w, whilst the y-axis indicates the resulting expected loss.
2.4. Numerical Simulation
Details of a numerical simulation are now provided. The scenario detailed in Example 2.1 was tested in R [16] by considering the outcome of 3 million trials of both the classic and adaptive framework.
Each classical trial consisted of:
1) A SPRT with consequence of Type I/II error of 2 and cost of observation 0.1 run repeatedly until a Type II error is made. The bounds used are those in Equation (14), namely , before value of information is considered.
, before value of information is considered.
2) Upon making a Type II error, the cost from that particular SPRT is stored. The value of  is then learned and another SPRT is run using the true value for the consequence of Type II error. The two costs are added to provide the total value for that trial.
is then learned and another SPRT is run using the true value for the consequence of Type II error. The two costs are added to provide the total value for that trial.
In accordance with our prior on , two-thirds of the trials were performed with the true value of
, two-thirds of the trials were performed with the true value of , while the others had
, while the others had .
.
A further 3 million trials were then run using the adaptive framework under the same procedure but with the bounds in step 1 being different. This is due to the different values used for consequence of Type II error seen in Equation (19). Using initial values of  corresponded to using
corresponded to using , resulting in bounds of approximately
, resulting in bounds of approximately . The second step remains the same as the classical trial.
. The second step remains the same as the classical trial.
The average costs are given in Table 5. As can be seen, this indicated a substantial improvement (21% with the numerical scenario here) in using the adaptive framework and formally taking such uncertainty into account.
2.5. Statistical Dependence
To conclude we give a brief discussion on the effect of their being statistical dependence between the state of nature w and cost parameter . Without loss of generality, consider a joint distribution as taking on the values (and associated probability) given in Table 6. This implies conditional probabilities as given in Table 7. Note that this specification ensures that w and
. Without loss of generality, consider a joint distribution as taking on the values (and associated probability) given in Table 6. This implies conditional probabilities as given in Table 7. Note that this specification ensures that w and  are not independent.
are not independent.
Now consider the implementation of the SPRT. The initial loss table when w and  were independent is given in Table 8. However, note that we can only incur losses governed by
were independent is given in Table 8. However, note that we can only incur losses governed by  when the state of nature is
when the state of nature is . So any loss that occurs in the joint distribution when
. So any loss that occurs in the joint distribution when  is true should not be considered here. Also note that an equivalent scenario will occur if the uncertainties were in both Type I and Type II errors. Thus, Table 8 should be corrected to that given in Table 9, where, as can be seen,
is true should not be considered here. Also note that an equivalent scenario will occur if the uncertainties were in both Type I and Type II errors. Thus, Table 8 should be corrected to that given in Table 9, where, as can be seen,  remains constant at
remains constant at  independently of the value of
independently of the value of , and hence the value of
, and hence the value of . This means the SPRT will have constant losses that do not change between observations, and so we simply proceed as before.
. This means the SPRT will have constant losses that do not change between observations, and so we simply proceed as before.
Table 5. Average costs from the simulation described in Section 2.4.
Table 6. Assumed joint distribution between w and .
.
Table 7. Implied conditional probabilities.
Table 8. Initial loss table in the case of independence.
Table 9. Loss table in the case of statistical dependence.
3. Unknown Observation Cost
Now suppose that the costs of making a Type I ( ) or Type II (
) or Type II ( ) error are known. This means that if we were to implement an immediate decision the expected loss will be unchanged from the classical setting. However, we assume the observation cost
) error are known. This means that if we were to implement an immediate decision the expected loss will be unchanged from the classical setting. However, we assume the observation cost  is uncertain but subject to some prior distribution
is uncertain but subject to some prior distribution  and some specified data likelihood, in which case the expected loss of making a decision after observation will have to take into account not only the uncertainty concerning the information we may receive in relation to the true state of nature, but also the uncertainty in the additional cost of having taken a further observation.
and some specified data likelihood, in which case the expected loss of making a decision after observation will have to take into account not only the uncertainty concerning the information we may receive in relation to the true state of nature, but also the uncertainty in the additional cost of having taken a further observation.
If we take the expected value of ,
,  as the observation cost, then we can determine bounds
as the observation cost, then we can determine bounds  on values of
on values of  within which we should seek additional data before implementing a decision. The expected risk profile
within which we should seek additional data before implementing a decision. The expected risk profile  (expected loss), as a function of
(expected loss), as a function of  would then be:
would then be:
 . (29)
. (29)
where  is a concave (or linear) function of
is a concave (or linear) function of  determined by the data generating mechanism. Then, for each possible information statement i we may receive (where here i contains both the information concerning the true state of nature and any information we gain concerning
determined by the data generating mechanism. Then, for each possible information statement i we may receive (where here i contains both the information concerning the true state of nature and any information we gain concerning  the cost of sampling), we can determine a posterior distribution on
the cost of sampling), we can determine a posterior distribution on  and updated expected value
and updated expected value . With this we continue the SPRT leading to updated intervals
. With this we continue the SPRT leading to updated intervals  which if
which if  does not fall within, would result in our now taking an immediate decision. The updated risk table would now have form:
does not fall within, would result in our now taking an immediate decision. The updated risk table would now have form:
 . (30)
. (30)
Here  is another concave (or linear) function in
is another concave (or linear) function in .
.
As the information i we may receive is currently unknown, we take the expectation of Equation (30). Subtracting this from Equation (29) (the expected risk without learning information) we obtain the expected value of that information, which can be thought of as the most we would be willing to pay for it in advance of seeing it. This should now be subtracted from , the original expected observation cost, to obtain what we would use as the adaptive information cost for the adaptive SPRT. Note that this value will be a function of
, the original expected observation cost, to obtain what we would use as the adaptive information cost for the adaptive SPRT. Note that this value will be a function of . A classical SPRT is then performed with this adaptive observation cost until the true cost has been learned, at which point the test continues with the cost uncertainty removed, i.e., in the classical way.
. A classical SPRT is then performed with this adaptive observation cost until the true cost has been learned, at which point the test continues with the cost uncertainty removed, i.e., in the classical way.
Remark. The expected value of information is zero for any  (the bounds on
(the bounds on  for which we would take further samples) and also for any
for which we would take further samples) and also for any  that is always contained in
that is always contained in .
.
Numerical Example
As a toy example to aid in clarification of the above, suppose we are testing the efficacy of a drug and are certain of the costs incurred in making a Type I or Type II error (say 2 and 4 units respectively). Assume, however, that we have little experience in running clinical trials (our observation costs) and are not sure if it will be easy and cheap to organise ( ) or relatively expensive (
) or relatively expensive ( ). Prior beliefs are that it is more likely to be cheap so that
). Prior beliefs are that it is more likely to be cheap so that . Also suppose that the probability a bad drug passes the clinical trial is 0.5 whilst the probability that a drug that works passes is 0.8.
. Also suppose that the probability a bad drug passes the clinical trial is 0.5 whilst the probability that a drug that works passes is 0.8.
As we begin testing of the first drug we determine how to modify the SPRT procedure to take into account this uncertainty. Interest lies in the expected value of information of the observation cost, and we assume that the information will be of a perfect nature (namely remove all uncertainties). Noting that , the risk profile, without information, is:
, the risk profile, without information, is:
 . (31)
. (31)
So if  we take a further observation and hence also determine the true value of
we take a further observation and hence also determine the true value of . This leads to two possible further risk profiles depending on if we learn
. This leads to two possible further risk profiles depending on if we learn or
or .
.
For :
:
 . (32)
. (32)
For :
:
 . (33)
. (33)
Recalling the prior on  is such that
is such that  leads to an expected risk after learning information of:
leads to an expected risk after learning information of:
 . (34)
. (34)
Subtracting Equation (34) (expected risk with knowledge of ) from Equation (31) provides the expected value of perfect information for the observation cost:
) from Equation (31) provides the expected value of perfect information for the observation cost:
 (35)
(35)
A plot of Equation (35) is provided in Figure 4. Note that the areas where the expected value of information is zero are where the decision rule is the same regardless of the information concerning the cost of sampling, agreeing with our earlier remark, and that the expected value of sampling information increases to be maximal where we are currently indifferent between making an immediate decision or taking further samples. With this to hand, we would continue by performing the SPRT as if we had an observation cost of , and if we do take an observation we learn the true value of
, and if we do take an observation we learn the true value of  and continue the SPRT with this knowledge.
and continue the SPRT with this knowledge.
4. Conclusions
In this paper we have considered the generalisation of SPRTs from a classical to adaptive utility setting where preferences or associated costs are not assumed fully known but are instead learned through experience or by funding additional information through survey or trial etc. Both unknown cost of Type I/II error was examined before subsequently considering the effect of uncertain observation cost.
Both perfect and noisy information were discussed, where we demonstrated the methods of quantifying the value for such information and numerical examples were

Figure 4. A plot of the expected value of information in Example 3.1 given by Equation (35).
provided to demonstrate the theory. Statistical dependence between the parameter and the state of nature was also considered and shown to not influence results. The numerical simulation indicated the enhanced performance by formally treating uncertainties and opportunities to learn within a SPRT in comparison to the somewhat easier modelling assumption of equating uncertainties in costs to their expected values.
Cite this paper
McMeel, C. and Houlding, B. (2016) Incorporating Uncertain Costs within a Series of Sequential Probability Ratio Tests. Open Journal of Statistics, 6, 882-897. http://dx.doi.org/10.4236/ojs.2016.65073
References
- 1. Wald, A. (1945) Sequential Tests of Statistical Hypotheses. Annals of Mathematical Statistics, 16, 117-186.
http://dx.doi.org/10.1214/aoms/1177731118 - 2. Wald, A. and Wolfowitz, J. (1948) Optimum Character of the Sequential Probability Ratio Test. Annals of Mathematical Statistics, 19, 326-339.
http://dx.doi.org/10.1214/aoms/1177730197 - 3. Gross, K. and Humenik, K. (1991) Sequential Probability Ratio Test for Nuclear Plant Component Surveillance. Nuclear Technology, 93, 131-137.
- 4. Kulldorf, M., Davis, R.L., Kolczak, M., Lewis, E., Lieu, T. and Platt, R. (2011) A Maximised Sequential Probability Ratio Test for Drug and Vaccine Safety Surveillance. Sequential Analysis, 30, 58-70.
http://dx.doi.org/10.1080/07474946.2011.539924 - 5. Spiegelhalter, D., Grigg, O., Kinsman, R. and Treasure, T. (2003) Risk-Adjusted Sequential Probability Ratio Tests: Applications to Bristol, Shipman and Adult Cardiac Surgery. International Journal for Quality in Health Care, 15, 7-13.
http://dx.doi.org/10.1093/intqhc/15.1.7 - 6. Spray, J.A. and Reckase, M.D. (1996) Comparison of SPRT and Sequential Bayes Procedures for Classifying Examinees into two Categories using a Computerized Test. Journal of Educational and Behavioral Statistics, 21, 405-414.
http://dx.doi.org/10.3102/10769986021004405 - 7. Corsini, G., DalleMese, E., Marchetti, G. and Verrazzani, L. (1985) Design of the SPRT for Radar Target Detection. IEE Proceedings F Communications, Radar and Signal Processing, 132, 139-148.
http://dx.doi.org/10.1049/ip-f-1.1985.0035 - 8. Fay, M., Kim, H. and Hachey, M. (2007) On Using Truncated Sequential Probability Ratio Test Boundaries for Monte Carlo Implementation of Hypothesis Tests. Journal of Computational and Graphical Statistics, 16, 946-967.
http://dx.doi.org/10.1198/106186007X257025 - 9. Malladi, D. and Speyer, J. (1999) A Generalized Shiryayev Sequential Probability Ratio Test for Change Detection and Isolation. IEEE Transactions on Automatic Control, 44, 1522-1534.
http://dx.doi.org/10.1109/9.780416 - 10. Matas, J. and Chum, O. (2005) Randomized Ransac with Sequential Probability Ratio Test. Tenth IEEE International Conference on Computer Vision (ICCV’05), 1, 1727-1732.
http://dx.doi.org/10.1109/ICCV.2005.198 - 11. Cyert, R. and DeGroot, M. (1975) Adaptive Economic Models. Academic Press.
- 12. Boutilier, C. (2003) On the Foundations of Expected Expected Utility. Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence (IJCAI-03), Acapulco, 9-15 August 2003, 285-290.
- 13. Chajewska, U., Koller, D. and Parr, R. (2000) Making Rational Decisions Using Adaptive Utility Elicitation. Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, Austin, Texas, 30 July-3 August 2000, 363-369.
- 14. Houlding, B. and Coolen, F.P.A. (2011) Adaptive Utility and Trial Aversion. Journal of Statistical Planning and Inference, 141, 734-747.
http://dx.doi.org/10.1016/j.jspi.2010.07.023 - 15. DeGroot, M. (1984) Changes in Utility as Information. Theory and Decision, 17, 287-303.
http://dx.doi.org/10.1007/BF00132613 - 16. R Core Team (2014) R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna.