Journal of Applied Mathematics and Physics
Vol.04 No.11(2016), Article ID:72413,34 pages
10.4236/jamp.2016.411207
High-Capacity Quantum Associative Memories
M. Cristina Diamantini1, Carlo A. Trugenberger2
1Nips Laboratory, INFN and Dipartimento di Fisica, University of Perugia, Perugia, Italy
2Swiss Scientific, Cologny, Switzerland
Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: September 6, 2016; Accepted: November 27, 2016; Published: November 30, 2016
ABSTRACT
We review our models of quantum associative memories that represent the “quantization” of fully coupled neural networks like the Hopfield model. The idea is to replace the classical irreversible attractor dynamics driven by an Ising model with pattern-dependent weights by the reversible rotation of an input quantum state onto an output quantum state consisting of a linear superposition with probability amplitudes peaked on the stored pattern closest to the input in Hamming distance, resulting in a high probability of measuring a memory pattern very similar to the input. The unitary operator implementing this transformation can be formulated as a sequence of one-qubit and two-qubit elementary quantum gates and is thus the exponential of an ordered quantum Ising model with sequential operations and with pattern-dependent interactions, exactly as in the classical case. Probabilistic quantum memories, that make use of postselection of the measurement result of control qubits, overcome the famed linear storage limitation of their classical counterparts because they permit to completely eliminate crosstalk and spurious memories. The number of control qubits plays the role of an inverse fictitious temperature. The accuracy of pattern retrieval can be tuned by lowering the fictitious temperature under a critical value for quantum content association while the complexity of the retrieval algorithm remains polynomial for any number of patterns polynomial in the number of qubits. These models thus solve the capacity shortage problem of classical associative memories, providing a polynomial improvement in capacity. The price to pay is the probabilistic nature of information retrieval.
Keywords:
Quantum Information, Associative Memory, Quantum Pattern Recognition

1. Introduction
There is a growing consensus that the fundamental mechanism of human intelligence is simply pattern recognition, the retrieval of information based on content association, albeit repeated in ever increasing hierarchical structures [1] [2] . Correspondingly, pattern recognition in machine intelligence [3] has made enormous progress in the last decade or so and such systems are now to be found in applications ranging from medical diagnosis to facial and voice recognition in security and digital personal assistants, the latest addition to the family being self-driving cars. On the other side, the last two decades have seen the birth of, and an explosion of research in a new information- theoretic field: quantum information theory and quantum computation [4] [5] . This chapter deals with quantum pattern recognition, with particular emphasis on models that are both accessible to detailed analytical treatment and efficiently implementable within the framework of the quantum circuit model.
Pattern recognizers, which go also under the name of associative memories (or more precisely autoassociative memories), are fundamentally different than von Neumann or Turing machines [6] , which have grown into the ubiquitous computers that permeate our information society. Computation is not sequential but, rather, based on collective phenomena due to interactions among a large number of, typically redundant, elementary components. Information is not address-oriented, i.e. stored in look-up tables (random access memories, RAMs) but, rather, distributed in often very complex ways over the connections and interactions parameters. In traditional computers information is identified by a label and stored in a database indexed by these labels. Retrieval requires the exact knowledge of the relevant label, without which information is simply not accessible. This is definitely not how our own brain works. When trying to recognize a person from a blurred photo it is totally useless to know that it is the 16878th person you met in your life. Rather, the recognition process is based on our strong power of association with stored memories that resemble the given picture. Association is what we use every time we solve a crossword puzzle and is distinctive of the human brain.
The best known examples of pattern recognizers are neural networks [7] [8] and hidden Markov models [9] , the Hopfield model [10] (and its generalization to a bidirectional associative memory [11] ) being the paradigm, since it can be studied analytically in detail by the techniques of statistical mechanics [7] [8] [12] . The great advantage of these architectures is that they eliminate the extreme rigidity of RAM memories, which require a precise knowledge of the memory address and, thus, do not permit the retrieval of incomplete or corrupted inputs. In associative memories, on the contrary, recall of information is possible also on the basis of partial knowledge of its content, without knowing a precise storage location, which typically does not even exist. This is why they are also called “content-addressable memories”.
Unfortunately, classical associative memories suffer from a severe capacity shortage. When storing multiple patterns, these interfere with each other, a phenomenon that goes under the name of crosstalk. Above a critical number of patterns, crosstalk becomes so strong that a phase transition to a completely disordered spin glass phase [13] takes place. In this phase there is no relation whatsoever between the information encoded in the memory and the original patterns. For the Hopfield model, the critical threshold on the number p of patterns that can be stored in a network of n binary neurons is 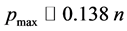 [7] [8] . While various possible improvements can be envisaged, the maximum number of patterns remains linear in the number of neurons,
[7] [8] . While various possible improvements can be envisaged, the maximum number of patterns remains linear in the number of neurons,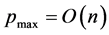 .
.
The power of quantum computation [4] [5] is mostly associated with the speed-up in computing time it can provide with respect to its classical counterpart, the paramount examples being Shor’s factoring algorithm [14] and Grover’s database search algorithm [15] . The efficiency advantage over classical computation is due essentially to the quantum superposition principle and entanglement, which allow for massively parallel information processing.
The bulk of the research effort in quantum computation has focused on the “quantization” of the classical sequential computer architecture, which has led to the quantum circuit model [4] [5] , in which information processing is realized by the sequential application of a universal set of elementary one- and two-qubit gates to typically highly entangled quantum states of many qubits. The computation is said to be efficient if the desired unitary evolution of the quantum state can be realized by the application of a polynomial number (in terms of the number of involved qubits) of these elementary quantum gates.
However, the question immediately arises if quantum mechanics can be applied successfully also to the collective information processing paradigm typical of machine intelligence algorithms and, specifically, if there are advantages in doing so. While this research has trailed the development of the quantum circuit model, it is presently experiencing a flurry of increased interest, so much so that last year NASA and Google have teamed up to found the Quantum Artificial Intelligence Laboratory, entirely dedicated to develop and advance machine intelligence quantum algorithms.
While speed has been the main focus of quantum computation, it can be shown that quantum mechanics also offers a way out from the impossibility of reconciling the association power of content-addressable memories with the requirement of large storage capacity. Indeed, one of us pointed out already in 2001 [16] [17] [18] [19] that storage capacity of associative memories can also be greatly enhanced by the quantum superposition principle. The key idea is to exploit the fundamental probabilistic nature of quantum mechanics. If one is willing to abandon the classical paradigm of one-off retrieval and sacrifice some speed by repeating the information retrieval step several times, then it is possible to store any desired polynomial number (in terms of the number of qubits) of patterns in a quantum associative memory and still tune the associative retrieval to a prescribed accuracy, a large advantage with respect to the classical linear limitation described above. Quantum entanglement permits to completely eliminate crosstalk and spurious memories in a tuneable probabilistic content association procedure with polynomial complexity for a polynomial number of stored patterns. Such probabilistic quantum associative memories can thus be implemented efficiently. Similar ideas in this direction were developed simultaneously in [20] [21] [22] .
In this chapter, we will review our own work on fundamental aspects of quantum associative memories and quantum pattern recognition. We will begin by a short survey of the main features of classical fully coupled neural networks like the Hopfield model and its generalizations, with a special emphasis on the capacity limitation and its origin. We will then describe the quantization of the Hopfield model [23] : the idea is to replace the classical irreversible dynamics that attracts input patterns to the closest minima of an energy function, representing the encoded memories, with a reversible unitary quantum evolution that amplifies an input quantum state to an output quantum state representing one of the stored memories at a given computational time t. In the classical model there is a complex phase diagram in terms of the two noise parameters, the temperature T and the disorder p/n with n the number of bits and p the number of stored patterns. It is, specifically the disorder due to an excessive loading factor p/n that prevents the storage of more than a critical number of patterns by causing the transition to a spin glass phase [13] , even at zero temperature. Correspondingly, in the quantum version there are quantum phase transitions due to both disorder and quantum fluctuations, the latter being encoded in the effective coupling Jt, with J being the energy parameter of the model and t being the computational time (throughout the review we will use units in which c = 1 and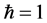 ). These are first examples of quantum collective phenomena typical of quantum machine intelligence. It turns out that, barring periodicity effects due to the unitary time evolution, the phase diagram for the quantum Hopfield model is not so different from its classical counterpart. Specifically, for small loading factors the quantum network has indeed associative power, a very interesting feature by itself, but the maximum loading factor is still limited to
). These are first examples of quantum collective phenomena typical of quantum machine intelligence. It turns out that, barring periodicity effects due to the unitary time evolution, the phase diagram for the quantum Hopfield model is not so different from its classical counterpart. Specifically, for small loading factors the quantum network has indeed associative power, a very interesting feature by itself, but the maximum loading factor is still limited to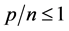 , above which there is a totally disordered spin glass phase, with no association power for any computational time. The transition to this quantum spin glass phase takes place when one tries to store a number of memories that is not anymore linearly independent.
, above which there is a totally disordered spin glass phase, with no association power for any computational time. The transition to this quantum spin glass phase takes place when one tries to store a number of memories that is not anymore linearly independent.
We then turn our attention to probabilistic quantum associative memories [16] [17] [18] [19] . The basic idea underlying their architecture is essentially the same as above, with one crucial difference: they exploit, besides a unitary evolution, a second crucial aspect of quantum mechanics, namely wave function collapse upon measurement [4] [5] . A generic (pure) quantum state is a superposition of basis states with complex coefficients. A measurement projects (collapses) the state probabilistically onto one of the basis states, the probability distribution being governed by the squared absolute values of the superposition coefficients. Probabilistic quantum associative memories involve, besides the memory register itself a certain number b of control qubits. The unitary evolution of the input state is again determined by a Hamiltonian that depends only on the stored patterns. Contrary to quantized Hopfield memories, however, this unitary evolution mixes the memory register and the control qubits. After having applied the unitary evolution to the initial input state, the control qubits are measured. Only if one obtains a certain specific result, one proceeds to measure the memory register. This procedure is called probabilistic postselection of the measurement result and guarantees that the memory register is in a superposition of the stored patterns such that the measurement probabilities are peaked on those patterns that minimize the Hamming distance to the input. A measurement of the memory register will thus associate input and stored patterns according to this probability distribution.
Of course, if we limit ourselves to a maximum number T of repetitions, there is a non-vanishing probability that the memory retrieval will fail entirely, since the correct control qubit state will never be measured. One can say that information retrieval in these quantum memories consists of two steps: recognition (the correct state of the control qubits has been obtained) and identification (the memory register is measured to give an output). Both steps are probabilistic and both the recognition efficiency and the identification accuracy depend on the distribution of the stored patterns: recognition efficiency is best when the number of stored patterns is large and the input is similar to a substantial cluster of them, while identification accuracy is best for isolated patterns which are very different from all other ones, both very intuitive features. Both recognition efficiency and identification accuracy can be tuned to prescribed levels by varying the repetition threshold T and the number b of control qubits.
The accuracy of the input-output association depends only on the choice of the number b of control qubits. Indeed, we will show that 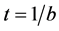 plays the role of an effective temperature [19] . The lower t, the sharper is the corresponding effective Boltz- mann distribution on the states closest in Hamming distance to the input and the better becomes the identification. By averaging over the distribution of stored patterns with Hamming distance to the input above a threshold d one can eliminate the dependence on the stored pattern distribution and derive the effective statistical mechanics of quantum associative memories by introducing the usual thermodynamic potentials as a function of d and the effective temperature
plays the role of an effective temperature [19] . The lower t, the sharper is the corresponding effective Boltz- mann distribution on the states closest in Hamming distance to the input and the better becomes the identification. By averaging over the distribution of stored patterns with Hamming distance to the input above a threshold d one can eliminate the dependence on the stored pattern distribution and derive the effective statistical mechanics of quantum associative memories by introducing the usual thermodynamic potentials as a function of d and the effective temperature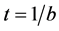 . In particular, the free energy
. In particular, the free energy 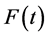 describes the average behaviour of the recall mechanism and provides concrete criteria to tune the accuracy of the quantum associative memory. By increasing b (lowering t), the associative memory undergoes a phase transition from a disordered phase with no correlation between input and output to an ordered phase with perfect input-output association encoded in the minimal Hamming distance d. This extends to quantum information theory the relation with Ising spin systems known in error-correcting codes [24] [25] [26] and in public key cryptography [27] .
describes the average behaviour of the recall mechanism and provides concrete criteria to tune the accuracy of the quantum associative memory. By increasing b (lowering t), the associative memory undergoes a phase transition from a disordered phase with no correlation between input and output to an ordered phase with perfect input-output association encoded in the minimal Hamming distance d. This extends to quantum information theory the relation with Ising spin systems known in error-correcting codes [24] [25] [26] and in public key cryptography [27] .
The recognition efficiency can be tuned mainly by varying the repetition threshold T: the higher T, the larger the number of input qubits that can be corrupted without affecting recognition. The crucial point is that the recognition probability is bounded from below by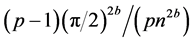 . For any number of patterns, thus, a repetition threshold T polynomial in n guarantees recognition with probability
. For any number of patterns, thus, a repetition threshold T polynomial in n guarantees recognition with probability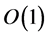 . Due to the factor
. Due to the factor 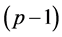 in the numerator, whose origin is exclusively quantum mechanical, the number of repetitions required for efficient recognition would actually be polynomial even for a number of patterns exponential in n. The overall complexity of probabilistic associative quantum memories is thus bounded by the complexity
in the numerator, whose origin is exclusively quantum mechanical, the number of repetitions required for efficient recognition would actually be polynomial even for a number of patterns exponential in n. The overall complexity of probabilistic associative quantum memories is thus bounded by the complexity 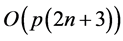 of the unitary evolution operator. Any polynomial number of patterns
of the unitary evolution operator. Any polynomial number of patterns 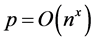 can be encoded and retrieved efficiently in polynomial computing time. The absence of spurious memories leads to a substantial storage gain with respect to classical associative memories, the price to pay being the probabilistic nature of information recall.
can be encoded and retrieved efficiently in polynomial computing time. The absence of spurious memories leads to a substantial storage gain with respect to classical associative memories, the price to pay being the probabilistic nature of information recall.
2. The Classical Hopfield Model
Historically, the interest in neural networks [7] [8] has been driven by the desire to build machines capable of performing tasks for which the traditional sequential computer architecture is not well suited, like pattern recognition, categorization and generalization. Since these higher cognitive tasks are typical of biological intelligences, the design of these parallel distributed processing systems has been largely inspired by the physiology of the human brain.
The Hopfield model is one of the best studied and most successful neural networks. It was designed to model one particular higher cognitive function of the human brain, that of associative pattern retrieval or associative memory.
The Hopfield model consists of an assembly of n binary neurons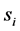 ,
,  [28] , which can take the values ±1 representing their firing (+1) and resting (−1) states. The neurons are fully connected by symmetric synapses with coupling strengths
[28] , which can take the values ±1 representing their firing (+1) and resting (−1) states. The neurons are fully connected by symmetric synapses with coupling strengths 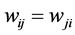 (
(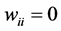 ). Depending on the signs of these synaptic strengths, the couplings will be excitatory (>0) or inhibitory (<0). The model is characterised by an energy function
). Depending on the signs of these synaptic strengths, the couplings will be excitatory (>0) or inhibitory (<0). The model is characterised by an energy function
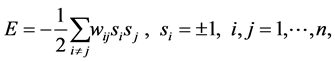 (1)
(1)
and its dynamical evolution is defined by the random sequential updating (in time t) of the neurons according to the rule
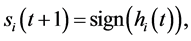 (2)
(2)
 (3)
(3)
where  is called the local magnetization.
is called the local magnetization.
The synaptic coupling strengths are chosen according to the Hebb rule
 (4)
(4)
where ,
,  are p binary patterns to be memorized. An associative memory is defined as a dynamical mechanism that, upon preparing the network in an initial state
are p binary patterns to be memorized. An associative memory is defined as a dynamical mechanism that, upon preparing the network in an initial state  retrieves the stored pattern
retrieves the stored pattern  that most closely resembles the presented pattern
that most closely resembles the presented pattern , where resemblance is determined by minimizing the Hamming distance, i.e. the total number of different bits in the two patterns. As emerges clearly from this definition, all the memory information in a Hopfield neural network is encoded in the synaptic strengths.
, where resemblance is determined by minimizing the Hamming distance, i.e. the total number of different bits in the two patterns. As emerges clearly from this definition, all the memory information in a Hopfield neural network is encoded in the synaptic strengths.
It can be easily shown that the dynamical evolution (2) of the Hopfield model satis- fies exactly the requirement for an associative memory. This is because:
・ The dynamical evolution (2) minimizes the energy functional (1), i.e. this energy functional never increases when the network state is updated according to the evolution rule (2). Since the energy functional is bounded by below, this implies that the network dynamics must eventually reach a stationary point corresponding to a, possibly local, minimum of the energy functional.
・ The stored patterns  correspond to, possibly local, minima of the energy functional. This implies that the stored patterns are attractors for the network dynamics (2). An initial pattern will evolve till it overlaps with the closest (in Hamming distance) stored pattern, after which it will not change anymore.
correspond to, possibly local, minima of the energy functional. This implies that the stored patterns are attractors for the network dynamics (2). An initial pattern will evolve till it overlaps with the closest (in Hamming distance) stored pattern, after which it will not change anymore.
Actually, the second of these statements must be qualified. Indeed, the detailed behavior of the Hopfield model depends crucially upon the loading factor , the ratio between the number of stored memories and the number of available bits. This is best analyzed in the thermodynamic limit
, the ratio between the number of stored memories and the number of available bits. This is best analyzed in the thermodynamic limit ,
,  , in which the different regimes can be studied by statistical mechanics techniques [7] [8] [12] and characterized formally by the values of critical parameters.
, in which the different regimes can be studied by statistical mechanics techniques [7] [8] [12] and characterized formally by the values of critical parameters.
For , the system is in a ferromagnetic (F) phase in which there are global energy minima corresponding to all stored memories. The former differ from the original input memories only in a few percent of the total number of bits. Mixing between patterns leads to spurious local energy minima. These, however are destabilized at sufficiently high temperatures.
, the system is in a ferromagnetic (F) phase in which there are global energy minima corresponding to all stored memories. The former differ from the original input memories only in a few percent of the total number of bits. Mixing between patterns leads to spurious local energy minima. These, however are destabilized at sufficiently high temperatures.
For , the system is in a mixed spin glass (SG) [13] and ferromagnetic phase. There are still minima of sizable overlap with the original memories but they are now only metastable states. The true ground state is the spin glass, characterized by an exponentially increasing number of minima due to the mixing of original memories (crosstalk). The spin glass phase is orthogonal to all stored memories. If an input pattern is sufficiently near (in Hamming distance) to one of the original memories it will be trapped by the corresponding metastable state and the retrieval procedure is successful. On the other hand, if the input pattern is not sufficiently close to one of the stored memories, the network is confused and it will end up in a state very far from all original memories.
, the system is in a mixed spin glass (SG) [13] and ferromagnetic phase. There are still minima of sizable overlap with the original memories but they are now only metastable states. The true ground state is the spin glass, characterized by an exponentially increasing number of minima due to the mixing of original memories (crosstalk). The spin glass phase is orthogonal to all stored memories. If an input pattern is sufficiently near (in Hamming distance) to one of the original memories it will be trapped by the corresponding metastable state and the retrieval procedure is successful. On the other hand, if the input pattern is not sufficiently close to one of the stored memories, the network is confused and it will end up in a state very far from all original memories.
For , the system is in a pure spin glass (SG) phase [13] in which all retrieval capabilities are lost due to an uncontrolled proliferation of spurious memories. It is this phase transition to a spin glass that limits the storage capacity of the Hopfield model to
, the system is in a pure spin glass (SG) phase [13] in which all retrieval capabilities are lost due to an uncontrolled proliferation of spurious memories. It is this phase transition to a spin glass that limits the storage capacity of the Hopfield model to . While various improvements are possible, the storage capacity of classical associative memories remains linearly bounded by the number n of classical bits [7] [8] .
. While various improvements are possible, the storage capacity of classical associative memories remains linearly bounded by the number n of classical bits [7] [8] .
3. Quantum Neural Networks and the Quantization of the Hopfield Model
In this section, we introduce a quantum information processing paradigm that is different from the standard quantum circuit model [23] . Instead of one- and two-qubit gates that are switched on and off sequentially, we will consider long-range interactions that define a fully-connected quantum neural network of qubits. This is encoded in a Hamiltonian that generates a unitary evolution in which the operator acting on one qubit depends on the collective quantum state of all the other qubits. Note that some of the most promising technologies for the implementation of quantum information processing, like optical lattices [29] and arrays of quantum dots [30] rely exactly on similar collective phenomena.
In mathematical terms, the simplest classical neural network model is a graph with the following properties:
・ A state variable  is associated with each node (neuron) i.
is associated with each node (neuron) i.
・ A real-valued weight  is associated with each link (synapse) (ij) between two nodes i and j.
is associated with each link (synapse) (ij) between two nodes i and j.
・ A state-space-valued transfer function  of the synaptic potential
of the synaptic potential  determines the dynamics of the network.
determines the dynamics of the network.
Directed graphs correspond to feed-forward neural networks [7] [8] while undirected graphs with symmetric weights contain feed-back loops. If the graph is complete one has fully-connected neural networks like the Hopfield model. Two types of dynamical evolution have been considered: sequential or parallel synchronous. In the first case the neurons are updated one at a time according to
 (5)
(5)
while in the second case all neurons are updated at the same time. The simplest model is obtained when neurons become binary variables taking only the values  for all i and the transfer function becomes the sign function. This is the original Mc-Cullogh- Pitts [28] neural network model, in which the two states represent quiescent and firing neurons.
for all i and the transfer function becomes the sign function. This is the original Mc-Cullogh- Pitts [28] neural network model, in which the two states represent quiescent and firing neurons.
As we have seen in the previous section, the Hopfield model [10] is a fully-connected McCullogh-Pitts network in which the synaptic weights are symmetric quantities chosen according to the Hebb rule [7] [8]
 (6)
(6)
and in which the the dynamics-defining function f is the sign function, . This dynamics minimises the energy function
. This dynamics minimises the energy function
 (7)
(7)
where n is the total number of neurons and  are the p binary patterns to be memorized (
are the p binary patterns to be memorized ( )
)
A quantum McCullogh-Pitts network can correspondingly be defined as a graph that satisfies:
・ A two-dimensional Hilbert space  is associated with each node (neuron) i, i.e. each neuron becomes a qubit whose basis states can be labeled as
is associated with each node (neuron) i, i.e. each neuron becomes a qubit whose basis states can be labeled as  and
and .
.
・ A vector-valued weight  is associated with each link (synapse) (ij) between two nodes i and j.
is associated with each link (synapse) (ij) between two nodes i and j.
・ The synaptic potential becomes an operator , where
, where  is the vector of Pauli matrices acting on the Hilbert space
is the vector of Pauli matrices acting on the Hilbert space . A unitary operator
. A unitary operator  determines the dynamics of the network starting from an initial input quantum state on the product Hilbert space of all qubits.
determines the dynamics of the network starting from an initial input quantum state on the product Hilbert space of all qubits.
In case of feed-forward quantum networks on directed graphs only a subset of qubits is measured after the unitary evolution, in case of fully connected quantum networks with symmetric weights the state of the whole network is relevant.
The crucial difference with respect to classical neural networks concerns the interactions between qubits. In the classical model, the dynamics (5) induced by the transfer function is fully deterministic and irreversible, which is not compatible with quantum mechanics. A first generalization that has been considered is that of stochastic neurons, in which the transfer function determines only the probabilities that the classical state variables will take one of the two values:  with probabilities
with probabilities , where f must satisfy
, where f must satisfy ,
,  and
and . While this modification makes the dynamics probabilistic by introducing thermal noise, the evolution of the network is still irreversible since the actual values of the neurons are prescribed after an update step. In quantum mechanics the evolution must be reversible and only the magnitudes of the changes in the neuron variables can be postulated. Actually, the dynamics must generate a unitary evolution of the network.
. While this modification makes the dynamics probabilistic by introducing thermal noise, the evolution of the network is still irreversible since the actual values of the neurons are prescribed after an update step. In quantum mechanics the evolution must be reversible and only the magnitudes of the changes in the neuron variables can be postulated. Actually, the dynamics must generate a unitary evolution of the network.
It is known that two-level unitary gates are universal, i.e. every unitary matrix on an n-dimensional Hilbert space may be written as a product of two-level unitary matrices. However, an arbitrary unitary evolution cannot be implemented as a sequential succession of a discrete set of elementary gates, nor can it be approximated efficiently with a polynomial number of such gates [4] [5] . In general, quantum neural networks as defined above, have to be thought of as defined by Hamiltonians H that code hard-wired qubit interactions and generate a unitary evolution . This corresponds to the parallel synchronous dynamics of classical neural networks. Only in particular cases, one of which will be the subject of the next section, does this unitary evolution admit a representation as a sequential succession of a discrete set of elementary one- and two- bit gates. In this cases the network admits a sequential dynamics as its classical counterpart.
. This corresponds to the parallel synchronous dynamics of classical neural networks. Only in particular cases, one of which will be the subject of the next section, does this unitary evolution admit a representation as a sequential succession of a discrete set of elementary one- and two- bit gates. In this cases the network admits a sequential dynamics as its classical counterpart.
We now describe a direct “quantization” of the Hopfield model in this spirit, i.e. by defining a quantum Hamiltonian that generalizes (7). At first sight one would be tempted to simply replace the classical spins  of (7) with the third Pauli matrix
of (7) with the third Pauli matrix  acting on the Hilbert space
acting on the Hilbert space . This however would accomplish nothing, the model would still be identical to the original classical model, since all terms in the Hamiltonian would commute between themselves. A truly quantum model must involve at least two of the three Pauli matrices. In [23] we have proposed the following “transverse” Hamiltonian:
. This however would accomplish nothing, the model would still be identical to the original classical model, since all terms in the Hamiltonian would commute between themselves. A truly quantum model must involve at least two of the three Pauli matrices. In [23] we have proposed the following “transverse” Hamiltonian:
 (8)
(8)
where ,
,  denote the Pauli matrices and J is a coupling constant with the dimensions of mass (we remind the reader that we use units in which
denote the Pauli matrices and J is a coupling constant with the dimensions of mass (we remind the reader that we use units in which ). This generates a unitary evolution of the network:
). This generates a unitary evolution of the network:
 (9)
(9)
where . Specifically, we will choose as initial configuration of the network the uniform superposition of all computational basis states [4] [5]
. Specifically, we will choose as initial configuration of the network the uniform superposition of all computational basis states [4] [5]
 (10)
(10)
This corresponds to a “blank memory” in the sense that all possible states have the same probability of being recovered upon measurement. In the language of spin systems this is a state in which all spins are aligned in the x direction.
Inputs  can be accomodated by adding an external transverse magnetic field along the y axis, i.e. modifying the Hamiltonian to
can be accomodated by adding an external transverse magnetic field along the y axis, i.e. modifying the Hamiltonian to
 (11)
(11)
where . This external magnetic field can be thought of as arising from the interaction of the network with an additional “sensory” qubit register prepared in the state
. This external magnetic field can be thought of as arising from the interaction of the network with an additional “sensory” qubit register prepared in the state , the synaptic weights between the two layers being identical to those of the network self-couplings.
, the synaptic weights between the two layers being identical to those of the network self-couplings.
Let us now specialize to the simplest case of one assigned memory  in which
in which . In the classical Hopfield model there are two nominal stable states that represent attractors for the dynamics, the pattern
. In the classical Hopfield model there are two nominal stable states that represent attractors for the dynamics, the pattern  itself and its negative
itself and its negative . Correspondingly, the quantum dynamics defined by the Hamiltonian (8) and the initial state (10) have a
. Correspondingly, the quantum dynamics defined by the Hamiltonian (8) and the initial state (10) have a  symmetry generated by
symmetry generated by , corresponding to the inversion
, corresponding to the inversion  of all qubits.
of all qubits.
As in the classical case we shall analyze the model in the mean field approximation. In this case, the mean field represents the average over quantum fluctuations rather than thermal ones but the principle remains the same. The mean field model becomes exactly solvable and allows to derive self-consistency conditions on the average overlaps with the stored patterns. In the classical case, the mean field approximation is known to become exact for long-range interactions [31] .
In the quantum mean-field approximation operators are decomposed in a sum of their mean values in a given quantum state and fluctuations around it,  , and quadratic terms in the fluctuations are neglected in the Hamiltonian. Apart from an irrelevant constant, this gives
, and quadratic terms in the fluctuations are neglected in the Hamiltonian. Apart from an irrelevant constant, this gives
 (12)
(12)
where  is the average overlap of the state of the network with the stored pattern. This means that each qubit i interacts with the average magnetic field (synaptic potential)
is the average overlap of the state of the network with the stored pattern. This means that each qubit i interacts with the average magnetic field (synaptic potential)  due to all other qubits: naturally, the correct values of these mean magnetic fields
due to all other qubits: naturally, the correct values of these mean magnetic fields  have to be determined self-consistently.
have to be determined self-consistently.
To this end we compute the average pattern overlaps  using the mean field Hamiltonian (12) to generate the time evolution of the quantum state. This reduces to a sequence of factorized rotations in the Hilbert spaces of each qubit, giving
using the mean field Hamiltonian (12) to generate the time evolution of the quantum state. This reduces to a sequence of factorized rotations in the Hilbert spaces of each qubit, giving
 (13)
(13)
where  and
and  is the average over-
is the average over-
lap of the external stimulus with the stored memory.
Before we present the detailed solution of these equations, let us illustrate the mechanism underlying the quantum associative memory. To this end we note that, for , the pattern overlaps
, the pattern overlaps  and
and  in the two directions cannot be simultaneously different from zero. As we show below, only
in the two directions cannot be simultaneously different from zero. As we show below, only  for
for  (for
(for  the roles of
the roles of  and
and  are interchanged). In this case the evolution of the network becomes a sequence of n rotations
are interchanged). In this case the evolution of the network becomes a sequence of n rotations
 (14)
(14)
in the two-dimensional Hilbert spaces of each qubit i. The rotation parameter is exactly the same synaptic potential  which governs the classical dynamics of the Hopfield model. When these rotations are applied on the initial state (10) they amount to a single update step transforming the qubit spinors into
which governs the classical dynamics of the Hopfield model. When these rotations are applied on the initial state (10) they amount to a single update step transforming the qubit spinors into
 (15)
(15)
This is the generalization to quantum probability amplitudes of the probabilistic formulation of classical stochastic neurons. Indeed, the probabilities for the qubit to be in its eigenstates ±1 after a time t, obtained by squaring the probability amplitudes, are given by , where
, where  has exactly the properties of an activation function (alternative to the Fermi function), at least in the region
has exactly the properties of an activation function (alternative to the Fermi function), at least in the region . In this correspondence, the effective coupling constant Jt plays the role of the inverse temperature, as usual in quantum mechanics.
. In this correspondence, the effective coupling constant Jt plays the role of the inverse temperature, as usual in quantum mechanics.
We shall now focus on a network without external inputs. In this case the equation for the average pattern overlaps has only the solution  for
for . For such small effective couplings (high effective temperatures), corresponding to weak synaptic connections or to short evolution times, the network is unable to remember the stored pattern. For
. For such small effective couplings (high effective temperatures), corresponding to weak synaptic connections or to short evolution times, the network is unable to remember the stored pattern. For , however, the solution
, however, the solution  becomes unstable, and two new stable solutions
becomes unstable, and two new stable solutions  appear. This means that the reaction of the mean orientation of the qubit spinors against a small deviation
appear. This means that the reaction of the mean orientation of the qubit spinors against a small deviation  from the
from the  solution is larger than the deviation itself. Indeed, any so small external perturbation
solution is larger than the deviation itself. Indeed, any so small external perturbation  present at the bifurcation time
present at the bifurcation time  is sufficient for the network evolution to choose one of the two stable solutions, according to the sign of the external perturbation. The point
is sufficient for the network evolution to choose one of the two stable solutions, according to the sign of the external perturbation. The point  represents a quantum phase transition [32] from an amnesia (paramagnetic) phase to an ordered (ferromagnetic) phase in which the network has recall capabilities: the average pattern overlap
represents a quantum phase transition [32] from an amnesia (paramagnetic) phase to an ordered (ferromagnetic) phase in which the network has recall capabilities: the average pattern overlap  is the corresponding order parameter. In the ferromagnetic phase the original Z2 symmetry of the model is spontaneously broken.
is the corresponding order parameter. In the ferromagnetic phase the original Z2 symmetry of the model is spontaneously broken.
For , the solution becomes
, the solution becomes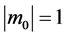 , which means that the network is capable of perfect recall of the stored memory. For
, which means that the network is capable of perfect recall of the stored memory. For , the solution
, the solution  decreases slowly to 0 again. Due to the periodicity of the time evolution, however, new stable solutions
decreases slowly to 0 again. Due to the periodicity of the time evolution, however, new stable solutions  appear at
appear at  for every integer n. Also, for
for every integer n. Also, for , new solutions with
, new solutions with  and
and  appear. These, however, correspond all to metastable states. Thus,
appear. These, however, correspond all to metastable states. Thus,  is the ideal computation time for the network.
is the ideal computation time for the network.
The following picture of quantum associative memories emerges from the above construction. States of the network are generic linear superpositions of computational basis states. The network is prepared in the state  and is then let to unitarily evolve for a time t. After this time the state of the network is measured, giving the result of the computation. During the evolution each qubit updates its quantum state by a rotation that depends on the aggregated synaptic potential determined by the state of all other qubits. These synaptic potentials are subject to large quantum fluctutations which are symmetric around the mean value
and is then let to unitarily evolve for a time t. After this time the state of the network is measured, giving the result of the computation. During the evolution each qubit updates its quantum state by a rotation that depends on the aggregated synaptic potential determined by the state of all other qubits. These synaptic potentials are subject to large quantum fluctutations which are symmetric around the mean value . If the interaction is strong enough, any external disturbance will cause the fluctuations to collapse onto a collective rotation of all the network’s qubits towards the nearest memory.
. If the interaction is strong enough, any external disturbance will cause the fluctuations to collapse onto a collective rotation of all the network’s qubits towards the nearest memory.
We will now turn to the more interesting case of a finite density  of stored memories in the limit
of stored memories in the limit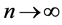 . In this case, the state of the network can have a finite overlap with several stored memories
. In this case, the state of the network can have a finite overlap with several stored memories  simultaneously. As in the classical case we shall focus on the most interesting case of a single “condensed pattern”, in which the network uniquely recalls one memory without admixtures. Without loss of generality we will chose this memory to be the first,
simultaneously. As in the classical case we shall focus on the most interesting case of a single “condensed pattern”, in which the network uniquely recalls one memory without admixtures. Without loss of generality we will chose this memory to be the first,  , omitting then the memory superscript on the corresponding overlap m. Correspondingly, we will consider external inputs so that only
, omitting then the memory superscript on the corresponding overlap m. Correspondingly, we will consider external inputs so that only . For simplicity of presentation, we will focus directly on solutions with a non-vanishing pattern overlap along the z-axis, omitting also the direction superscript z.
. For simplicity of presentation, we will focus directly on solutions with a non-vanishing pattern overlap along the z-axis, omitting also the direction superscript z.
In case of a finite density of stored patterns, one cannot neglect the noise effect due to the infinite number of memories. This changes (13) to
 (16)
(16)
As in the classical case we will assume that  and
and  are all independent random variables with mean zero and we will denote by square brackets the configurational average over the distributions of these random variables. As a consequence of this assumption, the mean and variance of the noise term are given by
are all independent random variables with mean zero and we will denote by square brackets the configurational average over the distributions of these random variables. As a consequence of this assumption, the mean and variance of the noise term are given by  and
and , where
, where
 (17)
(17)
is the spin-glass order parameter [13] . According to the central limit theorem one can now replace  in (16) by an average over a Gaussian noise,
in (16) by an average over a Gaussian noise,
 (18)
(18)
The second order parameter r has to be evaluated self-consistently by a similar procedure starting from the equation analogous to Equation (16) for . In this case one can use
. In this case one can use  for
for  to expand the transcendental function on the right- hand side in powers of this small parameter, which gives
to expand the transcendental function on the right- hand side in powers of this small parameter, which gives
 (19)
(19)
where . Solving the integrals gives finally the following coupled equations for the two order parameters m and r:
. Solving the integrals gives finally the following coupled equations for the two order parameters m and r:
 (20)
(20)
In terms of these order parameters one can distinguish three phases of the network. First of all the value of m determines the presence ( ) or absence (
) or absence ( ) of ferromagnetic order (F). If
) of ferromagnetic order (F). If  the network can be in a paramagnetic phase (P) if also
the network can be in a paramagnetic phase (P) if also  or a quantum spin glass phase (SG) if
or a quantum spin glass phase (SG) if . The phase structure resulting from a numerical solution of the coupled Equation (20) for
. The phase structure resulting from a numerical solution of the coupled Equation (20) for  is shown in Figure 1.
is shown in Figure 1.
For  the picture is not very different from the single memory case. For large enough computation times there exists a ferromagnetic phase in which the
the picture is not very different from the single memory case. For large enough computation times there exists a ferromagnetic phase in which the  solution is unstable and the network has recall capabilities. The only difference is that the maximum value of the order parameter m is smaller than 1 (recall is not perfect due to noise) and the ideal computation time t at which the maximum is reached depends on
solution is unstable and the network has recall capabilities. The only difference is that the maximum value of the order parameter m is smaller than 1 (recall is not perfect due to noise) and the ideal computation time t at which the maximum is reached depends on . For
. For  instead, ferromagnetic order coexists as a metastable state with a quantum spin glass state. This means that ending up in the memory retrieval solution depends not only on the presence of an external stimulus but also on its magnitude; in other words, the external pattern has to be close enough to the stored memory in order to be retrieved. For
instead, ferromagnetic order coexists as a metastable state with a quantum spin glass state. This means that ending up in the memory retrieval solution depends not only on the presence of an external stimulus but also on its magnitude; in other words, the external pattern has to be close enough to the stored memory in order to be retrieved. For  all retrieval capabilities are lost and the
all retrieval capabilities are lost and the

Figure 1. The phase structure of quantum associative memories with finite density of stored patterns. P, F and SG denote (quantum) paramagnetic, ferromagnetic and spin-glass phases, respectively. F + SG denotes a mixed phase in which the memory retrieval solution is only locally stable.
network will be in a quantum spin glass state for all computation times (after the transition from the quantum paramagnet).  is thus the maximum memory capacity of this quantum network. Note that
is thus the maximum memory capacity of this quantum network. Note that  corresponds to the maximum possible number of linearly independent memories. For memory densities smaller but close to this maximum value, however, the ferromagnetic solution exists only for a small range of effective couplings centered around
corresponds to the maximum possible number of linearly independent memories. For memory densities smaller but close to this maximum value, however, the ferromagnetic solution exists only for a small range of effective couplings centered around : for these high values of
: for these high values of  the quality of pattern retrieval is poor, the value of the order parameter m being of the order 0.15 - 0.2. Much better retrieval qualities are obtained for smaller effective couplings: e.g. for
the quality of pattern retrieval is poor, the value of the order parameter m being of the order 0.15 - 0.2. Much better retrieval qualities are obtained for smaller effective couplings: e.g. for  the order parameter is larger than 0.9 (corresponding to an error rate smaller than 5%) for memory densities up to 0.1. In this case, however the maximum memory density is 0.175, comparable with the classical result of the Hopfield model. Quantum mechanics, here, does not carry any advantage.
the order parameter is larger than 0.9 (corresponding to an error rate smaller than 5%) for memory densities up to 0.1. In this case, however the maximum memory density is 0.175, comparable with the classical result of the Hopfield model. Quantum mechanics, here, does not carry any advantage.
4. Probabilistic Quantum Memories
We have seen in the last section that crosstalk prevents the amplification of patterns stored in the weights of a simple quantum Hamiltonian like (8) when the loading factor exceeds a linear bound comparable with the classical one. In this section we show that this limit can be overcome by probabilistic quantum memories, which use postselection of the measurement results of certain control qubits [16] [17] [18] [19] . The price to pay is that such probabilistic memories require repetitions of the retrieval process and that there is non-vanishing probability that this fails entirely. When it is successful, however, it allows retrieval of the most appropriate pattern among a polynomial pool instead of a linear one.
4.1. Storing Patterns
Let us start by describing the elementary quantum gates [4] [5] that we will use in the rest of the paper. First of all there are the single-qbit gates represented by the Pauli matrices ,
, . The first Pauli matrix
. The first Pauli matrix , in particular, implements the NOT gate. Another single-qbit gate is the Hadamard gate H, with the matrix representation
, in particular, implements the NOT gate. Another single-qbit gate is the Hadamard gate H, with the matrix representation
 (21)
(21)
Then, we will use extensively the two-qbit XOR (exclusive OR) gate, which performs a NOT on the second qbit if and only if the first one is in state . In matrix notation this gate is represented as
. In matrix notation this gate is represented as , where 1 denotes a two-dimensional identity matrix and
, where 1 denotes a two-dimensional identity matrix and  acts on the components
acts on the components  and
and  of the Hilbert space. The 2XOR, or Toffoli gate is the three qbit generalization of the XOR gate: it performs a NOT on the third qbit if and only if the first two are both in state
of the Hilbert space. The 2XOR, or Toffoli gate is the three qbit generalization of the XOR gate: it performs a NOT on the third qbit if and only if the first two are both in state . In matrix notation it is given by
. In matrix notation it is given by . In the storage algorithm we shall make use also of the nXOR generalization of these gates, in which there are n control qbits. This gate is also used in the subroutines implementing the oracles underlying Grover’s algorithm [4] [5] and can be realized using unitary maps affecting only few qbits at a time [33] , which makes it efficient. All these are standard gates. In addition to them we introduce the two-qbit controlled gates
. In the storage algorithm we shall make use also of the nXOR generalization of these gates, in which there are n control qbits. This gate is also used in the subroutines implementing the oracles underlying Grover’s algorithm [4] [5] and can be realized using unitary maps affecting only few qbits at a time [33] , which makes it efficient. All these are standard gates. In addition to them we introduce the two-qbit controlled gates
 (22)
(22)
for . These have the matrix notation
. These have the matrix notation . For all these gates we shall indicate by subscripts the qbits on which they are applied, the control qbits coming always first.
. For all these gates we shall indicate by subscripts the qbits on which they are applied, the control qbits coming always first.
The construction of quantum memories relies, of course, on the fundamental fact that one can use entanglement to “store” an arbitrary number p of binary patterns  of length n in a quantum superposition of just n qubits,
of length n in a quantum superposition of just n qubits,
 (23)
(23)
The idea of the memory architecture consists thus of two steps:
・ Generate the state  by a unitary evolution M from a simple prepared state, say
by a unitary evolution M from a simple prepared state, say ,
, .
.
・ Given an input state , generate from
, generate from  a superposition of the pattern states that is no more uniform but whose amplitudes define a probability distribution peaked on the pattern states with minimal Hamming distance front the input. It is this step that involves both a unitary evolution and a postselection of the measurement result.
a superposition of the pattern states that is no more uniform but whose amplitudes define a probability distribution peaked on the pattern states with minimal Hamming distance front the input. It is this step that involves both a unitary evolution and a postselection of the measurement result.
The quantum memory itself is the unitary operator M that codes the p patterns. It defines implicitly a Hamiltonian through the formal relation , a Hamiltonian that represents pattern-dependent interactions among the qubits. This is the quantum generalization of the classical Hopfield model. In order to dispel any possible misunderstandings right away, we point out that this is quite different to the communication of classical information via a quantum channel, limited by the Holevo theorem [34] , as we discuss in detail below.
, a Hamiltonian that represents pattern-dependent interactions among the qubits. This is the quantum generalization of the classical Hopfield model. In order to dispel any possible misunderstandings right away, we point out that this is quite different to the communication of classical information via a quantum channel, limited by the Holevo theorem [34] , as we discuss in detail below.
In order to construct explicitly the quantum memory M we will start from an algorithm that loads sequentially the classical patterns into an auxiliary register, from which they are then copied into the actual memory register. A first version of such an algorithm was introduced in [35] . The simplified version that we present here is due to [16] [17] .
We shall use three registers: a first register p of n qbits in which we will subsequently feed the patterns  to be stored, a utility register u of two qbits prepared in state
to be stored, a utility register u of two qbits prepared in state , and another register m of n qbits to hold the memory. This latter will be initially prepared in state
, and another register m of n qbits to hold the memory. This latter will be initially prepared in state . The full initial quantum state is thus
. The full initial quantum state is thus
 (24)
(24)
The idea of the storage algorithm is to separate this state into two terms, one corresponding to the already stored patterns, and another ready to process a new pattern. These two parts will be distinguished by the state of the second utility qbit :
:  for the stored patterns and
for the stored patterns and  for the processing term.
for the processing term.
For each pattern  to be stored one has to perform the operations described be- low:
to be stored one has to perform the operations described be- low:
 (25)
(25)
This simply copies pattern  into the memory register of the processing term, identified by
into the memory register of the processing term, identified by .
.
 (26)
(26)
The first of these operations makes all qbits of the memory register ’s when the contents of the pattern and memory registers are identical, which is exactly the case only for the processing term. Together, these two operations change the first utility qbit
’s when the contents of the pattern and memory registers are identical, which is exactly the case only for the processing term. Together, these two operations change the first utility qbit  of the processing term to a
of the processing term to a , leaving it unchanged for the stored patterns term.
, leaving it unchanged for the stored patterns term.
 (27)
(27)
This is the central operation of the storing algorithm. It separates out the new pattern to be stored, already with the correct normalization factor.
 (28)
(28)
These two operations are the inverse of Equation (26) and restore the utility qbit  and the memory register m to their original values. After these operations on has
and the memory register m to their original values. After these operations on has
 (29)
(29)
With the last operation,
 (30)
(30)
one restores the third register m of the processing term, the second term in Equation (29) above, to its initial value . At this point one can load a new pattern into register p and go through the same routine as just described. At the end of the whole process, the m-register is exactly in state
. At this point one can load a new pattern into register p and go through the same routine as just described. At the end of the whole process, the m-register is exactly in state , Equation (23).
, Equation (23).
Any quantum state can be generically obtained by a unitary transformation of the initial state . This is true also for the memory state
. This is true also for the memory state . In the following we will explicitly construct the unitary memory operator M which implements the transformation
. In the following we will explicitly construct the unitary memory operator M which implements the transformation .
.
To this end we introduce first the single-qbit unitary gates
 (31)
(31)
where  is the second Pauli matrix. These operators are such that their product over the n qbits generates pattern
is the second Pauli matrix. These operators are such that their product over the n qbits generates pattern  out of
out of :
:
 (32)
(32)
We now introduce, in addition to the memory register proper, the same two utility qbits as before, also initially in the state . The idea is, exactly as in the sequential algorithm, to split the state into two parts, a storage term with
. The idea is, exactly as in the sequential algorithm, to split the state into two parts, a storage term with  and a pro- cessing term with
and a pro- cessing term with . Therefore we generalize the operators
. Therefore we generalize the operators  defined above to
defined above to
 (33)
(33)
which loads pattern  into the memory register only for the processing term. It is then easy to check that
into the memory register only for the processing term. It is then easy to check that
 (34)
(34)
From this construction it is easy to see that the memory operator M involves a number  of elementary one- and two-qbit gates. It is thus efficient for any number p of patterns polynomial in the number n of qubits. It is interesting to note that another version of this operator has been recently derived in [36] , with a bound of
of elementary one- and two-qbit gates. It is thus efficient for any number p of patterns polynomial in the number n of qubits. It is interesting to note that another version of this operator has been recently derived in [36] , with a bound of  on its complexity. This is also linear in p, implying again efficiency for a polynomial number of patterns.
on its complexity. This is also linear in p, implying again efficiency for a polynomial number of patterns.
While the memory construction we have presented here mirrors its classical counterpart, it is important to stress one notable difference. In classical associative memories, patterns are stored as minima of an energy landscape or, alternatively in the parameters of a dynamical evolution law [7] [8] . This is reflected verbatim in the construction of the unitary operator M in (34), which completely codes the patterns in a dynamical law, albeit reversible in the quantum case. In quantum mechanics, however, there is the possibility of shuffling some (but not all, as we will shortly see) information about the patterns from the unitary evolution law M onto a set of quantum states.
The ideal, most compressed quantum memory would indeed be the quantum superposition of patterns  in (23) itself. This, however is impossible. If the memory state has to be used for information retrieval it must be measured and this destroys all information about the patterns (save the one obtained in the measurement). The quantum state must therefore be copied prior to use and this is impossible since the linearity of quantum mechanics forbids exact universal cloning of quantum states [37] . Universal cloning of quantum states is possible only in an approximate sense [38] and has two disadvantages: first of all the copies are imperfect, though optimal [39] [40] and secondly, the quality of the master copy decreases with each additional copy made. Approximate universal cloning is thus excluded for the purposes of information recall since the memory would be quickly washed out.
in (23) itself. This, however is impossible. If the memory state has to be used for information retrieval it must be measured and this destroys all information about the patterns (save the one obtained in the measurement). The quantum state must therefore be copied prior to use and this is impossible since the linearity of quantum mechanics forbids exact universal cloning of quantum states [37] . Universal cloning of quantum states is possible only in an approximate sense [38] and has two disadvantages: first of all the copies are imperfect, though optimal [39] [40] and secondly, the quality of the master copy decreases with each additional copy made. Approximate universal cloning is thus excluded for the purposes of information recall since the memory would be quickly washed out.
This leaves state-dependent cloning [41] as the only viable option. State-dependent cloners are designed to reproduce only a finite number of states and this is definitely enough for our purposes. Actually the memory M in (34) is equivalent to a state- dependent cloner for the state  in (23). In this case the information about the stored patterns is completely coded in the memory operator, or equivalently, the state- dependent cloner. It is possible, however, to subdivide the pattern information among an operator and a set of quantum states, obviously including
in (23). In this case the information about the stored patterns is completely coded in the memory operator, or equivalently, the state- dependent cloner. It is possible, however, to subdivide the pattern information among an operator and a set of quantum states, obviously including , by using a probabilistic cloning machine [42] . Probabilistic cloners copy quantum states exactly but the copying process is not guaranteed to succeed and must be repeated until the measurement of an auxiliary register produces a given result associated with copying success. In general, any number of linearly independent states can be copied probabilistically. In the present case for example, it would be sufficient to consider any dummy state
, by using a probabilistic cloning machine [42] . Probabilistic cloners copy quantum states exactly but the copying process is not guaranteed to succeed and must be repeated until the measurement of an auxiliary register produces a given result associated with copying success. In general, any number of linearly independent states can be copied probabilistically. In the present case for example, it would be sufficient to consider any dummy state  different from
different from  (for more than two states the condition would be linear independence) and to construct a probabilistic cloning machine for these two states. This machine would reproduce
(for more than two states the condition would be linear independence) and to construct a probabilistic cloning machine for these two states. This machine would reproduce  with probability
with probability  and
and  with probability
with probability ; a flag would tell when the desired state
; a flag would tell when the desired state  has been obtained. In order to obtain an exact copy of
has been obtained. In order to obtain an exact copy of  one would need then
one would need then  trials on average. The master copy would be exactly preserved.
trials on average. The master copy would be exactly preserved.
The cloning efficiencies of the probabilistic cloner of two states are bounded as follows [42] :
 (35)
(35)
This bound can be made large by choosing  as nearly orthogonal to
as nearly orthogonal to  as possible. A simple way to achieve this for a large number of patterns would be, for example, to encode also the state
as possible. A simple way to achieve this for a large number of patterns would be, for example, to encode also the state
 (36)
(36)
together with  when storing information. This can be done easily by using alternately the operators
when storing information. This can be done easily by using alternately the operators  and
and  in the storing algorithm above. For binary patterns which are all different from one would then have
in the storing algorithm above. For binary patterns which are all different from one would then have
 (37)
(37)
and the bound for the cloning efficiencies would be very close to its maximal value 2 in both cases.
The quantum network for the probabilistic cloner of two states has been developed in [43] . It can be constructed exclusively out of the two simple distinguishability tranfer (D) and state separation (S) gates. As expected, these gates embody information about the two states to be cloned. Part of the memory, therefore, still resides in the cloning network. The pattern-dependence of the network cloner can be decreased by choosing a larger set of states in the pool that can be cloned, so that the cloner becomes more and more generic. On one side this decreases also the efficiency of the cloner, so that more repetitions are required, on the other side, since the clonable pool is limited to a set of linearly independent states, one can never eliminate completely the pattern-dependence of the cloning operator. This is why the original claim of an exponential capacity increase of quantum associative memories [16] [17] , based on probabilistic cloning of the state , is excessive. The complexity of the cloner, be it exact as in the memory operator M or probabilistic, remains linear in the number of patterns and the requirement of efficient implementability limits thus p to a polynomial function of the number n of qubits, which is still a large improvement upon classical associative memories.
, is excessive. The complexity of the cloner, be it exact as in the memory operator M or probabilistic, remains linear in the number of patterns and the requirement of efficient implementability limits thus p to a polynomial function of the number n of qubits, which is still a large improvement upon classical associative memories.
4.2. Retrieving Patterns
Let us now assume we are given a binary input i that is a corrupted version of one of the patterns stored in the memory. The task of the retrieval algorithm is to “recognize” it, i.e. output the stored pattern that most resembles this input, where similarity is defined (here) in terms of the Hamming distance, the number of different bits between the two patterns, although other similarity measures [7] could also be incorporated.
The retrieval algorithm requires also three registers. The first register i of n qbits contains the input pattern; the second register m, also of n qbits, contains the memory ; finally there is a control register c with b qbits all initialized in the state
; finally there is a control register c with b qbits all initialized in the state . The full initial quantum state is thus:
. The full initial quantum state is thus:
 (38)
(38)
where  denotes the input qbits, the second register, m, contains the memory (23) and all b control qbits are in state
denotes the input qbits, the second register, m, contains the memory (23) and all b control qbits are in state . Applying the Hadamard gate to the first control qbit one obtains
. Applying the Hadamard gate to the first control qbit one obtains
 (39)
(39)
Let us now apply to this state the following combination of quantum gates:
 (40)
(40)
As a result of the above operation the memory register qbits are in state  if
if  and
and  are identical and
are identical and  otherwise:
otherwise:
 (41)
(41)
where  if and only if
if and only if  and
and  otherwise.
otherwise.
Consider now the following Hamiltonian:
 (42)
(42)
where  is the third Pauli matrix.
is the third Pauli matrix.  measures the number of 0’s in register m, with a plus sign if c1 is in state
measures the number of 0’s in register m, with a plus sign if c1 is in state  and a minus sign if c1 is in state
and a minus sign if c1 is in state . Given how we have prepared the state
. Given how we have prepared the state , this is nothing else than the number of qbits which are different in the input and memory registers i and m. This quantity is called the Hamming distance and represents the (squared) Euclidean distance between two binary patterns.
, this is nothing else than the number of qbits which are different in the input and memory registers i and m. This quantity is called the Hamming distance and represents the (squared) Euclidean distance between two binary patterns.
Every term in the superposition (41) is an eigenstate of  with a different eigenvalue. Applying thus the unitary operator
with a different eigenvalue. Applying thus the unitary operator  to
to  one obtains
one obtains
 (43)
(43)
where  denotes the Hamming distance bewteen the input i and the stored pattern
denotes the Hamming distance bewteen the input i and the stored pattern .
.
In the final step we restore the memory gate to the state  by applying the inverse transformation to Equation (40) and we apply the Hadamard gate to the control qbit
by applying the inverse transformation to Equation (40) and we apply the Hadamard gate to the control qbit , thereby obtaining
, thereby obtaining
 (44)
(44)
The idea is now to repeat the above operations sequentially for all b control qbits  to
to . This gives
. This gives
 (45)
(45)
where  denotes the set of all binary numbers of b bits with exactly l bits 1 and
denotes the set of all binary numbers of b bits with exactly l bits 1 and  bits 0.
bits 0.
Note that one could also dispense with a register for the input but, rather, code also the input directly into a unitary operator. Indeed, the auxiliary quantum register for the input is needed only by the operator (40) leading from (39) to (41). The same result (apart from an irrelevant overall sign) can be obtained by applying
 (46)
(46)
directly on the memory state . The rest of the algorithm is the same, apart the reversing of the operator (40) which needs now the operator
. The rest of the algorithm is the same, apart the reversing of the operator (40) which needs now the operator .
.
The end effect of the information retrieval algorithm represents thus a rotation of the memory quantum state in the enlarged Hilbert space obtained by adding b control qbits. The overall effect of this rotation is an amplitude concentration on memory states similar to the input, if there is a large number of  control qbits in the output state and an amplitude concentration on states different from the input, if there is a large number of
control qbits in the output state and an amplitude concentration on states different from the input, if there is a large number of  control qbits in the output state. As a consequence, the most interesting state for information retrieval purposes is the projection of
control qbits in the output state. As a consequence, the most interesting state for information retrieval purposes is the projection of  onto the subspace with all control qbits in state
onto the subspace with all control qbits in state .
.
There are two ways of obtaining this projection. The first, and easiest one, is to simply repeat the above algorithm and measure the control register several times, until exactly the desired state for the control register is obtained. If the number of such repetitions exceeds a preset threshold T the input is classified as “non-recognized” and the algorithm is stopped. Otherwise, once  is obtained, one proceeds to a measurement of the memory register m, which yields the output pattern of the memory.
is obtained, one proceeds to a measurement of the memory register m, which yields the output pattern of the memory.
The second method is to first apply T steps of the amplitude amplification algorithm [44] rotating  towards its projection onto the “good” subspace formed by the states with all control qbits in state
towards its projection onto the “good” subspace formed by the states with all control qbits in state . To this end it is best to use the version of the retrieving algorithm that does not need an auxiliary register for the input. Let us define as
. To this end it is best to use the version of the retrieving algorithm that does not need an auxiliary register for the input. Let us define as  the input-dependent operator which rotates the memory state in the Hilbert space enlarged by the b control qbits towards the final state
the input-dependent operator which rotates the memory state in the Hilbert space enlarged by the b control qbits towards the final state  in Equation (45) (where we now omit the auxiliary register for the input):
in Equation (45) (where we now omit the auxiliary register for the input):
 (47)
(47)
By adding also the two utility qbits needed for the storing algorithm one can then obtain  as a unitary transformation of the initial state with all qbits in state
as a unitary transformation of the initial state with all qbits in state :
:
 (48)
(48)
The amplitude amplification rotation of  towards its “good” subspace in which all b control qbits are in state
towards its “good” subspace in which all b control qbits are in state  is then obtained [44] by repeated application of the operator
is then obtained [44] by repeated application of the operator
 (49)
(49)
on the state . Here S conditionally changes the sign of the amplitude of the “good” states with the b control qbits in state
. Here S conditionally changes the sign of the amplitude of the “good” states with the b control qbits in state , while
, while  changes the sign of the amplitude if and only if the state is the zero state
changes the sign of the amplitude if and only if the state is the zero state . As before, if a measurement of the control registers after the T iterations of the amplitude amplification rotation yields
. As before, if a measurement of the control registers after the T iterations of the amplitude amplification rotation yields  one proceeds to a measurement of the memory register, otherwise the input is classified as “non-recognized”.
one proceeds to a measurement of the memory register, otherwise the input is classified as “non-recognized”.
The expected number of repetitions needed to measure the desired control register state is , with
, with
 (50)
(50)
the probability of measuring . The threshold T governs thus the recognition efficiency of the memory. Note, however, that amplitude amplification provides a quadratic boost [44] to the recognition efficiency since only
. The threshold T governs thus the recognition efficiency of the memory. Note, however, that amplitude amplification provides a quadratic boost [44] to the recognition efficiency since only  steps are typically required to rotate
steps are typically required to rotate  onto the desired subspace. Accordingly, the threshold T can be lowered to
onto the desired subspace. Accordingly, the threshold T can be lowered to  with respect to the method of projection by measurement. The crucial point is that, due to the quantum nature of the retrieval mechanism, this recognition probability depends on the distribution of all stored patterns. A lower bound on the recognition probability can thus be established as follows. Of all the stored patterns, all but one have Hamming distance from the input smaller or equal than
with respect to the method of projection by measurement. The crucial point is that, due to the quantum nature of the retrieval mechanism, this recognition probability depends on the distribution of all stored patterns. A lower bound on the recognition probability can thus be established as follows. Of all the stored patterns, all but one have Hamming distance from the input smaller or equal than . There is only pattern that can have a larger Hamming distance equal to n. So we shall use the upper bound
. There is only pattern that can have a larger Hamming distance equal to n. So we shall use the upper bound  for the Hamming distance of all patterns but one, for which we shall use the upper bound n, and this one does not contribute to the recognition probability since the cosine function vanishes. Given that cosine is a decreasing function in the interval
for the Hamming distance of all patterns but one, for which we shall use the upper bound n, and this one does not contribute to the recognition probability since the cosine function vanishes. Given that cosine is a decreasing function in the interval , we get the lower bound
, we get the lower bound
 (51)
(51)
For  we can now estimate this lower bound as
we can now estimate this lower bound as
 (52)
(52)
This shows that, independent of the number p of patterns, the threshold T for recognition can be set as a polynomial function of the number n of qubits. Note that this is entirely due to the factor  in the numerator of (52), which, in turn, depends on the quantum nature of the memory. In other words, the probabilistic character of the retrieval process does not limit at all the number of possible stored patterns. The typical number of repetitions required would be polynomial even for an exponential number or patterns. The efficient implementability of the quantum memory is limited only by the number of elementary quantum gates in M, which is linear in p.
in the numerator of (52), which, in turn, depends on the quantum nature of the memory. In other words, the probabilistic character of the retrieval process does not limit at all the number of possible stored patterns. The typical number of repetitions required would be polynomial even for an exponential number or patterns. The efficient implementability of the quantum memory is limited only by the number of elementary quantum gates in M, which is linear in p.
In general, the probability of recognition is determined by comparing (even) powers of cosines and sines of the distances to the stored patterns. It is thus clear that the worst case for recognition is the situation in which there is an isolated pattern, with the remaining patterns forming a tight cluster spanning all the largest distances to the first one. As a consequence, the threshold needed to recognize all patterns diminishes when the number of stored patterns becomes very large, since, in this case, the distribution of patterns becomes necessarily more homogeneous. Indeed, for the maximal number of stored patterns  one has
one has  and the recognition efficiency becomes also maximal, as it should be.
and the recognition efficiency becomes also maximal, as it should be.
Once the input pattern i is recognized, the measurement of the memory register yields the stored pattern  with probability
with probability
 (53)
(53)
 (54)
(54)
Clearly, this probability is peaked around those patterns which have the smallest Hamming distance to the input. The highest probability of retrieval is thus realized for that pattern which is most similar to the input. This is always true, independently of the number of stored patterns. In particular, contrary to classical associative memories, there are no spurious memories: the probability of obtaining as output a non-stored pattern is always zero. This is another manifestation of the fact that there are no restrictions on the loading factor p/n due to the information retrieval algorithm.
In addition to the threshold T, there is a second tunable parameter, namely the number b of control qbits. This new parameter b controls the identification efficiency of the quantum memory since, increasing b, the probability distribution  becomes more and more peaked on the low
becomes more and more peaked on the low  states, until
states, until
 (55)
(55)
where  is the index of the pattern (assumed unique for convenience) with the smallest Hamming distance to the input.
is the index of the pattern (assumed unique for convenience) with the smallest Hamming distance to the input.
While the recognition efficiency depends on comparing powers of cosines and sines of the same distances in the distribution, the identification efficiency depends on comparing the (even) powers of cosines of the different distances in the distribution. Specifically, it is best when one of the distances is zero, while all others are as large as possible, such that the probability of retrieval is completely peaked on one pattern. As a consequence, the identification efficiency is best when the recognition efficiency is worst and vice versa.
The role of the parameter b becomes familiar upon a closer examination of Equation (53). Indeed, the quantum distribution described by this equation is equivalent to a canonical Boltzmann distribution with (dimensionless) temperature  and (dimensionless) energy levels
and (dimensionless) energy levels
 (56)
(56)
with Z playing the role of the partition function.
The appearance of an effective thermal distribution suggests studying the average behaviour of quantum associative memories via the corresponding thermodynamic potentials. Before this can be done, however, one must deal with the different distributions of stored patterns characterizing each individual memory. The standard way to do this in similar classical problems is to average over the random distribution of patterns. Typically, one considers quenched averages in which extensive quantities, like the free energy are averaged over the disorder: this is the famed replica trick used to analyze spin glasses [13] . In the present case, however, the disorder cannot lead to spin-glass- like phases since there are no spurious memories: by construction, probabilistic quantum memories can output only one of the stored patterns. The only question is how accurate is the retrieval of the most similar pattern to the input as a function of the fictitious temperature . To address this question we will “quench” only one aspect of the random pattern distribution, namely the minimal Hamming distance d between the input and the stored patterns. The rest of the random pattern distribution will be considered as annealed. In doing so, one obtains an average description of the average memory as a function of the fictitious temperature
. To address this question we will “quench” only one aspect of the random pattern distribution, namely the minimal Hamming distance d between the input and the stored patterns. The rest of the random pattern distribution will be considered as annealed. In doing so, one obtains an average description of the average memory as a function of the fictitious temperature  and the minimal Hamming distance d.
and the minimal Hamming distance d.
To do so we first normalize the pattern representation by adding (modulo 2) to all patterns, input included, the input pattern i. This clearly preserves all Hamming distances and has the effect of choosing the input as the state with all qbits in state . The Hamming distance
. The Hamming distance  becomes thus simply the number of qbits in pattern
becomes thus simply the number of qbits in pattern  with value
with value . The averaged partition function takes then a particularly simple form:
. The averaged partition function takes then a particularly simple form:
 (57)
(57)
where  describes a probability distribution,
describes a probability distribution,  , with the following properties. Let the number of patterns scale as the xth power of the number of qubits,
, with the following properties. Let the number of patterns scale as the xth power of the number of qubits,  for
for . Then
. Then
 (58)
(58)
with all other  for
for  unconstrained.
unconstrained.  is the set of such distributions and
is the set of such distributions and  the corresponding normalization factor. Essentially the probability distribution becomes unconstrained in the limit of large n.
the corresponding normalization factor. Essentially the probability distribution becomes unconstrained in the limit of large n.
We now introduce the free energy  by the usual definition
by the usual definition
 (59)
(59)
where we have chosen a normalization such that  describes the deviation of the partition function from its value for b = 0 (high effective temperature). Since
describes the deviation of the partition function from its value for b = 0 (high effective temperature). Since , and consequently also
, and consequently also  posses a finite, non-vanishing large-n limit, this normalization ensures that
posses a finite, non-vanishing large-n limit, this normalization ensures that  is intensive, exactly like the energy levels (56), and scales as a constant for large n. This is the only difference with respect to the familiar situation in statistical mechanics.
is intensive, exactly like the energy levels (56), and scales as a constant for large n. This is the only difference with respect to the familiar situation in statistical mechanics.
The free energy describes the equilibrium of the system at effective temperature  and has the usual expression in terms of the internal energy U and the entropy S:
and has the usual expression in terms of the internal energy U and the entropy S:
 (60)
(60)
Note that, with the normalization we have chosen in (59), the entropy S is always a negative quantity describing the deviation from its maximal value  at
at .
.
By inverting Equation (56) with F substituting E one can also define an effective (relative) input/output Hamming distance  at temperature t:
at temperature t:
 (61)
(61)
This corresponds exactly to representing the recognition probability of the average memory as
 (62)
(62)
which can also be taken as the primary definition of the effective Hamming distance.
The function  provides a complete description of the behaviour of the average probabilistic quantum associative memory with a minimal distance Hamming distance d. This can be used to tune its performance. Indeed, suppose that one wants the memory to recognize and identify inputs with up to
provides a complete description of the behaviour of the average probabilistic quantum associative memory with a minimal distance Hamming distance d. This can be used to tune its performance. Indeed, suppose that one wants the memory to recognize and identify inputs with up to  corrupted inputs with an efficiency of
corrupted inputs with an efficiency of 
 . Then one must choose a number b of control qbits sufficiently large that
. Then one must choose a number b of control qbits sufficiently large that  and a threshold T of repetitions satisfying
and a threshold T of repetitions satisfying
 , as illustrated in Figure 2.
, as illustrated in Figure 2.
A first hint about the general behaviour of the effective distance function  can be obtained by examining closer the energy eigenvalues (56). For small Hamming distance to the input these reduce to
can be obtained by examining closer the energy eigenvalues (56). For small Hamming distance to the input these reduce to
 (63)
(63)
Choosing again the normalization in which  and introducing a “spin”
and introducing a “spin”  with value
with value  if qbit i in pattern
if qbit i in pattern  has value
has value  and
and  if qbit i in pattern
if qbit i in pattern  has value
has value , one can express the energy levels for
, one can express the energy levels for  as
as
 (64)
(64)

Figure 2. Effective input/output distance and entropy (rescaled to [0, 1]) for 1 Mb patterns and .
.
Apart from a constant, this is the Hamiltonian of an infinite-range antiferromagnetic Ising model in presence of a magnetic field. The antiferromagnetic term favours configurations k with half the spins up and half down, so that , giving
, giving . The magnetic field, however, tends to align the spins so that
. The magnetic field, however, tends to align the spins so that , giving
, giving . Since this is lower than
. Since this is lower than , the ground state configuration is ferromagnetic, with all qbits having value
, the ground state configuration is ferromagnetic, with all qbits having value . At very low temperature (high b), where the energy term dominates the free energy, one expects thus an ordered phase of the quantum associative memory with
. At very low temperature (high b), where the energy term dominates the free energy, one expects thus an ordered phase of the quantum associative memory with . This corresponds to a perfect identification of the presented input. As the temperature is raised (b decreased) however, the thermal energy embodied by the entropy term in the free energy begins to counteract the magnetic field. At very high temperatures (low b) the entropy approaches its maximal value
. This corresponds to a perfect identification of the presented input. As the temperature is raised (b decreased) however, the thermal energy embodied by the entropy term in the free energy begins to counteract the magnetic field. At very high temperatures (low b) the entropy approaches its maximal value  (with the normalization chosen here). If this value is approached faster than 1/t, the free energy will again be dominated by the internal energy. In this case, however, this is not any more determined by the ground state but rather equally distributed on all possible states, giving
(with the normalization chosen here). If this value is approached faster than 1/t, the free energy will again be dominated by the internal energy. In this case, however, this is not any more determined by the ground state but rather equally distributed on all possible states, giving
 (65)
(65)
and leading to an effective distance
 (66)
(66)
This value corresponds to a disordered phase with no correlation between input and output of the memory.
A numerical study of the thermodynamic potentials in (60) and (61) indeed confirms a phase transition from the ordered to the disordered phase as the effective temperature is raised. In Figure 2 we show the effective distance  and the entropy S for 1 Mb (
and the entropy S for 1 Mb ( ) patterns and
) patterns and  as a function of the inverse temperature b (the entropy is rescaled to the interval [0, 1] for ease of presentation). At high temperature there is indeed a disordered phase with
as a function of the inverse temperature b (the entropy is rescaled to the interval [0, 1] for ease of presentation). At high temperature there is indeed a disordered phase with  and
and . At low temperatures, instead, one is in the ordered phase with
. At low temperatures, instead, one is in the ordered phase with  and
and . The effective Hamming distance plays thus the role of the order parameter for this quantum phase transition.
. The effective Hamming distance plays thus the role of the order parameter for this quantum phase transition.
The phase transition occurs around . The physical regime of the quantum associative memory (b = positive integer) lies thus just above this transition. For a good accuracy of pattern recognition one should choose a fictitious temperature low enough to be well into the ordered phase. As is clear from Figure 2, this can be achieved already with a number of control qubits
. The physical regime of the quantum associative memory (b = positive integer) lies thus just above this transition. For a good accuracy of pattern recognition one should choose a fictitious temperature low enough to be well into the ordered phase. As is clear from Figure 2, this can be achieved already with a number of control qubits .
.
Having described at length the information retrieval mechanism for complete, but possibly corrupted patterns, it is easy to incorporate also incomplete ones. To this end assume that only  qbits of the input are known and let us denote these by the indices
qbits of the input are known and let us denote these by the indices . After assigning the remaining qbits randomly, there are two possibilities. One can just treat the resulting complete input as a noisy one and proceed as above or, better, one can limit the operator
. After assigning the remaining qbits randomly, there are two possibilities. One can just treat the resulting complete input as a noisy one and proceed as above or, better, one can limit the operator  in the Hamiltonian (42) to
in the Hamiltonian (42) to
 (67)
(67)
so that the Hamming distances to the stored patterns are computed on the basis of the known qbits only. After this, the pattern recall process continues exactly as described above. This second possibility has the advantage that it does not introduce random noise in the similarity measure but it has the disadvantage that the operations of the memory have to be adjusted to the inputs.
Finally, it is fair to mention that the model of probabilistic quantum associative memory presented here has been criticised [45] on three accounts:
・ It has been claimed that the same result could have been obtained by storing only one of the p patterns in n classical bits and always using this single pattern as the same output independently of the input, provided the input has a Hamming distance to the unique stored pattern lower than a given threshold, otherwise the input would not be recognized.
・ It has been claimed that the Holevo theorem bounds the number of patterns that can be stored in a quantum associative memory.
・ It has been pointed out that the complexity of memory preparation prevents the efficient storing of patterns.
This criticism is wrong on the first two accounts and partially justified on the third [46] . It is true that both the quantum memory and the proposed equivalent classical prescription are based on probabilistic recognition and identification processes. In the proposed classical alternative, however the probabilities for both recognition and identification depend on one unique, fixed and random pattern whereas in the quantum memory, exactly due to its quantum character, these probabilities depend on the distribution of all stored patterns. These probabilities are such that an input different from most stored patterns is more difficult to recognize than an input similar to many stored memories and that the identification probability distribution can be peaked with any prescribed accuracy on the stored pattern most similar to the input. In the proposed classical alternative, given that only one single pattern can be stored on the n classical bits, the recognition or lack thereof depends on the distance to a randomly chosen pattern and the identification probability is a delta function peaked on this fixed random pattern. In other words there is no correlation whatsoever between input and output apart from the fact that they have Hamming distance below a certain threshold, a prescription that can hardly qualify as an associative memory: it would indeed be a boring world the one in which every stimulus would produce exactly the same response, if any response at all. Also, the Holevo theorem [34] does not impose any limitation on this type of probabilistic quantum memories. The Holevo theorem applies to the situation in which Alice codes information about a classical random variable in a quantum state and Bob tries to retrieve the value of this random variable by measurements on the received quantum state. In the present case Alice gives to Bob also corrupted or incomplete classical information about the random variable (the input) and Bob can use also a unitary transformation that encodes both the memories and the input (operator  in (47)) in addition to measurements, a completely different situation. Contrary to what the authors of [45] affirm, a memory that “knows the patterns it is supposed to retrieve” not only makes sense but it is actually the very definition of an associative memory: if the memory would not “know” the data it has to retrieve it would just be a random access database, exactly the architecture that one wants to improve by content association, the mechanism whose goal is to recognize and correct corrupted or incomplete inputs. The dynamics of the classical Hopfield model “knows” the patterns it is supposed to retrieve: they are encoded in the neuronal weights. So does any human brain. Finally, the third critique is partially correct. The complexity of the memory operator M is
in (47)) in addition to measurements, a completely different situation. Contrary to what the authors of [45] affirm, a memory that “knows the patterns it is supposed to retrieve” not only makes sense but it is actually the very definition of an associative memory: if the memory would not “know” the data it has to retrieve it would just be a random access database, exactly the architecture that one wants to improve by content association, the mechanism whose goal is to recognize and correct corrupted or incomplete inputs. The dynamics of the classical Hopfield model “knows” the patterns it is supposed to retrieve: they are encoded in the neuronal weights. So does any human brain. Finally, the third critique is partially correct. The complexity of the memory operator M is  and thus the original claim [16] [17] of an exponential capacity gain by quantum associative memories is excessive. This, however, does not invalidate the main claim, a large gain in capacity is made possible by quantum mechanics, albeit only a polynomial one. This correction has been incorporated in the present review.
and thus the original claim [16] [17] of an exponential capacity gain by quantum associative memories is excessive. This, however, does not invalidate the main claim, a large gain in capacity is made possible by quantum mechanics, albeit only a polynomial one. This correction has been incorporated in the present review.
4.3. Efficiency, Complexity and Memory Tuning
In this last section we would like to address the efficient implementation of probabilistic quantum memories in the quantum circuit model [4] [5] and their accuracy tuning.
We have stressed several times that all unitary operators involved in the memory preparation can be realized as a sequence of one- and two-qubit operators. It remains to prove that this is true also for pattern retrieval and that all these operators can be implemented in terms of a small set of universal gates. To this end we would like to point out that, in addition to the standard NOT, H (Hadamard), XOR, 2XOR (Toffoli) and nXOR gates [4] [5] we have introduced only the two-qbit gates  in Equation (22) and the unitary operator
in Equation (22) and the unitary operator . The latter can, however also be realized by simple gates involving only one or two qbits. To this end we introduce the single-qbit gate
. The latter can, however also be realized by simple gates involving only one or two qbits. To this end we introduce the single-qbit gate
 (68)
(68)
and the two-qbit controlled gate
 (69)
(69)
It is then easy to check that  in Equation (41) can be realized as follows:
in Equation (41) can be realized as follows:
 (70)
(70)
where c is the control qbit for which one is currently repeating the algorithm. Essentially, this means that one implements first  and then one corrects by implementing
and then one corrects by implementing  on that part of the quantum state for which the control qbit
on that part of the quantum state for which the control qbit  is in state
is in state .
.
Using this representation for the Hamming distance operator one can count the total number of simple gates that one must apply in order to implement one step of the information retrieval algorithm. This is given by  using the auxiliary register for the input and by
using the auxiliary register for the input and by  otherwise. This retrieval step has then to be repeated for each of the b control qbits. Therefore, implementing the projection by repeated measurements, the overall complexity C of information retrieval is bounded by
otherwise. This retrieval step has then to be repeated for each of the b control qbits. Therefore, implementing the projection by repeated measurements, the overall complexity C of information retrieval is bounded by
 (71)
(71)
where  is the complexity of the memory preparation, given by the operator M or a probabilistic cloning machine. In particular, it is given by
is the complexity of the memory preparation, given by the operator M or a probabilistic cloning machine. In particular, it is given by
 (72)
(72)
for the simplest version of the algorithm, using memory preparation by M and an auxiliary input register.
The computation of the overall complexity is easier for the information retrieval algorithm which uses the amplitude amplification technique. In this case the initial memory is prepared only once by a product of the operators M, with complexity  and
and , with complexity
, with complexity . Then one applies T times the operator Q, with complexity
. Then one applies T times the operator Q, with complexity , where
, where  and
and  are the polynomial complexities of the oracles implementing S and
are the polynomial complexities of the oracles implementing S and . This gives
. This gives
 (73)
(73)
As expected, the memory complexity (be it (72) or (73)) depends on both T and b, the parameters governing the recognition and identification efficiencies. The major limitation comes from the factor p representing the total number of stored patterns. Note however that, contrary to classical associative memories, one can efficiently store and retrieve any polynomial number of patterns due to the absence of spurious memories and crosstalk.
Let us finally show how one can tune the accuracy of the quantum memory. Suppose one would like to recognize on average inputs with up to 1% of corrupted or missing bits and identify them with high accuracy. The effective i/o Hamming distance  shown in Figure 2 can then be used to determine the values of the required parameters T and b needed to reach this accuracy for the average memory. For
shown in Figure 2 can then be used to determine the values of the required parameters T and b needed to reach this accuracy for the average memory. For  e.g., one has
e.g., one has , which gives the average i/o distance (in percent of total qbits) if the minimum possible i/o distance is 0.01. For this value of b the recognition probability is 3.4 ´ 10−4. With the measurement repetition technique one should thus set the threshold
, which gives the average i/o distance (in percent of total qbits) if the minimum possible i/o distance is 0.01. For this value of b the recognition probability is 3.4 ´ 10−4. With the measurement repetition technique one should thus set the threshold . Using amplitude amplification, however, one needs only around
. Using amplitude amplification, however, one needs only around  repetitions. Note that the values of b and T obtained by tuning the memory with the effective i/o Hamming distance become n-independent for large values of n. This is because they are intensive variables unaffected by this “thermodynamic limit”. For any fixed p polynomial in n, the information retrieval can then be implemented efficiently and the overall complexity is determined by the accuracy requirements via the n-independent parameters T and b.
repetitions. Note that the values of b and T obtained by tuning the memory with the effective i/o Hamming distance become n-independent for large values of n. This is because they are intensive variables unaffected by this “thermodynamic limit”. For any fixed p polynomial in n, the information retrieval can then be implemented efficiently and the overall complexity is determined by the accuracy requirements via the n-independent parameters T and b.
5. Conclusions
We would like to conclude this review by highlighting the fundamental reason why a probabilistic quantum associative memory works better than its classical counterpart and pointing out about some very intuitive features of the information retrieval process.
In classical associative memories, the information about the patterns to recall is typically stored in an energy function. When retrieving information, the input configuration evolves to the corresponding output, driven by the dynamics associated with the memory function. The capacity shortage is due to a phase transition in the statistical ensemble governed by the memory energy function. Spurious memories, i.e. spurious metastable minima not associated with any of the original patterns become important for loading factors p/n above a critical value and wash out completely the memory, a phenomenon that goes by the name of crosstalk. So, in the low p/n phase the memory works perfectly in the sense that it outputs always the stored pattern which is most similar to the input. For p/n above the critical value, instead, there is an abrupt transition to total amnesia caused by spurious memories.
Probabilistic quantum associative memories work better than classical ones since they are free from spurious memories. The easiest way to see this is in the formulation
 (74)
(74)
All the information about the stored patterns is encoded in the unitary operator M. This generates a quantum state in which all components that do not correspond to stored patterns have exactly vanishing amplitudes.
An analogy with the classical Hopfield model [7] [8] can be established as follows. Instead of generating the memory state  from the initial zero state
from the initial zero state , one can start from a uniform superposition of the computational basis. This is achieved by the operator MW defined by
, one can start from a uniform superposition of the computational basis. This is achieved by the operator MW defined by
 (75)
(75)
Now, this same result can also be obtained by Grover’s algorithm, or better by its generalization with zero failure rate [47] . Here the state  is obtained by applying to the uniform superposition of the computational basis q times the search operator X defined in
is obtained by applying to the uniform superposition of the computational basis q times the search operator X defined in
 (76)
(76)
where J rotates the amplitudes of the states corresponding to the patterns to be stored by a phase  which is very close to p (the original Grover value) for large n and
which is very close to p (the original Grover value) for large n and  does the same on the zero state. Via the two equations (75) and (76), the memory operator M provides an implicit realization of the phase shift operator J. Being a unitary operator, this can always be written as an exponential of an hermitian Hamiltonian
does the same on the zero state. Via the two equations (75) and (76), the memory operator M provides an implicit realization of the phase shift operator J. Being a unitary operator, this can always be written as an exponential of an hermitian Hamiltonian , which is the quantum generalization of a classical energy function. By defining
, which is the quantum generalization of a classical energy function. By defining  one obtains an energy operator which is diagonal in the computa- tional basis and such that the patterns to be stored have energy eigenvalues
one obtains an energy operator which is diagonal in the computa- tional basis and such that the patterns to be stored have energy eigenvalues  while all others have energy eigenvalues
while all others have energy eigenvalues . This formulation is the exact quantum generalization of the Hopfield model; the important point is that the operator M realizes efficiently a dynamics in which the patterns to be stored are always, for any number p of patterns, the exact global minima of a quantum energy landscape, without the ap- pearance of any spurious memories.
. This formulation is the exact quantum generalization of the Hopfield model; the important point is that the operator M realizes efficiently a dynamics in which the patterns to be stored are always, for any number p of patterns, the exact global minima of a quantum energy landscape, without the ap- pearance of any spurious memories.
The price to pay is the probabilistic nature of the information retrieval mechanism. As always in quantum mechanics, the dynamics determines only the evolution of probability distributions and the probabilistic aspect is brought in by the collapse of this probability distributions upon measurement. Therefore, contrary to the classical Hopfield model in the low p/n phase, one does not always have the absolute guarantee that an input is recognized and identified correctly as the stored pattern most similar to the input, even if this state has the highest probability of being measured. But, after all, this is a familiar feature of the most concrete example of associative memory, our own brain, and should thus not be so disturbing. Indeed, it is not only the probabilistic nature of information retrieval that is reminiscent of the behaviour of the human brain but also the properties of the involved probability distributions. These are such that inputs very similar to a cluster of stored patterns will be much easier to recognize than i.
Cite this paper
Diamantini M.C. and Trugenberger, C.A. (2016) High- Capacity Quantum Associative Memories. Journal of Applied Mathematics and Physics, 4, 2079-2112. http://dx.doi.org/10.4236/jamp.2016.411207
References
- 1. Hawkins, J. (with Blakeslee, S.) (2004) On Intelligence. Times Books.
- 2. Kurzweil, R. (2012) How to Create a Mind. Penguins Books, London.
- 3. Bishop, C.M. (2006) Pattern Recognition and Machine Learning. Springer Verlag, Singapore.
- 4. Nielsen, M.A. and Chuang, I.L. (2000) Quantum Computation and Quantum Information. Cambridge University Press, Cambridge.
- 5. Pittenger, A.O. (2000) An Introduction to Quantum Computing Algorithms. Birkhäuser, Boston.
- 6. Davis, M. (2000) Engines of Logic: Mathematicians and the Origin of the Computer. W. W. Norton Company, New York.
- 7. Müller, B. and Reinhardt, J. (1990) Neural Networks. Springer-Verlag, Berlin.
- 8. Kohonen, T. (1984) Self-Organization and Associative Memmory. Springer-Verlag, Berlin.
- 9. Rabiner, L.R. (1989) A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77, 257-286.
https://doi.org/10.1109/5.18626 - 10. Hopfield, J.J. (1982) Neural Networks and Physical Systems with Emergent Collective Computational Abilities. Proceedings of the National Academy of Sciences of the United States of America, 79, 2554-2558.
https://doi.org/10.1073/pnas.79.8.2554 - 11. Kosko, B. (1988) Bidirectional Associative Memories. IEEE Transactions on Systems, Man, and Cybernetics, 18, 49-60.
https://doi.org/10.1109/21.87054 - 12. Nishimori, H. (2001) Statistical Physics of Spin Glasses and Information Processing. Oxford University Press, Oxford.
https://doi.org/10.1093/acprof:oso/9780198509417.001.0001 - 13. Mezard, M., Parisi, G. and Virasoro, M.A. (1987) Spin Glass Theory and Beyond. World Scientific, Singapore City.
- 14. Shor, P.W. (1997) Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM Journal of Computing, 26, 1484-1509.
- 15. Grover, L. (1997) Quantum Mechanics Helps in Searching for a Needle in a Haystack. Physical Review Letters, 79, 325.
https://doi.org/10.1103/PhysRevLett.79.325 - 16. Trugenberger, C.A. (2001) Probabilistic Quantum Memories. Physical Review Letters, 87, 067901.
https://doi.org/10.1103/PhysRevLett.87.067901 - 17. Ball, P. (2001) Brain Inspires New Memories. Nature News, August 6.
- 18. Trugenberger, C.A. (2002) Phase Transitions in Quantum Pattern Recognition. Physical Review Letters, 89, 277903.
https://doi.org/10.1103/PhysRevLett.89.277903 - 19. Trugenberger, C.A. (2002) Quantum Pattern Recognition. Quantum Information Processing, 1, 471.
https://doi.org/10.1023/A:1024022632303 - 20. Sasaki, M., Carlini, A. and Jozsa, R. (2001) Quantum Template Matching. Physical Review A, 64, 022317.
https://doi.org/10.1103/PhysRevA.64.022317 - 21. Sasaki, M and Carlini, A. (2003) Quantum Learning and Universal Quantum Matching Machine. Physical Review A, 66, 022303.
https://doi.org/10.1103/PhysRevA.66.022303 - 22. Schützhold, R. (2003) Pattern Recognition on a Quantum Computer. Physical Review A, 67, 062311.
https://doi.org/10.1103/PhysRevA.67.062311 - 23. Cristina Diamantini, M. and Trugenberger, C.A. (2006) Quantum Pattern Retrieval by Qubit Networks with Hebb Interactions. Physical Review Letters, 97, 130503.
https://doi.org/10.1103/PhysRevLett.97.130503 - 24. Sourlas, N. (1989) Spin-Glass Models as Error-Correcting Codes. Nature, 339, 693-695.
https://doi.org/10.1038/339693a0 - 25. Kanter, I. and Saad, D. (1999) Error-Correcting Codes That Nearly Saturate Shannon’s Bound. Physical Review Letters, 83, 2660.
https://doi.org/10.1103/PhysRevLett.83.2660 - 26. Kabashima, Y., Murayama, T. and Saad, D. (2000) Typical Performance of Gallager-Type Error-Correcting Codes. Physical Review Letters, 84, 1355.
https://doi.org/10.1103/PhysRevLett.84.1355 - 27. Kabashima, Y., Murayama, T. and Saad, D. (2000) Cryptographical Properties of Ising Spin Systems. Physical Review Letters, 84 2030.
https://doi.org/10.1103/PhysRevLett.84.2030 - 28. McCullogh, W.S. and Pitts, W. (1943) A Logical Calculus of the Ideas Immanent in Nervous Activity. The bulletin of Mathematical Biophysics, 5, 115-133.
https://doi.org/10.1007/BF02478259 - 29. Mandel, O., Greiner, M., Widera, A., Rom, T., Hänsch, T.W. and Bloch, I. (2003) Controlled Collisions for Multi-Particle Entanglement of Optically Trapped Atoms. Nature, 425, 937-940.
https://doi.org/10.1038/nature02008 - 30. Kane, B.E. (2003) A Silicon-Based Nuclear Spin Quantum Computer. Nature, 393, 133-137.
https://doi.org/10.1038/30156 - 31. Parisi, G. (1988) Statistical Field Theory. Addison-Wesley, Redwood City.
- 32. Sachdev, S. (1999) Quantum Phase Transitions. Cambridge University Press, Cambridge.
- 33. Barenco, A., Bennet, C., Cleve, R., DiVincenzo, D., Margolus, N., Shor, P., Sleator, T., Smolin, J. and Weinfurter, H. (1995) Elementary Gates for Quantum Computation. Physical Review A, 52, 3457.
https://doi.org/10.1103/PhysRevA.52.3457 - 34. Holevo, A.S. (1973) Bounds for the Quantity of Information Transmitted by a Quantum Communication Channel. Problems of Information Transmission, 9, 177-183.
- 35. Ventura, D. and Martinez, T. (1999) Initializing the Amplitude Distribution of a Quantum State. Foundations of Physics Letters, 12, 547-559.
https://doi.org/10.1023/A:1021695125245 - 36. Tanaka, Y., Ichikawa, T., Tada-Umezaki, M., Ota, Y. and Nakahara, M. (2011) Quantum Oracles in Terms of Universal Gate Set. International Journal of Quantum Information, 9, 1363-1381.
https://doi.org/10.1142/S0219749911008106 - 37. Wootters, W. and Zurek, W. (1982) A Single Quantum Cannot Be Cloned. Nature, 299, 802-803.
https://doi.org/10.1038/299802a0 - 38. Buzek, V. and Hillery, M. (1996) Quantum Copying: Beyond the No-Cloning Theorem. Physical Review A, 54, 1844.
https://doi.org/10.1103/PhysRevA.54.1844 - 39. Gisin, N. and Massar, S. (1997) Optimal Quantum Cloning Machines. Physical Review Letters, 79, 2153.
https://doi.org/10.1103/PhysRevLett.79.2153 - 40. Bruss, D., Ekert, A.K. and Macchiavello, C. (1998) Optimal Universal Quantum Cloning and State Estimation. Physical Review Letters, 81, 2598.
https://doi.org/10.1103/PhysRevLett.81.2598 - 41. Bruss, D., DiVincenzo, D.P., Ekert, A., Fuchs, C.A., Macchiavello, C. and Smolin, J.A. (1998) Optimal Universal and State-Dependent Quantum Cloning. Physical Review A, 57, 2368.
https://doi.org/10.1103/PhysRevA.57.2368 - 42. Duan, L.-M. and Guo, G.-C. (1998) Probabilistic Cloning and Identification of Linearly Independent Quantum States. Physical Review Letters, 80, 4999.
https://doi.org/10.1103/PhysRevLett.80.4999 - 43. Chefles, A. and Barnett, S. M. (1999) Strategies and Networks for State-Dependent Quantum Cloning. Physical Review A, 60, 136.
https://doi.org/10.1103/PhysRevA.60.136 - 44. Brassard, G., Hoyer, P., Mosca, M. and Tapp, A. Amplitude Amplification and Estimation, quant-ph/0005055.
- 45. Brun, T., Klauck, H., Nayak, A., Roetteler, M. and Zalka, Ch. (2003) Comment on “Probabilistic Quantum Memories”. Physical Review Letters, 91, 209801.
https://doi.org/10.1103/PhysRevLett.91.209801 - 46. Trugenberger, C.A. (2003) Trugenberger Replies. Physical Review Letters, 91, 209802.
https://doi.org/10.1103/PhysRevLett.91.209802 - 47. Long, G.L. (2001) Grover Algorithm with Zero Theoretical Failure Rate. Physical Review A, 64, 022307.
https://doi.org/10.1103/physreva.64.022307