Open Journal of Statistics
Vol.05 No.01(2015), Article ID:54231,14 pages
10.4236/ojs.2015.51010
On the Maximum Likelihood and Least Squares Estimation for the Inverse Weibull Parameters with Progressively First-Failure Censoring
Amal Helu
Department of Mathematics, The University of Jordan, Amman, Jordan
Email: a.helu@ju.edu.jo
Copyright © 2015 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 5 February 2015; accepted 23 February 2015; published 26 February 2015
ABSTRACT
In this article, we consider a new life test scheme called a progressively first-failure censoring scheme introduced by Wu and Kus [1] . Based on this type of censoring, the maximum likelihood, approximate maximum likelihood and the least squares method estimators for the unknown parameters of the inverse Weibull distribution are derived. A comparison between these estimators is provided by using extensive simulation and two criteria, namely, absolute bias and mean squared error. It is concluded that the estimators based on the least squares method are superior compared to the maximum likelihood and the approximate maximum likelihood estimators. Real life data example is provided to illustrate our proposed estimators.
Keywords:
Inverse Weibull Distribution, Progressive First-Failure Censoring, Maximum Likelihood, Least Squares Method

1. Introduction
Let 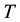 follow
follow  a two-parameter Weibull distribution
a two-parameter Weibull distribution 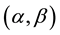 with the probability density function (pdf)
with the probability density function (pdf)

then 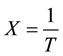 has an
has an 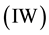 distribution with pdf
distribution with pdf
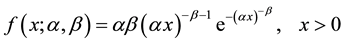 (1)
(1)
where  and
and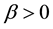 , are the scale and shape parameters, respectively.
, are the scale and shape parameters, respectively.
If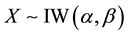 , then the cumulative distribution function (cdf) of
, then the cumulative distribution function (cdf) of 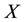 is given by:
is given by:
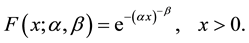 (2)
(2)
The IW distribution, also known as type 2 extreme value or the Frechet distribution (Johnson et al. [2] ), has a long right tail compared to other known distributions. The hazard function of the IW distribution is similar to that of the log-normal and inverse gaussian distributions (Murthy et al. [3] ). Carriere [4] used the IW dis- tribution to model the mortality curve of a population. Keller and Kamath [5] suggested that this distribution was suitable to model the failure of the degradation phenomena of mechanical components of diesel engines such as pistons, crankshafts, and main bearings. Furthermore, Erto [6] showed that the IW distribution provided a good fit to several data such as the time to breakdown of an insulating fluid subjected to the action of a constant tension (Nelson [7] ).
Several researches have been carried out on the IW distribution using classical and Bayesian approaches. For example, Calabria and Pulcini [8] obtained the maximum likelihood estimates (MLE) and least squares esti- mates of the parameters of the IW distribution. Calabria and Pulcini [9] considered the Bayesian approach to predict the ordered lifetimes in a future sample when those lifetimes are assumed to follow the IW distribution. Panaitescu et al. [10] developed the Bayesian and non-Bayesian analysis in the context of recording statistic values from a modified IW distribution. All these studies have been done based on a complete sample. However, there are many scenarios in life testing and reliability experiment when researchers can not obtain complete information on failure times for all the units in the experiment as in the case of accidental breakage of an experimental unit or if an individual under study drops out. Moreover, there are many situations in which the researcher intentionally removes units prior to their failure and this is due to the lack of funds and/or time constrains. Data obtained from such experiments are called censored data. Therefore, we consider estimation procedures based on censored samples.
The most common censoring schemes are type-I censoring in which the test ceases at a pre-fixed time, and type-II censoring that allows the experiment to be terminated at a predetermined number of failures. These methods do not allow the removal of active units during the experiment; therefore, the focus in the last few years has been on progressive censoring due to its flexibility that allows the experimenter to remove active units during the experiment. A progressively type-II censoring is a generalization of type-II censoring. Many authors have discussed inference under progressive censoring using various lifetime distributions, among others, Cohen [11] , Mann [12] , Wingo [13] , Balakrishnan and Sandhu [14] , Aggarwala and Balakrishnan [15] , Balakrishnan and Asgharzadeh [16] . For a comprehensive recent review of progressive censoring, readers are referred to Balakrishnan [17] .
Johnson [18] introduced the first-failure censoring plan where the experimenter could arrange 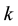 items into
items into 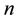 sets, then all the
sets, then all the 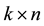 items were tested simultaneously until the first failure in each
items were tested simultaneously until the first failure in each 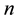 set occurred. However, in situations where the lifetime of a product is high and test facilities are limited but test material is cheap. Balasooriya [19] modified Johnson [18] approach by testing each set one after the other until the first failure in each set occurred. This modified approach can save time and money.
set occurred. However, in situations where the lifetime of a product is high and test facilities are limited but test material is cheap. Balasooriya [19] modified Johnson [18] approach by testing each set one after the other until the first failure in each set occurred. This modified approach can save time and money.
However, due to certain situations such as loss of contact with the individuals under study or loss of experi- ment units as mentioned above, it is desirable for researchers to be able to remove sets before the final termina- tion point. This situation leads to the area of progressive censoring.
Wu and Kus [1] wanted to improve the efficiency of the test by developing a new life test scheme, pro- gressively first-failure censoring scheme, by combining the concept of first failure censoring with the pro- gressive censoring. In this scheme sets with no failures can be removed from the test before the end of the experiment. Based on this scheme, Wu and Kus [1] derived the MLEs and constructed exact and approximate confidence intervals for the parameters of the Weibull distribution. Wu and Huang [20] developed the reliability sampling plans for the Weibull distribution. Soliman et al. ( [21] [22] ) derived Bayes and frequentist estimators for the parameters of Gompertz and Burr type XII distributions respectively. Hong et al. [23] used the same
scheme to construct MLE for the lifetime performance index CL based on progressively first-failure censoring from Weibull distribution. Ahmadi et al. [24] developed a confidence interval and ML estimator for CL based on the progressive first-failure censored sample under the Weibull distribution when the shape parameter was known.
In this study and based on m progressively first-failure censored sample from IW model, we consider the problem of estimating the parameters of the model using the maximum likelihood, the approximate maximum likelihood and the least square estimators (LSE). Balakrishnan et al. [25] conducted inference on progressive type-II censored data for extreme value distribution. They derived the MLE and approximate values for the maximum likelihood estimators (AMLE) using the Taylor expansion. They also concluded that the MLEs and AMLEs were almost identical in terms of bias and variance. Kim et al. [26] derived the maximum likelihood and the Bayes estimates for the three-parameter exponentiated Weibull distribution for type-II progressively censored sample. Gusmao et al. [27] studied the properties of a mixture of two generalized IW distribution and derived the maximum likelihood estimator of the parameters of this mixture based on censored data.
This article unfolds as follows: In Section 2 we describe the formulation of a progressive first-failure cen- soring scheme as described by Wu and Kus [1] . The MLEs, approximate MLEs, and LSE methods for estimat- ing the unknown parameters based on the progressive first-failure censoring scheme are derived in Section 3, 4 and 5 respectively. Simulation studies, results and conclusion are presented in Section 6. All methods that are discussed in this article are illustrated in Section 7 through a real life data set coming from highways pavement projects in Amman-Jordan during 2012.
2. A Progressive First-Failure Censoring Scheme
The progressive first-failure censoring can be described as follows: Given  and
and  non-
non-
negative integers such that . Let n independent groups with
. Let n independent groups with  items within each group be placed
items within each group be placed
on a life testing experiment and only  failures are completely observed. The censoring occurs progressively in
failures are completely observed. The censoring occurs progressively in  stages. At the time of the first failure
stages. At the time of the first failure ,
,  random groups and the group with the observed failure are randomly removed. Similarly, at the time of the second failure
random groups and the group with the observed failure are randomly removed. Similarly, at the time of the second failure ,
,  random groups and the group with the observed failure are randomly removed and so on. Finally, at the time of the
random groups and the group with the observed failure are randomly removed and so on. Finally, at the time of the  -th failure all the remaining active groups
-th failure all the remaining active groups  and the group with the observed failure are removed. Then
and the group with the observed failure are removed. Then  is the progressive first-failure censored order statistics.
is the progressive first-failure censored order statistics.
The main advantage of this scheme is that it reduces the time in which more items are used but only m out of  items are observed. Moreover, it includes as special cases, the progressively type-II scheme (when k = 1), first-failure scheme (when
items are observed. Moreover, it includes as special cases, the progressively type-II scheme (when k = 1), first-failure scheme (when ), conventional type II scheme (when k = 1 and
), conventional type II scheme (when k = 1 and  and the complete sample (when
and the complete sample (when  and
and ). Furthermore, the progressively first- failure censored sample
). Furthermore, the progressively first- failure censored sample  can be considered as a progressively type-II censored
can be considered as a progressively type-II censored
sample from a population with distribution function  (Wu and Kus [1] ) which enables us to
(Wu and Kus [1] ) which enables us to
extend all the results on progressively type-II censored order statistics to progressively first-failure censored order statistics.
3. Maximum Likelihood Estimation
Suppose that  independent units are placed on a test. The ordered
independent units are placed on a test. The ordered  failures are observed under the progressively first-failure.
failures are observed under the progressively first-failure.
Let  with
with  denote the progressively first-failure cen- sored ordered statistics with the progressive censoring scheme
denote the progressively first-failure cen- sored ordered statistics with the progressive censoring scheme  from a population with pdf and cdf given in Equations (1) and (2), respectively. For notation simplicity, we will write
from a population with pdf and cdf given in Equations (1) and (2), respectively. For notation simplicity, we will write  for
for . The likelihood func- tion based on progressively first-failure censored sample (see Wu and Kus [1] ) is given by:
. The likelihood func- tion based on progressively first-failure censored sample (see Wu and Kus [1] ) is given by:
 (3)
(3)
where,

In accordance with (1), (2) and (3), the log-likelihood function of  and
and  based on progressively first- failure censored sample
based on progressively first- failure censored sample  becomes
becomes
 (4)
(4)
The MLEs of the parameters  and
and  can be obtained by deriving (4) with respect to
can be obtained by deriving (4) with respect to  and
and  and equating the normal equations to 0 as follows:
and equating the normal equations to 0 as follows:
 (5)
(5)
 (6)
(6)
The MLEs are exist and unique (see Calabria and Pulcini [8] and Marusic et al. [28] ). Notice that there are no explicit solutions to (5) and (6). Hence, numerical methods are applied to solve the required equations. The maximum likelihood estimation method based on progressively censored data has been studied extensively, but traditionally, the Newton Raphson (NR) method was utilized to obtain the MLEs (Ng et al. [29] ). However, the MLEs via the NR method are very sensitive to their initial parameters estimation value. In this article we propose using the Expectation-Maximization (EM) algorithm for computing the MLEs.
4. Approximate Maximum Likelihood Estimation
Since the MLE does not provide explicit estimators for the shape and scale parameters of the IW distribution as mentioned before, we derive approximate MLE (AMLE) for the parameters  and
and .
.
Balakrishnan ( [30] - [34] ) and Balakrishnan and Vardan [35] developed the AMLE procedure. This procedure depends on the Taylor expansion of the likelihood function when the pdf under consideration belongs to the location-scale families. However, the IW distribution does not have the location-scale structure required for the AMLE procedure, but if we consider the transformation , then
, then  extreme value distribution and this distribution has this feature.
extreme value distribution and this distribution has this feature.
The  and
and  of
of  are given respectively by
are given respectively by
 (7)
(7)
and,
 (8)
(8)
where,  and
and  are the location and scale parameters respectively.
are the location and scale parameters respectively.
Hence, the AMLE procedure can be used to estimate the parameters  and
and  of the IW distribution.
of the IW distribution.
Let  with
with  denotes a progressively first-failure censored sample from (7) and (8). Then the joint pdf based on the censored sample is given by:
denotes a progressively first-failure censored sample from (7) and (8). Then the joint pdf based on the censored sample is given by:
 (9)
(9)
where,

If , then (9) can be written as
, then (9) can be written as
 (10)
(10)
with log-likelihood equation
 (11)
(11)
Taking derivatives with respect to  and
and  and equating them to zero, gives
and equating them to zero, gives
 (12)
(12)
 (13)
(13)
Because of the presence of the terms  and
and , Equations (12) and (13) do not have explicit solution. Hence, we consider a first-order Taylor approximation to
, Equations (12) and (13) do not have explicit solution. Hence, we consider a first-order Taylor approximation to  and
and  around
around
 (see Balakrishnan and Aggarwala [36] ; for reasoning).
(see Balakrishnan and Aggarwala [36] ; for reasoning).
From Balakrishnan and Aggarwala [36] , if 
 denote a progressively first-failure censored
denote a progressively first-failure censored
sample from Uniform  with censoring scheme
with censoring scheme , then
, then ,
,  are statistically independent random variables from Beta
are statistically independent random variables from Beta  with
with
 (14)
(14)
and,
 (15)
(15)
The approximation is around  upon expanding
upon expanding  and
and  around the point
around the point  and keeping only the first two terms, we get
and keeping only the first two terms, we get
 (16)
(16)
where,

and,
 (17)
(17)
where,

Plugging (16) and (17) in (12) and (13) we get
 (18)
(18)
and,
 (19)
(19)
where, . Equations (18) and (19) can be rewritten as
. Equations (18) and (19) can be rewritten as
 (20)
(20)
 (21)
(21)
where,

The solutions to (20) and (21) yield the AMLEs
 (22)
(22)
One of the drawbacks of the AMLEs is that they are biased. Moreover, the exact bias of  and
and  can not be theoretically computed because of the intractability encountered of
can not be theoretically computed because of the intractability encountered of . On the other hand, the AMLEs provide an excellent starting value for the iterative solution of the likelihood equations.
. On the other hand, the AMLEs provide an excellent starting value for the iterative solution of the likelihood equations.
5. Least Squares Estimation Method
The LS method which is originally suggested by Swain et al. [37] is computationally easier to handle, it provides simple closed form solutions for estimates (Hossain and Zimmer [38] ). In addition it can also be used quite effectively to estimate the shape and scale parameters of the IW distribution. Finally Marusic et al. [28] showed that the least squares estimators (LSE) for estimating the parameters of the IW distribution did exist.
In this section we will discuss the least squares method for estimating  and
and  using the set up in Section 1; that is,
using the set up in Section 1; that is,  are progressively first-failure censored sample from the IW distribution with censoring scheme
are progressively first-failure censored sample from the IW distribution with censoring scheme . The LS method is a combination of parametric
. The LS method is a combination of parametric  and non-parametric
and non-parametric  distribution functions. It depends on the choice of
distribution functions. It depends on the choice of  which should be as effective as possible. In our study we use
which should be as effective as possible. In our study we use  which is proposed by Montanari and Cacciari [39] as a non-parametric
which is proposed by Montanari and Cacciari [39] as a non-parametric  for progressive type-II censored sample.
for progressive type-II censored sample.
 (23)
(23)
where,

and,

For the parametric cdf , Balakrishnan and Aggarwala [36] and Kim and Han [40] , proposed
, Balakrishnan and Aggarwala [36] and Kim and Han [40] , proposed
 (24)
(24)
where,

The procedure attempts to minimize the following function with respect to  and
and 
 (25)
(25)
The LSE estimates of  and
and  are denoted by
are denoted by  and
and  respectively.
respectively.
6. Simulation Study
The purpose of the simulation study is to compare the performance of the MLE, AMLE and LSE estimates based on progressively first-failure censored samples generated from the IW distribution with 
 ,
,  ,
,  ,
,  ,
,  ,
,  , using different combinations of
, using different combinations of  and different censoring schemes
and different censoring schemes . The data are simulated using Balakrishnan and Aggarwala [36] algorithm based on the fact that progressively first-failure censored sample with distribution
. The data are simulated using Balakrishnan and Aggarwala [36] algorithm based on the fact that progressively first-failure censored sample with distribution  can be
can be
viewed as a progressively type II censored sample from a population with distribution function .
.
We obtain the MLEs of  and
and  by solving the nonlinear Equations (5) and (6), in which the AMLEs are used as starting values of the MLE iterations. The AMLE and LSE are computed using (22) and (25) respec- tively. The criteria used for comparing all the above estimates are the absolute bias (ABias) and the mean squared error (MSE). Suppose
by solving the nonlinear Equations (5) and (6), in which the AMLEs are used as starting values of the MLE iterations. The AMLE and LSE are computed using (22) and (25) respec- tively. The criteria used for comparing all the above estimates are the absolute bias (ABias) and the mean squared error (MSE). Suppose 
 is the estimate of
is the estimate of 
 for the i-th simulated data set, then the ABias and MSE are computed as follows:
for the i-th simulated data set, then the ABias and MSE are computed as follows:
1) .
.
2) .
.
6.1. Data Analysis and Comparison Study
Due to the large number of tables, only part of them is reported. Results are summarized in Tables 1-4 provided at the end of this section as follows:
・ Table 1 and Table 2 provide the ABias and MSE values for the estimates of .
.
・ Table 3 and Table 4 provide the ABias and MSE values for the estimates of .
.
Throughout this section we will refer to  by
by ,
,  by
by 
(where ),
),  by
by ,
,  by
by ,
,
 by
by , and finally
, and finally  by
by . Moreover, we will refer to schemes
. Moreover, we will refer to schemes ,
,  , and
, and  by group-1, similarly we will refer to the schemes
by group-1, similarly we will refer to the schemes ,
,  , and
, and  by group-2. A summary of the results is provided below.
by group-2. A summary of the results is provided below.

Table 1. Bias and MSE (parentheses) of  when
when
Table 2. Bias and MSE (parentheses) of  when
when
Table 3. Bias and MSE (parentheses) of  when
when .
.
Table 4. Bias and MSE (parentheses) of  when
when .
.
6.1.1. Scale Parameter 
・ For progressively first-failure censoring  we can easily notice that
we can easily notice that  is the most efficient
is the most efficient
scheme in terms of ABias and MSE values for MLE and AMLE, while scheme  is the most efficient
is the most efficient
scheme for LSE. On the other hand when , that is the progressively type-II censoring, scheme
, that is the progressively type-II censoring, scheme  is the most efficient for all estimates namely MLE, AMLE and LSE.
is the most efficient for all estimates namely MLE, AMLE and LSE.
・ Notice that when  is small
is small , the MSE values are almost identical for all the estimates regardless of the different schemes and the different values of
, the MSE values are almost identical for all the estimates regardless of the different schemes and the different values of , this indicates that the estimates of
, this indicates that the estimates of  are sensitive to the choice of
are sensitive to the choice of .
.
・ In general, LSE and MLE have comparable ABias and MSE values, which makes LSE estimates very good competitors to the MLE estimates.
6.1.2. Shape Parameter 
・ When  scheme
scheme  is the most efficient scheme in terms of ABias and MSE values for MLE and LSE.
is the most efficient scheme in terms of ABias and MSE values for MLE and LSE.
・ For progressively type-II censoring  scheme
scheme  is the most efficient in terms of ABias and MSE values for MLE while scheme
is the most efficient in terms of ABias and MSE values for MLE while scheme  is the most efficient for LSE.
is the most efficient for LSE.
・ As for the AMLE estimates, we notice that the scheme  is the most efficient in terms of ABias whereas
is the most efficient in terms of ABias whereas
scheme  is the most efficient in terms of MSE values for all values of
is the most efficient in terms of MSE values for all values of .
.
・ In addition,  generally has the smallest ABias while
generally has the smallest ABias while  has the smallest MSE values.
has the smallest MSE values.
6.2. Conclusions and Recommendations
In the past few years, progressive censoring has received a great attention by many researchers. This is due to its advantages in reducing the cost and time of the tests. Moreover, the availability of high speed computing re- sources enhances the focus on progressive censoring. In this article, we have considered the MLE, approximate MLE and LSE to estimate the unknown parameters of the IW distribution when data under consideration are progressively first-failure censoring.
It is out of question that all estimates are affected by the choice of , and our goal is to compare the three methods namely MLE, AMLE and LSE and decide which is the most efficient for estimating
, and our goal is to compare the three methods namely MLE, AMLE and LSE and decide which is the most efficient for estimating  and
and . It is important to point out the following:
. It is important to point out the following:
・ The results for group-1 and group-2 are very similar with slight edge improvement in favor of group-1.
・ ABias and MSE values decrease as the effective sample proportion  increases for fixed
increases for fixed  and for all estimates of
and for all estimates of  and
and .
.
・ In general, progressively first-failure censoring (i.e. ) is more efficient compared to progressive type-II censoring
) is more efficient compared to progressive type-II censoring  in terms of ABias and MSE values. This is true for MLE and LSE estimates.
in terms of ABias and MSE values. This is true for MLE and LSE estimates.
・ Table 1 and Table 2 clearly show that the MSE values for LSE and MLE are almost identical and their ABias is comparable. Moreover, Table 3 and Table 4 show the similarity in performance between LSE and MLE for estimating . Keep in mind that LSE formula is simple and easy to implement compared to the formula of the MLE.
. Keep in mind that LSE formula is simple and easy to implement compared to the formula of the MLE.
Based on this, we highly recommend using LSE method and progressively first-failure censoring scheme for estimating the parameters of the IW distribution.
7. Real Life Data
In this example, we consider a real life data set to illustrate the proposed method and verify how our estimators work in practice. The validity of the IW model is checked using Kolmogrov-Smirnov  test, as well as Anderson-Darling
test, as well as Anderson-Darling  and chi-square tests. The data set for this application came from a real highway construction project in Amman/Jordan supervised by the Greater Amman Municipality and executed by a local contractor in 2012 (http://www.ammancity.gov.jo/en/gam/index.asp). The data consist of 64 readings that de- monstrate the percentage of asphalt content in hot mix asphalt specimens sampled from the mentioned project above. Percentage of asphalt content is one of the main elements of a hot mix asphalt sample characteristics that has a direct effect on the quality and durability of the pavement. That is why this data is used in this example.
and chi-square tests. The data set for this application came from a real highway construction project in Amman/Jordan supervised by the Greater Amman Municipality and executed by a local contractor in 2012 (http://www.ammancity.gov.jo/en/gam/index.asp). The data consist of 64 readings that de- monstrate the percentage of asphalt content in hot mix asphalt specimens sampled from the mentioned project above. Percentage of asphalt content is one of the main elements of a hot mix asphalt sample characteristics that has a direct effect on the quality and durability of the pavement. That is why this data is used in this example.
We fit the IW distribution based on  and
and . We observe that
. We observe that  with
with ,
,  and chi-square distance = 0.6468 with a corresponding
and chi-square distance = 0.6468 with a corresponding . This indicates that the IW model provides a good fit. The initial estimates for the MLEs are chosen by using pseudo complete estimates of the MLEs. We group the data into 32 sets with 2 items in each. We modify the data to consider four types of censoring as follows:
. This indicates that the IW model provides a good fit. The initial estimates for the MLEs are chosen by using pseudo complete estimates of the MLEs. We group the data into 32 sets with 2 items in each. We modify the data to consider four types of censoring as follows:
The modified data sets are provided in Table 5. The evaluated Hessian matrix to guarantee the uniqueness of the MLEs is presented in Table 6. Finally, the estimates of  and
and  based on different estimation methods are provided in Table 7.
based on different estimation methods are provided in Table 7.
Table 5. Progressive first-failure censored samples for the percentage of asphalt content in hot mix samples.
Table 6. The eigne-values and the determinant of the Hessian matrix for each of the four data sets.
Table 7. The corresponding estimates.
It is quite clear that all the estimates for the scale parameter  are quite close to each other. It is of great importance to notice through this analysis that the estimates based on progressively first-failure are comparable with the values of the estimates based on progressively type-II censored samples and they are very close to those of the complete data set. Although
are quite close to each other. It is of great importance to notice through this analysis that the estimates based on progressively first-failure are comparable with the values of the estimates based on progressively type-II censored samples and they are very close to those of the complete data set. Although  is higher than
is higher than  and
and , it is however comparable with its value when data is complete. Moreover, in this case
, it is however comparable with its value when data is complete. Moreover, in this case  is the closest to the complete case.
is the closest to the complete case.
Cite this paper
AmalHelu, (2015) On the Maximum Likelihood and Least Squares Estimation for the Inverse Weibull Parameters with Progressively First-Failure Censoring. Open Journal of Statistics,05,75-89. doi: 10.4236/ojs.2015.51010
References
- 1. Wu, S. and Kus, C. (2009) On Estimation Based on Progressive First-Failure Censored Sampling. Computational Statistics and Data Analysis, 53, 3659-3670.
http://dx.doi.org/10.1016/j.csda.2009.03.010 - 2. Johnson, N., Kotz, S. and Balakrishnan, N. (1994) Continuous Univariate Distribution. Vol. 1, John Wiley and Sons, New York.
- 3. Murthy, D.N.P., Bulmer, M. and Eccleston, J.A. (2004) Weibul Model Selection for Reliability Modeling. Reliability Engineering & System Safety, 86, 257-267.
http://dx.doi.org/10.1016/j.ress.2004.01.014 - 4. Carriere, J. (1992) Parametric Models for Life Tables. Transactions of Society of Actuaries, 44, 77-100.
- 5. Keller, A.Z. and Kamath, A.R.R. (1982) Alternative Reliability Models for Mechanical Systems. Proceeding of the 3rd International Conference on Reliability and Maintainability, 411-415.
- 6. Erto, P. (1986) Properties and Identification of the Inverse Weibull: Unknown or Just Forgotten. Quality and Reliability Engineering International, 9, 383-385.
- 7. Nelson, W. (1982) Applied Life Data Analysis. Wiley, New York.
http://dx.doi.org/10.1002/0471725234 - 8. Calabria, R. and Pulcini, G. (1990) On the Maximum Likelihood and Least Squares Estimation in the Inverse Weibull Distribution. Statistics Applicata, 2, 53-66.
- 9. Calabria, R. and Pulcini, G. (1994) Bayes 2-Sample Prediction for the Inverse Weibull Distribution. Communications in Statistics—Theory & Methods, 23, 1811-1824.
http://dx.doi.org/10.1080/03610929408831356 - 10. Panaitescu, E., Popescu, P.G., Cozma, P. and Popa, M. (2010) Bayesian and Non-Bayesian Estimators Using Record Statistics of the Modified-Inverse Weibull Distribution. Proceedings of the Romanian Academy, Series A, 11, 224-231.
- 11. Cohen, A.C. (1963) Progressively Censored Samples in Life Testing. Technometrics, 5, 327-339.
http://dx.doi.org/10.1080/00401706.1963.10490102 - 12. Mann, N.R. (1971) Best Linear Invariant Estimation for Weibull Parameters under Progressive Censoring. Technometrics, 13, 521-533.
http://dx.doi.org/10.1080/00401706.1971.10488815 - 13. Wingo, D.R. (1993) Maximum Likelihood Estimation of Burr XII Distribution Parameters under Type II Censoring. Microelectronics Reliability, 33, 1251-1257.
http://dx.doi.org/10.1016/0026-2714(93)90126-J - 14. Balakrishnan, N. and Sandhu, A. (1995) A Simple Simulational Algorithm for Generating Progressive Type-II Censored Samples. American Statistician, 49, 229-230.
- 15. Aggarwala, R. and Balakrishnan, N. (1999) Maximum Likelihood Estimation of the Laplace Parameters Based on Progressive Type-II Censored Samples. In: Balakrishnan, N., Ed., Advances in Methods and Applications of Probability and Statistics, Gordan and Breach Publisher, Newark.
- 16. Balakrishnan, N. and Asgharzadeh, A. (2005) Inference for the Scaled Half-Logistic Distribution Based on Progressively Type II Censored Samples. Communications in Statistics—Theory and Methods, 34, 73-87.
http://dx.doi.org/10.1081/STA-200045814 - 17. Balakrishnan, N. (2007) Progressive Censoring Methodology: An Appraisal (with Discussion). TEST, 16, 211-259.
http://dx.doi.org/10.1007/s11749-007-0061-y - 18. Johnson, N. (1964) Theory and Technique of Variation Research. Elsevier, Amsterdam.
- 19. Balasooriya, U. (1995) Failure-Censored Reliability Sampling Plans for the Exponential Distribution. Journal of Statistical Computation and Simulation, 52, 337-349.
http://dx.doi.org/10.1080/00949659508811684 - 20. Wu, S. and Huang, S. (2012) Progressively First-Failure Censored Reliability Sampling Plans with Cost Constraint. Computational Statistics & Data Analysis, 56, 2018-2030.
http://dx.doi.org/10.1016/j.csda.2011.12.008 - 21. Soliman, A., Abd-Ellah, A., Abou-Elheggag, N. and Abd-Elmougod, G. (2012) Estimation of the Parameters of Life for Gompertz Distribution Using Progressive First-Failure Censored Data. Computational Statistics & Data Analysis, 56, 2471-2485.
http://dx.doi.org/10.1016/j.csda.2012.01.025 - 22. Soliman, A., Abd-Ellah, A., Abou-Elheggag, N. and Modhesh, A. (2012) Estimation from Burr Type XII Distribution Using Progressive First-Failure Censored Data. Journal of Statistical Computation and Simulation, 73, 887-898.
- 23. Hong, C., Lee, W. and Wu, J. (2012) Computational Procedure of Performance Assessment of Lifetime Index of Products for the Weibull Distribution with the Progressive First-Failure Censored Sampling Plan. Journal of Applied Mathematics, 2012, Article ID: 717184.
- 24. Ahmadi, M.V., Doostparast, M. and Ahmadi, J. (2013) Estimating the Lifetime Performance Index with Weibull Distribution Based on Progressively First-Failure Censoring Scheme. Journal of Computational and Applied Mathematics, 239, 93-102.
http://dx.doi.org/10.1016/j.cam.2012.09.006 - 25. Balakrishnan, N., Kannan, N., Lin, C.T. and Ng, H.K.T. (2003) Point and Interval Estimation for Gaussian Distribution Based on Progressively Type-II Censored Samples. IEEE Transactions on Reliability, 52, 90-95.
http://dx.doi.org/10.1109/TR.2002.805786 - 26. Kim, C., Jung, J. and Chung, Y. (2009) Bayesian Estimation for the Exponentiated Weibull Model under Type II Progressive Censoring. Statistical Papers, 51, 375-387.
- 27. Gusmao, F.R.S., Ortega, E.M.M. and Cordeiro, G.M. (2009) The Generalized Inverse Weibull Distribution. Statistical Papers, 52, 271-273.
- 28. Marusic, M., Markovic, D. and Jukic, D. (2010) Least Squares Fitting the Three-Parameter Inverse Weibull Density. Mathematical Communications, 15, 539-553.
- 29. Ng, H.K.T., Chan, P.S. and Balakrishnan, N. (2002) Estimation of Parameters from Progressively Censored Data Using EM Algorithm. Computational Statistics & Data Analysis, 39, 371-386.
http://dx.doi.org/10.1016/S0167-9473(01)00091-3 - 30. Balakrishnan, N. (1989) Approximate MLE of the Scale Parameter of the Rayleigh Distribution with Censoring. IEEE Transactions on Reliability, 38, 355-357.
http://dx.doi.org/10.1109/24.44181 - 31. Balakrishnan, N. (1989) Approximate Maximum Likelihood Estimation of the Mean and Standard Deviation of the Normal Distribution Based on Type-II Censored Samples. Journal of Statistical Computation and Simulation, 32, 137-148.
http://dx.doi.org/10.1080/00949658908811170 - 32. Balakrishnan, N. (1990) Maximum Likelihood Estimation Based on Complete and Type-II Censored Samples in the Logistic Distribution. Marcel Dekker, New York.
- 33. Balakrishnan, N. (1990) Approximate Maximum Likelihood Estimation for a Generalized Logistic Distribution. Journal of Statistical Planning and Inference, 26, 221-236.
http://dx.doi.org/10.1016/0378-3758(90)90127-G - 34. Balakrishnan, N. (1990) On the Maximum Likelihood Estimation of the Location and Scale Parameters of Exponential Distribution Based on Multiply Type-II Censored Samples. Journal of Applied Statistics, 17, 55-61.
http://dx.doi.org/10.1080/757582647 - 35. Balakrishnan, N. and Varden, J. (1991) Approximate MLEs for the Location and Scale Parameters of the Extreme Value Distribution with Censoring. IEEE Transactions on Reliability, 40, 146-151.
http://dx.doi.org/10.1109/24.87115 - 36. Balakrishnan, N. and Aggarwala, R. (2000) Progressive Censoring: Theory, Methods and Applications. Birkh?user, Boston.
http://dx.doi.org/10.1007/978-1-4612-1334-5� - 37. Swain, J., Venkatraman, S. and Wilson, J. (1988) Least Squares Estimation of Distribution Functions in Johnson’s Translation System. Journal of Statistical Computation and Simulation, 29, 271-297.
http://dx.doi.org/10.1080/00949658808811068 - 38. Hossain, A. and Zimmer, W. (2003) Comparison of Estimation Methods for the Weibull Parameters: Complete and Censored Samples. Journal of Statistical Computation and Simulation, 73, 145-153.
http://dx.doi.org/10.1080/00949650215730 - 39. Montanari, G.C. and Cacciari, M. (1988) Progressively Censored Aging Tests on XLPE-Insulated Cable Models. IEEE Transactions on Electrical Insulation, 23, 365-372.
http://dx.doi.org/10.1109/14.2376 - 40. Kim, C. and Han, K. (2010) Estimation of the Scale Parameter of the Half-Logistic Distribution under Progressively Type-II Censored Sample. Statistical Papers, 51, 375-387.
http://dx.doi.org/10.1007/s00362-009-0197-9