Positioning
Vol.4 No.1(2013), Article ID:28433,20 pages DOI:10.4236/pos.2013.41010
Correction of Inertial Navigation System’s Errors by the Help of Video-Based Navigator Based on Digital Terrarium Map
![]()
Transist Video Ltd., Skolkovo Resident, Russia
Email: olegkup@yahoo.com
Received November 30th, 2012; revised December 31st, 2012; accepted January 11th, 2013
Keywords: Video-Based Navigator; Digital Terrarium Map; Autonomous Vehicles; Inertial Navigation
ABSTRACT
This paper deals with the error analysis of a novel navigation algorithm that uses as input the sequence of images acquired from a moving camera and a Digital Terrain (or Elevation) Map (DTM/DEM). More specifically, it has been shown that the optical flow derived from two consecutive camera frames can be used in combination with a DTM to estimate the position, orientation and ego-motion parameters of the moving camera. As opposed to previous works, the proposed approach does not require an intermediate explicit reconstruction of the 3D world. In the present work the sensitivity of the algorithm outlined above is studied. The main sources for errors are identified to be the optical-flow evaluation and computation, the quality of the information about the terrain, the structure of the observed terrain and the trajectory of the camera. By assuming appropriate characterization of these error sources, a closed form expression for the uncertainty of the pose and motion of the camera is first developed and then the influence of these factors is confirmed using extensive numerical simulations. The main conclusion of this paper is to establish that the proposed navigation algorithm generates accurate estimates for reasonable scenarios and error sources, and thus can be effectively used as part of a navigation system of autonomous vehicles.
1. Introduction
Vision-based algorithms has been a major research issue during the past decades. Two common approaches for the navigation problem are: landmarks and ego-motion integration. In the landmarks approach several features are located on the image-plane and matched to their known 3D location. Using the 2D and 3D data the camera’s pose can be derived. Few examples for such algorithms are [1, 2]. Once the landmarks were found, the pose derivation is simple and can achieve quite accurate estimates. The main difficulty is the detection of the features and their correct matching to the landmarks set.
In ego-motion integration approach the motion of the camera with respect to itself is estimated. The ego-motion can be derived from the optical-flow field, or from instruments such as accelerometers and gyroscopes. Once the ego-motion was obtained, one can integrate this motion to derive the camera’s path. One of the factors that make this approach attractive is that no specific features need to be detected, unlike the previous approach. Several ego-motion estimation algorithms can be found in [3-6]. The weakness of ego-motion integration comes from the fact that small errors are accumulated during the integration process. Hence, the estimated camera’s path is drifted and the pose estimation accuracy decrease along time. If such approach is used it would be desirable to reduce the drift by activating, once in a while, an additional algorithm that estimates the pose directly. In [7], such navigation-system is being suggested. In that work, like in this work, the drift is being corrected using a Digital Terrain Map (DTM). The DTM is a discrete representation of the observed ground’s topography. It contains the altitude over the sea level of the terrain for each geographical location. In [8] a patch from the ground was reconstructed using “structure-from-motion” (SFM) algorithm and was matched to the DTM in order to derive the camera’s pose. Using SFM algorithm which does not make any use of the information obtained from the DTM but rather bases its estimate on the flow-field alone, positions their technique under the same critique that applies for SFM algorithms [8].
The algorithm presented in this work does not require an intermediate explicit reconstruction of the 3D world. By combining the DTM information directly with the images information it is claimed that the algorithm is well-conditioned and generates accurate estimates for reasonable scenarios and error sources. In the present work this claim is explored by performing an error analysis on the algorithm outlined above. By assuming appropriate characterization of these error sources, a closed form expression for the uncertainty of the pose and motion of the camera is first developed and then the influence of different factors is studied using extensive numerical simulations.
Comparison of the corrected position of the object, measured by an independent navigation system DGPS, with the calculated position of the object would estimate the real effectiveness of navigation corrections. The correspondent investigation for described method was made during flight in Galilee in Israel [9]. The position error was about 25 meters and angle error was about 1.5 degree.
2. Problem Definition and Notations
The problem can be briefly described as follows: At any given time instance t, a coordinates system 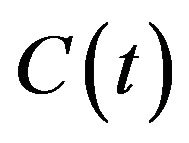 is fixed to a camera in such a way that the Z-axis coincides with the optical-axis and the origin coincides with the camera’s projection center. At that time instance the camera is located at some geographical location
is fixed to a camera in such a way that the Z-axis coincides with the optical-axis and the origin coincides with the camera’s projection center. At that time instance the camera is located at some geographical location 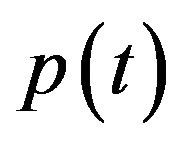 and has a given orientation
and has a given orientation 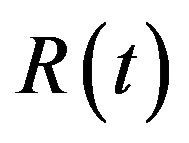 with respect to a global coordinates system W (
with respect to a global coordinates system W (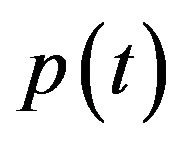 is a 3D vector,
is a 3D vector,  is an orthonormal rotation matrix).
is an orthonormal rotation matrix).  and
and  define the transformation from the camera’s frame
define the transformation from the camera’s frame  to the world’s frame W, where if
to the world’s frame W, where if 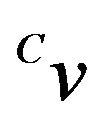 and
and 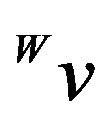 are vectors in
are vectors in 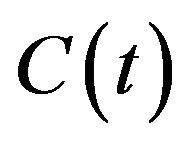 and W respectively, then
and W respectively, then
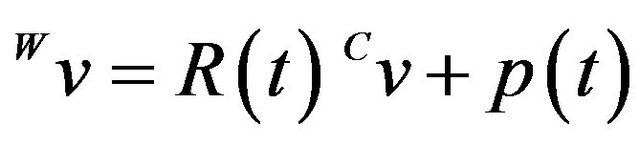 .
.
Consider now two sequential time instances t1 and t2: the transformation from 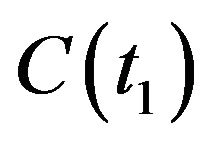 to
to 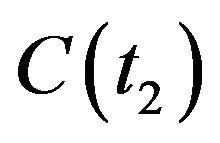 is given by the translation vector
is given by the translation vector 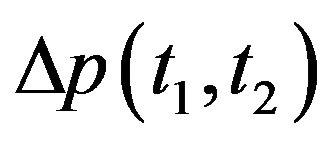 and the rotation matrix
and the rotation matrix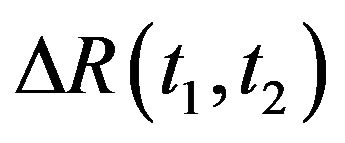 , such that
, such that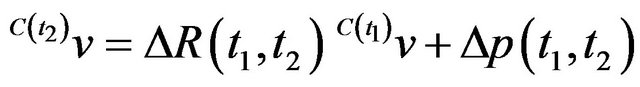 . A rough estimate of the camera’s pose at t1 and of the ego-motion between the two time instances—
. A rough estimate of the camera’s pose at t1 and of the ego-motion between the two time instances—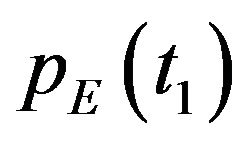 ,
, 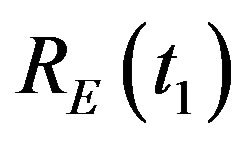 ,
, 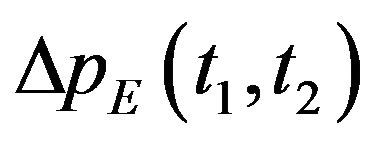 and
and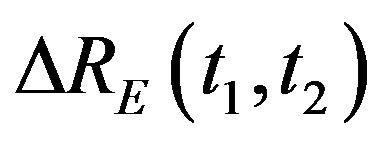 —are supplied (the subscript letter “E” denotes that this is an estimated quantity).
—are supplied (the subscript letter “E” denotes that this is an estimated quantity).
Also supplied is the optical-flow field: 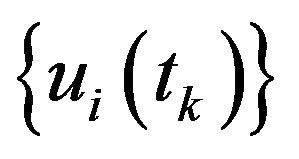
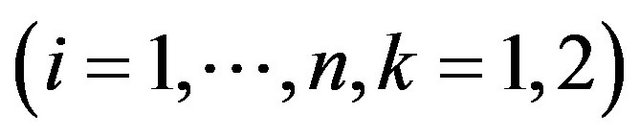 . For the i’th feature,
. For the i’th feature, 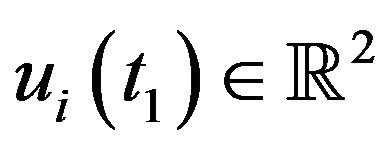 and
and 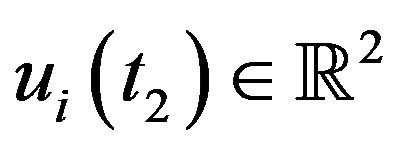 represent its locations at the first and second frame respectively.
represent its locations at the first and second frame respectively.
Using the above notations, the objective of the proposed algorithm is to estimate the true camera’s pose and ego-motion: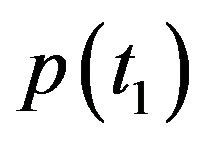 ,
, 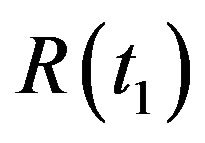 ,
, 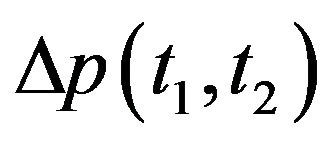 and
and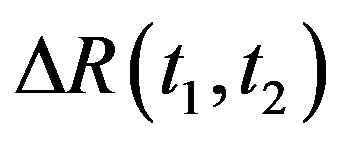 , using the optical-flow field
, using the optical-flow field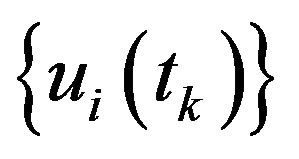 , the DTM and the initial-guess:
, the DTM and the initial-guess: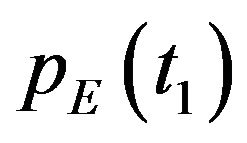 ,
, 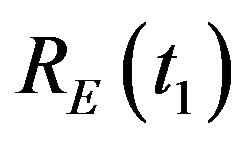 ,
, 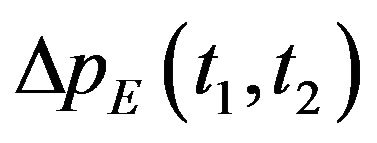 and
and 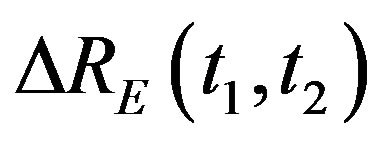 .
.
3. The Navigation Algorithm
The following section describes a navigation algorithm which estimate the above mentioned parameters. The pose and ego-motion of the camera are derived using a DTM and the optical-flow field of two consecutive frames. Unlike the landmarks approach no specific features should be detected and matched. Only the correspondence between the two consecutive images should be found in order to derive the optical-flow field. As was mentioned in the previous section, a rough estimate of the required parameters is supplied as an input. Nevertheless, since the algorithm only use this input as an initial guess and re-calculate the pose and ego-motion directly, no integration of previous errors will take place and accuracy will be preserved.
The new approach is founded on the following observation. Since the DTM supplies information about the structure of the observed terrain, depth of observed features is being dictated by the camera’s pose. Hence, given the pose and ego-motion of the camera, the opticalflow field can be uniquely determined. The objective of the algorithm will be finding the pose and ego-motion which lead to an optical-flow field as close as possible to the given flow field.
A single vector from the optical-flow field will be used to define a constraint for the camera’s pose and ego-motion. Let 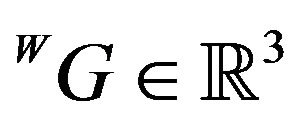 be a location of a ground feature point in the 3D world. At two different time instances t1 and t2, this feature point is projected on the image-plane of the camera to the points
be a location of a ground feature point in the 3D world. At two different time instances t1 and t2, this feature point is projected on the image-plane of the camera to the points 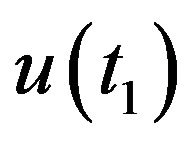 and
and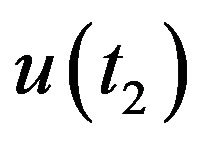 . Assuming a pinhole model for the camera, then
. Assuming a pinhole model for the camera, then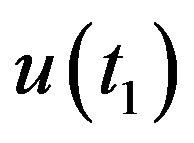 ,
,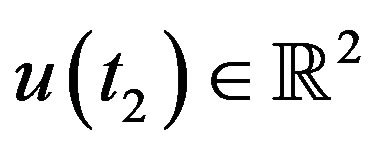 . Let
. Let 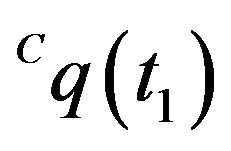 and
and 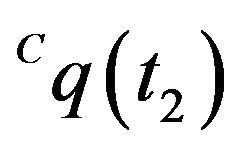 be the homogeneous representations of these locations. As standard, one can think of these vectors as the vectors from the optical-center of the camera to the projection point on the image plane. Using an initial-guess of the pose of the camera at t1, the line passing through
be the homogeneous representations of these locations. As standard, one can think of these vectors as the vectors from the optical-center of the camera to the projection point on the image plane. Using an initial-guess of the pose of the camera at t1, the line passing through  and
and 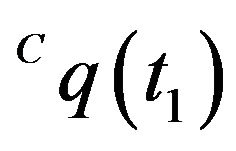 can be intersected with the DTM. Any ray-tracing style algorithm can be used for this purpose. The location of this intersection is denoted as
can be intersected with the DTM. Any ray-tracing style algorithm can be used for this purpose. The location of this intersection is denoted as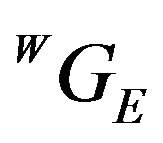 . The subscript letter “E” highlights the fact that this ground-point is the estimated location for the feature point, that in general will be different from the true ground-feature location
. The subscript letter “E” highlights the fact that this ground-point is the estimated location for the feature point, that in general will be different from the true ground-feature location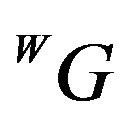 . The difference between the true and estimated locations is due to two main sources: the error in the initial guess for the pose and the errors in the determination of
. The difference between the true and estimated locations is due to two main sources: the error in the initial guess for the pose and the errors in the determination of 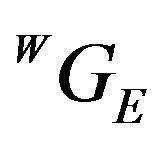 caused by DTM discretization and intrinsic errors. For a reasonable initial-guess and DTM-related errors, the two points
caused by DTM discretization and intrinsic errors. For a reasonable initial-guess and DTM-related errors, the two points 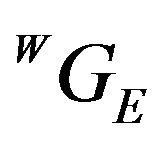 and
and 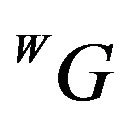 will be close enough so as to allow the linearization of the DTM around
will be close enough so as to allow the linearization of the DTM around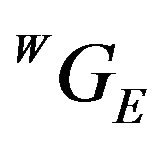 . Denoting by N the normal of the plane tangent to the DTM at the point
. Denoting by N the normal of the plane tangent to the DTM at the point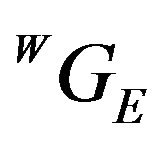 , one can write:
, one can write:
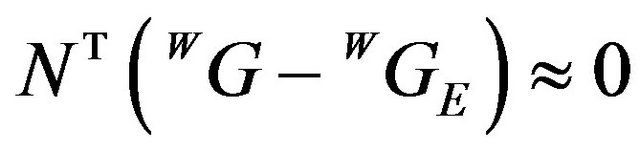 . (1)
. (1)
The true ground feature 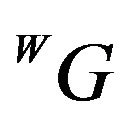 can be described using true pose parameters:
can be described using true pose parameters:
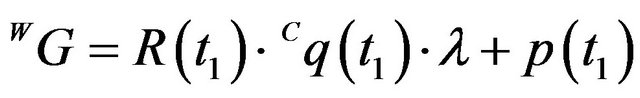 . (2)
. (2)
Here, ![]() denotes the depth of the feature point (i.e. the distance of the point to the image plane projected on the optical-axis). Replacing (2) in (1):
denotes the depth of the feature point (i.e. the distance of the point to the image plane projected on the optical-axis). Replacing (2) in (1):
.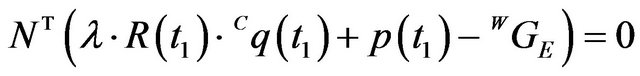 (3)
(3)
From this expression, the depth of the true feature can be computed using the estimated feature location:
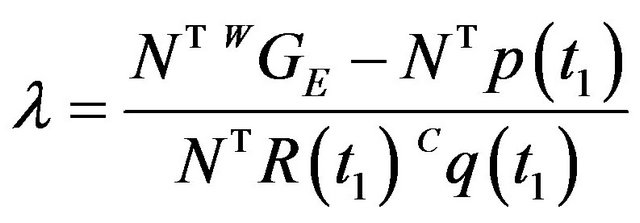 . (4)
. (4)
By plugging (4) back into (2) one gets:
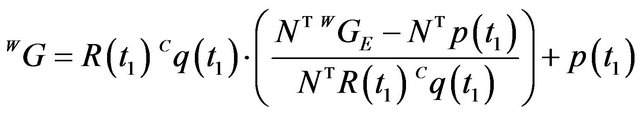 . (5)
. (5)
In order to simplify notations, 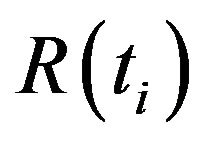 will be replaced by
will be replaced by 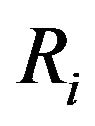 and likewise for
and likewise for 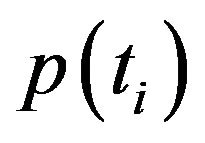 and
and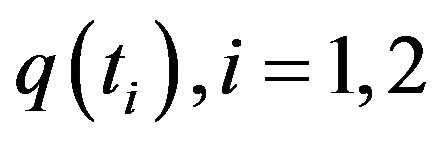 .
. 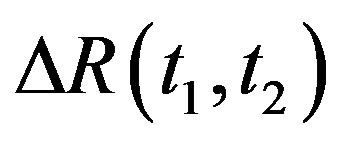 and
and 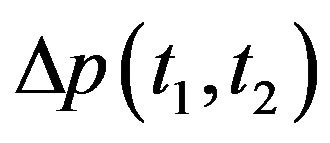 will be replaced by
will be replaced by 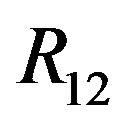 and
and 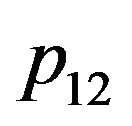 respectively. The superscript describing the coordinate frame in which the vector is given will also be omitted, except for the cases were special attention needs to be drawn to the frames. Normally,
respectively. The superscript describing the coordinate frame in which the vector is given will also be omitted, except for the cases were special attention needs to be drawn to the frames. Normally, 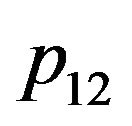 and q’s are in camera's frame while the rest of the vectors are given in the world's frame. Using the simplified notations, (5) can be rewritten as:
and q’s are in camera's frame while the rest of the vectors are given in the world's frame. Using the simplified notations, (5) can be rewritten as:
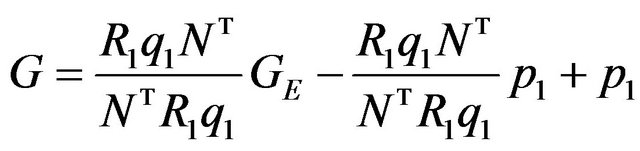 . (6)
. (6)
In order to obtain simpler expressions, define the following projection operator:
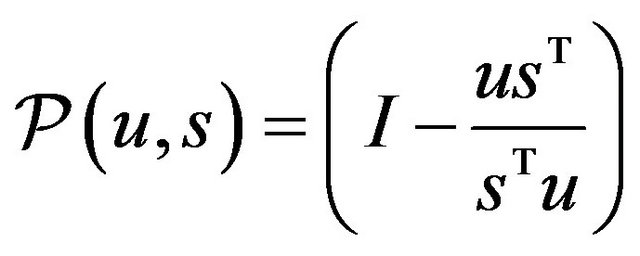 . (7)
. (7)
This operator projects a vector onto the subspace normal to![]() , along the direction of
, along the direction of![]() . As an illustration, it is easy to verify that
. As an illustration, it is easy to verify that 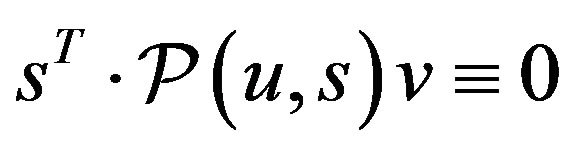 and
and 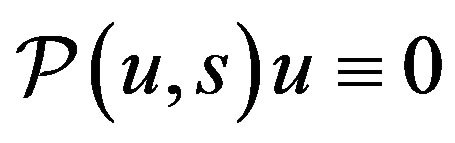 . By adding and subtracting
. By adding and subtracting 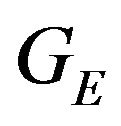 to (6), and after reordering:
to (6), and after reordering:
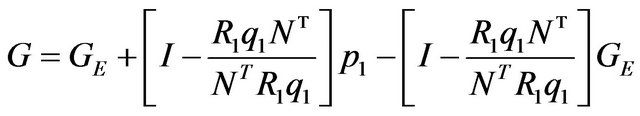 . (8)
. (8)
Using the projection operator, (8) becomes:
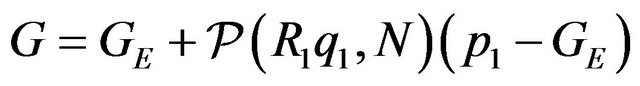 . (9)
. (9)
The above expression has a clear geometric interpretation (see Figure 1). The vector from GE to p1 is being projected onto the tangent plane. The projection is along the direction R1q1, which is the direction of the ray from the camera’s optical-center (p1), passing through the image feature.
Our next step will be transferring G from the global coordinates frame-W into the first camera’s frame C1 and then to the second camera’s frame C2. Since p1 and R1 describe the transformation from C1 into W, we will use the inverse transformation:
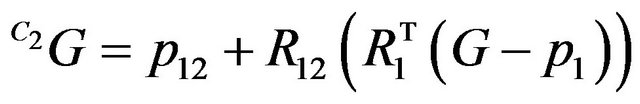 . (10)
. (10)
Assigning (9) into (10) gives:
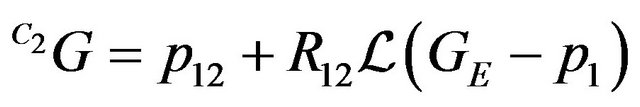 . (11)
. (11)
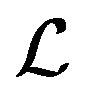 in the above expression represents:
in the above expression represents:
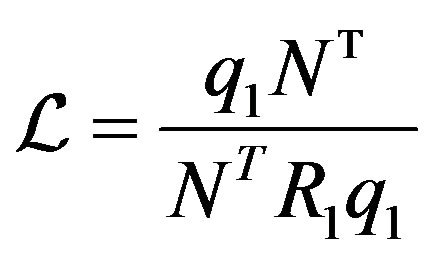 . (12)
. (12)
One can think of 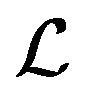 as an operator with inverse characteristic to
as an operator with inverse characteristic to : it projects vectors on the ray continuing R1q1 along the plane orthogonal to N.
: it projects vectors on the ray continuing R1q1 along the plane orthogonal to N.
q2 is the projection of the true ground-feature G. Thus, the vectors q2 and 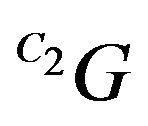 should coincide. This observation can be expressed mathematically by projecting
should coincide. This observation can be expressed mathematically by projecting 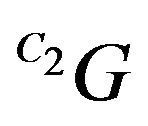 on the ray continuation of q2:
on the ray continuation of q2:
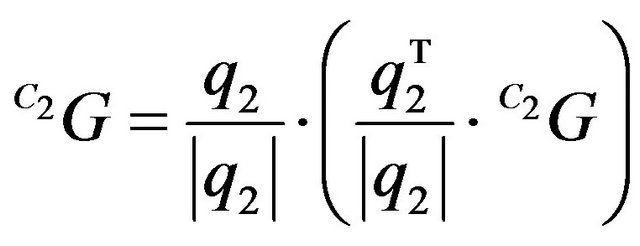 . (13)
. (13)
In expression (13), 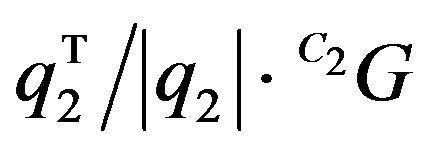 is the magnitude of
is the magnitude of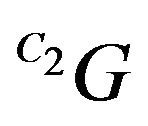 ’s projection on q2. By reorganizing (13) and using
’s projection on q2. By reorganizing (13) and using
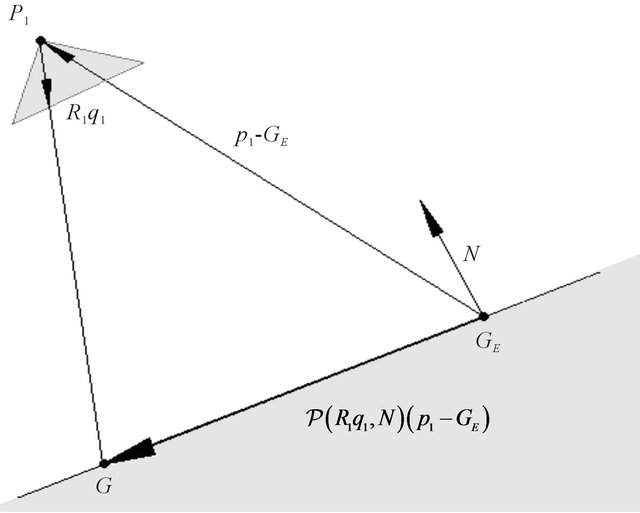
Figure 1. Geometrical description of expression (9) using the projection operator (7).
the projection operator, we obtain:
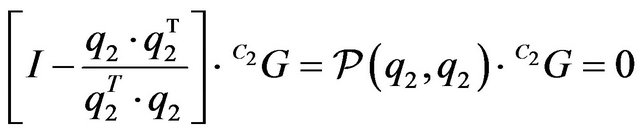 (14)
(14)
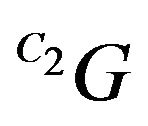 is being projected on the orthogonal complement of q2. Since
is being projected on the orthogonal complement of q2. Since 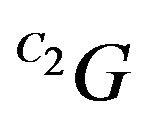 and q2 should coincide, this projection should yield the zero-vector. Plugging (11) into (14) yields our final constraint:
and q2 should coincide, this projection should yield the zero-vector. Plugging (11) into (14) yields our final constraint:
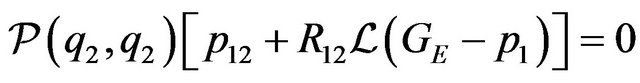 (15)
(15)
This constraint involves the position, orientation and the ego-motion defining the two frames of the camera. Although it involves 3D vectors, it is clear that its rank can not exceed two due to the usage of  which projects
which projects  on a two-dimensional subspace.
on a two-dimensional subspace.
Such constraint can be established for each vector in the optical-flow field, until a non-singular system is obtained. Since twelve parameters need to be estimated (six for pose and six for the ego-motion), at least six opticalflow vectors are required for the system solution. But it is correct conclusion for nonlinear problem. If we use Gauss-Newton iterations method and so make linearization of our problem near approximate solution. The found matrix will be always singular for six points (with zero determinant) as numerical simulations demonstrate. So it is necessary to use at least seven points to obtain nonsingular linear approximation. Usually, more vectors will be used in order to define an over-determined system, which will lead to more robust solution. The reader attention is drawn to the fact that a non-linear constraint was obtained. Thus, an iterative scheme will be used in order to solve this system. A robust algorithm which uses Gauss-Newton iterations and M-estimator is described in [10]. We begin to use Levenberg-Marquardt method if Gauss-Newton method after several iterations stopped to converge. This two algorithms are realized in lsqnonlin() Matlab function. The applicability, accuracy and robustness of the algorithm was verified though simulations and lab-experiments.
It is more convenient to use more robust for iterations equivalent to (15) equation:
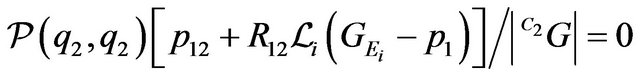 (16)
(16)
Using of this normalized form of equations avoids to get incorrect trivial solution when two positions are in a single point on the ground.
3.1. Multiple Features
Suppose next that n feature points are tracked in two frames, so that the estimated locations  and projections onto the image plane
and projections onto the image plane 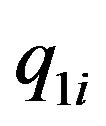 and
and 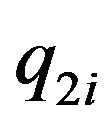 are estimated and measured, respectively, for
are estimated and measured, respectively, for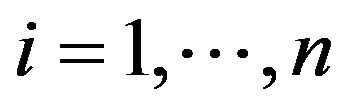 . Associated with each
. Associated with each  is the normal vector to the DTM at this point, namely
is the normal vector to the DTM at this point, namely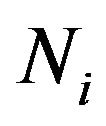 .
.
Taking this into account, one can rewrite (15) in matrix form as:
 (17)
(17)
Repeating this for each feature point:
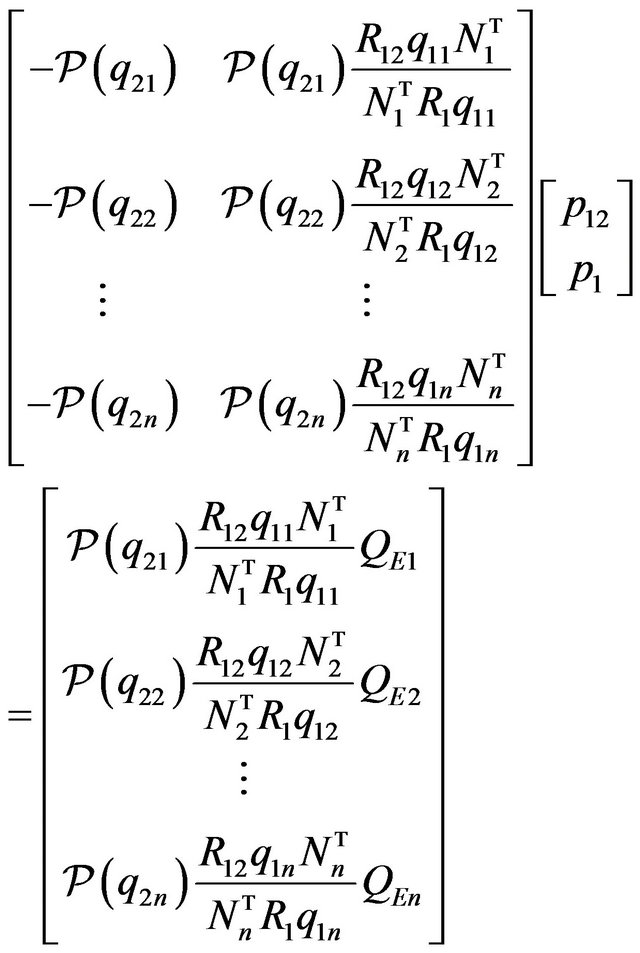 (18)
(18)
In compact notation:
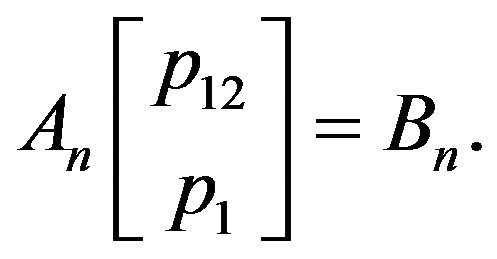 (19)
(19)
Note that 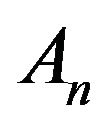 and
and 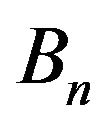 depend on known quantities: the estimated features, the normals of the DTM tangent planes, and the images of the features at the two time instances, together with the unknown orientation
depend on known quantities: the estimated features, the normals of the DTM tangent planes, and the images of the features at the two time instances, together with the unknown orientation 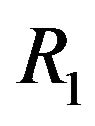 and the relative rotation
and the relative rotation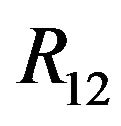 . At this point in our discussion, several remarks are in order.
. At this point in our discussion, several remarks are in order.
Remark 1: The constraint (18) involves twelve “unknowns”, namely the pose and ego-motion of the camera. From the remark at the end of the previous section, the equation involves at most 2n linearly independent constraints, so that at least six features at different locations  are required to have a determinate system of equations. But it is correct conclusion for nonlinear problem. If we use Gauss-Newton iterations method and so make linearization of our problem near approximate solution. The found matrix will be always singular for six points (with zero determinant) as numerical simulations demonstrate. So it is necessary to use at least seven points to obtain nonsingular linear approximation. Usually, more vectors will be used in order to define an over-determined system, and hence reduce the effect of noise. Clearly, there are degenerate scenarios in which the obtained system is singular, no matter what is the number of available features. Examples for such scenarios include flying above completely planar or spherical terrain. However, in the general case where the terrain has “interesting” structure the system is non-singular and the twelve parameters can be obtained.
are required to have a determinate system of equations. But it is correct conclusion for nonlinear problem. If we use Gauss-Newton iterations method and so make linearization of our problem near approximate solution. The found matrix will be always singular for six points (with zero determinant) as numerical simulations demonstrate. So it is necessary to use at least seven points to obtain nonsingular linear approximation. Usually, more vectors will be used in order to define an over-determined system, and hence reduce the effect of noise. Clearly, there are degenerate scenarios in which the obtained system is singular, no matter what is the number of available features. Examples for such scenarios include flying above completely planar or spherical terrain. However, in the general case where the terrain has “interesting” structure the system is non-singular and the twelve parameters can be obtained.
Remark 2: The constraint (18) is non-linear and, therefore, no analytic solution to it is readily available. Thus, an iterative scheme will be used in order to solve this system. A robust algorithm using Newton-iterations and M-estimator will be described in following sections.
Remark 3: Given Remark 2, one observes that the location and translation appear linearly in the constraint. Using the pseudo-inverse, these two vectors can be solved explicitly to give:
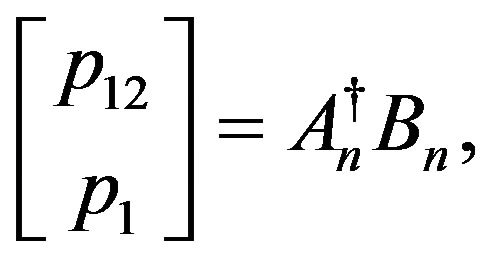 (20)
(20)
so that, after resubstituting in (19):
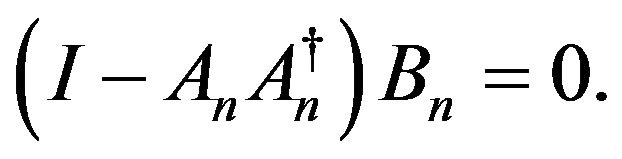 (21)
(21)
This remark leads to two conclusions:
1) If the rotation is known to good accuracy and measurement noise is relatively low, then the position and translation can be determined by solving a linear equation. This fact may be relevant when “fusing” the procedure described here with other measurement, e.g., with inertial navigation.
2) Equation (21) shows that the estimation of rotation (both absolute and relative) can be separated from that of location/translation. This fact is also found when estimating pose from a set of visible landmarks as shown in [11]. In that work, similarly to the present, the estimate is obtained by minimizing an objective function which measures the errors in the object-space rather than on the image plane (as in most other works). This property enables the decoupling of the estimation problem. Note however that [11] address’s only the pose rotation and translation decoupling while here the 6 parameters of absolute and relative rotations are separated from the 6 parameters of the camera location and translation.
3.2. The Epipolar Constraint Connection
Before proceeding any further, it is interesting to look at (15) in the light of previous work in SFM and, in particular, epipolar geometry. In order to do this, it is worth deriving the basic constraint in the present framework and notation. Write:
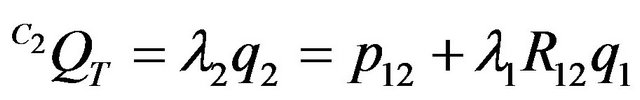 (22)
(22)
for some scalars 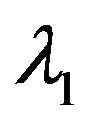 and
and 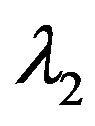 (see Figure 2).
(see Figure 2).
It follows that:
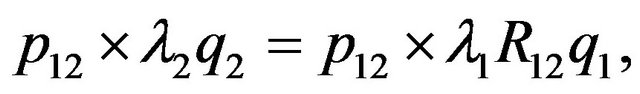 (23)
(23)
and hence:
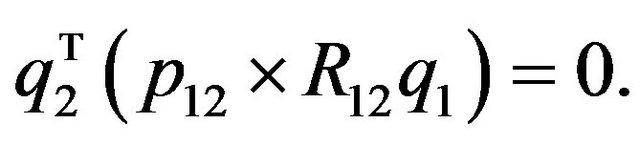 (24)
(24)
For a vector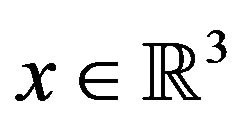 , let
, let 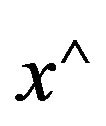 denote the skew-symmetric matrix:
denote the skew-symmetric matrix:
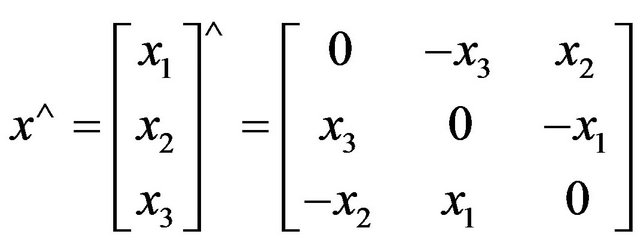
Then, it is well known that the vector product between two vectors x and y can be expressed as:
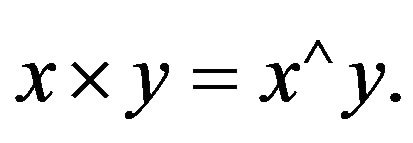
Using this notation, the epipolar constraint (24) can be written as:
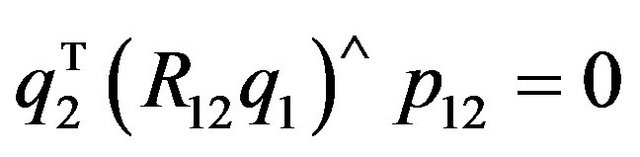 (25)
(25)
and symmetrically as:
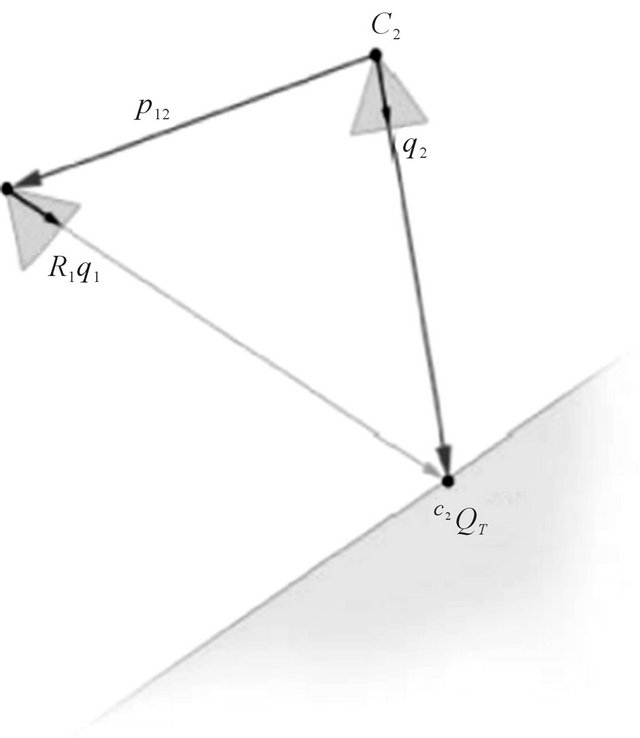
Figure 2. The examined scenario from the second camera frame’s (C2) point of view. q2 is the perspective projection of the terrain feature , and thus the two should coincide. Additionally, since q1 is also a projection of the same feature in the C1-frame, the epipolar constraint requires that the two rays (one in the direction of q2 and the other from p12 in the direction of R12q1) will intersect.
, and thus the two should coincide. Additionally, since q1 is also a projection of the same feature in the C1-frame, the epipolar constraint requires that the two rays (one in the direction of q2 and the other from p12 in the direction of R12q1) will intersect.
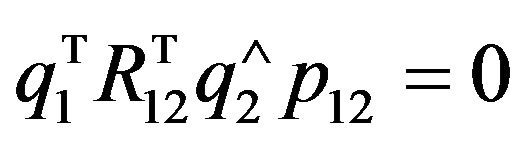 . (26)
. (26)
The important observation here is that if the vector 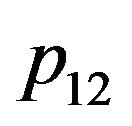 verifies the above constraint, then the vector
verifies the above constraint, then the vector 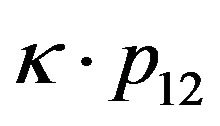 also verifies the constraint, for any number
also verifies the constraint, for any number![]() . This is an expression of the ambiguity built into the SFM problem. On the other hand, the constraint (15) is non-homogeneous and hence does not suffer from the same ambiguity. In terms of the translation alone (and for only one feature point!), if p12 verifies (15) for given R1 and R12, then also
. This is an expression of the ambiguity built into the SFM problem. On the other hand, the constraint (15) is non-homogeneous and hence does not suffer from the same ambiguity. In terms of the translation alone (and for only one feature point!), if p12 verifies (15) for given R1 and R12, then also 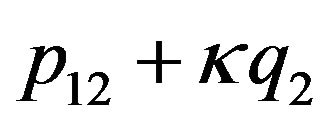 will verify the constraint, and hence the egomotion translation is defined up to a one-dimensional vector. However, one has the following trivially:
will verify the constraint, and hence the egomotion translation is defined up to a one-dimensional vector. However, one has the following trivially:
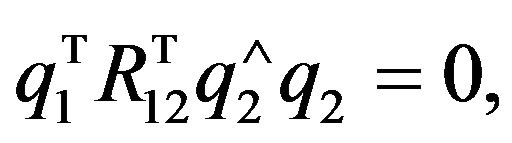 (27)
(27)
and hence the epipolar constraint does not provide an additional equation that would allow us to solve for the translation in a unique manner. Moreover, observe that (15) can be written using a vector product instead of the projection operator as:
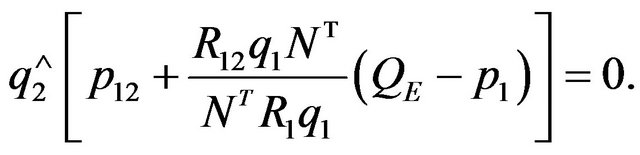 (28)
(28)
Taking into account the identity
 (29)
(29)
it is possible to conclude that (28) ® (26), and hence the new constraint “contains” the classical epipolar geometry. Indeed, one could think of the constraint derived in (15) as strengthening the epipolar constraint by requiring not only that the two rays (in the directions of q1 and q2) should intersect, but, in addition, that this intersection point should lie on the DTM’s linearization plane. Observe, moreover, that taking more than one feature point would allow us to completely compute the translation (at least for the given rotation matrices).
4. Vision-Based Navigation Algorithm Corrections for Inertial Navigation by Help of Kalman Filter
Vision-based navigation algorithms has been a major research issue during the past decades. Algorithm used in this paper is based on foundations of multiple-view geometry and a land map. By help of this method we get position and orientation of a observer camera. On the other hand we obtain the same data from inertial navigation methods. To adjust these two results Kalman filter is used. We employ in this paper extended Kalman filter for nonlinear equations [12].
For inertial navigation computations was used Inertial Navigation System Toolbox for Matlab [13].
Input of Kalman filter consists of two part. The first one is variables X for equations of motion. In our case it is inertial navigation equations. Vector X consists of fifteen components:
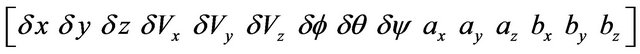 .
.
Coordinates 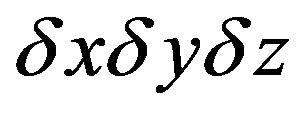 are defined by difference between real position of the camera and position gotten from inertial navigation calculus.Variables
are defined by difference between real position of the camera and position gotten from inertial navigation calculus.Variables 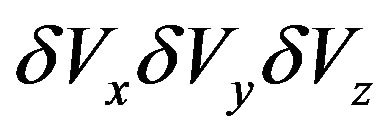 are defined by difference between real velocity of the camera and velocity gotten from inertial navigation calculus. Variable
are defined by difference between real velocity of the camera and velocity gotten from inertial navigation calculus. Variable  are defined as Euler angles of matrix
are defined as Euler angles of matrix 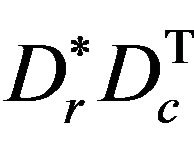 where
where 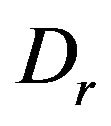 is matrix defined by real Euler angles of camera with respect to Local Level Frame (L-Frame) and
is matrix defined by real Euler angles of camera with respect to Local Level Frame (L-Frame) and 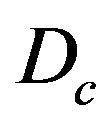 is matrix defined by Euler angles of camera with respect to Local Level Frame (L-Frame) gotten by inertial navigation computation. It is necessary to pay attention that found Euler angles
is matrix defined by Euler angles of camera with respect to Local Level Frame (L-Frame) gotten by inertial navigation computation. It is necessary to pay attention that found Euler angles  ARE NOT equivalent to difference between real Euler angles and Euler angles gotten from inertial navigation calculus. For small values of
ARE NOT equivalent to difference between real Euler angles and Euler angles gotten from inertial navigation calculus. For small values of  perturbations to these angles can be added linearly and so these angles can be used in Kalman filter for small errors. Such choose of angles is made because formulas describing their evolution are much simpler than formulas describing evolution of Euler angles differences. Variables
perturbations to these angles can be added linearly and so these angles can be used in Kalman filter for small errors. Such choose of angles is made because formulas describing their evolution are much simpler than formulas describing evolution of Euler angles differences. Variables  are defined by vector of Accel bias in inertial navigation measurements. Variables
are defined by vector of Accel bias in inertial navigation measurements. Variables  are defined by vector of Gyro bias in inertial navigation measurements.
are defined by vector of Gyro bias in inertial navigation measurements.
The second input of Kalman filter is Z-result of measurements by vision-based navigation algorithms. Vector Z consists of six components 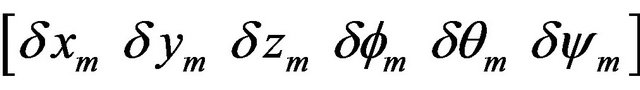 Coordinates
Coordinates 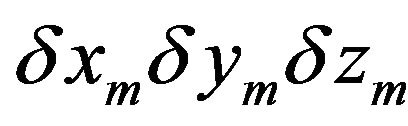 are difference between camera position measured by vision-based navigation algorithm and position gotten from inertial navigation calculus. Variable
are difference between camera position measured by vision-based navigation algorithm and position gotten from inertial navigation calculus. Variable 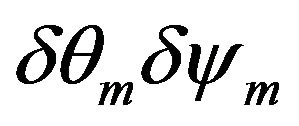 are defined as Euler angles of matrix
are defined as Euler angles of matrix 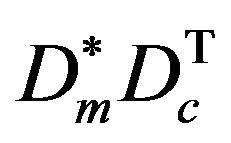 where
where 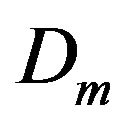 is matrix defined by Euler angles of camera with respect to Local Level Frame (L-Frame) measured by vision-based navigation algorithm and
is matrix defined by Euler angles of camera with respect to Local Level Frame (L-Frame) measured by vision-based navigation algorithm and 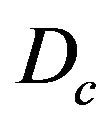 is matrix defined by Euler angles of camera with respect to Local Level Frame (LFrame) gotten by inertial navigation computation. Let variable k to be number of step for time discretization used in Kalman filter.
is matrix defined by Euler angles of camera with respect to Local Level Frame (LFrame) gotten by inertial navigation computation. Let variable k to be number of step for time discretization used in Kalman filter.
We assume that errors for between values gotten by inertial navigation computation and real values are linearly depend on noise. Corespondent process noise covariance matrix is denoted by Qk. Diagonal elements of Qk correspondent to velocity are defined by Accel noise and proportional to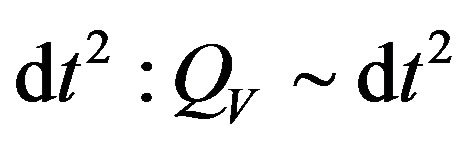 , where dt is time interval between tk and
, where dt is time interval between tk and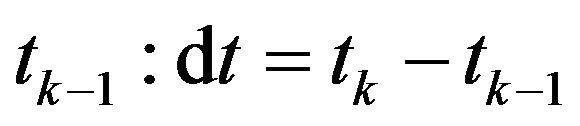 . Diagonal elements of Qk correspondent to Euler angles are defined by Gyro noise and proportional to
. Diagonal elements of Qk correspondent to Euler angles are defined by Gyro noise and proportional to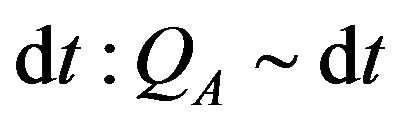 .
.
We assume that errors for between values gotten by vision-based navigation algorithm and real values are linearly depend on noise. Corespondent measurement noise covariance matrix is denoted by Rk. Error analysis giving this matrix is described in [14].
Kalman filter equations describe evolution of a posteriori state estimation Xk described above and a posteriori error covariation covariance matrix Pk for variables Xk.
To write Kalman filter equations we must define two 15 × 15 matrices yet: Hk and Ak. Matrix Hk is measurement Jacobian describing connection between predicted measurement 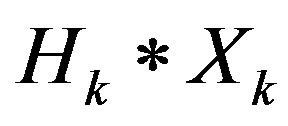 and actual measurement Zk defined above. Diagonal elements
and actual measurement Zk defined above. Diagonal elements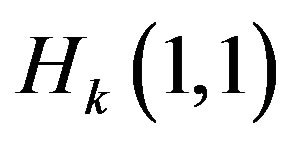 ,
,  ,
, 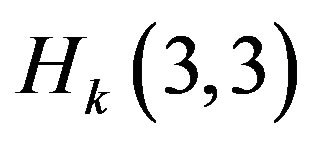 describing coordinate and elements
describing coordinate and elements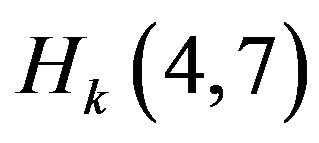 ,
, 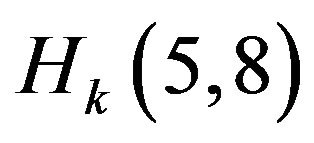 ,
, 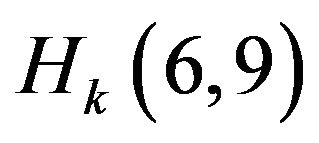 describing angles are equal to one. The rest of the elements are equal to zero.
describing angles are equal to one. The rest of the elements are equal to zero.
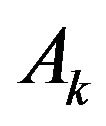 is Jacobian matrix describing evolution of vector
is Jacobian matrix describing evolution of vector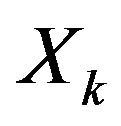 . The exact expression for this matrix is very difficult so we use approximate formula for
. The exact expression for this matrix is very difficult so we use approximate formula for 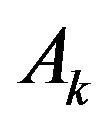 neglecting by Coriolis effects, Earth rotation and so on. Let
neglecting by Coriolis effects, Earth rotation and so on. Let 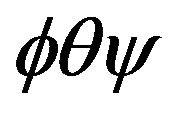 be the Euler angles in L-Frame,
be the Euler angles in L-Frame, 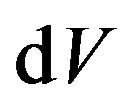 is deltaV vector gotten from inertial navigation measurements,
is deltaV vector gotten from inertial navigation measurements, 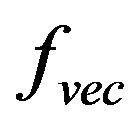 is acceleration vector in L-frame,
is acceleration vector in L-frame, 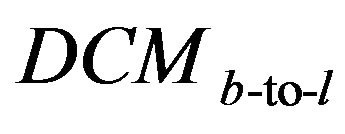 is direction cosine matrix (from body-frame to L-frame).
is direction cosine matrix (from body-frame to L-frame).
The formulas defining 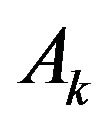 are follow:
are follow:
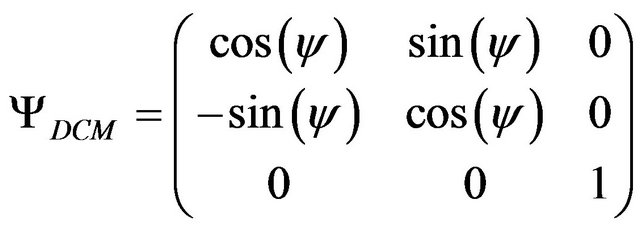 (30)
(30)
 (31)
(31)
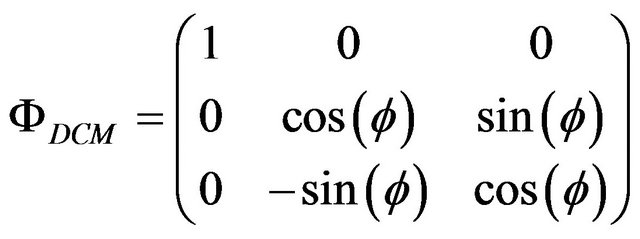 (32)
(32)
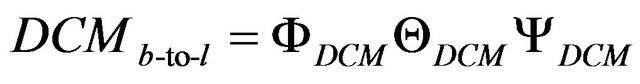 (33)
(33)
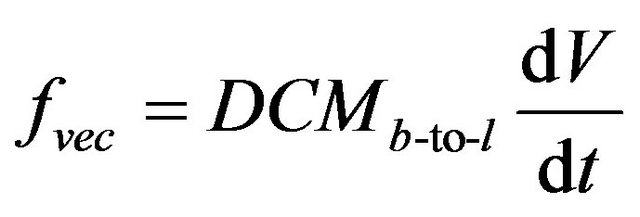 (34)
(34)
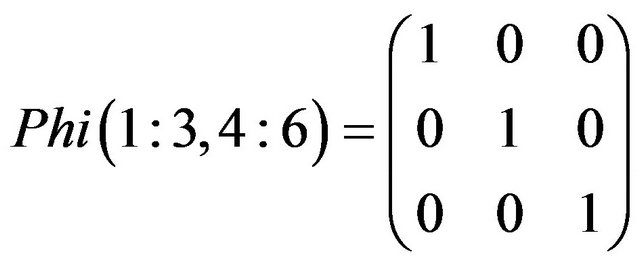 (35)
(35)
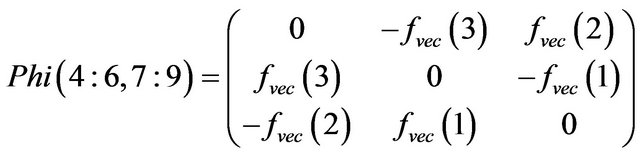 (36)
(36)
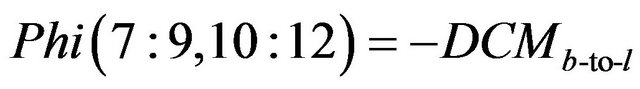 (37)
(37)
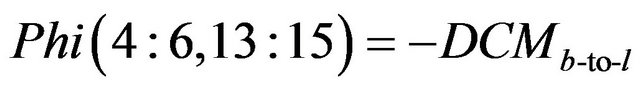 (38)
(38)
The rest of elements for matrix Phi are equal to zero.
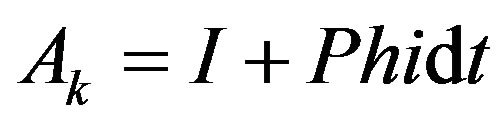 (39)
(39)
Kalman filter time update equations are follow:
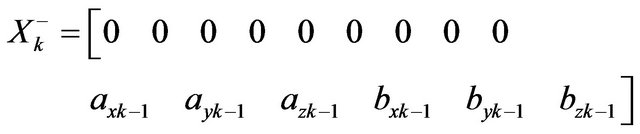 (40)
(40)
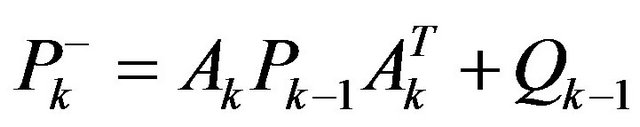 (41)
(41)
Kalman filter update equations project the state and covariance estimates from the previous time step 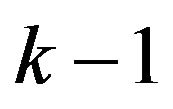 to the current time step k.
to the current time step k.
Kalman filter measurement update equations are follow:
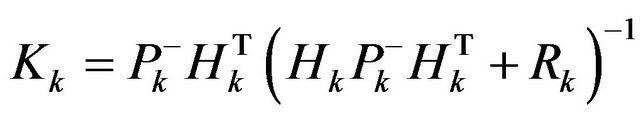 (42)
(42)
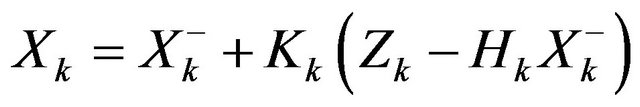 (43)
(43)
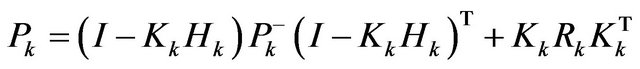 (44)
(44)
Kalman filter measurement update equations correct the state and covariance estimates with measurement .
.
The found vector 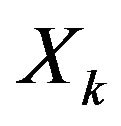 is used to update coordinates, velocities, Euler angles, Accel and Gyro biases for inertial navigation calculations on the next step.
is used to update coordinates, velocities, Euler angles, Accel and Gyro biases for inertial navigation calculations on the next step.
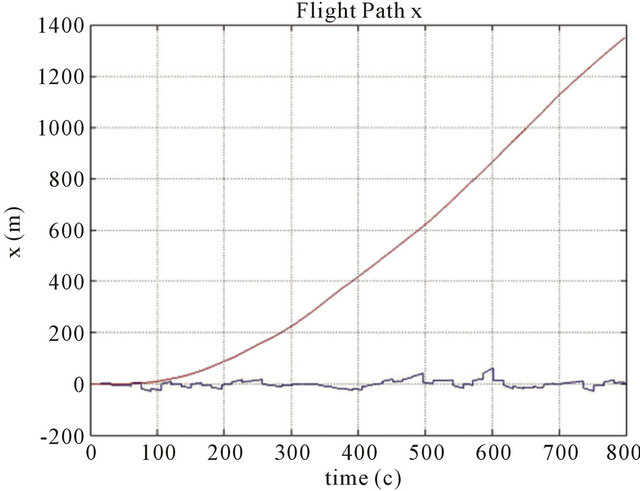
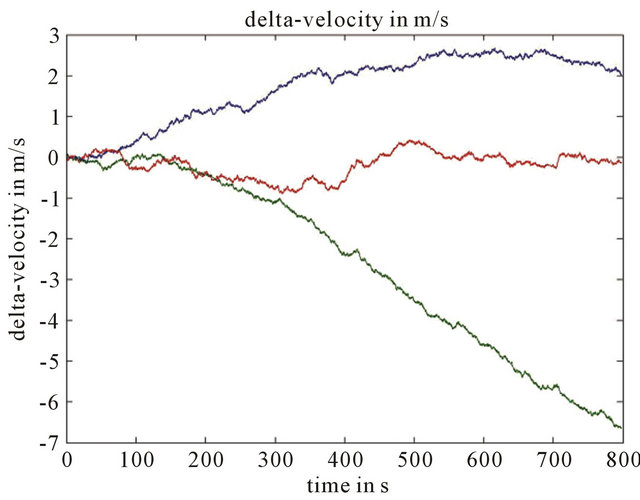
Numerical simulations were realized to examine effectiveness of Kalman filter to combine these two navigation algorithms. On Figures 3-5 we can see that corrected path for coordinate error much smaller than inertial navigation coordinate error without Kalman filter. Improved results by help Kalman filter are gotten also for velocity in spite of the fact that this velocity was not measured by help vision-based navigation algorithm (Figure 6).
5. Error Analysis
The rest of this work deals with the error-analysis of the proposed algorithm. In order to evaluate the algorithm’s performance, the objective-function of the minimization process needs to be defined first: For each of the n optical-flow vectors, the function 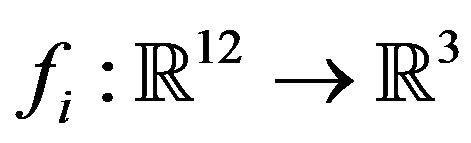 is defined as the left-hand side of the constraint described in (16):
is defined as the left-hand side of the constraint described in (16):
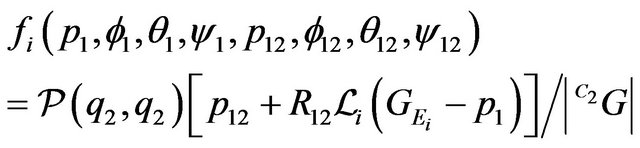 (45)
(45)
In the above expression, 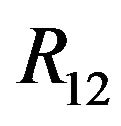 and
and 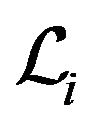 are functions of
are functions of 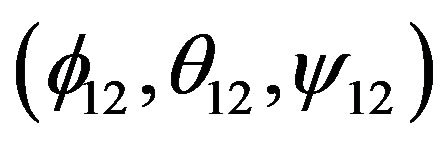 and
and 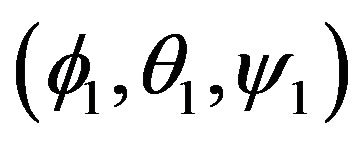 respectively. Additionally, the function
respectively. Additionally, the function 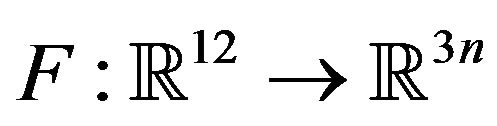 will be defined as the concatenation of the
will be defined as the concatenation of the 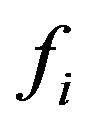 functions:
functions:
 . According to these notations, the goal of the algorithm is to find the twelve parameters that minimize
. According to these notations, the goal of the algorithm is to find the twelve parameters that minimize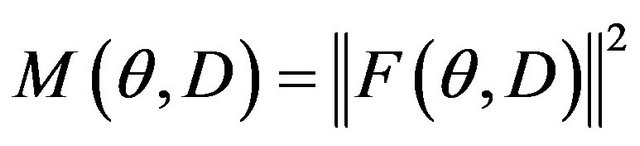 , where θ represents the 12-vector of the parameters to be estimated, and D is the concatenation of all the data obtain from the optical-flow and the DTM. If D would have been free of errors, the true parameters were obtained. Since D contains some error perturbation, the estimated parameters are drifted to erroneous values. It has been shown in [15] that the connection between the uncertainty of the data and the uncertainty of the estimated parameters can be described by the following first-order approximation:
, where θ represents the 12-vector of the parameters to be estimated, and D is the concatenation of all the data obtain from the optical-flow and the DTM. If D would have been free of errors, the true parameters were obtained. Since D contains some error perturbation, the estimated parameters are drifted to erroneous values. It has been shown in [15] that the connection between the uncertainty of the data and the uncertainty of the estimated parameters can be described by the following first-order approximation:
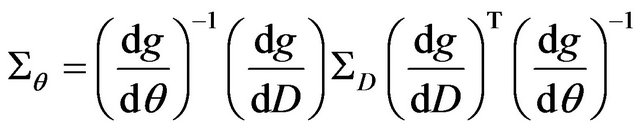 (46)
(46)
Here, 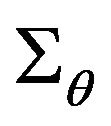 and
and 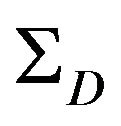 represent the covariance matrices of the parameters and the data respectively. g is defined as follows:
represent the covariance matrices of the parameters and the data respectively. g is defined as follows:
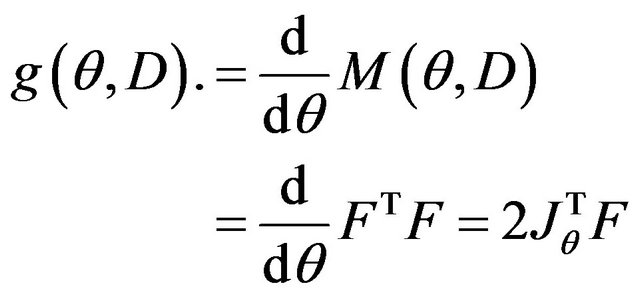 (47)
(47)
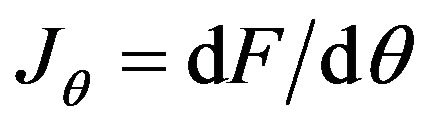 is the (3n × 12) Jacobian matrix of F with respect to the twelve parameters. By ignoring second-order elements, the derivations of g can be approximate by:
is the (3n × 12) Jacobian matrix of F with respect to the twelve parameters. By ignoring second-order elements, the derivations of g can be approximate by:
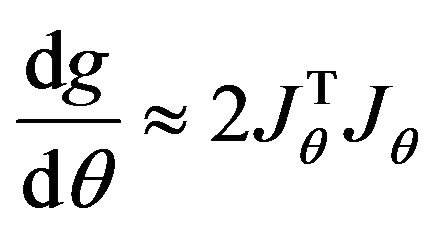 (48)
(48)
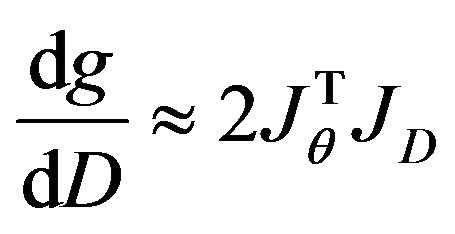 (49)
(49)
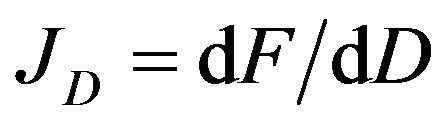 is defined in a similar way as the (3n × m) Jacobian matrix of F with respect to the m data components. Assigning (48) and (49) back into (46) yield the following expression:
is defined in a similar way as the (3n × m) Jacobian matrix of F with respect to the m data components. Assigning (48) and (49) back into (46) yield the following expression:
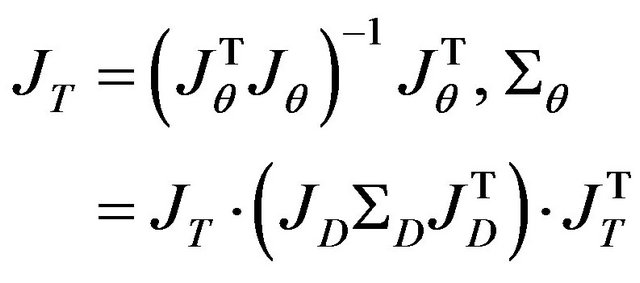 (50)
(50)
The central component 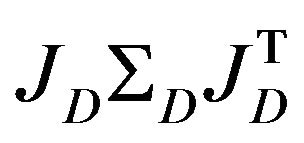 represents the uncertainties of F while the pseudo-inverse matrix
represents the uncertainties of F while the pseudo-inverse matrix 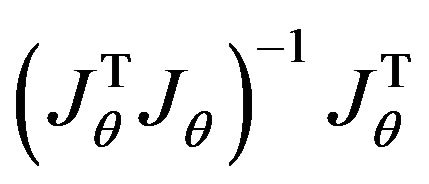 transfers the uncertainties of F to those of the twelve parameters. In the following subsections,
transfers the uncertainties of F to those of the twelve parameters. In the following subsections, 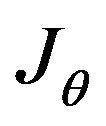 ,
,  and
and 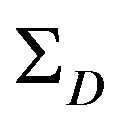 are explicitly derived.
are explicitly derived.
 (a)
(a)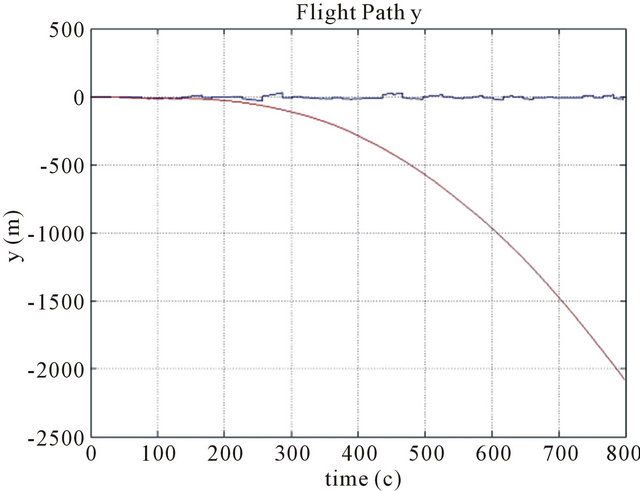 (b)
(b)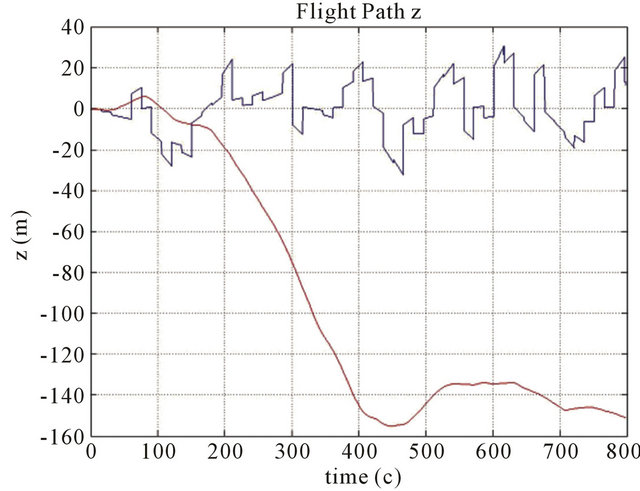 (c)
(c)
Figure 3. Position errors ((a) for x coordinate (b) for y coordinate (c) for z coordinate) of the drift path are marked with a red line, and errors of the corrected path are marked with a blue line. Parameters: Height 1000 m, FOV 60 degree, Features number 120, Resolution 1000 × 1000, Baseline = 200 m, ∆time = 15 s.
 (a)
(a)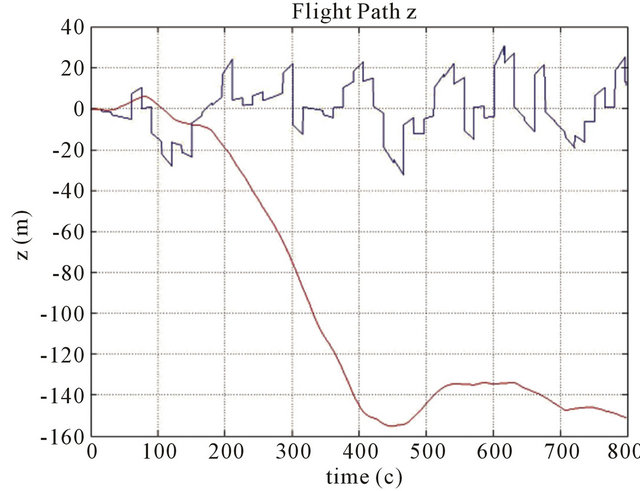 (b)
(b)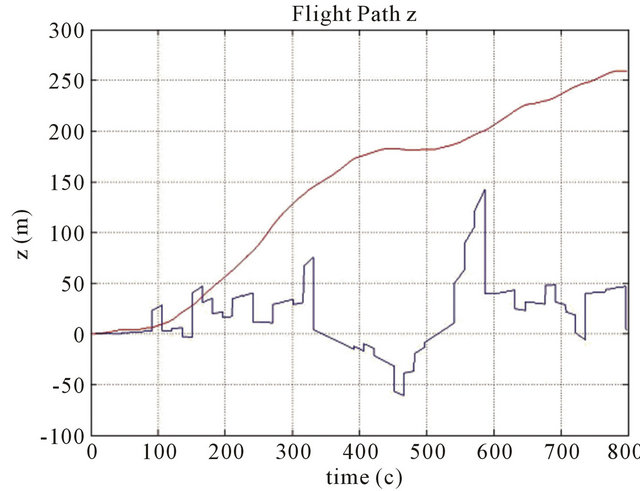 (c)
(c)
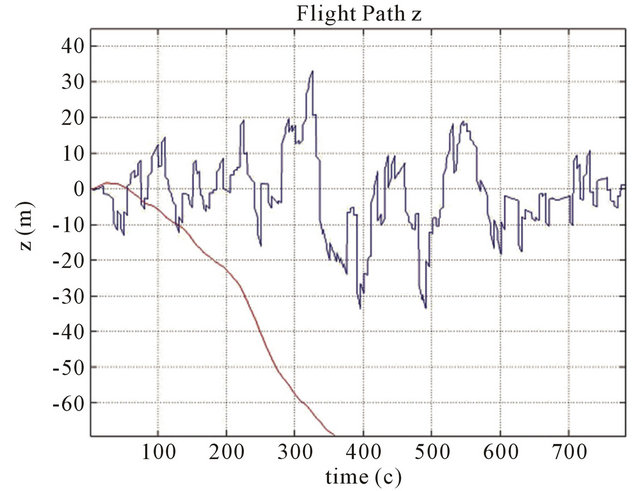
Figure 4. Position errors for z coordinate of the drift path are marked with a red line, and errors of the corrected path are marked with a blue line. Parameters: FOV 60 degree, Features number 120, Resolution 1000 × 1000, Baseline = 200 m, ∆time = 15 s, Height (a) 700 m; (b) 1000 m; (c) 3000 m.
 (a)
(a)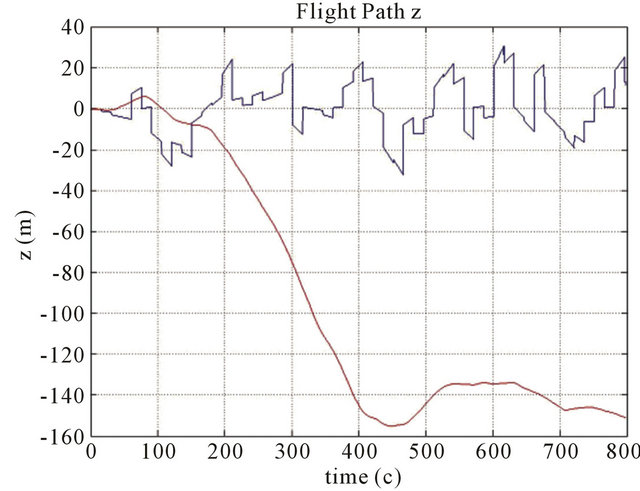 (b)
(b)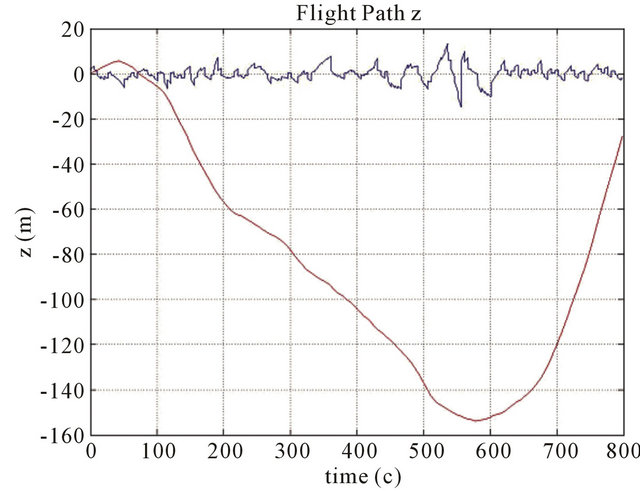 (c)
(c)
Figure 5. Position errors for z coordinate of the drift path are marked with a red line, and errors of the corrected path are marked with a blue line. Parameters: FOV 60 degree, Features number 120, Baseline = 200 m, ∆time = 15 s, Height 1000 m, Resolution (a) 500 × 500; (b) 1000 × 1000; (c) 4000 × 4000.
 (a)
(a)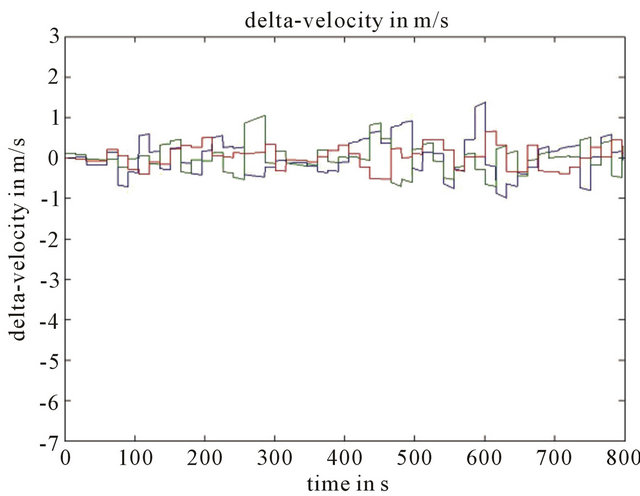 (b)
(b)
Figure 6. (a) Velocity errors of the drift path (x y z components), and (b) Velocity errors of the corrected path (x y z components). Parameters Height 1000 m, FOV 60 degree, Features number 120, Resolution 1000 × 1000, Baseline = 200 m, ∆time = 15 s.
5.1. Jθ Calculation
Simple derivations of 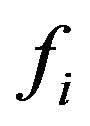 which is presented in (45), yield the following results:
which is presented in (45), yield the following results:
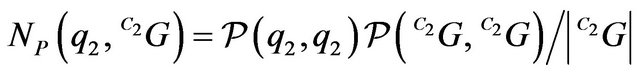 (51)
(51)
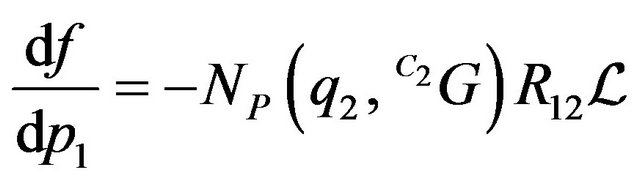 (52)
(52)
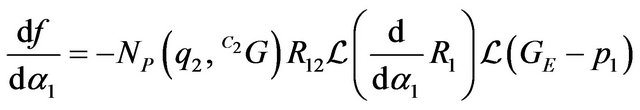 (53)
(53)
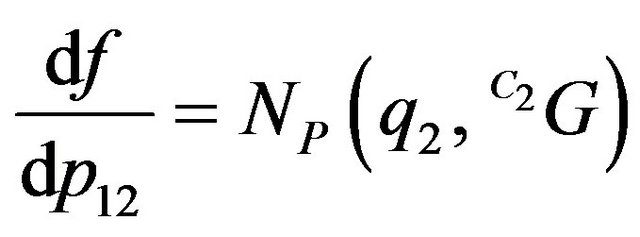 (54)
(54)
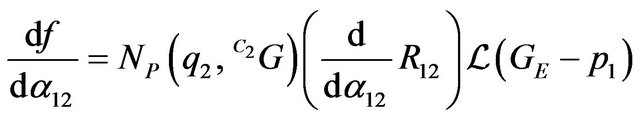 (55)
(55)
In expressions (53) and (55): 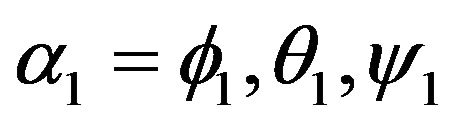 and:
and: 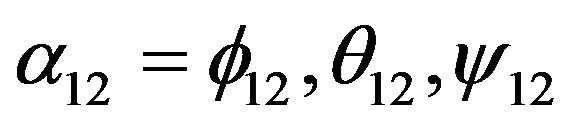 . The Jacobian
. The Jacobian 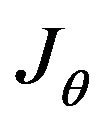 is obtained by simple concatenation of the above derivations.
is obtained by simple concatenation of the above derivations.
5.2. JD Calculation
Before calculating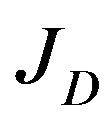 , the data vector D must be explicitly defined. Two types of data are being used by the proposed navigation algorithm: data obtained from the optical-flow field and data obtained form the DTM. Each flow vector starts at
, the data vector D must be explicitly defined. Two types of data are being used by the proposed navigation algorithm: data obtained from the optical-flow field and data obtained form the DTM. Each flow vector starts at 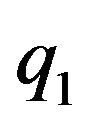 and ends at
and ends at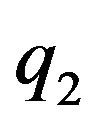 . One can consider
. One can consider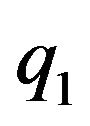 ’s location as an arbitrary choice of some ground feature projection, while
’s location as an arbitrary choice of some ground feature projection, while 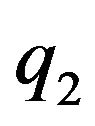 represent the new projection of the same feature on the second frame. Thus the flow errors are realized through the
represent the new projection of the same feature on the second frame. Thus the flow errors are realized through the 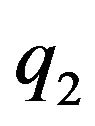 vectors.
vectors.
The DTM errors influence the 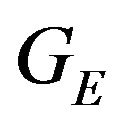 and N vectors in the constraint equation. As before, the DTM linearization assumption will be used. For simplicity the derived orientation of the terrain’s local linearization, as expressed by the normal, will be considered as correct while the height of this plane might be erroneous. The connection between the height error and the error of
and N vectors in the constraint equation. As before, the DTM linearization assumption will be used. For simplicity the derived orientation of the terrain’s local linearization, as expressed by the normal, will be considered as correct while the height of this plane might be erroneous. The connection between the height error and the error of 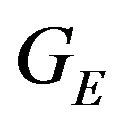 will be derived in the next subsection. Resulting from the above, the
will be derived in the next subsection. Resulting from the above, the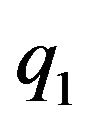 ’s and the N’s can be omitted from the data vector D. It will be defined as the concatenation of all the
’s and the N’s can be omitted from the data vector D. It will be defined as the concatenation of all the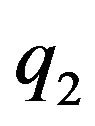 ’s followed by concatenation of the
’s followed by concatenation of the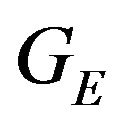 ’s.
’s.
The i’th feature’s data vectors: 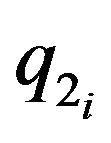 and
and 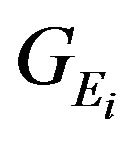 appears only in the i’th feature constraint, thus the obtained Jacobian matrix
appears only in the i’th feature constraint, thus the obtained Jacobian matrix 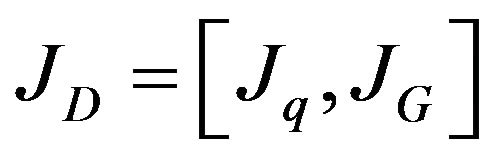 is a concatenation of two block diagonal matrices:
is a concatenation of two block diagonal matrices: 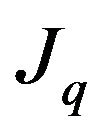 followed by
followed by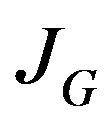 . The i’th diagonal block element is the 3 × 3 matrix
. The i’th diagonal block element is the 3 × 3 matrix 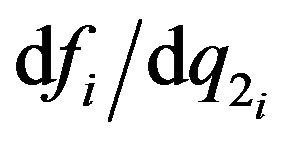 and
and 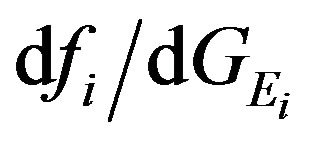 for
for 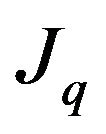 and
and 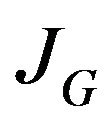 respectively:
respectively:
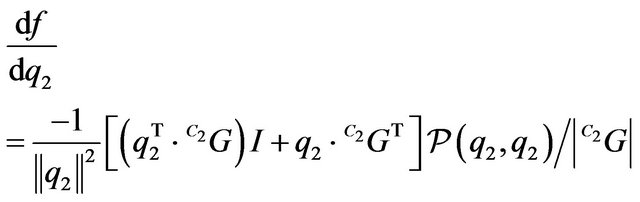 (56)
(56)
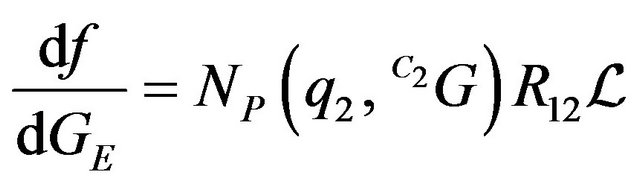 (57)
(57)
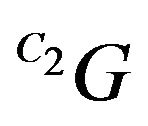 in expression (56) is the ground feature G under the second camera frame as defined in (11).
in expression (56) is the ground feature G under the second camera frame as defined in (11).
5.3. ΣD Calculation
As mention above, the data-vector D is constructed from concatenation of all the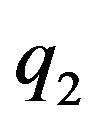 ’s followed by concatenation of the
’s followed by concatenation of the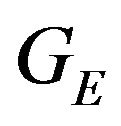 ’s. Thus
’s. Thus 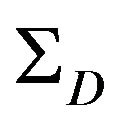 should represent the uncertainty of these elements. Since the
should represent the uncertainty of these elements. Since the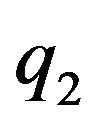 ’s and the
’s and the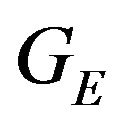 ’s are obtained from two different and uncorrelated processed the covariance relating them will be zero, which leads to a two block diagonal matrix:
’s are obtained from two different and uncorrelated processed the covariance relating them will be zero, which leads to a two block diagonal matrix:
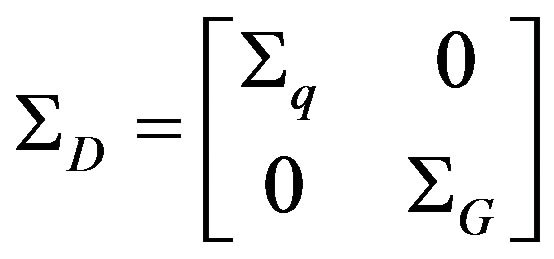 (58)
(58)
In this work the errors of image locations and DTM height are assumed to be additive zero-mean Gaussian distributed with standard-deviation of 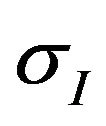 and
and 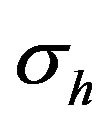 respectively. Each
respectively. Each 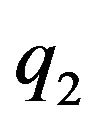 vector is a projection on the image plane where a unit focal-length is assumes. Hence, there is no uncertainty about its z-component. Since a normal isotropic distribution was assumed for the sake of simplicity, the covariance matrix of the image measurements is defined to be:
vector is a projection on the image plane where a unit focal-length is assumes. Hence, there is no uncertainty about its z-component. Since a normal isotropic distribution was assumed for the sake of simplicity, the covariance matrix of the image measurements is defined to be:
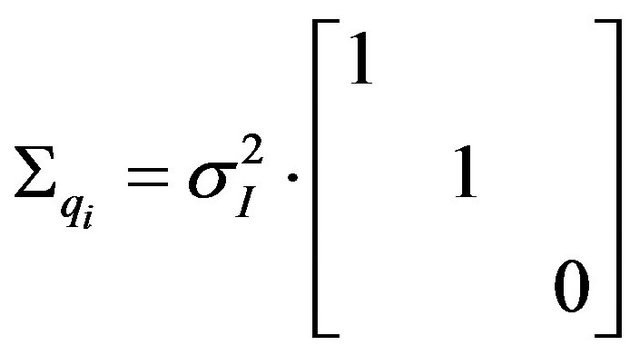 (59)
(59)
and 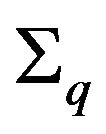 is the matrix with the
is the matrix with the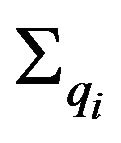 ’s along its diagonal.
’s along its diagonal.
In [16] the accuracy of location’s height obtained by interpolation of the neighboring DTM grid points is studied. The dependence between this accuracy and the specific required location, for which height is being interpolated, was found to be negligible. Here, the above finding was adopted and a constant standard-deviation was set to all DTM heights measurements. Although there is a dependence between close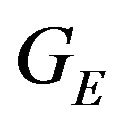 ’s uncertainties, this dependence will be ignored in the following derivations for the sake of simplicity. Thus, a block diagonal matrix is obtained for
’s uncertainties, this dependence will be ignored in the following derivations for the sake of simplicity. Thus, a block diagonal matrix is obtained for 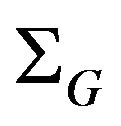 containing the 3 × 3 covariance matrices
containing the 3 × 3 covariance matrices 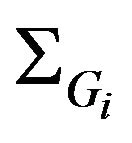 along its diagonal which will be derived as follows: consider the ray sent from
along its diagonal which will be derived as follows: consider the ray sent from 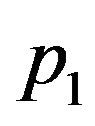 along the direction of
along the direction of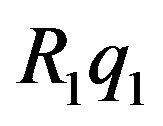 . This ray should have intersected the terrain at
. This ray should have intersected the terrain at 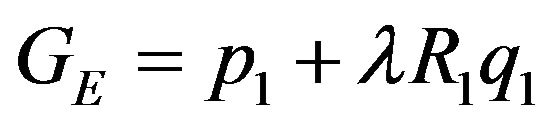 for some
for some![]() , but due to the DTM height error the point
, but due to the DTM height error the point 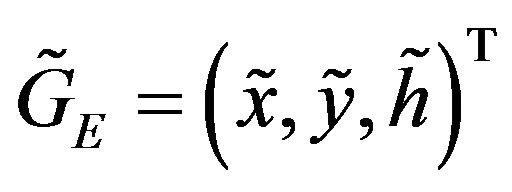 was obtained. Let h be the true height of the terrain above
was obtained. Let h be the true height of the terrain above 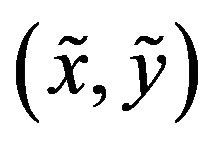 and
and 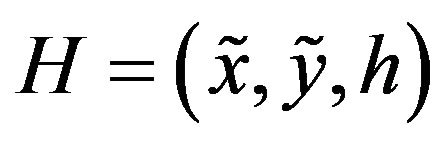 be the 3D point on the terrain above that location.
be the 3D point on the terrain above that location.
Using that H belongs to the true terrain plane one obtains:
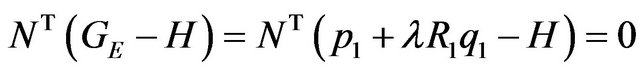 (60)
(60)
Extracting ![]() from (60) and assigning it back to
from (60) and assigning it back to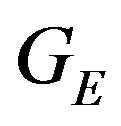 ’s expression yields:
’s expression yields:
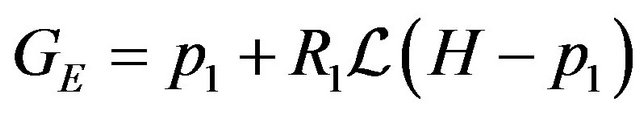 (61)
(61)
For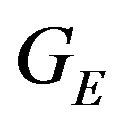 ’s uncertainty calculation the derivative of
’s uncertainty calculation the derivative of 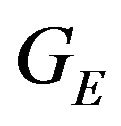 with respect to h should be found:
with respect to h should be found:
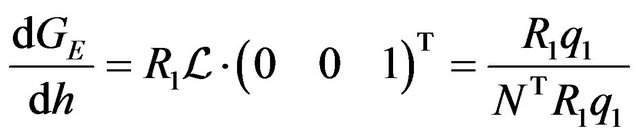 (62)
(62)
The above result was obtained using the fact that the z-component of 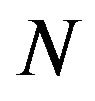 is
is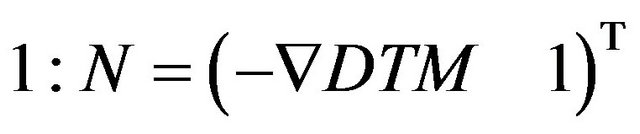 . Finally, the uncertainty of
. Finally, the uncertainty of 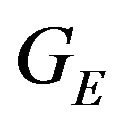 is expressed by the following covariance-matrix:
is expressed by the following covariance-matrix:
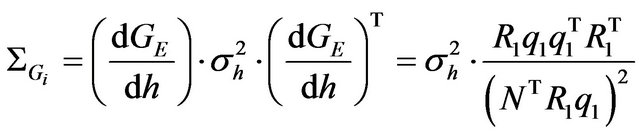 (63)
(63)
5.4. 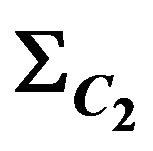 Calculation
Calculation
The algorithm presented in this work estimates the pose of the first camera frame and the ego-motion. Usually, the most interesting parameters for navigation purpose will be the second camera frame since it reflect the most updated information about the platform location. The second pose can be obtained in a straightforward manner as the composition of the first frame pose together with the camera ego-motion:
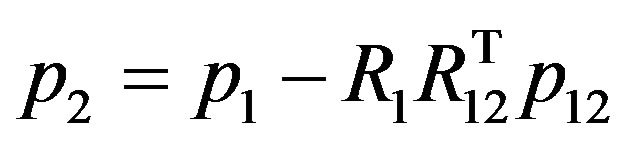 (64)
(64)
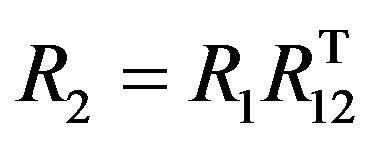 (65)
(65)
The uncertainty of the second pose estimates will be described by a 6 × 6 covariance matrix that can be derived from the already obtained 12 × 12 covariance matrix 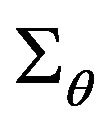 by multiplication from both sides with
by multiplication from both sides with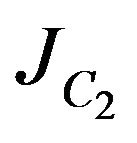 . The last notation is the Jacobian of the six
. The last notation is the Jacobian of the six 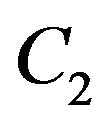 parameters with respect to the twelve parameters mentioned above. For this purpose, the three Euler angles
parameters with respect to the twelve parameters mentioned above. For this purpose, the three Euler angles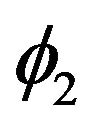 ,
, 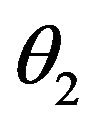 and
and 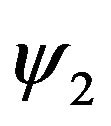 need to be extracted from (65) using the following equations:
need to be extracted from (65) using the following equations:
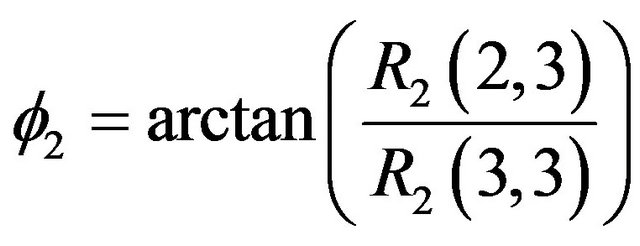 (66)
(66)
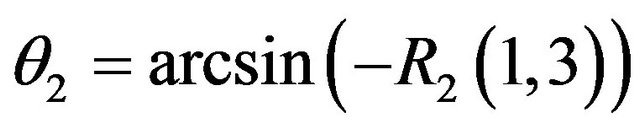 (67)
(67)
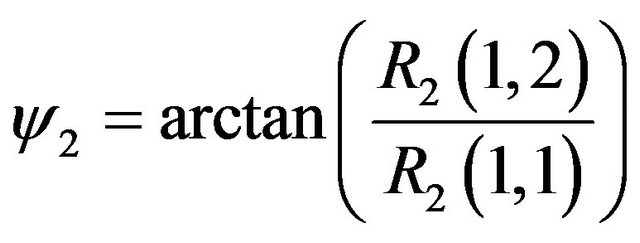 (68)
(68)
Simple derivations and then concatenation of the above expressions yields the required Jacobian which is used to propagate the uncertainty from 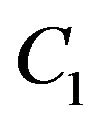 and the egomotion to
and the egomotion to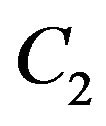 . The found covariance matrix
. The found covariance matrix 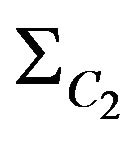 is the same as measurement covariant matrix
is the same as measurement covariant matrix 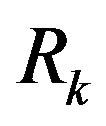 described in section about Kalman filter.
described in section about Kalman filter.
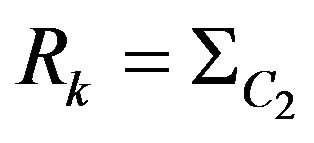 . (69)
. (69)
6. Divergence of the Method. Necessary Thresholds for the Method Convergence
In previous section we considered Error analysis for video navigation method. But its consideration is correct only if found solution is close to true one. If it is not true nonlinear effects can appear or even we can found incurrect local minimum. In this case the method can begins to diverge. We can obtain the such result:
1) if large number of outliers features appears.
2) if the case is close to degenerated one. In this case the position or orientation errors are too large. It can happen for example for small number of features, flat ground, small field of view of camera and all that.
3) if the initial position and orientation for iterations process are too far from true values.
In the follow subsections we consider some threshold conditions which allow us to avoid the such situations.
If in some case even one of these threshold conditions is not correct we don’t use for this case the correction of visual navigation method and use only usual INS result.If such situation repeats three times we stope to use the visual navigation method at all and don’t use it also for the last correct case. Let us discourse these three factors in details
6.1. Dealing with Outliers
In order to handle real data, a procedure for dealing with outliers must be included in the implementation. The objective of the present section is to describe the current implementation, which seems to work satisfactorily in practice. Three kinds of outliers should be considered:
1) Outliers present in the correspondence solution (i.e., “wrong matches”);
2) Outliers caused by the terrain shape; and 3) Outliers caused by relatively large errors between the DTM and the observed terrain.
The latter two kinds of outliers are illustrated in Figure 7. The outliers caused by the terrain shape appear for terrain features located close to large depth variations. For example, consider two hills, one closer to the camera, the other farther away, and a terrain feature Q located on
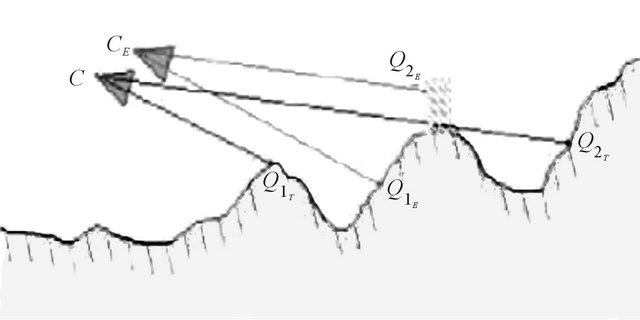
Figure 7. Outliers caused by terrain shape and DTM mismatch. CT and CE are true and estimated camera frames, respectively. 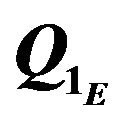 and
and 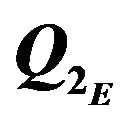 are outliers caused by terrain shape and by terrain/DTM mismatch, respectively.
are outliers caused by terrain shape and by terrain/DTM mismatch, respectively.
the closer hill. The ray-tracing algorithm using the erroneous pose may “miss” the proximal hill and erroneously place the feature on the distal one. Needless to say, the error between the true and estimated locations is not covered by the linearization. To visualize the errors introduced by a relatively large DTM-actual terrain mismatch, suppose a building was present on the terrain when the DTM was acquired, but is no longer there when the experiment takes place. The ray-tracing algorithm will locate the feature on the building although the true terrain-feature belongs to a background that is now visible.
As discussed above, the multi-feature constraint is solved in a least-squares sense for the pose and motion variables. Given the sensitivity of least-squares to incorrect data, the inclusion of one or more outliers may result in the convergence to a wrong solution. A possible way to circumvent this difficulty is by using an M-estimator, in which the original solution is replaced by a weighted version. In this version, a small weight is assigned to the constraints involving outliers, thereby minimizing their effect on the solution. More specifically, consider the function 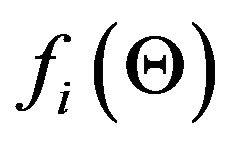 defined in (45) resulting from the i-th correspondence pair. In the absence of noise, this function should be equal to zero at the true pose and motion values and hence, following standard notation, define the residual
defined in (45) resulting from the i-th correspondence pair. In the absence of noise, this function should be equal to zero at the true pose and motion values and hence, following standard notation, define the residual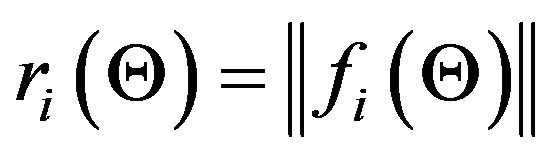 . Using an M-estimator, the solution for
. Using an M-estimator, the solution for  (the twelve parameters to be estimated) is obtained using an iterative re-weighted least-squares scheme:
(the twelve parameters to be estimated) is obtained using an iterative re-weighted least-squares scheme:
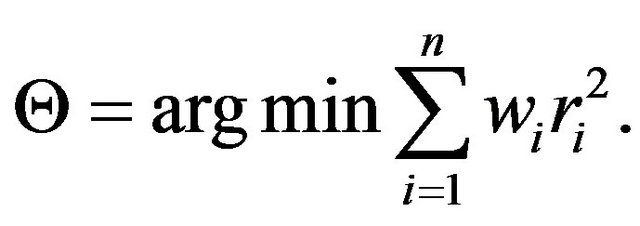 (70)
(70)
The weights 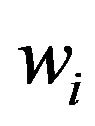 are recomputed after each iteration according to their corresponding updated residual. In our implementation we used the so-called Geman-McClure function, for which the weights are given by:
are recomputed after each iteration according to their corresponding updated residual. In our implementation we used the so-called Geman-McClure function, for which the weights are given by:
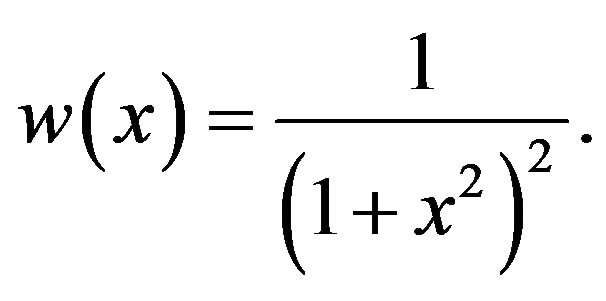 (71)
(71)
The calculated weights are then used to construct a weighted pseudo-inverse matrix that replaces the regular pseudo-inverse 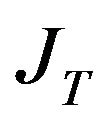 appearing in (50). See [17] for further details about M-estimation techniques. Let us define weights matrix W which allows us to decrease influence of outliers
appearing in (50). See [17] for further details about M-estimation techniques. Let us define weights matrix W which allows us to decrease influence of outliers
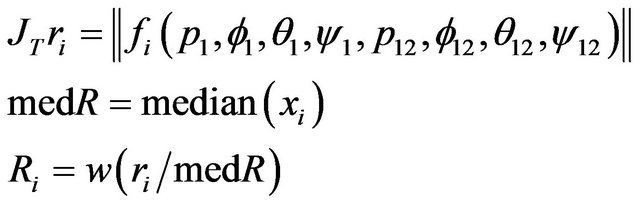 (72)
(72)
where 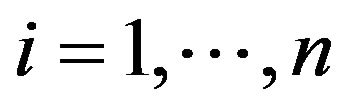 and n is number of features.
and n is number of features.
The weights matrix W 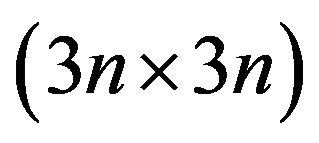 can be found as follow: for diagonal elements of W we can write: Wii = Rk where k is integer part of
can be found as follow: for diagonal elements of W we can write: Wii = Rk where k is integer part of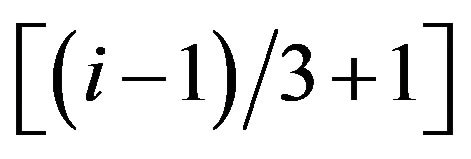 . Non-diagonal elements of
. Non-diagonal elements of 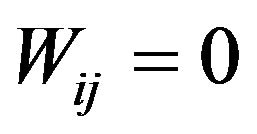 for
for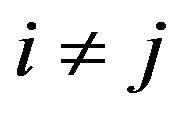 .
.
Instead Equation (50) we use new one:
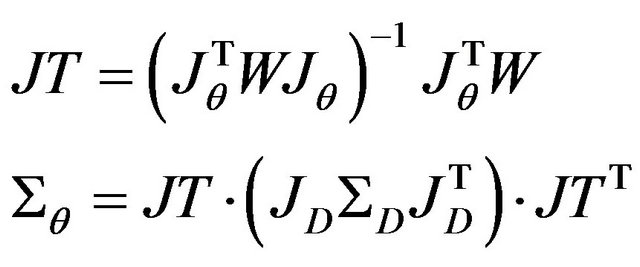 (73)
(73)
If we know two positions of camera and features position in the first photo so we can find the features position on the second photo. If the distance between true position of some correspondent feature on second photo and the position found by previously described method larger than 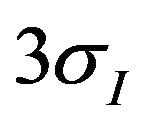 we would consider the such feature as outlier. Let us define Ni as number of outliers in initial approximation of cameras position and orientation (i.e. before using visual navigation method) and Nf as number of outliers after visual navigation method corrections. The follow conditions let us to avoid too large number of outliers case:
we would consider the such feature as outlier. Let us define Ni as number of outliers in initial approximation of cameras position and orientation (i.e. before using visual navigation method) and Nf as number of outliers after visual navigation method corrections. The follow conditions let us to avoid too large number of outliers case:
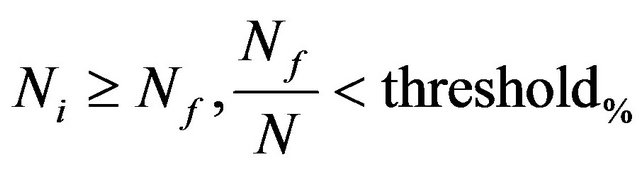 (74)
(74)
where N is full number of features and threshold% is some threshold value. We choose it to be equal 0.1.
6.2. Degenerated Case Large Errors
For degenerate case the matrix 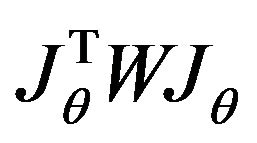 in Equation (73) can be singular. It gives us follow threshold condition:
in Equation (73) can be singular. It gives us follow threshold condition:
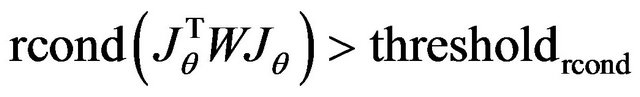 (75)
(75)
where rcond()-Matlab function for matrix reciprocal condition number estimate. It is measure for matrix singularity (0 < rcond() < 1). Threshold value thresholdrcond is chosen to be 10−16.
Degenerated case because of small number of features, flat ground or small field of view of camera gives the follow threshold conditions:
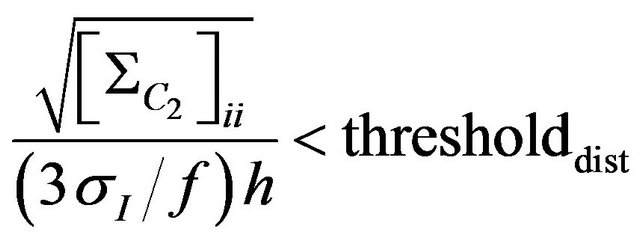 (76)
(76)
where 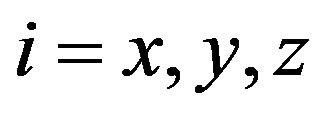 coordinate indexes for diagonal elements of covariance matrix
coordinate indexes for diagonal elements of covariance matrix 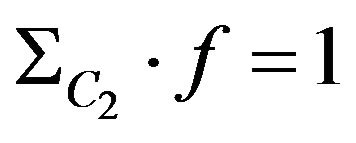 is a focus length of the camera, h is height of the camera.
is a focus length of the camera, h is height of the camera. 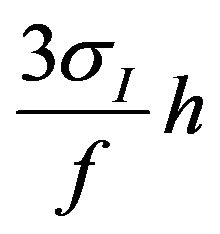 gives us the maximum camera position shift allowing the photo feature error to be smaller than pixel size. Threshold value thresholddist is chosen to be 40.
gives us the maximum camera position shift allowing the photo feature error to be smaller than pixel size. Threshold value thresholddist is chosen to be 40.
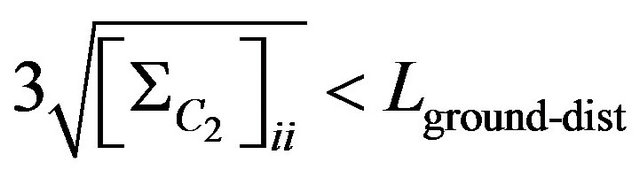 (77)
(77)
where 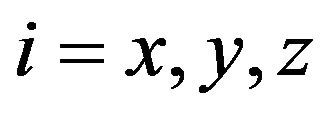 coordinate indexes for diagonal elements of covariance matrix
coordinate indexes for diagonal elements of covariance matrix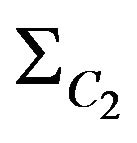 ,
,  is character size of ground relief change.
is character size of ground relief change.
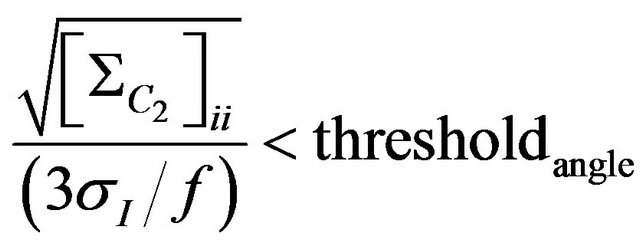 (78)
(78)
where 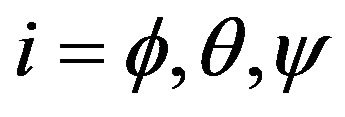 angular indexes for diagonal elements of covariance matrix
angular indexes for diagonal elements of covariance matrix 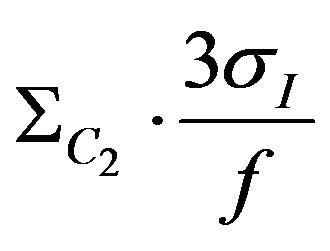 gives us the maximum camera angular shift allowing the photo feature error to be smaller than pixel size.Threshold value
gives us the maximum camera angular shift allowing the photo feature error to be smaller than pixel size.Threshold value 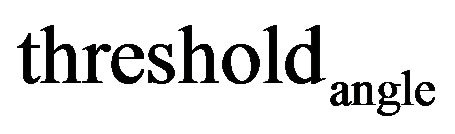 is chosen to be 40.
is chosen to be 40.
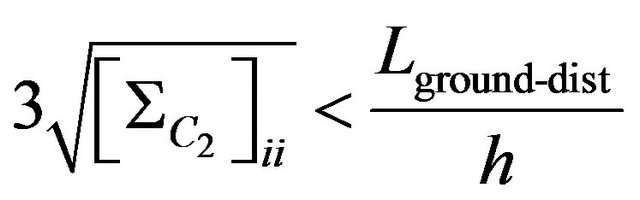 (79)
(79)
where 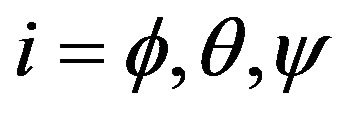 angular indexes for diagonal elements of covariance matrix
angular indexes for diagonal elements of covariance matrix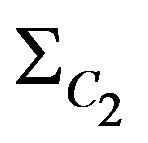 .
.
Degenerated case because of small baseline (distance between two camera positions used in video navigation method) gives the follow threshold conditions:
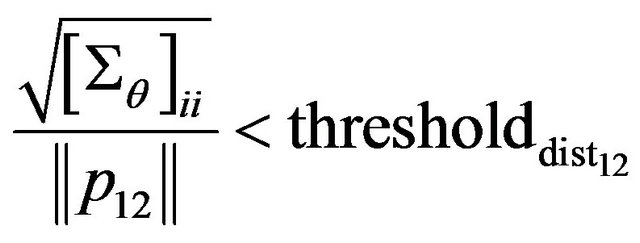 (80)
(80)
where 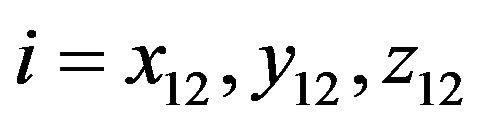 mutual coordinate indexes for diagonal elements of covariance matrix
mutual coordinate indexes for diagonal elements of covariance matrix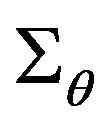 . Threshold value
. Threshold value 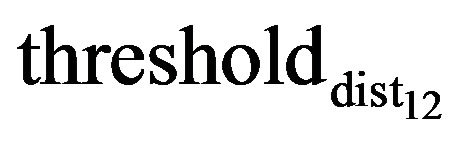 is chosen to be 0.1.
is chosen to be 0.1.
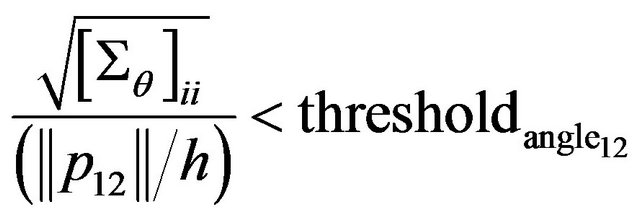 (81)
(81)
where 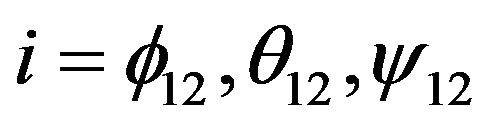 mutual angular indexes for diagonal elements of covariance matrix
mutual angular indexes for diagonal elements of covariance matrix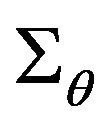 . Threshold value
. Threshold value 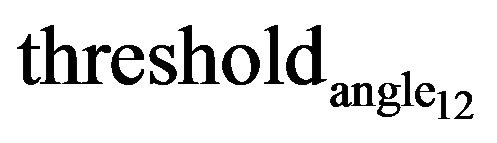 is chosen to be 0.1.
is chosen to be 0.1.
6.3. The Initial State of the Camera Is Too Far from It’s True or Final Calculated State
Let us define threshold conditions to avoid the initial state of the camera to be too far from the its true state. 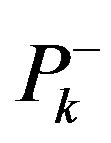 is covariant matrix obtained from INS and previous corrections of INS by video navigation method with help of Kalman filter and described in section about Kalman filter.
is covariant matrix obtained from INS and previous corrections of INS by video navigation method with help of Kalman filter and described in section about Kalman filter.
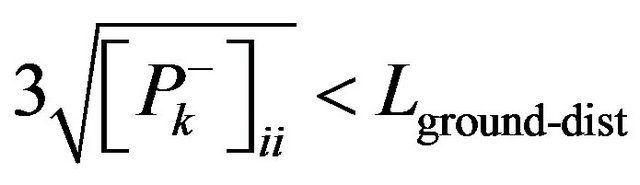 (82)
(82)
where 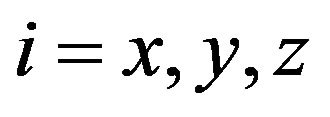 coordinate indexes for diagonal elements of covariance matrix
coordinate indexes for diagonal elements of covariance matrix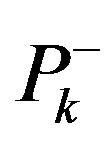 .
.
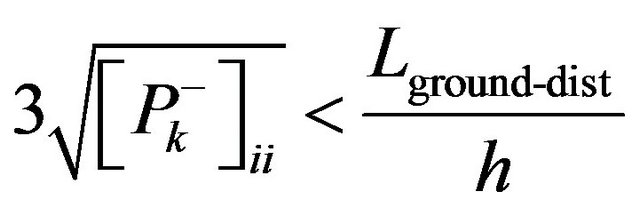 (83)
(83)
where  angular indexes for diagonal elements of covariance matrix
angular indexes for diagonal elements of covariance matrix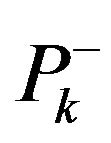 .
.
Let us define threshold conditions to avoid the initial state of the camera to be too far from the its final state. The follow four equations give us differences between initial and final state obtain as corrections of INS by video navigation method with help of Kalman filter.
 (84)
(84)
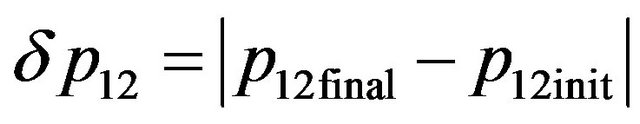 (85)
(85)
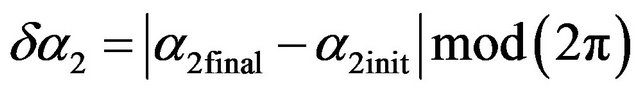 (86)
(86)
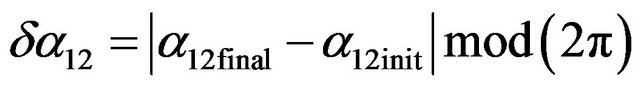 (87)
(87)
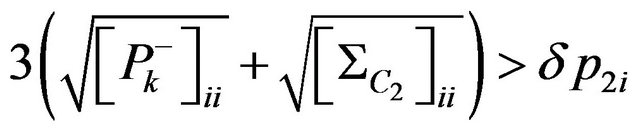 (88)
(88)
where 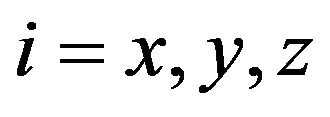 coordinate indexes for diagonal elements of covariance matrix
coordinate indexes for diagonal elements of covariance matrix 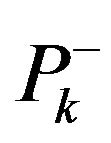 and
and 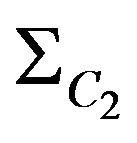
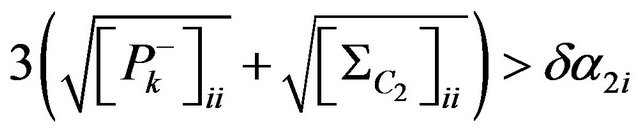 (89)
(89)
where 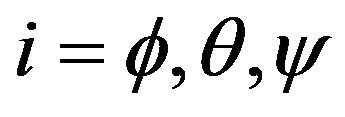 angular indexes for diagonal elements of covariance matrix
angular indexes for diagonal elements of covariance matrix 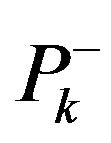 and
and 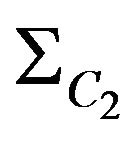
 (90)
(90)
where 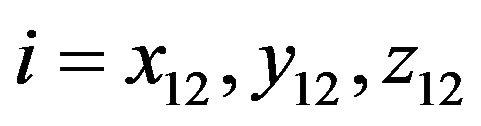 mutual coordinate indexes.
mutual coordinate indexes.
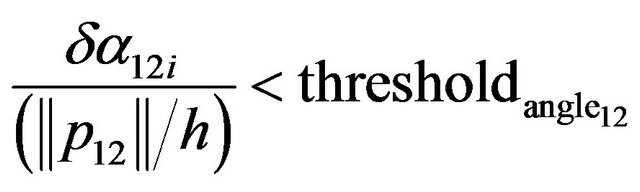 (91)
(91)
where 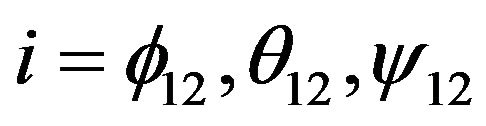 mutual angular indexes.
mutual angular indexes.
7. Simulations Results
7.1. Dependence of Error Analysis on Different Factors
The purpose of the following section is to study the influence of different factors on the accuracy of the proposed algorithm estimates. The closed form expression that was developed throughout the previous section is being used to determine the uncertainty of these estimates under a variety of simulated scenarios. Each tested scenario is characterized by the following parameters: the number of optical-flow features being used by the algorithm, the image resolution, the grid spacing of the DTM (also referred as the DTM resolution), the amplitude of hills/mountains on the observed terrain, and the magnitude of the ego-motion components. At each simulation, all parameters except the examined one are set according to a predefined parameters set. In this default scenario, a camera with 400 × 400 image resolution flies at altitude of 500 m above the terrain. The terrain model dimensions are 3 × 3 km with 300 m elevation differences (Figure 13(b)). A DTM of 30 m grid spacing is being used to model the terrain (Figure 10(c)). The DTM resolution leads to a standard-deviation of 2.34 m for the height measurements. The default-scenario also defines the number of optical-flow features to about 170, where an ego-motion of 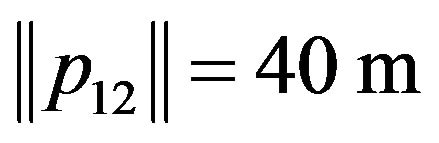 and
and 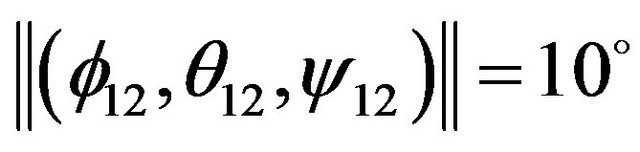 differs the two images being used for the optical-flow computation. Each of the simulations described below study the influence of different parameter. A variety of values are examined and 150 random tests are performed for each tested value. For each test the camera position and orientation were randomly selected, except the camera’s height that was dictated by the scenario’s parameters. Additionally, the direction of the ego-motion translation and rotation components were first chosen at random and then normalized to the require magnitude.
differs the two images being used for the optical-flow computation. Each of the simulations described below study the influence of different parameter. A variety of values are examined and 150 random tests are performed for each tested value. For each test the camera position and orientation were randomly selected, except the camera’s height that was dictated by the scenario’s parameters. Additionally, the direction of the ego-motion translation and rotation components were first chosen at random and then normalized to the require magnitude.
In Figure 8, the first simulation results are presented. In this simulation the number of optical-flow features that are used by the algorithm is varied and its influence on the obtained accuracy of  and the ego-motion is studied. All parameters were set to their default values except for the features number. Figure 8(a) presents the standard-deviations of the second frame of the camera while the deviations of the ego-motion are shown in Figure 8(b). As expected, the accuracy improves as the number of features increases, although the improvement becomes negligible after the features’ number reaches about 150.
and the ego-motion is studied. All parameters were set to their default values except for the features number. Figure 8(a) presents the standard-deviations of the second frame of the camera while the deviations of the ego-motion are shown in Figure 8(b). As expected, the accuracy improves as the number of features increases, although the improvement becomes negligible after the features’ number reaches about 150.
In the second simulation the influence of the image resolution was studied (Figure 9). It was assumed that the image measurements contain uncertainty of half-pixel, where the size of the pixels is dictated by the image resolution. Obviously, the accuracy improves as image resolution increases since the quality of the optical-flow data is directly depends on this parameter.
The influence of DTM grid spacing is the objective of the next simulation. Different DTM resolutions were tested varying from 10 m up to an extremely rough resolution of 190 m between adjacent grid points (see Figure 10). The readers attention is drawn to the fact that the obtained accuracy seems to decrease linearly with respect to the DTM grid-spacing (see Figure 11). This phenomenon can be understood since, as was explained in the previous section, the DTM resolution does not affect the accuracy directly but rather it influences the height uncertainty which is involved in the accuracy calculation. As can be seen in Figure 12, the standard-deviation of
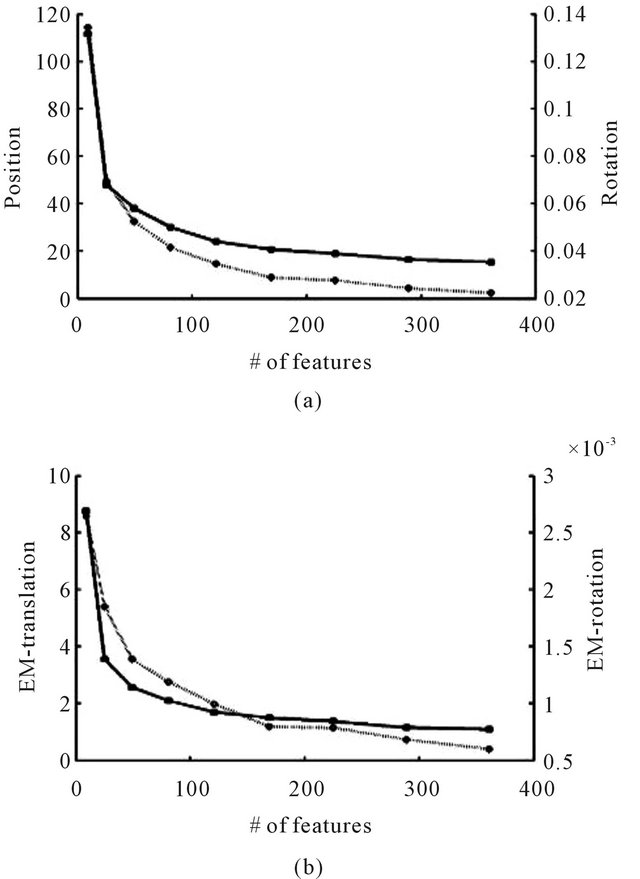
Figure 8. Average standard-deviation of the second position and orientation (a), and the ego-motion’s translation and rotation (b) with respect to the number of flow-features. In both graphs, the left vertical axis measures the translational deviations (in meters) and corresponds to the solid graphline, while the right vertical axis measures the rotational deviations (in radians) and corresponds to the dotted graphline.
the DTM heights increases linearly with respect to the DTM grid spacing which is the reason for the obtained results.
Another simulation demonstrates the importance of the terrain structure to the estimates accuracy. In the extreme scenario of flying above a planar terrain, the observed ground features do not contain the required information for the camera pose derivation, and a singular system will be obtained. As the height differences and the variability of the terrain increase, the features become more informative and a better estimates can be derived. For this simulation, the DTM elevation differences were scaled to vary from 50 m to 450 m (Figure 13). It is emphasized that while the terrain structure plays a crucial role at the camera pose estimation together with the translational component of the ego-motion, it has no direct affect on the ego-motion rotational component. As the optical-flow is a composition of two vector fieldstranslation and rotation, the information for deriving the
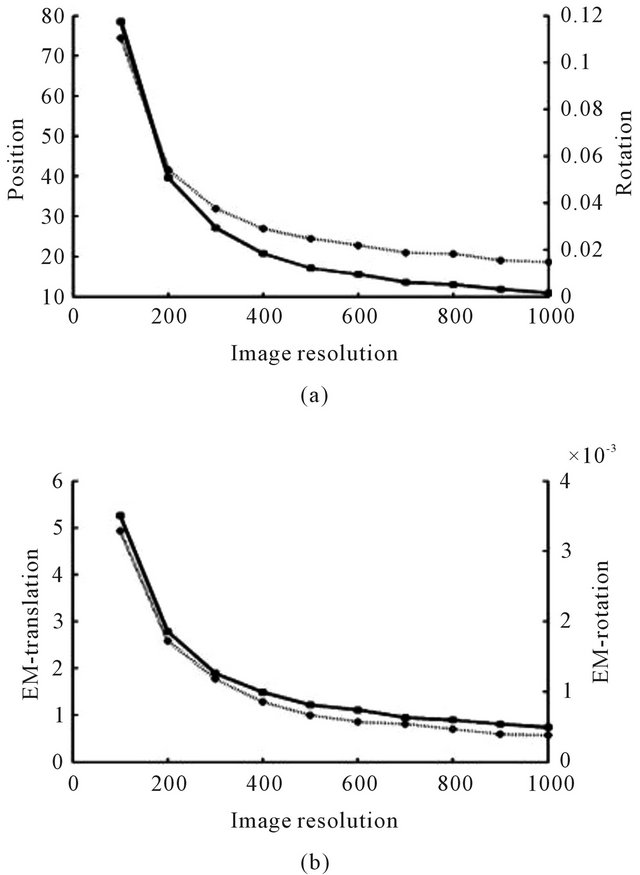
Figure 9. Average standard-deviation of the second position and orientation (a), and the ego-motion’s translation and rotation (b) with respect to the image resolution.
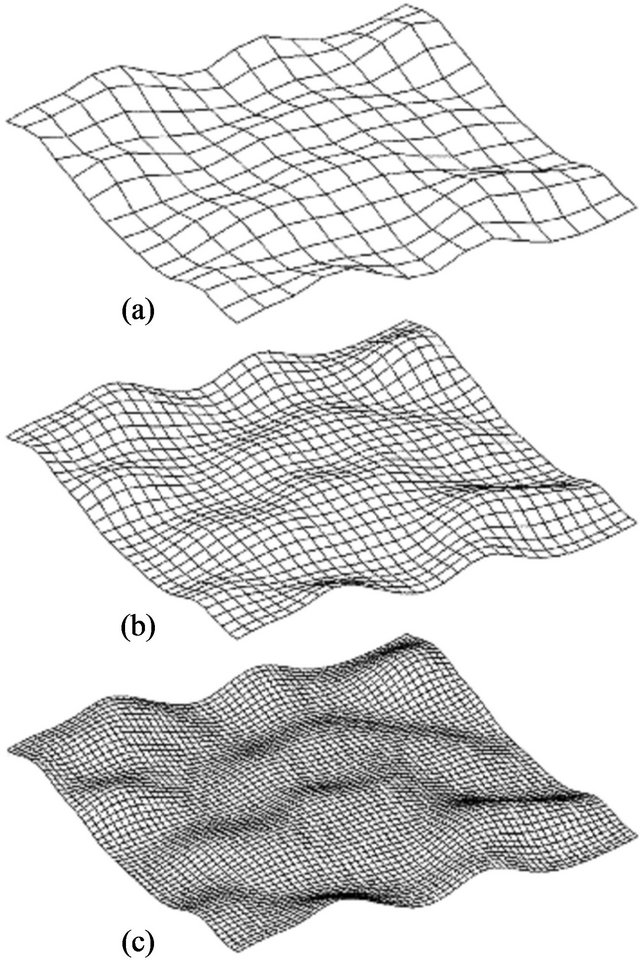
Figure 10. Different DTM resolutions: (a) grid spacing = 190 m; (b) grid spacing = 100 m; (c) grid spacing = 30 m.
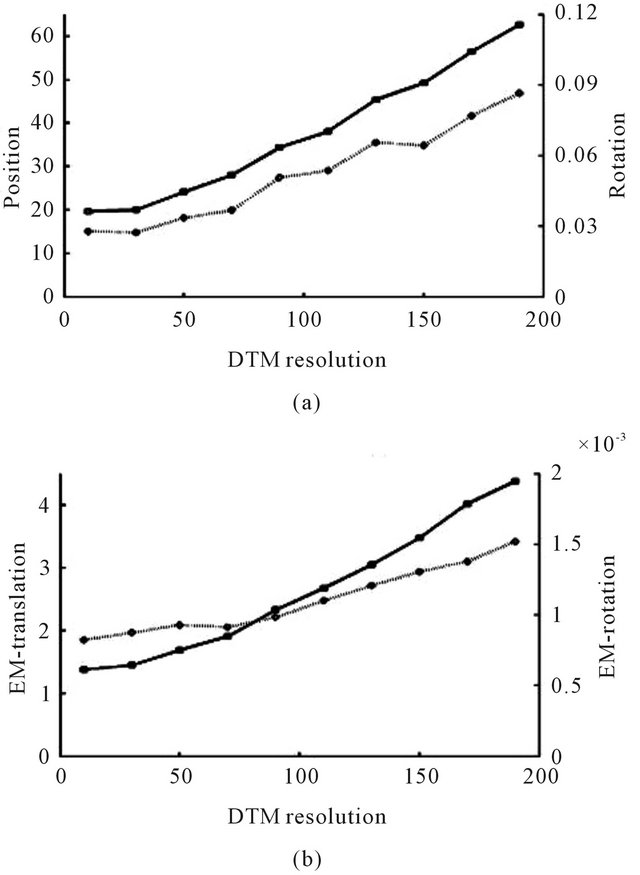
Figure 11. Average standard-deviation of the second position and orientation (a), and the ego-motion’s translation and rotation (b) with respect to the grid-spacing of the DTM.
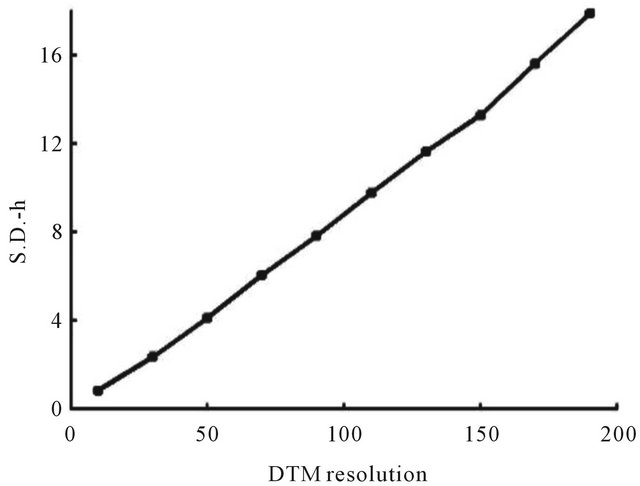
Figure 12. Standard-deviation of the DTM’s height measurement with respect to the grid-spacing of the DTM.
ego-motion rotation is embedded only in the rotational component of the flow-field. Since the features depths influence only the flow’s translational component it is expected that the varying height differences or any other structural change in the terrain will have no affect on the

Figure 13. DTM elevation differences: (a) 150 m; (b) 300 m; (c) 450 m.
ego-motion rotation estimation. The above characteristics are well demonstrated in Figure 14.
Since it is the translation component of the flow which holds the information required for the pose determination, it would be interesting to observe the effect of increasing the magnitude of this component. The last simulation presented in this work demonstrates the obtained pose accuracy when the ego-motion translation component vary form 5 m to 95 m. Although it has no significant effect on the ego-motion accuracy, the uncertainty of the pose estimates decreases for a large magnitude of translations (see Figure 15). As a conclusion from the above stated, the time gap between the two camera frames should be as long as the optical-flow derivation algorithm can tolerate.
7.2. Results of Numerical Simulation for Real Parameters of Flight and Camera
Inertial navigation systems (INS) are used usually for detection of missile position and orientation. The problem of this method is that its error increases all time. We propose to use new method (Navigation Algorithm based on Optical-Flow and a Digital Terrain Map) [18] to correct result of INS and to make the error to be finite and constant. Kalman Filter is used to combine results of INS and results of new method [12]. Error analysis with linear first-order approximation is used to find error corre-
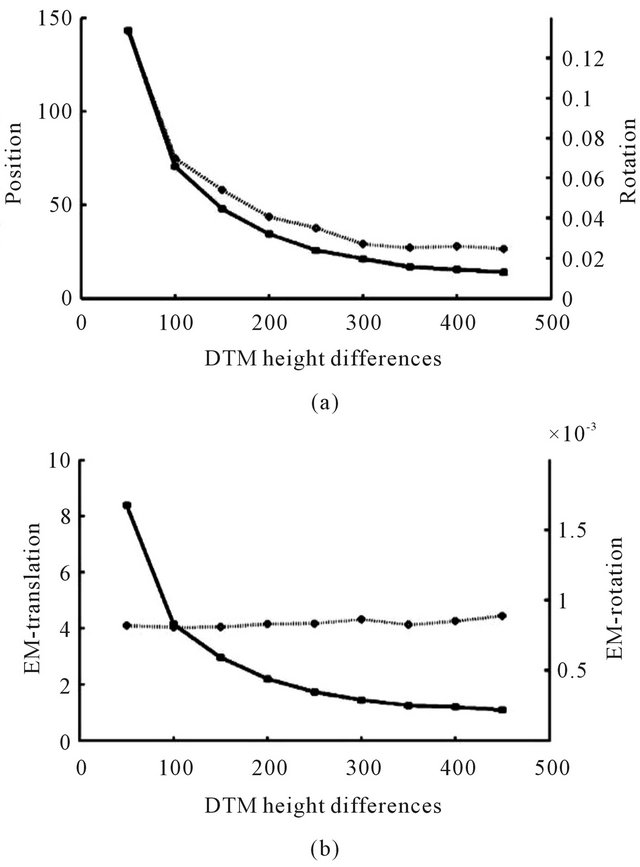
Figure 14. Average standard-deviation of the second position and orientation (a), and the ego-motion’s translation and rotation (b) with respect to the height differences of the terrain.
lation matrix for our new method [14]. We made numerical simulations of flight with real parameters of flight and camera using only INS and INS and our new method to check usefulness of this new method.
The chosen flight parameters are following:
Height of flight is 700, 1000, 3000 m;
Velocity of flight is 200 m/s;
Flight time is 800 s.
Trajectory of the flight we can see on (Figure 16). Digital Terrain Map of real ground was used as cell (Figure 17) for our simulations. This cell was continued periodically to obtain full Map of the ground (Figure 18). Random noise was used as main component of INS noise. The more real drift and bias noise give much bigger mistake (about 6000 m instead 1000 m in the finish point of the flight).
The chosen camera and simulation parameters are following:
FOV (field of view of camera) is 60 degree. (FOV is field of view of camera.)
Features number found on photos is 100, 120.
Resolution of camera is 500 × 500, 1000 × 1000, 4000 × 4000. (The resolution of camera defines precision of
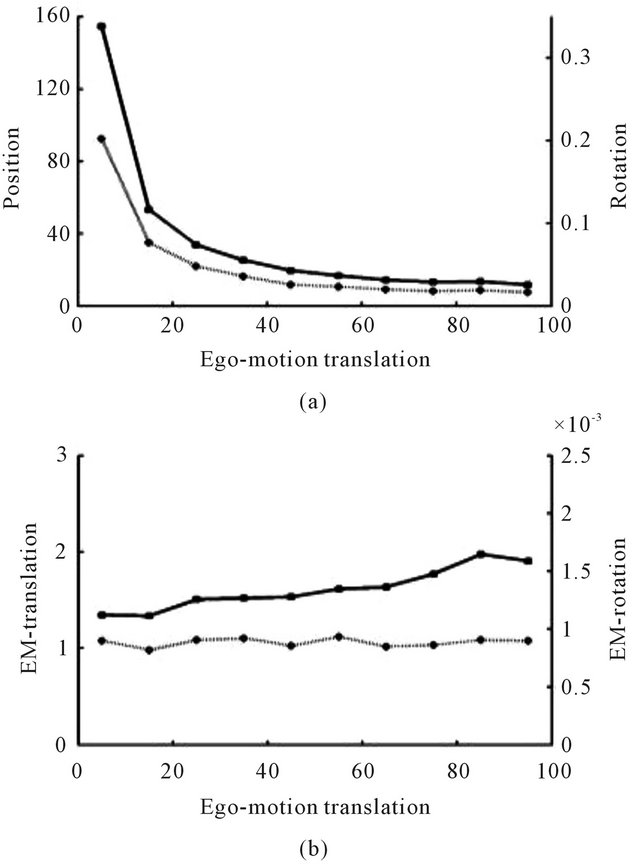
Figure 15. Average standard-deviation of the second position and orientation (a), and the ego-motion’s translation and rotation (b) with respect to the magnitude of the translational component of the ego-motion.
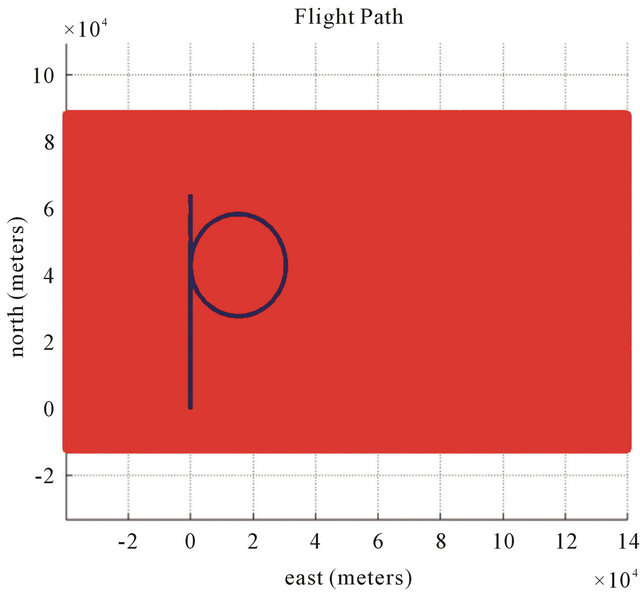
Figure 16. Trajectory of the flight.
feature detection, we assume no Optical Flow outliers for features.)
Baseline is 30 m, 50 m or 200 m. (Baseline is distance
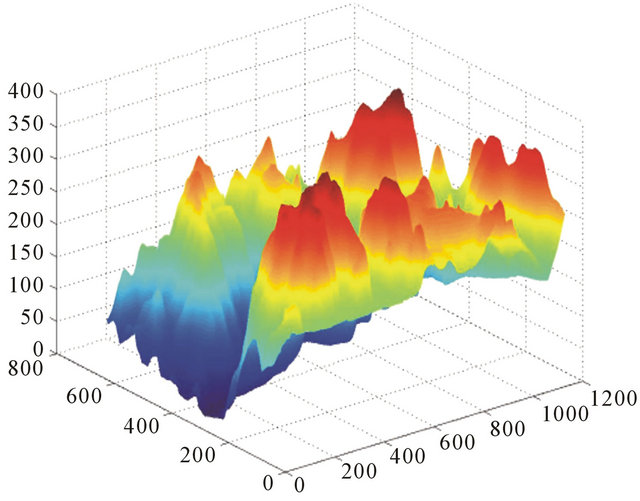
Figure 17. Map of real ground was used as cell.
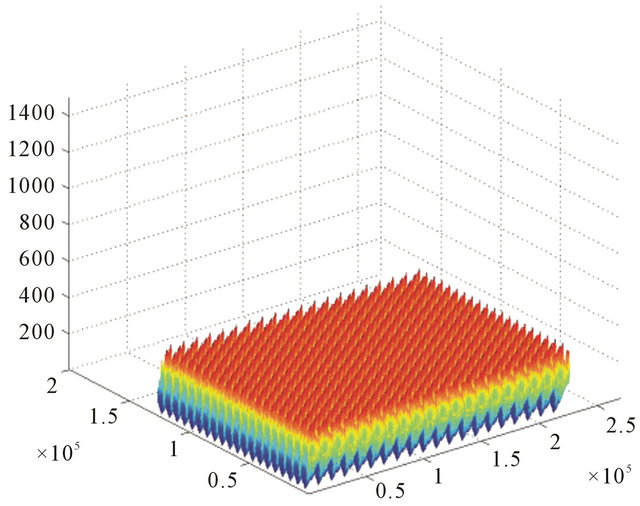
Figure 18. Cell was continued periodically to obtain full Map of the ground.
between two camera positions used to make two photos for new method.)
∆time is 5 s, 15 s, 30 s. (∆time is time interval between measurements.)
The typical results of numerical simulations can be seen on (Figures 3-6) for different cases of flight, camera and simulation parameters. Let us demonstrate error tables for typical case with positive results: x, y, z position errors of INS with using new method and without using new method.
Used flight, camera and simulation parameters for this case:
FOV is 60 degree;
Number of features is 120;
Resolution is 1000 × 1000;
Baseline is 200 m;
∆time is 15 s;
Flight velocity is 200 m/s;
Heights are 700 m, 1000 m, 3000 m.
Let us demonstrate error tables for typical case with positive results: x, y, z position errors of INS with using new method for different resolutions of camera. Used flight, camera and simulation parameters for this case:
FOV 60 degree, Number of features:120, Resolution 500 × 500, 1000 × 1000, 4000 × 4000, Baseline 200 m, Deltatime 15 s, Flight velocity 200 m/s, Heights: 1000 m.
8. Open Problems and Future Method Development
1) If situation is close to degenerated case (for example, for small camera field of view, almost flat ground, small baseline and so on) we can not used described method because it is impossible to find cameras states from this data. But it is possible also for this case to used found correspondent features constrains for INS results improvement by help Kalman filter. We can consider directly these corespondent features (and not calculated position and orientation on basis these features) as result of measurement for Kalman filter. Example of the such improvement can be found in [19]. But in this case errors of method will increase with time similar to INS. So after some time measured position is too far from the true position and we can not use DTM constrains for error correction, but only epipolar constrains. For described in this paper method the error stops to increase and remains constant so we are capable to use DTM constrains all time.
2) It is possible to consider more optimal and fast methods for looking for minimum of function giving position and orientation of camera. For example it is possible to improve initial state for described method , using epipolar Equation (25) for R12 and p12 up to constant calculations. The next step can be use Equation (21) for R1 calculation. And final step using Equation (18) for p12 and p1 calculation. The result can be improved by described iteration method.
3) We can look for not only some random features. Also hill tops, valleys and hill occluding boundaries can be used for position and orientation specifying.
4) Using distributed (not point) features and also some character object recognition.
5) Using the used methods in different practical situations: orientation in rooms, inside of man body.
9. Conclusions
An algorithm for pose and motion estimation using corresponding features in images and a DTM was presented with using Kalman filter. The DTM served as a global reference and its data was used for recovering the absolute position and orientation of the camera. In numerical simulations position and velocity estimates were found to be sufficiently accurate in order to bound the accumulated errors and to prevent trajectory drifts.
An error analysis has been performed for a novel algorithm that uses as input the optical flow derived from two consecutive frames and a DTM. The position, orientation and ego-motion parameters of the the camera can be estimated by the proposed algorithm. The main source for errors were identified to be the optical-flow computation, the quality of the information about the terrain, the structure of the observed terrain and the trajectory of the camera. A closed form expression for the uncertainty of the pose and motion was developed. Extensive numerical simulations were performed to study the influence of the above factors.
Tested under reasonable and common scenarios, the algorithm behaved robustly even when confronted with relatively noisy and challenging environment. Following the analysis, it is concluded that the proposed algorithm can be effectively used as part of a navigation system of autonomous vehicles.
On basis results of numerical simulation for real parameters of flight and camera we also can conclude follow:
1) The most important parameter of simulations is FOV: for the small FOV the method diverges. For FOV 60 degree the results are very good. The reason for this is that for small FOV (12 or 6 degree) the situation is close to degenerated state, also we must choose small baseline and observed ground patch is too small and almost flat.
2) Resolution of camera is also very important parameter: for better resolution we have much more better results, because of much more better precision of features detection.
3) The precision of new method depends on flight height. Initially precision increases with height increasing because we can use bigger baseline and can see bigger patch of ground. But for bigger heights precision begin to decrease because of small parallax effect.
10. Acknowledgements
We would like to thank Ronen Lerner, Ehud Rivlin and Hector Rotstein for very useful consultations.
REFERENCES
- Y. Liu and M. A. Rodrigues, “Statistical Image Analysis for Pose Estimation without Point Correspondences,” Pattern Recognition Letters, Vol. 22, No. 11, 2001, pp. 1191- 1206. doi:10.1016/S0167-8655(01)00052-6
- P. David, D. DeMenthon, R. Duraiswami and H. Samet, “SoftPOSIT: Simultaneous Pose and Correspondence Determination,” In: A. Heyden, et al., Eds., LNCS 2352, Springer-Verlag, Berlin, 2002, pp. 698-714.
- J. L. Barron and R. Eagleson, “Recursive Estimation of Time-Varying Motion and Structure Parameters,” Pattern Recognition, Vol. 29, No. 5, 1996, pp. 797-818. doi:10.1016/0031-3203(95)00114-X
- T. Y. Tian, C. Tomashi and D. J. Hegger, “Comparison of Approaches to Egomotion Computation,” Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, 18-20 June 1996, pp. 315-320.
- A. Chiuso and S. Soatto, “MFm: 3-D Motion from 2-D Motion, Causally Integrated over Time,” Washington University Technical Report, Washington University, St. Louis, 1999.
- M. Irani, B. Rousso and S. Peleg, “Robust Recovery of Ego-Motion,” Proceedings of Computer Analysis of Images and Patterns (CAIP), Budapest, 13-15 September 1993, pp. 371-378.
- D. G. Sim, R. H. Park, R. C. Kim, S. U. Lee and I. C. Kim, “Integrated Position Estimation Using Aerial Image Sequences,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 24, No. 1, 2002, pp. 1-18. doi:10.1109/34.982881
- J. Oliensis, “A Critique of Structure-from-Motion Algorithms,” Computer Vision and Image Understanding, Vol. 80, No. 2, 2000, pp. 172-214. doi:10.1006/cviu.2000.0869
- R. Lerner and E. Rivlin, “Direct Method for Video-Based Navigation Using a Digital Terrain Map,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 33, No. 2, 2011, pp. 406-411. doi:10.1109/TPAMI.2010.171
- R. Lerner, E. Rivlin and H. P. Rotstein, “Pose and Motion Recovery from Correspondence and a Digital Terrain Map,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 28, No. 9, 2006, pp. 1404-1417.
- C.-P. Lu, G. D. Hager and E. Mjolsness, “Fast and Globally Convergent Pose Estimation from Video Images,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22, No. 6, 2000, pp. 610-622. doi:10.1109/34.862199
- G. Welch and G. Bishop, “An Introduction to the Kalman Filter,” 2004. http://www.menem.com/ilya/digital_library/control/welch-bishop-01.pdf
- Inertial Navigation System (INS) Toolbox for MATLAB. http://www.gpsoftnav.com/
- O. Kupervasser, R. Lerner, E. Rivlin and P. H. Rotstein, “Error Analysis for a Navigation Algorithm Based on Optical-Flow and a Digital Terrain Map,” Proceedings of the 2008 IEEE/ION Position, Location and Navigation Symposium, Monterey, 5-8 May 2008, pp. 1203-1212.
- R. M. Haralick, “Propagating Covariance in Computer Vision,” In: A. Rosenfeld, Bowyer and Ahuja, Eds., Advances in Image Understanding, IEEE Computer Society Press, Washington DC, 1996, pp. 142-157.
- W. G. Rees, “The Accuracy of Digital Elevation Models Interpolated to Higher Resolutions,” International Journal of Remote Sensing, Vol. 21, No.1, 2000, pp. 7-20. doi:10.1080/014311600210957
- D. Hoaglin, F. Mosteller and J. Tukey, “Understanding Robust and Exploratory Data Analysis,” John Wiley & Sons Inc, New York, 1983.
- R. Lerner, E. Rivlin and P. H. Rotstein, “Pose and Motion Recovery from Feature Correspondences and a Digital Terrain Map,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 28, No. 9, 2006, pp. 1404- 1417. doi:10.1109/TPAMI.2006.192
- P. Gurfil and H. Rotstein, “Partial Aircraft State Estimation from Visual Motion Using the Subspace Constraints Approach,” Journal of Guidance, Control and Dynamics, Vol. 24, No. 5, 2001, pp. 1016-1028.