Theoretical Economics Letters
Vol.05 No.03(2015), Article ID:57523,9 pages
10.4236/tel.2015.53050
Testing the Long-Memory Features in Return and Volatility of NSE Index
Naseem Ahamed1, Mamoni Kalita2, Aviral Kumar Tiwari1
1IBS Hyderabad, IFHE, Hyderabad, India
2ICFAI University, Agartala, India
Email: naseemahamed@ibsindia.org
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 21 May 2015; accepted 26 June 2015; published 29 June 2015
ABSTRACT
Long-term memory of stock markets is a topic that has not received its due attention from academics. Posting the assertion made by Fama, 1970 [1] about markets being efficient, no one can consistently outrun it for a longer duration. Handful of papers checked the efficiency in emerging markets to see if the efficiency proposition held true. Furthering the literature in this study we test for the long-term memory of National Stock Exchange (NSE) index, Nifty and NSE_500 which are a collection of 50 and 500 listed firms respectively in India. The duration of the data for study is roughly eight years over the period from 2006-06-29 to 2012-09-13, a total of 1545 observations. We observe that long-term memory does exist in the context of Indian stock market index.
Keywords:
NSE Index, Volatility, Long-Memory, Stock Market

1. Introduction
The Efficient Market Hypothesis proposed and professed by Fama (1970) would have markets that utilize full information and reflect in the stock prices without any participant standing a chance to outperform it. But that kind of market is an ideal one and does not exist in real world making long memory one of the important features of any market. It is the property of markets returning to the mean value of index over a significantly long period of time. Since the markets have a tendency to move towards the mean, participants who are endowed with quality information can outperform against the efficient market hypothesis condition. Markets react to news that is observable and well established, but the point of difference is the extent of reaction to any news. A market absorbs all the information and reflects that in the index or if it does not, some market participants are left at an advantage. Presence of long-term memory makes it advantageous for some market participants to outperform the market and make speculative profit at the expense of others. All of these happen because of the lack of complete arbitrage of market information. Long-term memory hence intuitively is a characteristic of less developed financial market as opposed to an efficient one. Most of the previous studies found that emerging stock market countries are far from efficient due to the increase in the number of retail and institutional investors trading on stock markets. The different reactions in terms of their degree of information, interests and risk profiles, and reactions to news across different times are believed to be producing long memory in the stock return volatility. Earlier literatures on the strand of long memory and volatility are from diverse regions of the world like Germany, Malaysia etc. A few pertinent articles of Bilel, T. M. & S. Nadhem (2009) [2] , Corhay, A., A. T. Rad, & J. P. Urbain (1995) [3] , Gurgul, H., & T. Wójtowicz (2006) [4] , Kang, S. H., Cheong, C. C. & Yoon, S. M. (2010) [5] , Tan & Khan (2010) [6] , Kang, S. H. & Yoon, S. M. (2007) [7] , Kang, S. H. & Yoon, S. M. (2008) [8] , Lo, A. W. (1991) [9] need to be mentioned. This study attempts to test if stock returns and volatility exhibit long memory in national stock exchange (NSE) price indices over the period from 2006-06-29 to 2012-09-13, a total of 1545 observations.
2. Methodology
In this section we briefly explain about Autoregressive Fractional Integrated Moving Average (ARFIMA) model, Fractional Integrated GARCH (FIGARCH) model and the Fractional Integrated Asymmetric Power ARCH (FIAPARCH) model.
2.1. Autoregressive Fractional Integrated Moving Average (ARFIMA) Model
Following the Granger and Joyeux (1980) [10] , and Hosking (1981) [11] , for the series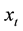 ,
, 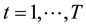 the ARFIMA(r, d, s) model may be expressed as follows:
the ARFIMA(r, d, s) model may be expressed as follows:
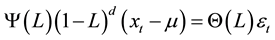 (1)
(1)
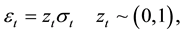 (2)
(2)
where μ is conditional mean and εt is independent and identically distributed (i.i.d.) with a variance , and L is the lag operator as denoted earlier.
, and L is the lag operator as denoted earlier. 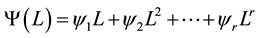 and
and 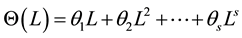 are the autoregressive (AR) and moving-average (MA) polynomials lie outside of unit cycles, respectively.
are the autoregressive (AR) and moving-average (MA) polynomials lie outside of unit cycles, respectively.
The process is said to be long memory at the long run as long as d > 0 in Equation (1). In particular, for 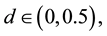 and d ≠ 0, the series is covariance stationary and mean reverting, with shocks disappearing in the long run; for
and d ≠ 0, the series is covariance stationary and mean reverting, with shocks disappearing in the long run; for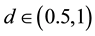 , the series imply mean-reversion, however, it is not a covariance stationary process as there is no long run impact of an innovation on future values of the process. For d ≥ 1, the series is non-statio- narity and non-mean-reversion. On the contrary, the process is said to exhibit intermediate memory, for
, the series imply mean-reversion, however, it is not a covariance stationary process as there is no long run impact of an innovation on future values of the process. For d ≥ 1, the series is non-statio- narity and non-mean-reversion. On the contrary, the process is said to exhibit intermediate memory, for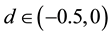 .
.
2.2. Fractional Integrated GARCH (FIGARCH) Model
Similar research on the volatility has led to an extension of the ARFIMA representation in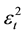 , leading to the FIGARCH model. Baillie et al. (1996) [12] have extended the traditional GARCH model to capture the long memory component in the return’s volatility. The FIGARCH (p, ξ, q) model is given by
, leading to the FIGARCH model. Baillie et al. (1996) [12] have extended the traditional GARCH model to capture the long memory component in the return’s volatility. The FIGARCH (p, ξ, q) model is given by
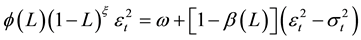
Or
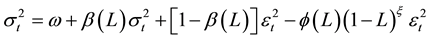
where 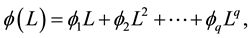 and
and 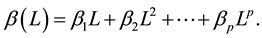 All the roots of
All the roots of 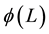 and
and 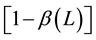 are assumed to stand in outside the unit root. The FIGARCH model provides greater flexibility for modelling the volatility as it nests GARCH. If ξ = 0, the FIGARCH (p, ξ, q) process reduces to a GARCH (p, q) process. The impact of a shock is said to decrease at a hyperbolic rate when 0 < ξ < 1. By allowing ξ to take a value within 0 and 1, FIGARCH permits for an intermediate range of persistence.
are assumed to stand in outside the unit root. The FIGARCH model provides greater flexibility for modelling the volatility as it nests GARCH. If ξ = 0, the FIGARCH (p, ξ, q) process reduces to a GARCH (p, q) process. The impact of a shock is said to decrease at a hyperbolic rate when 0 < ξ < 1. By allowing ξ to take a value within 0 and 1, FIGARCH permits for an intermediate range of persistence.
The parameters of the various-type of GARCH models can be estimated by using nonlinear optimization procedures to maximize the logarithm of the Gaussian likelihood function. However, as highlighted by Tang and Shieh (2006) [13] and Kang et al. (2010), the residuals estimated from the GARCH type model often suffer from asymmetry and leptokurtosis. To overcome the leptokurtosis problem, the Student-t distribution can be considered (Cheong 2008 [14] ; Kang and Yoon, 2008). On the other hand, to capture the asymmetry and leptokurtosis, Lambert and Laurent (2001) [15] proposed the skewed Student-t distribution.
2.3. Data Analysis and Findings
The data set used in this study comprises daily observations of NSE_Nifty and NSE_500 of India over the period 2006-06-29 to 2012-09-13, a total of 1545 observations. The daily stock returns are defined as the logarithmic first-difference of the daily closing index values. The data is extracted from the official website of reserve bank of India. We begin with descriptive statistics and stationarity analysis and presented first results in Table 1.
Table 1 of Panel A provides a summary of statistics of the stock return series. The significance of all the normality tests applied (in Panel B) indicated that the residuals appear to be leptokurtic. Further, the significant Ljung-Box statistics for the returns, Q(5) and squared returns, Q(10), indicating the rejection of the null of white noise, asserting that these return series are auto-correlated. In summary, it is clear that the Indian stock market exhibits frequent volatilities with extensive amplitude (which is also apparent in Figure 1), implying the assumption of normal distribution may not be suitable for capturing asymmetry and tail-fatness in a return distribution. Finally, unit root and stationary results reported in Panel C of Table 1 indicate that return series is stationary.
2.4. The Quantile-Quantile Test (Q-Q Plot)
The Q-Q plot helps us to compare shapes of probability distributions by plotting their quantiles against each other.

Table 1. Descriptive statistics and stationarity analysis.
Note: in the parenthesis we report p-values. *Denotes significance at 1% level of significance.
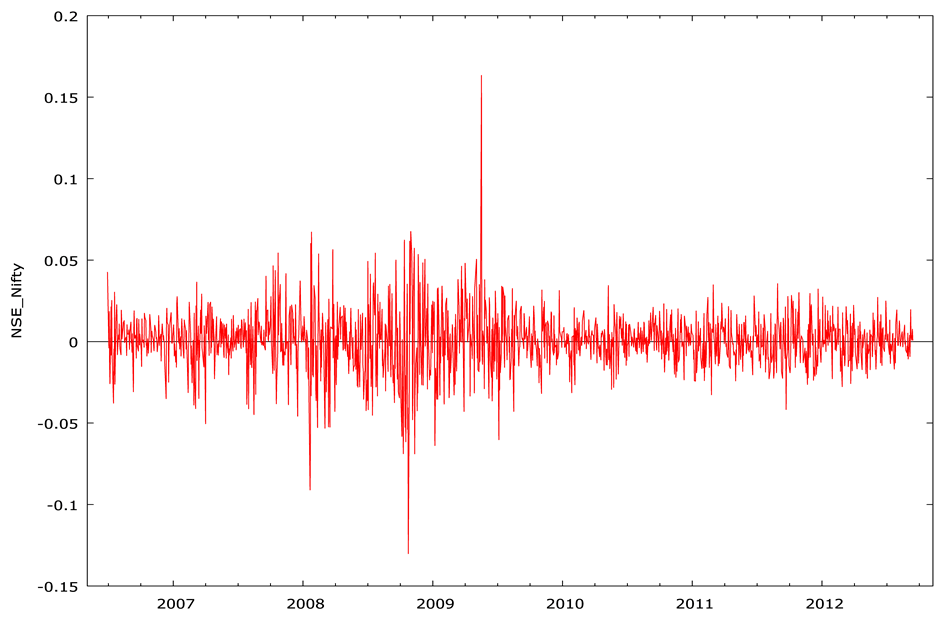
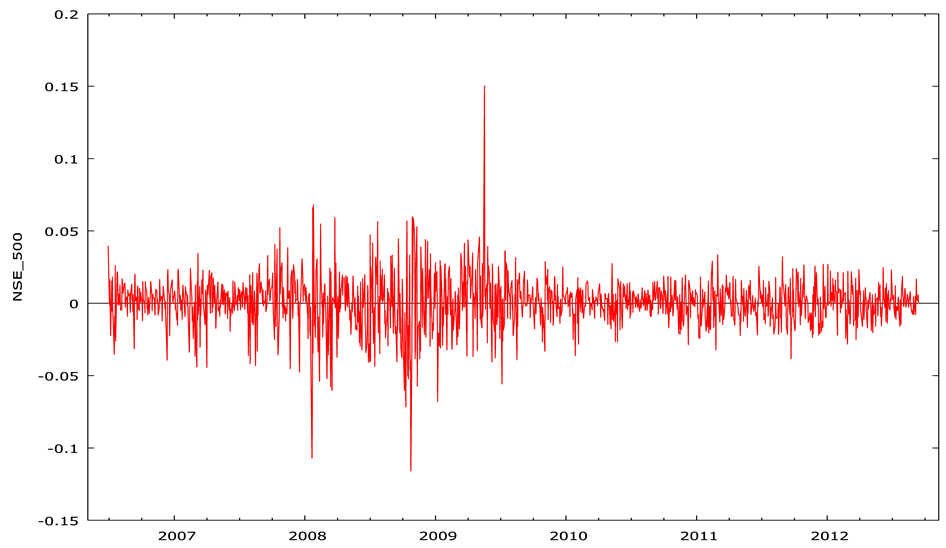
Figure 1. Exhibiting frequent volatilities for NSE_Nifty and NSE_500.
When we compare two distributions, if the points in the Q-Q plot lies approximately on the line y = x, then both distribution have similar pattern. If the Q-Q plot lies exactly on a line, then the distributions are linearly related. The Quantile-Quantile plots results (Figure 2) suggest that both share common and similar distributions.
The results obtained from the ARFIMA model (Figure 3), ARFIMA-FIGARCH model and ARFIMA-
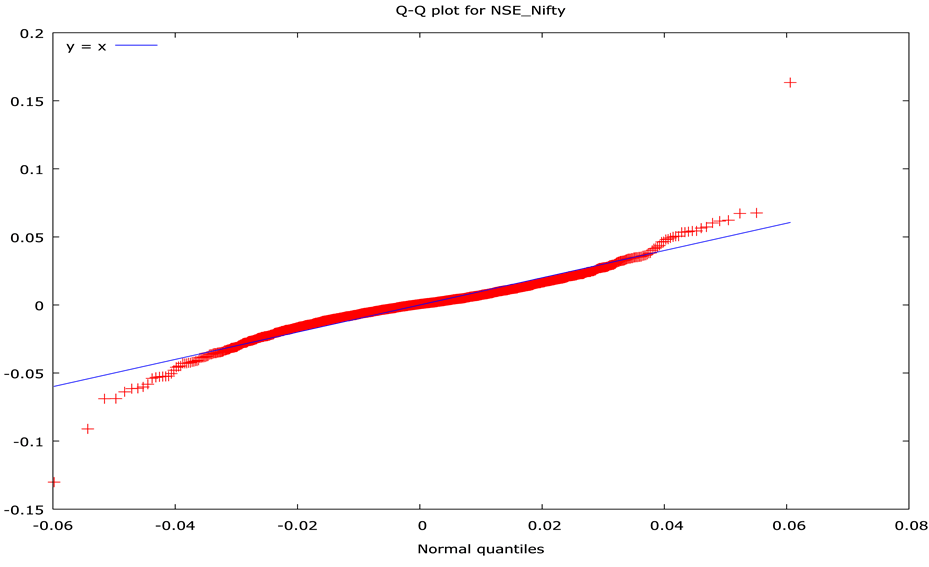
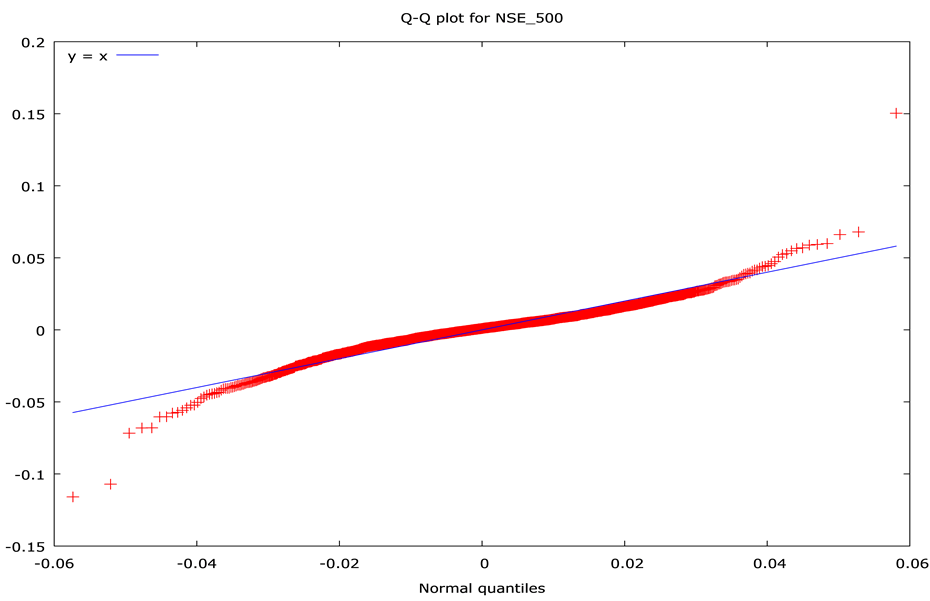
Figure 2. Q-Q plot for NSE_Nifty and NSE_500.
FIAPARCH are reported in Table 2 while those are based on Student t-distribution. The ARFIMA model is selected using the Akaike Information Criteria (AIC) [16] while fixing AR and MA at the maximum of 3. An ARFIMA (3, d, 3) model is found to best represent the long memory process in stock return series. The estimates of d are statistically significant at less than 1% percent level of significance. Thus, the results support that the
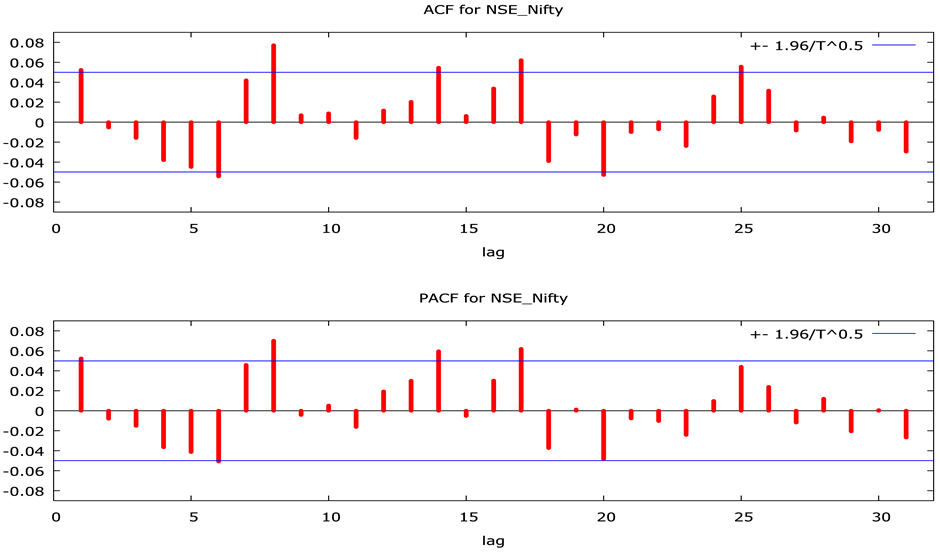
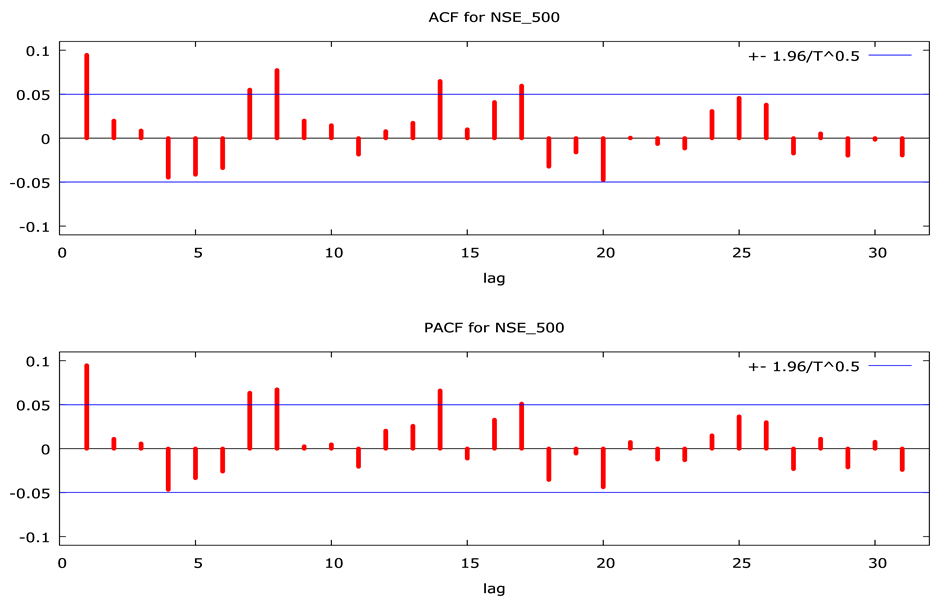
Figure 3. Autocorrelation and partial autocorrelation function for NSE_Nifty and NSE_500.
returns are forecastable and supportive of long memory processes. However, the residuals are mostly negatively skewed, implying that the distribution is non-symmetric. Further, we find significant Q-statistics implying that the residuals are not independent, the J-B test statistics provide the signal that the residuals are leptokurtic and the significant ARCH statistics indicates that the ARCH effects is present in the standardized residuals. There-
Table 2. Estimation results of the ARFIMA models for NSE_Nifty.
Notes: standard errors and p-values are in parentheses and brackets respectively. ** and * indicate significant at 5 and 1 percent significance level respectively. ln(L) value is the maximized value of the log likelihood function, and AIC is the Akaike (1974) Information criteria. J-B refers to Jarque-Bera normality test. The ARCH(5) and ARCH(10) denotes the ARCH test statistic with lag 5 and 10, while the Q(p) is the Ljung-Box test statistic for standardized residuals at lag p.
fore, based on these test statistics one can infer that for such situations working with the ARFIMA model in the return series and at the same time highlights the importance of testing the existence of long memory in volatility.
Therefore, in the next step we relied on ARFIMA-FIGARCH model. As shown in Table 3, the parameter d (i.e., d-Arfima) remains significant revealing the presence of long memory in return series. We find the long memory parameters, (d-Figarch), as 0.67 for the volatility component which is significant at 1 percent significance level, indicating the long-range memory phenomenon for volatilities. The existence of long memory in both return and volatility contradicts the efficient market hypothesis of Fama (1970) that the future return and
Table 3. Estimation results of the ARFIMA models for NSE_500.
Notes: Standard errors and p-values are in parentheses and brackets respectively. ** and * indicate significant at 5 and 1 percent significance level respectively. Ln(L) value is the maximized value of the log likelihood function, and AIC is the Akaike (1974) Information criteria. J-B refers to Jarque-Bera normality test. The ARCH(5) and ARCH(10) denotes the ARCH test statistic with lag 5 and 10, while the Q(p) is the Ljung-Box test statistic for standardized residuals at lag p.
volatility values are unpredictable. Further, the estimates of fat-tailed parameter (Student (DF)) is also statistically significant at the 1 percent level with the value of is 6.455669, suggesting the usefulness of Student-t distribution in modelling the leptokurtosis of estimated residuals.
Further, we estimated the ARFIMA-FIAPARCH model under Student-t distribution. The values of fractionally differencing parameters (i.e., d-Arfimaand d-Figarch) providing the evidence of dual long-memory process as they are significantly different from zero. Besides, the estimates of fat-tailed parameter (Student (DF)) which is statistically significant at the 1 percent level with value of 7.09, suggesting the usefulness of Student-t distribution in modelling the leptokurtosis of estimated residuals. The insignificant diagnostic statistics, for instance, the Q (p), and ARCH (p) also further confirm the selection of Student-t distribution to capture time-varying volatility.
In fact, Awartani and Corradi (2005) [17] , Tan and Khan (2010) also found that GARCH-class of models that do not allow for asymmetries in the volatility process are beaten by asymmetric GARCH models. As seen in the tables, according to the AIC, the ARFIMA-FIAPARCH models fit the return series better than the ARFIMA- FIGARCH models.
3. Conclusions
It can be concluded that there does exist a non-normal distribution in the return on Indian stock exchange, slightly leptokurtic as indicated by the Jarque-Berra test.
The process is said to be long memory at the long run as long as d > 0 in Equation (1). In particular, for d Î (0, 0.5), and d ¹ 0, the series is covariance stationary and mean reverting, with shocks disappearing in the long run; for d Î (0.5, 1), the series imply mean-reversion; however, it is not a covariance stationary process as there is no long-run impact of an innovation on future values of the process. For d ≥ 1, the series is non-stationary and non- mean-reversion. On the contrary, the process is said to exhibit intermediate memory, for d Î (−0.5, 0). Since our study exhibits that a d value of 0.09, 0.09 and 0.1 is indicative of mean reversion in conflict with efficient market.
References
- Fama, E. (1970) Efficient Capital Markets: A Review of Theory and Empirical Work. Journal of Finance, 25, 383-417. http://dx.doi.org/10.2307/2325486
- Bilel, T.M. and Nadhem, S. (2009) Long Memory in Stock Returns: Evidence of G7 Stocks Markets. Research Journal of International Studies, 9, 36-46.
- Corhay, A., Rad, A.T. and Urbain, J.P. (1995) Long Run Behavior of Pacific Basin Stock Prices. Applied Financial Economics, 5, 11-18. http://dx.doi.org/10.1080/758527666
- Gurgul, H. and Wójtowicz, T. (2006) Long Memory on the German Stock Exchange. Czech Journal of Economics and Finance, 56, 447-468.
- Kang, S.H., Cheong, C.C. and Yoon, S.M. (2010) Long Memory Volatility in Chinese Stock Markets. Physica A, 389, 1425-1433. http://dx.doi.org/10.1016/j.physa.2009.12.004
- Tan, S. and Khan, M. (2010) Long-Memory Features in Return and Volatility of the Malaysian Stock. Economics Bulletin, 30, 3267-3281.
- Kang, S.H. and Yoon, S.M. (2007) Long Memory Properties in Return and Volatility: Evidence from the Korean Stock Market. Physica A, 385, 597-600. http://dx.doi.org/10.1016/j.physa.2007.07.051
- Kang, S.H. and Yoon, S.M. (2008) \Long Memory Features in the High Frequency Data of the Korean Stock Market. Physica A, 387, 5189-5196. http://dx.doi.org/10.1016/j.physa.2008.05.050
- Lo, A.W. (1991) Long Term Memory in Stock Market Prices. Econometrica, 59, 1279-1313. http://dx.doi.org/10.2307/2938368
- Joyeux, R. and Granger, C.W.J. (1980) An Introduction to Long-Memory Time Series Models and Fractional Differencing. Journal of Time-Series Analysis, 1, 15-29. http://dx.doi.org/10.1111/j.1467-9892.1980.tb00297.x
- Hosking, J.R.M. (1981) Fractional Differencing. Biometrika, 68, 165-176. http://dx.doi.org/10.1093/biomet/68.1.165
- Bailliea, R.T., Bollerslev, T. and Mikkelsenc, H.O. (1996) Fractionally Integrated Generalized Autoregressive Conditional Heteroskedasticity. Journal of Econometrics, 74, 3-30. http://dx.doi.org/10.1016/S0304-4076(95)01749-6
- Tang T.L. and Shieh, S.J. (2006) Long Memory in Stock Index Future Markets: A Value-at-Risk Approach. Physica A: Statistical Mechanics and its Applications, 366, 437-448. http://dx.doi.org/10.1016/j.physa.2005.10.017
- Cheong, W.C. (2008) Volatility in Malaysian Stock Market: An Empirical Study Using Fractionally Integrated Approach. American Journal of Applied Sciences, 5, 683-688. http://dx.doi.org/10.3844/ajassp.2008.683.688
- Lambert, P. and Laurent, S. (2001) Modelling Financial Time Series Using GARCH-Type Models and a Skewed Student Density. Université de Liège, Mimeo.
- Akaike, H. (1974) A New Look at the Statistical Model Identification. IEEE Transactions on Automatic Control, 19, 716-723. http://dx.doi.org/10.1109/TAC.1974.1100705
- Awartani, B. and Corradi, V. (2005) Predicting the Volatility of S&P-500 Stock Index via GARCH Models: The Role of Asymmetries. International Journal of Forecasting, 21, 167-183. http://dx.doi.org/10.1016/j.ijforecast.2004.08.003