Journal of Mathematical Finance
Vol.07 No.03(2017), Article ID:78848,18 pages
10.4236/jmf.2017.73040
Multi-Period Portfolio Selection with No-Shorting Constraints: Duality Analysis
Jun Qi, Lan Yi
Management School, Jinan University, Guangzhou, China

Copyright © 2017 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: July 25, 2017; Accepted: August 28, 2017; Published: August 31, 2017
ABSTRACT
This paper considers a multi-period mean-variance portfolio selection problem with no shorting constraint. We assume that the sample space is finite, and the possible securities price vector transitions is equivalent to the number of securities. By making use of the embedding technique of Li and Ng (2000), the original nonseparable problem can be solved by introducing an auxiliary problem. After the risk neutral probability is calculated, the auxiliary problem can be solved by using the martingale method of Pliska (1986). Finally, we derive a closed form of the optimal solution to the original constrained problem.
Keywords:
Multi-Period Mean-Variance Formulation, Auxiliary Market, Martingale Method, Risk Neutral Probability, Duality, Optimal Trading Strategy

1. Introduction
Portfolio theory deals with the question of how to find an optimal distribution of the wealth among various assets. Mean-variance analysis and expected utility formulation are two different tools for dealing with portfolio selections. A fun- damental basis for portfolio selection in a single period was provided by Mar- kowitz. Under the assumption that short-selling of stocks is not allowed, ana- lytical expression of the mean-variance efficient frontier in single-period port- folio selection was derived by solving a quadratic programming problem in Markowitz (1952) [1] . Later, an analytical solution to the single-period mean- variance problem with assumption that short-selling is allowed is derived in Merton (1972) [2] .
Recently, a multi-period portfolio selection problem has been studied. This problem is more interesting as investors always invest their wealth in multi periods instead of only one period. Work of Li and Ng (2000) [3] considers the multi-period portfolio selection problem in a mean-variance framework when short-selling of stocks is allowed. Li and Ng have derived the analytical formu- lation of the frontier of the multi-period portfolio selection by embedding the assets-only multi-period mean-variance problem into a large tractable problem. When short-selling is not allowed, the multi-period portfolio selection problem is much more difficult to deal with. For continuous-time mean-variance port- folio selections, Xun, Xunyu and Andrew (2002) [4] use stochastic optimal linear-quadratic method. For multi-period setting, the portfolio selection pro- blem with no-shorting constraint has been studied in Xu and Shreve (1992) [5] [6] . These papers investigated a utility maximization problem with a no short- selling constraint using a duality analysis.
The objective of this paper is to investigate dynamic mean-variance portfolio selection when short-selling is not allowed. Instead of using optimization me- thod, this paper used a martingale approach, which was originally proposed by Pliska (1986) [7] . To our knowledge, no analytical numerical method using martingale measure for finding the optimal portfolio policy with no-short shelling constraint for the multiperiod mean-variance formulation has been reported in the literature. In this sense, this paper extends existing literature by utilizing a martingale approach to solve an optimal portfolio selection problem with no-shorting constraint. This approach also showed that a unique equivalent martingale measure exist in the no-arbitrage complete market model. An effec- tive algorithm is derived for finding the maximum quadratic utility function with no-short selling constraint.
To outline of this paper, In Section 2, we build up the security market model. In Section 3, we consider the optimal portfolio selection problem with no short- selling constraint. By transforming the original market to some auxiliary markets, the optimal value of original constrained problem can be derived by the optimal valued of the unconstrained problem in the auxiliary markets. In Section 4, we use martingale approach to solve the unconstrained problem in the auxiliary markets. In Section 5, the optimal terminal wealth was derived by solving a dual problem. In Section 6, the derive the optimal trading strategy based on the optimal terminal wealth. A numerical example is also given in the Section 7. Finally, we conclude the paper.
2. Security Market Model
We consider a multi-period security market model with trading dates (indexed by ), and the time horizon T is finite. There are n risky securities and one bond in the market. Let be the probability space. Suppose there are finite states of the world, and let be the state space of the economy at time t. The sample space of the economy has a finite number of element with . The filtra- tion where is generated by reveals the information on the economy. Specifically, and . We claim that the process is -adapted. For any , .
The securities are traded in the market without transaction cost. Denote the stochastic process of the security price as , where is a random vector, and the bond price process as , where is constant. Let be the risky security return process defined by and for , and be the bond return process defined by with for all .
Assumption 2.1. 1) The state space at time has elements; 2) For any , if , then ; 3) Denote a matrix of the securities’ prices
for and
The above assumption makes the security market a complete one. We can easily verify that the sample space of the market has elements under assumption 2.1.
We consider an investor in the financial market with initial wealth v. She or he follows a self-financing trading strategies
where and is the number of units of the ith risky security held between time and . The number of money invested in the bond is .
Assumption 2.2. The investor invests her or his wealth in the complete market with no short-selling constraint, that is
(1)
Let be the value of portfolio at time , it satisfies
(2)
where
For our convenience, we introduce the discounted price process with and . So the discounted value of portfolio is . The change of the discounted prices of risky security is defined as with .
We can also defined the self-financing trading strategies as , where and is the fraction of money invested in ith risky security at time . Similarly, the no short-selling requires that is non-negative for any . Therefore, the value of portfolio can be re- written as . It is easy to verify that .
3. Primal and Auxiliary Problem
The multi-period portfolio optimization problem under mean-variance frame- work in this paper can be formulated as follows:
for . Varying the value of yields the set of efficient solutions.
As indicated in Li and Ng (2000), above problem is difficult to be solved directly because of the non-separability in the sense of dynamic programming. In Li and Ng (2000), the relation between the multi-period mean-variance portfolio selection problem with a fixed investment horizon and a separable portfolio selection problem with a quadratic utility function is investigated and the analytical solution is derived by using an embedding scheme. Fortunately, Theorems 1 and 2 in Li and Ng (2000) can be also applied in the current subject with an uncertain investment horizon. We now consider the following auxiliary problem:
The objective function of the auxiliary problem is equivalent to the quadratic utility function , . It is concave and twice con- tinuously differentiable function.
Proposition 3.1. 1) The first derivative of is .
2) The inverse function of is .
The optimal portfolio problem is to maximize the expectation of under the no short selling constraint . So the con- strained optimal portfolio problem is:
where denote the set of all admissible trading strategies belong in .
Since there is a no short-selling constraint in the optimal portfolio selection problem, it is difficult to be solved directly by dynamic programming. We will try to solve the problem by introducing unconstraint auxiliary problems.
Denote the support function of by
In order to eliminate the situation , we defined that the effective domain of is the convex cone , and for . We introduce the predictable process with for all . Let denote the set of all such process . Define an auxiliary market for each by modifying the return processes for the bond and the risky securities as:
Specially, the market with is the original market.
We consider the unconstraint optimal portfolio problem in the market :
Let denote the corresponding optimal objective value in the market .
Theorem 3.1. Suppose is the optimal solution of the primal constrained problem, and is the optimal solution of the dual problem
where is the optimal objective value in the unconstrained market , associated with the optimal solution . If the optimal trading strategy for the unconstrained market satisfies.
a)
b) , for all
Then is the optimal strategy for the original constrained market, and .
Proof. For the market and optimal trading strategy which satisfies (a) and (b), the value of portfolio at time is
As is a feasible solution of the original constrained problem, the expected utility of is smaller than or equal to the optimal value of the original constrained problem. So we have .
On the overhands, for an arbitrary market and the optimal trading strategy of the original constrained portfolio problem, we have,
Since for any , therefore, for any . Hence, .
Putting together the above two inequalities, we have .
4. Martingale Method
Now we try to solve the auxiliary problems
Denote the risk neutral probability in the market as . Let be the state price density.
Proposition 4.1. Under the no-arbitrage consideration, The expected dis- counted terminal wealth based on the risk neutral probability is equal to the initial wealth, i.e.
So the problem is equivalent to
Theorem 4.1. For the above optimal problem with quadratic utility function, the optimal attainable wealth is:
and the optimal objective value is
Proof.
The necessary conditions to maximize this expression must be:
This is equivalent to
The value of the parameter is the one that makes satisfies . Hence
Therefore, . Hence, we have
and the optimal objective value
5. Optimal Terminal Wealth
Now we come to the dual problem:
Since and , the problem is equivalent to
Definition 5.1. For arbitrary , we defined the matrix of the price change at time as
where is the change of discounted price of jth security at time when the market is at state at time .
Definition 5.2. Denote as an matrix, which comes from by deleting column .
Definition 5.3. Denote as an matrix, which comes from by replacing the row with .
Theorem 5.1. Under the assumption 2.1, the market exists an unique risk neutral probability
is the price of the ith risky security at time when the market is at the state .
Proof. We can see that for any . First, we try to prove that the sum of is equal to one.
For , we have
and .
Because
where
hence
Suppose for , the sum of the is one.For , the sample space is . Under the assumption 2.1, can be divided into subspace , where includes all the which has the same state in the first k period (i.e. ), and . for any . So for arbitrary subspace ,
we can verify that
Therefore,
So we conclude that for any T, the sum of is one, and this defines a probability.
Now we try to prove that the probability is a risk neutral probability in the market. Consider an arbitrary time t, and arbitrary event A corresponding to (i.e. for , have been known). Suppose , we know that , . We denote the subset of A as , where all element in has ( ). For ith risky security we have
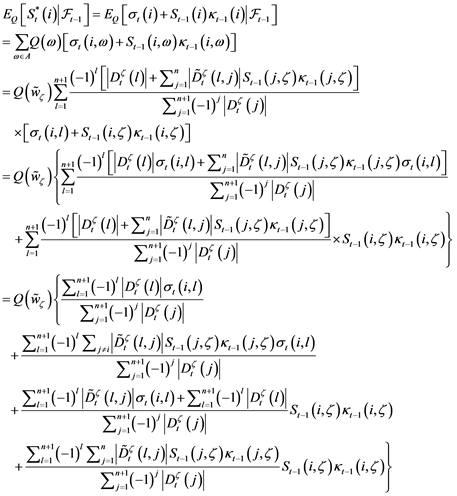
There are four part. For part (1),
where is the ith row of .
For part (2), because
for , where is the ith row of . Hence,
For part (3),
For part (4),
Hence,
So this probability is a risk neutral probability of the market.
The dual problem is equivalent to
To simplify our problem, we give the following notations:
So the problem can be rewrite as:
There have some special properties of the objective function, which makes the calculus much easy. Denote
Proposition 5.1. Under the assumption 2.1, have the following pro- perty:
So we have
The problem is separable and can be solved by dynamic programming.
Theorem 5.2. If has full rank for any and , then the optimal solution of the dual problem is
for and , with
where is:
Proof. Let
At , for ,
We separately solve the following problem for each :
We solve the unconstrained problem, and the optimal is:
The optimal solution of the constrained problem is where
So , and
Now we come to . We separably to solve the following problem for :
We solve the unconstrained problem, and the optimal is:
The optimal solution of the constrained problem is where
So , and
Generally, at stage , we suppose is
We separably to solve the following problem for each :
We solve the unconstrained problem, and the optimal is:
The optimal solution of the constrained problem is where
Hence, the optimal solution of the dual problem is
for and , with
where is:
Hence, the risk neutral probability with optimal is
and the optimal terminal wealth is
Hence, the expectation and variance of terminal wealth are:
where
The optimal must satisfy the optimality condition of , that is,
6. Optimal Trading Strategy
Let , so .
Proposition 6.1. For any , are equivalent for
where is belong to the period sample space, and . We denote
We have the relationship between and for any :
So we can iteratively derive and corresponding trading strategy for each .
For , we consider , and . For each i there are element in the set . For an arbitrary set , we notate the element in it as . So
Rewrite the above equations as the matrix form as , where
If is full rank, .
Generally, for , we consider , and . For each i there are element in the set . For an arbitrary set , we notate the element in it as . So
Rewrite the above equations as the matrix form as , where
If is full rank, .
7. Numerical Example
We consider a market with one risky security and one bond, and the investment horizon is . Suppose the bond price is constant. The prices of the risky security are:

The risk neutral probability in market are:
We solve the dual problem:
The optimal solution of this is easily found to be:
The optimal value is
Finally, we get the optimal trading strategy of the original problem by solving some linear equations. The optimal strategy are
8. Conclusion
Optimal mean-variance multiperiod portfolio selection with no shorting con- straints problem is studied in the paper. We connect the original mean-variance problem to an auxiliary problem by using an embedding technique. Since the auxiliary problem is difficult to solve directly, we extend the literature by using duality theory and martingale approach to do the analysis. Finally, the derived analytical optimal multiperiod portfolio strategy provides investors with the best strategy to follow in a no-short selling dynamic investment environment. The limitation in this paper is that we derive the optimal portfolio policy by maxi- mizing the quadratic utility function. A future research subject is investigation of an optimal solution using different utility objective function.
Acknowledgements
Jinan University scientific research cultivation and Innovation Fund, Number: 17JNQN025.
Cite this paper
Qi, J. and Yi, L. (2017) Multi-Period Portfolio Selection with No-Shorting Constraints: Duality Analysis. Journal of Mathematical Finance, 7, 751-768. https://doi.org/10.4236/jmf.2017.73040
References
- 1. Markowiz, H. (1983) Portfolio Selection. The Journal of Finance, 7, 77-91.
- 2. Merton, R.C. (1972) An Analytic Derivation of the Efficient Portfolio. The Journal of Financial and Quantitative Analysis, 7, 13-15. https://doi.org/10.2307/2329621
- 3. Duan, L. and Ng, W.L. (2000) Optimal Dynamic Portfolio Selection: Multiperiod Mean-Variance Formulation. Mathematical Finance, 10, 387-406. https://doi.org/10.1111/1467-9965.00100
- 4. Li, X., Zhou, X.Y. and Lim, A.E.B. (2002) Dynamic Mean-Variance Portfolio Selection with No-Shorting Constraints. Journal on Control and Optimization, 40, 1540-1555. https://doi.org/10.1137/S0363012900378504
- 5. Xu, G.L. and Shreve, S.E. (1992) A Duality Method for Optimal Consumption and Investment under Short-Selling Prohibition. i. General Market Coefficients. Annals of Applied Probability, 2, 87-112. https://doi.org/10.1214/aoap/1177005772
- 6. Xu, G.L. and Shreve, S.E. (1992) A Duality Method for Optimal Consumption and Investment under Short-Selling Prohibition. ii. Constant Market Coefficients. Annals of Applied Probability, 2, 314-328. https://doi.org/10.1214/aoap/1177005706
- 7. Pliska, S.R. (1986) A Stochastic Calculus Model of Continuous Trading: Optimal Portfolios. Mathematics of Operations Research, 11, 371-382. https://doi.org/10.1287/moor.11.2.371