Journal of Mathematical Finance
Vol.06 No.01(2016), Article ID:63752,17 pages
10.4236/jmf.2016.61010
An Econometric Approach to Incorporating Non-Normality in VaR Measurement
Victor Gumbo, Simiso Siziba
Department of Finance, National University of Science and Technology, Bulawayo, Zimbabwe

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 20 October 2015; accepted 22 February 2016; published 25 February 2016
ABSTRACT
Following the recent financial crises, there has been a proliferation of new risk management and portfolio construction approaches. These approaches all endeavour to better quantify and manage risk by accounting for the stylised facts of financial time series mainly heavy and skewed tails, volatility clustering and converging correlations. Capturing all these stylised facts in a coherent framework has proved to be an elusive and knotty task. We here propose a pure econometric framework that captures all the stylised facts satisfactorily. We use three data sets to show how the approach is implemented in VaR forecasting and correlation analysis. We show how an investment portfolio can be constructed in order to optimise reserve capital holding. The approach employed is linear programming (LP) computable, satisfies second degree stochastic dominance and outperforms the general mean/VaR quadratic optimisation to arrive at efficient asset allocation.
Keywords:
VaR, Stylised Facts, Volatility Clustering, Leptokurtic Returns, Converging Correlation

1. Introduction
The past decade has seen a number of financial institutions fail worldwide. In Zimbabwe alone, from a peak of 40 banks in 2002, 20 banks remain operational as of January 2014 [1] . In the USA, since 2008, 465 banks have failed, amounting to USD 687 bn in total assets [2] . Failures at these institutions are more often than not caused by deep rooted risk management deficiencies, excessive risk appetite resulting in over-trading and poor cor- porate governance practices. In developing countries, these institutions are key in the economy as they provide basic financial services to the public, financing to commercial enterprises, and access to the payment systems; hence there is a need to safeguard their continued existence and ensure sustainable economic growth. For these reasons, the quality of risk management expected of banking institutions is very high.
World over emphasis on risk management is quite high as demonstrated by the evolution of the Basel accord. Specifically, it was recognised that some changes were necessary to the computation of capital for market risk in the Basel 2 framework. These changes are referred to as Basel 2.5. There are three changes involving:
・ The calculation of a stressed VaR;
・ A new incremental risk charge; and
・ A comprehensive risk measure for instruments dependent on credit correlation.
These measures all have the effect of greatly increasing the market risk capital that large banks are required to hold. Our interest lies in the approach to VaR and the essence of stressed VaR in order to optimise reserve capital holding.
Studies by [2] -[4] among others, show how the GARCH framework may be used to arrive at VaR. In [5] the extreme value theory and GARCH processes are used as the key tools in measurement of risk. We here follow the GJR-GARCH of [6] in an attempt to capture the stylised facts of financial time series. In practice, Basel 2.5 requires banks to calculate two VaRs [7] . One is the usual VaR (based on the previous one to four years of market movements). The other is stressed VaR (calculated from a stressed period of 250 days). The two VaR measures are combined to calculate a total capital charge. The formula for the total capital charge is
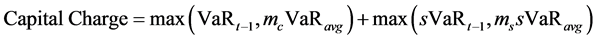
where 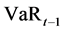 and
and 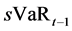 are the VaR and stressed VaR (with a 10-day time horizon and a 99 percent confidence level), respectively, calculated on the previous day. The variables
are the VaR and stressed VaR (with a 10-day time horizon and a 99 percent confidence level), respectively, calculated on the previous day. The variables 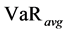 and
and 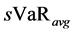 are the average of VaR and stressed VaR (again with a 10-day time horizon and a 99 percent confidence level) cal- culated over the previous 60 days. The parameters
are the average of VaR and stressed VaR (again with a 10-day time horizon and a 99 percent confidence level) cal- culated over the previous 60 days. The parameters 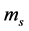 and
and 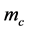 are multiplicative factors that are determined by bank supervisors and are at minimum equal to three. The capital requirement prior to Basel 2.5 was
are multiplicative factors that are determined by bank supervisors and are at minimum equal to three. The capital requirement prior to Basel 2.5 was
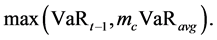
Because stressed VaR is always at least as great as VaR, the formula shows that (assuming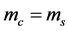 ) the capital requirement must at least double under Basel 2.5, and beyond.
) the capital requirement must at least double under Basel 2.5, and beyond.
2. Problem Statement and Objectives
Two main issues are of concern. Fistrly, looking closely we do observe that the stressed VaR period is subjective. In Europe, it was considered that 2008 would constitute a good one-year period for the calculation of stressed VaR. Later it was required that Banks search for a one-year period during which its portfolio would perform very poorly [7] . The stressed period used by one bank is not necessarily the same as that used by another bank. In order to better measure risk, there is need to incorporate non-normality of financial time series. This paper seeks to achieve the following objectives:
1) To develop a practically sound, functional and industry useful framework for market risk management.
2) To demonstrate how serial correlation can be tested and corrected for in financial times series.
3) To show how skewed and leptokurtic tails are accounted for in VaR measurement.
4) To show how GARCH forecasting can be integrated into determining portfolio risk.
5) To test for returns normality in 3 asset classes.
6) To test whether the Skewed t outperforms the normal distribution in explaining asset returns.
Secondly, we also note that randomness and normality generalisation of financial time series may need to be re-thought in order to accurately quantify risk. Studies in [8] observed that the tails of a distribution of price changes are extraordinarily long and the sample second moment of price typically varies in an erratic fashion. This in essence does suggest Stable Paretian distributions. Similar conclusions are drawn in [9] and [10] . Generally the studies conclude in disfavour of the normality assumption. However the model choice for asset returns remains a statistical option. In this study we use the skewed t approach.
3. Methodology
The risk management approach which we detail is that of a long position in financial instruments, hence great emphasis is put on the left tail of the distribution. Our end goal is to articulate an asset allocation framework that optimises future return expectations with sturdy downside risk management. To comprehensively capture the four stylised facts, a profound knowledge of AR, GARCH processes, and stable Paretian distributions is needed.
From an investment perspective, lower than necessary capital levels increase the risk of failure, whereas higher than required capital levels lower equity rate of return, and locks up vital capital needed for that could be invested elsewhere to maximise value. We test for normality from the three data set, the ZSE industrial index, USD/ZAR exchange rate and Gold which are selected proxies for the equities, foreign exchange markets and commodities markets. The problem of non-normality is addressed in four phases:
1) Serial correlations in returns.
2) Heteroscedasticity in volatility of returns.
3) Asymmetric returns: Negative skewness and leptokurtosis.
4) Correlation convergence.
Let S be a subset of the real numbers. For every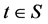 , let
, let 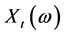 be a random variable defined on a probability space (
be a random variable defined on a probability space (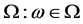 ). The stochastic process
). The stochastic process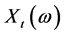 :
: 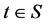 is called a time series. It is stochastic in the sense that it is a collection of random variables ordered in time. Now let
is called a time series. It is stochastic in the sense that it is a collection of random variables ordered in time. Now let 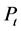 be the price or value of a security. We define
be the price or value of a security. We define  as follows:
as follows:
 (1)
(1)
A stochastic process is said to be stationary if its mean and variance are constant over time and the value of the covariance between the two time periods depends only on the lag between the two time periods and not on the actual time at which the covariance are computed; thus
 (2)
(2)
 (3)
(3)
 (4)
(4)
In the autoregressive (AR) time series model, an observation  is directly related to p previous observation by:
is directly related to p previous observation by:
 (5)
(5)
Here  is assumed to be white noise thus
is assumed to be white noise thus .
.
For each asset class we formally test for serial correlation by calculating Ljung-Box (LB) Q statistic, [11] . We show how the AR process may be applied to model the dependence of returns. The lag length is determined by the decay of the partial autocorrelation function (PACF). We show that when first order serial correlation is not corrected for, it conceals true asset volatility and may lead to underestimation of total portfolio risk. In order to correct for the impact of serial correlation we follow [12] ’s unsmoothing methodology.
We consider a simple AR smoothing model
 (6)
(6)
where  denotes the reported return at t,
denotes the reported return at t,  is the true underlying return, and
is the true underlying return, and  is the smoothing parameter.
is the smoothing parameter.
Assume that the true returns follow a stationary AR(1) process:
 (7)
(7)
where .
.
Combining equations the above, we get;
 (8)
(8)
where .
.
Applying OLS to (8) above we obtain an estimate for  as
as
 (9)
(9)
We proceed to test for statistical significance of serial dependence at 5 percent. Where statistical significance is found, we transform our returns by following the relationship in (6):
 (10)
(10)
Financial time series has a tendency to produce returns that are skewed and leptokurtic [13] . Our model of choice is the GJR GARCH [6] , an extension to the original Generalised Autoregressive Conditional Heterosced- asticity (GARCH) model [14] . We want to capture other stylized facts such as asymmetry, leverage effect, volatility clustering and allow for fat tails. This will aid us to properly quantify risk. Consider a returns series
 (11)
(11)
where  is the expected return and
is the expected return and  is a zero mean white noise process. If we can write an expression for
is a zero mean white noise process. If we can write an expression for  as
as  where
where  is standard normal, then
is standard normal, then  follows a GJR GARCH
follows a GJR GARCH  and its conditional volatility can be expressed as:
and its conditional volatility can be expressed as:
 (12)
(12)
where  if
if , 0 otherwise.
, 0 otherwise.
We estimate the GJR GARCH (1, 1) which is generally sufficient for financial time series
 (13)
(13)
The following restrictions apply:
 ,
,  and
and . The model is still admissible if
. The model is still admissible if  provided
provided .
.
We apply the Jacque-Bera test for normality of the residuals. The following relationship should hold
 (14)
(14)
otherwise we fit the residuals to some fat tailed distribution.
We here state without proof that the GJR model implies that the forecast of the conditional variance at time T + h is given by:
 (15)
(15)
Our approach to modelling left tail risk is a semi parametric approach. We define left tails as 10 percent of all data to the extreme left. Our choice of extreme value distribution is the Skewed t distribution. We define the loss function as:
Definition 3.1 (Loss Function). The loss function is given by the change in value, V, of the portfolio between time t and :
:
 (16)
(16)
By convention, the loss function is usually expressed as a positive value and we are concerned with the left hand tail, i.e., for long positions. Mathematically, VaR refers to the alpha-quantile of a distribution.
Definition 3.2 (Value at Risk). The value at risk,  for confidence level
for confidence level , where
, where  is the cumulative loss function associated with x is given by
is the cumulative loss function associated with x is given by

3.1. Value at Risk for the Gaussian Distribution
The main assumption in this model is that of conditional normality. The return on day t is normally distributed conditional on the information on day . Therefore, the shocks
. Therefore, the shocks  ~iid N(0; 1).
~iid N(0; 1).
Once  and
and  are obtained from the conditional mean and variance equations, the VaR can be calculated as:
are obtained from the conditional mean and variance equations, the VaR can be calculated as:
 (17)
(17)
where  is the standard normal cdf.
is the standard normal cdf.
3.2. Value at Risk for the Skewed t Distribution
The model parameters are estimated in two steps. In the first step, the parameters of the GARCH process are estimated. In the second step, the standardized residuals  are extracted from the fit and as in [15] skewed t distribution is fit to these residuals. VaR is calculated using the property that linear transformations of skewed t distributed variables are also skewed t distributed. For example,
are extracted from the fit and as in [15] skewed t distribution is fit to these residuals. VaR is calculated using the property that linear transformations of skewed t distributed variables are also skewed t distributed. For example,  and loss is given by
and loss is given by . Once the estimates are computed, the conditional mean and variance ascertained, VaR can be obtained as
. Once the estimates are computed, the conditional mean and variance ascertained, VaR can be obtained as
 (18)
(18)
We extend the univariate GARCH models to incorporate the assymetric response of returns to market shocks. For a single asset, conditional variance is the variance of the unpredictable part, . That is, if
. That is, if  then the conditional variance is given by
then the conditional variance is given by .
.
The same is true for the multivariate conditional variance-covariance matrix. We define the conditional variance-covariance matrix for the part of  that is not predictable as:
that is not predictable as:
 (19)
(19)
where ,
,  is a 3 × 3 variance-covariance (vcov) matrix,
is a 3 × 3 variance-covariance (vcov) matrix,  is a 3 × 1 disturbance vector,
is a 3 × 1 disturbance vector,  represents the information set at time
represents the information set at time ,
,  is a 6 × 1 parameter vector, A and
is a 6 × 1 parameter vector, A and  are 6 × 6 para- meter matrices and
are 6 × 6 para- meter matrices and  denotes the column-stacking operator applied to the upper portion of the sym- metric matrix. As before, Equation (19) below holds. We simplify (18) above and present it in an estimable form tailored to estimate the vcov matrix.
denotes the column-stacking operator applied to the upper portion of the sym- metric matrix. As before, Equation (19) below holds. We simplify (18) above and present it in an estimable form tailored to estimate the vcov matrix.
 (20)
(20)
We contrast the estimated v-cov to the industry practice of using the linear correlation coefficient,
 (21)
(21)
As a side note and not to venture far afield we follow [16] and present our bi-criteria objective which might be used to allocate assets in the portfolio.
Let:
 be the available number of assets;
be the available number of assets;
 be the vector of the predicted mean returns of the
be the vector of the predicted mean returns of the  asset;
asset;
 the number of assets to invest (
the number of assets to invest ( );
);
 the minimum inversion ratio in the
the minimum inversion ratio in the  asset;
asset;
 the maximum inversion ratio allowed in the
the maximum inversion ratio allowed in the  asset;
asset;
 if the
if the  asset is chosen, 0 otherwise;
asset is chosen, 0 otherwise;
 is vector of the money ratio (
is vector of the money ratio ( );
);
 be the loss function for the portfolio.
be the loss function for the portfolio.
The optimisation problem is formulated in the following way:
Objective:
 (22)
(22)
Subject to
 (23)
(23)
 (24)
(24)
 (25)
(25)
 (26)
(26)
We also define the following terms:
 (27)
(27)
 (28)
(28)
where  is the confidence level,
is the confidence level,
 (29)
(29)
Our primary performance measure is the ratio of the mean forecast return divided by the forecast . This is consistent with our optimisation problem above.
. This is consistent with our optimisation problem above.
 (30)
(30)
where  is the forecast return,
is the forecast return,  refers to the Value at Risk with a confidence level of
refers to the Value at Risk with a confidence level of .
.
We now describe our approach for evaluating the robustness of our findings to alternative performance mea- sures. We define a performance measure as a ratio of reward to risk that is valid with respect to a given utility function. In practice, investor preferences are heterogeneous and there is no single utility function that is valid for all investors. Hence there is no single performance measure that is appropriate for all investors and it makes sense to evaluate performance through the prism of a number of different measures [2] . We restrict ourselves to measures that are consistent with the expected utility theory, and have a decision theoretic basis.
Up to now we have considered a regulatory risk measure, VaR, that does not care about losses in excess of VaR. If one looked at the area below the cumulative density function up to a given target payoff, this would be a risk measure which would consider not only the probability, but also the amount of losses. This measure is called Lower Partial Moment One . The formal definition of the lower partial moment of order n with target h is,
. The formal definition of the lower partial moment of order n with target h is,

For all pay-offs above the target, the target is reached and therefore the shortfall is zero: payoffs that are higher than the target cannot compensate payoffs below the target. Then,  gives the expected amount by which the target is missed (the expected shortfall).
gives the expected amount by which the target is missed (the expected shortfall).
Generalised lower partial moments (LPM) provide the basis for our supplementary performance measures. LPM follow directly from the utility function proposed in [17] and (1982) [18] . The Generalised Lower Partial Moment,  , where n is the LPM degree, h the target/threshold return,
, where n is the LPM degree, h the target/threshold return,  is the return to security i during period t and m the number of observations is defined as follows:
is the return to security i during period t and m the number of observations is defined as follows:
 (31)
(31)
In the same way as in VaR, we measure the mean LPM order 1 and 2 ratios. This gives a complementary view to portfolio performance measurement analysis.
4. Data Analysis and Presentation of Findings
Our approach is made up of two parts. Firstly, we identify the several types of non-normality that are typically not allowed for in traditional asset allocation. Secondly, we then integrate these empirical results in risk mea- surement.
Data for the period March 2009 to April 2014 was used. The Zimbabwe Stock Exchange (ZSE) Industrial index, was used as a proxy for equities, the USD/ZAR exchange rate for currencies and gold for commodities. There is, however, limited exposure by Zimbabwean investors to other asset classes such as bonds and options. A real estate index was constructed but unfortunately its returns differed markedly from those reported in the real estate market hence it was discarded at least for purposes of this study. Figures 1-3 show the returns time plot of the three assets under consideration.

Figure 1. Currencies returns time plot.

Figure 2. Equities return time plot.

Figure 3. Gold return time plot.
4.1. Evidence of Non-Normality in Returns
4.1.1. Serial Correlation
Serial correlation occurs when one period’s return is correlated to the previous period’s return. Figures 4-6 show the time plot of the asset values. Noticeably, the ZSE plot is not stationary i.e. the data does not fluctuate around some common mean or location, this attribute induces dependence in returns over time. However the time/returns of Figures 1-3 does appear to be stationary (the data does fluctuate around a common mean or location). Henceforth, it is not graphically clear to concur on the presence of serial correlation.

Figure 4. Equities time plot.

Figure 5. Currencies time plot.

Figure 6. Gold time plot.
When dealing with time series it is desirable to have a stationary data set primarily because the traits of a stationary data set allow one to assume models that are independent of a particular starting point. In essence it becomes unnessecary to compute VaR and Stressed VaR seperately. The two under strict stationarity give similar VaR. Double the VaR computed here is able to satisfy Basel 2.5 requirements.
When there is non-stationary the previous values of the error term will have a non-declining effect on the current value of returns as time progresses. We consolidate our above findings by formally testing for first order serial correlation using the Lung Q-Statistic [11] . We conduct the test as follows:
H0: first order serial correlation does not exist in the data.
H1: first order serial correlation does exist in the data.
If the Q-Statistic for a given asset class has significance at a 5 percent, i.e. a p < 0.05 we reject the null hypothesis of no serial correlation and conclude that there is serial correlation in data. In this case we must allow for the effect of serial correlation on future asset class returns. If the p value is higher than 0.05, the null is not rejected and we conclude that there is insufficient evidence to reject the null. We summarise our results in Table 1.
We conclude that serial correlation is present in equities and the foreign exchange rate returns. We generalise the major drivers of the findings to this case as driven by illiquidity, jumps especially for equities and low frequency of trade. In the case of currencies, the exchange rate is a managed float. This control makes it hard-to- price the true intrinsic value of the asset.
4.1.2. Heteroscedasticity
Presence of Heteroscedasticity makes it difficult to gauge the true standard deviation of the forecast errors, usually resulting in confidence intervals that are too wide or too narrow. In particular, if the variance of the errors is increasing over time, confidence intervals for out-of-sample predictions will tend to be unrealistically narrow. In Figures 1-3 we observed volatility clustering. We will estimate the GJR GARCH model to capture Heteroscedasticity in returns, generating heavy tails in the unconditional distribution of returns. Through modelling Heteroscedasticity we show simple, yet effective approaches to forecasting future volatility and VaR computation.
4.1.3. Fat Tails
We summarise the returns data with summary statistics in Table 2.
The table below shows data is non-normal. In practise, when normality is imposed, risk is understated. To further stress the fact that data is not normal, we show in Figures 7-9 the empirical histogram superimposed with the normal distribution of equal mean and standard deviation. The graphs clearly show the existence of stylised fact; fat tails.
From the diagrams, it is visibly shown that the third stylised fact, fat tails are real. Negative returns are observed in greater magnitude and with higher probability than implied by the normal distribution. Neglect of this non-normality leads to underestimation of risk. On all the two asset classes we reject normality and also conclude that the left tail is indeed heavier than predicted by the normal distribution.

Table 1. Testing for serial correlation.
Table 2. Testing for normality in daily asset returns.

Figure 7. ZSE industrial index returns.

Figure 8. USD/ZAR retuns empirical histogram.

Figure 9. Gold returns.
4.1.4. Converging Correlations
It is common observation in financial literature that correlations tend to be unstable over time and converge in times of economic turmoil. We investigate whether correlations between asset classes tend to increase during periods of high market volatility compared to periods of relative calm. We compare the correlations during the first two years after dollarisation1 with correlations spanning the whole period. We attempt portfolio con- struction using GARCH DCC analysis. Table 3 shows Pearson’s correlation coefficient during the 2 periods of contrast. The upper portion shows pearson’s  during the 5.25 years under study yet the bottom triangulation is for the first two stressed volatile years.
during the 5.25 years under study yet the bottom triangulation is for the first two stressed volatile years.
Shockingly, the results show that correlations not only defy stationarity but they do converge during times of high market volatility. This simply means that the benefits of diversification are overestimated. Frameworks which assume normality and linear co-movement of asset returns lead to significant underestimation of joint negative returns during bearish markets.
4.2. Incorporating Non-Normality into Asset Allocation Framework
In this section, we offer statistical methodologies for incorporating the four categories of non-normality dis- cussed above. Our belief is that achieving optimal portfolio efficiency should be based on a more precise estimation of risk and advertently requires embracing non-normality in financial time series.
4.2.1. Incorporating the Impact of Serial Correlation
Existence of serial correlation conceals the true risk characteristics of an asset. If ignored, this will reduce risk estimates from a time series by smoothing true asset volatility. Our task is to compute the unsmoothed more volatile return series for both equities and currencies. Industry convention is to use the partial autocorrelation function (PACF) as a guide to determine the appropriate lag length. The PACF of our data is shown in Figures 10-12. The order is determined by viewing the lines that fall outside the confidence bounds (the blue lines) and
Table 3. Correlation data over stressed and normal periods.

Figure 10. Commodities autocorrelation function.

Figure 11. Currencies autocorrelation function.

Figure 12. Equitities autocorrelation function.
counting how many lags it takes for the data to fall inside the confidence bounds. By viewing the PACF, the evidence is weak towards finding a good fitting AR model for the data. According to the PACF the data looks random and certainly shows no easily discernible pattern. Our thrust is for correcting for first order serial correlation. This would support the appearance of the time series plot since it looks a lot like white noise except for the change in spread (variation) of observations. Such Heteroscedasticity would most likely not be evident in a truly random data set. This, however, does not mean we rule out the possibility that the data fits an AR model with weak autocorrelation.
In order to correct for serial correlation we apply [12] unsmoothing methodology.
Step 1. We estimate  for both equities and currencies:
for both equities and currencies:


The USD/ZAR returns had jumps. This was largely attributed to the exchange rate regime which are managed floats. Also, the slow decay of its ACF may imply the presence of Heteroscedasticity, hence we attempt to capture the stylised fact in the next section.
Step 2. We produce our unsmoothed return series in Table 4. The summary statistics demonstrated that across the board, unsmoothed data does unmask true asset volatility which is higher.
A simple observation can be made that unsmoothed data even deviates more from normality than the un- smoothed returns data. We invoke the Jacque-Bera test to verify this. The data speaks for its self.
 , with p-value 0.
, with p-value 0.
 , with p-value 1.57802e−011.
, with p-value 1.57802e−011.
The increase in the series volatility as a result of removing first order serial correlation coupled with strong evidence of non-normality are compelling findings for use of more robust risk measuring tools.
4.2.2. Incorporating Heteroscedasticity
We now shift gears in an attempt to find some sort of pattern in the data that would suggest the use of a different model. The result of the ACF plot in Figures 9-12 does suggest that a pattern exist in the unconditional distribu- tion of the mean equation. This is noticed from the slow decay of the ACF lag plots. This indicates there is correlation between the magnitude of change in the returns. In other words, there is serial dependence in the variance of the data. Our proposed risk measure, VaR, is a prediction concerning possible loss of a portfolio in a given time horizon. Following the Basel recommendations, it should be computed using the predictive dis- tribution of future returns and volatility. We estimate the conditional mean and variance equations.
Using Gretl on quasi maximum likelihood (QML) we simultaneously estimate the parameters ,
,  ,
,  ,
,  and
and . The assumption that
. The assumption that  is Gaussian or not does not necessarily imply that the returns are Gaussian.
is Gaussian or not does not necessarily imply that the returns are Gaussian.
Prediction
If  is the sample volatility at time T and letting
is the sample volatility at time T and letting ,
,  ,
,  ,
,  and
and  be the estimates of the model then a volatility forecast for a time length
be the estimates of the model then a volatility forecast for a time length  may be presented as:
may be presented as:
 (32)
(32)
Thus
 (33)
(33)
(a) We assume , the innovations are standard normal, the fitted mean and volatility equations are
, the innovations are standard normal, the fitted mean and volatility equations are
 (34)
(34)
 (35)
(35)
(b) We assume the errors follow a Skewed t distribution, our mean and variance equation are:
Table 4. Summary statistics for unsmoothed returns.
 (36)
(36)
 (37)
(37)
When we use the GJR GARCH and distributions that allow for leptokurtic returns we enhance risk reporting. It can also be shown as is generally misconstrued that VaR is not a function of time but rather of the returns conditional distribution. In Figures 12-15 we plot the quantile plots for the fit data. It can be shown that the skewed t distribution is a better fit. It might not be perfect but it does have a fair track of the left tail better.
Outliers still persist as in Gold returns and USD/ZAR exchange rate returns, however the Skewed t distribu- tion manages to tracks the tails fairly well.
4.2.3. GARCH DCC
A multivariate GARCH model of the diagonal VECH type is employed. The coefficient estimates are easiest presented in the following equations for the conditional variance or covariance:
 (38)
(38)

Figure 13. QQ plot rGold skewed T innovations.

Figure 14. QQ plot USD-ZAR skewed T innovations.

Figure 15. QQ plot ZSE skewed T innovations.
where  is the conditional covariance,
is the conditional covariance,  are a set of value weights at
are a set of value weights at  refers to equities, currencies and commodities respectively.
refers to equities, currencies and commodities respectively.
The unconditional covariance between the assets are positive. It is however interesting to note that there is a very strong positive correlation between gold and the USD/ZAR exchange rate. This inadvertently implies that it is unwise for a trader to overweight long positions on both gold and USD.
Table 5 summarises the VaR estimates achieved when the proposed model is implemented. A skewed t case
Table 5. Forecast VaR.
is contrasted to the normal distribution case.
In this section we have conducted a statistical analysis in a stepwise framework. We first removed the autocorrelation component to unmask true asset volatility, then the GJR-GARCH model is estimated assuming normal errors and finally the skewed t-distribution is fit to the errors. The fitted model is used as a basis to estimate VaR and the correlation matrix in the case of a portfolio.
5. Conclusions
Econometric approaches have been used extensively in risk measurement to address stylised facts in financial time series. In recent years, a number of people have proposed various models with diverse transformations and adaptations. These models endeavour to better quantify risk. Unfortunately, in practice, usefulness of these models could be associated with unintended consequences especially as their level of complexity increases with every step taken to enhance accuracy. In this paper a stepwise model that captures the stylised facts in a simple, coherent and user friendly method is presented.
The main thrust of the model is in accounting for heavy tails in returns data. Incorporating these fat tails generally increases capital requirements, and thus effectively reduces chances of failure though inadvertently return on capital is reduced. Contrary to what literature suggests, VaR is a function of the returns distribution for a given asset and not of time. The study proposes a stepwise AR/GJR-GARCH Skewed-t distribution to incor- porate deviations from normality. The first step involves unsmoothing returns using the AR to unmasks auto- correlation and bring out the true volatility. This results in a more jerked returns time plot. The GJR-GARCH captures heteroscedasticity and the leverage effect. The Skewed-t captures asymptotic behaviour of the tails. The choice of innovations distribution structure is a purely statistic one. The GPD, Multivariate Student t, EVT, Skewed Normal distribution, the Frechet and Gumbul distributions may all be used. We use three data sets to show how the approach is implemented in VaR forecasting and correlation analysis. We show how an invest- ment portfolio can be constructed in order to optimise reserve capital holding. The approach employed is linear programming (LP) computable, satisfies second degree stochastic dominance and outperforms the general mean/ VaR quadratic optimisation to arrive at efficient asset allocation.
Cite this paper
VictorGumbo,SimisoSiziba, (2016) An Econometric Approach to Incorporating Non-Normality in VaR Measurement. Journal of Mathematical Finance,06,82-98. doi: 10.4236/jmf.2016.61010
References
- 1. Dhliwayo, C.L. (2013) Limiting the Risk of Failure in Financial Institutions. Reserve Bank of Zimbabwe.
- 2. Allen, D. and Satchell, S. (2014) The Four Horsemen: Heavy Tails, Negative Skew, Volatility Clustering, Assymetric Dependence. University of Sydney.
- 3. Hamilton, J.D. and Susmel, R. (1994) Autoregressive Conditional Heteroskedasticity and Chages in Regime. Journal of Econometrics, 64, 307-333.
http://dx.doi.org/10.1016/0304-4076(94)90067-1 - 4. Malmsten, H. and Terasvirta, T. (2004) Stylised Facts of Financial Time Series and Three Popular Models of Volatility. Stockholm School of Economics, Working Paper Series in Economics and Finance No. 563.
- 5. Nystrom, K. and Skuglund, J. (2002) Univariate Extreme Value Theory, GARCH and Measures of Risk Sweden Bank.
- 6. Glosten, L., Jagannathan, R. and Runkle, D. (1993) Relationship between the Expectd Value and the Volatility of the Nominal Excess Return on Stocks. Journal of Finance, 48, 1779-1801.
http://dx.doi.org/10.1111/j.1540-6261.1993.tb05128.x - 7. Risk Metrics Technical Document, 4th Edition, New York.
- 8. Mandelbrot, B. (1963) The Variation of Certain Speculative Prices. Journal of Business, 36, 394-419.
http://dx.doi.org/10.1086/294632 - 9. Rama, C. (2001) Empirical Properties of Asset Returns: Stylised Facts and Statistical Issues. Quantitative Finance, 1, 223-236.
http://dx.doi.org/10.1080/713665670 - 10. Sheikh, A. and Qiao, H. (2010) Non-Normality of Market Returns: A Framework for Asset Allocation Decision Making. Journal of Alternative Investments, 12, 8-35. http://dx.doi.org/10.3905/JAI.2010.12.3.008
- 11. Lung, G.M. and Box, G.P. (1978) On a Measure of Lack of Fit in Time Series Models. Biometrika, 6, 66-72.
http://dx.doi.org/10.1093/biomet/65.2.297 - 12. Fisher, J. and Geltner, D. (2000) De-Lagging the NCREIF Index.
- 13. Embrechts, P., McNeil, A. and Straumann, D. (1999) Correlation and Dependence in Tisk Management: Properties and Pitfalls.
- 14. Bollerslev, T. (1986) Generalized Autoregressive Conditional Heteroscedasticity. Journal of Econometrics, 1, 307-327.
http://dx.doi.org/10.1016/0304-4076(86)90063-1 - 15. Azzalini, A. and Capitanio, A. (2003) Distributions Generated by Perturbation of Symmetry with Emphasis on a Multivariate Skew t Distribution. Journal of Royal Statistical Society, B65, 367-389.
http://dx.doi.org/10.1111/1467-9868.00391 - 16. Rockafellar, R. and Uryasev, S. (1999) Optimisation of Conditional Value at Risk.
- 17. Fishburn, P.C. (1977) Mean-Risk Analysis with Risk Associated with Below-Target Returns. American Economic Review, 57, 116-126.
- 18. Bawa, V.S. (1982) Stochastic Dominance: A Research Bibliography. Management Science, 28, 698-712.
http://dx.doi.org/10.1287/mnsc.28.6.698
NOTES

1The period after February 2009.