Journal of Mathematical Finance
Vol.08 No.02(2018), Article ID:85001,21 pages
10.4236/jmf.2018.82029
Currency Portfolio Risk Measurement with Generalized Autoregressive Conditional Heteroscedastic-Extreme Value Theory-Copula Model
Cyprian O. Omari1*, Peter N. Mwita2, Antony W. Gichuhi3
1Department of Statistics and Actuarial Science, Dedan Kimathi University of Technology, Nyeri, Kenya
2Department of Mathematics and Statistics, Machakos University, Machakos, Kenya
3Department of Statistics and Actuarial Sciences, Jomo Kenyatta University of Agriculture and Technology, Nairobi, Kenya

Copyright © 2018 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: March 29, 2018; Accepted: May 28, 2018; Published: May 31, 2018
ABSTRACT
This paper implements the statistical modelling of the dependence structure of currency exchange rates using the concept of copulas. The GARCH-EVT-Copula model is applied to estimate the portfolio Value-at-Risk (VaR) of currency exchange rates. First the univariate ARMA-GARCH model is used to filter the return series. The generalized Pareto distribution is then fitted to model the tail distribution of standardized residuals. The dependence structure between transformed residuals is modeled using bivariate copulas. Finally the portfolio VaR is estimated based on Monte Carlo simulations on an equally weighted portfolio of four currency exchange rates. The empirical results demonstrate that the Student’s t copula provide the most appropriate representation of the dependence structure of the currency exchange rates. The backtesting results also demonstrate that the semi-parametric approach provide accurate estimates of portfolio risk on the basis of statistical coverage tests compared to benchmark copula models.
Keywords:
Backtesting, Copulas, Currency Exchange Rate, Dependence Modelling, GARCH-EVT-Copula Model, Portfolio Risk, Value-at-Risk

1. Introduction
The currency exchange market plays an important role in evaluating the performance of the country’s economy and the stability of its financial system. In the recent past, the financial markets worldwide have experienced exponential growth coupled with significant extreme price movements such as the global financial crisis, currency crisis, and extreme default losses. The ever increasing uncertainties in the financial markets have motivated practitioners, researchers and academicians to develop new and improve existing methodologies applied in financial risk measurement. For a given asset or portfolio of financial assets, probability and time horizon, VaR is defined as the worst expected loss due to change in value of the asset or portfolio of financial assets at a given confidence level over a specific time horizon (typically a day or 10 days) under the assumption of normal market conditions and no transaction costs in the assets.
The complexity in modeling VaR lies in making the appropriate assumption about the distribution of financial returns, which typically exhibits the stylized characteristics such as; non-normality, volatility clustering, fat tails, leptokurtosis and asymmetric conditional volatility. Engle and Manganelli (2004) [1] noted that the main difference among VaR models is how they deal with the difficulty of reliably describing the tail distribution of returns of an asset or portfolio. However, the main challenge lies in choosing an appropriate distribution of returns to capture the time varying conditional volatility of future return series. The popularity of VaR as a risk measure can be attributed to its theoretical and computational simplicity, flexibility and its ability to summarize into a single value several components of risk at firm level that can be easily communicated to the management for decision making.
However, for a portfolio consisting of multiple assets, estimating the VaR for each asset within the portfolio is not sufficient to capture the portfolio risk since VaR doesn’t satisfy the sub-additive condition [2] . Therefore, there is need to evaluate the portfolio risk in a multivariate setting to account for the diversification benefits. While many researchers have conscientiously focused on univariate VaR forecasting, the multivariate case has challenges due to the complexity of modeling joint multivariate distributions. Conventionally, portfolio VaR estimation methods often assume that portfolio returns follow the multivariate normal or Student’s t distributions. However, the stylized characteristics of financial time series data confirm that the return distributions are heavy tailed and exhibit excess kurtosis, hence cannot be modeled using multivariate normal distribution.
Modelling portfolio VaR is also significantly affected by the tail distribution of returns. By applying the extreme value theory (EVT) to characterize the tail distributions of the return series the accuracy the portfolio VaR can be improved significantly. EVT assumes that the return series are independently and identically distributed but this is not always the case. In order to apply the EVT to the return series the two-step approach by McNeil and Frey (2000) [3] is applied to generated the i.i.d. observations. First the GARCH model is fitted to the return series and then EVT is applied to the standardized residuals.
Moreover, the non-linear dependence structure that exists between tails of asset returns can be modeled using copulas. Sklar (1959) [4] introduced the concept of copulas in modeling the dependence structure between random variables. An increasing number of contributions in the development of copula theory and applications in several fields of research have appeared in literature. However, the motivation for increased interest by researchers to apply copulas is the discovery of the notation of copulas that is applicable in several applied fields. Embrechts et al. (1999) [5] pioneered the application of copulas in financial research. McNeil et al. (2005) [6] and Denuit et al. (2006) [7] applied copula methods from a risk management perspective while Cherubini et al. (2004) [8] and Cherubini et al. (2012) [9] applied copulas from a mathematical finance perspective. Nelsen (2006) [10] and Joe (1997) [11] introduced the standard references for copula theory, providing comprehensive introductions to copulas and dependence modeling, while emphasizing the statistical foundations.
Recent studies have ascertained the superiority of copula-based models that capture the tail dependence and accurately estimate portfolio VaR, since they offer much more flexibility in constructing a suitable joint distribution when dealing with financial data which exhibits non-normality. Rockinger and Jondeau (2006) [12] introduced the Copula-GARCH combination to model the dependence structure between stock markets. Wang et al. (2010) [13] applied the GARCH-EVT copula to study the portfolio risk of currency exchange rates. Ahmed Ghorbel and Trabelsi (2014) [14] proposed a method for estimating the energy portfolio VaR based on the combinations of AR (FI)-GARCH-GPD-copula model. Others include Tang et al. (2015) [15] utilized the GARCH-EVT-copula model to estimate the portfolio risk of natural gas portfolios and Huang et al. (2014) [16] utilized the GARCH-EVT-copula-CVaR models in portfolio optimization.
The main objective of this paper is to implement the statistical modelling of the dependence structure of currency exchange rates using bivariate copulas and then estimate one-day-ahead Value-at-Risk via Monte Carlo simulations of an equally weighted currency exchange portfolio using GARCH-EVT-Copula approach. The GARCH-EVT-Copula modelling framework integrates the asymmetric GJR-GARCH models for modelling heteroscedasticity in return distributions, extreme value theory for modelling tail distributions, and selected bivariate copulas for modelling the dependence structure for all the exchange rates. Monte Carlo based simulation is then performed to compute portfolio VaR based on the GARCH-EVT-Copula model. Finally, statistical backtesting techniques are employed to ascertain and analyze the performance of the GARCH-EVT-Copula model.
The rest of the paper is organized as follows. Section 2 briefly reviews the copulas. Section 3 describes the two-step estimation approach for modelling the marginal distributions of the currency return series. Section 4 implements the portfolio VaR forecasting using GARCH-EVT-copula model. The empirical and backtesting results are presented in Sections 5. Finally, Section 6 gives the conclusion.
2. Copulas
Copulas are important tool for modelling the dependence structure between random variables. Since the seminal paper of Sklar [4] the concept of copulas has become popular in statistical modelling. Copulas combine, link or couple univariate marginal distributions to a multivariate joint distribution. The theory of copula is based on the Sklar’s theorem, which states that a multivariate distribution can be separated into its d marginal distributions and a d-dimensional copula, which completely characterizes the dependence between the variables. A d-dimensional copula is a multivariate distribution function defined on the unit cube , with uniform marginal distributions that satisfies the following properties; [10]
C is grounded and d-increasing
C has margins which satisfy for all
Let be a continuous d-variate cumulative distribution function with univariate margins , by Sklar’s theorem there exists a copula function C, which maps such that
(1)
holds for any
For continuous marginals the copula C is unique and is defined as:
. (2)
In addition, if F is absolutely continuous then the copula density is given by
(3)
For purposes of dependence structure modelling, many copula classes have been developed in literature e.g. elliptical, Archimedean and extreme-value copulas. In this paper, the following elliptical and Archimedean copulas are considered; Gaussian copula, Student-t copula, Clayton copula, Frank copula, Gumbel copula and Joe copula.
Gaussian copula
The bivariate Gaussian (or normal) copula is the function
(4)
where is the standard bivariate normal distribution function with linear correlation coefficient between the two random variables X and Y, is the inverse of the standard bivariate normal distribution function. The Gaussian copula has zero tail dependence.
Student-t copula
The Student-t copula (or t-copula) is defined analogous to the Gaussian copula using a Student-t distribution. The bivariate Student-t copula with degrees of freedom is the function
(5)
where is the bivariate Student’s t distribution with degrees of freedom, is the inverse function of Student’s t-distribution, and is the Pearson’s correlation coefficient between the random variables X and Y for . The t-copula allows for some flexibility in covariance structure and exhibits symmetric tail dependence.
Clayton copula
The Clayton copula is an asymmetric Archimedean copula and also a left-tailed extreme value copula that exhibits strong left (lower) tail dependence compared to the right (upper) tail. The generator function of the copula is , hence , it is completely monotonic if the permissible parameter range is .The bivariate Clayton copula is the function:
(6)
where is the copula parameter value, the lower tail dependence is and the upper tail dependence is zero, i.e., . As the copula parameter tends to infinity, the dependence becomes maximal while the limiting case is be interpreted as the 2-dimensional independence copula [3] .
Frank copula
The Frank copula is a symmetric Archimedean copula. The generator function is given by , hence , it is completely monotonic if . The bivariate Frank copula is the function:
(7)
where , both the upper tail and lower tail dependencies are equal to zero, i.e., . The independence copula is attained when whereas as maximal dependence is achieved.
Gumbel copula
The Gumbel copula also known as Gumbel-Hougaard copula family introduced in Hougaard (1986) [17] is both an asymmetric Archimedean copula and an extreme value copula that exhibits stronger dependence in the upper tail than in the lower tail. The Gumbel copula generator function is given by , hence , it is completely monotonic if . The bivariate Gumbel copula is the function:
(8)
where . When the variables are independent and when we obtain perfect positive dependence between the variables. For the Gumbel copula exhibits upper tail dependence.
Joe copula
The Joe copula is a member of the Archimedean copula and has the generator function , hence . The bivariate Joe copula is the function:
(9)
The concept of tail dependence measures the joint probability of extreme events that can occur in the upper-right tail or lower-left tail, or both tails of a bivariate distribution. Let X and Y be continuous random variables with distribution functions F and G respectively. The upper tail dependence coefficient is the limit (if it exists) of the conditional probability that Y is greater than the q-th quantile of G given that X is greater than the q-th quantile of F as q approaches 1, i.e.,
(10)
and the lower tail dependence coefficient
(11)
The tail dependence measures dependence between extreme values and only depends upon the underlying copula, and not the marginal distributions.
The parametric estimation of copulas is usually implemented using the two steps IFM (inference function for margins) approach by Joe and Xu (1996) [18] . The IFM approach estimates the parameters of the marginal distributions separately from the copula parameters. In the first step, the marginal distributions parameters are estimated via maximum likelihood estimation (MLE):
(12)
The parameter estimates for the marginal distributions obtained from step 1, are used to estimate the copula parameters in the second step using maximum likelihood:
(13)
The resulting IFM estimator is . Under certain regulatory conditions, Patton (2006b) [19] demonstrates that the IFM estimator is reliable and verifies the property of asymptotically normality.
The goodness of fit may be accessed through some goodness of fit (GOF) tests, usually based on some selection criteria. The selection of the most appropriate copula is based on the following information criterion, specifically the Akaike’s Information Criterion (AIC), and the Bayesian Information Criterion (BIC) that compare the values of the optimized likelihood function are utilized:
・ The Akaike information criterion (AIC) by Akaike (1974) [20] is defined as:
(14)
where k denote the number of unknown parameters, is the log-likelihood function and the set of unknown copula parameters to be estimated for the fitted copula function. However, the more parameters in the copula function tend to result in a higher value of the likelihood function. Consequently to compensate for parsimony in the copula specification the BIC criteria is utilized.
・ the Bayesian information criterion (BIC) by Schwarz (1978) [21] is defined as
(15)
where is the optimized value of the log likelihood (LL) function, n is the number of observations in the sample and k is the number of unknown parameters to be estimated. For either AIC or BIC, one would select the copula model that yields the smallest values of the criterion.
3. Modelling of Marginal Distributions
In this paper, the two-step estimation approach is adopted in modelling the marginal distribution of the return series. In the first step the ARMA-GJR-GARCH models are fitted to all the currency exchange returns series to model the marginal distributions of each return series to capture the stylized characteristics exhibited by financial time series data. The ARMA model filters the serial autocorrelation while the GJR-GARCH [22] model compensates for the asymmetric volatility clustering in the data through the leverage term. The specification of the ARMA (m, n)-GJR-GARCH (p, q) model can be expressed as
(16)
(17)
(18)
where , and is the indicator function that takes values 1 when and zero otherwise. The persistence functions of the model is given as , where denotes the expected
value of the standardized residuals. The Equations ((16) and (18)) are the mean equation and variance equations respectively; Equation (17) illustrates the residuals that consists of standard variance and standardized residuals ; the leverage coefficient is normally applied to negative residuals resulting in additional weight for negative changes. In addition, the standardized residuals follow the Student’s t distribution that captures the fat-tailed distribution usually associated with financial time series data.
In the second step of marginal distribution estimation, the standardized residuals are fitted with a semi-parametric CDF, using a kernel density estimation method (with a Gaussian density as kernel function) for the interior part of the distribution and a generalized Pareto distribution (GPD) for both tails.
The distribution function of the generalized Pareto distribution (GPD) is given by
(19)
where is the scale parameter and the parameter is associated to the shape of the distribution. When , we obtain the Fréchet distributions, when , the Weibull distributions and finally when the Gumbel distributions respectively. Financial returns frequently follow heavy-tailed distributions and therefore only the Fréchet distributions are suitable for modeling financial returns data.
The selection of the threshold value u is an important step in estimating the parameters of the GPD using POT. McNeil and Frey (2000) [3] suggest that the threshold value should be high enough to approximate the conditional excess distribution by the GPD. However, with a higher threshold level there are fewer observations that remain for estimating the parameters. Consequently, the variance of the parameter estimates increases. In the empirical analysis the McNeil and Frey (2000) [3] approach is adopted to choose the exceedances. Carol (2008) [23] suggest that, provided that the sample data is sufficiently large (at least 2000 observations) there will always be enough log returns in the 10% tail to obtain a reasonably accurate estimate of the GPD scale and tail parameters. Thus, the GPD is used to estimate the marginal distributions in the lower and upper tails by setting the threshold levels to be approximately 10% of the data points for both the lower and upper tails and the Gaussian kernel density estimator in the interior part of the innovations distribution. The cumulative distribution function for the tail of the distribution is given by
(20)
where
are the lower and upper threshold values respectively,
is the empirical distribution on the interval
, is the number of
and
is the number of innovations whose value is smaller than
and 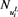 is the number of innovations whose value is bigger than
is the number of innovations whose value is bigger than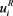 .
.
4. Forecasting VaR and Backtesting
4.1. Value-at-Risk (VaR)
Value-at-Risk (VaR) is the commonly used risk measure by both the regulators and practitioners to estimate risk especially in financial risk management. It is defined as a quantile of the profit or loss (P&L) distribution of the asset or portfolio of financial assets. It is also defined as the maximum loss due to change in asset or portfolio value at a given confidence level and a specific time duration (typically a day or 10 days) under the assumption of normal market conditions and no transactions in the assets.
Given the confidence level denoted as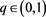 , and the loss of the asset portfolio denoted as L, the VaR of a given portfolio is the smallest number 1 such that the probability of the portfolio loss L exceeds 1 is no larger than 1 − q. Mathematically, the VaR of a given portfolio of assets at time t with level q-quantile is defined as
, and the loss of the asset portfolio denoted as L, the VaR of a given portfolio is the smallest number 1 such that the probability of the portfolio loss L exceeds 1 is no larger than 1 − q. Mathematically, the VaR of a given portfolio of assets at time t with level q-quantile is defined as
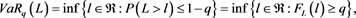 (21)
(21)
where 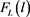 is the cumulative distribution function of the return distribution.
is the cumulative distribution function of the return distribution.
In this paper the Monte Carlo simulation approach is used to forecast the one-day-ahead portfolio VaR based on the fitted copula model to the currency exchange rates. The estimation procedure applied to forecast the one-day-ahead VaR of the equally weighted portfolio using GARCH-EVT-Copula model is as follows:
Step 1: Fit the univariate ARMA-GJR-GARCH model with appropriate error distribution for the marginal time series to each currency exchange return series to obtain standardized residuals computed as:
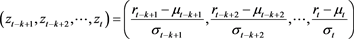 (22)
(22)
Step 2: Fit the generalized Pareto distribution (GPD) to all the standardized residual series by setting the threshold value u to be approximately 10% of the data points for both the upper and lower tails and Gaussian kernel method for the interior of the distribution. The generated standardized residuals are then transformed into standard uniform (0, 1) variates using the probability-integral transformation (PIT) and are assumed to be i.i.d observations.
Step 3: Fit the most appropriate copula for each pair of transformed data series, and estimate the parameter(s) using the Inference Function for Margins (IFM) estimation method.
Step 4: Use the estimated copula parameters to simulate N (N = 5000 in our case) times to generate N random numbers and transform them to the original scales of the log returns using the inverse quantile function of the marginal distributions.
Step 5: Finally, compute the VaR of the equally weighted portfolio by taking the sample quantile at the given significance level of the portfolio return forecasts.
The number of simulations N select is significant in terms of determining the accuracy of the VaR forecasts when applying the above procedure. The larger the number of simulations, the more accurate the estimated VaR forecasts are. This procedure can be repeated on a daily basis using rolling windows. This means that the copula and the ARMA-GJR-GARCH margins are re-estimated for each window.
4.2. Backtesting
Backtesting is a statistical method that is used to systematically compare the accuracy of the forecast portfolio VaR with the actual profit (loss) of the particular portfolio at a given significance level and specified time interval. In this paper, three backtesting procedures are implemented to evaluate the performance of the GARCH-EVT-copula model in forecasting portfolio VaR. The backtesting procedures include the percentage of VaR exceptions, the Kupiec’s unconditional coverage test and Christoffersen’s conditional coverage test.
The indicator function sometimes referred to as the “hit function” is adopted to determine whether the observed portfolio loss exceeds the estimated portfolio VaR. Let 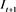 be the hit function of VaR exceptions that is denoted as:
be the hit function of VaR exceptions that is denoted as:
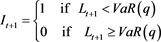 (23)
(23)
where 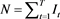 denotes the number of exceedences over a given time period when the actual loss exceeds the VaR forecast.
denotes the number of exceedences over a given time period when the actual loss exceeds the VaR forecast.
Kupiec (1995) [24] proposed the unconditional coverage test for assessing the reliability of VaR forecast models based on the effectiveness of the VaR forecasts to test the difference between observed and forecasted VaR of the equally weighted portfolio profit and loss. Given that q is the quantile, the theory behind this method is to test whether 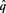 is statistically different from q. The number of exceptions N is a sum of Bernoulli variable
is statistically different from q. The number of exceptions N is a sum of Bernoulli variable 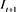 it follows a binomial probability distribution:
it follows a binomial probability distribution:
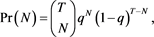 (24)
(24)
where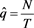 . The null hypothesis of the test is
. The null hypothesis of the test is
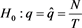 (25)
(25)
Given the q-th quantile, the likelihood ratio (LR) statistic for the test of null hypothesis is defined as:
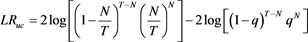 (26)
(26)
This statistic is asymptotically distributed as a chi-square distribution with one degree of freedom. However, Christoffersen (1998) [25] demonstrated that the unconditional coverage test only gives the essential condition to categorize a VaR model as satisfactory but it does not account for the possibility of clustering of violations, which can be as a result of volatility in the return series.
Christoffersen (1998) [25] introduced the conditional coverage test, which jointly combines the independence test to recognize the presence of cluster in the series and the independence of exceedances to defeat the insufficiencies of Kupiec’s unconditional coverage test. The conditional coverage test is a complete test that addresses both the unconditional coverage property and independence property. The unconditional coverage property puts a restriction on the frequency of VaR violations. The independence property or exception clustering places a restriction on the ways in which these violations may occur. The null hypothesis of LR independence test is asymptotically distributed as a chi-square distribution with one degree of freedom. Under the null hypothesis that the violations (exceptions) on any given day are independent and the average number of observed violations at any two diverse days have to be independently distributed. The appropriate likelihood ratio test statistic is defined as:
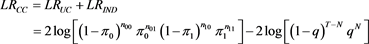 (27)
(27)
where nij represent the number of days that i occured at time t followed by j, where i, j = 0, 1. Moreover, 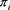 denote the probability that the exception occurs
denote the probability that the exception occurs
at time t + 1 conditional on state i at time t with 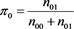 and
and .
.
The test statistic is asymptotically distributed as a chi-square distribution with two degrees of freedom.
5. Data and Empirical Results
5.1. Data Description
The data set consists of four daily currency exchange rates of the US dollar (USD), UK Sterling pound (GBP), European Union euro (EUR) and South Africa rand (SAR) against the Kenyan shilling from November 2, 2004, to February 26, 2018. The total observations are 3476 daily exchange rates for each currency exchange rate, excluding public holidays and weekends obtained from the website of the CBK website. Each data set represents the daily average closing price of analyzed currencies. The daily currency exchange rates are converted into continuously compounded returns using the formula  where
where  is the price at time t of i-th currency exchange rate series.
is the price at time t of i-th currency exchange rate series.
Figure 1 present the plot of the returns series of all currency exchange rates and the plots illustrate the stylized feature of leptokurtosis that arises from a pattern of time-varying volatility clustering in the currency exchange market where periods of high (low) volatility are followed by periods of high (low) volatility. The time-varying behaviour of currency exchange returns suggest the presence of stylized characteristics exhibited by financial time series data.
The summary statistics of the daily currency exchange return series are presented in Table 1. For all exchange rates the values of the mean are close to zero and all the values of standard deviations are positive and considerably large confirming the high volatility illustrated by the return plots. The results for skewness indicate that the return series for the US dollar and EU euro are positively skewed while the return series for the GB pound and SA rand are negatively skewed. The results for kurtosis indicate that all the return series exhibit excess kurtosis implying the return distributions have fat tails and exhibit leptokurtosis. The Jarque-Bera (JB) test statistic values are significantly large compared to their critical values confirming that the return series are non-normal. The Augmented Dickey Fuller (ADF) unit root test is used to determine whether the return series are stationary. The ADF test results confirm that all the return series can be assumed to be stationary, since the unit root null hypothesis is

Figure 1. Daily currency prices and daily returns (period from November 02, 2004 to February 26, 2018).

Table 1. Summary descriptive statistics of currency exchange returns.
The table presents the summary statistics of the daily returns over the full sample period from November 2, 2004, to February 26, 2018 for the USD, GBP, EUR and ZAR. JB is the test statistic of the Jarque-Bera test form normality of the unconditional distribution of returns. ADF (k) is the statistic of the augmented Dickey-Fuller (1979) test for a unit root against a trend stationary alternative augmented with k lagged difference terms. LBQ (k) is the statistic of the Ljung-Box (1978) portmanteau Q-test assessing the null hypothesis of no autocorrelations in the squared returns at k lags. LM (k) is Engle’s (1982) Lagrange multiplier statistics for testing the presence of ARCH effects on k lags. The critical values of Ljung-Box test and LM test are 18.307 (lag 10), 31.410 (lag 20) and, 67.5048 (lag 50) at 5%. The correlations report Pearson’s linear unconditional sample correlation between the daily returns over the full sample period.
rejected at all levels of signifiance. The Ljung-Box test is used to test the presence serial autocorrelation in the squared returns data; the Ljung-Box Q-statistics reported for all currencies are significantly high rejecting the null hypothesis of no serial autocorrelation through 20-lags at the 5% level of significance. Finally the ARCH-LM test rejects the null hypothesis of no ARCH effect, thus confirming the strong presence conditional heteroscedasticity is the data. This supports the need to apply an appropriate conditional heteroscedastic model to filter the heteroscedasticity in the currency exchange returns series. The correlations report Pearson’s linear unconditional sample correlations between the daily returns over the full sample period. The correlation coefficient figures are all positive for each pair of the currency exchange return series. The EUR-GBP has the highest correlation and the USD-ZAR has the lowest.
5.2. Results for the Marginal Distributions
The two-step estimation approach is adopted. In the first step the ARMA (1, 1)-GJR-GARCH (1, 1) model introduced in Section 3 is fitted to each returns series assuming that the innovations are conditionally distributed as Student’s t to account for heavy tailed distribution. Parameter estimates for the fitted models are obtained by the method of quasi-maximum likelihood. The parameter values for the fitted models (standard errors enclosed in parenthesis) together with the results of diagnostic tests for the standardized squared residuals are presented in Table 2. All constant parameters are positively significant from zero except for ZAR, so all currency exchange rates increase over time. The AR (1) and MA (1) terms for all the currency exchange rates are not significantly different from zero. In all four series the sum of  and
and  parameters is less than one, suggesting that the fitted model is stationary. The Ljung-Box test statistic and the Engle’s ARCH tests confirm that all the standardized squared residuals fails to detect any serial correlation and presence of ARCH effects. The null hypothesis of no serial autocorrelation remain is not rejected at 5% level, indicating that neither long memory dependence nor non-linear dependence is found in the residual series. We conclude that the ARMA (1, 1)-GJR(1, 1)-model sufficiently explains the autocorrelation and heteroscedasticity effects in each log return series and leads to standardized residuals which represent the underlying zero mean and unit variance independently and identically distributed series upon which the EVT estimation of the sample CDF tails is based.
parameters is less than one, suggesting that the fitted model is stationary. The Ljung-Box test statistic and the Engle’s ARCH tests confirm that all the standardized squared residuals fails to detect any serial correlation and presence of ARCH effects. The null hypothesis of no serial autocorrelation remain is not rejected at 5% level, indicating that neither long memory dependence nor non-linear dependence is found in the residual series. We conclude that the ARMA (1, 1)-GJR(1, 1)-model sufficiently explains the autocorrelation and heteroscedasticity effects in each log return series and leads to standardized residuals which represent the underlying zero mean and unit variance independently and identically distributed series upon which the EVT estimation of the sample CDF tails is based.
Next, the standardized residuals are fitted with a semi-parametric CDF which
Table 2. Parameter Estimates of the ARMA (1, 1)-GJR-GARCH (1, 1) Model with Student’s t innovations.
The table contains results of maximum likelihood estimator for margin models with ARMA (1, 1)-GJR-GARCH (1, 1) Model with the standard errors in parentheses.
consists of using a Gaussian kernel density function for the interior part of the distribution and generalized Pareto distribution (GPD) for both tails. Specifically, 10% of the standardized residuals are reserved for the upper and lower thresholds to estimate the tail distribution. Table 3 presents the results of estimated parameters of the tails distribution based on the GPD fitted to the standardized innovations. Two threshold levels (upper and lower) are also indicated in Table 3, where 10% of total observations for these standardized residual series are used in the estimation. For all the returns series, the shape parameter is found to be positive (except for the upper tail of SAR and the lower tail of EUR) and significantly different from zero, indicating heavy-tailed distributions of the innovation process characterized by the Fréchet distribution. The Ljung-Box test and the Kolmogorov-Smirnov (KS) tests are used to test the transformed standardized residuals confirm that they are uniform [0, 1].
Figure 2 and Figure 3 present the scatter plots of the bivariate standardized residual series for the ARMA-GJR-GARCH-EVT models before and after transformation into uniform [0, 1] variates respectively. We can observe positive dependence between the pairs of USD-GBP and EUR-GBP currency exchange rates. Such filtration still preserves the contemporaneous dependence among the returns as shown in Figure 3. The transformed data are used in analyzing the dependence structure using copula.
5.3. Results for the Dependence Models
The dependence structure between the transformed standardized residuals of the currency exchange rates are modeled using copulas. The results for the estimated copula parameter are given in Table 4. The results include the copula parameter estimates with the standard errors in parentheses, the coefficients of lower tail dependence (LTD) and upper tail dependence (UTD) and selection criteria; AIC, BIC and log-likelihood values of each fitted copula. The degrees freedom of the Student-t copula are relatively low (less than or equal to 10), suggesting that the
Table 3. Parameter estimates for ARMA-GJR-GARCH-EVT model.

Figure 2. Scatter plots of standardized residuals for the pairs of USD-GBP and EUR-GBP currency exchange rates.

Figure 3. Scatter plots of transformed standardized residuals for the pairs of USD-GBP and EUR-GBP currency exchange rates.
inter-dependence and tail dependence of the currency exchange pairs are non-normal. Comparing AIC, BIC, the Student’s t copula performs best for all pairs according to the AIC, BIC criteria. Therefore, we conclude that the Student’s-t copula is dominant as the best-fitting copula function for the currency exchange rates.
Table 4. Parameter estimates for the fitted copulas.
This table presents estimated parameters of copulas via two-stage maximum likelihood estimator. Standard errors are shown in parentheses. Loglik represents log likelihood function. Figures in bold indicate significant at 5% level.
5.4. Forecasting Value at Risk
In this section, an equally weighted portfolio of the four currency exchange rates is constructed to exploit the GARCH-EVT-copula framework in forecasting portfolio VaR. In order to compute portfolio VaR forecasts, a rolling window is set at 1000 observations to generate portfolio VaR forecasts per currency exchange series for all the data sets. The Monte Carlo simulation approach is used to compute the one-day-ahead VaR of the portfolio at the 90%, 95% and 99% levels of significance.
To assess the accuracy of portfolio VaR forecasts, the Kupiec’s unconditional coverage test and the independence and Christoffersen’s conditional coverage tests are used to perform backtesting. For the testing period of 2475 observations and confidence levels of 10%, 5%, and 1%, we expect 248, 124 and 25 exceedances, respectively. As expected, VaR forecasts of the Gaussian-copula model, which we include for comparison, are the least accurate. However, we would like to evaluate them using the above tests in order to compare them directly to the forecasting accuracy of the Student’s t copula as well as the GARCH-EVT-t copula model. For our testing period, the benchmark Gaussian and the Student’s t copula produce almost the same hit sequences and hence are considered together. When comparing these expected hits with the actual hits then it looks like the 99% VaR is fairly accurate, but the 95% and 90% VaR slightly overestimate the risk.
The p-values of the VaR backtests are shown in Table 5. According to the tests, the forecasts of the copula models show a weak lack of coverage at the 90% and 95% levels, but this is not the case at the important 99% level, which is frequently used in practice. The backtesting results indicate that all p-values of the unconditional coverage and conditional coverage tests are greater than 0.05 and the calculated exceedances percentages of all portfolio VaR tests are close to the
Table 5. Tests of independence, unconditional and conditional coverage.
Table 5 Results for the one-day-ahead portfolio VaR for the currency exchange portfolio data. P-values for the Kupiec and Christoffersen VaR backtests are also given.
theoretical probability level of 10%, 5% and 1%. For the 99% VaR none of the combined tests is rejected, so this means the amount of hits are not significantly different from the expected hits. This implies that all the null hypotheses are not rejected and the calculated exceedances based on the best-fitting GARCH-EVT-t copula model are correct. That is, they are correct and independent (conditional coverage test).
6. Conclusion
This paper implements the application of the GARCH-EVT-Copula model to evaluate the portfolio risk of an equally weighted portfolio of currency exchange rates. First, the ARMA-GJR-GARCH (1, 1) model is used to filter the log-returns for the presence of autocorrelation and conditional heteroscedasticity. Consequently the Generalized Pareto distribution is applied to model the tail distribution of the innovation of each currency return. Bivariate Elliptical and Archimedean copulas are fitted to the paired independently and identically distributed transformed standardized series to model the dependence structure between the return series. The portfolio VaR for an equally weighted portfolio of four currency exchange returns is also computed using the benchmark models and the GARCH-EVT-copula model. The empirical results demonstrate that the Student’s-t copula is the most appropriate copula in modeling dependence structure between all pairs of currency exchange rates. The GARCH-EVT-Copula model captures the portfolio VaR forecast successfully on the basis of the coverage backtesting tests. Further research should consider time-varying dependence modeling and high dimensional multivariate copula modelling approach such as vine copulas in financial risk management applications.
Acknowledgements
The author acknowledges the Dedan Kimathi University Research Fund for financial support. The authors also thank all the reviewers for insightful comments.
Cite this paper
Omari, C.O., Mwita, P.N. and Gichuhi, A.W. (2018) Currency Portfolio Risk Measurement with Generalized Autoregressive Conditional Heteroscedastic-Extreme Value Theory-Copula Model. Journal of Mathematical Finance, 8, 457-477. https://doi.org/10.4236/jmf.2018.82029
References
- 1. Engle, R.F. and Manganelli, S. (2004) CAViaR: Conditional Autoregressive Value at Risk by Regression Quantiles. Journal of Business & Economic Statistics, 22, 367-381. https://doi.org/10.1198/073500104000000370
- 2. Artzner, P., Delbaen, F., Eber, J.M. and Heath, D. (1999) Coherent Measures of Risk. Mathematical Finance, 9, 203-228. https://doi.org/10.1111/1467-9965.00068
- 3. McNeil, A.J. and Frey, R. (2000) Estimation of Tail-Related Risk Measures for Heteroscedastic Financial Time Series: An Extreme Value Approach. Journal of Empirical Finance, 7, 271-300. https://doi.org/10.1016/S0927-5398(00)00012-8
- 4. Sklar, M. (1959) Fonctions de Répartition à n Dimensions et Leurs Marges. Publications de l’Institut Statistique de l'Université de Paris, 8, 229-231.
- 5. Embrechts, P. (1999) Extreme Value Theory in Finance and Insurance. Manuscript, Department of Mathematics, ETH, Swiss Federal Technical University.
- 6. Demarta, S. and McNeil, A.J. (2005) The t Copula and Related Copulas. International Statistical Review, 73, 111-129. https://doi.org/10.1111/j.1751-5823.2005.tb00254.x
- 7. Denuit, M., Dhaene, J., Goovaerts, M., Kaas, R. and Laeven, R. (2006) Risk Measurement with Equivalent Utility Principles. Statistics & Decisions, 24, 1-25. https://doi.org/10.1524/stnd.2006.24.1.1
- 8. Cherubini, U., Luciano, E. and Vecchiato, W. (2004) Copula Methods in Finance. John Wiley & Sons, Hoboken. https://doi.org/10.1002/9781118673331
- 9. Cherubini, U., Gobbi, F., Mulinacci, S. and Romagnoli, S. (2012) Dynamic Copula Methods in Finance. John Wiley & Sons, Hoboken.
- 10. Nelsen, R.B. (2006) An Introduction to Copulas. 2nd Edition, Springer Science Business Media, New York.
- 11. Joe, H. (1997) Multivariate Models and Multivariate Dependence Concepts. CRC Press, Boca Raton. https://doi.org/10.1201/b13150
- 12. Jondeau, E. and Rockinger, M. (2006) The Copula-GARCH Model of Conditional Dependencies: An International Stock Market Application. Journal of International Money and Finance, 25, 827-853. https://doi.org/10.1016/j.jimonfin.2006.04.007
- 13. Wang, Z.R., Chen, X.H., Jin, Y.B. and Zhou, Y.J. (2010) Estimating Risk of Foreign Exchange Portfolio: Using VaR and CVaR Based on GARCH-EVT-Copula Model. Physica A: Statistical Mechanics and Its Applications, 389, 4918-4928. https://doi.org/10.1016/j.physa.2010.07.012
- 14. Ghorbel, A. and Trabelsi, A. (2014) Energy Portfolio Risk Management Using Time-Varying Extreme Value Copula Methods. Economic Modelling, 38, 470-485. https://doi.org/10.1016/j.econmod.2013.12.023
- 15. Tang, J., Zhou, C., Yuan, X. and Sriboonchitta, S. (2015) Estimating Risk of Natural Gas Portfolios by Using GARCH-EVT-Copula Model. The Scientific World Journal, 2015, Article ID: 12595. https://doi.org/10.1155/2015/125958
- 16. Huang, C.S. and Huang, C.K. (2014) Assessing the Relative Performance of Heavy-Tailed Distributions: Empirical Evidence from the Johannesburg Stock Exchange. Journal of Applied Business Research, 30, 1263. https://doi.org/10.19030/jabr.v30i4.8675
- 17. Hougaard, P. (1986) A Class of Multivariate Failure Time Distributions. Biometrika, 73, 671-678. https://doi.org/10.2307/2336531
- 18. Joe, H. and Xu, J.J. (1996) The Estimation Method of Inference Functions for Margins for Multivariate Models. The University of British Columbia, Vancouver.
- 19. Patton, A.J. (2006) Estimation of Multivariate Models for Time Series of Possibly Different Lengths. Journal of Applied Econometrics, 21, 147-173. https://doi.org/10.1002/jae.865
- 20. Akaike, H. (1974) A New Look at the Statistical Model Identification. IEEE Transactions on Automatic Control, 19, 716-723. https://doi.org/10.1109/TAC.1974.1100705
- 21. Schwarz, G. (1978) Estimating the Dimension of a Model. The Annals of Statistics, 6, 461-464. https://doi.org/10.1214/aos/1176344136
- 22. Glosten, L.R., Jagannathan, R. and Runkle, D.E. (1993) On the Relation between the Expected Value and the Volatility of the Nominal Excess Return on Stocks. The Journal of Finance, 48, 1779-1801. https://doi.org/10.1111/j.1540-6261.1993.tb05128.x
- 23. Alexander, C. and Sheedy, E. (2008) Developing a Stress Testing Framework Based on Market Risk Models. Journal of Banking & Finance, 32, 2220-2236. https://doi.org/10.1016/j.jbankfin.2007.12.041
- 24. Kupiec, P.H. (1995) Techniques for Verifying the Accuracy of Risk Measurement Models. The Journal of Derivatives, 3, 73-84. https://doi.org/10.3905/jod.1995.407942
- 25. Christoffersen, P.F. (1998) Evaluating Interval Forecasts. International Economic Review, 39, 841-862. https://doi.org/10.2307/2527341