Psychology
Vol.08 No.03(2017), Article ID:74392,14 pages
10.4236/psych.2017.83029
Encoding Factors Affecting Context Effects on Memory: Congruency, Attention and Exposure Time
Shiri Schonbach-Medina, Eli Vakil*
Department of Psychology, Leslie and Susan Gonda (Goldschmied) Multidisciplinary Brain Research Center, Bar-Ilan University, Ramat-Gan, Israel

Copyright © 2017 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: December 9, 2016; Accepted: February 24, 2017; Published: February 27, 2017
ABSTRACT
The aim of the current study was to examine the effects of three factors on the emergence of context effects (CEs). The basic assumption was that the way Target and Context words are initially encoded affects their impact on recognition CE. The strength of the memory depends on many factors, including the amount of attention allocated to target and context stimuli when memorizing the information and whether the participants were distracted. The interaction and relationships between these different factors were examined in the present study. First is Congruency between target and context words in terms of the gender of the nouns presented. Second is Attention allocated to the stimuli, whether equal attention so that both are considered targets (T-T) or differential attention allocation so that one is the target and the other is context (T-C). Third is Exposure time of 300 vs. 3000 msec. We hypothesized that CE would be stronger under the T-T vs. T-C attention condition, congruent vs. incongruent learning conditions and short vs. long exposure time. One-hundred and fifteen individuals participated in this study. They were randomly assigned to one of the two Exposure time conditions. Half of the word-pairs were congruent and half were incongruent. Short exposure time in the Congruent T-T condition was associated with CE in terms of hit rates, but not false alarms, with no CE in the incongruent pairs. As predicted, lengthening exposure time reduced CE in terms of hit rates, and congruent relations were associated with greater CE in terms of false alarms, with no influence of encoding type.
Keywords:
Context Effect, Recognition, Congruency Effect, Exposure Time, Attention

1. Introduction
Superior recall or recognition of consistent versus changing context between learning and test phases is referred to as Context Effect (CE) (Memon & Bruce, 1985; Vakil, Raz, & Levy, 2007) . The encoding specificity principle provides a framework for understanding how the conditions while encoding information are related to retrieval of that information (Tulving & Thomson, 1973) . According to this principle, CE upon recall is most effective when the conditions at the time of encoding match the conditions at the time of retrieval. These conditions may refer to the context in which the information was encoded, the physical location, the surroundings, or the participant’s state at the time of encoding.
CE was demonstrated in laboratory conditions with a wide range of stimuli such as word lists (McKenzie & Tiberghien, 2004) , pictures of faces (Dalton, 1993; Winograd & Rivers-Bulkeley, 1977) , pictures of objects (Levy, Rabinyan, & Vakil, 2008) , and pictures of faces and hats (Vakil et al., 2007) . As in many domains of cognition, the effects of context on memory are ubiquitous and pervasive. Though context effects on free and cued recall are generally robust, findings regarding context effects on recognition have been widely divergent. Therefore, several studies have attempted to identify the factors that mediate emergence of CE in recognition (e.g., Bloch & Vakil, 2016; Smith & Vela, 2001 ).
The basic assumption was that CE in recognition is an inconsistent phenomenon because it is dependent on various factors. The present study focused on how Target and Context words are encoded and predicted that these encoding conditions would affect recognition CE. The amount of attention allocated to target and context stimuli during encoding and the relationship between the target and context stimuli that were paired together were assumed to affect whe- ther context stimuli would be encoded or ignored, resulting in increased or decreased recognition CE later on.
Studies of semantic priming have shown that participants respond faster to a target word (e.g., bread) when presented after a related prime word (e.g., butter), compared to when presented after an unrelated prime (e.g., doctor) (Meyer & Schvaneveldt, 1971; Neely, 1991; McNamara, 2005) . Typically, pronunciation or lexical decision tasks were used in studies of semantic priming. However, no experiments were performed using different encoding conditions to test how encoding relations between target and context affect recognition CE. Furthermore, in the present study Target-Target pairs and Target-Context pairs were presented simultaneously, and not as a priming paradigm.
Three factors at the encoding phase have been already shown to modulate CE:
Congruency between target and context, Exposure time, and the differential Attention allocated to the target versus the context stimuli. Although previous studies tested the effect of each one of these factors on CE separately, the goal of the present study is to investigate the interactive effect of these factors on CE in recognition. All three factors affect attention to the stimuli presented in different ways. The nature of the stimuli is assumed to affect attention implicitly when congruency is manipulated. Time exposure allows more or less time for the participant to attend to the stimuli, and the last factor is actually explicitly controlling attention to each one of the stimuli.
The first factor, Congruency between target and context stimuli, is expected to affect the amount of attention allocated to each stimulus. Same-gender nouns (Hebrew nouns have genders) will be considered congruent stimuli while different-gender words will be the incongruent stimuli. Bein et al. (2015) provided evidence that supports the elaboration-integration account and shows that congruency is a function of semantic relatedness between item and context words. The researchers conducted four experiments. Participants were exposed to word-pairs that appeared simultaneously, with the target word appearing above the context word. They were asked to indicate whether the two words are congruent or incongruent in their meaning. During the recognition test, target words were presented again, but this time they appeared alone on the screen. The researchers divided the mnemonic advantage of congruent items into two constituent elements: memory for target item only (“know” response) and the ability to recall the context word itself (“remember” response). Bein et al. (2015) showed that reinstatement of the encoding context at the test phase better facilitated memory of congruent items than incongruent items. However, altering the encoding context during retrieval hindered memory of congruent items more than memory of incongruent items, thus reinforcing the view that components of congruent stimuli are better integrated than those of incongruent stimuli.
They explain Craik and Tulving’s integration-elaboration hypothesis (Craik & Tulving, 1975) , which postulates that the target items “integrate” more easily with congruent contexts than with incongruent ones. Thus, in the congruent condition, the context is more elaborated in the target encoding process. These more elaborate traces are, thereafter, assumed to be more easily accessed during retrieval.
The paradigm in the current study differs from that of Bein et al. (2015) herecongruency between target and context words is not semantic but rather requires shallow processing by judging the congruency of the gender type of the two stimuli presented. In addition, congruency was tested here in order to examine its effect on CE rather than examining its effect on memory for the target or context stimuli per se. We predicted that if indeed congruency between contexts and targets increases the binding between them at encoding, then CE will be better facilitated under the congruent condition than under the incongruent one. We hypothesized that incongruent contexts (differing in gender category from the target) would be less related to target words than congruent contexts.
The second factor is Exposure time of the stimuli at the encoding phase. In an attempt to explore the underlying processes of CE, researchers explored which conditions enhance or weaken CE. Smith and Vela (2001) discuss the environmental context and propose that the “overshadowing principle” explains why CE does not reliably emerge during recognition tasks. According to this principal, when participants engage in conceptual processing during learning in order to deeply process target information, little or no encoding of the environmental contextoccurs. In other words, participants do not notice background environmental context because they are focused on processing the target. Therefore according to this principle, CE is expected to weaken under conditions in which deep-processing of target stimuli occurs at the encoding phase. They further propose that longer stimulus exposure time increases the amount of processing devoted to each stimulus, thereby leading to more stable memories. This decreases dependency on context information in order to aid memory recognition and reduces CE as a result.
In fact, the overshadowing principle specifies the conditions under which CE emerges in terms of the relative strength at which item vs. context cues were encoded. The strength of item cues was found to increase in correlation with the length of study time. Therefore, the item cues are more likely to overshadow the context cues. Accordingly, the overshadowing principle predicts that the probability of CE will decrease with longer study time. Isarida et al. (2012) clearly confirmed these predictions in two empirical experiments. Significant CEs were found in the short study-time condition (1500 milliseconds) but not in the long study-time experiment (4000 milliseconds). Our findings support this notion.
In the present study it was assumed that longer exposure time allows participants to over-learn targets so that they become less dependent on contextual cues.
The third factor is the differential Attention allocated explicitly to the target versus the context stimuli at the encoding phase. Johnston and Dark (1986) compared focus of attention to a beam that is characterized by a specific size that can vary according to task demands (see also: LaBerge, 1983; Umilta, 1988 ). Under the target-target (T-T) condition, participants were instructed to pay equal attention to the two stimuli presented each time. This can be viewed as a typical paired associate learning word (see also Duncan, 1980; Jonides, 1983 ). In contrast, under the target-context (T-C) condition participant were instructed to focus only on one of the two stimuli presented, i.e. the target stimulus. In the present study the assumption was that if CE is dependent on the relative attention directed towards the context word then the T-T encoding condition would result in greater CE as compared with the T-C encoding condition. It is hypothesized that stronger binding is formed between the stimuli under the T-T condition and therefore recognition would be more context dependent. In other words, CE would be more pronounced under the T-T than the T-C learning condition.
2. Method
2.1. Participants
One-hundred and fifteen undergraduate students volunteered to take part in the experiment. Participants were randomly assigned to one of the two exposure- time conditions. Sixty-six participants were assigned to the short-exposure condition and forty-nine participants were assigned to the long-exposure one. This division formed two equal groups consisting of 58 participants in the T-T condition and 57 in the T-C condition, as will be shown. The group in the short-ex- posure condition consisted of 31 males and 35 females, with an average age of 23.19 years, SD = 2.93. The group in the long-exposure condition consisted of 25 males and 24 females, with an average age of 23.95 years, SD = 2.83. In the short-exposure condition 33 participants were randomly assigned to the T-T condition and 33 participants were assigned to the T-C condition. In the long- exposure condition 25 participants were randomly assigned to the T-T condition and 24 participants were assigned to the T-C condition. All participants had normal or corrected vision. All were native Hebrew speakers. Written informed consent was obtained from all participants for a protocol approved by the Bar Ilan University Institutional Review Board.
2.2. Tasks and Procedure
Participants were tested individually in two consecutive task phases. Participants performed the encoding task followed by the recognition task. In the encoding task, participants were exposed to pairs of words for 300 milliseconds in the short exposure condition or for 3000 milliseconds in the long exposure condition, while applying either the T-T or T-C condition. Operationally, the Attention conditions were manipulated by the timing of an arrow indicating the position of the target word to be judged. Namely, in the T-C condition participants were aware of the position of the target word to be judged in advance, before the word-pair appeared, namely, the target was indicated by an arrow above its location. The arrow appeared 600 milliseconds before each pair of words was displayed. Showing the arrow for this time-interval before or after viewing the word-pairs was shown by Klauer and Musch (2001) to be sufficient to drawselective visual attention to the target by attracting attention to the arrow. The arrow appeared above the location of the upcoming target for 300 milliseconds and disappeared 300 milliseconds before the pairs were shown. This manipulation is assumed to cause differential allocation of attention to the stimuli, yielding the T-C condition. In the T-T condition, an arrow appeared 300 milliseconds after the pairs had disappeared from screen. The arrow appeared for 300 milliseconds above the location where the defined target had appeared beforehand. Thus in the T-T condition, no indication was given regarding which word in the pair was the target and which was the context word until the word-pair had disappeared and the indicating arrow appeared. This manipulation is assumed to lead to equal allocation of attention to the two stimuli, yielding the T-T condition.
The 50 nouns used for the word-pairs were selected from a set of 100 words tested in a pre-test. Thirty students ranked those words according to their frequency of use and also ranked their gender identity, i.e. the degree to which they represent masculine or feminine identity. In addition, reaction time for judging the gender type of each word was measured. Words were dropped from the list if the time required to judge them was significantly higher than the mean reaction time. Only four to seven-letter words were chosen.
The list of word-pairs in the encoding task consisted of 32 target-context pairs. Four pairs were used for the training phase. Half of the pairs of target and context words were congruent in gender identity and half were not. Both words were displayed in black bold Arial font size 48. The distance between the two words was 4 cm. Participants performed the recognition task immediately after the encoding task. All pairs were counterbalanced for congruency of gender. The attention condition within-subjects remained consistent between the attention and recognition tasks.
Four types of target-context pairs were manipulated in the recognition task. Sixty-four word-pairs were combined as stimuli for the recognition task. Sixteen old, original pairs were taken from the list of pairs from the encoding task; 32 mixed pairs consisting of 16 old targets paired with new contexts and 16 old contexts paired with new targets; and finally, 16 foils or new pairs consisting of new targets paired with new context words.
2.3. Learning Task
The SuperLab program (Cedrus, Inc.) was used to randomly display word-pairs at the center of the computer screen. Participants were randomly assigned to one of the two encoding condition groups (T-CorT-T). The location of targets and contexts was counterbalanced in right or left positions and was randomly selected in both the T-C and T-T conditions. Specifically, in half of the pairs, the indicating arrow appeared above the left word informing participants that this was the target word to be judged, and in the other half of the pairs the indicating arrow appeared above the right word, informing participants that the word on the right was the target word to be judged (in the T-C condition the arrow appeared before the presentation of each word-pair and in the T-T condition the arrow appeared after the presentation of each word-pair). Participants were given the following instructions: “You will be shown pairs of nouns. Judge as precisely and as quickly as you can whether the word is masculine or feminine.” Participants were asked to indicate their decision by pressing either “p” or “q” on the keyboard for “masculine” or “feminine” respectively. Participants’ responses were recorded using the SuperLab program which also recorded response times.
The use of each of the two keys was counterbalanced between “masculine” and “feminine” answers. Four pairs were presented to train participants for the encoding task. In the encoding task itself, 32 word-pairs were judged. Participants were asked to judge whether the target, word in each pair was feminine or masculine. The second word in each pair, for which no instruction was given, is referred to as the context-word. Pairs were congruent or incongruent in gender type.
2.4. Recognition Task
Immediately after performing the encoding task, each participant was presented with the recognition task. The encoding task was used as a study phase for the recognition task. Word-pairs for the recognition task were presented in the same way that they were presented for the encoding task. Exposure-time condition was kept consistent between encoding task and recognition task for the same participants. The position of the pre-stimulus or post-stimulus arrow remained the same as in the encoding phase.
In addition, a target word remained a target word in both tasks (and same for context words), meaning that the indicating arrows did not change their position for each word-pair. Recognition of the context word paired with the target was never required, meaning that the target in the encoding task was always the target in the recognition task for intact pairs.
Participants were instructed as follows: “Please press the ‘yes’ key if the word that the arrow points to is one that you have seen before. Press the ‘no’ key if it is a new word”. The two possible answers (“yes” and “no”) were randomly assigned to participants as “p” or “q” keys on the keyboard. Participants’ responses were recorded using the SuperLab program, which also recorded response times.
Four trial pairs were presented, followed by a recognition task consisting of 64 pairs. Original old, mixed and new pairs were randomly presented in this task. Recognition performance for targets was measured by comparing recognition of targets when paired with old vs. new contexts.
3. Results
Performance accuracy on the recognition task reflected by the hit rate and false alarms were analyzed. A 2 × 2 × 2 mixed design ANOVA with repeated measures was conducted in order to examine the effect of three variables on recognition: Attention (T-C condition vs. T-T condition), Congruency of pairs (congruent vs. incongruent) and Context type (old vs. new). The Attention variable was manipulated as a between-subject factor in order to avoid possible intervening factors that might have confused participants if exposed to both T-T and T-C conditions. Congruency and Context type were manipulated as within- subject factors in order to examine their differential effect on within-partici- pant performance. Analyses were performed separately for the short exposure condition and for the long exposure condition. This was done in order to avoid four way analyses.
3.1. Short Exposure Time
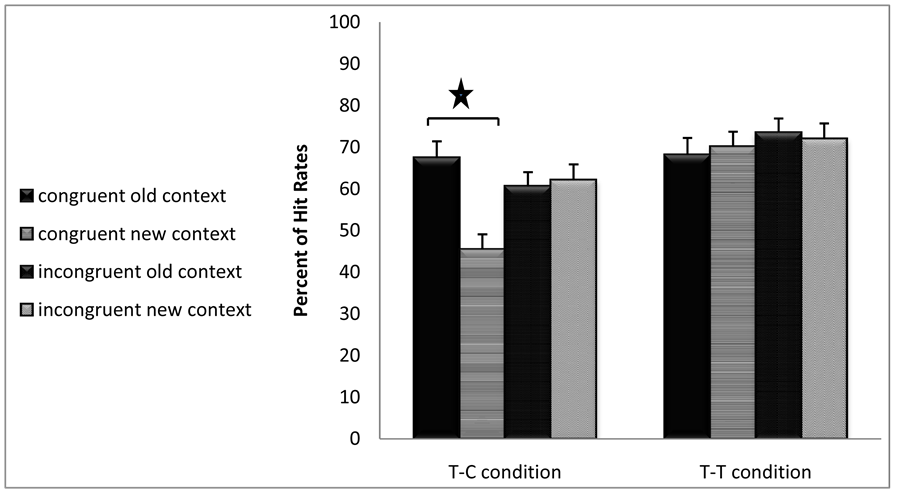
Hit rate: Main effect for context reached significance, F(1,64) = 6.32, p = 0.014, showing CE so that old contexts yielded higher hit rates for target words compared to new contexts. In addition, a main effect was found for congruency showing better overall recognition in incongruent pairs vs. congruent pairs F(1,64) = 5.28, p = 0.025 , and a main effect was found for attention showing higher hit rates in the T-C vs. T-T condition F(1,64) = 8.95, p = 0.004. These effects should be interpreted with caution because of the significant triple interaction between them F(1,64) = 12.09, p = 0.001. In order to detect the source of this interaction, two separate two-way ANOVA was performed in a 2 × 2 within-within design between congruency and context type in T-C condition and in T-T condition. The two analyses show that while in the T-T condition CE emerged as a main effect F(1,32) = 10.72, p = 0.003 and interacted with congruency F(1,32) = 13.33, p = 0.001, no CE was found in the T-C condition F(1,32) = 0.001, p = 0.94. Two separate analyses of CE in congruent and incongruent pairs in the T-T condition revealed that CE emerged in congruent pairs, F(1,32) = 19.64, p = 0.001, but not in incongruent pairs, F(1,32) = 0.14, p = 0.70. Results of hit rates in the short exposure experiment are displayed in Figure 1(a).
 (a)
(a)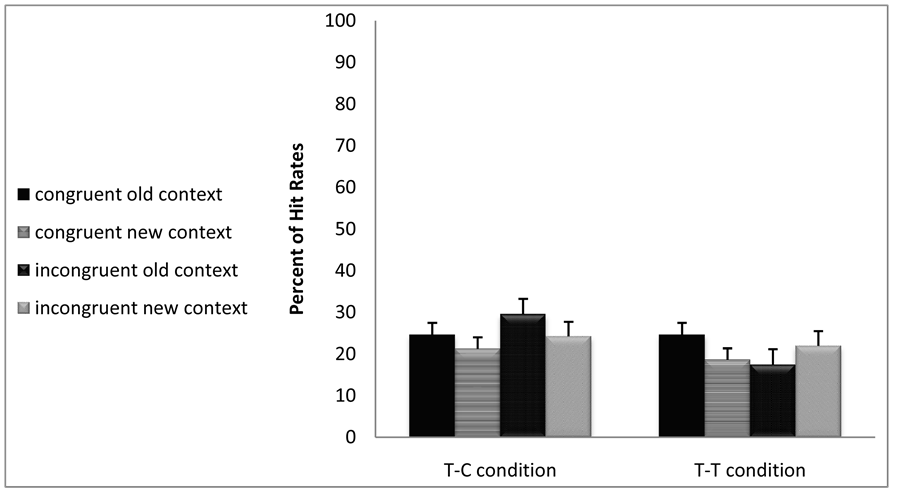 (b)
(b)
Figure 1.(a) Short exposure. Percentage of hit rates as a function of context type and congruency of pairs in T-T vs. T-C conditions. (b) Short exposure. Percentage of false alarm rates as a function of context type and congruency of pairs in T-T vs. T-C conditions.
False alarm rate measures: Main effect for context did not reach significance, F(1,64) = 1.82, p = 0.18. No interaction was found with the other factors. Results of the false alarms in the short exposure experiment are displayed in Figure 1(b).
3.2. Long Exposure Time
A 2 × 2 × 2 mixed design ANOVA with repeated measures was performed in order to examine the effect of three variables on recognition: Attention (T-C condition vs. T-T condition), Congruency of pairs (congruent vs. incongruent) and Context type (old vs. new).
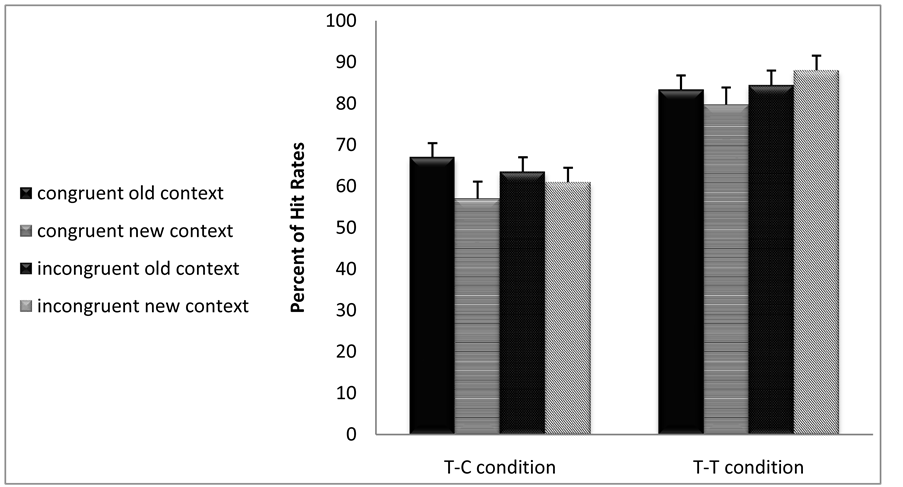
Hit rate measures: CE did not reach significance, F(1,47) = 1.74, p = 0.19. A main effect of attention was found, showing that target recognition was better in the T-C condition as compared to the T-T condition F(1,45) = 35.58, p = 0.001. No interaction was found between attention congruency and context type F(1,47) = 3.22, p = 0.08 (see Figure 2(a)). No other paired interaction was found.
False alarm rate measures: No main effect of CE was found in terms of false alarm measures F(1,47) = 0.31, p = 0.58, but a main effect was found for congruency showing higher false alarm rates for congruent pairs as compared with incongruent pairs F(1,47) = 4.59, p = 0.037 No triple interaction was found between attention congruency and context type F(1,47) = 0.60, p = 0.28, but an interaction was found between congruency and context type F(1,47) = 11.54, p = 0.001. In order to find the source of this interaction, two separate one-way ANOVA with repeated measures were conducted for congruent and incongruent pairs separately. CE was found for the congruent pairs F(1,48) = 7.17, p = 0.001 but not for incongruent pairs F(1,48) = 3.31, p = 0.075 (see Figure 2(b)).
4. Discussion
The findings of this study are consistent with previous studies that demonstrated that the emergence of CE is dependent on the interaction of several moderating factors (e.g., Bloch & Vakil, 2016 ). Longer exposure time enabled participants to process target stimuli better than under the short exposure time. In short exposure time, the attention factor (T-Cor T-T conditions) affected emergence of CE, while in long exposure time attention did not play a critical role in affecting the emergence of CE. In such conditions an “overshadowing” process seemed to take place. In line with the overshadowing principle, the strength of item cues was found to increase with the length of study time, at the expense of context cues (see also Isarida et al., 2012 ).
The Congruency factor affected CE under the short exposure time condition, CE emerged only with congruent pairs. In addition, better overall recognition for targets in the incongruent pairs was found, which was in line with our predictions due to less dependency on contextual cues in these pairs. Furthermore, CE emerged only in the T-T condition in the congruent pairs in the short exposure condition. This finding suggests that the amount of attention allocated to
 (a)
(a)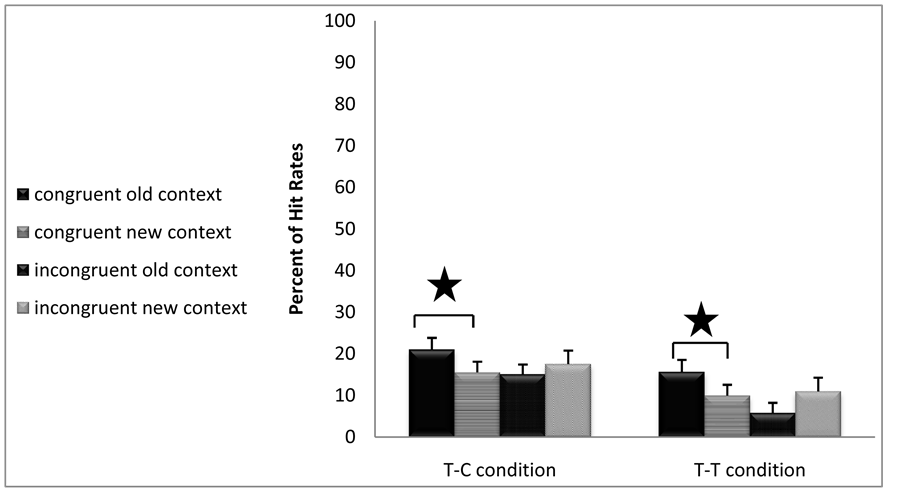 (b)
(b)
Figure 2. (a) Long Exposure. Percentage of Hit Rates as a function of Context type and Congruency of pairs in T-T vs. T-C conditions. (b) Long Exposure. Percentage of False Alarm rates as a function of Context type and Congruency of pairs in T-T vs. T-C conditions.
the stimuli affects the emergence of CE only during short exposure. Long exposure time, however, makes manipulation of attention ineffective because there is sufficient time to process both stimuli.
When using short exposure time, the T-C condition apparently made it clear to the participants which word was the target in each pair. Having only a short time to learn the targets, participant paid little or no attention to the context words and therefore no CE emerged in these pairs. This was true for both congruent and incongruent pairs under the T-C condition. In contrast, the T-T condition made it unclear to the participants which word was the target, so that even in this short time, participants had to pay attention to both targets and contexts without knowing which word would be the target. In these cases, CE emerged only in the congruent pairs and not in the incongruent pairs. It is possible that congruency facilities processing of contextual stimuli while incongruence inhibits this process by interfering with target encoding.
No CE was found in terms of false alarms in the short exposure condition. On the contrary, participants more accurately rejected new target words when paired with an old context word than when paired with a new context word. This finding could be interpreted as an indication that short exposure enabled minimal encoding of context, yielding CE under the conditions described above. However, such short exposure was insufficient to encode the context to a degree that would cause false alarms when presented with a new target stimulus.
The long exposure time revealed a different pattern for influencing CE. The findings in the long exposure condition support our assumption that long exposure would make contextual cues less relevant regardless of the attention allocated to the stimuli and congruency, thereby diminishing CE. Generally, targets were better recognized in the T-Ccondition as compared to the T-T condition because of the greater focus on the target stimuli in the former compared to the latter condition.
Smith and Vela’s (2001) overshadowing hypothesis postulates that when the learning targets are over-processed, context becomes less necessary as a retrieval cue and therefore CE is eliminated. Our findings under the long exposure time condition are consistent with this hypothesis. The long exposure enabled over learning of the target stimuli which made participants less dependent on contextual cues, resulting in no CE in both congruent and incongruent pairs.
Interestingly, CEs emerged in terms of false alarms only in the congruent pairs. Participants tended to mistakenly recognize new targets as old ones when paired with old congruent contexts but not with old incongruent contexts. In other words, the tendency towards positive recognition of a target was due to the presence of old contexts in these pairs. This process was unaffected by the manipulation of attention (T-T vs. T-C) because of sufficient exposure time while encoding targets in each encoding condition.
Migo, Mayes and Montaldi (2012) describe the dual process of recollection versus familiarity in contextual cueing, where recollection occurs when a stimulus cues recall of details linked to a specific target in a previous encounter. Familiarity, on the other hand, is explained as a sense of having had prior exposure to a stimulus without recalling any associated details from prior exposure, namely without binding between the target and the original contextual cue. They describe above-threshold familiarity as involving a conscious feeling of memory to a degree that cannot be equated with “unconscious” memory for a stimulus even if that feeling is very weak (Joordens, Wilson, Spalek, & Pare, 2010) . The findings related to false alarms for CE in the present study could be viewed as some kind of “unconscious” familiarity that misled participants when familiar context appeared with new context.
Familiarity context effect was not directly examined in the current study because an evaluation of familiarity, recollection and binding processes between targets and contexts must involve a comparison of the re-pair (manipulating an old different context) and new/none conditions in recognition as was described in the multifactorial model of context effect (see Vakil et al., 2007 ).
This pattern was displayed only when long exposure time was given, but was not displayed for incongruent contexts, thereby suggesting that incongruent irrelevant contexts at encoding diminished not only CE hit rates but also false alarms. This supports our assumption (in line with the “overshadowing hypothesis”) that allocating more attention resources to target stimuli in the Encoding phase at the expense of focusing on context stimuli, given longer exposure time and irrelevant context stimulus, results in fewer CE false alarms as well.
An important finding in the present study was that CE was affected by the congruency at the encoding phase. Incongruent contexts seemed to interrupt performance while judging targets’ gender at the encoding phase. These incongruent contexts became irrelevant and distracting, thereby reducing CE in recognition.
One of the methodological limitations of this study is that word frequency was not equated using a formal statistical Hebrew language word frequency database. In future research it is also recommended to consider a cognitive load hypothesis to make sure that participants did not have to elaborate two words in the T-T condition instead of only one word in the T-C condition. However, even if the cognitive load was higher for the T-T condition, this would not be enough to explain the differences in context effect, given that the findings of better general target recognition in the T-C condition as compared with the T-T condition was affected by both context type and congruency.
5. Conclusion
In summary, this study sheds light on the interaction between the various factors at encoding that affect the emergence of CE-exposure time, congruence between the stimuli, and the differential attention allocated to each stimulus. When target stimuli receive sufficient attention, as was shown for the long exposure time, these targets may overshadow the effect of the contextual cues, therefore weakening the emergence of CE (see Smith & Vela, 2001 ). However, when target stimuli received little attention, as was shown for the short time exposure, contextual cues became more relevant in determining the emergence of CE.
Conflict of Interest
We would like to declare that there is no conflict of interest in the manuscript.
Cite this paper
Schonbach-Medina, S., & Vakil, E. (2017). Encoding Factors Af- fecting Context Effects on Memory: Congruency, Attention and Exposure Time. Psy- chology, 8, 463-476. https://doi.org/10.4236/psych.2017.83029
References
- 1. Bloch, A., & Vakil, E. (2016). In a Context of Time: The Impact of Delay and Exposure Time on the Emergence of Memory Context Effects. Psychological Research.
https://doi.org/10.1007/s00426-015-0710-9 [Paper reference 2] - 2. Craik, F. I. M., & Tulving, E. (1975). Depth of Processing and the Retention of Words in Episodic Memory. Journal of Experimental Psychology: General, 104, 268-294.
https://doi.org/10.1037/0096-3445.104.3.268 [Paper reference 1] - 3. Dalton, P. (1993). The Role of Stimulus Familiarity in Context-Dependent Recognition. Memory & Cognition, 21, 223-234.
https://doi.org/10.3758/BF03202735 [Paper reference 1] - 4. Duncan, J. (1980). The Locus of Interference in the Perception of Simultaneous Stimuli. Psychological Review, 87, 272-300.
https://doi.org/10.1037/0033-295X.87.3.272 [Paper reference 1] - 5. Isarida, T., Isarida, T. K., & Sakai, T. (2012). Effects of Study Time and Meaningfulness on Environmental Context-Dependent Recognition. Memory & Cognition, 40, 1225-1235.
https://doi.org/10.3758/s13421-012-0234-0 [Paper reference 2] - 6. Johnston, W. A., & Dark, V. J. (1986). Selective Attention. Annual Review of Psychology, 37, 43-75.
https://doi.org/10.1146/annurev.ps.37.020186.000355 [Paper reference 1] - 7. Jonides, J. (1983). Further toward a Model of the Mind’s Eye’s Movements. Bulletin of the Psychonomic Society, 21, 247-250.
https://doi.org/10.3758/BF03334699 [Paper reference 1] - 8. Joordens, S., Wilson, D. E., Spalek, T. M., & Paré, D. E. (2010). Turning the Process-Dissociation Procedure Inside-Out: A New Technique for Understanding the Relation between Conscious and Unconscious Influences. Consciousness and Cognition, 19, 270-280.
https://doi.org/10.1016/j.concog.2009.09.011 [Paper reference 1] - 9. Klauer, K. C., & Musch, J. (2001). Does Sunshine Prime Loyal? Affective Priming in the Naming Test. Quarterly Journal of Experimental Psychology, 54, 727-751.
https://doi.org/10.1080/713755986 [Paper reference 1] - 10. LaBerge, D. (1983). Spatial Extent of Attention to Letters and Words. Journal of Experimental Psychology: Human Perception and Performance, 9, 371-379.
https://doi.org/10.1037/0096-1523.9.3.371 [Paper reference 1] - 11. Levy, D. A., Rabinyan, E., & Vakil, E. (2008). Forgotten but Not Gone: Context Effects on Recognition Do Not Require Explicit Memory for Context. Quarterly Journal of Experimental Psychology, 61, 1620-1628.
https://doi.org/10.1080/17470210802134767 [Paper reference 1] - 12. McKenzie, W. A., & Tiberghien, G. (2004). Context Effects in Recognition Memory: The Role of Familiarity and Recollection. Consciousness & Cognition, 13, 20-38.
https://doi.org/10.1016/S1053-8100(03)00023-0 [Paper reference 1] - 13. McNamara, T. P. (2005). Semantic Priming: Perspectives from Memory and Word Recognition. New York: Psychology Press.
https://doi.org/10.4324/9780203338001 [Paper reference 1] - 14. Memon, A., & Bruce, V. (1985) Context Effects in Episodic Studies of Verbal and Facial Memory: A Review. Current Psychological Research and Reviews, 86, 349-369.
https://doi.org/10.1007/BF02686589 [Paper reference 1] - 15. Meyer, D. E., & Schvaneveldt, R. W. (1971). Facilitation of Recognizing Pairs of Words: Evidence of a Dependence between Retrieval Operations. Journal of Experimental Psychology, 90, 227-234.
https://doi.org/10.1037/h0031564 [Paper reference 1] - 16. Migo, E. M., Mayes, A. R., & Montaldi, D. (2012). Measuring Recollection and Familiarity: Improving the Remember/Know Procedure. Consciousness and Cognition, 21, 1435-1455.
https://doi.org/10.1016/j.concog.2012.04.014 [Paper reference 1] - 17. Neely, J. H. (1991). Semantic Priming Effects in Visual Word Recognition: A Selective Review of Current Findings and Theories. In D. Besner, & G. W. Humphreys (Eds.), Basic Processes in Reading: Visual Word Recognition (pp. 264-336). Hillsdale: Erlbaum. [Paper reference 1]
- 18. Smith, S. M., & Vela, E. (2001). Environmental Context-Dependent Memory: A Review and Meta-Analysis. Psychonomic Bulletin & Review, 8, 203-220.
https://doi.org/10.3758/BF03196157 [Paper reference 4] - 19. Tulving, E., & Thomson, D. M. (1973). Encoding Specificity and Retrieval Processes in Episodic Memory. Psychological Review, 80, 352-373.
https://doi.org/10.1037/h0020071 [Paper reference 1] - 20. Umilta, C. (1988). Orienting of Attention. In F. Boller, & J. Grafman (Eds.), Handbook of Neuropsychology (Vol. 1, pp. 175-193). Amsterdam: Elsevier. [Paper reference 1]
- 21. Vakil, E., Raz, T., & Levy, D. A. (2007). The Multifactorial Nature of Recognition Memory Context Effects. Quarterly Journal of Experimental Psychology, 60, 916-923.
https://doi.org/10.1080/17470210701357568 [Paper reference 3] - 22. Winograd, E., & Rivers-Bulkeley, N. T. (1977). Effects of Changing Context on Remembering Faces. Journal of Experimental Psychology: Human, Learning and Memory, 3, 397-405.
https://doi.org/10.1037/0278-7393.3.4.397 [Paper reference 1]