Applied Mathematics
Vol. 3 No. 2 (2012) , Article ID: 17399 , 10 pages DOI:10.4236/am.2012.32030
Model of Overlapping Messages with Degenerate Coding
1Institute of Evolution, University of Haifa, Haifa, Israel
2Software Engineering Department, ORT Braude College of Engineering, Karmiel, Israel
Email: valery@research.haifa.ac.il, vlvolkov@braude.ac.il
Received September 29, 2011; revised November 26, 2011; accepted December 4, 2011
Keywords: Overlapping Messages; Degenerate Coding; Sequence Compacting; De Bruijn Graph; DNA Triplet Code
ABSTRACT
Superposition of signals in DNA molecule is a sufficiently general principle of information coding. The necessary requirement for such superposition is the degeneracy of the code, which allows placing different messages on the same DNA fragment. Code words that are equivalent in the informational sense (i.e., synonyms) form synonymous group and the entire set of code words is partitioned into synonymous groups. This paper is dedicated to constructing and analyzing the model of synonymous coding. We evaluate some characteristics of synonymous coding as applied to code words of length two although many definitions may be extended for words of arbitrary length.
1. Introduction
The article discusses the peculiarities of degenerate codes with the emphasis on their use for creating “overlapping messages”. This study was motivated by the existence of such type of messages in DNA-protein coding. In what follows, we will describe some features of the DNA triplet code which are relevant for our study.
It is well known that the information contained in DNA is written using a 4-letter alphabet 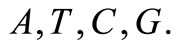 There exist a total of 64 3-letter words over this alphabet, encoding 20 amino acids. Consequently, the code is degenerate, i.e., the same amino acid can be encoded by several alternative words. A group that contains all possible words encoding the same amino acid is referred to as a synonymous group. Any finite length succession of code words can be viewed as a message of DNA sequence. Such message is decoded starting from the first letter (start position), each successive triplet being transformed into the corresponding amino-acid. Usually, there exists only one start position to make a sensible message. However, in some cases the choice of another start position (e.g., shifted by one letter) also results in a sensible message. This is the situation of overlapping messages, which is quite common in genes [1-3] and there exist hundreds of overlapping pairs of protein coding genes in vertebrate genomes [4]. In particular, the start position of overlapping genes may be shifted by 1 or 2 positions, which is the case, e.g., in virus genomes [5-7].
There exist a total of 64 3-letter words over this alphabet, encoding 20 amino acids. Consequently, the code is degenerate, i.e., the same amino acid can be encoded by several alternative words. A group that contains all possible words encoding the same amino acid is referred to as a synonymous group. Any finite length succession of code words can be viewed as a message of DNA sequence. Such message is decoded starting from the first letter (start position), each successive triplet being transformed into the corresponding amino-acid. Usually, there exists only one start position to make a sensible message. However, in some cases the choice of another start position (e.g., shifted by one letter) also results in a sensible message. This is the situation of overlapping messages, which is quite common in genes [1-3] and there exist hundreds of overlapping pairs of protein coding genes in vertebrate genomes [4]. In particular, the start position of overlapping genes may be shifted by 1 or 2 positions, which is the case, e.g., in virus genomes [5-7].
In this study, the simplest coding model is suggested for a degenerate code with overlapping messages. This model, despite its simplicity, gives the opportunity to investigate the described above biological mechanisms. In particular, we evaluate the effectiveness of creating overlapping messages depending on the type of synonymous partitioning and assess the effectiveness using a specially constructed sequence. We obtain these characteristics for code words of length 2; however, some of the definitions given here can be extended also to words of arbitrary length [8].
Assume that there exists alphabet  where
where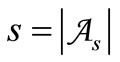 . Let the code words be the words of length 2 over this alphabet and let them belong to set
. Let the code words be the words of length 2 over this alphabet and let them belong to set  Set
Set  does not necessarily coincide with the entire set of the words of length 2 over alphabet
does not necessarily coincide with the entire set of the words of length 2 over alphabet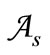 . Further, let
. Further, let 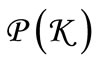 be a certain partition of set
be a certain partition of set  into non-empty subsets. Assume that, being assigned to each subset, there exists only one message, which can be transmitted via any element of this subset. Thus, the elements of each subset are synonyms, and any partition
into non-empty subsets. Assume that, being assigned to each subset, there exists only one message, which can be transmitted via any element of this subset. Thus, the elements of each subset are synonyms, and any partition 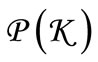 will be referred to as a synonymous partition. Let us consider a finite sequence of letters over alphabet
will be referred to as a synonymous partition. Let us consider a finite sequence of letters over alphabet , which we define as message M. We assume that a hypothetical decoding “device” reads the message word by word (the length of the words is 2), starting from the first position. As a result, an ordered sequence of separated words of length 2 is obtained. This “construction” is equivalent to the triplet coding and translation of protein.
, which we define as message M. We assume that a hypothetical decoding “device” reads the message word by word (the length of the words is 2), starting from the first position. As a result, an ordered sequence of separated words of length 2 is obtained. This “construction” is equivalent to the triplet coding and translation of protein.
Extending this analogy, we can note that decoding with a shift of the reading frame by 1 also creates a certain sequence of words of length 2. In the context of this model, we define both sequences as “functional” if the union of the words, constituting both sequences, contains just one word from each synonymous groups and does not contain non-code words of length 2. The latter condition is important in the situation where not all the words of length 2 over a given alphabet are code words. In other words, neither “functional” sequences contain synonymous words nor do they have common synonymous words.
We will call message M, considered above, a dense sequence. Respectively, a closed dense sequence will be called a dense contour. The mathematical methods that we are going to use lead to practically the same results in the cases of dense sequence or dense contour, but hereafter it will be more convenient to formulate propositions for a dense contour, rather than for a dense sequence. In this study, we investigate the existence criteria for a dense contour (dense sequence) for different synonymous partitions. In Section 2 we present the simplest examples of the connection between the composition of synonymous groups and the possibility to create a dense message. Cartesian synonymous partitions are introduced, which also may be used in the description of a standard triplet code [8]. These partitions comprise only a subset of all possible partitions, yet even in this simple case quite non-trivial properties are observed, which are the subject of the present study.
In the case of Cartesian partitions a new alphabet can be defined, in which each synonymous group may be substituted by a single word (in our case, of length 2). This alphabet is not a standard one, in the sense that its different letters are allowed to be superposed when they are used for creating a sequence. The rules of superposition are established by a special table of correspondence. Actually, each element of such an alphabet is a multivalued function, whose values belong to the original alphabet. The description of this alphabet, the main operational rules and the concept of a dense sequence over this alphabet are presented in Section 3. In the same section the main theorems on the existence of dense sequences are evaluated in the terms of abstract alphabet.
In Section 4, are specialized for the case of Cartesian synonymous partitions.
2. The Simplest Properties of Synonymous Partitions. Cartesian Synonymous Partitions
2.1. Example of a Synonymous Partition
Let us examine the simplest example of a synonymous partition. Let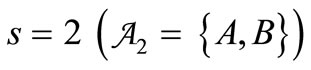 . There are four twoletter words
. There are four twoletter words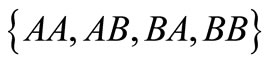 . Let us break this set arbitrarily into two non-empty synonymous classes, for example,
. Let us break this set arbitrarily into two non-empty synonymous classes, for example, 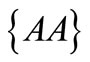 and
and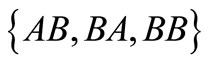 . Our task is to determine if a dense sequence or contour exist for this partition. Since there are only two classes, the sequence must contain two words with the shift of 1, i.e. have length 3. It is obvious that the word
. Our task is to determine if a dense sequence or contour exist for this partition. Since there are only two classes, the sequence must contain two words with the shift of 1, i.e. have length 3. It is obvious that the word 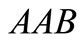 is the desired sequence, since it contains the two-letter word
is the desired sequence, since it contains the two-letter word 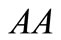 from the first synonymous set
from the first synonymous set 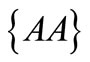 and the word
and the word 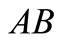 from the second set
from the second set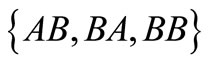 . There is one additional sequence
. There is one additional sequence 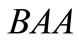 with the same properties:
with the same properties:  belongs to the second synonymous set and
belongs to the second synonymous set and 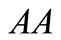 to the first one. Thus, there are two dense sequences for this synonymous partition (moreover, the synonym
to the first one. Thus, there are two dense sequences for this synonymous partition (moreover, the synonym 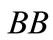 is not used), and packing by a contour is impossible at all. Indeed, such a contour would have to consist of two letters, which necessarily belonged to
is not used), and packing by a contour is impossible at all. Indeed, such a contour would have to consist of two letters, which necessarily belonged to 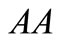 the only word from a synonymous group. But, obviously, this contour contains no words from the second synonymous group.
the only word from a synonymous group. But, obviously, this contour contains no words from the second synonymous group.
Let us examine now all possible synonymous partitions into two groups in this example. There are 7 such combinations: 5 partitions:
 (2.1)
(2.1)
plus those obtained from (2.1) by transposition of symbols  and
and 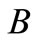 (The last three partitions are preserved under this transposition of letters.) It is sufficient to solve our problem only for partitions in (2.1). In the partition
(The last three partitions are preserved under this transposition of letters.) It is sufficient to solve our problem only for partitions in (2.1). In the partition 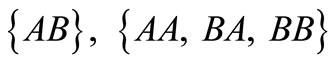 there are four complete dense sequences:
there are four complete dense sequences: 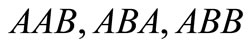 and
and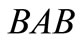 . In this case all synonyms of both groups are used. There is also a contour AB, which includes two words AB and BA from different synonymous partitions. We can say that this synonymous partition is more effective than the first one in terms of quantity of possible versions of the dense packing. Further, for the partition
. In this case all synonyms of both groups are used. There is also a contour AB, which includes two words AB and BA from different synonymous partitions. We can say that this synonymous partition is more effective than the first one in terms of quantity of possible versions of the dense packing. Further, for the partition 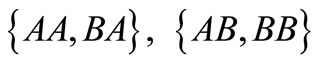 there are four dense sequences:
there are four dense sequences: 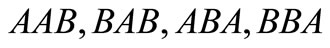 and one contour
and one contour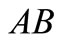 . For the partition
. For the partition 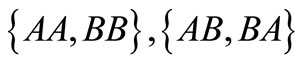 there are words
there are words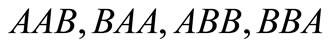 , and no contour. For the partition
, and no contour. For the partition 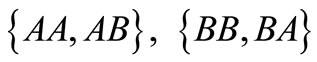 we have words BAA,
we have words BAA, 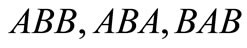 and a contour
and a contour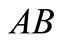 .
.
Our analysis of this example is now complete. We can see that for any synonymous partition into two sets there exist dense sequences, and the number of such sequences depends on the partition and varies from 2 to 4.
Statement 2.1. Let the set of code words 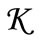 include all possible words of length 2 for any alphabet
include all possible words of length 2 for any alphabet  where
where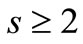 . Then for any partition into three nonempty synonymous groups there exists at least one dense sequence.
. Then for any partition into three nonempty synonymous groups there exists at least one dense sequence.
Proof. Let us prove that for 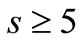 it is possible to select such four symbols of the alphabet
it is possible to select such four symbols of the alphabet  that the intersection of the set of the words over these symbols with each of three synonymous sets is not empty. In other words, the contraction of synonymous partition into this alphabet, reduced to the 4 symbols, also has three nonempty synonymous groups. Let us place the symbols of the alphabet
that the intersection of the set of the words over these symbols with each of three synonymous sets is not empty. In other words, the contraction of synonymous partition into this alphabet, reduced to the 4 symbols, also has three nonempty synonymous groups. Let us place the symbols of the alphabet  at the integral points of the
at the integral points of the 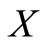 and
and 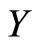 axes of rectangular system of coordinates (Let us call such points symbolic). Then the words of length two are the corresponding points of Cartesian plane. Let us consider the following cases:
axes of rectangular system of coordinates (Let us call such points symbolic). Then the words of length two are the corresponding points of Cartesian plane. Let us consider the following cases:
• Case 1: For any 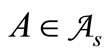 all words
all words 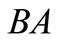 are synonyms. Then for any
are synonyms. Then for any 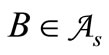 there exist
there exist 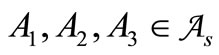 such that
such that 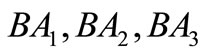 belong to different synonymous groups. Four symbols:
belong to different synonymous groups. Four symbols: 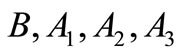 (see Figure 1).
(see Figure 1).
• Case 2: There exists 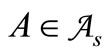 such that
such that 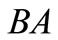 and
and  are not synonyms, and
are not synonyms, and  is synonymous either to
is synonymous either to 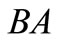 or to
or to  for any
for any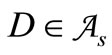 . Let
. Let 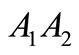 be not synonymous to
be not synonymous to 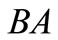 and
and . Then
. Then 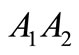 is not synonymous to
is not synonymous to 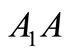 which is not synonymous to either
which is not synonymous to either 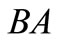 or
or . Four symbols:
. Four symbols: 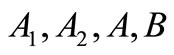 (or
(or ) (see Figure 2).
) (see Figure 2).
• Case 3: There exists 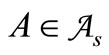 such that
such that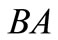 ,
,  and
and 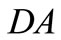 are not synonymous, and
are not synonymous, and 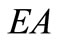 is synonymous to one of them for any
is synonymous to one of them for any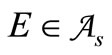 . Four symbols:
. Four symbols: 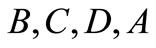 (see Figure 3).
(see Figure 3).
• Thus, it remains to prove Statement 2.1 for cases where . This task was solved by sorting out all the possibilities on the computer. It is shown that set
. This task was solved by sorting out all the possibilities on the computer. It is shown that set  is not empty in all cases for all nontrivial partitions into three synonymous groups. □
is not empty in all cases for all nontrivial partitions into three synonymous groups. □
Further analysis of the number of synonymous partitions only in terms of s is ineffective. Indeed, let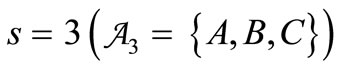 . There exist 9 two-letter words. Let us examine the partition
. There exist 9 two-letter words. Let us examine the partition 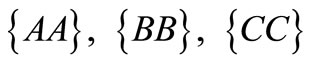 and {everything else}. Here we have 4 synonymous groups. Three groups consist of one word each and cannot be connected directly. It means that for their connection it is necessary to use at least two words from the fourth group, so that the obtained word will have not less than two synonyms. Therefore, there is no dense sequence for this partition.
and {everything else}. Here we have 4 synonymous groups. Three groups consist of one word each and cannot be connected directly. It means that for their connection it is necessary to use at least two words from the fourth group, so that the obtained word will have not less than two synonyms. Therefore, there is no dense sequence for this partition.
2.2. Two-Dimensional Cartesian Synonymous Partitions
Assume that there is given a finite alphabet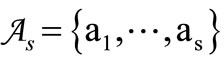 . We will use a Cartesian plane to represent all possible two-letter words over this alphabet. Let us arrange the letters of the alphabet
. We will use a Cartesian plane to represent all possible two-letter words over this alphabet. Let us arrange the letters of the alphabet 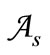 on the axes of the rectangular two-dimensional coordinate system, say, in the ascending order of numbers. Then the set of all possible two-letter words
on the axes of the rectangular two-dimensional coordinate system, say, in the ascending order of numbers. Then the set of all possible two-letter words 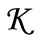 can be identified with the set of points
can be identified with the set of points  on the plane.
on the plane.
Example 2.2.1. Let 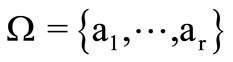 be a partition of the set
be a partition of the set 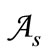 into the pairs of disjoint sets (classes)
into the pairs of disjoint sets (classes) 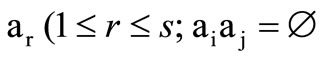 , if
, if 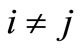 and
and 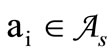 for
for 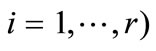 . Let us define a new alphabet. We will call the set ar a quotient letter, the set
. Let us define a new alphabet. We will call the set ar a quotient letter, the set 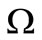 the alphabet, and
the alphabet, and
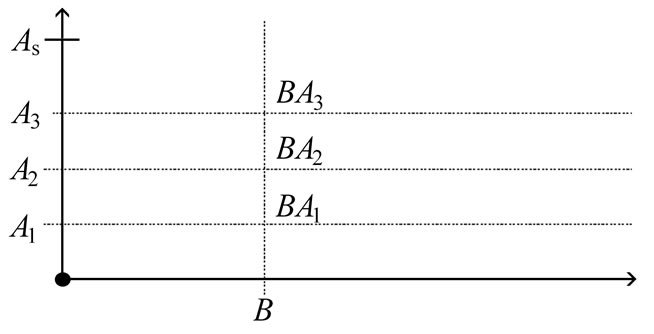
Figure 1. Geometrical illustration of proof of Statement 2.1, Case 1.
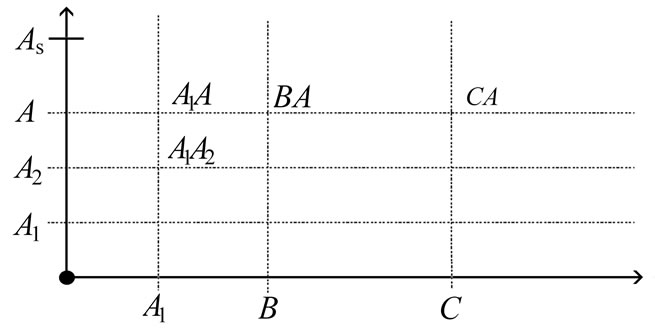
Figure 2. Geometrical illustration of proof of Statement 2.1, Case 2.

Figure 3. Geometrical illustration of proof of Statement 2.1, Case 3.
the set  in this context, the basic alphabet. The above partition induces the partition
in this context, the basic alphabet. The above partition induces the partition 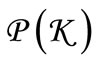 of all code words into the groups. All words obtained by the direct product of
of all code words into the groups. All words obtained by the direct product of  by
by 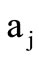 belong to one group. We will assume that each such group is synonymous, i.e. all code words included into this group contain the same message. It is convenient to denote synonymous group as a pair
belong to one group. We will assume that each such group is synonymous, i.e. all code words included into this group contain the same message. It is convenient to denote synonymous group as a pair  (see Figure 4). Let us call this pair of classes a quotient word. Let us define now the rules of the formation of the sequences of quotient words.
(see Figure 4). Let us call this pair of classes a quotient word. Let us define now the rules of the formation of the sequences of quotient words.
Namely, word  follows the word
follows the word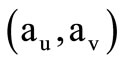 , if class
, if class 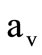 is equal to class
is equal to class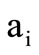 . Let us write down this chain as
. Let us write down this chain as
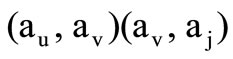 (2.2)
(2.2)
Clearly, such definition is coherent with the standard one for the sequence of letters. Let x be any element of the class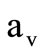 . Then (2.2) can be understood as any triplet, where and are any elements of the corresponding sets
. Then (2.2) can be understood as any triplet, where and are any elements of the corresponding sets 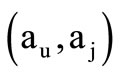 . Let us call such set of sequences of letters matched with the chain of quotient words the projection of the chain of quotient words. Further, by analogy for
. Let us call such set of sequences of letters matched with the chain of quotient words the projection of the chain of quotient words. Further, by analogy for
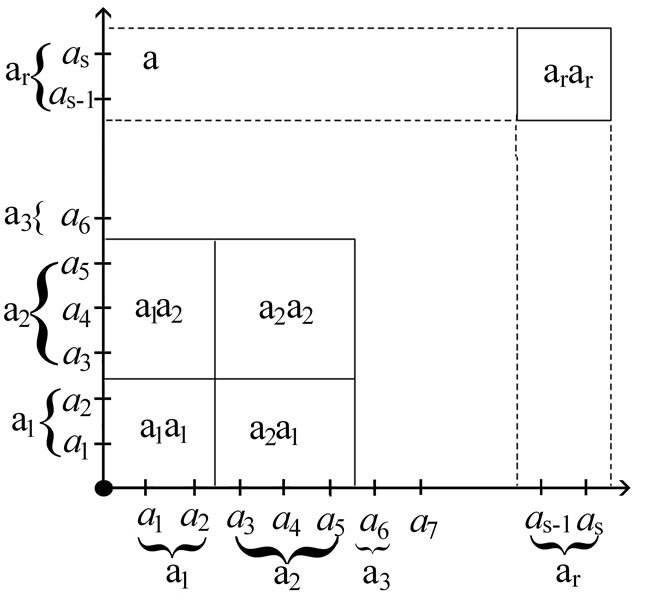
Figure 4. Partition of the set 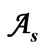 into the pairs of disjoint sets ar; a pair (ai, aj) is a synonymous group.
into the pairs of disjoint sets ar; a pair (ai, aj) is a synonymous group.
the quotient words 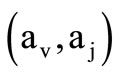 and
and 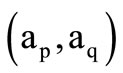 sets
sets 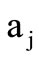 and
and 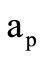 coincide and thus we can write down sequence of three words of the classes
coincide and thus we can write down sequence of three words of the classes
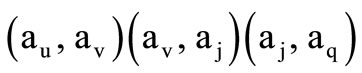 . (2.3)
. (2.3)
Obviously, the projection of this chain consists of all possible words of the form, where y is any element from the set aj, selected independently of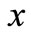 .
.
In the standard situation the alphabet W coincides withthe initial alphabet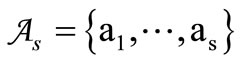 , when the partition is trivial
, when the partition is trivial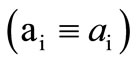 . Thus, in this situation we can use a Cartesian plane too.
. Thus, in this situation we can use a Cartesian plane too.
Example 2.2.2. Let 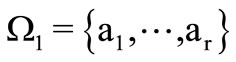 and
and  be two partitions of the set
be two partitions of the set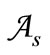 . The pair
. The pair 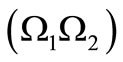 induces the partition of all code words into the groups as in the previous Example 2.1: all words obtained by the direct product of the set
induces the partition of all code words into the groups as in the previous Example 2.1: all words obtained by the direct product of the set  by the set
by the set 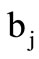 belong to the same group. We will also assume that each such group is synonymous and will denote it as the quotient word
belong to the same group. We will also assume that each such group is synonymous and will denote it as the quotient word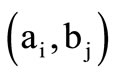 . Let us define now the rules of the formation of the sequences in the set of classes. Namely, word
. Let us define now the rules of the formation of the sequences in the set of classes. Namely, word 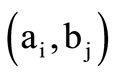 follows word
follows word  if the intersection of the second element of the latter word (class
if the intersection of the second element of the latter word (class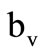 ) with the first element of the former word (class
) with the first element of the former word (class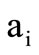 ) is not empty. Let us write down this chain as
) is not empty. Let us write down this chain as
 (2.4)
(2.4)
It is easy to see that such definition is coherent with the standard one for the sequence of letters. Namely, let x be any element from the intersection of sets 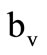 and
and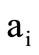 . Then (2.4) can be understood as any triplet, where
. Then (2.4) can be understood as any triplet, where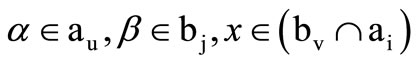 . Further, by analogy for the quotient words
. Further, by analogy for the quotient words 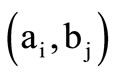 and
and 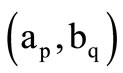 we can write down a sequence of three quotient words
we can write down a sequence of three quotient words
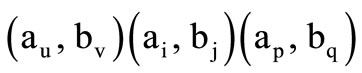 (2.5)
(2.5)
if the intersection of sets 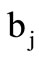 and
and 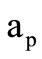 is non-empty. It is obvious that the projection of this chain consists of all possible words of the form, where
is non-empty. It is obvious that the projection of this chain consists of all possible words of the form, where 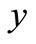 can be any element from the intersection of sets
can be any element from the intersection of sets 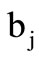 and
and 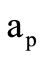 selected independently of
selected independently of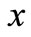 .
.
By definition, for any basic alphabet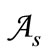 , a Cartesian synonymous partition is a partition of
, a Cartesian synonymous partition is a partition of  into pairs of type
into pairs of type  where
where 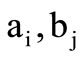 are some subsets of the letters of the basic alphabet. We call such partitions regular Cartesian synonymous partitions, if as in the previous examples sets
are some subsets of the letters of the basic alphabet. We call such partitions regular Cartesian synonymous partitions, if as in the previous examples sets 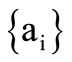 and
and 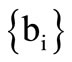 form the partition of the letters of the basic alphabet
form the partition of the letters of the basic alphabet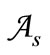 .
.
Example 2.2.3. Let a set of the code words over the alphabet 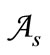 be divided into “rectangles”, which do not intersect and cover the entire Cartesian square
be divided into “rectangles”, which do not intersect and cover the entire Cartesian square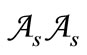 . The projections of the sides of these rectangles on X and Y axes form on these axes, generally speaking, two systems of intersecting intervals such that their union on each axis, obviously, is equal to
. The projections of the sides of these rectangles on X and Y axes form on these axes, generally speaking, two systems of intersecting intervals such that their union on each axis, obviously, is equal to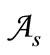 . Let us denote both these systems as earlier
. Let us denote both these systems as earlier  and
and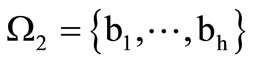 . In this case, however, sets
. In this case, however, sets  can intersect and the amount of sets r and h in each system can be greater than the length of the initial alphabet
can intersect and the amount of sets r and h in each system can be greater than the length of the initial alphabet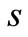 . For example, let us examine a partition containing pairs
. For example, let us examine a partition containing pairs 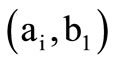 with
with 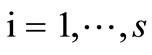 and square
and square 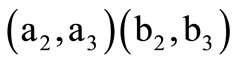 (see Figure 5). There exist already
(see Figure 5). There exist already 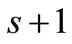 intervals on the X-axis. Nevertheless, it is possible to describe each “rectangle” (a synonymous set), as earlier, by an appropriate pair
intervals on the X-axis. Nevertheless, it is possible to describe each “rectangle” (a synonymous set), as earlier, by an appropriate pair  or by a single quotient word. The definition of a sequence of quotient words is transferred from Example 2.2.2. It is obvious that this is an irregular Cartesian synonymous partition.
or by a single quotient word. The definition of a sequence of quotient words is transferred from Example 2.2.2. It is obvious that this is an irregular Cartesian synonymous partition.
3. Abstract Dense Sequences
The quotient letters introduced above (Example 2.2.1) may be viewed as letters belonging to some alphabet and possessing a definite inner structure. As a counter example, we will also consider the abstract alphabet, i.e. an alphabet without any assumptions about the nature of origins of its letters. In this chapter we investigate the problem of constructing a dense sequence in terms of the abstract alphabet. This problem is close to standard for combination theory of words (see, for example, [9]), however differs in some details. This more generalized approach allows us to include into consideration not only Cartesian synonymous partition with the known mechanism of projecting abstract (quotient) letters onto the letters of the initial alphabet, but also other potential methods of mapping a correspondence between the signals as they overlap.
Analysis of Cartesian synonymous partition demonstrates that it is natural to consider two abstract alphabets. Indeed, different alphabets already appeared in examples

Figure 5. Pairs (ai, b1) with 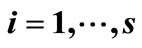 and a square (a2, a3) (b2, b3).
and a square (a2, a3) (b2, b3).
of Cartesian synonymous groups. For example, the collections of sets 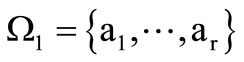 and
and 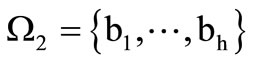 in Example 2.2 can be considered as two different alphabets for constructing the quotient words. Letters of the first alphabet can stand only at the beginning of code word, and letters of the second alphabet can stand only at the end of the word. The rules of the construction of sequences of code words in these examples were connected with the origin of letters of the both alphabets, while these alphabets were the subsets of a certain initial set.
in Example 2.2 can be considered as two different alphabets for constructing the quotient words. Letters of the first alphabet can stand only at the beginning of code word, and letters of the second alphabet can stand only at the end of the word. The rules of the construction of sequences of code words in these examples were connected with the origin of letters of the both alphabets, while these alphabets were the subsets of a certain initial set.
In line with this example, let us immediately define two different alphabets 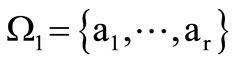 and
and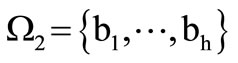 . That is, code word will be any pair
. That is, code word will be any pair 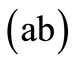 of letters such that its first element (letter) belongs to the alphabet
of letters such that its first element (letter) belongs to the alphabet  and the second one belongs to the alphabet
and the second one belongs to the alphabet . To construct a sequence of such words it is necessary to define a table of correspondence of the letters of different alphabets. We define this correspondence using a many-valued mapping
. To construct a sequence of such words it is necessary to define a table of correspondence of the letters of different alphabets. We define this correspondence using a many-valued mapping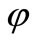 : set
: set 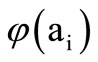 consists of the letters of the alphabet
consists of the letters of the alphabet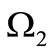 , which are compatible with the symbol
, which are compatible with the symbol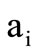 . Let us call this mapping a table of correspondence of symbols. Note that in the case of Cartesian synonymous partitions, when the quotient letters are subsets of a certain set, the table of correspondence of symbols is defined by the relationship (2.4), i.e. by the non-empty intersection of the corresponding subsets. In our abstract case the table of correspondence of symbols makes possible to form sequences of words of the form
. Let us call this mapping a table of correspondence of symbols. Note that in the case of Cartesian synonymous partitions, when the quotient letters are subsets of a certain set, the table of correspondence of symbols is defined by the relationship (2.4), i.e. by the non-empty intersection of the corresponding subsets. In our abstract case the table of correspondence of symbols makes possible to form sequences of words of the form
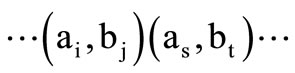 (3.1)
(3.1)
If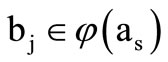 . Recall that in the case of the abstract alphabet the sequence is composed of the words following one another whereas the letters standing next to each other must satisfy the table of correspondence. In this case, a dense sequence is a sequence of words of the form (3.1), where each word is encountered exactly once. A dense contour is defined in a similar fashion.
. Recall that in the case of the abstract alphabet the sequence is composed of the words following one another whereas the letters standing next to each other must satisfy the table of correspondence. In this case, a dense sequence is a sequence of words of the form (3.1), where each word is encountered exactly once. A dense contour is defined in a similar fashion.
Let us analyze sequences of words over the alphabets  and
and  with the help of the following bipartite graph
with the help of the following bipartite graph . The sets of vertices
. The sets of vertices  and
and  of this graph correspond to the letters of the alphabets
of this graph correspond to the letters of the alphabets 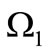 and
and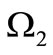 , respectively. Arcs, leaving the vertices of the set
, respectively. Arcs, leaving the vertices of the set  and entering the vertices of the set
and entering the vertices of the set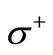 , correspond to the code words. An arc connecting the vertex of the set
, correspond to the code words. An arc connecting the vertex of the set 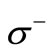 associated with a letter
associated with a letter 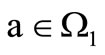 with the vertex of the set
with the vertex of the set 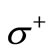 associated with a letter
associated with a letter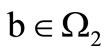 , corresponds to the word
, corresponds to the word . We call these arcs arcs of words. Let us denote the set of all arcs of words by
. We call these arcs arcs of words. Let us denote the set of all arcs of words by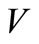 . Arcs of another kind connect the vertices of the set
. Arcs of another kind connect the vertices of the set 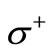 with the vertices of the set
with the vertices of the set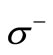 . These arcs are defined by the table of correspondence of symbols. Namely, if
. These arcs are defined by the table of correspondence of symbols. Namely, if 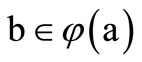 then there is an arc leaving the vertex of the set
then there is an arc leaving the vertex of the set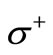 , associated with a letter
, associated with a letter 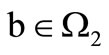 and entering the vertex of the set
and entering the vertex of the set 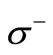 associated with a letter
associated with a letter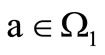 . Let us call these arcs arcs of recovery. We denote the set of the arcs of recovery by
. Let us call these arcs arcs of recovery. We denote the set of the arcs of recovery by 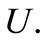 Several arcs of recovery can leave each vertex, including none, depending on the table of correspondence.
Several arcs of recovery can leave each vertex, including none, depending on the table of correspondence.
Example 3.1. There are given two different alphabets  and
and 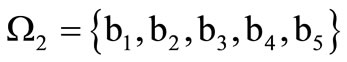 and a table of correspondence (Table 1). Let us assume that the code words are
and a table of correspondence (Table 1). Let us assume that the code words are 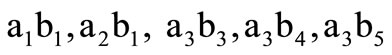 and
and . Therefore, not all arcs of words should be drawn in the corresponding bipartite graph. Figure 6 illustrates the corresponding bipartite graph
. Therefore, not all arcs of words should be drawn in the corresponding bipartite graph. Figure 6 illustrates the corresponding bipartite graph , where thin arrows depict arcs of words, and thick arrows depict arcs of recovery.
, where thin arrows depict arcs of words, and thick arrows depict arcs of recovery.
There exists a path in graph  that traverses all of the arcs of words only once. It may be written as a sequence of arcs
that traverses all of the arcs of words only once. It may be written as a sequence of arcs
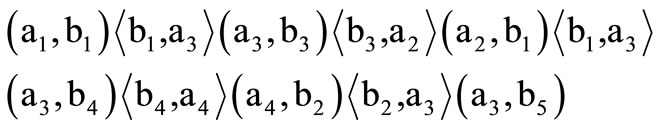 (3.2)
(3.2)
where the symbol “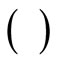 ” denotes arc of word and “
” denotes arc of word and “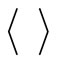 ” —arc of recovery. Note that in construction of the above sequence the arc of recovery
” —arc of recovery. Note that in construction of the above sequence the arc of recovery 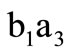 was traversed twice.
was traversed twice.
Thus, the sequence of arcs (3.2) constitutes an Euler path conditional on the arc of recovery 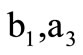 being of degree two. Furthermore, the arc of recovery
being of degree two. Furthermore, the arc of recovery 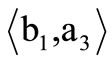 means that the words
means that the words 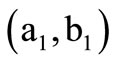 and
and 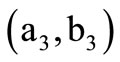 may form a sequence
may form a sequence  according to definition (3.1). The same is true for all the other arcs of recovery in the sequence of arcs (3.2). Hence, the sequence of words
according to definition (3.1). The same is true for all the other arcs of recovery in the sequence of arcs (3.2). Hence, the sequence of words
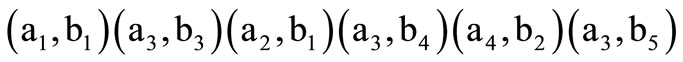 (3.3)
(3.3)
follows from the sequence of arcs (3.2). The sequence (3.3) contains all the code words only once and does not contain any other words. This is a dense sequence by definition. Note that in contrast to the standard De Bruijn graph, arcs of recovery do not correspond to words, and they, in some sense, are intermediate steps, which are represented neither by letters nor by words in the formed
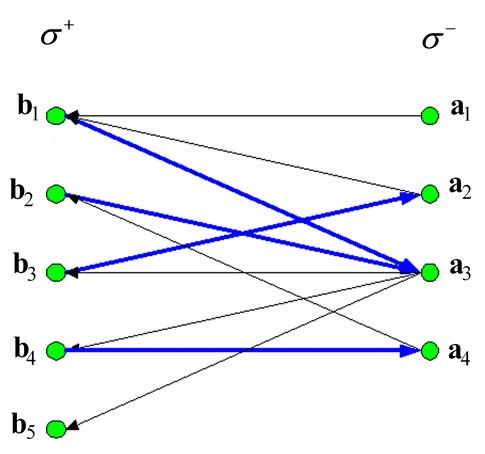
Figure 6. The bipartite graph G in Example.
sequence. Therefore, it is possible either to traverse the arc of recovery several times or not to traverse it at all, i.e., these arcs (multi-arcs) can have an arbitrary nonnegative multiplicity. The Table of correspondence (Table 1) of symbols defines the set  of the arcs of recovery; however, the multiplicities of these arcs can be assigned in several possible ways.
of the arcs of recovery; however, the multiplicities of these arcs can be assigned in several possible ways.
It follows from Good’s Theorem ([10], Section 9) that for the existence of Euler cycle it is necessary and sufficient that the sum of the multiplicities of the entering arcs is equal to the sum of the multiplicities of the leaving arcs for all vertices of the graph . Suppose that now the conditions of this theorem are violated in only two vertices of the graph. Specifically, the number of arcs with the first vertex as their initial vertex exceed by 1 than the number of arcs with the first vertex as their terminal vertex, and the reverse is true for the second vertex. It is easy to show that in this case there exists an Euler path which begins and ends with these two vertices. This fact reduces the problem of construction of a dense sequence to the problem of definition of the multiplicities of arcs of recovery with the given sets
. Suppose that now the conditions of this theorem are violated in only two vertices of the graph. Specifically, the number of arcs with the first vertex as their initial vertex exceed by 1 than the number of arcs with the first vertex as their terminal vertex, and the reverse is true for the second vertex. It is easy to show that in this case there exists an Euler path which begins and ends with these two vertices. This fact reduces the problem of construction of a dense sequence to the problem of definition of the multiplicities of arcs of recovery with the given sets  and
and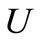 , so that the graph
, so that the graph 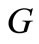 satisfies the Eulerian condition (see [10], Section 9). Naturally, only arcs of recovery may be assigned different multiplicities, because multiplicity of an arc of word always equals 1. In the Example 3.1, multiplicity of the arc
satisfies the Eulerian condition (see [10], Section 9). Naturally, only arcs of recovery may be assigned different multiplicities, because multiplicity of an arc of word always equals 1. In the Example 3.1, multiplicity of the arc 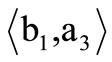 should be set to 2, and multiplicities of all the other arcs of recovery should be set to 1. In this case, the number of incoming and outgoing arcs is the same (taking multiplicity into account). The number of arcs with the vertex
should be set to 2, and multiplicities of all the other arcs of recovery should be set to 1. In this case, the number of incoming and outgoing arcs is the same (taking multiplicity into account). The number of arcs with the vertex 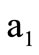 as their initial vertex is greater than the number of arcs with
as their initial vertex is greater than the number of arcs with 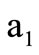 as their terminal vertex by 1, and the reverse is true for the vertex
as their terminal vertex by 1, and the reverse is true for the vertex . Hence, the conditions for the existence of an Euler path in this graph are fulfilled.
. Hence, the conditions for the existence of an Euler path in this graph are fulfilled.
Let us investigate the problem of construction of a dense sequence that contains all possible words over the alphabets 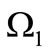 and
and 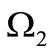 exactly once using graph
exactly once using graph . Let the alphabets
. Let the alphabets 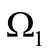 and
and 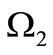 have the same cardinality
have the same cardinality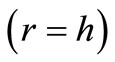 . In this case
. In this case 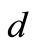 arcs leave each vertex of the set
arcs leave each vertex of the set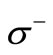 . Let
. Let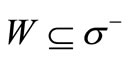 . Let us denote the set of verti-
. Let us denote the set of verti-

Table 1. Table of correspondence between the letters of alphabets W1 and W2.
ces in 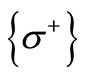 adjacent to
adjacent to 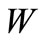 via arcs of recovery by
via arcs of recovery by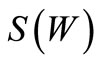 .
.
Theorem 3.1. Let . For the existence of a cyclic sequence of words including each word exactly once it is necessary and sufficient that for any set
. For the existence of a cyclic sequence of words including each word exactly once it is necessary and sufficient that for any set 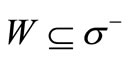 the following inequality holds:
the following inequality holds:
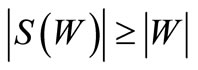
Proof. Necessity. Since all arcs of words are drawn in this graph, each vertex of the set 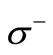 has the out-degree equal to
has the out-degree equal to . For the same reason, each vertex of the set
. For the same reason, each vertex of the set 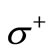 has the in-degree also equal to
has the in-degree also equal to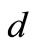 . Let us examine an arbitrary set
. Let us examine an arbitrary set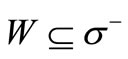 . In order that the out-degrees and the in-degrees of all vertices of this set would be equal, it is necessary that the sum of multiplicities of the arcs of recovery of the set
. In order that the out-degrees and the in-degrees of all vertices of this set would be equal, it is necessary that the sum of multiplicities of the arcs of recovery of the set 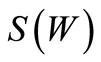 incident to
incident to 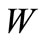 would be equal
would be equal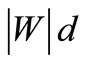 . However, the vertices of the set
. However, the vertices of the set 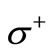 also must have equal out-degrees and in-degrees, therefore the multiplicity of the arc of recovery is limited by value
also must have equal out-degrees and in-degrees, therefore the multiplicity of the arc of recovery is limited by value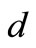 . (Multiplicity of the arc of recovery can be less than
. (Multiplicity of the arc of recovery can be less than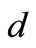 , if there is more than one arc of recovery leaving that vertex.) Therefore, the sum of multiplicities of the arcs of recovery does not exceed the value of
, if there is more than one arc of recovery leaving that vertex.) Therefore, the sum of multiplicities of the arcs of recovery does not exceed the value of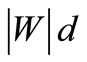 , hence it is necessary that
, hence it is necessary that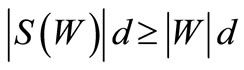 .
.
Sufficiency. Conditions of this theorem coincide with the conditions of the Hall’s theorem [10] of existence of perfect matching in the set of arcs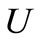 , i.e. matching, containing all vertices of graph. Let
, i.e. matching, containing all vertices of graph. Let 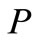 be such a matching. Let us assume that the multiplicities of all arcs not in
be such a matching. Let us assume that the multiplicities of all arcs not in  equal zero, and the multiplicities of arcs in
equal zero, and the multiplicities of arcs in  equal
equal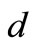 . It is obvious that in this case the out-degrees and the in-degrees of all vertices in
. It is obvious that in this case the out-degrees and the in-degrees of all vertices in 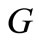 are equal. Therefore, an Euler cycle exists. The Theorem is proven. □
are equal. Therefore, an Euler cycle exists. The Theorem is proven. □
Note that the matching mentioned in the proof of Theorem 3.1 defines a one-to-one correspondence between letters of both alphabets. In this case it is possible to return to the initial situation when the first and the second letters of each word belong to the same alphabet. In particular, it is possible to identify the corresponding vertices of the graph 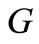 from
from  and
and 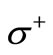 and thus to obtain the standard De Bruijn graph.
and thus to obtain the standard De Bruijn graph.
Consider now the general case, when the alphabets 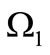 and
and 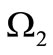 are of different cardinality
are of different cardinality 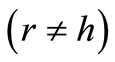 and the set of the code words M does not necessarily coincide with the set of all possible words. It means that the sets of left and right vertices have different size,
and the set of the code words M does not necessarily coincide with the set of all possible words. It means that the sets of left and right vertices have different size, 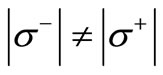 and not all arcs of words are drawn in the graph G. In this case let us denote the out-degree of vertex
and not all arcs of words are drawn in the graph G. In this case let us denote the out-degree of vertex 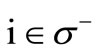 by
by 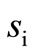 and the in-degree of vertex
and the in-degree of vertex 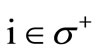 by
by . It is obvious that
. It is obvious that
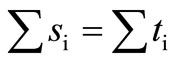 (3.4)
(3.4)
Let us define the generalized out-degree of the vertex as the number of arcs leaving it, each taken with its multiplicity and the generalized in-degree of the vertex as the number of arcs entering it, each taken with its multiplicity. Let us denote an arbitrary subset of vertices of graph G by X and the sum of generalized out-degrees of these vertices by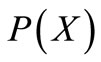 . Let us denote, as earlier, the set of vertices in
. Let us denote, as earlier, the set of vertices in 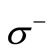 by
by  and the set of vertices in
and the set of vertices in 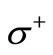 that are adjacent to
that are adjacent to 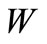 via arcs of recovery, by
via arcs of recovery, by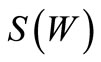 .
.
Theorem 3.2. For the existence of a cyclic sequence of words including each word from the set  exactly once it is necessary and sufficient that the graph
exactly once it is necessary and sufficient that the graph 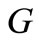 is connected, and for any set
is connected, and for any set 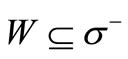 the following inequality holds:
the following inequality holds:
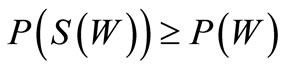 (3.5)
(3.5)
Proof. Necessity. Indeed, some of the arcs of recovery leaving the set S(W), possibly all of them, enter the vertices of the set W, but no other arc of recovery enters this set according to the definition of the set S(W). If graph  is a generalized Euler graph, i.e. each vertex has equal generalized out-degree and generalized in-degree, then the following inequality holds:
is a generalized Euler graph, i.e. each vertex has equal generalized out-degree and generalized in-degree, then the following inequality holds: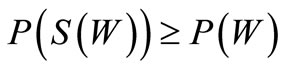 .
.
Sufficiency. It is necessary to show that if (3.5) holds then there exist non-negative integral values on the arcs of recovery (multiplicities) such that the generalized outdegree and the generalized in-degree at each vertex of the graph 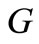 are equal. We apply the theory of flows in networks. Let us assume that for every i the capacity of vertex i from the set
are equal. We apply the theory of flows in networks. Let us assume that for every i the capacity of vertex i from the set 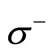 is equal to
is equal to 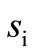 (out-degree) and the capacity of vertex
(out-degree) and the capacity of vertex 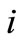 from the set
from the set 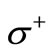 is equal to
is equal to 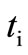 (in-degree). For convenience, let us add to the graph
(in-degree). For convenience, let us add to the graph 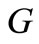 two new vertices in the following way. Let us join all vertices of the set
two new vertices in the following way. Let us join all vertices of the set 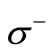 to a new vertex
to a new vertex 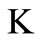 by arcs directed to vertex
by arcs directed to vertex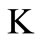 . Let us join a new vertex L to all vertices of the set
. Let us join a new vertex L to all vertices of the set 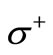 by arcs directed from vertex L. In the theory of network flows these vertices are conventionally called a sink and a source respectively. We will further examine only the arcs of recovery (set
by arcs directed from vertex L. In the theory of network flows these vertices are conventionally called a sink and a source respectively. We will further examine only the arcs of recovery (set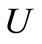 ) on the graph
) on the graph  discarding the arcs of words from the graph
discarding the arcs of words from the graph , and denote the graph obtained in this way by
, and denote the graph obtained in this way by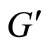 . By construction, graph
. By construction, graph 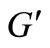 is oriented from the vertex L, the source, to the vertex
is oriented from the vertex L, the source, to the vertex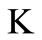 , the sink (see Figure 7).
, the sink (see Figure 7).
In the network flow problem it is required to find a non-negative function on the arcs of the graph (called the maximum flow), possessing specific properties. By definition, the sum of the values of the flow function on all
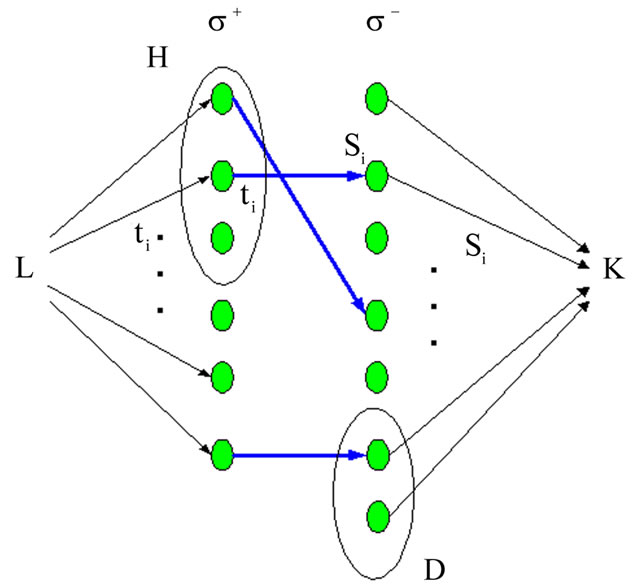
Figure 7. Graph , oriented from the vertex L, the source, to the vertex K, the sink.
, oriented from the vertex L, the source, to the vertex K, the sink.
arcs incident to the sink is called the flow value. It is required that: 1) for each vertex, except for the sink and the source, the total value of the flow on all arcs entering the vertex and the total value on all arcs leaving the vertex must be equal to each other and must not exceed the capacity of the vertex, 2) it is not possible to increase the flow value without destroying condition (1). A vertex of graph is saturated, if the total value of the flow on entering (and, consequently, on leaving) arcs is equal to its capacity.
Let us show that if there is a flow of value  in the graph
in the graph , then all vertices of the sets
, then all vertices of the sets  and
and  are saturated. Indeed, according to the definition of the flow value,
are saturated. Indeed, according to the definition of the flow value, 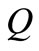 is equal to the sum of flows on all the arcs going from each vertex
is equal to the sum of flows on all the arcs going from each vertex 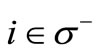 to the vertex
to the vertex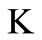 . However, the flow for each such arc does not exceed the capacity
. However, the flow for each such arc does not exceed the capacity 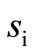 of the corresponding vertex according to the property 1) of the flow. Consequently, the sum of all such flows does not exceed
of the corresponding vertex according to the property 1) of the flow. Consequently, the sum of all such flows does not exceed 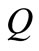 and is equal to
and is equal to 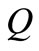 only when the flow on arc is equal to the capacity of the vertex. When the flow value is
only when the flow on arc is equal to the capacity of the vertex. When the flow value is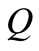 , all the vertices of the set
, all the vertices of the set 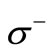 are saturated. Further, for any vertex
are saturated. Further, for any vertex 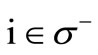 we will denote the sum of the flows on all arcs entering such a vertex by
we will denote the sum of the flows on all arcs entering such a vertex by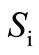 . According to the property (1) of the flow,
. According to the property (1) of the flow, 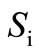 is equal to the sum of the flows on all leaving arcs, i.e.
is equal to the sum of the flows on all leaving arcs, i.e.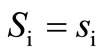 . Let us denote now the sum of flows on all arcs leaving any vertex
. Let us denote now the sum of flows on all arcs leaving any vertex 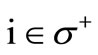 by
by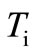 . According to the definition of the flow,
. According to the definition of the flow, 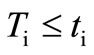 i.e.
i.e. 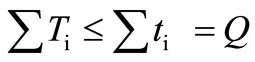 (see 3.4). On the other hand, it is clear that
(see 3.4). On the other hand, it is clear that 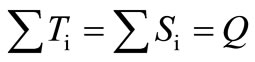 , since both sums are taken on the same set of arcs. From this follows that
, since both sums are taken on the same set of arcs. From this follows that 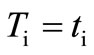 for any vertex
for any vertex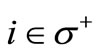 . Therefore, when the flow value is
. Therefore, when the flow value is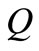 , all vertices of the set
, all vertices of the set 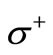 are also saturated. It remains to assign flow
are also saturated. It remains to assign flow 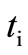 to each arc leaving vertex L and entering vertex
to each arc leaving vertex L and entering vertex 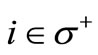 of graph
of graph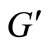 . In this case all the conditions of the flow are maintained.
. In this case all the conditions of the flow are maintained.
We assume now that the value of flow  not only exists, but also is integral, i.e. the values of the functions on the arcs of the graph are integral non-negative numbers. In this case for every arc of recovery its multiplicity must be defined as the value of flow on this arc. Since all vertices of the set
not only exists, but also is integral, i.e. the values of the functions on the arcs of the graph are integral non-negative numbers. In this case for every arc of recovery its multiplicity must be defined as the value of flow on this arc. Since all vertices of the set 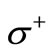 in graph
in graph 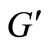 are saturated, every vertex of the set
are saturated, every vertex of the set 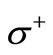 in the initial graph
in the initial graph 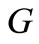 has equal generalized out-degree and in-degree (number of arcs of words). The same is true for vertices of the set
has equal generalized out-degree and in-degree (number of arcs of words). The same is true for vertices of the set 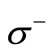 in the initial graph
in the initial graph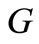 . As it was proven earlier, the values of multiplicities are equal to the capacities of vertices, i.e. to the out-degrees for vertices of the set
. As it was proven earlier, the values of multiplicities are equal to the capacities of vertices, i.e. to the out-degrees for vertices of the set 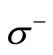 and to the in-degrees for vertices of the set
and to the in-degrees for vertices of the set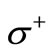 .
.
With such multiplicities of the arcs of recovery the initial graph  is an Euler graph. It remains to prove that with the theorem condition the flow value
is an Euler graph. It remains to prove that with the theorem condition the flow value 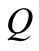 exists and it is integral.
exists and it is integral.
We call a set of vertices a vertex-cut (or just a cut) of the graph 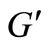 if it does not contain the sink and the source, and any path from L into K contains at least one vertex of this set. Let us call the sum of the capacities of the cut’s vertices the weight of the cut. The cut is called minimal if it has the smallest weight. According to the Ford-Fulkerson theory [11], the value of the maximum flow is equal to the value of the minimal cut. Now we determine the value of the minimal cut in graph
if it does not contain the sink and the source, and any path from L into K contains at least one vertex of this set. Let us call the sum of the capacities of the cut’s vertices the weight of the cut. The cut is called minimal if it has the smallest weight. According to the Ford-Fulkerson theory [11], the value of the maximum flow is equal to the value of the minimal cut. Now we determine the value of the minimal cut in graph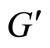 . In graph
. In graph 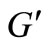 there are two obvious cuts: the entire set of vertices
there are two obvious cuts: the entire set of vertices 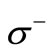 and the entire set of vertices
and the entire set of vertices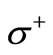 . Both these cuts have an equal weight
. Both these cuts have an equal weight 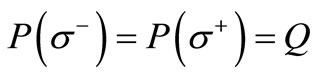 (see Equality (3.4)). Let us demonstrate that the cuts
(see Equality (3.4)). Let us demonstrate that the cuts 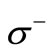 and
and 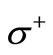 are minimal. That is, the weight of any other cut is greater than or equal to Q. Consider a cut
are minimal. That is, the weight of any other cut is greater than or equal to Q. Consider a cut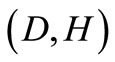 , where
, where 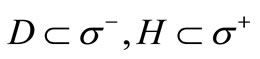 respectively; its weight is equal to
respectively; its weight is equal to 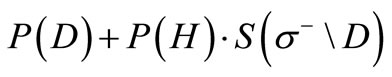 is a set of vertices in
is a set of vertices in 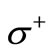
that are adjacent to the vertices of 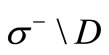 via arcs of recovery and
via arcs of recovery and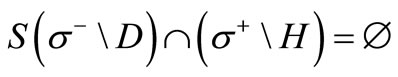 . Indeed, otherwise there would be an arc from the vertex of the set
. Indeed, otherwise there would be an arc from the vertex of the set , not included in the cut, into the vertex of the set
, not included in the cut, into the vertex of the set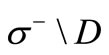 , also not included in the cut. This contradicts the definition of the cut. In other words,
, also not included in the cut. This contradicts the definition of the cut. In other words,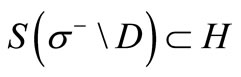 . Hence, taking into account the condition of the theorem
. Hence, taking into account the condition of the theorem
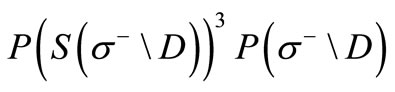 , the following inequality holds:
, the following inequality holds:

Thus, the weight of the cut 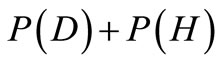 is not less than the value of
is not less than the value of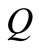 . Therefore, the value of the maximum flow on graph
. Therefore, the value of the maximum flow on graph 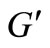 is equal to
is equal to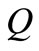 .
.
The integrality of this flow easily follows from the standard algorithm of the construction of the maximum flow [11], which results in integral flow if the capacities of the vertices are integral numbers. The Theorem is proven. □
Corollary 3.1. Assume that in the graph 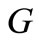 all arcs of words are drawn, and
all arcs of words are drawn, and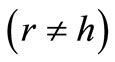 . Then for the existence of a cyclic sequence of words that includes each word exactly once it is necessary and sufficient that for any set
. Then for the existence of a cyclic sequence of words that includes each word exactly once it is necessary and sufficient that for any set 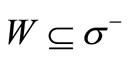 the following inequality holds:
the following inequality holds:
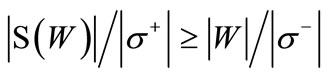 (3.6)
(3.6)
Proof. Indeed, the in-degree of every vertex of the set 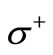 is equal to
is equal to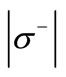 , and the out-degree of every vertex of the set
, and the out-degree of every vertex of the set  is equal to
is equal to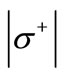 . Therefore, inequality (3.5) can be re-written as
. Therefore, inequality (3.5) can be re-written as
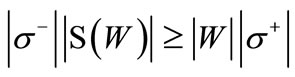
From there follows (3.6). □
4. Cartesian Synonymous Partitions
Let us consider the case of Cartesian synonymous partitions and words of length two. Two different partitions of the basic alphabet 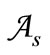 produce two quotient alphabets
produce two quotient alphabets  and
and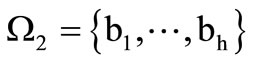 . We have described in detail the corresponding constructions of words and sequences in this case in Example 2.2.2 Let us examine the problem of construction of a dense sequence that includes all possible words of length two over the given alphabets. Let us use for this purpose the bipartite graph
. We have described in detail the corresponding constructions of words and sequences in this case in Example 2.2.2 Let us examine the problem of construction of a dense sequence that includes all possible words of length two over the given alphabets. Let us use for this purpose the bipartite graph 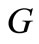 with the sets of vertices
with the sets of vertices 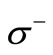 and
and 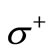 introduced in Section 3;
introduced in Section 3; 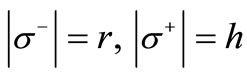 The set
The set 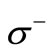 corresponds to the alphabet
corresponds to the alphabet 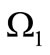 and contains the first letters of the words, and the set s+ corresponds to the alphabet
and contains the first letters of the words, and the set s+ corresponds to the alphabet 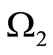 and contains the second letters of the words. All possible arcs of words are drawn in this graph. The arcs of recovery are determined by the table of correspondence of symbols, which in this case is not a free parameter. Specifically, we assume that the arc of recovery occurs from vertex
and contains the second letters of the words. All possible arcs of words are drawn in this graph. The arcs of recovery are determined by the table of correspondence of symbols, which in this case is not a free parameter. Specifically, we assume that the arc of recovery occurs from vertex 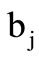 into vertex
into vertex 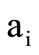 if the intersection of the corresponding sets is not empty:
if the intersection of the corresponding sets is not empty: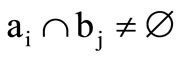 . This definition is reasonable, since the sequences in the terms of a Cartesian synonymous partition must correspond to the sequences of letters of the basic alphabet in the sense of Section 2. Thus, the possibility of construction of a dense sequence is determined by the conditions given in Section 3. Some of the
. This definition is reasonable, since the sequences in the terms of a Cartesian synonymous partition must correspond to the sequences of letters of the basic alphabet in the sense of Section 2. Thus, the possibility of construction of a dense sequence is determined by the conditions given in Section 3. Some of the  and
and  partitions of the basic alphabet satisfy these conditions, and some of them do not.
partitions of the basic alphabet satisfy these conditions, and some of them do not.
Example 4.1. Let the alphabet  consist only of two sets of elements
consist only of two sets of elements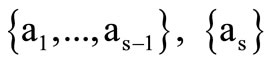 , and let the alphabet
, and let the alphabet 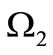 coincide with
coincide with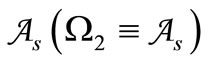 . In this case
. In this case 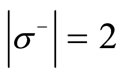 and the out-degree of each vertex of the set
and the out-degree of each vertex of the set 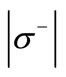 is equal to
is equal to ; also
; also 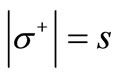 and the in-degree of each vertex of the set
and the in-degree of each vertex of the set 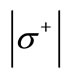 is equal to 2. If
is equal to 2. If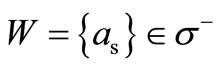 , then
, then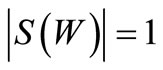 , since only one arc of recovery enters the vertex
, since only one arc of recovery enters the vertex 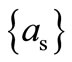 according to the definition of the arcs of recovery: only vertex
according to the definition of the arcs of recovery: only vertex 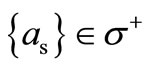 has a non-empty intersection with the vertex
has a non-empty intersection with the vertex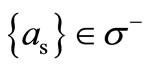 . Thus, inequality
. Thus, inequality 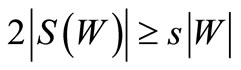 is true only when
is true only when . According to Corollary 3.1 this indicates an absence of an Euler cycle in the graph with
. According to Corollary 3.1 this indicates an absence of an Euler cycle in the graph with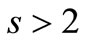 . Consider now the same construction with the transposition of the alphabet:
. Consider now the same construction with the transposition of the alphabet: 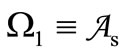 and
and 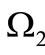 consists only of two sets of elements
consists only of two sets of elements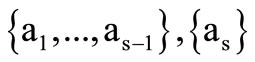 . In this case
. In this case 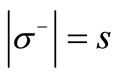 and the out-degree of each vertex of the set
and the out-degree of each vertex of the set 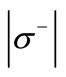 is equal to 2; also
is equal to 2; also 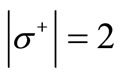 and the in-degree of each vertex of the set
and the in-degree of each vertex of the set 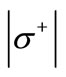 is equal to
is equal to . Let
. Let 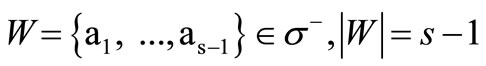 . All arcs of recovery, by construction, are drawn from the sole vertex
. All arcs of recovery, by construction, are drawn from the sole vertex 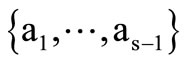 of the set
of the set  that has a non-empty intersection with each of the vertices
that has a non-empty intersection with each of the vertices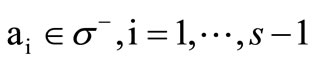 . Therefore,
. Therefore,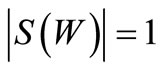 . According to Corollary 3.1 an Euler cycle exists if |
. According to Corollary 3.1 an Euler cycle exists if |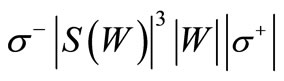 . In our case this inequality yields
. In our case this inequality yields 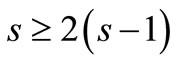 and it is only fulfilled with
and it is only fulfilled with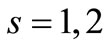 .
.
Let us suppose that positive integers 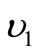 and
and 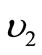 are such that
are such that 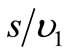 and
and  are integers.
are integers.
Statement 4.1. Let the set 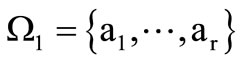 and the set
and the set 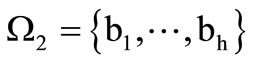 be the partitions of the basic alphabet
be the partitions of the basic alphabet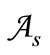 , where the set
, where the set 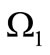 consists of subsets of size
consists of subsets of size 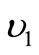 and the set
and the set 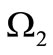 consists of subsets of size
consists of subsets of size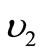 . There exists a cyclic dense sequence in the set of all possible words over these alphabets.
. There exists a cyclic dense sequence in the set of all possible words over these alphabets.
Proof. Let us examine the corresponding bipartite graph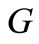 . The set of vertices
. The set of vertices  corresponds to the quotient letters of the set
corresponds to the quotient letters of the set 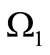 and the set of vertices
and the set of vertices 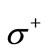 corresponds to the quotient letters of the set
corresponds to the quotient letters of the set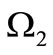 .
. 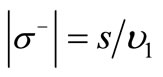 and
and 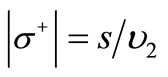 by construction. Consider an arbitrary set
by construction. Consider an arbitrary set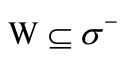 . Then
. Then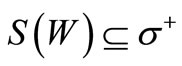 , by definition, is a set of all vertices from which the arcs of recovery are drawn into the vertices of the set
, by definition, is a set of all vertices from which the arcs of recovery are drawn into the vertices of the set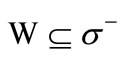 . Further, the number of different letters of the basic alphabet
. Further, the number of different letters of the basic alphabet 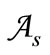 in all words of the set
in all words of the set 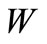 is equal to
is equal to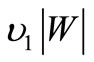 ; the same letters, by the definition of the arcs of recovery, can be found in all words of the set
; the same letters, by the definition of the arcs of recovery, can be found in all words of the set . Thus,
. Thus, . Therefore the following inequality holds:
. Therefore the following inequality holds:
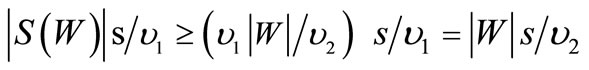
Since an Eulerian conditions, according to Corollary 3.1, take in this case the form 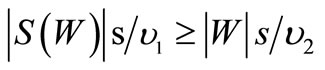 , the Statement is proven. □
, the Statement is proven. □
Above we analyzed the case when the quotient letters of each alphabet consisted of the same number of letters of the basic alphabet. Now let us consider the case when the number of letters of the basic alphabet in the quotient letters is not fixed. For two partitions 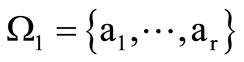 and
and 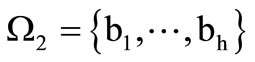 of the basic alphabet
of the basic alphabet 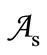 with an equal number of subsets
with an equal number of subsets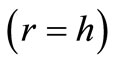 , the in-degree and out-degree of each vertex are equal. According to the Theorem 3.1, in this case the existence of an Euler cycle depends only on Cartesian partitions that produce alphabets
, the in-degree and out-degree of each vertex are equal. According to the Theorem 3.1, in this case the existence of an Euler cycle depends only on Cartesian partitions that produce alphabets 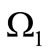 and
and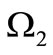 , since the table of correspondence is determined by the composition of the sets. It is possible to reformulate the criterion of the existence of the dense cycle obtained in Theorem 3.1. Let us examine the set of words
, since the table of correspondence is determined by the composition of the sets. It is possible to reformulate the criterion of the existence of the dense cycle obtained in Theorem 3.1. Let us examine the set of words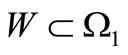 . Partition
. Partition 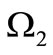 in an obvious manner induces the partition of the set of all the letters over the basic alphabet included in the words from the set
in an obvious manner induces the partition of the set of all the letters over the basic alphabet included in the words from the set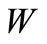 . Let us denote this partition by
. Let us denote this partition by
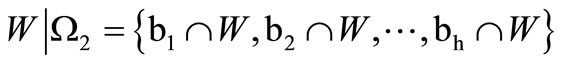
and let us denote the number of non-empty subsets of 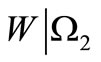 by
by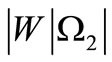 . By definition, the arc of recovery occurs from vertex
. By definition, the arc of recovery occurs from vertex 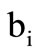 into vertex of the set
into vertex of the set 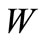 if
if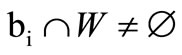 . Therefore, the following inequality always holds:
. Therefore, the following inequality always holds: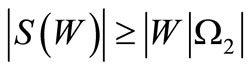 .
.
Statement 4.2. Let the sets
 ,
, 
be the partitions of the basic alphabet 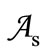 into an equal quantity of subsets
into an equal quantity of subsets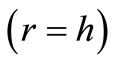 ). Let for each subset W Ì W1 the inequality
). Let for each subset W Ì W1 the inequality 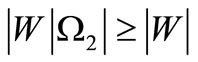 be fulfilled. Then there is
be fulfilled. Then there is 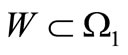 a dense cyclic sequence in the set of all possible words over these alphabets.
a dense cyclic sequence in the set of all possible words over these alphabets.
The proof is obvious in a view of the observations made above. Specifically, from the inequalities
 and
and 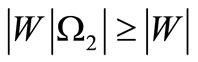 we obtain the following inequality:
we obtain the following inequality: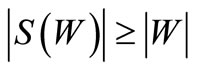 , and apply Theorem 3.1.
, and apply Theorem 3.1.
5. Conclusions
Unlike the traditional setting up a problem in the coding theory [12], coding in DNA is not aimed at the correction of possible mistakes made during transferring information. In the case of DNA the crucial point is the way of recording information. We have chosen a particular important case of overlapping messages together with the degeneracy of the code. This scheme is interesting also regardless of how common this phenomenon is in biological objects.
We suggest a simple model of such coding on the basis of the standard triplet code. The quality of the code was tested on a sequence, which contained one word from each synonymous group. A full analysis of the model is carried out and the criterion for the possibility of building the test sequence is obtained in relation to different Cartesian partitions.
The methods developed in this article may be applied to building sequences of more general types, where, for each synonymous group, the number of the words that are contained in the sequence is preset. The same methods are applicable for analysis in the case of the standard triplet code [8]. Noteworthy also is the concept of “abstract alphabet” and the sequences built over it. This alphabet allows for superposing not only the same letters, but also different ones, as determined by the table of correspondence.
5. Acknowledgements
The authors are grateful to Professors Ed. Trifonov, A. Vainshtein, A. Korol for fruitful discussions.
REFERENCES
- P. J. Cock and D. E. Whitworth, “Evolution of Gene Overlaps: Relative Reading Frame Bias in Prokaryotic Two-Component System Genes,” Journal of Molecular Evolution, Vol. 64, No. 4, 2007, pp. 475-462. doi:10.1007/s00239-006-0180-1
- Z. I. Johnson and S. W. Chisholm, “Properties of Overlapping Genes are Conserved across Microbial Genomes,” Genome Research, Vol. 14, No. 11, 2004, pp. 2268-2272. doi:10.1101/gr.2433104
- C. Kingsford, A. Delcher and S. L. Salzberg, “A Unified Model Explaining the Offsets of Overlapping and Nearoverlapping Prokaryotic Genes,” Molecular Biology and Evolution, Vol. 24, No. 9, 2007, pp. 2091-2098. doi:10.1093/molbev/msm145
- I. Makalowska, C. F. Lin and W. Makalowski. “Overlapping Genes in Vertebrate Genomes,” Computational Biology and Chemistry, Vol. 29, No. 1, 2005, pp. 1-12. doi:10.1016/j.compbiolchem.2004.12.006
- D. Candotti, C. Chappey, M. Rosenheim, P. M’Pelé, J. M. Huraux and H. Agut, “High Variability of the Gag/Pol Transframe Region among HIV-1 Isolates,” Comptes Rendus de l’Académie des Sciences: Série III, Vol. 317, No. 2, 1994, pp. 183-923.
- K. M. McGirr and G. C. Buehuring, “Tax & Rex: Overlapping Genes of the Deltaretrovirus Group,” Virus Genes, Vol. 32, No. 3, 2006, pp. 229-239. doi:10.1007/s11262-005-6907-z
- H. L. Zaaijer, F. J. van Hemert, M. N. Koppelman and V. V. Lukashov, “Independent Evolution of Overlapping Polymerase and Surface Protein Genes of Hepatitis B Virus,” Journal of General Virology, Vol. 88, 2007, pp. 2137-2143. doi:10.1099/vir.0.82906-0
- M. Gorel and V. M. Kirzhner, “Degenerate Coding and Sequence Compacting,” ESI Preprints 1819, 2006. http://www.esi.ac.at/preprints/ESI-Preprints.html
- M. Lothaire, “Applied Combinatorics on Words,” Encyclopedia of Mathematics and Its Applications, Cambridge University Press, Cambridge, 2005
- M. Hall, “Combinatorial Theory,” John Wiley & Sons, Hoboken, 1976.
- L. R. Ford, Jr. and D. R. Fulkerson, “Flows in Networks,” Princeton University Press, Princeton, 1962.
- I. F. Blake, “A Perspective on Coding Theory,” Information Sciences, Vol. 57-58, 1991, pp. 111-118. doi:10.1016/0020-0255(91)90070-B