Journal of Mathematical Finance
Vol.06 No.05(2016), Article ID:72243,21 pages
10.4236/jmf.2016.65060
Predicting Risk/Return Performance Using Upper Partial Moment/Lower Partial Moment Metrics
Fred Viole1, David Nawrocki2
1OVVO Financial Systems, Holmdel, NJ, USA
2Villanova School of Business, Villanova University, Villanova, PA, USA

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: June 15, 2016; Accepted: November 21, 2016; Published: November 24, 2016
ABSTRACT
Minimizing the classical definition of risk should be a counterintuitive venture as the explanatory nature of historical metrics’ construction challenges their ability to serve a predictive purpose on a non-stationary process. We uncover an ill-conceived bias in these metrics and discover that they provide a contrary indication to an investment’s survivability. The breakdown in the explanatory-predictive link is troubling and we aim to correct this via a better derived explanatory metric. The predictive variant of our metric will directly question the notion of optimization in order to serve the first priority of any continuous system, survival.
Keywords:
Partial Moments, Asymmetric Nonlinear Utility, Entropy, Non-Stationary Benchmark

1. Introduction
Was the financial crisis of 2008 really an anomaly or was the preceding era of complacent volatility the true anomaly? This historically low volatility environment fostered a false positive in the minds of many risk managers. We have tamed the beast as it were. With the advent of value-at-risk (VaR) and other newly accepted risk management techniques, it was actually possible to figure out how much one could lose in a given day and contain volatility. That is if nothing happened. And nothing did happen for quite a while. This muted entropy created a reflexive feedback loop of ignorance. The first event was the Long Term Capital Management failure in 1998. Instead of losing a maximum of $50 million a day according to VaR, the fund started losing $500 million a day soon after the Russian bond default. Then in June of 2007, the next shoe dropped. Two Bear Sterns hedge funds, the Bear Stearns High-Grade Structured Credit Fund and the Bear Sterns High-Grade Structured Credit Enhanced Fund both needed bail outs. Risk managers’ models throughout the industry viewed these events as “tail events” thus believing a mean reversion to perceived normalcy would surely follow. The ensuing bifurcation over the next 18 months decimated any and all risk models that had been constructed and optimized on these experimental parameters which were devoid of any common sense assumptions.
Lopes and Oden [1] note that the very notion of risk may be misguided. Lopes and Oden (1999, p. 21) “Few, however, have explored the possibility of modeling risk as the raw probability of not achieving an aspiration level”. As Swisher and Kasten [2] astutely point out “A valid risk definition must not yield nonsensical answers-it must describe actual investor fear of bad outcomes with reasonable accuracy… returns above the mean- or MAR-are not what investors fear.” It is in this spirit we aim to dismiss the classical notion of risk as solely a downside variance parameter and attempt to re- quantify it within an upper and lower partial moment fabric.
2. Historical Measures
Performance measures provide us with the age old argument of explanatory versus predictive, to optimize or not. Milton Friedman [3] published “The Methodology of Positive Economics” in 1953, in which he argued that unrealistic assumptions in economic theory do not matter so long as the theories make correct predictions. Assumptions need no further justification as long as the results are correct. In other words, if it wasn’t “garbage out” it didn't matter what was going “in.” Herbert Simon [4] countered that purpose of scientific theories is not to make predictions, but to explain things ? predictions are then tests of whether the explanations are correct (Beinhocker, [5] ). This argument is especially relevant to quantitative finance, specifically stochastic volatility models-Do you let the data drive your answers and optimize the here and now or do you factor in some expected assumption that would de-optimize your explanatory results? Survival dictates the latter, following modern portfolio theory (MPT) and post-modern portfolio theory (PMPT) “risk” measurements provides the former.
MPT measures have been scrutinized for decades. The low hanging fruit has already been picked. Post Modern Portfolio Theory (PMPT), using downside deviation, evolved and merely refined a flawed thought process. In a nescient blessing, MPT is marginally better conceived because it uses standard deviation, which encompasses the entire distribution, even though it assumes a Gaussian distribution. However, neither model defines volatility expeditiously, regardless of distributional assumptions. A Brownian Motion (Wiener) process illustrates the effects of time on cumulative volatility. The effect of a proportional increase in volatility as time increases has been lost on all of the historical return/risk measures. The fact that standard deviation, variance or semi-variance, is used in the denominator and mean returns are used in the numerator creates ratios that have a natural tendency to decline over time. The mean return, it is argued, should be able to overcome that headwind, illustrating a superior investment. It is not only where you wind up, but how you get there that will illustrate a superior investment.
The issue is that benefit-cost analysis such as the Treynor ratio, Sharpe Ratio, Jensen’s Alpha, reward to semivariability ratio, Mean/Lower Partial Moment (LPM) ratio all utilize standard deviation, beta or below target semivariance solely in their denominator. Jensen’s Alpha utilizes the portfolio Beta as a multiplier in its computation, therefore succumbing to the unequal treatment of volatility. The other measures using the mean return or any other averaging metric does not offer an adequate substitute for the observed upside volatility in the numerator. An observation at time t is not transitive, it cannot simultaneously be a gain and a loss. If a result is below a target, it is a negative utility result to the investor. The use of mean in the numerator and a positive target for semivariance in the denominator for example, will generate these logical violations where the same observation is being used in a conflicting manner.
Given an opportunity cost such as a risk-free rate of return, the semivariance will compute the volatility of returns below this opportunity cost (target return). The mean return in the numerator is an expected benefit of holding the investment but it will include returns below the opportunity cost. The benefit in the numerator should not include below target returns. Therefore, the proper measure of an investment’s benefits will only include returns that are above the target return. We propose the Upper Partial Moment (UPM) because it will only include returns that are above the target return and the use of a UPM/LPM ratio because it discriminates between a benefit and a cost.
Stochastic Dominance was a promising methodology of ordering since volatility itself is a stochastic process, but fails due to its reliance on cumulative distribution functions which only consider below target probabilities1. We have noted that there are very different connotations between above target gains and below target losses. Stochastic dominance also requires an underlying stationarity assumption that is not consistent with real life observations.
Value at Risk (VaR) which calculates its thresholds from the distribution of historical portfolio returns does not consider an increase in distribution volatility which would extend observed thresholds. In fact, VaR offers less predictive value than a 0 degree Lower Partial Moment (LPM) calculation. Tee [7] illustrates how VaR is transformed into LPM of zero, LPM0 (−VaR(p)), of target t = (−VaR(p)), giving the probability that the actual loss to be greater than −VaR(p). The entire point of VaR is that losses can be extremely large, and sometimes impossible to define, once you get beyond a VaR point. To a risk manager, VaR is the level of losses at which you stop trying to guess what will happen next, and start preparing for anything. David Einhorn, the hedge fund manager who actively began shorting Lehman Brothers in July 2007, compared VaR to “an airbag that works all the time, except when you have a car accident.”2
To summarize, previous financial crises have demonstrated the insufficiencies of historical measures. Most measures also have no utility theory support, assuming linear utility functions above the target return, and are completely backwards looking in- sample. The “ill-conceived bias” is the fact a single observation is used for both “Risk” and “Return” considerations. VaR fails as a risk metric because it is not based on any notion of utility theory (and has been rejected by Markowitz [8] as a risk measure) and because it along with stochastic dominance, Sharpe ratio, Treynor ratio, Reward to Semivaribility, Mean-LPM, and the Jensen Alpha, do not discriminate between a benefit and a cost. Very simply, a return cannot be both a benefit and a cost.
3. A Better Explanatory/Predictive Measure
Ang and Chua [9] describe the problem as: “There is a need to develop a theoretically rigorous composite measure that takes higher moments into account.” The use of downside risk measures like the lower partial moment has traditionally been justified as being able to handle the third moment of the distribution, skewness and the fourth moment of the distribution, kurtosis. The method of computation for our metric will therefore be partial moment calculations so that these effects can be properly compensated. In addition to information about the market portfolio and the risk free asset, it requires knowledge on the part of the investor about the return and systematic skewness of a zero systemic risk and nonzero investment opportunity (Ang and Chua [9] ). The Lower Partial Moment (LPM) will handle all below target observations while the Upper Partial Moment (UPM) will handle all above target observations. The beauty of partial moments is that they allow for different targets to be calculated with variations in degrees; highly configurable to multiple constraints and do not require any distributional assumptions.
Partial moments are well integrated into expected utility theory as developed in the literature by Friedman and Savage [10] , Markowitz [11] , Bawa [12] , Fishburn [13] , Fishburn and Kochenberger [14] , Holthausen [15] and Viole and Nawrocki [16] . Finally, Cumova and Nawrocki [17] provide optimization algorithms for UPM-LPM portfolio selection. Partial moments meet all of the requirements for portfolio theory as set out by Markowitz [8] .
The formulas representing the n-degree LPM and q-degree UPM are:
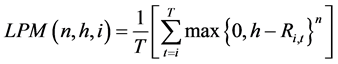 (1)
(1)
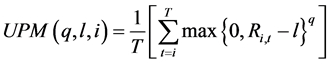 (2)
(2)
where Ri,t represents the returns of the investment i at time t, n is the degree of the LPM, q is the degree of the UPM, h is the target for computing below target returns, and l is the target for computing above target returns3.
Below target analysis alone is akin to only hiring a defensive coordinator. Yes, defense wins championships and is arguably more important to survival than offense which is why our metric allows for the asymmetry of these notions via the degree used in the computations (representative of an investors fear and greed levels). This is an instance where an investor places more weight on below target outcomes rather than on above target outcomes, n > q.
This view was recently expressed by Warren Buffet [18] :
“…Second, though we have lagged the S&P in some years that were positive from the market, we have consistently done better than the S&P in the eleven years during which it delivered negative results. In other words, our defense has been better than our offense, and that’s likely to continue.” (Buffett [18] ).
Diversification is the panacea of risk management techniques. Does it accomplish what it is designed to do, i.e., reduce the non-systemic risk relative to an individual position? Yes. How does it achieve this? Well, the answer may not be as comforting as one would think. The preferred method to reduce non-systemic risk is to add investments with the greatest historical marginal non systemic risk net of systemic risk. Historical analysis has shown that a portfolio of at least 20 stocks will diversify away the non-sys- temic risk. It is essentially fighting fire with fire. This has been quantified by subtracting the systemic benchmark from the total downside risk of the investment as in Equation (3). At this point going forward, we will substitute x for Ri which is the return for an individual investment and y for a benchmark return, Rb which can be a fixed income asset return or a stock market index return such as the CRSP index.
Non-systemic risk is risk that is specific to an asset or a small group of assets net of general market effects. To compute it, first we use a total risk computation such as Equation (1) which uses a target (h) specific to that individual such as the Rf or the individual’s cost of capital. This computation ignores any effects from the market or systemic risk. Non-systemic risk is eliminated through diversification. But, in diversifying, we increase the systemic risk, which is described in the immediate paragraph above. The next part of the equation describes how to remove the systemic risk by subtracting the UPM/LPM of the systemic benchmark (y) from the total risk of the investment (x) using the same target (h) in order to achieve the net non-systemic risk.
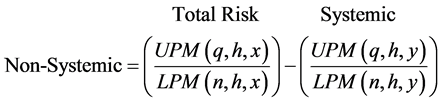 (3)
(3)
To effectively calculate the marginal risk, the same target h must be used for both the investment x and the market benchmark y. We can consolidate this Equation (3) to generate the UPM/LPM for the investment (x) using the systemic benchmark as the target (y) to ascertain how much non-systemic risk an investment has net of the systemic effects, as presented in Equation (4).
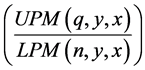 (4)
(4)
This leads to the quandary faced by all risk metrics, what is the systemic benchmark and how does one properly quantify it? This is subjective to say the least and can vary from investor to investor. We are not as brazen as some authors of historical measures and do not purport to have an answer to this. There are certain variables an individual must implement that match their unique composition. A more durable service is to offer a framework capable of being as unique as the individual utilizing it. Our metric also avoids any philosophical inconsistencies by using the same target for gains and losses.
An overwhelming majority of investors use the S&P 500 index as a proxy for systemic risk. While tempting, it is not a complete measure of the asset class thus we cannot implicitly support its use as a proxy for systemic risk for an equity investment. However, the particular topic is beyond the scope of this paper4. For individual security analysis the target is a bit more intricate. A double non-stationary benchmark is used: the asset class benchmark and the risk free rate of return. The greater of the two observations at time t will be the target for that particular period’s partial moment derivation. This will address the aggregate asset class compared to the opportunity cost of investing in the risk free alternative simultaneously. Equation (4) with a double non-stationary conditional target, the asset class benchmark and the risk free rate will capture this allocation consideration.
This ratio answers the question when comparing and ranking multiple investments- What investment historically goes up more than the market when the market goes up and historically loses less when the market loses? That’s great for explanatory historical analysis, but what about future predictive capacity?
“Risk can be greatly reduced by concentrating on only a few holdings.”
Warren Buffett
The intended reduction in non-systemic risk comes with the hefty price of increased exposure to systemic risk. In times of increased entropy or even crisis, cross correlations of securities tend towards 1, effectively rendering the diversification useless and augmenting one’s losses. The axiom was developed “throwing the baby out with the bath water,” noting this very situation. Li’s copula, a formula widely used in analysis to construct CDOs failed due to its ignorance of these dynamic correlations in times of crisis and an underlying assumption of a Gaussian distribution for those correlations5.
So we have maximized our additional non-systemic risk based off of our explanatory model. Now we have to deal with the dormant beast: systemic risk. Autocorrelation/ dependence/serial correlation (ρ(x)) is an important tool in identifying increasing distributional risks such as muted entropic environments and lending a predictive ability to an explanatory metric. When investing in a fund, the autocorrelation is quite useful in picking up on discretionary marks used by the manager in illiquid securities with the attempt to smooth out returns, unmasking the layer of uncertainty presented to the investor. The predictive ability is crucial to avoiding ensuing bifurcation disruptions which are not as exogenous or infrequent as one would assume. Benoit Mandelbrot6 coined the term “Joseph Effect”, alluding to the Old Testament story of seven years feast fol- lowed by seven years of famine for Egypt. While a mathematician’s experimental prob- ability model would suggest year eight should be of equal or greater feast to year seven, the observed autocorrelation incorporated into our model will sound alarm bells well before. The autocorrelation formula for a 1 period lag is for investment x at time t is:
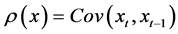 (5)
(5)
Taking the absolute value…
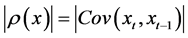 (6)
(6)
The absolute value is used because an autocorrelation of −1 or 1 is equally dangerous to investors. In the −1 instance the mean from the target would be zero for a period of observed autocorrelation of −1 and there would be an equally likely series of above or below target results, a true guess
A 1 period lag is used because we aim to err on the side of caution. Where there’s smoke there’s fire. If a 10 period lag presents autocorrelation, it will obviously be noticed in the 1 period prior. The risk is that between lag differences, a bifurcation abruptly ceases thus leaving the investor waiting for a confirmation to avoid the very event that has just transpired, effectively rendering this metric explanatory. Russell Ackoff [20] was famous for noting that, “it is better to do the right thing wrong than to do the wrong thing right.” We agree and in the instance of acting on a false positive due to the short lag, c’est la vie, fungibility assures the ability to reapply those funds. The other consideration with autocorrelation is the number of observations to calculate over for a predictive measure. There is a subjective interpretation as to the subset of periods of autocorrelation analyzed. A smaller subset will yield more frequent transactions and monitoring, whereby a longer subset of data will yield smaller observed measurements and an increased risk of bifurcation exposure. We do not have any insight into the individual’s ability to monitor and transact nor their desire to do so. As with the benchmark, this discretionary input is left entirely up to the individual investor. Another input that needs to be derived is the period of analysis for an investment’s distribution in computing the metric. This is not subjective. When investing in a fund or a manager, always utilize the data since inception. This is critical in ascertaining the manager’s reward to risk profile. Since returns are not stationary, using a discrete sample of a continuous process will foolishly ignore the non-stationary effects for manager evaluation.
“A more difficult decision for us was how to measure the progress of Berkshire versus the S&P. There are good arguments for simply using the change in our stock price. Over an extended period of time, in fact, this is the best test. But year-to-year market prices can be extraordinarily erratic. Even evaluations covering as long as a decade can be distorted by foolishly high or low prices at the beginning or end of the measurement period.” (Buffett [18] ).
When evaluating an individual security, a more complete analysis as shown in Figure 1, reveals that means, variances and other metrics do not stabilize towards the population value until there are at least 100 observations.

Figure 1. Graph illustrating the number of sample size observations for mean, standard deviation, and semideviation to stabilize around a population value assuming a normal distribution with a population mean of 9% and a population standard deviation of 20%.
Similar to a “bubble” or parabolic move7, an observed 1 autocorrelation reading denotes a dubious situation. The increased autocorrelation influence can be subtracted from itself to compensate for an increased likelihood of an unstable investment, thus lowering the metric to reflect this probable risk. Bubbles are good until they burst. George Soros explains that bubbles and his participation in them are what provided him with his vast wealth8. The trick is knowing when to exit prior to the bubble bursting. Equation (7) is our predictive metric using the autocorrelation coefficient.
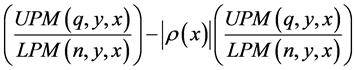 (7)
(7)
An example may help illustrate the goal of the predictive element. If you enter an investment based on its historical explanatory risk metric of 100 shares and its autocorrelation is zero then you retain your 100 shares. Say the investment performs well and its autocorrelation reaches 0.5. The metric will have decreased by 0.5, forcing you to cut your holdings by 50% to match the potential risks the autocorrelation is measuring. Say the investment skyrockets and the next period of review for your investment, you find that the autocorrelation is now 1. This would yield a result of zero to the predictive metric suggesting you sell your remaining shares. It is not intended to pick an inflection point (since one never knows the top until after they have seen it), but the translation to deltas onto your position will properly manage anticipated risks. The ranking of their investments based on the predictive metric is another means an investor can transact on the autocorrelation concerns. In the preceding example, if an investment’s metric is cut by half upon the investor’s first review, then replacing the investment with a senior ranked investment is a viable interpretation of the data.
Unfortunately the inverse does not hold for negative autocorrelation. While the “bubble” example above will protect profits, entering a position based on the negative autocorrelation will be akin to the “catching a falling knife” axiom. This metric avoids this as well as the pitfalls of irrationality. Keynes9 famously noted, “The market can stay irrational longer than you can stay solvent” and since our metric does not predict an inflection point, let it stay irrational. In essence it’s a long only strategy with the entry at zero autocorrelation and the full exit at absolute value 1.
The dynamic positioning example also highlights an important shortcoming of passive investing. Coupled with diversification (which we have just explained tends to have the inverse effect when one really needs it), buying and holding a diverse portfolio has been preached ad nauseam as a means of mitigating risk. In a 1991 journal piece, William Sharpe [22] provides us a definition of passive investing. Sharpe presents his thesis in a very Friedman like manner whereby his underlying assumptions do not stand up to detailed investigation and lead us to question the very notion of passive investing.
To summarize, our explanatory and predictive measures are as follows:
EXPLANATORY PREDICTIVE
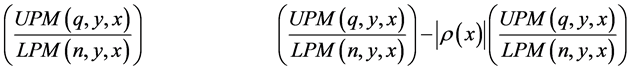
4. Empirical Results
Our empirical test generates rank correlations between the performance measures and asset returns for both an explanatory period and an out-of-sample predictive period. On balance, we were able to generate minimal explanatory correlations with no out-of- sample predictive correlations using the explanatory model and no explanatory correlations with significant out-of-sample correlations when using the predictive model. MPT metrics similarly offered sparse explanatory and predictive correlations. Our security universe consisted of approximately 300 surviving S&P 500 companies for three 11-year periods: January 1978-January 1989; January 1988-January 1999; and January 1998-January 2009. Each period represents different economic conditions but all three are difficult market periods. Figures 2-4 graphically portray the S&P 500 performance for each of our three periods to highlight what we are trying to predict and the associated subset utilized to accomplish that goal. Figures 2-4 demonstrate both a one year and a two year out-of-sample period.
Table 1 and Table 2 present the results for the first period 1978-1989 for one and two year holding periods. Table 3 and Table 4 present the results for the second period 1988-1999 while Table 5 and Table 6 present the results for 1998-2009. We generated four rank correlations for these periods. First is the correlation between the mean return for the explanatory period and the performance metric derived from the explanatory period. The second correlation is between the mean return for the holding period and the explanatory period’s performance metric. This is one correlation where any ex ante efficiency would be observed. The third correlation is the Rho adjusted explanatory UPM/LPM metric derived in Equation (7) correlated to the mean return for the explanatory period10. The fourth correlation is again the Rho adjusted explanatory
UPM/LPM metric correlated against the holding period mean return. This correlation is where we would expect the significant ex ante efficiency. The asset class benchmark used in our explanatory and predictive metric is the CRSP market cap index which we use to proxy systemic risk. It is used in the double non-stationary conditional benchmark along with the non-stationary 3-month Treasury Bill rate for individual equities.
In the following tables (Tables 1-6), we present four different classifications of investor types and their associated risk profiles: Risk Averse, whereby the gain sensitivity exponent q will be less than the loss sensitivity exponent n, (q: n = 0.25); Prospect Theory, (q: n = 0.44)11; Risk Neutral (q: n = 1); and Risk Seeking (q: n = 2). With the

Figure 2. Period 1 S&P 500 performance with our explanatory and predictive periods identified.

Figure 3. Period 2 S&P 500 performance with our explanatory and predictive periods identified. Inverse ex ante correlations were present, reflecting Rho’s defensive influence 14 months prior to the Nasdaq implosion.
exception of Prospect Theory and Risk Neutral, these ratios are by no means stationary. Individuals can and do alter their risk profile which leads to the creation of a sum over histories for personal utility. For brevity, we increase the loss sensitivity exponent n by 1 in each classification to illustrate the heightened sensitivities within each classification.
The more sensitive the investor (an increased loss sensitivity exponent n or gain sensitivity exponent q), the greater correlations of our predictive metric with out-of-sam- ple rankings for one and two year holding periods. Two year holding periods also provide the most significant ex ante correlations, likely due to the systemic events present in each period. In period 1, the Crash of ’87 was in the two year holding period. In period 2, the Asian Financial Crisis/Russian Debt Crisis was in the two year holding period. Period 2 was also the only to end at its highs for the sample period, as if the systemic event were truly just a blip. Our period 2 ex ante correlations began exhibiting inverse significant results 14 months prior to the peak of the Nasdaq for both 1 and 2 year holding periods. Upon consideration, we could not be more pleased with this as

Figure 4. Period 3 S&P 500 performance with our explanatory and predictive periods identified.
the Rho present in the obvious bubble was accurately being reflected in our predictive metric, prior to its bursting. This unique “mid bubble” data set fully supported equation 7’s goal, to avoid bifurcations (in this instance a 78% decline from March 2000 through September 2002).
Finally, in period 3 the 2007-2009 Financial Crisis was accounted for in that two year holding period. It should be mentioned that the explanatory subset of period 3 data contains the bursting of the Nasdaq bubble, which on a percentage basis dwarfs all other systemic events in our study to which all explanatory metrics had the equal opportunity to absorb and account for.
Explanatory MPT/PMPT metrics did offer a universal conclusion-they offered no statistically significant correlations during the holding period (with the exception of the R/V ratio in the one year holding in period 1). During the explanatory period, the results varied from period to period, and MPT/PMPT measure to MPT/PMPT measure.
In Period 1 (January 1978-January 1989, Table 1 and Table 2), 1 year holding period, we see some predictive correlations for the risk neutral and risk averse UPM/LPM measures. With the 2 year holding period, the predictive UPM/LPM model has very

Table 1. Pearson rank correlation results for various performance measures January 1978 - January 1989. 258 companies with holding period February 1988 to January 1989―One Year.
Mean hist-correlation between historic performance measure and historic mean return. *10% significance; mean hold-correlation between historic performance measure and holding mean return. **5% significance; urho hist-correlation between historic UPM/LPM adjusted for rho and historic mean return. ***1% significance; urho hold-correlation between historic UPM/LPM adjusted for rho and holding mean return. ****0.1% significance.
Table 2. Pearson rank correlation results for various performance measures January 1978 to January 1989. 258 Companies with holding period February 1987 to January 1989―two years.
Mean hist-correlation between historic performance measure and historic mean return. *10% significance; mean hold-correlation between historic performance measure and holding mean return. **5% significance; urho hist-correlation between historic UPM/LPM adjusted for rho and historic mean return. ***1% significance; urho hold-correlation between historic UPM/LPM adjusted for rho and holding mean return. ****0.1% significance.
Table 3. Pearson rank correlation results for various performance measures January 1988 to January 1999. 314 companies with holding period February 1998 to January 1999―one year.
Mean hist-correlation between historic performance measure and historic mean return. *10% significance; mean hold-correlation between historic performance measure and holding mean return. **5% significance; urho hist-correlation between historic UPM/LPM adjusted for Rho and historic mean return. ***1% significance; urho hold-correlation between historic UPM/LPM adjusted for rho and holding mean return. ****0.1% significance.
Table 4. Pearson rank correlation results for various performance measures January 1988 to January 1999. 314 companies with holding period February 1997 to January 1999―two years.
Mean hist-correlation between historic performance measure and historic mean return. *10% significance; mean hold-correlation between historic performance measure and holding mean return. **5% significance; urho hist-correlation between historic UPM/LPM adjusted for rho and historic mean return. ***1% significance; urho hold-correlation between historic UPM/LPM adjusted for rho and holding mean return. ****0.1% significance.
Table 5. Pearson rank correlation results for various performance measures January 1998 to January 2009. 293 companies with holding period February 2008 to January 2009―one year.
Mean hist-correlation between historic performance measure and historic mean return. *10% significance; mean hold-correlation between historic performance measure and holding mean return. **5% significance; urho hist-correlation between historic UPM/LPM adjusted for rho and historic mean return. ***1% significance; urho hold-correlation between historic UPM/LPM adjusted for rho and holding mean return. ****0.1% significance.
Table 6. Pearson rank correlation results for various performance measures January 1998 to January 2009. 293 Companies with holding period February 2007 to January 2009―two years.
Mean hist-correlation between historic performance measure and historic mean return. *10% significance; mean hold-correlation between historic performance measure and holding mean return. **5% significance; urho hist-correlation between historic UPM/LPM adjusted for rho and historic mean return. ***1% significance; urho hold-correlation between historic UPM/LPM adjusted for rho and holding mean return. ****0.1% significance.
strong predictive power throughout all UPM/LPM measures. At the same time, none of the measures were very explanatory.
In Period 2 (January 1988-January 1998, Table 3 and Table 4), 1 year holding period, we see some scattered predictive and almost no explanation. With the 2 year holding period, the predictive UPM/LPM had significant correlations for the risk seeking and risk averse UPM/LPM measures.
In Period 3 (January 1998-January 2009, Table 5 and Table 6), 1 year holding period, we see our explanatory UPM/LPM measures has some bright spots, but the major significance is with our predictive UPM/LPM model working with the out-of-sample holding period. All of the utility functions represented in our UPM/LPM models had significant predictive power for the one year holding period. This result is repeated for the two year holding period with all of the predictive UPM/LPM models showing significant predictive power for the holding period.
As an important note to our results, the inconsistency of our predictive metric throughout all degree values is actually a major differentiation between our metric and the MPT/PMPT offerings. If we were philosophically aligned with the MPT/PMPT one-size-fits-all efficient frontier, then the inconsistency would be a concern. However, we are not; we offer a framework. It is up to the individual investor to categorize themselves with their own characteristics. Classifications of those characteristics are then presented in our results. Therefore, it should not be universal or consistent across values as each investor is not homogenous. Example, in some periods a risk seeking investor may benefit more than their risk averse counterpart. In fact, we need to divorce the notion of a global optimum efficient frontier and replace it with an individual efficient frontier that is as non-stationary as the individual utilizing the metric and may in fact look completely different than the concavity preached for decades.
5. Conclusions
Edward Thorp [24] , the famed MIT professor who penned “Beat the Dealer” in 1962 picked up on the relationship between observed and expected volatility. Assigning a positive count to a small card dealt to the table reflected the larger remaining high cards that would lead to an increased probability of a dealer bust. Not saying the next hand or the hand following that, but over the remaining hands dealt this probability would be observed. He was right, and in the process got himself banned from every casino imaginable while forcing the industry to make it exponentially harder to spot this inevitable truth. And if you can do it now, they still throw you out.
Madoff, LTCM, Bayou, Matador funds were all able to raise large sums of money under the guise that they could contain volatility while effectively disregarding the underlying Brownian forces. The continued prevalence of these metrics and indeed the financial crisis itself is a testament to the fact that this painful lesson, repeated time and again, has not been learned. Risk is not bad. In fact, it is necessary for growth. Russell Ackoff [20] also notes that your best learning is to learn from doing the right thing wrong, otherwise you already know how to do it. With over four decades of learning, one would think that by now, risk managers should be the smartest guys in the room.
The investment industry does its best to warn us, have you ever heard or noticed in print, “Past performance is not indicative of future results?” With the misapplication of explanatory metrics leading to the creation of ex post efficient portfolios, it doesn’t appear many have heeded this prominent warning in their generation of ex ante portfolios. Our use of statistical certainty (ρ) as a punitive variable in quantifying risk humbles the methodology in so far as admitting we are beholden to a Knightian uncertain future12.
Cite this paper
Viole, F. and Nawrocki, D. (2016) Predicting Risk/Return Performance Using Upper Partial Moment/ Lower Partial Moment Metrics. Journal of Mathematical Finance, 6, 900-920. http://dx.doi.org/10.4236/jmf.2016.65060
References
- 1. Lopes, L.L. and Oden, G.C. (1999) The Role of Aspiration Level in Risk Choice: A Comparison of Cumulative Prospect Theory and SP/A Theory. Journal of Mathematical Psychology, 43, 286-313.
http://dx.doi.org/10.1006/jmps.1999.1259 - 2. Pete, S. and Kasten, G.W. (2005) Post-Modern Portfolio Theory. Journal of Financial Planning, 18, 74-85.
- 3. Friedman, M. (1953) Essays in Positive Economics. University of Chicago Press, Chicago.
- 4. Simon, H. (1963) Problems of Methodology—Discussion. The American Economic Review, 53, 229-231.
- 5. Beinhocker, E. (2006) The Origin of Wealth. Harvard Business School Press, Boston.
- 6. Saunders, A., Ward, C. and Woodward, R. (1980) Stochastic Dominance and the Performance of UK Unit Trusts. The Journal of Financial and Quantitative Analysis, 15, 323-330.
http://dx.doi.org/10.2307/2330348 - 7. Tee, K.-H. (2009) The Effect of Downside Risk Reduction on UK Equity Portfolios Included with Managed Futures Funds. International Review of Financial Analysis, 18, 303-310.
http://dx.doi.org/10.1016/j.irfa.2009.09.007 - 8. Markowitz, H.M. (2010) Portfolio Theory: As I Still See It. Annual Review of Financial Economics, 2, 1-23.
http://dx.doi.org/10.1146/annurev-financial-011110-134602 - 9. Ang, J. and Chua, J. (1979) Composite Measure for the Evaluation of Investment Performance. The Journal of Financial and Quantitative Analysis, 14, 361-384.
http://dx.doi.org/10.2307/2330509 - 10. Friedman, M. and Savage, L.J. (1948) The Utility Analysis of Choices Involving Risk. Journal of Political Economy, 56, 279-304.
http://dx.doi.org/10.1086/256692 - 11. Markowitz, H.M. (1952) The Utility of Wealth. The Journal of Political Economy, 60, 151-158.
http://dx.doi.org/10.1086/257177 - 12. Bawa, V.S. (1975) Optimal Rules for Ordering Uncertain Prospects. Journal of Financial Economics, 2, 95-121.
http://dx.doi.org/10.1016/0304-405X(75)90025-2 - 13. Fishburn, P.C. (1977) Mean-Risk Analysis with Risk Associated with Below-Target Returns. The American Economic Review, 67, 116-126.
- 14. Fishburn, P.C. and Kochenberger, G.A. (1979) Two-Piece Von Neumann-Morgenstern Utility Functions. Decision Sciences, 10, 503-518.
http://dx.doi.org/10.1111/j.1540-5915.1979.tb00043.x - 15. Holthausen, D.M. (1981) A Risk-Return Model with Risk and Return Measured as Deviations from a Target Return. The American Economic Review, 71, 182-188.
- 16. Viole, F. and Nawrocki, D. (2011) The Utility of Wealth in an Upper and Lower Partial Moment Fabric. The Journal of Investing, 20, 58-85.
http://dx.doi.org/10.3905/joi.2011.20.2.058 - 17. Cumova, D. and Nawrocki, D. (2014) Portfolio Optimization in an Upside Potential and Downside Risk Framework. Journal of Economics and Business, 71, 68-89.
http://dx.doi.org/10.1016/j.jeconbus.2013.08.001 - 18. Buffett, W. (2010) Chairman’s Letter to the Shareholders. Berkshire Hathaway 2009 Annual Report, 3-27.
- 19. Mandelbrot, B. and Hudson, R., (2004) The (Mis)Behavior of Markets: A Fractal View of Risk, Ruin, and Reward. Basic Books, Cambridge.
- 20. Ackoff, R. (1999) Ackoff’s Best: His Classic Writings on Management. John Wiley and Sons, Hoboken.
- 21. Keynes, J.M. (1936) The General Theory of Employment, Interest and Money. Macmillan Cambridge University Press, Cambridge.
- 22. Sharpe, W.F. (1991) The Arithmetic of Active Management. Financial Analysts Journal, 47, 7-9.
http://dx.doi.org/10.2469/faj.v47.n1.7 - 23. Kahneman, D. and Tversky, A. (1979) Prospect Theory: An Analysis of Decision under Risk. Econometrica, 47, 263-291.
http://dx.doi.org/10.2307/1914185 - 24. Thorp, E.O. (2016) Beat the Dealer: A Winning Strategy for the Game of Twenty-One. Edward Thorp Publication, New York.
https://books.google.com/books?id=tx9I0vK9xQoC&pg=PP5&lpg=PP5&dq=ISBN+0-394-70310-3&source=bl&ots=VBRJY5uXZO&sig= YuTC1D2GlMp0O7HIWyDEUWKU03k&hl=en&sa=X&ved=0ahUKEwirtdm2-aXQAhWi4 IMKHXOyCocQ6AEIKTAD#v=onepage&q=ISBN%200-394-70310-3&f=false - 25. Knight, F.H. (1921) Risk, Uncertainty, and Profit. Hart, Schaffner, and Marx Prize Essays, No. 31. Houghton Mifflin, Boston and New York.
https://msu.edu/~emmettr/fhk/rup.htm
Appendix A
Survivorship/Systemic Biases
The first priority of any continuous system is survival. We actually want this bias present in our data because we are analyzing the characteristics of the survivors. Firms close for a myriad of reasons outside of actual performance statistics, so to include them quantitatively would not portray an accurate distinction of survivors and failures.
If anything, the survivorship bias in our study would pad the performance of the explanatory metrics generating higher ex post rank correlations. However, this does not offer an acceptable counterpoint to why these metrics completely fail out-of-sample regardless of the systemic event.
Furthermore, these biases have assisted in creating a far more granular explanation of the characteristics of successful investments; however, they are only explanations and not predictions. The error lies not in the bias, but in the extrapolation of the explanations.
NOTES

1Saunders, Ward and Woodward [6] .
2http://en.wikipedia.org/wiki/Value_at_risk.

3For the purposes of this paper, we will assume h = l for the remainder of the paper. We will use h to compute the UPM as well as the LPM.

4We do try to improve on this issue by using the CRSP market cap weighted index that includes all stocks from all three major U.S. markets: NYSE, AMEX, and NASDAQ.
5https://www.wired.com/2009/02/wp-quant/?currentPage=all.
6Mandelbrot and Hudson [19] .

7Y = x2 is a parabolic function with 1 autocorrelation reading.
8http://www.youtube.com/watch?v=MUEGC4btm64.

9Keynes [21] .

10Rho was calculated off the entire explanatory period, not the varying periods as presented in the dynamic positioning example. A different transactional study is required.
11Kahneman and Tversky [23] .

12Knight [25] .