Open Journal of Statistics
Vol.06 No.03(2016), Article ID:67749,9 pages
10.4236/ojs.2016.63046
Frequentist Model Averaging and Applications to Bernoulli Trials
Georges Nguefack-Tsague1, Walter Zucchini2, Siméon Fotso3
1Biostatistics Unit, Department of Public Health, Faculty of Medicine and Biomedical Sciences, University of Yaounde 1, Yaounde, Cameroon
2Institute for Statistics and Econometrics, University of Goettingen, Goettingen, Germany
3Department of Mathematics, Higher Teachers’ Training College, University of Yaoundé I, Yaoundé, Cameroon

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 26 April 2016; accepted 25 June 2016; published 28 June 2016
ABSTRACT
In several instances of statistical practice, it is not uncommon to use the same data for both model selection and inference, without taking account of the variability induced by model selection step. This is usually referred to as post-model selection inference. The shortcomings of such practice are widely recognized, finding a general solution is extremely challenging. We propose a model averaging alternative consisting on taking into account model selection probability and the likelihood in assigning the weights. The approach is applied to Bernoulli trials and outperforms Akaike weights model averaging and post-model selection estimators.
Keywords:
Model Selection, Post-Model Selection Estimator, Frequentist Model Averaging, Bernoulli Trials

1. Introduction
In statistical modeling practice, it is typical to ignore the variability of the model selection step, which can result in inaccurate post-selection inference (Berk et al. ( [1] [2] ), Belloni et al. ( [3] [4] ), Tibshirani et al. [5] , and Chernozhukov et al. [6] ). The model selection step is often a complex decision process and can involve collecting expert opinions, preprocessing, applying a variable selection rule, data-driven choice of one or more tuning parameters, among others. Except in simple cases, it is hard to explicitly characterize the form of the post-selection of interest while incorporating the variability of model selection. References for model selection include e.g. Zucchini [7] and Zucchini et al. [8] . An alternative to selecting a single model for estimation purposes is to use a weighted average of the estimates resulting from each of the models under consideration. This leads to the class of model averaging estimators. Model averaging can be done either in Bayesian and frequentist approaches. The most common Bayesian approach is Bayesian model averaging (BMA) and its variants, using Bayesian information criterion (BIC) as approximation (Schwarz [9] ). The seminal paper of Hoeting et al. [10] fully describes the basic of BMA. BMA and its applications can be found in Nguefack- Tsague ( [11] [12] ), Nguefack-Tsague and Ingo [13] , Nguefack-Tsague and Zucchini ( [14] [15] ). Several options are available for specifying the weights in frequentist approaches; references on least squares regression types and like include Hansen ( [16] - [21] ), Hansen and Racine [22] , Cheng and Hansen [23] , Charkhi et al. [24] , and Wan et al. [25] . The aforementioned weighting schemes perform model averaging on a set of nested candidate models with the weights vector chosen such that a specific criterion is minimized.
References using Akaike’s information criterion, AIC (Akaike [26] ) include Burnham and Anderson [27] , Nguefack-Zucchini [28] , Nguefack-Tsague ( [29] - [32] ). The R package [33] MuMIn is used to perform model averaging based on Burnham and Anderson [27] . Schomaker and Heumann [34] , and Schomaker [35] developes model averaging schemes based on multiple imputation and shrinkage; the R package MAMI is used for practical implementations. This paper is organized as follows: In Section 2, we develop model averaging based on information criterion while, in Section 3, we propose a new approach for computing the weights for the competing models, one that takes both account the selection probability and the likelihood of each model. Section 4 illustrates with applications to Bernoulli trials. The paper ends with concluding remarks.
2. Frequentist Model Averaging Based on Information Criterion
Let 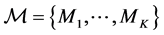 be a set of K plausible models to estimate
be a set of K plausible models to estimate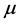 , the quantity of interest. Denote by
, the quantity of interest. Denote by 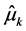 the estimator of
the estimator of 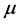 obtained when using model
obtained when using model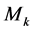 . Model averaging involves finding non-negative weights,
. Model averaging involves finding non-negative weights, 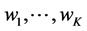 , that sum to one, and then estimating
, that sum to one, and then estimating 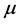 by
by
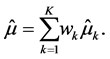 (1)
(1)
In model selection, the model selection criterion determines which model is to be assigned weight one, i.e. which model is selected and subsequently used to estimate the parameter of interest. We note that, since the value of the selection criterion depends on the data, the index, 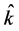 , of the selected model is a random variable. We therefore denote the selected model by
, of the selected model is a random variable. We therefore denote the selected model by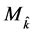 , and the corresponding estimator of the quantity of interest,
, and the corresponding estimator of the quantity of interest, 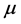 , by
, by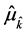 . In terms of the notation introduced above, we may write
. In terms of the notation introduced above, we may write
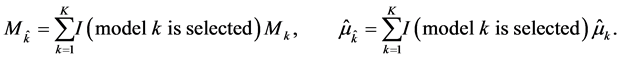
Clearly, the selected model depends on the set of candidate models, 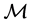 , and on the selection procedure, which we denote by S. However, it is important to realize that, even if the same
, and on the selection procedure, which we denote by S. However, it is important to realize that, even if the same 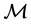 and S, are used, different samples can lead to different models being selected;
and S, are used, different samples can lead to different models being selected;  is a “randomly selected model”. In this section we focus attention on post-model selection estimators (PMSEs), which is the special case of model averaging estimators with zero/one weights only.
is a “randomly selected model”. In this section we focus attention on post-model selection estimators (PMSEs), which is the special case of model averaging estimators with zero/one weights only.
Some classical model averaging weights base the weights on penalized likelihood values. Let  denote an “information criterion”of the form
denote an “information criterion”of the form
 (2)
(2)
where  is a penalty term, and
is a penalty term, and  is the maximized likelihood value for the model
is the maximized likelihood value for the model . The Akaike infor- mation criterion (AIC, Akaike [26] ) is the special case with
. The Akaike infor- mation criterion (AIC, Akaike [26] ) is the special case with , where
, where  is the number of parameters of model
is the number of parameters of model . Buckland et al. [36] proposed using weights of the form:
. Buckland et al. [36] proposed using weights of the form:
 (3)
(3)
“Akaike weights” (denoted by ) refer to the case with
) refer to the case with . Numerous applications of Akaike weights are given in Burnham and Anderson [27] .
. Numerous applications of Akaike weights are given in Burnham and Anderson [27] .
3. Likelihood and Selection Probability in Assigning the Weights
Since the selection procedure (S) and likelihood are important for model selection, we therefore suggest estimating  by a weighted average of the
by a weighted average of the  in which the weights take account of S, specifically where they depend on estimators
in which the weights take account of S, specifically where they depend on estimators .
.
 (4)
(4)
The likelihoods are taken into account because they quantify the relative plausibility of the data under each competing model; the estimated selection probability  adjusts the weights for the selection pro- cedure. Both of these components are required. If one were to use only the likelihoods to determine the weights then complex models (i.e. models having many parameters) would automatically be assigned larger weights. The weights
adjusts the weights for the selection pro- cedure. Both of these components are required. If one were to use only the likelihoods to determine the weights then complex models (i.e. models having many parameters) would automatically be assigned larger weights. The weights  are similar to the weights
are similar to the weights  defined in (3) but they differ in the way the likelihood is adjusted. With the proposed method a “bad” model will be penalized by any reasonable selection procedure through the probability
defined in (3) but they differ in the way the likelihood is adjusted. With the proposed method a “bad” model will be penalized by any reasonable selection procedure through the probability , even if it is complex in terms of the number of parameters. We let the selection procedure determine in how far a model is penalized.
, even if it is complex in terms of the number of parameters. We let the selection procedure determine in how far a model is penalized.
If the selection probabilities depend on some parameter for which a closed form expression exists, and if one can find an estimator of the parameter, then it is possible to obtain estimators for these probabilities.
4. Applications to Bernoulli Trials
Let  be n independent Bernouilli trials, that is
be n independent Bernouilli trials, that is ,
,  is the number of successes;
is the number of successes;
Y-binomial (n, q), q unknown. Inference will be based on Y, since the likelihood function of the Xi’s is
 and involves the sufficient statistic Y.
and involves the sufficient statistic Y. ,
,  is the proba-
is the proba-
bility mass function (PMF) of Y; the quantity of interest is . Sensitivity analyses showed that the finding obtained here are insensitive to parameter choice, irrespective of the sample size n.
. Sensitivity analyses showed that the finding obtained here are insensitive to parameter choice, irrespective of the sample size n.
4.1. A Two-Model Selection Problem
(a) Consider the choice between the 2 models:  and
and . The true model may not belong to these 2 models. Suppose that the selection procedure chooses the model with smaller AIC. In this case, this entails to choosing the model with higher likelihood, since there is no parameter to be estimated for each model.
. The true model may not belong to these 2 models. Suppose that the selection procedure chooses the model with smaller AIC. In this case, this entails to choosing the model with higher likelihood, since there is no parameter to be estimated for each model.  will be chosen if
will be chosen if  or equivalently if
or equivalently if .
.


Let  and
and  be the probabilities of choosing models 1 and 2, respectively.
be the probabilities of choosing models 1 and 2, respectively.

where  is the cumulative distribution function of binomial (n, q).
is the cumulative distribution function of binomial (n, q).
The estimated probabilities are given by , where
, where  and
and
 . The PMSE
. The PMSE  if
if  and
and  otherwise. The properties of
otherwise. The properties of  are given by
are given by




The Akaike weights are defined by
 ,
, .
.
The adjusted likelihood weights are defined by
 ,
,
 .
.
The weighted estimators are
 .
.
 .
.
 .
.
 .
.
Figure 1 shows model selection probabilities for ,
,  and
and  for the range of parameter space. The two curves cross at
for the range of parameter space. The two curves cross at  showing different values of the parameters space used for weighting.
showing different values of the parameters space used for weighting.
Figure 2 compares PMSE to estimators based on Akaike weights and adjusted weights using true model selection probabilities. It can be seen that adjusted likelihood is always better than PMSE and Akaike weights estimators. However, for some values of the true parameter, the risk of Akaike weight tends to be slightly bigger than that of PMSEs. Maxima occur at  while minima occur at 0.4 and 0.6.
while minima occur at 0.4 and 0.6.
(b) Consider now a choice between the following two models:
 and
and .
.
AIC is used to select a model,  , for illustration, we choose
, for illustration, we choose 
 .
.
Model 1 is chosen if
 ,
,
 .
.
 and
and  are obtained by replacing
are obtained by replacing  by
by .
.
The PMSE  if
if  and
and  otherwise.
otherwise.

Figure 1. Model selection probabilities as a function q, 
 and
and .
.

Figure 2. Risk of two simple proportions comparing PMSEs, Akaike weights estimators and adjusted estimators as a function of q.

The Akaike weights are defined by
 ,
, 
and the adjusted weights is defined by
 ,
,
 .
.
Figure 3 displays model selection probabilities with both curves crossing at 0.6 and 0.4. At 0.5, while Model 2 is at the minimum, Model 1 is at maximum. Figure 4 displays risks performance of estimators. It can be seen that Akaike weighting does not perform better than PMSEs when the true parameter is between  and between
and between . However, the adjusted weights perform better than both.
. However, the adjusted weights perform better than both.
4.2. Multi-Model Choice
Consider also a choice between the following models:  for arbitrary K models;
for arbitrary K models;  known. For a choice using AIC criterion, since there is no unknown parameter, this is the same as selecting the model with higher likelihood. Model
known. For a choice using AIC criterion, since there is no unknown parameter, this is the same as selecting the model with higher likelihood. Model  is chosen if
is chosen if .
.
PMSE  if
if  is selected.
is selected.
 ,
,  if
if  is chosen and 0 otherwise. Model selection probability for
is chosen and 0 otherwise. Model selection probability for
model  is given by:
is given by: .
.
The estimated model selection probabilities  are given by replacing
are given by replacing  by the estimated
by the estimated
 . The Akaike weights are defined by
. The Akaike weights are defined by , and the adjusted weights by
, and the adjusted weights by
 .
.
Numerical computations of the properties for these estimators are for ,
,  , models are between 0.1 and 0.9 and are given in Figure 5. One can see that Akaike weights are not better than PMSEs for certain
, models are between 0.1 and 0.9 and are given in Figure 5. One can see that Akaike weights are not better than PMSEs for certain

Figure 3. Model selection probabilities as a function q.

Figure 4. Risk of two proportions comparing PMSEs, Akaike weights estimators and adjusted estimators as a function of q.

Figure 5. Risk of 30 models comparing PMSEs, Akaike weights esti- mators and adjusted estimators as a function of q.
regions of the parameter space, but the adjusted likelihood weights are better than both.
5. Concluding Remarks
In this paper, we have considered model averaging in frequentist perspective; and proposed an approach of assigning weights to competing models taking account model selection probability and likelihood. The method appears to perform well for Bernoulli trials. The method needs to be applied in variety of situations before it can be adopted.
Acknowledgements
We Thank the Editor and the referee for their comments on earlier versions of this paper.
Cite this paper
Georges Nguefack-Tsague,Walter Zucchini,Siméon Fotso, (2016) Frequentist Model Averaging and Applications to Bernoulli Trials. Open Journal of Statistics,06,545-553. doi: 10.4236/ojs.2016.63046
References
- 1. Berk, R., Brown, L. and Zhao, L. (2010) Statistical Inference after Model Selection. Journal of Quantitative Criminology, 26, 217-236.
http://dx.doi.org/10.1007/s10940-009-9077-7 - 2. Berk, R., Brown, L., Buja, A., Zhang, K. and Zhao, I. (2013) Valid Post-Selection Inference. Annals of Statistics, 41, 802-837.
http://dx.doi.org/10.1214/12-aos1077 - 3. Belloni, A., Chernozhukov, V. and Kato, K. (2015) Uniform Post-Selection Inference for Least Absolute Deviation Regression and Other Z-Estimation Problems. Biometrika, 102, 77-94.
http://dx.doi.org/10.1093/biomet/asu056 - 4. Belloni, A., Chernozhukov, V. and Wei, Y. (2016) Post-Selection Inference for Generalized Linear Models with Many Controls. Journal of Business and Economic Statistics.
http://dx.doi.org/10.1080/07350015.2016.1166116 - 5. Tibshirani, R.J., Taylor, J., Lockhart, R. and Tibshirani, R. (2014) Exact Post-Selection Inference for Sequential Regression Procedures. arXiv:1401.3889.
- 6. Chernozhukov, V., Hansen, C. and Spindler, M. (2015) Valid Post-Selection and Post-Regularization Inference: An Elementary, General Approach. Annual Review of Economics, 7, 649-688.
http://dx.doi.org/10.1146/annurev-economics-012315-015826 - 7. Zucchini, W. (2000) An Introduction to Model Selection Journal of Mathematical Psychology, 44, 41-61.
http://dx.doi.org/10.1006/jmps.1999.1276 - 8. Zucchini, W., Claeskens, G. and Nguefack-Tsague, G. (2011) Model Selection. International Encyclopedia of Statistical Science, Springer, Berlin Heidelberg, 830-833.
http://dx.doi.org/10.1007/978-3-642-04898-2_373 - 9. Schwarz, G. (1978) Estimating the Dimension of a Model. Annals of Statistics, 6, 461-465.
http://dx.doi.org/10.1214/aos/1176344136 - 10. Hoeting, J.A., Madigan, D., Raftery, A.E. and Volinsky, C.T. (1999) Bayesian Model Averaging: A Tutorial (with Discussions). Statistical Science, 14, 382-417.
- 11. Nguefack-Tsague, G. (2011) Using Bayesian Networks to Model Hierarchical Relationships in Epidemiological Studies. Epidemiology and Health, 33, e201100633.
http://dx.doi.org/10.4178/epih/e2011006 - 12. Nguefack-Tsague, G. (2013) Bayesian Estimation of a Multivariate Mean under Model Uncertainty. International Journal of Mathematics and Statistics, 13, 83-92.
- 13. Nguefack-Tsague, G. and Ingo, B. (2014) A Focused Bayesian Information Criterion. Advances in Statistics, 2014, Article ID: 504325.
http://dx.doi.org/10.1155/2014/504325 - 14. Nguefack-Tsague, G. and Zucchini W. (2016) A Mixture-Based Bayesian Model Averaging Method. Open Journal of Statistics, 6, 220-228.
http://dx.doi.org/10.4236/ojs.2016.62019 - 15. Nguefack-Tsague, G. and Zucchini, W. (2016) Effects of Bayesian Model Selection on Frequentist Performances: An Alternative Approach. Applied Mathematics, 7, 1103-1105.
http://dx.doi.org/10.4236/am.2016.710098/am.2016.710098 - 16. Hansen, B.E. (2007) Least Squares Model Averaging. Econometrica, 75, 1175-1189.
http://dx.doi.org/10.1111/j.1468-0262.2007.00785.x - 17. Hansen, B.E. (2008) Least-Squares Forecast Averaging. Journal of Econometrics, 146, 342-350.
http://dx.doi.org/10.1016/j.jeconom.2008.08.022 - 18. Hansen, B.E. (2009) Averaging Estimators for Regressions with a Possible Structural Break. Econometric Theory, 25, 1498-1514.
http://dx.doi.org/10.1017/S0266466609990235 - 19. Hansen, B.E. (2010) Averaging Estimators for Autoregressions with a Near Unit Root. Journal of Econometrics, 158, 142-155.
http://dx.doi.org/10.1016/j.jeconom.2010.03.022 - 20. Hansen, B.E. (2014) Model Averaging, Asymptotic risk, and Regressor Groups. Quantitative Economics, 5, 495-530.
http://dx.doi.org/10.3982/QE332 - 21. Hansen, B.E. (2014) Nonparametric Sieve Regression: Least Squares, Averaging Least Squares, and Cross-Validation. In: Racine, J., Su, L.J. and Ullah, A., Eds., Handbook of Applied Nonparametric and Semiparametric Econometrics and Statistics, Oxford University Press, Oxford, 215-248.
- 22. Hansen, B.E. and Racine, J.S. (2012) Jackknife Model Averaging. Journal of Econometrics, 167, 38-46.
http://dx.doi.org/10.1016/j.jeconom.2011.06.019 - 23. Cheng, X. and Hansen, B.E. (2015) Forecasting with Factor-Augmented Regression: A Frequentist Model Averaging Approach. Journal of Econometrics, 186, 280-293.
http://dx.doi.org/10.1016/j.jeconom.2015.02.010 - 24. Charkhi, A., Claeskens, G. and Hansen, B.E. (2016) Minimum Mean Squared Error Model Averaging in Likelihood Models. Statistica Sinica, 26, 809-840.
http://dx.doi.org/10.5705/ss.202014.0067 - 25. Wan, A.T.K., Zhang X. and Zou, G. (2010) Least Squares Model Averaging by Mallows Criterion. Journal of Econometrics, 156, 277-283.
http://dx.doi.org/10.1016/j.jeconom.2009.10.030 - 26. Akaike, H. (1973) Information Theory and an Extension of the Maximum Likelihood Principle. 2nd International Symposium on Information Theory, Akademiai Kiado, Budapest, 267-281.
- 27. Burnham, K.P. and Anderson, D.R. (2013) Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach. Springer, Cambridge.
- 28. Nguefack-Tsague, G. and Zucchini, W. (2011) Post-Model Selection Inference and Model Averaging. Pakistan Journal of Statistics and Operation Research, 7, 347-361.
http://dx.doi.org/10.18187/pjsor.v7i2-Sp.292 - 29. Nguefack-Tsague, G. (2013) On Bootstrap and Post-Model Selection Inference. International Journal of Mathematics and Computation, 21, 51-64.
- 30. Nguefack-Tsague, G. (2013) An Alternative Derivation of Some Commons Distributions Functions: A Post-Model Selection Approach. International Journal of Applied Mathematics and Statistics, 42, 138-147.
- 31. Nguefack-Tsague, G. (2014) Estimation of a Multivariate Mean under Model Selection Uncertainty. Pakistan Journal of Statistics and Operation Research, 10, 131-145.
http://dx.doi.org/10.18187/pjsor.v10i1.449 - 32. Nguefack-Tsague, G. (2014) On Optimal Weighting Scheme in Model Averaging. American Journal of Applied Mathematics and Statistics, 2, 150-156.
http://dx.doi.org/10.12691/ajams-2-3-9 - 33. R Development Core Team (2016) R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna.
- 34. Schomaker, M. and Heumann, C. (2014) Model Selection and Model Averaging after Multiple Imputation. Computational Statistics and Data Analysis, 77, 758-770.
http://dx.doi.org/10.1016/j.csda.2013.02.017 - 35. Schomaker, M. (2012) Shrinkage Averaging Estimation. Statistical Papers, 53, 1015-1034.
http://dx.doi.org/10.1007/s00362-011-0405-2 - 36. Buckland, S.T., Burnham, K.P. and Augustin, N.H. (1997) Model Selection: An Integral Part of Inference. Biometrics, 53, 603-618.
http://dx.doi.org/10.2307/2533961