 J. Software Engineering & Applications, 2010, 3: 99-108 doi:10.4236/jsea.2010.32013 Published Online February 2010 (http://www.SciRP.org/journal/jsea) Copyright © 2010 SciRes JSEA 99 A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers A. Akoum1, B. Daya1, P. Chauvet2 1Lab. GRIT, Institute of Technology, Lebanese University, Saida, Lebanon; 2CREAM/IRFA, Institute of Applied Mathematics, UCO, Angers, France. E-mail: alhussain.akoum@etud.univ-angers, b_daya@ul.edu.lb, pierre.chauvet@uco.fr Received November 10th, 2009; revised December 16th, 2009; accepted December 20th, 2009. ABSTRACT This work proposes a method for the detection and identification of parked vehicles stationed. This technique composed many algorithms for the detection, localization, segmentation, extraction and recognition of number plates in images. It is acts of a technology of image processing used to identify the vehicles by their number plates. Knowing that we work on images whose level of gray is sampled with (120×180), resulting from a base of abundant data by PSA. We present two algorithms allowing the detection of the horizontal position of the vehicle: the classical method “horizontal gradients” and our approach “symmetrical method”. In fact, a car seen from the front presents a symmetry plan and by detecting its axis, that one finds its position in the image. A phase of localization is treated using the parameter MGD (Maximum Gradient Difference) which allows locating all the segments of text per horizontal scan. A specific technique of filtering, combining the method of symmetry and the localization by the MGD allows eliminating the blocks which don’t pass by the axis of symmetry and thus find the good block containing the number plate. Once we locate the plate, we use four algorithms that must be realized in order to allow our system to identify a license plate. The first algorithm is adjusting the intensity and the contrast of the image. The second algorithm is segmenting the characters on the plate using profile method. Then extracting and resizing the characters and finally recognizing them by means of optical character recogni- tion OCR. The efficiency of these algorithms is shown using a database of 350 images for the tests. We find a rate of lo- calization of 99.6% on a basis of 350 images with a rate of false alarms (wrong block text) of 0.88% by image. Keywords: Vehicle Detection, Segmentation, Extraction, Recognition Number Plate, Gradient Method, Symmetry Method, Real-Time System 1. Introduction Automatic identification of the vehicles used, is an effec- tive control, in the automatic check of the traffic regula- tions and the maintenance of the application of the law on the public highways [1]. The identification of the ve- hicles is a crucial step in the intelligent transport systems. Today, vehicles play a great part in transportation. The traffic, also, increased because of population growth and human needs during the last years. Consequently, the control of the vehicles is becoming a big problem and much more difficult to solve. Since each vehicle is equipped with a single number plate, not of external charts, the tags or the transmitters must be recognizable at the number plate. Thus, many researches concerning the identification of cars involved the extraction and the recognition of number plate. Some of these works are the following: [2] proposed knowledge-guided boundary following and template matching for automatic vehicle identification. [2,3] rotted to find a presentation of six descriptors, among the most used. [4,5] found the de- scription of the detector. [8] found the description of the Dog detector. [6] used a genetic algorithm ASED seg- mentation to extract the plate area. [8] used Gabor jets of projection to form a vector characteristic for the recogni- tion of weak grey scale resolution character. [9] proposed a method of extraction of characters without preliminary knowledge of their position and the size of the image. The general information of the system depends mainly on the general information of the number plate. If one seeks the common characteristics for various types of number plates, one finds one of the fundamental charac- teristics which are contrast, which means relatively large difference of color or intensity between the signs and the background of the number plate. This fact is often used in many methods of localization of the number plates [10,  A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers 100 12,13], and the problem of localization of text in the im- age [11,14,15–17]. In our work, we study the processes allowing to detect and identify the plate number, the best possible, in real time system. The database contains images of good qual- ity (high-resolution: 1280×960 resize 120×180) for vehi- cles seen from the front, more or less near, parked either in the street or in a car park, with a negligible inclination. To contribute in improving the automatic vehicle plate detection and identification systems, this work presents, in a more robust way, the detection and identification of number plates in images of vehicles stationed. Automatic number plate recognition is a mass surveil- lance method that uses optical character recognition on images to read the license plates on vehicles. It can be used to store the images captured by the cameras as well as the text from the license plate, with some configurable to store a photograph of the driver. We present two algorithms allowing the detection of the horizontal position of the vehicle: the classical me- thod “horizontal gradients” and our approach “symmet- rical method” In fact, a car seen from the front presents a symmetry plan and by detecting its axis, we find its posi- tion in the image. A phase of localization is treated using the parameter MGD (Maximum Gradient Difference) which allows the detection to locate all the segments of text per horizontal scan. These calculations must take into account the horizontal position of the vehicle so as to remove the segments which are not cut by the axis of detection. The potential segments of text are then wid- ened or combined with possible adjacent segments of text by this line sweep (in the two directions) to form blocks of text, which will make, thereafter, the object of filtering. The blocks of text obtained are regarded as areas of candidate text. These areas must undergo a specific tech- nique of filtering which makes it possible to find the good block containing the plate number among different blocks obtained by the previous algorithm of detection. After locating the plate, we use four algorithms that must be executed so that our system can read a license plate. The first algorithm will adjust the intensity and the con- trast of the image. The second, will segment the charac- ters on the plate using vertical profile method. The third algorithm will extract and resize characters and the Last algorithm will allow optical character recognition OCR. During the adjustment phase, we use techniques of edge detection to increase the contrast between the characters and the background of the plate. Then a specified filter is used to eliminate the noise that surrounds the characters. The rest of the work is organized as follows: In Sec- tion 2, a description of the real dataset used in our ex- periment is given. We present, in Section 3, the two methods of detection of vehicles: “horizontal gradients” and “symmetrical approach”. In Section 4 we describe our approach of localization of the plate registration combining the MGD method with the symmetrical, we give in Section 5 the description of our algorithm which extracts the characters from the license plate, and we conclude in Section 6. 2. Databases The database (Base Images with License) contains im- ages of good quality (high-resolution: 1280×960 pixels resizes to 120×180 pixels) of vehicles seen of face, more or less near, parked either in the street or in a car park, with a negligible slope. The images being neither in stereophony nor in the form of sequence (video), they were treated consequently with methods not using infor- mation which can provide it video (movement, follow-up of vehicle) and stereophony (measurement of depth, validation). The cameras used can include existing road-rule en- forcement or closed-circuit television cameras as well as mobile units which are usually attached to vehicles. Some systems use infrared cameras to take a clearer im- age of the plates [18–21]. Let us note that in our system we will divide in a ran- dom way the unit of our database into two: 1) A base of Training on which we regulate all the pa- rameters and thresholds necessary to the system so as to obtain the best results. 2) A base T is on which we will test all our programs. 2.1 Labeling of the Data The all database was labeled in order to detect that vehi- cle which is not partially hidden, only on the vehicles which are in direct link with the vehicle equipped with a camera (potentially dangerous and close vehicle). 2.2 Characteristics of the Image The images employed have characteristics which limit the use of certain methods. Very of access, the images are in level of gray. What eliminates the methods using spaces of color RGB, HSV or others? Then, the images are isolated, in the direction where they make neither started from a sequence nor of a couple of stereo image. The video can be used to make a follow-up of the vehi- Figure 1. Some examples from the database training Copyright © 2010 SciRes JSEA  A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers101 cles and thus to check detections while stereophony makes it possible to have information of depth. The im- ages have an original size of 1280×960 pixels. (Figure 1) 3. Our Approach for the Detection of the Vehicle Position The bibliographical study led on the detection of vehicle for help to control, has brought to us a certain number of method and technique imagined for a few years. From this study, our work of development was to create and test some one of these methods. We limited ourselves mainly to two techniques of de- tection. These techniques are the following ones: Method horizontal gradients. Our approach (Method Symmetry). The goal is to detect the position of the vehicles in or- der to exclude false alarms, all around the vehicle that we will find in the stage of detection of the plate and to keep only those which are cut by the axis of detection. Let us note that we work with images in level of gray under sampled (120×180), which eliminates the methods using spaces of color RGB or HSV and reduces the execution of time. 3.1 Method Horizontal Gradients The method uses knowledge in frequent appearance of the front view of a car having horizontal contours and basing on the fact that the horizontal position of the ve- hicle is where one finds a strong concentration of hori- zontal gradients [16]. Thus we calculate the profile of horizontal contours (the sum of the horizontal gradients by column) and the presence of a peak in this last makes it possible to go back to the horizontal position of the corresponding ve- hicle. 3.1.1 The Algorithm of the Method “Horizontal Gradients” Extraction of horizontal contours: We calculate the image of the horizontal gradients by withdrawing from the original image its shifted copy of a line to the bottom (or upwards). One filters the preceding image by pre- serving only the pixels belonging to a sufficiently long horizontal segment (here the length was fixed at 11 pix- els). This gives the indication of the horizontal gradients to us. Calculation of the horizontal profile: We calculate the profile of horizontal contours by summoning for each column the horizontal gradients. Detection of vehicle: By finding the position of the peak in the profile of horizontal contours, one finds the position of the vehicle. Figures 2 to 7 show an example of detailed execution for our algorithm, allowing the detection of the position of the vehicle. Figure 2. Initial image Figure 3. Conversion of the image into level of gray Figure 4. Subtraction enters the shifte d image and itself of a line to the bottom horizontal contours Figure 5. Image with segment length>11 Copyright © 2010 SciRes JSEA 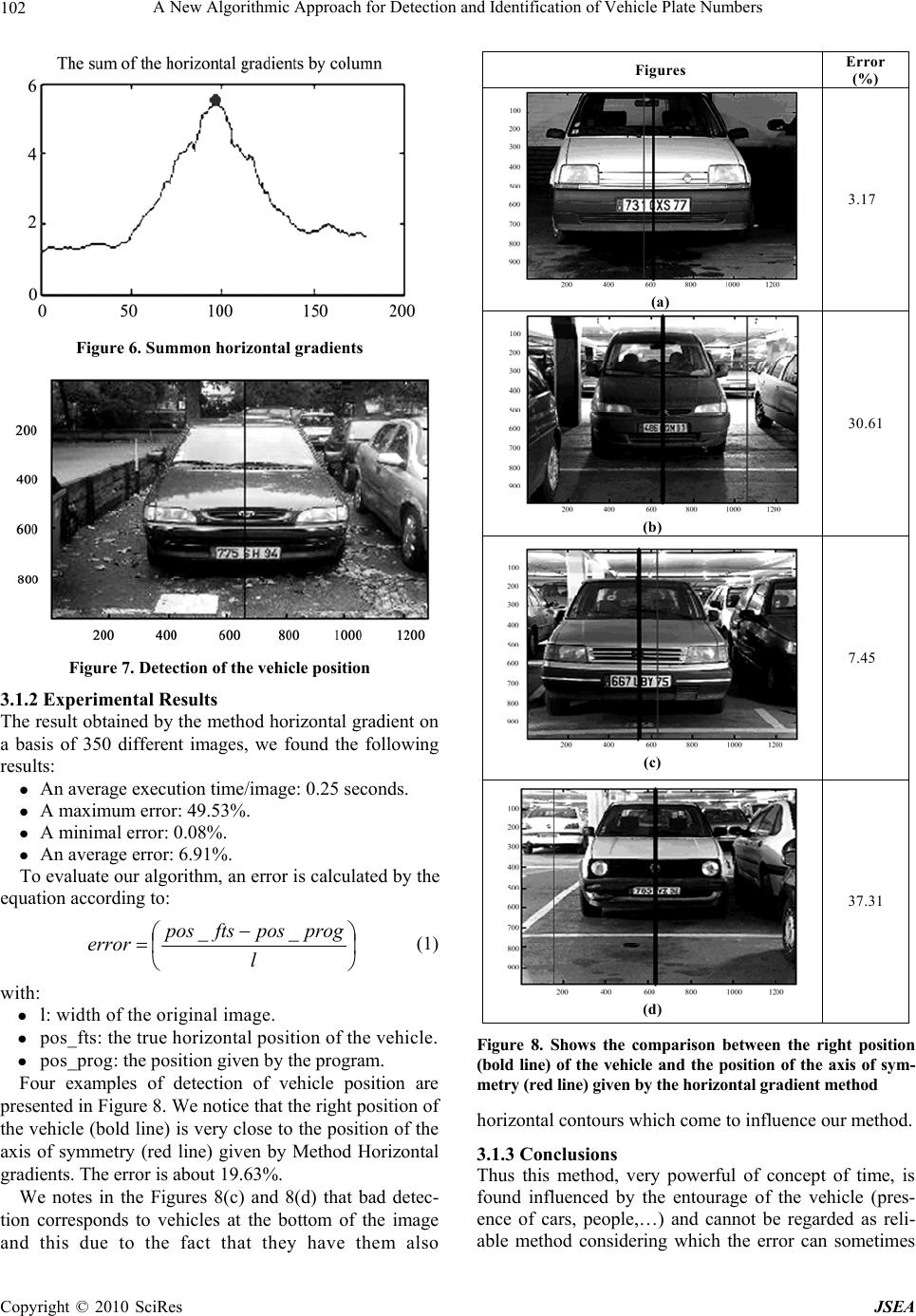 A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers 102 Figure 6. Summon horizontal gradients Figure 7. Detection of the vehicle position 3.1.2 Experimental Results The result obtained by the method horizontal gradient on a basis of 350 different images, we found the following results: An average execution time/image: 0.25 seconds. A maximum error: 49.53%. A minimal error: 0.08%. An average error: 6.91%. To evaluate our algorithm, an error is calculated by the equation according to: l progposftspos error __ (1) with: l: width of the original image. pos_fts: the true horizontal position of the vehicle. pos_prog: the position given by the program. Four examples of detection of vehicle position are presented in Figure 8. We notice that the right position of the vehicle (bold line) is very close to the position of the axis of symmetry (red line) given by Method Horizontal gradients. The error is about 19.63%. We notes in the Figures 8(c) and 8(d) that bad detec- tion corresponds to vehicles at the bottom of the image and this due to the fact that they have them also Figures Error (%) (a) 3.17 (b) 30.61 (c) 7.45 (d) 37.31 Figure 8. Shows the comparison between the right position (bold line) of the vehicle and the position of the axis of sym- metry (red line) given by the horizontal gradient method horizontal contours which come to influence our method. 3.1.3 Co n clusions Thus this method, very powerful of concept of time, is found influenced by the entourage of the vehicle (pres- ence of cars, people,…) and cannot be regarded as reli- able method considering which the error can sometimes Copyright © 2010 SciRes JSEA 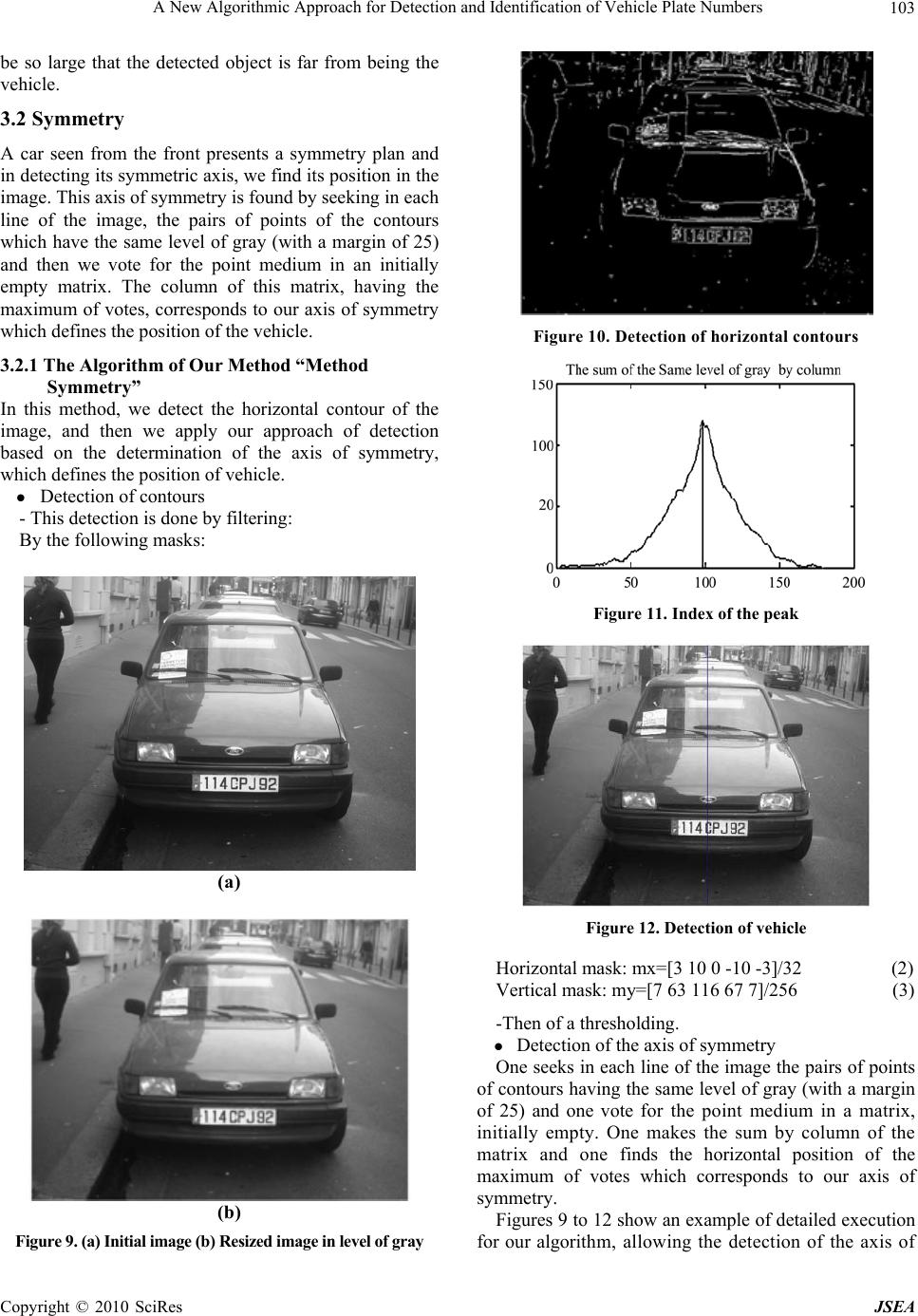 A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers103 be so large that the detected object is far from being the vehicle. 3.2 Symmetry A car seen from the front presents a symmetry plan and in detecting its symmetric axis, we find its position in the image. This axis of symmetry is found by seeking in each line of the image, the pairs of points of the contours which have the same level of gray (with a margin of 25) and then we vote for the point medium in an initially empty matrix. The column of this matrix, having the maximum of votes, corresponds to our axis of symmetry which defines the position of the vehicle. 3.2.1 The Algorithm of Our Method “Method Symmetry” In this method, we detect the horizontal contour of the image, and then we apply our approach of detection based on the determination of the axis of symmetry, which defines the position of vehicle. Detection of contours - This detection is done by filtering: By the following masks: (a) (b) Figure 9. (a) Initial image (b) Resized image in level of gray Figure 10. Detectio n of hori zontal co ntours Figure 11. Index of the peak Figure 12. Detection of vehicle Horizontal mask: mx=[3 10 0 -10 -3]/32 (2) Vertical mask: my=[7 63 116 67 7]/256 (3) -Then of a thresholding. Detection of the axis of symmetry One seeks in each line of the image the pairs of points of contours having the same level of gray (with a margin of 25) and one vote for the point medium in a matrix, initially empty. One makes the sum by column of the matrix and one finds the horizontal position of the maximum of votes which corresponds to our axis of symmetry. Figures 9 to 12 show an example of detailed execution for our algorithm, allowing the detection of the axis of Copyright © 2010 SciRes JSEA  A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers 104 symmetry of the vehicle. 3.2.2 Results On a test basis of 350 different images, one finds: An average execution time/image: 0.25 seconds. A maximum error2.87%. A minimal error: 0%. An average error0.34%. Examples of detection It is noted that with this method one always detected well the position of the vehicle independently of his lim- its. (see as in Figure 13) 3.2.3 Co n clusions Thus this method is reliable and effective being: it is simple, fast and the average error is 20 times smaller than that obtained with the method of the “horizontal gradi- ents” and thus we will continue our work using this method. 4. Algorithm of Localization of the Plate Registration Our algorithm is based on the fact that an area of text is characterized by its strong variation between the levels of gray and this is due to the passage from the text to the background and vice versa (see Figure 14). Thus by lo- cating all the segments marked by this strong variation, while keeping those which are cut by the axis of symme- try of the vehicle found in the preceding stage, and by gathering them. One obtains blocks to which we apply certain conditions (surface, width, height, the width ra- tio/height,…) in order to recover the areas of text candi- dates i.e. the areas which can be the number plate of the vehicle in the image. 4.1 Detection of the Segments of Potential Text This phase consists of elaborating one robust algorithm for the extraction of the text from the image. First, the algorithm calculates the MGD for each line (Maximum Gradient Difference) in order to keep all the segments which have a strong variation of level of gray (segments in which we find a high MGD), and which intersect with the axis of symmetry of the vehicle. To calculate this MGD, we start by applying a mask [-1 1] to each line of the image. Then, on each site of pixel, the MGD is calculated as being the difference be- tween the maximum and the minimum of values within a local window of size N×1 centered on the pixel. Parame- ter N depends on the maximum size of the text which we want to detect. A good choice for N is a value which is slightly larger than the width of the greatest character we want to detect. In our algorithm, we chose N=10. In general, the segments of text have great values of MGD (see Figure 15). Figure Error (%) (a) 0.13 (b) 0.72 (c) 0.81 (d) 0.15 Figure 13. Show the comparison between the right position (bold line) of the vehicle and the position of the axis of symmetry (red line) given by the symmetrical method Copyright © 2010 SciRes JSEA 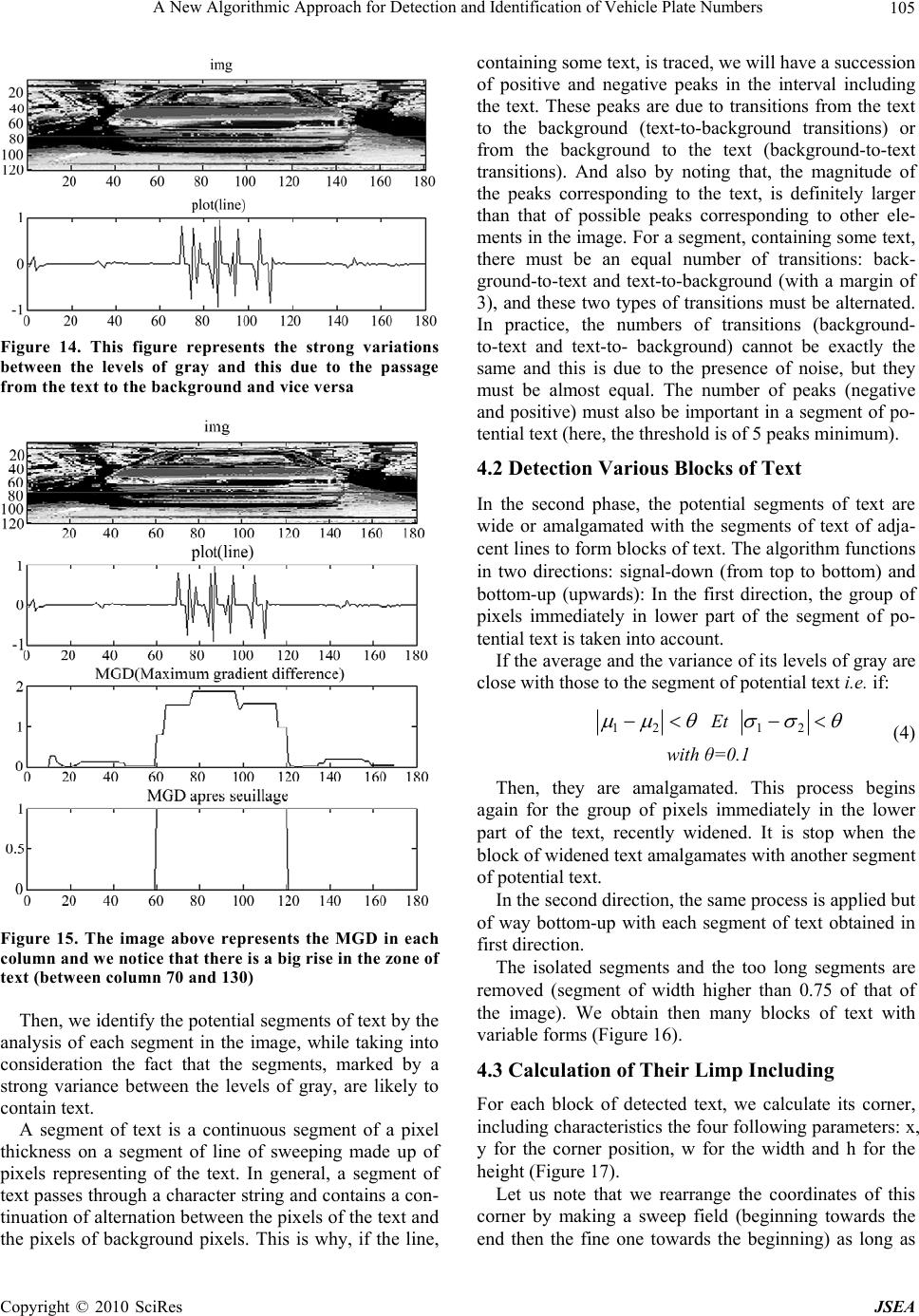 A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers105 Figure 14. This figure represents the strong variations between the levels of gray and this due to the passage from the text to the background and vice versa Figure 15. The image above represents the MGD in each column and we notice that there is a big rise in the zone of text (between column 70 and 130) Then, we identify the potential segments of text by the analysis of each segment in the image, while taking into consideration the fact that the segments, marked by a strong variance between the levels of gray, are likely to contain text. A segment of text is a continuous segment of a pixel thickness on a segment of line of sweeping made up of pixels representing of the text. In general, a segment of text passes through a character string and contains a con- tinuation of alternation between the pixels of the text and the pixels of background pixels. This is why, if the line, containing some text, is traced, we will have a succession of positive and negative peaks in the interval including the text. These peaks are due to transitions from the text to the background (text-to-background transitions) or from the background to the text (background-to-text transitions). And also by noting that, the magnitude of the peaks corresponding to the text, is definitely larger than that of possible peaks corresponding to other ele- ments in the image. For a segment, containing some text, there must be an equal number of transitions: back- ground-to-text and text-to-background (with a margin of 3), and these two types of transitions must be alternated. In practice, the numbers of transitions (background- to-text and text-to- background) cannot be exactly the same and this is due to the presence of noise, but they must be almost equal. The number of peaks (negative and positive) must also be important in a segment of po- tential text (here, the threshold is of 5 peaks minimum). 4.2 Detection Various Blocks of Text In the second phase, the potential segments of text are wide or amalgamated with the segments of text of adja- cent lines to form blocks of text. The algorithm functions in two directions: signal-down (from top to bottom) and bottom-up (upwards): In the first direction, the group of pixels immediately in lower part of the segment of po- tential text is taken into account. If the average and the variance of its levels of gray are close with those to the segment of potential text i.e. if: 21 Et 21 (4) with θ=0.1 Then, they are amalgamated. This process begins again for the group of pixels immediately in the lower part of the text, recently widened. It is stop when the block of widened text amalgamates with another segment of potential text. In the second direction, the same process is applied but of way bottom-up with each segment of text obtained in first direction. The isolated segments and the too long segments are removed (segment of width higher than 0.75 of that of the image). We obtain then many blocks of text with variable forms (Figure 16). 4.3 Calculation of Their Limp Including For each block of detected text, we calculate its corner, including characteristics the four following parameters: x, y for the corner position, w for the width and h for the height (Figure 17). Let us note that we rearrange the coordinates of this corner by making a sweep field (beginning towards the end then the fine one towards the beginning) as long as Copyright © 2010 SciRes JSEA  A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers 106 Figure 16. Detection of plate numbers (without filtering) Figure 17. Detection of the block of text having the same characteristic of the plate number (after filtering) less than 40% of the pixels are white. 4.4 Filtering of the Blocks of Text In the last phase, we filter each block detected, in func- tion of: 1) Its geometrical properties which are: a) Width/height ratio must be higher than 5. b) Surface must be higher than 60 pixels. c) Width must be lower than 60% of the width of the image. 2) Its contents: After a numerical representation of each block, we calculate the ratio between the number of white pixels and that of the black pixels (minimum/maximum). This report/ratio corresponds to the proportion of the text on the block which must be higher than 0.15 (the text occu- pies more than 15% of the block). In the experimental results of the entire process, we found a rate of detection of 99.6% on a basis of 350 im- ages with a rate of false alarms (wrong block text) of 0.88% by image. 5. License Plate Characters Extracting The block of the plate detected in gray (Figure 18) will be converted into binary code, and we construct a matrix with the same size block detected. Then we make a his- togram that shows the variations of black and white characters [22]. To filter the noise, we proceed as follows: we calculate the sum of the matrix column by column, and then we calculate the min_sumbc and max_sumbc representing the minimum and the maximum of the black and white variations detected in the plaque. All variations which are less than 0.08 * max_sumbc will be considered as noises. These will be canceled facilitating the cutting of charac- ters. (Figure 19) To define each character, we detect areas with mini- mum variation (equal to min_sumbc). The first detection of a greater variation of the minimum value will indicate the beginning of one character. And when we find again another minimum of variation, this indicates the end of the character. So, we construct a matrix for each charac- ter detected. (Figure 20) The Headers of the detected characters are considered as noise and must be cut. Thus, we make a 90 degree rotation for each character and then perform the same work as before to remove these white areas. (Figure 21) Figure 18. Extracting of license plate Figure 19. Histogram to see the variation black and white of the characters Figure 20. The characters are separated by several verti- cal lines by de tecting the col umns completely black Copyright © 2010 SciRes JSEA  A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers107 Figure 21. Extraction of one character Figure 22. Rotation 90 degrees of the character Figure 23. Representation of the histogram of the alpha- numeric chain and extraction of a character from the number plate A second filter can be done at this stage to eliminate the small blocks through a process similar to that of ex- traction by variations black white column. (Figure 22) Finally, we make the rotation 3 times for each image to return to its normal state. Then, we convert the text in black and change the dimensions of each extracted char- acter to adapt it to our system of recognition. (Figure 23) 6. Conclusions In this paper, we presented a system of detection of the position of vehicles and the localization of their numbers plates by two robust algorithms: the classical “horizontal gradients” and our approach “symmetrical method”. Then we used four algorithms for the normalization, segmentation, extraction and recognition. In our system, we apply the symmetrical approach which allows finding the symmetrical axis which will determine the position of the vehicle in the image. Then we proposed an approach of localization for the plate, which calculates the MGD (Maximum Gradient Difference) and detects the potential segments of text per horizontal scan. The blocks of texts obtained are regarded as areas of text candidates. These areas must undergo a specific technique of filtering which makes it possible to find the good block contain- ing the numbers plates among the various blocks ob- tained by the previous algorithm. After detecting the plate, we use four algorithms: normalization (adjustment of the intensity and the contrast of the image), segmenta- tion of characters (separation of character on the plate), and extraction (removal each character of the plaque) and recognition (optical identification of characters by OCR). We tested our approach on a group of 350 images of vehicles seen from the front (taken in real situation). We obtained very encouraging results, in fact: a rate of de- tection of 99.6% with a rate of false alarms (wrong block text) of 0.88% by image. Moreover, the results also showed that the system is robust with respect to occlu- sions partial of the image. This work could have several continuations like: 1) An adaptation to all kinds of number plates (universal di- mensioning and flexible device); 2) A phase of recogni- tion of the characters in the detected blocks of text. Thus, we could conceive our own system of automatic reading of the number plates. 7. Acknowledgements The authors would like to thank Dr. Lionel PROVEST for his contribution to this work. This research was sup- ported by the CEDRE project (07SciF29/L42). REFERENCES [1] D. G. Bailey, D. Irecki, B. K. Lim, and L. Yang, “Test bed for number plate recognition applications,” Proceed- ings of First IEEE International Workshop on Electronic Design, Test and Applications (DELTA’02), IEEE Com- puter Society, 2002. [2] E. R. Lee, P. K. Kim, and H. J. Kim, “Automatic recogni- tion of a car license plate using color image processing,” Proceedings of the International Conference on Image Processing, 1994. [3] K. Mikolajczyk, T. Tuytelaars, C. Schmid, A. Zisserman, J. Matas, F. Schaffalitzky, T. Kadir, and L. Van Gool, “A comparison of affine region detectors,” International Journal of Computer Vision, 2006. [4] “Detecting salient blob-like image structures and their scales with a scale-space primal sketch: A method for fo- cus-of-attention,” International Journal of Computer Vi- sion, 1993. [5] T. Lindeberg, “Scale-space theory: A basic tool for ana- lyzing structures at different scales,” Journal of Applied Statistics, 1994. [6] S. K. Kim, D. W. Kim, and H. J. Kim, “A recognition of vehicle license plate using a genetic algorithm based segmentation,” Proceedings of 3rd IEEE International Conference on Image Processing, Vol. 2, pp. 661–664, 2006. [7] D. G. Lowe, “Distinctive image features from scale-invariant key points,” IJCV, 2004. [8] H. Yoshimura, M. Etoh, K. Kondo, and N. Yokoya, “Gray-scale character recognition by Gabor jets projec- Copyright © 2010 SciRes JSEA  A New Algorithmic Approach for Detection and Identification of Vehicle Plate Numbers Copyright © 2010 SciRes JSEA 108 tion,” Proceedings 15th International Conference on Pat- tern Recognition, ICPR, IEEE Computer Society, Los Alamitos, USA, Vol. 2, pp. 335–8, 2000. [9] H. Hontani and T. Koga, “Character extraction method without prior knowledge on size and information,” Pro- ceedings of the IEEE International Vehicle Electronics Conference (IVEC’01), pp. 67–72, 2001. [10] H. Kwaśnicka and B. Wawrzyniak, “License plate local- ization and recognition in camera pictures,” Gliwice, Po- land, November 13–15, 2002. [11] E. K. Wong and M.Chen, “A new robust algorithm for video text extraction: Pattern recognition,” pp 1397–1406, 2003. [12] S. Ozbay and E. Ercelebi, “Automatic vehicle identifica- tion by plate,” Proceedings of Word Academy of Science Engineering and Technology, ISSN, Vol. 9, pp. 1307– 6884, November 2005. [13] N. Vazquer, M. Nakano, and H. perez Meana Autom, “Automatic system for localization and recognition of ve- hicle plate number,” Journal of Applied Research and Technology, Vol. 1, pp. 63–77, 2003. [14] L. M. B. Claudino, “Text fragments segmentation for license plate location,” Master’s Thesis (in Portuguese), Graduate Program of Electrical Engineering of Universi- dade Federal de Minas Gerais–PPGEE/UFMG, Belo Horizonte-MG, Brazil, 2005. [15] L. M. B. Claudino, A. de P. Braga, and A. de A. Ara_ujo, “Text fragments segmentation for license plate location,” (in Portuguese), CD-ROM Proceedings of the Workshop of Theses and Dissertations on Computer Graphics and Image Processing of the IEEE. [16] A. Khammari, F. Nashashibi, Y. Abramson, and C. Laur- geau, “Vehicle detection combining gradient analysis and adaboost classification,” In 8th International IEEE Con- ference on Intelligent Transportation Systems, Vienna, Austria, pp. 66–71, September 2005. [17] A. Cornuéjols et L. Miclet. Eyrolles, “Apprentissage par combinaison de décisions,” XIX Brazilian Symposium on Computer Graphics and Image Processing-WTDCGPI/ SIBGRAPI, Manaus-AM, Brazil, Extended (English) version to appear in the Brazilian Journal of Theoretical and Applied Computing, 2006. [18] http://www.photocop.com/recognition.htm. [19] http://vortex.cs.wayne.edu/papers/ijns1997.pdf. [20] http://www.siemenstraffic.com/customcontent/case_studi es/anpr/anpr.html. [21] http://www.be.itu.edu.tr/Ekahraman/License plate char- acter segmentation based on the Gabor transform and vector quantization.pdf. [22] H. Hontani and T. Kogth, “Character extraction method without prior knowledge on size and information,” Pro- ceedings of the IEEE lnternational Vehicle Electronics Conference (IVEC’01), pp. 67–72, 2001.
|