Applied Mathematics
Vol.06 No.05(2015), Article ID:56709,16 pages
10.4236/am.2015.65079
Functional Weak Laws for the Weighted Mean Losses or Gains and Applications
Gane Samb Lo1,2, Serigne Touba Sall1,3, Pape Djiby Mergane1
1LERSTAD, Université Gaston Berger de Saint-Louis, Saint-Louis, Sénégal
2LSTA, Université Pierre et Marie Curie, Paris, France
3Ecole Normale Supérieure, Dakar, Sénégal
Email: pdmergane@ufrsat.org
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 22 February 2015; accepted 24 May 2015; published 27 May 2015
ABSTRACT
In this paper, we show that many risk measures arising in Actuarial Sciences, Finance, Medicine, Welfare analysis, etc. are gathered in classes of Weighted Mean Loss or Gain (WMLG) statistics. Some of them are Upper Threshold Based (UTH) or Lower Threshold Based (LTH). These statistics may be time-dependent when the scene is monitored in the time and depend on specific functions w and d. This paper provides time-dependent and uniformly functional weak asymptotic laws that allow temporal and spatial studies of the risk as well as comparison among statistics in terms of dependence and mutual influence. The results are particularized for usual statistics like the Kakwani and Shorrocks ones that are mainly used in welfare analysis. Data-driven applications based on pseudo-panel data are provided.
Keywords:
Empirical Process, Time Dependent Process, Weak Theory, Risk Measures, Poverty Index, Loss Function, Economic Welfare

1. Introduction and Motivation
In many situations and many areas, we face the double problem of estimating the risk of lying in some marked zone and, at the same time, the cost associated with it. To fix ideas, we may be interessed in estimating the immunocompromised patients number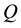 , and the size of the set
, and the size of the set 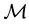 of infected people, in some population
of infected people, in some population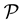 . At the same time, we know that the severity of the infection is measured by the viral load
. At the same time, we know that the severity of the infection is measured by the viral load 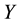 expressed in RNA copies per milliliter of blood plasma. The cost of treatement, for example a course of chemotherapy, heavily depends on the viral load. If one has to treat all the patients, there is a cost to pay for each treatment, which is a cost function
expressed in RNA copies per milliliter of blood plasma. The cost of treatement, for example a course of chemotherapy, heavily depends on the viral load. If one has to treat all the patients, there is a cost to pay for each treatment, which is a cost function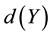 . Facing these two problems at the same time, comparing two different populations or monitoring the evolution of the global situation should be based on the couple
. Facing these two problems at the same time, comparing two different populations or monitoring the evolution of the global situation should be based on the couple 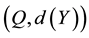 rather than on which is commonly called the HIV/AIDS adult prevalence rate, on what is based international comparison. In order to make a workable statistic, consider a sample of individuals
rather than on which is commonly called the HIV/AIDS adult prevalence rate, on what is based international comparison. In order to make a workable statistic, consider a sample of individuals 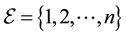 drawn for
drawn for  and measure the viral load
and measure the viral load 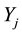 for each
for each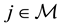 . A general comparative statistic should be of the form
. A general comparative statistic should be of the form
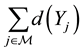
Since comparisons over the time are based on this index, one will be interested in putting more or less emphasis on the more infected or not, in terms of viral load. This is achieved by affecting a weight 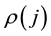 to
to 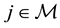 as a monotone function of the rank
as a monotone function of the rank 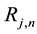 of
of 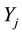 in the sample. For an increasing
in the sample. For an increasing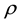 , it is paid more attention to less infected while the contrary holds for a decreasing one. This leads to statistics like
, it is paid more attention to less infected while the contrary holds for a decreasing one. This leads to statistics like
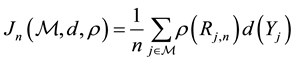 . (1)
. (1)
It is also known that the viral load is detectable only above a threshold of value  RNA copies per milliliter of blood plasma. We thus have
RNA copies per milliliter of blood plasma. We thus have
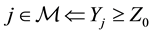
and
 .
.
We may decide to concentrate on the very expansive chemotherapy courses due to financial pressure. In that case, we change the threshold to 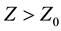 according to the available budget.
according to the available budget.
Such statistics are also used in insurance theory. Suppose that one insurance company receives 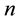 claims
claims . We may fix a threshold
. We may fix a threshold  such that any claim greater than
such that any claim greater than  is seen as causing a loss
is seen as causing a loss  for the company. It then becomes interesting to estimate the number of possible claims over
for the company. It then becomes interesting to estimate the number of possible claims over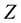 ,
,
 (2)
(2)
and to choose a distorsion function 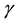 of the individual loss
of the individual loss ; hence, (1) is transformed here into
; hence, (1) is transformed here into
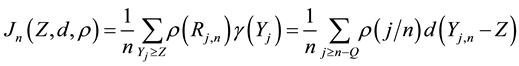 ,
,
where 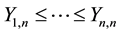 are the order statistics based on
are the order statistics based on . In this case,
. In this case,  may be seen as a risk measure.
may be seen as a risk measure.
In poor countries, an individual is considered as a poor one when his income  below some threshold
below some threshold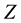 , called poverty line. And then
, called poverty line. And then
 (3)
(3)
is the total number of poor people in the sample, while  is the poor headcount. Usually the cost function
is the poor headcount. Usually the cost function
here depends on the relative poverty gap . In this field, following Lo [1] ,
. In this field, following Lo [1] , 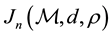
may be called a General Poverty Index (GPI). The same form may also be used in medical science when dealing with vitamine (say vitamine D) deficiency. In this case,  is used as a general measure of vitamine deficiency to evaluate the mean cost of vitamine supply as a treatment.
is used as a general measure of vitamine deficiency to evaluate the mean cost of vitamine supply as a treatment.
We see from the lines above that (1) is a very general statistic, which works in various fields, with losses or gains dependent on the meaning of the cost function . We are entitled to name it as a Weighted Mean Loss or Gain (WMLG) statistic or random measure or index. It may take a specific name, depending on the particular field where it operates. In the loss (resp. gain) case, we simply denote it WML (resp. WMG).
. We are entitled to name it as a Weighted Mean Loss or Gain (WMLG) statistic or random measure or index. It may take a specific name, depending on the particular field where it operates. In the loss (resp. gain) case, we simply denote it WML (resp. WMG).
When we have time-dependent data, over the time 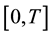 with continuous observations
with continuous observations
 , we are led to a time-dependent WMLG statistic in the form
, we are led to a time-dependent WMLG statistic in the form
 .
.
In the case where  is based on the threshold
is based on the threshold ; the latter should eventually depend on the time and becomes
; the latter should eventually depend on the time and becomes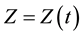 . Also, in an spatial analysis, it would be possible to have a particular threshold for any area.
. Also, in an spatial analysis, it would be possible to have a particular threshold for any area.
The choice of  and
and 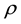 depends of the specific role played by (1). But, a set of axioms, which are desirable or mandatory to be fulfilled for a welfare or a risk measure, is usually adopted. For risk measures, such axiomes alongside an axiomatic foundation are to be found in Artzner et al. [2] . For poverty analysis, a large and deep review of the axiomatic approach, due to Sen [3] , is available in Zheng [4] .
depends of the specific role played by (1). But, a set of axioms, which are desirable or mandatory to be fulfilled for a welfare or a risk measure, is usually adopted. For risk measures, such axiomes alongside an axiomatic foundation are to be found in Artzner et al. [2] . For poverty analysis, a large and deep review of the axiomatic approach, due to Sen [3] , is available in Zheng [4] .
Finally, taking into account various forms of (1) in the literature, the following form of threshold-based weighted mean loss seems to be a general one
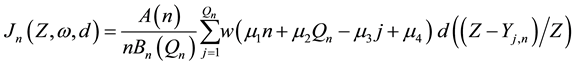 , (4)
, (4)
or the following
 , (5)
, (5)
depending on whether we handle loss (with 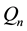 defined in (3)) or gains (with
defined in (3)) or gains (with 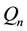 defined in (2)), and where
defined in (2)), and where
 .
.
From a mathematical point of view, the asymptotic behaviors of the two forms radically differ although the writing seems symetrical. The reason is that for the first, the random variables used in (4) are bounded and the asymptotic handling is much easier. As for (5), we should face heavy tail problems and further complications may arise.
This paper is aimed at offering a full functional weak theory according to the most recent setting of such theories as stated in [5] . Particularly, we are interested here in the time-dependent investigation of (4), and next the functional weak theory in 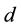 and
and . We call the first class of statistics Upper Threshold Based Weighted Mean Loss or Gain (UTB WMLG) ones and the others are named Lower Threshold Based Weighted Mean Loss indices (LTB WMLG). This paper is only concerned with the first class of statistics. The others will be objects of further studies.
. We call the first class of statistics Upper Threshold Based Weighted Mean Loss or Gain (UTB WMLG) ones and the others are named Lower Threshold Based Weighted Mean Loss indices (LTB WMLG). This paper is only concerned with the first class of statistics. The others will be objects of further studies.
Consider for a while that 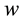 and
and  are fixed as well as the time. We notice that asymptotic results of
are fixed as well as the time. We notice that asymptotic results of 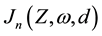 are available for specific forms in Welfare theory or in Actuarial Sciences. For example, Lo [1] proved that
are available for specific forms in Welfare theory or in Actuarial Sciences. For example, Lo [1] proved that
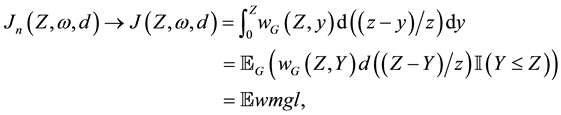
where  may be called the Exact UTB WMLG. For instance, the weight
may be called the Exact UTB WMLG. For instance, the weight 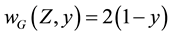 is related to the Shorrocks [6] and Thon [7] statistics,
is related to the Shorrocks [6] and Thon [7] statistics,  is the Kakwani weight (see [8] ), that in- cludes the Sen [3] one corresponding to
is the Kakwani weight (see [8] ), that in- cludes the Sen [3] one corresponding to . For
. For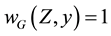 , we get the nonweighted mean losses or gains.
, we get the nonweighted mean losses or gains.
To be able to base statistical tests of such results, we may be interested in finding the asymptotic law of
 .
.
However, we still need to handle longitidunal data, where the risk situation is analysed over a continuous period of time . In this case, we are faced with continuous data in the form of
. In this case, we are faced with continuous data in the form of , and some modification is needed in the definition of indices to take this into account. We are then led to consider the time-dependent and UTB WMLG statistic defined by
, and some modification is needed in the definition of indices to take this into account. We are then led to consider the time-dependent and UTB WMLG statistic defined by
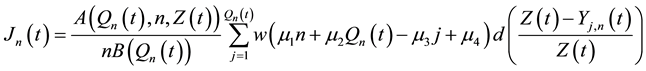 , (6)
, (6)
with 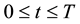 and
and .
.
Instead of analysing such UTB WMLG for some specific functions  or
or , or at a fixed point
, or at a fixed point , it may be more valuable to have at once a uniform weak theory on
, it may be more valuable to have at once a uniform weak theory on ,
,  and
and . Such a result will provide indi- vidual tests, and enables spatial and temporal comparisons of the risk measure. As well, since all the measure are expressed in the same Gaussian field, we have joint asymptotic distributions of the different indices themselves.
. Such a result will provide indi- vidual tests, and enables spatial and temporal comparisons of the risk measure. As well, since all the measure are expressed in the same Gaussian field, we have joint asymptotic distributions of the different indices themselves.
This paper is aimed at settling the uniform weak convergence of such statistics, which is the asymptotic theory of the time-dependent poverty measures (6), in the space  of real continuous functions defined on
of real continuous functions defined on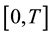 . First attempts were treated for the special case of time-dependent nonweighted mean loss or gain (MLG) measures in [9] and, in [10] , for nonrandomly WMLG statistics, that is, WMLG statistics for which the weight is nonrandom, like the Shorrocks one, is dealt with. Now, we target to give here the most general results on the time-dependent UTB-WMLG statistics. Two potential applications areas here are vitamine deficiency risk mea- sures and poverty measures. It is then natural to consider a threshold depending on the time. But we suppose that it lies in some finite interval
. First attempts were treated for the special case of time-dependent nonweighted mean loss or gain (MLG) measures in [9] and, in [10] , for nonrandomly WMLG statistics, that is, WMLG statistics for which the weight is nonrandom, like the Shorrocks one, is dealt with. Now, we target to give here the most general results on the time-dependent UTB-WMLG statistics. Two potential applications areas here are vitamine deficiency risk mea- sures and poverty measures. It is then natural to consider a threshold depending on the time. But we suppose that it lies in some finite interval
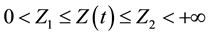 .
.
An important application is the statistical estimation of the Relative Mean Loss Variation (RMLV) from time  to
to  defined as follow
defined as follow

by confidence intervals where 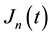 is a poverty measure, one of the Millennium Development Goals (MDG) is halving of extreme poverty from t = 2000 to time s = 2015. This means that we target to have
is a poverty measure, one of the Millennium Development Goals (MDG) is halving of extreme poverty from t = 2000 to time s = 2015. This means that we target to have 
 . Our results below tackle this issue.
. Our results below tackle this issue.
We will need a number of hypotheses towards an adequate frame for our study. These hypotheses may appear severe and numerous, at first sight, but most of them are natural and easy to get. We first need the following shape conditions for the WMLG measures themselves. The letter S in the hypotheses names refers to shape con- ditions.
(HS1) There exist functions  of
of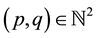 ,
,  and
and  of
of 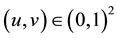 independent of
independent of , such that, as
, such that, as ,
,
 ,
,
where  denotes the convergence to zero in outer probability (see [5] ).
denotes the convergence to zero in outer probability (see [5] ).
(HS2)

(HS3) There exists a function 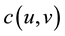 of
of  independent of
independent of , such that, as
, such that, as ,
,
 .
.
We will require other assumptions depending on the regularity of the functions  and
and . The letter
. The letter  in these hypotheses name refers to Regularity conditions..
in these hypotheses name refers to Regularity conditions..
(HR1) The bivariate functions  and
and  have equi-continuous partial differential on
have equi-continuous partial differential on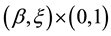 , where
, where  and
and  are two real numbers to be defined later on.
are two real numbers to be defined later on.
(HR2) For a fixed , the functions
, the functions  and
and  are monotone.
are monotone.
(HR3) There exist  and
and  such that, for
such that, for ,
,
 ,
,
and
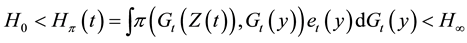 ,
,
Our final achievement is that, when putting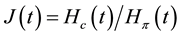 , we are able to get the uniform asymptotic
, we are able to get the uniform asymptotic
law of  and to describe the limiting Gaussian process
and to describe the limiting Gaussian process . This
. This
enables the statistical uniform estimates of  by
by  by interval confidences. We also particularize the results for the so-important Kakwani class of WMLG statistics of which the Sen one is a member. The results that have directly been derived for the Shorrocks case are rediscovered here.
by interval confidences. We also particularize the results for the so-important Kakwani class of WMLG statistics of which the Sen one is a member. The results that have directly been derived for the Shorrocks case are rediscovered here.
2. Our Results
Our results will rely on the representation of Theorem [11] , which in turn will need the following assumptions.
(HL1) There exist  and
and  such that
such that
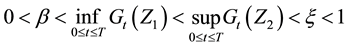 .
.
(HL2) The subclass 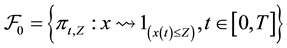 of
of , the set of real bounded and con-
, the set of real bounded and con-
tinuous functions, is a  -Glivenco-Cantelli class, that is, as
-Glivenco-Cantelli class, that is, as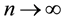 ,
,

where, for any  and
and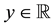 ,
, . As a reminder
. As a reminder ,
,  as
as
 means (
means ( in outer probability), that is : there exists a sequence of measurable random variables,
in outer probability), that is : there exists a sequence of measurable random variables,  such that for any
such that for any ,
,  and
and  as
as .
.
Finally let us denote , where
, where .
.
(HL3) For any ,
,  is strictly increasing and the functions
is strictly increasing and the functions  are uniformly continuous in
are uniformly continuous in .
.
(HL4)  is bounded by one and is differentiable with derivative function
is bounded by one and is differentiable with derivative function  bounded by M :
bounded by M :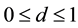 ,
, .
.
Theorem 1 Suppose that (HS1)-(HS2), (HR1)-(HR3) and (HL1)-(HL4) hold. Put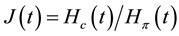 ,
,
 , (7)
, (7)
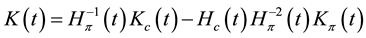 , (8)
, (8)
 (9)
(9)
and

Define
 ,
,
and

Then we have, uniformly in , the following representation, as
, the following representation, as ,
,
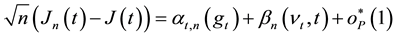 , (10)
, (10)
with
 .
.
and
 , (11)
, (11)
Suppose that (HS3), (HR1)-(HR3) and (HL1)-(HL4) hold. Then, (10) holds with
 . (12)
. (12)
This theorem expresses our studied time-dependent statistics as the sum of a functional empirical process and the stochastic process (11). It will be seen, for a fixed time, that  is asymptotically an integral of the quantile process
is asymptotically an integral of the quantile process  based on
based on  (where
(where 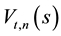 is the empirical quantile
is the empirical quantile
function) and then of empirical process , These facts make easy the handling of
, These facts make easy the handling of
 in the modern empirical process setting as stated in [5] . We still need a thorough study of (11) and its connection with
in the modern empirical process setting as stated in [5] . We still need a thorough study of (11) and its connection with  while the computation of the variance and covariance function. This is done separately in [12] to avoid lengthy papers.
while the computation of the variance and covariance function. This is done separately in [12] to avoid lengthy papers.
Now, we use these tools to give first, general laws for the WMLG statistic below and then for the Kakwani class of indices in Section 2.2 and for the Shorrocks-Thon indices in Section 3. We finish by a special study of the absolute and the relative poverty changes in Section 4.
While we deal with the general index and we use the outcomes of Theorem 1, we adopt the following writing:
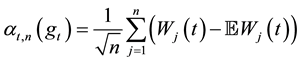
where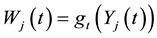 . Then we are entitled to express the hypotheses (HT1) and (HT2) below on the
. Then we are entitled to express the hypotheses (HT1) and (HT2) below on the  in place of the
in place of the  for the general case. And we suppose that
for the general case. And we suppose that  admits a density probability
admits a density probability  for each
for each . In particular cases, we will turn back to hypotheses on the
. In particular cases, we will turn back to hypotheses on the  for establishing (HT2) and (HT3) and subsequently recover the results. In the sequel,
for establishing (HT2) and (HT3) and subsequently recover the results. In the sequel,  is a fixed positive real number such that
is a fixed positive real number such that . And from now, the limits and the
. And from now, the limits and the  are performed when
are performed when .
.
(HT1) For ,
, 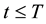 , for some constant
, for some constant ,
, .
.
(HT2) For ,
,  , for some constant
, for some constant ,
, .
.
In order to define our last assumption, we need the following functions:
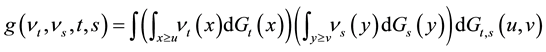
and
 .
.
with, by convention,  for a function
for a function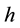 . Set
. Set
(HT3) If there is a universal constant , such that for any
, such that for any , for large enough values of
, for large enough values of ,
,
 (13)
(13)
We are now able to give our general main result.
Theorem 2 Assume the conditions of Theorem 1 hold and that (HT1)-(HT3) are satisfied. Then the stochastic process  converges in
converges in  to a centered Gaussian process
to a centered Gaussian process
 with covariance function
with covariance function
 ,
,
with
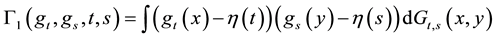 ,
,
 ,
,
 ,
,
and
 ,
,
with
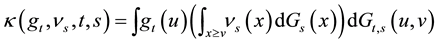 ,
,
and 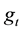 and
and  are given in Theorem 1, and
are given in Theorem 1, and
 .
.
Proof. We have to do three things. First, we show that  is asymptotically tight. Next, we have to prove that it converges in finite distributions. And finally, we should compute the covariance function. We will only sketch the first and the second tasks with the appropriate citations. The second will be properly adressed.
is asymptotically tight. Next, we have to prove that it converges in finite distributions. And finally, we should compute the covariance function. We will only sketch the first and the second tasks with the appropriate citations. The second will be properly adressed.
Since the assumptions of Theorem 1 hold, we have the representation (10). Put
 , (14)
, (14)
First (HT2) and (HT2) yield, for each , for some constant
, for some constant ,
,
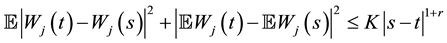 ,
,
and hence, by repeated use of 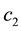 -inequality (that is, for any couple
-inequality (that is, for any couple  of scalars
of scalars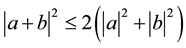 , for some constant K,
, for some constant K,
 . (15)
. (15)
We remind again that  is strictly less that
is strictly less that , otherwise functions satisfying 15 are constant. Here and in the sequel,
, otherwise functions satisfying 15 are constant. Here and in the sequel,  is a generic constant eventually taking different values from one formula to another. Next, we
is a generic constant eventually taking different values from one formula to another. Next, we
find in [12] , that 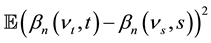 is
is
 , (16)
, (16)
where  is bounded uniformly in
is bounded uniformly in  and
and . So by combining (14), (15), (16) and (HT3), and by the
. So by combining (14), (15), (16) and (HT3), and by the  -inequality, we get for some
-inequality, we get for some  that for any
that for any , for large enough values of
, for large enough values of ,
,
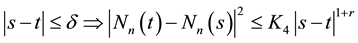 , (17)
, (17)
Thus  is asymptotically tight by Lemma 1 in [9] , which is an adaptation of Example 2.2.12 in [5] . To finish the proof, we have to establish that finite-distributions of
is asymptotically tight by Lemma 1 in [9] , which is an adaptation of Example 2.2.12 in [5] . To finish the proof, we have to establish that finite-distributions of  converge to those of some Gaussian tight process
converge to those of some Gaussian tight process . For simplicity’s sake, we do it in the two dimensional case, for
. For simplicity’s sake, we do it in the two dimensional case, for
 . Consider
. Consider . Still for simpicity’s sake, let us set
. Still for simpicity’s sake, let us set
 ,
,
and
 .
.
where the 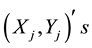 stand for the
stand for the  as independent observations of
as independent observations of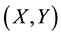 ,
,  (resp.
(resp.
 ) is the empirical function based on
) is the empirical function based on  (resp.
(resp. ). Put
). Put
 .
.
Now let, for each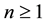 ,
,  (resp.
(resp. ) be the quantile processes based respectively on
) be the quantile processes based respectively on
 (resp.
(resp. ). It is not hard to see that
). It is not hard to see that
 ,
,
and
 .
.
Now, let  and
and  be the empirical processes based respectively on
be the empirical processes based respectively on  and on
and on . We have (see [13] , p. 584) that
. We have (see [13] , p. 584) that  uniformly in
uniformly in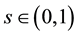 , which gives
, which gives
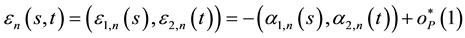 ,
,
uniformly in . Now let us consider the functional empirical process
. Now let us consider the functional empirical process  based on the
based on the
 , that is
, that is
 ,
,
where  a real function defined on
a real function defined on  such that
such that . Finally, let
. Finally, let  the fonctional empirical process based on the
the fonctional empirical process based on the  , defined for
, defined for ,
,

We have
 ,
,
for , We have by the classical results of empirical process that
, We have by the classical results of empirical process that  converges to a Gaussian process
converges to a Gaussian process  whenever
whenever  is a Donsker class. It follows that
is a Donsker class. It follows that
 converges to a Gaussian process
converges to a Gaussian process  whenever
whenever  is a Vapnik-Cervonenkis class.
is a Vapnik-Cervonenkis class.
But  is VC-class of index not greater than 2. (see [5] for VC-classes use to em-
is VC-class of index not greater than 2. (see [5] for VC-classes use to em-
pirical processes). Thus putting , we have
, we have
 ,
,
in  where
where 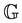 is a tight Gaussian process such that
is a tight Gaussian process such that
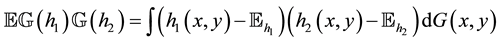 .
.
Further, for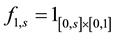 ,
,  ,
,
 ,
,
and for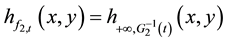 ,
,

Now, by using the Skorohod-Wichura-Dudley Theorem, we are entitled to suppose that we are on a probability space such that
 .
.
Now, since the functions  are bounded, and putting
are bounded, and putting  and
and ,
,  is equal to
is equal to
 .
.
One easily proves that
 .
.
is a Gaussian random variable since the second term is a Riemann integral, which is a limit of finite linear com- binations of Gaussian random variables. Thus  is asymptotically Gaussian. We are able to do the same for an arbitrary finite-distribution
is asymptotically Gaussian. We are able to do the same for an arbitrary finite-distribution , The computation of the limiting Gaussian process requires heavy calculations done in [12] . The proof ends with providing the covariance function
, The computation of the limiting Gaussian process requires heavy calculations done in [12] . The proof ends with providing the covariance function  of
of ,
,  of
of 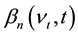 and the covariance
and the covariance  function between them.
function between them.
2.1. Special Cases
Since the results are stated in a more general form and may appear very sophisticated, it seems necessary to show how they work for common cases. We apply our results to two key examples in Welfare analysis: the class of Kakwani’s and Shorrocks’ statistics. These two examples are particularly interesting since they put the emphasis on the less deprived individuals within the whole population (with weight ) for Shorrock’s statistic), or within the marked individuals (with weight
) for Shorrock’s statistic), or within the marked individuals (with weight ) for Kakwani’s class of statistic including sen’s measure). In both case, taking the weight at the power
) for Kakwani’s class of statistic including sen’s measure). In both case, taking the weight at the power  may lead to more accuracy in the statistical estimation.
may lead to more accuracy in the statistical estimation.
2.2. The Kakwani Case
We are now applying the general results to the Kakwani WMLG statistics of parameter , defined by
, defined by
 .
.
The way we are using here is to be repeated for any particular index. For instance, the results in [9] and [10] may be rediscovered in this way. In this specific case, we turn the hypotheses (HT1) and (HT2) on 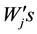 to the
to the  as follows. Suppose the
as follows. Suppose the 
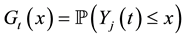 admits a derivative
admits a derivative . Put
. Put
 . Introduce:
. Introduce:
(H0) For ,
,  , for some constant
, for some constant ,
, .
.
(H1) There exists a positive function  such that for
such that for ,
, 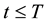 ,
,  ,
,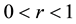 )
)
 .
.
and
 .
.
(H2) For ,
,  , for some constant
, for some constant ,
,
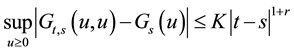 ,
,
and
 .
.
(H3) For ,
, 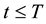 , for some constant
, for some constant ,
, 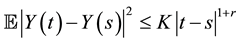 ,
,
We check, in the Kakwani case, that the representation of Theorem 1 holds with ,
,
 ,
,  and then
and then
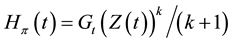 ,
,
 ,
,
so that
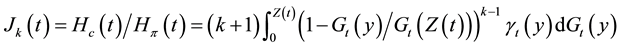 .
.
Next
 ,
,
and then
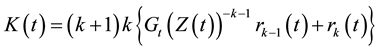 ,
,
where
 .
.
For
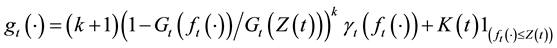 ,
,
and
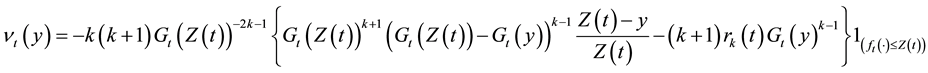 .
.
we will get the representation

with

Theorem 3 Let (HL1), (HL3), (HL4), (H0)-(H3) hold. Then 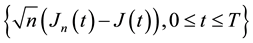 converges in
converges in  to a centered Gaussian process with covariance function
to a centered Gaussian process with covariance function  given in Theorem 2.
given in Theorem 2.
Proof. We begin to remark that (H3) ensures that  is asymptocially tight and hence (HL2). It is then enough to show that (HT1) and (HT2) hold from (H0), (H1), (H2) and (H3). But this follows from routine calculations that we only sketch here. We place these calculation in the appendix.
is asymptocially tight and hence (HL2). It is then enough to show that (HT1) and (HT2) hold from (H0), (H1), (H2) and (H3). But this follows from routine calculations that we only sketch here. We place these calculation in the appendix.
3. The Shorrocks-Thon-Like Case
We apply our results to the Shorrocks-Thon WMLG statistics measures defined by
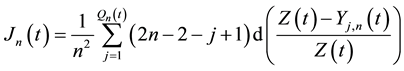
This is the Thon index. One obtains the Shorrocks one by replacing  by
by 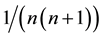 We also check here that representation of Theorem 1 holds in the simple case corresponding to (HS3), with
We also check here that representation of Theorem 1 holds in the simple case corresponding to (HS3), with , In this case,
, In this case, 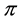 is useless. Then
is useless. Then
 ,
,

Here again  has the same asymptotic behaviour described in Theorem 3 with
has the same asymptotic behaviour described in Theorem 3 with
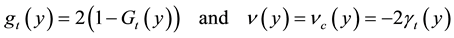
under the same hypotheses (HL1)-(HL4) and (H0)-(H3)
4. Estimation of the WLMG Statistic Variation
Although they are very expensive to collect, longitudinal data are highly preferred for adequate estimate of the absolute index variation , which is the exact measure of WMLG change between the
, which is the exact measure of WMLG change between the
periods t and s and the associate relative WMLG variation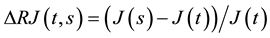 . Their respective
. Their respective
natural estimators are of course 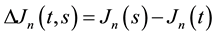 and
and 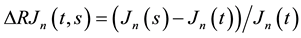 Our pre- vious results yield the follow
Our pre- vious results yield the follow
Theorem 4 Under the assumptioms of Theorem 1 or Theorem 2,
 ,
,
where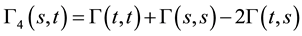 , and
, and
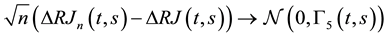
where

with
 ,
,

The proof is straightforward. We also might consider the convergence of 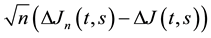 to the
to the
Gaussian process  in
in . Anyway for fixed
. Anyway for fixed  and
and ,
,
 converges to the Gaussian random variable
converges to the Gaussian random variable  by the conti- nuity Theorem with
by the conti- nuity Theorem with 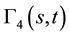 as variance. Also, by using the Skorohod-Wichura-Dudley Theorem, we have
as variance. Also, by using the Skorohod-Wichura-Dudley Theorem, we have

An important application of the second part of this theorem is related to checking the achievement of specific goals. One may, within a national or regional strategy, whish to have some deprivation limited to some extent. For example, the UN has assigned a number of goals, named Millennium Development Goals (MDG), to its members. We are concerned here by one of them. Indeed, it is whished to halve the extreme poverty in the world in year  starting from year
starting from year . When the WMLG statistic is a poverty measure, we may use
. When the WMLG statistic is a poverty measure, we may use  and check whether it is less than
and check whether it is less than . And an
. And an  -confidence interval
-confidence interval  based on these results is
based on these results is

where . This MDG will be reported achieved at the 95% level if the number
. This MDG will be reported achieved at the 95% level if the number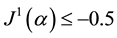 .
.
4.1. Datadriven Applications and Variance Computations
We apply our results in Economics and Welfare analysis. Especially, we consider the household surveys in Senegal in 2011 (ESAM II) and in 2006 (EPS) from which we construct pseudo-panel data and apply our results.
4.1.1. Variance Computations for Senegalese Data
We apply our results to Senegalese data. We do not really have longitudinal data. So we have constructed pseudo-panel data of size , from two surveys: ESAM II conducted from 2001 to 2002 and EPS from 2005 to 2006. We get two series
, from two surveys: ESAM II conducted from 2001 to 2002 and EPS from 2005 to 2006. We get two series  and
and . We present below the values of
. We present below the values of 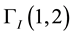 denoted here
denoted here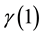 ,
,  denoted here
denoted here  and
and 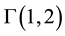 denoted here
denoted here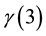 .
.
When constructing pseudo-panel data, we get small sizes like 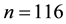 here. We use these sizes to compute the asymptotic variances in our results with nonparametric methods. In real contexts, we should use high sizes comparable to those of the real databases, that is around ten thousands, like in the Senegalese case. Nevertheless, we back on medium sizes, for instance
here. We use these sizes to compute the asymptotic variances in our results with nonparametric methods. In real contexts, we should use high sizes comparable to those of the real databases, that is around ten thousands, like in the Senegalese case. Nevertheless, we back on medium sizes, for instance , which give very accurate confidence intervals as shown in Table 1.
, which give very accurate confidence intervals as shown in Table 1.
Before we present the outcomes, let us say some words on the packages. We provide different R script files at http://www.ufrsat.org/lerstad/resources/sallmergslo01.zip.
The user should already have his data in two files data1.txt and data2.txt. The first script file named after gamma_mergslo1.dat provides the values of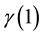 ,
,  and
and 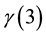 for the FGT measure for
for the FGT measure for  and for the six inequality measures used here. The second script file named gamma_mergslo2.dat performs the same for the Shorrocks measure. Finally, gamma_mergslo3.dat concerns the kakwani measures. Unless the user uploads new data1.txt and data2.txt files, the outcomes should the same as those presented in Appendix.
and for the six inequality measures used here. The second script file named gamma_mergslo2.dat performs the same for the Shorrocks measure. Finally, gamma_mergslo3.dat concerns the kakwani measures. Unless the user uploads new data1.txt and data2.txt files, the outcomes should the same as those presented in Appendix.
4.1.2. Analysis
First of all, we find that, at an asymptotical level, all our inequality measures and poverty indices used here have decreased. When inspecting the asymptotic variance, we see that for the poverty index, the FGT and the Kakwani classes respectively for ,
, 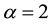 and
and  and
and  have the minimum variance, specially for
have the minimum variance, specially for  and
and . This advocates for the use of the Kakwani and the FGT measures for poverty reduction evaluation.
. This advocates for the use of the Kakwani and the FGT measures for poverty reduction evaluation.

Table 1. Variations of the poverty indices.
5. Conclusion
We obtained asymptotic laws of the UTB WMLG statistics with in mind, among other targets, the uniform estimation of the variation  and the relative variation
and the relative variation . The results are only illustrated with simple datadriven applications to income databases in Senegal. This opens large datadriven application in whole economic areas. In the theoritical hand, the Lower Threshold Based weighted mean loss or gain statistics is to be studied in accordance with heavy tail conditions and to be applied in Insurance and HIV/VIH fields.
. The results are only illustrated with simple datadriven applications to income databases in Senegal. This opens large datadriven application in whole economic areas. In the theoritical hand, the Lower Threshold Based weighted mean loss or gain statistics is to be studied in accordance with heavy tail conditions and to be applied in Insurance and HIV/VIH fields.
References
- Lo, G.S. (2013) The Generalized Poverty Index. Far East Journal of Theoretical Statistics, 42, 1-22. http://pphmj.com/journals/fjst.htm
- Artzner, P., Delbaen, F., Eber, J.M. and Heath, D. (1999) Coherent Measures of Risk. Mathematical Finance, 9, 203- 228. http://dx.doi.org/10.1111/1467-9965.00068
- Sen, A.K. (1976) Poverty: An Ordinal Approach to Measurement. Econometrica, 44, 219-231. http://dx.doi.org/10.2307/1912718
- Zheng, B. (1997) Aggregate Poverty Measures. Journal of Economic Surveys, 11, 123-162. http://dx.doi.org/10.1111/1467-6419.00028
- van der Vaart, A.W. and Wellner, J.A. (1996) Weak Convergence and Empirical Processes With Applications to Statistics. Springer, New York.
- Shorrocks, A.F. (1995) Revisiting the Sen Poverty Index. Econometrica, 63, 1225-1230. http://dx.doi.org/10.2307/2171728
- Thon, D. (1979) On Measuring Poverty. Review of Income and Wealth, 25, 429-440. http://dx.doi.org/10.1111/j.1475-4991.1979.tb00117.x
- Kakwani, N. (1980) On a Class of Poverty Measures. Econometrica, 48, 437-446. http://dx.doi.org/10.2307/1911106
- Sall, S.T. and Lo, G.S. (2009) Uniform Weak Convergence of the Time-Dependent Poverty Measure for Continuous Longitudinal Data. Brazilian Journal of Probability and Statistics, 24, 457-467. http://dx.doi.org/10.1214/08-BJPS101
- Lo, G.S. and Sall, S.T. (2009) Uniform Weak Convergence of Non Randomly Weighted Poverty Measures for Longitudinal Data. 57th ISI Session.
- Lo, G.S. and Sall, S.T. (2010) Asymptotic Representation Theorems for Poverty Indices. Afrika Statistika, 5, 238-244.
- Lo, G.S. (2010) A Simple Note on Some Empirical Stochastic Process as a Tool in Uniform L-Statistics Weak Laws. Afrika Statistika, 5, 245-251.
- Shorack, G.R. and Wellner, J.A. (1986) Empirical Processes with Applications to Statistics. Wiley-Interscience, New York.
Appendix
Put

with

and

We have first to prove that for ,
,
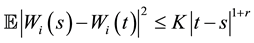
Based on the expression of  and on the facts that
and on the facts that 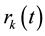 and
and  for
for 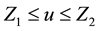 are uniformly bounded for
are uniformly bounded for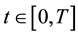 , it suffices to prove that
, it suffices to prove that
 (18)
(18)
for ,
,
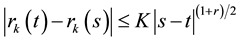 (19)
(19)
and
 (20)
(20)
This would help to conclude with the  that
that
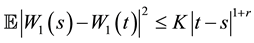 (21)
(21)
Let us establish (14). We have

where  lies between
lies between  and
and  and
and  lies between
lies between 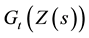 and
and . We then get
. We then get
 (22)
(22)
Now we show (15)

ince  is uniformly bounded, we have by (H0) and (H1),
is uniformly bounded, we have by (H0) and (H1),
 , (23)
, (23)
Further
 (24)
(24)
and, since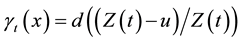 , we get that
, we get that
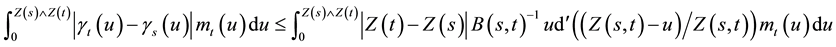 , (25)
, (25)
where  lies between
lies between 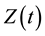 and
and . Then
. Then
 . (26)
. (26)
From (24)-(26), we conclude that
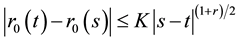 .
.
and for ,
,
 ,
,
and
 ,
,
with

and
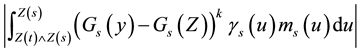
less than . Now
. Now 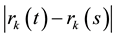 is less than
is less than  with
with
 ,
,
and
 .
.
By (H2), A is less than  and
and  by (24), (25) and (26). Then
by (24), (25) and (26). Then
for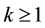 ,
,
 ,
,
which proves (15). Let us finally prove (16). We have by (H2), for a fixed ,
,
 ,
,
for some constant . Then by the
. Then by the 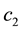 -inequality,
-inequality,
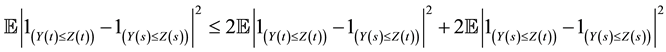 ,
,
with
 ,
,
and
 .
.
and then (16) holds.
By putting together (14), (15) and (16) and by repeatedly using the 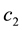 -inequality, we arrive at (21).
-inequality, we arrive at (21).
Now we have to establish that
 . (27)
. (27)
Put
 .
.
with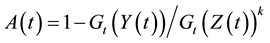 ,
, . We have by readily check that
. We have by readily check that
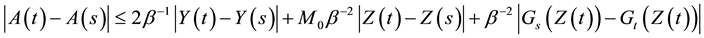 ,
,
Then by (H0)-(H3) and the 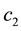 -inequality
-inequality
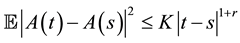 ,
,
Next
 ,
,
and

with
 ,
,
and

Then by (H2)
 ,
,
and
 .
.
Next, by putting ,
,
 ,
,
where  lies between (
lies between (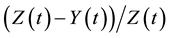 and
and . We finally get
. We finally get
 ,
,
By similar methods, we get
 .
.
By combining all that precedes, we get (27), which together with (21) establishes by the 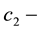 inequality
inequality
 . (28)
. (28)
Now we have to prove that
 .
.
We only sketch this second part. Let us consider ,
, . We have
. We have
 .
.
and
 .
.
By (14),(15) and the decomposition of  used in (25), we have
used in (25), we have
 .
.
Furthermore
 .
.
We then get
 .
.
Then
 .
.
Now
 ,
,
with
 .
.
Then

Since 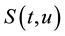 is uniformly bounded, we have
is uniformly bounded, we have
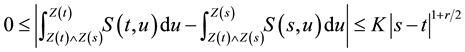 .
.
Moreover, one easily shows by the (H0)-(H3), with similar techniques used when handling , that
, that
 .
.
Thus
 .
.