Open Journal of Statistics
Vol.06 No.03(2016), Article ID:67590,13 pages
10.4236/ojs.2016.63042
Transition Logic Regression Method to Identify Interactions in Binary Longitudinal Data
Parvin Sarbakhsh1, Yadollah Mehrabi2*, Jeanine J. Houwing-Duistermaat3, Farid Zayeri4, Maryam Sadat Daneshpour5
1Department of Statistics and Epidemiology, School of Public Health, Tabriz University of Medical Sciences, Tabriz, Iran
2Department of Epidemiology, School of Public Health, Shahid Beheshti University of Medical Sciences, Tehran, Iran
3Department of Medical Statistics and Bioinformatics, Leiden University Medical Centre, Leiden, Netherlands
4Department of Biostatistics, School of Paramedicine, Shahid Beheshti University of Medical Sciences, Tehran, Iran
5Cellular and Molecular Endocrine Research Center, Research Institute for Endocrine Sciences, Shahid Beheshti University of Medical Sciences, Tehran, Iran

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 20 October 2015; accepted 19 June 2016; published 22 June 2016
ABSTRACT
Logic regression is an adaptive regression method which searches for Boolean (logic) combinations of binary variables that best explain the variability in the outcome, and thus, it reveals interaction effects which are associated with the response. In this study, we extended logic regression to longitudinal data with binary response and proposed “Transition Logic Regression Method” to find interactions related to response. In this method, interaction effects over time were found by Annealing Algorithm with AIC (Akaike Information Criterion) as the score function of the model. Also, first and second orders Markov dependence were allowed to capture the correlation among successive observations of the same individual in longitudinal binary response. Performance of the method was evaluated with simulation study in various conditions. Proposed method was used to find interactions of SNPs and other risk factors related to low HDL over time in data of 329 participants of longitudinal TLGS study.
Keywords:
Logic Regression, Longitudinal Data, Transition Model, Interaction, TLGS Study, Low HDL, SNP

1. Introduction
Regression analysis is an important tool in evaluating the functional relationship between dependent variable, and a set of independent variables. On most issues, regression models can only relate the main effects of predictor variables to the response variable and evaluation of interaction effects cannot be exceeded of two-way or at most three-way, due to complexity of such interactions.
In order to consider such interactions in the regression models, some combinations of explanatory variables can be constructed and these combinations can be used as new predictors instead of using individual variables.
“Logic Regression” is a type of generalized regression and classification method based on logic combinations of binary variables which can make Boolean combinations of original binary explanatory variables in order to reveal interactions [1] . Logic regression is different from logistic regression with “logit” link function that is a member of generalized linear model family for modeling response variables with binomial distribution. Although we can evaluate interactions using logistic regression, these interactions need to be known in advance, and used as input variables in the model. By contrast, Logic Regression is applicable for any type of response, as long as the predictors are binary. Interactions of interest need not be known in advance, quite the contrary, the detection of important variable interactions is the main aim of logic regression [2] . Logic regression is introduced and used for case control or cohort studies with independent observations [2] .
Furthermore, some extensions have been performed to this model in several ways. Namely, Multinomial Logic Regression has been developed for multinomial categorical responses [2] . Trio Logic Regression with conditional Logic Regression model has been proposed to analyze data of case parents trios [3] . Monte Carlo Logic Regression has been developed to generate a list of predictors related to the response [4] . Logic FS has been introduced and used to identify different Logic Regressions associated with response [5] . Genetic programming for association studies [6] has been proposed for classification settings, and uses genetic programming as search algorithm.
On the other hands, a longitudinal study is defined as an investigation where subject’s responses are recorded at multiple follow-up times. A longitudinal study yields “repeated measurements” on each subject. In compare to cross sectional studies, longitudinal studies have some benefits such as measurement of individual change in outcomes, separation of time effects, and control for cohort effects [7] .
Like other kind of regression models, interactions among predictors are important in modelling of longitudinal data. In addition, one of the goals of longitudinal studies is to examine whether the relationship between the response and the predictors changes over time. In other words, if there is any interaction between variables and time or not. It seems that logic regression theory can be used to assess interactions in modeling of longitudinal data. To find such time dependent interactions in quantitative longitudinal response, recently, “logic mixed model”, based on linear mixed model, has been proposed and used to assess the interactions of SNP associated with longitudinal quantitative cholesterol level [8] , but Logic Regression has not been developed for analysis of correlated binary observations of longitudinal studies up to now.
So, due to the importance of the interactions related to such responses, in this paper we proposed “Transition Logic Regression” model as an extension of logic regression to detect and assess higher order interactions over time in longitudinal data with binary response. Furthermore, we carried out a simulation study to evaluate the performance of our model in different settings and compare it with standard model. In addition, as an application, we assessed effects of some SNPs and other risk factors on having low level of HDL over time using our proposed Transition Logic Regression model.
The present paper was initially motivated by the SNP dataset with potential important interactions among SNPs related to binary longitudinal response.
2. Method
2.1. Logic Regression
Logic Regression is a generalized regression and classification method that enables identification of interactions by using Boolean combinations as new independent variables of the original binary variables. We try to find Boolean statements involving the binary predictors that enhance the prediction for the response. These Boolean combinations are logic expressions such as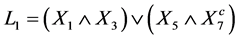 . It means that if the response is binary as well (which is not required in general), we attempt to find decision rules such as “if
. It means that if the response is binary as well (which is not required in general), we attempt to find decision rules such as “if 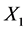 and
and 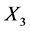 are true”, or “
are true”, or “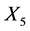 but not
but not 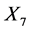 are true”, then the response is more likely to be in class 0.
are true”, then the response is more likely to be in class 0.
Let 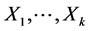 be binary predictors, Y be a response variable and
be binary predictors, Y be a response variable and 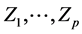 be quantitative covariates,
be quantitative covariates,
Logic Regression models are of the form: 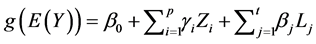
where g is a link function for response and 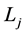 is a Boolean combination of the binary predictors
is a Boolean combination of the binary predictors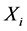 .
.
Logic regression is an adaptive algorithm which for a given model selects those 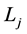 that minimize the score function of the model. Logic Regression framework includes many forms of regression (such as linear and logistic regression, Cox proportional hazards model). For every model type a score function is defined indicating the “quality” of the model. In general, any type of model can be considered, as long as a scoring function (such as a deviance or likelihood) is defined [2] .
that minimize the score function of the model. Logic Regression framework includes many forms of regression (such as linear and logistic regression, Cox proportional hazards model). For every model type a score function is defined indicating the “quality” of the model. In general, any type of model can be considered, as long as a scoring function (such as a deviance or likelihood) is defined [2] .
2.2. Simulated Annealing for Logic Regression
The number of logic expressions that can be built from a given set of binary predictors is huge, and there is no straight method to enlist all logic terms that yield different score. So, it is infeasible to do an exhaustive assessment of all different logic terms and select the best model. In order to solve this problem in Logic Regression, a simulated annealing as a stochastic search algorithm is used to search for the best logic combinations and estimate the 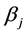 [1] .
[1] .
There are some permissible moves in logic regression theory such as alternating a predictor, alternating an operator, deleting a predictor and so on, which called permissible moves. These moves are used in Annealing algorithm to generate new logic expressions in the search for the best logic regression model according to a score function. For more information about permissible moves see [1] . In each iteration of the simulated annealing algorithm, a new logic term is proposed by randomly executing a move from the set of permissible move and so related new Logic Regression model is fitted. The acceptance probability for the new logic term is based on the score function of the new and current models, and a simulated annealing parameter called temperature [2] .
2.3. Transition Model: Marginal Modelling of Binary Longitudinal Data Using Markov Chains
In order to extend Logic Regression to longitudinal study, we considered one kind of transition model for binary longitudinal data introduced by Gonçalves [9] . This model is a marginal modelling of binary longitudinal data using Markov chains. Below this model is briefly described.
For notation, 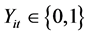 is binary response variables of individual i (
is binary response variables of individual i (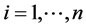 ) at time t
) at time t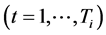 , with mean
, with mean . For each subject at each time, let
. For each subject at each time, let  be a set of p covariates that first column of its can be a vector of ones to consider intercept term. Logistic regression model that marginally connects the probability distribution of the response and auxiliary variables is:
be a set of p covariates that first column of its can be a vector of ones to consider intercept term. Logistic regression model that marginally connects the probability distribution of the response and auxiliary variables is:

where β is a p vector of unknown parameters. To take into account the correlation among successive observations of the same individual, the model considers a Markovian type of first order ( ) or of second order (
) or of second order ( ) dependence structure. For the sake of simplicity, the subject subscript i was ignored, since individuals are assumed to be independent from each other. In the first order binary Markov chain model, the joint distribution
) dependence structure. For the sake of simplicity, the subject subscript i was ignored, since individuals are assumed to be independent from each other. In the first order binary Markov chain model, the joint distribution  are determined by the distribution of
are determined by the distribution of  and a set of conditional probabilities:
and a set of conditional probabilities:

For a pair of successive observations  with known marginal distribution of
with known marginal distribution of ,
,  is chosen so that
is chosen so that  is already assigned.
is already assigned.
In order to analyze the binary data, the quantity odds ratio is the preferred measure of dependence between observations:

After solving following equations with respect to p0 and p1:

It yields:

where .
.
If , the variables are independent and
, the variables are independent and . Similarly, in the second order binary Markov chain model, for
. Similarly, in the second order binary Markov chain model, for  transition probabilities are:
transition probabilities are:

First and second order dependence are:
 (1)
(1)
 (2)
(2)
 can be calculated using these equations:
can be calculated using these equations:





Likelihood inference is performed based on sample of n subjects who are assumed to be independent from each other. If  is observation of subject i (
is observation of subject i ( ) at time t (
) at time t ( ), the contribution of subject i with all observations
), the contribution of subject i with all observations . to the log likelihood function for the parameters (β, λ) is:
. to the log likelihood function for the parameters (β, λ) is:

where .
.
Clearly, the likelihood function for the entire sample is obtained by calculating the sum of the likelihood of all
subjects [9] : .
.
AIC statistic for the model is calculated as:
 (3)
(3)
where q equals the number of parameters in the model.
2.4. Our Proposed Method: Transition Logic Regression
In this paper, mentioned first and second order Markov chain transition model with AIC (Equation (3)) as a score function of the model, was used to develop Logic Regression to longitudinal data. Therefore, “Transition Logic Regression” was defined as:  which
which  is binary response variables of individual i (
is binary response variables of individual i ( ) at time t
) at time t , with mean
, with mean  and
and  is vector of quantitative covariates and
is vector of quantitative covariates and  is vector of Boolean expression from binary predictors
is vector of Boolean expression from binary predictors .
.  are vectors of unknown parameters. To take into account the correlation among successive observations of the same individual, the model considers a Markovian type of first order (
are vectors of unknown parameters. To take into account the correlation among successive observations of the same individual, the model considers a Markovian type of first order ( ) or of second order (
) or of second order ( ) dependence structure (Equations (1) and (2)).
) dependence structure (Equations (1) and (2)).
Searching to find best  so that the fitted model has low AIC, was done using Annealing algorithm. Therefore, Annealing algorithm searched for Boolean combinations which according to the AIC statistic had the lowest score and therefore had the best fitting in Transition Logic Regression model. This extension allows for the fit of a Transition Logic Regression model. The program of Transition Logic Regression was written in FORTRAN 77 and added to “LogicReg” package [1] . Modified “LogicReg” package was recompiled an installed in R(2.15.3) to analyze data.
so that the fitted model has low AIC, was done using Annealing algorithm. Therefore, Annealing algorithm searched for Boolean combinations which according to the AIC statistic had the lowest score and therefore had the best fitting in Transition Logic Regression model. This extension allows for the fit of a Transition Logic Regression model. The program of Transition Logic Regression was written in FORTRAN 77 and added to “LogicReg” package [1] . Modified “LogicReg” package was recompiled an installed in R(2.15.3) to analyze data.
3. Simulation Study
Simulation study was done to assess the performance of proposed model and to compare it with the standard model. Data was produced from binomial distribution with first order Markov chain dependence structure for three time points.
Given specific sample size, for each sample in time t, ten covariates were simulated from Bernoulli (5):

The simulated model assumed  as the interaction effect between predictors at time t. For each sample in each time t, three repeated measurements were constructed as the response variable
as the interaction effect between predictors at time t. For each sample in each time t, three repeated measurements were constructed as the response variable  each with a predetermined probability of success
each with a predetermined probability of success  related to the interaction
related to the interaction  via logit link function:
via logit link function:


Starting with the first response,  was produced from Bernoulli distribution with mean
was produced from Bernoulli distribution with mean  Transition probabilities are:
Transition probabilities are:


Respect to our desired values of  and
and , these first order transition probabilities were calculated. So, if
, these first order transition probabilities were calculated. So, if  equals to one,
equals to one,  produced from Bernoulli distributed with probability of
produced from Bernoulli distributed with probability of  else if
else if  equals to zero,
equals to zero,  was simulated from Bernoulli distributed with mean
was simulated from Bernoulli distributed with mean .
.
In order to produce  under desired consideration, we calculated following transition probabilities:
under desired consideration, we calculated following transition probabilities:
 under desired consideration, we calculated below transition probabilities:
under desired consideration, we calculated below transition probabilities:


To simulate , if y2 equals to one,
, if y2 equals to one,  is simulated from Bernoulli distributed with probability
is simulated from Bernoulli distributed with probability  and if
and if  equals to zero,
equals to zero,  is produced from Bernoulli distribution with mean
is produced from Bernoulli distribution with mean .
.

Simulation study was done for various sample sizes (number of cases: 50, 200, 500, 1000), first order Markov chain dependences , and coefficients of the interaction term
, and coefficients of the interaction term .
.
With respect to simulated interaction term, we considered all covariates as the search space and one combination with two variables as the model size in annealing algorithm setting. For this simulation study, 500 datasets were generated for each condition.
Percentage of identification of exact simulated interaction was considered as quality of performance of the Transition Logic Regression model. Also, AIC of Transition Logic Regression was compared with AIC of Transition model as the standard model which only includes all ten covariates as the main effects in the model.
In addition, MSE and 95% empirical confidence interval of estimators in models that could identify interaction truly were calculated. Lower bound of empirical confidence intervals is 0.025th quantile and upper bound is 0.975th quantile of estimated values of parameters.
The results of simulation study are shown in Tables 1-4. According to these tables, as expected with increasing sample size and coefficient of interaction term, the rate of identification of true interaction increases. For example, in  and
and  method was able to find true interaction term in all 500 data sets. The value of the first order dependence did not have considerable effect on the performance of the method.
method was able to find true interaction term in all 500 data sets. The value of the first order dependence did not have considerable effect on the performance of the method.
The same holds, MSE and confidence intervals of estimations get better with increasing of sample size. In small sample sizes, amount of coefficient of interaction and first order dependence have effect on MSE of  so that in strong interaction effect or strong first order dependence, MSE of
so that in strong interaction effect or strong first order dependence, MSE of  is large.
is large.
Maximum type I error was 0.01 that method had found  as interaction effect when there was not such interaction in data
as interaction effect when there was not such interaction in data .
.
4. Application of Proposed Model on TLGS Data
Interactions usually play an important role in SNP (Single-nucleotide polymorphism) association studies. High order interactions of SNPs are supposed to explain the differences between low- and high-risk groups [10] . In addition to the main effects of SNPs, their interactions are assumed to be responsible for low HDL. SNPs interactions can be time-dependent. So, our aim of this study was investigation SNPs interactions related to low HDL over time. Subjects in this study were selected from among participants of the Tehran Lipid and Glucose Study (TLGS). TLGS is a prospective study to determine the risk factors and outcomes of non-communicable disease [11] . The structure of this study includes some major components. The TLGS design has been explained elsewhere [12] . Longitudinal data from the three phases of the TLGS study was analyzed to assess the association between the some related polymorphisms and other risk factors with low levels of HDL over time. In order to assess this association, Transition Logic Regression models with first and second order Markov chain were fitted.
First order Markov chain Transition Logic Regression model with three tree logic (Boolean combination) and 8 leaves (predictor variables) was fitted.
A total of 329 subjects (127 (38.6%) men and 202 (61.4%) women) who were present in phase I, II, III of TLGS study with age ≥20 years and without any missing value in evaluated variables were randomly selected and included in the current study.
Low HDL-C level was defined as <40 mg/dL for men and <50 mg/dL for women. High waist circumference (WC) was defined as WC ≥95 cm for Iranian men and women [13] . High triglyceride (TG) level was defined as TG ≥150 mg/dL, subjects who had blood pressure (BP) ≥130/85 mmHg or used anti-hypertension drug, and subjects with fasting blood sugar (FBS) ≥110 mg/dL or users of anti-diabetic drugs were considered as high BP and high FBS respectively [14] [15] . Subjects who smoke daily or occasionally were considered as smokers. Phase of study was considered as time.
Table 5 pictures the summary of demographic characteristic and clinical and lipid profiles of these subjects in three phases of study. Highest prevalence of having low HDL (79.3%) was seen in phase 2 of study.
The polymorphisms of ApoA1M1, ApoA1M2, ApoB, ApoAIV, ApoCIII, ABCA1, SRB1 and ApoE genes that have been shown to be associated with HDL-C disorder [16] - [20] were investigated. Allele frequencies given in Table 6 show genotype distributions. The +/+ genotype of Apo A1M2 gene had the highest prevalence (91.2%) and TT genotype of Apo AIV gene had the lowest frequency (0.3%).
Each SNP was considered as a random variable taking values 0, 1, and 2 corresponding to the nucleotide pairs. We coded each of these variables into two dummy binary variables corresponding to a dominant and a recessive effect. By this approach, we generated 2p binary predictors out of p SNPs to perform interaction terms for Logic Regression [1] .
The results of Transition Logic Regression with first order Markov chain show that subjects with high triglyceride and high waist circumstance have an odds ratio of 2.29 to have low level of HDL. Also, (being in phase 2 and ((carrier of the minor allele of ApoA1M1) or (being homozygous for the common allele of ApoCIII))) was

Table 1. Result of simulation study with n=50.

Table 2. Result of simulation study with n=200.

Table 3. Result of simulation study with n=500.

Table 4. Result of simulation study with n=1000.

Table 5. Demographic characteristic and clinical and lipid profiles of subjects in phases of study.
Entries are mean ± sd for Age and number (%) for the rest categorical variables. *is time dependent variable. †is time independent variable.
Table 6. Genotype and allele frequencies of Apo E, Apo A1M1, Apo A1M2, Apo B, Apo AIV, Apo CIII, and SRB1 in the study population.
associated with an increased odds of having low HDL (OR = 2.30). The odds ratio for having low level of HDL in subjects with ((high Blood pressure and male) or (being homozygous for the minor allele of SRB1)) combination is 0.38. The first order Markov chain dependence between adjacent observations of response was estimated 2.5 indicating the strong dependence between successive observations. The AIC for this model was 100.72. Also, second order Markov chain Transition Logic Regression model with three tree logic and 8 leaves was fitted. The result of Transition Logic Regression with second order Markov chain was fairly similar to the result of the first order. According to this model, The odds ratio for having low level of HDL in subjects with ((high Blood pressure and male) or (being homozygous for the minor allele of SRB1)) combination is 0.37 and being in phase 2 or being homozygous for the minor allele of ApoCIII was associated with an increased odds of having low HDL. Also, subjects with high triglyceride that have high waist circumstance or high blood pressure have an odds ratio of 2.51 to have low level of HDL. The first order Markov chain dependence between adjacent observations of response was estimated 2.32 and the second order Markov chain dependence was 1.65. The AIC for this model was 974.96. Results of first and second-order Transition Logic Regression are shown in Table 7.
Table 7. Results of Transition Logic Regression model with 3 Boolean combination of 8 binary predictor variables for first and second order Markov chain dependence structure to study interaction effects of SNPs and other risk factors on having low level of HDL.
5. Discussion
In the first part of the paper, we extended Logic Regression and proposed a model which allowed first and second order Markov dependence in longitudinal binary data for which the marginal probability of success was modeled via a form of Logic Regression. In the second part, a simulation study was done that evaluated performance of the proposed model in different conditions. The simulation study indicated a satisfactory behavior for proposed model so that, in all condition AIC of Transition Logic Regression models were less than AIC of transition models with only main effect. Moreover, Transition Logic Regression was able to find moderate or strong interaction effects nearly in all datasets for sample sizes more than 50. In sample size 50 the quality of the estimators were poor. In this sample size, MSE of ψ1 is not acceptable especially for strong interaction effect and high dependency. Also in this sample size, confidence intervals of estimators of β in β = 0.5 have not consisted true value of the parameter. By increasing the sample size, MSE measures of estimation for ψ1 and β were decreased so that in other sample sizes, the performance of the method and quality of estimators are acceptable.
In the last part of the paper, proposed models were applied to the data from TLGS study and some interactions among SNPs and other covariates related to low HDL were identified. The results of first and second order Markov chain were fairly similar to each other and both of them had similar combinations. AIC of Transition Logic Regression model with second order dependency was less than the model with first order so it can be concluded that second order model is able to fit the data better than first order.
In this study, we had to work only with complete dataset because in Logic Regression methodology, missing problem has not been solved yet. It will be helpful if missing data is addressed in Logic Regression in future research.
6. Conclusion
Considering the identification of interactions in longitudinal study with binary response, Transition Logic Regression was introduced and used to find interactions influencing low HDL over time and the most important interactions were identified.
Acknowledgements
We would like to thank the staff and participants in the TLGS study for data collection. The research presented in this paper was carried out on the High Performance Computing Cluster supported by the computer science department of Institute for Research in Fundamental Sciences (IPM). This article has been extracted from PhD thesis of Parvin Sarbakhsh in Biostatistics at School of Para-medicine at Shahid Beheshti University of Medical Sciences.
Conflict of Interest
The authors have declared no conflict of interest.
Cite this paper
Parvin Sarbakhsh,Yadollah Mehrabi,Jeanine J. Houwing-Duistermaat,Farid Zayeri,Maryam Sadat Daneshpour, (2016) Transition Logic Regression Method to Identify Interactions in Binary Longitudinal Data. Open Journal of Statistics,06,469-481. doi: 10.4236/ojs.2016.63042
References
- 1. Ruczinski, I., Kooperberg, C. and Le Blanc, M. (2003) Logic Regression. Journal of Computational and Graphical Statistics, 12, 475-511.
http://dx.doi.org/10.1198/1061860032238 - 2. Schwender, H. and Ruczinski, I. (2010) Logic Regression and Its Extensions. Advances in Genetics, 72, 25-45.
http://dx.doi.org/10.1016/B978-0-12-380862-2.00002-3 - 3. Li, Q., Fallin, M.D., Louis, T.A., Lasseter, V.K., McGrath, J.A., Avramopoulos, D., Wolyniec, P.S., Valle, D., Liang, K.Y., Pulver, A.E. and Ruczinski, I. (2010) Detection of SNP-SNP Interactions in Trios of Parents with Schizophrenic Children. Genetic Epidemiology, 34, 396-406.
http://dx.doi.org/10.1002/gepi.20488 - 4. Kooperberg, C. and Ruczinski, I. (2005) Identifying Interacting SNPs Using Monte Carlo Logic Regression. Genetic Epidemiology, 28, 157-170. http://dx.doi.org/10.1002/gepi.20042
- 5. Schwender, H. and Ickstadt, K. (2008) Identification of SNP Interactions Using Logic Regression. Biostatistics, 9, 187- 198.
http://dx.doi.org/10.1093/biostatistics/kxm024 - 6. Nunkesser, R., Bernholt, T., Schwender, H., Ickstadt, K. and Wegener, I. (2007) Detecting High-Order Interactions of Single Nucleotide Polymorphisms Using Genetic Programming. Bioinformatics, 23, 3280-3288.
http://dx.doi.org/10.1093/bioinformatics/btm522 - 7. Diggle, P.J., Liang, K.Y. and Zeger, S.L. (1994) Analysis of Longitudinal Data. Oxford University Press, New York.
- 8. Mehrabi, Y., Sarbakhsh, P., Houwing-Duistermaat, J.J., Zayeri, F. and Sadat Daneshpour, M. (2015) Assessment of SNP Interactions Affecting Total Cholesterol over Time Using Logic Mixed Model: TLGS Study. Gene Cell Tissue, 2, e25572.
http://dx.doi.org/10.17795/gct-25572 - 9. Goncalves, M.H. and Azzalini, A. (2008) Using Markov Chains for Marginal Modelling of Binary Longitudinal Data in an Exact Likelihood Approach. Metron-International Journal of Statistics, LXVI, 157-181.
- 10. Garte, S. (2001) Metabolic Susceptibility Genes as Cancer Risk Factors: Time for a Reassessment? Cancer Epidemiology Biomarkers & Prevention, 10, 1233-1237.
- 11. Azizi, F., Rahmani, M., Emami, H., Mirmiran, P., Hajipour, R., Madjid, M., Ghanbili, J., Ghanbarian, A., Mehrabi, J., Saadat, N., Salehi, P., Mortazavi, N., Heydarian, P., Sarbazi, N., Allahverdian, S., Saadati, N., Ainy, E. and Mæini, S. (2002) Cardiovascular Risk Factors in an Iranian Urban Population: Tehran Lipid and Glucose Study (Phase 1). Sozial- und Präventivmedizin/Social and Preventive Medicine, 47, 408-426.
http://dx.doi.org/10.1007/s000380200008 - 12. Azizi F Fau-Ghanbarian, A., Ghanbarian A Fau-Momenan, A.A., Momenan Aa Fau-Hadaegh, F., Hadaegh F Fau- Mirmiran, P., Mirmiran P Fau-Hedayati, M., Hedayati M Fau-Mehrabi, Y., Mehrabi Y Fau-Zahedi-Asl, S. and Zahedi-Asl, S. (2009) Prevention of Non-Communicable Disease in a Population in Nutrition Transition: Tehran Lipid and Glucose Study phase II.
- 13. Azizi, F., Khalili, D., Aghajani, H., Esteghamati, A., Hosseinpanah, F., Delavari, A., Larijani, B., Mirmiran, P., Mehrabi, Y., Kelishadi, R. and Hadaegh, F. (2010) Appropriate Waist Circumference Cut-Off Points among Iranian Adults: The First Report of the Iranian National Committee of Obesity. Archives of Iranian Medicine, 13, 243-244.
- 14. NCEP (2001) Executive Summary of the Third Report of The National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in Adults (Adult Treatment Panel III). JAMA, 285, 2486-2497.
http://dx.doi.org/10.1001/jama.285.19.2486 - 15. NCEP (2001) Executive Summary of the Third Report of The National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in Adults (Adult Treatment Panel III). JAMA, 285, 2486-2497.
http://dx.doi.org/10.1001/jama.285.19.2486 - 16. Daneshpour, M.S., Faam, B., Hedayati, M., Eshraghi, P. and Azizi, F. (2011) ApoB (XbaI) Polymorphism and Lipid Variation in Teharnian Population. European Journal of Lipid Science and Technology, 113, 436-440.
http://dx.doi.org/10.1002/ejlt.201000346 - 17. Brown, C.M., Rea, T.J., Hamon, S.C., Hixson, J.E., Boerwinkle, E., Clark, A.G. and Sing, C.F. (2006) The Contribution of Individual and Pairwise Combinations of SNPs in the APOA1 and APOC3 Genes to Interindividual HDL-C Variability. Journal of Molecular Medicine, 84, 561-572.
- 18. Daneshpour, M.S., Hedayati, M., Eshraghi, P. and Azizi, F. (2010) Association of Apo E Gene Polymorphism with HDL Level in Tehranian Population. European Journal of Lipid Science and Technology, 112, 810-816.
http://dx.doi.org/10.1002/ejlt.200900207 - 19. McCarthy, J.J., Lehner, T., Reeves, C., Moliterno, D.J., Newby, L.K., Rogers, W.J. and Topol, E.J. (2003) Association of Genetic Variants in the HDL Receptor, SR-B1, with Abnormal Lipids in Women with Coronary Artery Disease. Journal of Medical Genetics, 40, 453-458.
http://dx.doi.org/10.1136/jmg.40.6.453 - 20. Frikke-Schmidt, R. (2000) Context-Dependent and Invariant Associations between APOE Genotype and Levels of Lipoproteins and Risk of Ischemic Heart Disease: A Review. Scandinavian Journal of Clinical and Laboratory Investigation, 233, 3-25.
NOTES

*Corresponding author.