American Journal of Operations Research
Vol.05 No.05(2015), Article ID:59795,13 pages
10.4236/ajor.2015.55035
Mathematical Model and Algorithm for Link Community Detection in Bipartite Networks
Zhenping Li1, Shihua Zhang2, Xiangsun Zhang2
1School of Information, Beijing Wuzi University, Beijing, China
2National Center for Mathematics and Interdisciplinary Sciences, Academy of Mathematics and Systems Science, Beijing, China
Email: lizhenping66@163.com, zsh@amss.ac.cn, zxs@amt.ac.cn
Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 18 August 2015; accepted 19 September 2015; published 22 September 2015
ABSTRACT
In the past ten years, community detection in complex networks has attracted more and more attention of researchers. Communities often correspond to functional subunits in the complex systems. In complex network, a node community can be defined as a subgraph induced by a set of nodes, while a link community is a subgraph induced by a set of links. Although most researches pay more attention to identifying node communities in both unipartite and bipartite networks, some researchers have investigated the link community detection problem in unipartite networks. But current research pays little attention to the link community detection problem in bipartite networks. In this paper, we investigate the link community detection problem in bipartite networks, and formulate it into an integer programming model. We proposed a genetic algorithm for partition the bipartite network into overlapping link communities. Simulations are done on both artificial networks and real-world networks. The results show that the bipartite network can be efficiently partitioned into overlapping link communities by the genetic algorithm.
Keywords:
Bipartite Network, Link Community, Quantity Function, Integer Programming, Genetic Algorithm

1. Introduction
Many interesting systems can be represented as networks [1] -[4] . The networks are composed of nodes and links, each node represents a unit and each link represents a relation between two nodes. Since some nodes or links may have the same function in complex system. One of the most important topics in the area of networks is the community detection, which is a universal problem in many disciplines such as sociology, computer science and biology [5] -[7] .
The communities are dense subgraphs induced by a set of nodes or links. If the community is induced by a set of nodes, we call it node community. If a community is induced by a set of links, we call it link community. When we partition a network into node communities, each node must belong to one or more community, some links might belong to no community. When a network is partition into link communities, each link must belong to one community, and each node might belong to one or more communities. By partition the network into link communities, we can find overlapping node or link.
Although most research paid more attention to node community detection, some researchers have investigated link communities and cliques [8] -[12] . In some real-world networks, a link is more likely to have a unique identity while a node often has multiple functions, so the link communities might be more intuitive and informative than the node communities [13] [14] .
Given a unipartite network with M links and N nodes, let 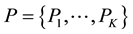 be a partition of the links into K
be a partition of the links into K
subsets. 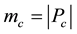 be the number of links in subset
be the number of links in subset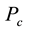 ,
,  be the number of nodes in subgraph
be the number of nodes in subgraph
induced by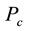 . Ahn [8] defined the partition density D as follows
. Ahn [8] defined the partition density D as follows
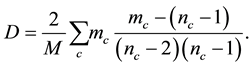
In [12] , the authors proposed another partition density H as follows:
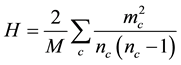
Obviously,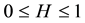 .
.
Given the number of communities, we can partition the unipartite network into link communities by maximize D or H.
Besides unipartite networks, there is another special category of network, where nodes are partitioned into two disjoint subsets, there is no link within the same subset. This type of network is called bipartite network. Some real-world relations are more suitable to be represented as bipartite networks [15] , such as plant-animal network, scientific publication network, artistic collaboration network, order-item network, paper-author networks, event-attendee networks and so on.
Some research has paid attention to the node community detection problem of bipartite networks [15] [16] . In [15] , the authors proposed a projection-based algorithm for node communities detection in bipartite network. In [17] , the authors develop a modified adaptive genetic algorithm (MAGA) to detect the node communities in bipartite network. In [18] , the authors propose another bipartite modularity detection method which can detect node overlap community. In [19] , the authors proposed a hierarchical divisive heuristic for approximate modularity maximization in bipartite graphs. In [20] , the authors proposed an algorithm Bitector to mine overlapping communities in large scale sparse bipartite networks. In [21] , the authors proposed an approach for detecting overlap node communities in a bipartite network based on dual optimization of modularity. In [22] [23] , the authors proposed weighted binary matrix factorization framework to detect overlapping communities in bipartite networks. Although the algorithms above can find node communities in bipartite network, current research activity has paid no attention to the link community detection problem in bipartite networks.
In this paper, we will investigate link communities in bipartite network, define the partition density of link communities in bipartite network, and formulate the link community partition problem of bipartite network into an integer programming model. Then we design a genetic algorithm for detecting link communities in bipartite network and conduct validations on some artificial and real-world bipartite networks. By the model and algorithm, the communities including two sets of nodes in bipartite network can be identified simultaneously.
2. Methods
2.1. Link Community Partition Density of Bipartite Networks
Given a bipartite network 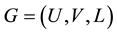 with
with 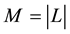 links and two node sets U and V, where
links and two node sets U and V, where ,
,  is a partition of the links into K subsets. The number of links in subset
is a partition of the links into K subsets. The number of links in subset  is
is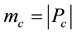 . The induced node set from link subset
. The induced node set from link subset  is
is 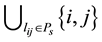 (where
(where 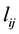 represents the link connecting node
represents the link connecting node 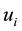 and
and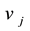 ), the number of induced nodes in node set U is
), the number of induced nodes in node set U is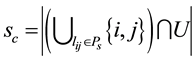 , the number of induced nodes in node set V is
, the number of induced nodes in node set V is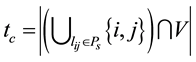 . The link density
. The link density 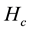 of community c in bipartite network is defined as follows:
of community c in bipartite network is defined as follows:
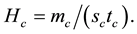
The partition density H is the average of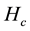 :
:
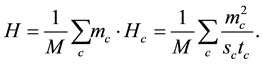
We can see that the maximum of H is 1 and the minimum value of H is 0. 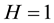 when each community is a complete bipartite network and
when each community is a complete bipartite network and 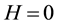 when each community is an empty bipartite graph. Given the number of communities, we can find the optimal link community partition of bipartite network by maximizing the value of H.
when each community is an empty bipartite graph. Given the number of communities, we can find the optimal link community partition of bipartite network by maximizing the value of H.
2.2. Integer Programming Model for Link Community Detection of Bipartite Network
Given a bipartite network 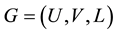 with M links and
with M links and 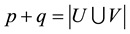 nodes (where
nodes (where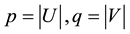 ), we assume that the number of link communities is K and find the optimal link community partition by maximizing the partition density H. This problem can be formulated into an integer programming model.
), we assume that the number of link communities is K and find the optimal link community partition by maximizing the partition density H. This problem can be formulated into an integer programming model.
Let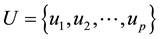 ,
, 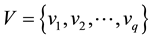 be two disjoint nodes sets of bipartite network G.
be two disjoint nodes sets of bipartite network G. 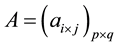 is the adjacent matrix of the bipartite network, where
is the adjacent matrix of the bipartite network, where 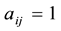 when node
when node 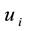 and
and 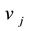 is connected by link
is connected by link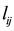 , while
, while 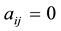 otherwise.
otherwise.
We also define binary variables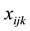 ,
, 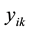 and
and 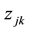 to represent the membership of link
to represent the membership of link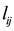 , node
, node 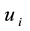 and node
and node 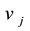 for link community k:
for link community k:
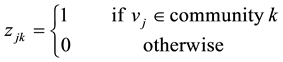
The link community detection problem of bipartite network can be formulated into the following integer programming model―Model 1.
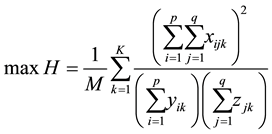 (1)
(1)

The objective function (1) is to maximize the link partition density H. Constraint (2) means that every link belongs to one community. If there is no link between node 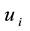 and
and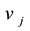 , then variables
, then variables 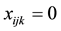 for any community k. Constraints (3) and (4) indicate that if link
for any community k. Constraints (3) and (4) indicate that if link 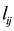 belong to community k, then its adjacent nodes
belong to community k, then its adjacent nodes 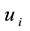 and
and 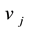 must belong to the same community k. Constraint (5) and (6) mean that if a node
must belong to the same community k. Constraint (5) and (6) mean that if a node 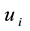 (or
(or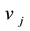 ) belongs to community k, then there is at least one link adjacent to node
) belongs to community k, then there is at least one link adjacent to node 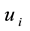 (or
(or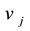 ) belonging to community k. Constraints (7) (8) (9) indicate that the variables are binary.
) belonging to community k. Constraints (7) (8) (9) indicate that the variables are binary.
Since there are a great many of variables in Model 1, it may have large memory overhead when solving the model directly. To decrease the number of variables used, Model 1 can be expressed by using relationship matrix.
Suppose that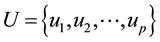 ,
, 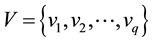 are two disjoint nodes sets, and
are two disjoint nodes sets, and 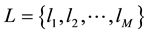 is the link set of bipartite network. Define two incidence matrix
is the link set of bipartite network. Define two incidence matrix 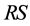 and
and 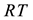 as follows:
as follows:

where
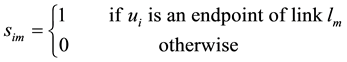
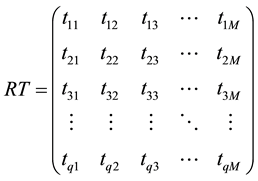
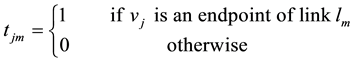
Define the binary variables as follows:
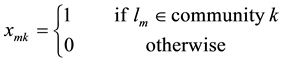
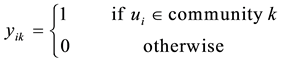
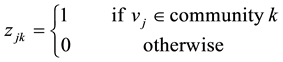
Based on the incidence matrix and the above variables, the link community detection problem of bipartite network can be reformulated into the following integer nonlinear programming model, Model 2.
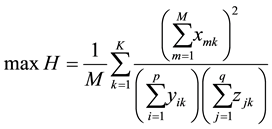 (10)
(10)

Where N is the number of nodes in the network,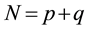 . The objective function (10) is to maximize the link partition density. Constraint (11) means that every link belongs to one community. Constraint (12) (13) mean that, if there is some adjacent links of node
. The objective function (10) is to maximize the link partition density. Constraint (11) means that every link belongs to one community. Constraint (12) (13) mean that, if there is some adjacent links of node 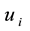 (
(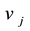 ) belonging to community k, then node
) belonging to community k, then node 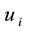 (
(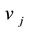 ) must belong to the same community k. Constraints (14) (15) mean that if node
) must belong to the same community k. Constraints (14) (15) mean that if node 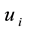 (
(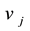 ) belongs to community k, then at least one link adjacent to this node must belong to community k. Constraints (16) (17) (18) indicate that the variables are binary.
) belongs to community k, then at least one link adjacent to this node must belong to community k. Constraints (16) (17) (18) indicate that the variables are binary.
In Model 1 and Model 2, since every link can belong to one and only one community, we might obtain the result that a pair of nodes belongs to two communities, but the link between this pair of nodes belongs to only one community. To reduce this drawback, we can revise Model 2 into the following model―Model 3.
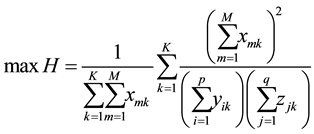 (10')
(10')

In model 3, the constraint (11') means that every link must belong to at least one community.
Using model 3, we can partition the network in Figure 1 into two communities, and link (3, 10) belongs to two communities. Each community is a complete bipartite subnetwork, and the optimal objective function value is 1.

Figure 1. The bipartite network consists of two overlapping communities, each community is a complete bipartite network, they are overlapped by nodes 3,10 and link (3,10). This bipartite network can be partitioned into two communities by model 3, and the objective function value is 1.
2.3. Genetic Algorithm for Link Community Detection of Bipartite Network
Although we can solve Model 2 or Model 3 to partition a bipartite network into link communities for small size of bipartite network. It is difficult to solve the integer programming model for large bipartite networks which might be a NP-hard problem. In addition, most of the algorithms for community detection need some priori knowledge about the community structure like the number of communities which is impossible to know in real-life networks. In [12] , the authors propose a link community detection algorithm based on the ideas of genetic algorithm and self-organize map (SOM) algorithm, which aims to find the best link community structure by maximizing the network partition density. The algorithm does not need any priori knowledge about the number of communities, which makes the algorithm useful in real-life networks. The algorithm outputs the final link community structure and its corresponding overlapping nodes as the result and does not impose further processing on the output. In the following, we will design another genetic algorithm for link community detection of bipartite network.
First of all, we need to design a chromosome representation suitable for the link community detection problem. In our implementation, the chromosome is represented by a matrix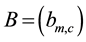 , where
, where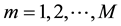 , and
, and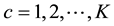 . Each element
. Each element 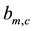 is the strength with which a link
is the strength with which a link 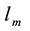 belongs to a community c. Note that
belongs to a community c. Note that 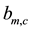 ranges in the interval [0.0, 1.0]. Each link of the bipartite network is subject to the following constraint:
ranges in the interval [0.0, 1.0]. Each link of the bipartite network is subject to the following constraint:
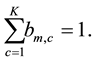 (19)
(19)
Equation (19) represents normalization to 1.0 of link factors of belonging to the communities.
For each chromosome, we design a partition matrix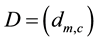 , where
, where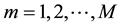 , and
, and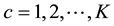 . Each element
. Each element 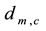 is either 0 or 1. Where
is either 0 or 1. Where 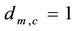 if the link
if the link 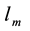 is assigned to community c, otherwise, link
is assigned to community c, otherwise, link 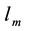 is not assigned to community c. Matrix D can be calculated from matrix B according to the following equation:
is not assigned to community c. Matrix D can be calculated from matrix B according to the following equation:
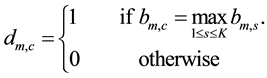 (20)
(20)
The bipartite network is represented by two incidence matrixes 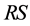 and
and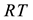 , two weighted incidence matrixes
, two weighted incidence matrixes 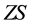 and
and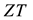 , link adjacent matrix A and weighted link adjacent matrix Q.
, link adjacent matrix A and weighted link adjacent matrix Q.
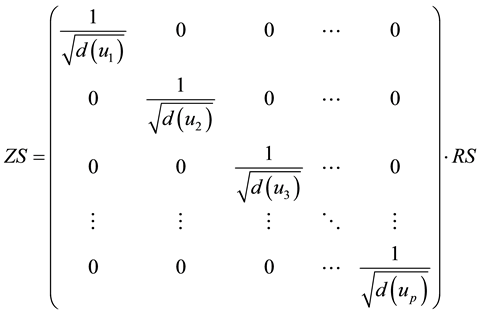
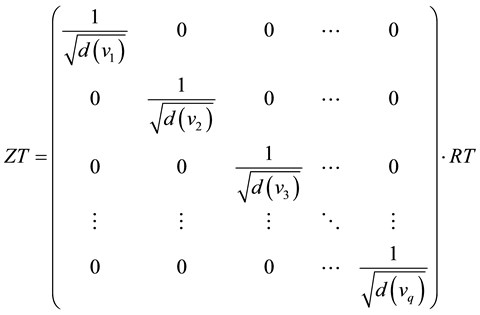
where 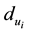 and
and 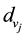 represent the nodes’ degree of nodes
represent the nodes’ degree of nodes 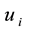 and
and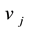 , which is the number of links incident to nodes
, which is the number of links incident to nodes 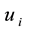 and
and 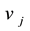 respectively.
respectively.
The link adjacent matrix A and the weighted link adjacent matrix Q can be calculated by the following equations:
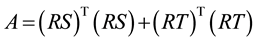
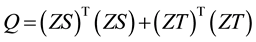
The weighted link adjacent matrix Q means the probability for a random walker go from one link to one of its adjacent links across their common node. And this can be regarded as the possibility of two adjacent links belonging to the same community.
2.3.1. The Genetic Algorithm Main Functions
• Input
Input the number of nodes p for node set 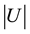 and q for node set
and q for node set 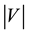 respectively, and the number of links M of the link set
respectively, and the number of links M of the link set 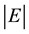 in bipartite network, the maximum number of communities K, parameters
in bipartite network, the maximum number of communities K, parameters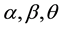 , where
, where
 .
.
Input the incident matrixes RS, RT. Calculate the weighted incident matrixes ZS and ZT, the link adjacent matrix A, and the weighted link adjacent matrix Q. Given the number of individuals N, the maximum epochs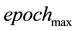 , mutation probability
, mutation probability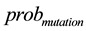 .
.
• Output
Output the link partition matrix 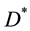 and its fitness value
and its fitness value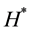 , two nodes set partition matrixes
, two nodes set partition matrixes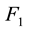 ,
,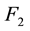 . Partition the network into communities according to
. Partition the network into communities according to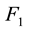 ,
,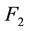 .
.
• Initialization: t = 0.
Randomly generate initial population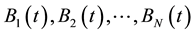 , and give random initial values of
, and give random initial values of 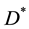 and its fitness
and its fitness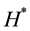 .
.
• Step 1. Population Fitness
For every individual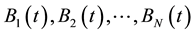 , calculate the partition matrix
, calculate the partition matrix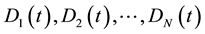 , and their fitness value (partition link density value)
, and their fitness value (partition link density value)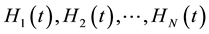 .
.
• Step 2. Population Sorting
Sort 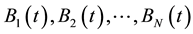 according to their fitness values in decreasing order. Suppose the sorted chromosomes are
according to their fitness values in decreasing order. Suppose the sorted chromosomes are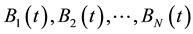 , where
, where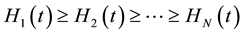 .
.
If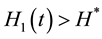 , then,
, then, 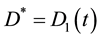 ,
,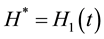 .
.
If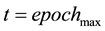 , stop, output
, stop, output 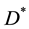 and
and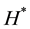 , and calculate the two corresponding node sets partition matrix
, and calculate the two corresponding node sets partition matrix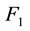 ,
,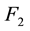 . Otherwise, go to Step 3.
. Otherwise, go to Step 3.
• Step 3. Population Crossover
For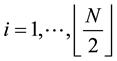 , let
, let 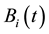 and
and 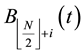 cross over to produce two temporary individuals ( matrixes)
cross over to produce two temporary individuals ( matrixes) 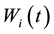 and
and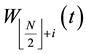 . If N is an odd number, let
. If N is an odd number, let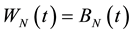 .
.
• Step 4. Population Mutation
Random select  temporary individuals (temporary matrices), do mutation operation on each temporary individual.
temporary individuals (temporary matrices), do mutation operation on each temporary individual.
• Step 5. Population Self Organize Mapping
For each temporary individual, do self organize mapping operation on it.
• Step 6. Population Normalization
For each temporary individual, do normalization on it. Denote the normalized individuals by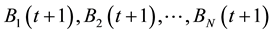 . Let
. Let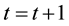 , go to step 1.
, go to step 1.
2.3.2. Partition Matrix and Fitness Evaluation
For every individual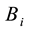 , calculate the partition matrix
, calculate the partition matrix 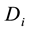 according to the Formula (20).
according to the Formula (20).
For each community s, 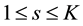 , let
, let 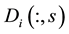 be the s-th column of matrix
be the s-th column of matrix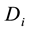 .
.
Then 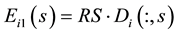 is a column vector whose element is a non-negative integer. A non-zero element in
is a column vector whose element is a non-negative integer. A non-zero element in 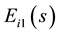 represents that the corresponding node of the node set
represents that the corresponding node of the node set 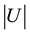 belongs to community s.
belongs to community s. 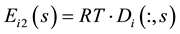 is a column vector whose element is a non-negative integer. A non-zero element in
is a column vector whose element is a non-negative integer. A non-zero element in 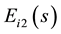 represents that the corresponding node of the node set
represents that the corresponding node of the node set 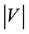 belongs to community s.
belongs to community s.
Let 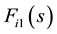 and
and 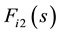 be 0-1 vectors,
be 0-1 vectors, 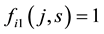 (or
(or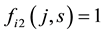 ) whenever
) whenever 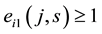 (or
(or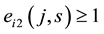 ).
). 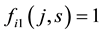 (or
(or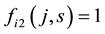 ) means that node
) means that node 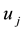 (or
(or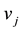 ) belongs to community s. The fitness value of individual
) belongs to community s. The fitness value of individual 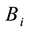 is defined by the link partition density of matrix
is defined by the link partition density of matrix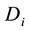 , which can be calculated by the following equation:
, which can be calculated by the following equation:
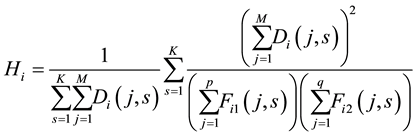
2.3.3. Population Sorting
Sort 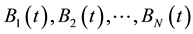 according to their fitness values in decreasing order. Suppose the sorted chromosomes are
according to their fitness values in decreasing order. Suppose the sorted chromosomes are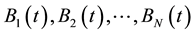 , where
, where .
.
If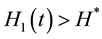 , then,
, then, 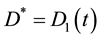 ,
,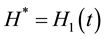 .
.
2.3.4. Population Crossover
For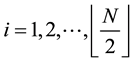 , do crossover operation on
, do crossover operation on 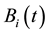 and
and 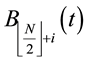 by the following rules: Randomly select a column s, revise the s-th column of
by the following rules: Randomly select a column s, revise the s-th column of 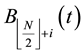 by the s-th column of
by the s-th column of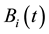 , and obtain two new temporal individuals
, and obtain two new temporal individuals 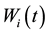 and
and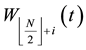 , where
, where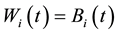 .
.
In this paper, we revised the s-th column of 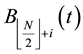 by adding a fraction of the s-th column of
by adding a fraction of the s-th column of 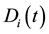
(where 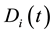 is the partition matrix corresponding to
is the partition matrix corresponding to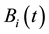 ), that is,
), that is,
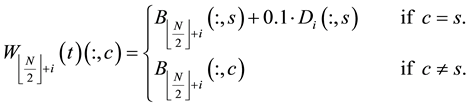
2.3.5. Population Mutation
According to the mutation probability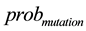 , randomly select
, randomly select  temporal individuals, do mutation operation on each selected individual.
temporal individuals, do mutation operation on each selected individual.
For each selected temporal individual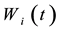 , randomly select two parameters
, randomly select two parameters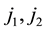 ,
,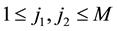 . There are three mutation rules can be used in this genetic algorithm, i.e. exchange the j1-th row and the j2-th row in
. There are three mutation rules can be used in this genetic algorithm, i.e. exchange the j1-th row and the j2-th row in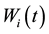 , or replace the j1-th row by the j2-th row in
, or replace the j1-th row by the j2-th row in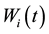 , or replace the elements of the j1-th row with a randomly selected number in [0.0,1.0]. Three rules lead to no significant difference in this genetic algorithm. In the following simulation, we replace the j1-th row with the j2-th row in
, or replace the elements of the j1-th row with a randomly selected number in [0.0,1.0]. Three rules lead to no significant difference in this genetic algorithm. In the following simulation, we replace the j1-th row with the j2-th row in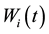 . The other elements in
. The other elements in 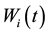 remain unchanged.
remain unchanged.
2.3.6. Population Self Organizing Map
For every link, find the community it belongs to and calculate its community ID variance. If the community ID variance of a link is larger than a threshold, then increase the weights of this link to its community and the weights of its neighbor links to the same community. If the community ID variance of a link is smaller than the threshold value, then decrease the weights of the link to its community and the weights of its neighbor links to the same community. This process can improve the quality of the partition by eliminating wrongly placed links.
For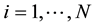 , do Self Organizing Map (SOM) operations on individual (chromosome)
, do Self Organizing Map (SOM) operations on individual (chromosome) 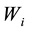 as follows:
as follows:
• According to temporal matrix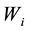 , calculate its partition matrix
, calculate its partition matrix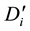 ;
;
• For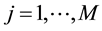 , do the following operation on link
, do the following operation on link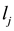 .
.
• Find the community ID that link 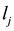 belongs to. The community ID corresponds to the maximum element in the j-th row of
belongs to. The community ID corresponds to the maximum element in the j-th row of 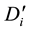 (the maximum element must be 1). Suppose the maximum element in the j-th row of
(the maximum element must be 1). Suppose the maximum element in the j-th row of 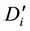 is in the s-th column, which is
is in the s-th column, which is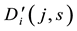 . This means that link
. This means that link 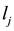 belongs to community
belongs to community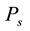 .
.
• Calculate the total number 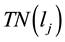 of adjacent links of
of adjacent links of 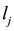 (including link
(including link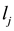 ), and the number of its adjacent links in
), and the number of its adjacent links in 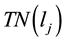 belonging to community
belonging to community 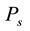 (denoted by
(denoted by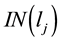 ).
). 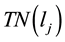 is equal to the sum of elements in the j-th row of matrix A, which can be expressed by
is equal to the sum of elements in the j-th row of matrix A, which can be expressed by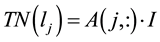 , where
, where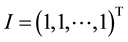 , and
, and 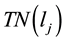 can be calculated by the equation
can be calculated by the equation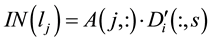 .
.
• Calculate the community ID variance 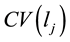 of link
of link 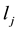 by the following equation.
by the following equation.
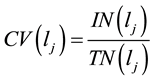
• If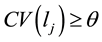 , then
, then
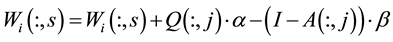
Else,
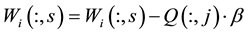
where a and b are adjustable parameters which can decrease with the step t. In this paper, we let
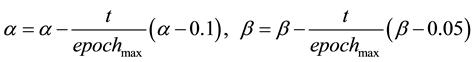
In the above equation, if an element is negative, then we set it to be 0.01
2.3.7. Normalization
For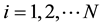 , do normalization on each row of temporal matrix
, do normalization on each row of temporal matrix 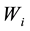 so that the sum of row elements in temporal matrix is 1. Let the normalized matrix be
so that the sum of row elements in temporal matrix is 1. Let the normalized matrix be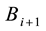 .
.
3. Numerical Experiments
In this section, we apply the genetic algorithm to both artificial bipartite networks and several well studied real-world bipartite networks, and analyze the results in terms of classification accuracy and ability of detecting meaningful communities. The algorithm is implemented by Matlab version 7.1.
3.1. Chain of Complete Bipartite Network
We test our algorithm on a type of exemplar networks, that is, chains of complete bipartite network. This network consists of many heterogeneous complete bipartite networks, connected through single nodes (Figure 2). Each complete bipartite network 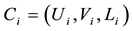
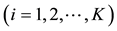 is a bipartite network, where there is a link between any pair of nodes
is a bipartite network, where there is a link between any pair of nodes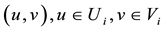 . Assume that
. Assume that 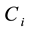 has
has 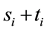 nodes and
nodes and 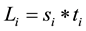 links, then the network has a total of
links, then the network has a total of 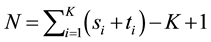 nodes and
nodes and 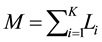 links. The network has a clear link bipartite modular structure where each community corresponds to a single bipartite complete network, thus the optimal partition density is 1. Using the genetic algorithm above, we can easily detect the optimal partition and identify the overlapping nodes. In this paper, we use a network consists of two (3,4)- complete bipartite networks, one (4,5)- complete bipartite network, one (4,6)- complete bipartite network, and one (5,5) complete bipartite network, the optimal partition results are obtained and described in Figure 2.
links. The network has a clear link bipartite modular structure where each community corresponds to a single bipartite complete network, thus the optimal partition density is 1. Using the genetic algorithm above, we can easily detect the optimal partition and identify the overlapping nodes. In this paper, we use a network consists of two (3,4)- complete bipartite networks, one (4,5)- complete bipartite network, one (4,6)- complete bipartite network, and one (5,5) complete bipartite network, the optimal partition results are obtained and described in Figure 2.
3.2. Real-World Networks
In this subsection, we validate our algorithm on some real-world networks.
The Southern Women Network During the 1930s, ethnographers Davis, Stubbs Davis, St. Clair Drake, Gardner, and Gardner collected data on social stratification in the town of Natchez, Mississippi. One of their work is collecting data on women's attendance to social events in the town [24] . They constructed the famous women-event bipartite network and analyze it. Since then the women-event bipartite network has become a de facto standard for discussing bipartite networks in the social science [12] [15] [20] [21] [24] -[27] .
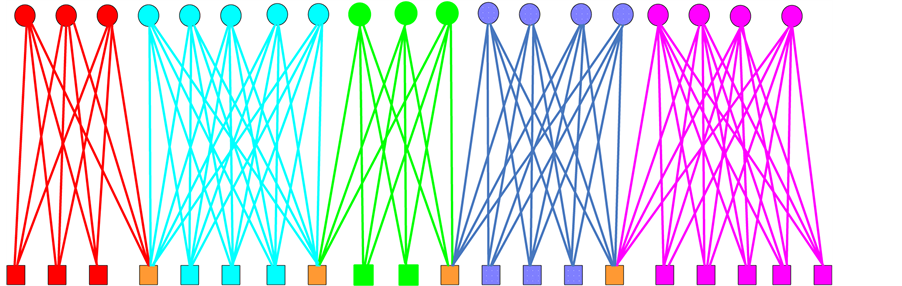
Figure 2. The chain of heterogeneous complete bipartite network. Each community is a complete bipartite network, and two adjacent communities are overlapped by one node.
Guimerà [15] has analyze the modules of both women and events by three methods: unweighted projection, weighted projection, and bipartite approach. The first method did not capture the true modular structure of the network. The second and third methods capture the two-module structure except one woman being partitioned wrong.
We applied the proposed method to the women-event network, using the parameters K = 2, N = 200, 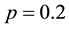 ,
, 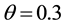 ,
, 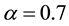 ,
, 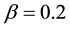 ,
,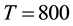 . The result is illustrated in Figure 3. In this result, 18 women and 14 events are partitioned into two communities, where 4 events are overlapped. The average link density is 0.5610. In the women-event bipartite network, four event nodes B6, B7, B8, B9 colored by yellow are overlapped and belong to two communities. Comparing with the results obtained by Guimerà [15] , the overlapped communities obtained by our method are more reasonable. When we partition the women-event network into four link communities using the parameters
. The result is illustrated in Figure 3. In this result, 18 women and 14 events are partitioned into two communities, where 4 events are overlapped. The average link density is 0.5610. In the women-event bipartite network, four event nodes B6, B7, B8, B9 colored by yellow are overlapped and belong to two communities. Comparing with the results obtained by Guimerà [15] , the overlapped communities obtained by our method are more reasonable. When we partition the women-event network into four link communities using the parameters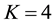 ,
, 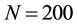 ,
, 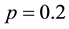 ,
, 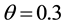 ,
, 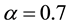 ,
, 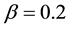 ,
, 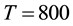 , we can obtain the maximum average link density 0.683, The result is illustrated in Figure 4. Six yellow nodes are overlapped, where
, we can obtain the maximum average link density 0.683, The result is illustrated in Figure 4. Six yellow nodes are overlapped, where 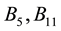 belong to two communities,
belong to two communities, 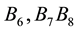 belong to three communities and
belong to three communities and 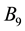 belong to four communities.
belong to four communities.
3.3. The Scotland Corporate Interlock Network
The Scotland corporate interlock network describe the corporate interlocks in Scotland in the beginning of the twentieth century (1904-1905). The network consists of 244 nodes and 356 edges. The 244 nodes are divided into two parts, where 136 nodes indicate the board members who held multiple directorships, and 108 nodes indicate the firms). The edges exist between each firm and its board members. The largest component of the Scotland corporate interlock network contains 131 directors and 86 firms, forming many communities.
We applied the proposed method to the largest component of Scotland corporate interlock network, using the parameters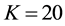 ,
, 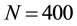 ,
, 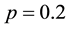 ,
, 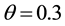 ,
, 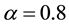 ,
, 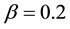 ,
,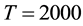 . In the experiment, we divides the network into 20 communities, and the link community density is 0.24777. With the number of communities K increasing, the link community density obtained by our algorithm increase. When we use the para-
. In the experiment, we divides the network into 20 communities, and the link community density is 0.24777. With the number of communities K increasing, the link community density obtained by our algorithm increase. When we use the para-
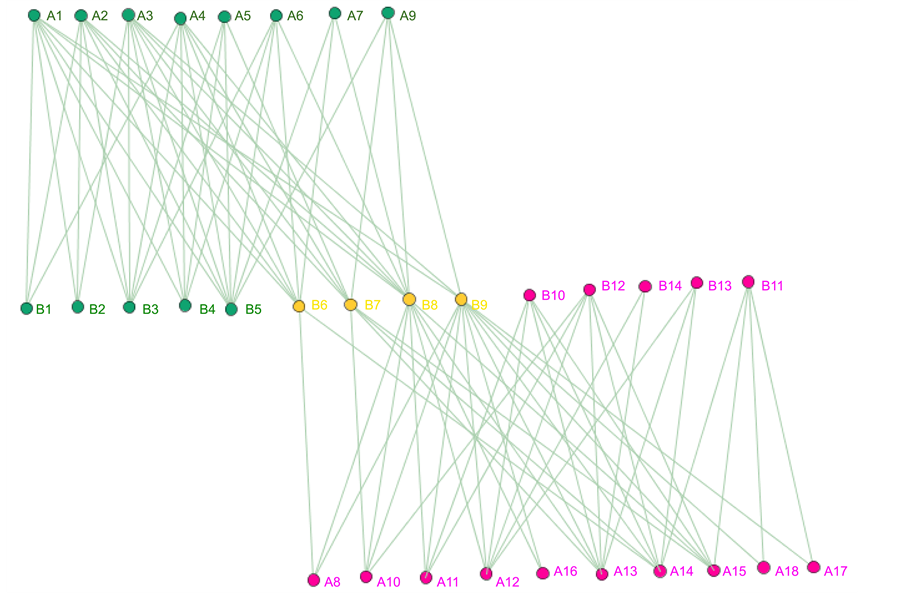
Figure 3. Result of the women-event networks partition into two link communities, where four yellow nodes B6; B7; B8; B9 belong to two communities.

Figure 4. Result of the women-event networks partition into 4 link communities. Six yellow nodes are overlapped, where B5; B11 belong to two communities, B6; B7; B8 belong to three communities and B9 belong to four communities.
meters ,
, 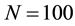 ,
, 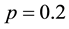 ,
, 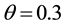 ,
, 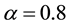 ,
, 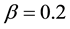 ,
,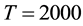 . We can obtained the maximum link community density 0.3553. If we increasing parameter K from 36 to 40, we can also partitioned the network into 36 link communities, the maximum link community density is also 0.3553. Since the real number of communities is 36 [25] , Our results mean that we can find the optimal community solution by our algorithm.
. We can obtained the maximum link community density 0.3553. If we increasing parameter K from 36 to 40, we can also partitioned the network into 36 link communities, the maximum link community density is also 0.3553. Since the real number of communities is 36 [25] , Our results mean that we can find the optimal community solution by our algorithm.
4. Conclusion and Discussion
Bipartite network community structure is one of the main characteristics of bipartite networks and very helpful for understanding the functions of these networks. In this paper, we investigate the link community detection problem of bipartite network and propose a quantity function for link community detection of bipartite network. We formulate the link community identification problem of bipartite network into an integer programming model by maximizing the quantity function. Furthermore, we design a genetic algorithm for solving the link community detection problem and conduct validation experiments on some simulated and real-world networks. The extensive computational results demonstrate that our model and algorithm can detect overlapping communities. Using our model and algorithm, we can not only find the node overlapping communities but also the link overlapping communities in bipartite networks. Although we only investigate the unweighted bipartite networks, the model and algorithm can also be extended to deal with weighted bipartite networks.
Acknowledgements
This work is supported by National Natural Science Foundation of China under Grant No. 11131009. It is also supported by the Funding Project for Academic Human Resources Development in Institutions of Higher Learning Under the Jurisdiction of Beijing Municipality (CIT&TCD20130327).
Cite this paper
ZhenpingLi,ShihuaZhang,XiangsunZhang, (2015) Mathematical Model and Algorithm for Link Community Detection in Bipartite Networks. American Journal of Operations Research,05,421-434. doi: 10.4236/ajor.2015.55035
References
- 1. Albert, R. and Barabási, A.L. (2002) Statistical Mechanics of Complex Networks. Reviews of Modern Physics, 74, 47-97.
http://dx.doi.org/10.1103/RevModPhys.74.47 - 2. Newman, M.E.J. (2003) The Structure and Function of Complex Networks. SIAM Review, 45, 167-256.
http://dx.doi.org/10.1137/S003614450342480 - 3. Newman, M.E.J. and Girvan, M. (2004) Finding and Evaluating Community Structure in Networks. Physical Review E, 69, Article ID: 026113.
http://dx.doi.org/10.1103/physreve.69.026113 - 4. Hu, Y., Chen, H., Zhang, P., Li, M., Di, Z. and Fan, Y. (2008) Comparative Definition of Community and Corresponding Identifying Algorithm. Physical Review E, 78, Article ID: 026121.
http://dx.doi.org/10.1103/PhysRevE.78.026121 - 5. Fortunato, S. (2010) Community Detection in Graph. Physics Reports, 486, 75-174.
http://dx.doi.org/10.1016/j.physrep.2009.11.002 - 6. Newman, M.E.J. (2012) Communities, Modules and Large-Scale Structure in Networks. Nature Physics, 8, 25-31.
http://dx.doi.org/10.1038/nphys2162 - 7. Zhang, S., Jin, G., Zhang, X.S. and Chen, L. (2007) Discovering Functions and Revealing Mechanisms at Molecular Level from Biological Networks. Proteomics, 7, 2856-2869.
http://dx.doi.org/10.1002/pmic.200700095 - 8. Ahn, Y.Y., Bagrow, J.P. and Lehmann, S. (2010) Link Communities Reveal Multi-Scale Complexity in Networks. Nature, 466, 761-764.
http://dx.doi.org/10.1038/nature09182 - 9. Evans, T.S. and Lambiotte, R. (2009) Line Graphs, Link Partitions and Overlapping Communities. Physical Review E, 80, Article ID: 016105.
http://dx.doi.org/10.1103/PhysRevE.80.016105 - 10. Evans, T.S. (2010) Clique Graphs and Overlapping Communities. Journal of Statistical Mechanics: Theory and Experiment, 12037.
http://dx.doi.org/10.1088/1742-5468/2010/12/P12037 - 11. Evans, T.S. and Lambiotte, R. (2010) Line Graphs of Weighted Networks for Overlapping Communities. The European Physical Journal B, 77, 265-272.
http://dx.doi.org/10.1140/epjb/e2010-00261-8 - 12. Li, Z., Zhang, X.S., Wang, R.S., Liu, H. and Zhang, S. (2013) Discovering Link Communities in Complex Networks by an Integer Programming Model and a Genetic Algorithm. PLoS ONE, 8, e83739.
http://dx.doi.org/10.1371/journal.pone.0083739 - 13. Zhang, S., Wang, R.S. and Zhang, X.S. (2007) Identification of Overlapping Community Structure in Complex Networks Using Fuzzy c-Means Clustering. Physica A, 374, 483-490.
http://dx.doi.org/10.1016/j.physa.2006.07.023 - 14. He, D.X., Liu, D., Zhang, W., Jin, D. and Yang, B. (2012) Discovering Link Communities in Complex Networks by Exploiting Link Dynamics. Journal of Statistical Mechanics, 2012, Article ID: P10015.
http://dx.doi.org/10.1088/1742-5468/2012/10/P10015 - 15. Guimmerà, R., Sale-Pardo, M. and Nunes Amaral, L.A. (2007) Module Identification in Bipartite and Directed Networks. Physical Review E, 76, Article ID: 036102.
http://dx.doi.org/10.1103/PhysRevE.76.036102 - 16. Barber, M.J. (2007) Modularity and Community Detection in Bipartite Networks. Physical Review E, 76, Article ID: 066102.
http://dx.doi.org/10.1103/physreve.76.066102 - 17. Zhan, W., Zhang, Z., Guan, J. and Zhou, S. (2011) Evolutionary Method for Finding Communities in Bipartite Networks. Physical Review E, 83, Article ID: 066120.
http://dx.doi.org/10.1103/PhysRevE.83.066120 - 18. Murata, T. and Ikeya, T. (2010) A New Modularity for Detecting One-to-Many Correspondence of Communities in Bipartite Networks. Advances in Complex Systems, 13, 19-31.
http://dx.doi.org/10.1142/S0219525910002402 - 19. Costa, A. and Hansen, P. (2014) A Locally Optimal Hierarchical Divisive Heuristic for Bipartite Modularity Maximization. Optimization Letters, 8, 903-917.
http://dx.doi.org/10.1007/s11590-013-0621-x - 20. Du, N., Wang, B., Wu, B. and Wang, Y. (2008) Overlapping Community Detection in Bipartite Networks. Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Sydney, 9-12 December 2008, 176-179.
http://dx.doi.org/10.1109/WIIAT.2008.98 - 21. Souam, F., AÏtelhadj, A. and Baba-Ali, R. (2013) Dual Modularity Optimization for Detecting Overlapping Communities in Bipartite Network. Knowledge and Information Systems, 40, 455-488.
http://dx.doi.org/10.1007/s10115-013-0644-8 - 22. Zhang, Z.Y., Wang, Y. and Ahn, Y.Y. (2013) Overlapping Community Detection in Complex Network Using Symmetric Binary Matrix Factorization. Physical Review E, 87, Article ID: 062803.
http://dx.doi.org/10.1103/PhysRevE.87.062803 - 23. Zhang, Z.Y. and Ahn, Y.Y. (2015) Community Detection in Bipartite Networks Using Weighted Symmetric Binary Matrix Factorization. International Journal of Modern Physics C, 26, Article ID: 1550096.
- 24. Freeman, L.C. (2003) Finding Social Groups: A Meta-Analysis of the Southern Women Data. In: Breiger, R., Carley, C. and Pattison, P., Eds., Dynamic Social Network Modeling and Analysis: Workshop Summary and Papers, National Research Council, The National Academies Press, Washington DC, 39-97.
- 25. Chen, B.L., Chen, L., Zhou, S.R. and Xu, X.L. (2013) Detecting Community Structure in Bipartite Networks Based on Matrix Factorization. International Journal of Wireless and Mobile Computing, 6, 599-607.
http://dx.doi.org/10.1504/IJWMC.2013.057576 - 26. Liu, X. and Murata, T. (2010) An Efficient Algorithm for Optimizing Bipartite Modularity in Bipartite Networks. Journal of Advanced Computational Intelligence and Intelligent Informatics, 14, 408-415.
- 27. Murata, T. (2009) Detecting Communities from Bipartite Networks Based on Bipartite Modularities. Proceedings of the 2009 International Conference on Computational Science and Engineering, Vancouver, 29-31 August 2009, 50-57.