Journal of Intelligent Learning Systems and Applications
Vol.08 No.01(2016), Article ID:62269,8 pages
10.4236/jilsa.2016.81001
Ensemble Neural Network in Classifying Handwritten Arabic Numerals
Kathirvalavakumar Thangairulappan, Palaniappan Rathinasamy
Department of Computer Science, V. H. N. S. N. College, Virudhunagar, India

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 26 August 2015; accepted 25 December 2015; published 28 December 2015
ABSTRACT
A method has been proposed to classify handwritten Arabic numerals in its compressed form using partitioning approach, Leader algorithm and Neural network. Handwritten numerals are re- presented in a matrix form. Compressing the matrix representation by merging adjacent pair of rows using logical OR operation reduces its size in half. Considering each row as a partitioned portion, clusters are formed for same partition of same digit separately. Leaders of clusters of partitions are used to recognize the patterns by Divide and Conquer approach using proposed ensemble neural network. Experimental results show that the proposed method recognize the patterns accurately.
Keywords:
Handwritten Numerals, Divide and Conquer, Cluster, Leader Algorithm, Neural Network, Ensemble, Classification

1. Introduction
Handwritten digit recognition has received remarkable attention in the field of character recognition. To meet industry demands, handwritten digit recognition systems must have good accuracy, acceptable classification times, and robustness to variations in handwriting style. Currently several approaches are able to reach com- petitive performance in terms of accuracy, including the ones based on multilayer neural networks [1] [2] support vector machines [3] and nearest neighbor method [4] . Neural networks require huge amount of training data and time to term effective models, but their feedforward nature makes them very efficient during runtime.
Clustering is a well known task in data mining and pattern recognition that organize a set of objects into groups in such a way that similar objects belong to the same cluster and dissimilar objects belong to different clusters [5] . Mitra et al., [6] have provided a survey of available literature on data mining using soft computing. Neural networks are nonparametric, robust and exhibit good learning and generalization capabilities in data-rich environments. Run-length encoding (RLE) is an way of representing a binary image using a run, which is a sequence of “1” pixels. Ravindra Babu et al., [7] have represented the given binary data as Run-Length Encoded data that would lead to compact or compressed representation of data. They have also proposed an algorithm to directly compute the Manhattan distance between two such binary encoded patterns. They have shown that classification of data in such compressed form improves the computation time. Akimov et al., [8] have con- sidered lossless compression of digital contours in map images. The problem is attacked by the use of context based statistical modeling and entropy coding of the chain codes.
Classification is an important problem in the emerging field of data mining. Although classification has been studied extensively in the past, most of the classification algorithms are designed only for memory resident data, thus limiting their suitability for data mining large data sets. Handwritten digit recognition has received re- markable attention in the field of character recognition. To meet industry demands, handwritten digit recogni- tion systems must have good accuracy, acceptable classification times, and robustness to variations in hand- writing style. Monu Agrawal et al., [4] have proposed a strategy to reduce the time and memory requirements in handwritten recognition by applying prototyping as an intermediate step in the synthetic pattern generation technique. Vijayakumar et al., [9] have proposed a novel algorithm for recognition of handwritten digits by classifying digits into two groups. One consists of blobs with/without stems and the other digits with stems only. The blobs are identified based on morphological region filling method. This eliminates the problem of finding the size of blobs and their structuring elements. The digit with blobs and stems are identified by a new concept called connected component. This eliminates the complex process of recognition of horizontal and vertical lines and concavity. Chen et al., [10] have described the effects of a large amount of artificial patterns to train an on- line Japanese handwritten character recognizer. They have constructed distortion models to generate large amount of artificial patterns and applied to train a character recognizer.
Park and Lee [11] have presented an efficient scheme for off-line recognition of large-set handwritten characters in the framework of stochastic models and the First Order Hidden Markov Models. Dhandra et al., [12] have proposed script independent automatic numeral recognition system that extract the local and global structural features like directional density estimation, water reservoirs, maximum profile distances and fillhole density. A probabilistic neural network classifier is used in the recognition system. Sarangi, et al., [13] have addressed the performance of Hopfield neural network model in recognizing the handwritten Oriya digit. Meier et al., [3] have proposed new method to train the member of a committee of a hidden layer neural nets. Instead of training various nets of subsets of the training data they have processed the training data for each individual model such that the corresponding errors are de-correlated. Having trained “n” networks, three different methods namely Majority Voting Committee, Average Committee and Median committee have been used to build the corres- ponding committee of networks. Noor et al., [14] have proposed a system to recognize Arabic (Indian) numerals using Fourier descriptors as the main classifier feature set and a simple structure based classifier is added as a supplementary classifier to improve the recognition accuracy. Patel et al., [15] have tackled the problem of handwritten character recognition with multi resolution technique using Discrete Wavelet Transform and Eucli- dean distance metric. Rajashekararadhya et al., [16] ) have extracted features based on zones of images and recognize mixed numerals of Kannada, Telugu, Tamil and Malayalam when it is existing mixed in the docu- ments using support vector machines. Asthana [17] have resolved the problem in identifying the PIN with Multilanguage script namely Devnagri, English, Urdu, Tamil and Telugu by neural network. A.A. Fatlawi et al., [18] have compared three different neural classifiers for graffiti recognition.
In this paper, handwritten Arabic numerals are recognized by partition, compression, cluster and ensemble neural network methods. The novelty of this method is recognizing cluster representatives by the proposed ensemble network. The rest of the paper is organized as follows. The ensemble neural network model is intro- duced in Section 2. In Section 3, a training method is given for neural network. An alternative method to recognize handwritten Arabic numerals is proposed in Section 4. In Section 5, the training procedure of the proposed method is given. Experimental result of the proposed work is in Section 6.
2. Ensemble Neural Network
The proposed network has group of Single hidden layer feedforward neural networks connected with a layer called classifier layer. The single hidden layer network has input, hidden and output layer as shown in Figure 1. The input layer is linear but hidden and output layers are non-linear. The activation function used in the hidden
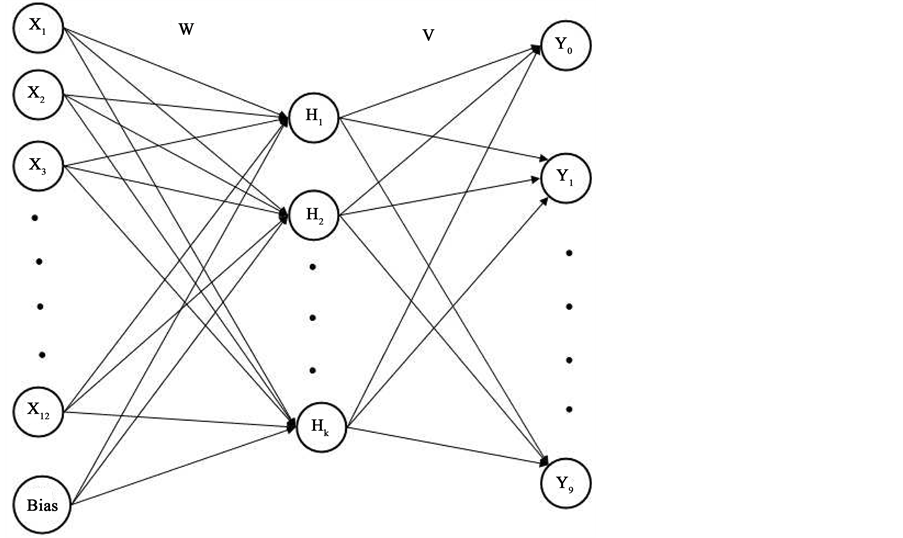
Figure 1. Neural network for partition of a digit.
and output layers are sigmoidal. Number of neural networks of this type considered in the ensemble network is equivalent to number of partitions of the matrix. Number of neurons in each output layer is 10, which represent the digits 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. All these single hidden layer neural networks are formed as an ensemble network by adding one more layer called classifier layer. Output layer of allthe feedforward neural networks are connected with classifier layer which has 10 neurons . First output neuron in all networks are connected with first neuron of the classifier layer. Second output neuron in all networks are connected with second neuron of the classifier layer. Similarly remaining output neurons in all networks are connected with corresponding neuron of the classifier layer. All connection lines between output layers of the networks and classifier layer are with weight 1.
. First output neuron in all networks are connected with first neuron of the classifier layer. Second output neuron in all networks are connected with second neuron of the classifier layer. Similarly remaining output neurons in all networks are connected with corresponding neuron of the classifier layer. All connection lines between output layers of the networks and classifier layer are with weight 1. 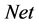 value of the neurons of classifier layer are calculated using (2). The output of the classifier layer is digit m if
value of the neurons of classifier layer are calculated using (2). The output of the classifier layer is digit m if 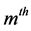 neuron of the layer has received maximum
neuron of the layer has received maximum 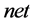 value, given by (1). The architecture of the ensemble network is shown in Figure 2.
value, given by (1). The architecture of the ensemble network is shown in Figure 2.
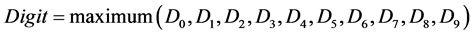 (1)
(1)
3. Neural Network Training
Decide the topology of the single hidden layer feedforward network for training the partitioned patterns for classification. For q partitions of the compressed matrix select q number of networks. Input the patterns through the corresponding neural network one by one. Find the output of the hidden and output layer neurons using (2) and (3). Find the error of the network using (4). Update the network weights using (5), (6) and (7). Again input the patterns through the corresponding network of the partitioned pattern. Repeat the above process until network gives predefined accuracy.
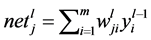 (2)
(2)
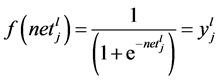 (3)
(3)
where m represents number of neurons in the layer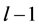 . The error of the network
. The error of the network 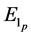 is calculated as follows:
is calculated as follows:
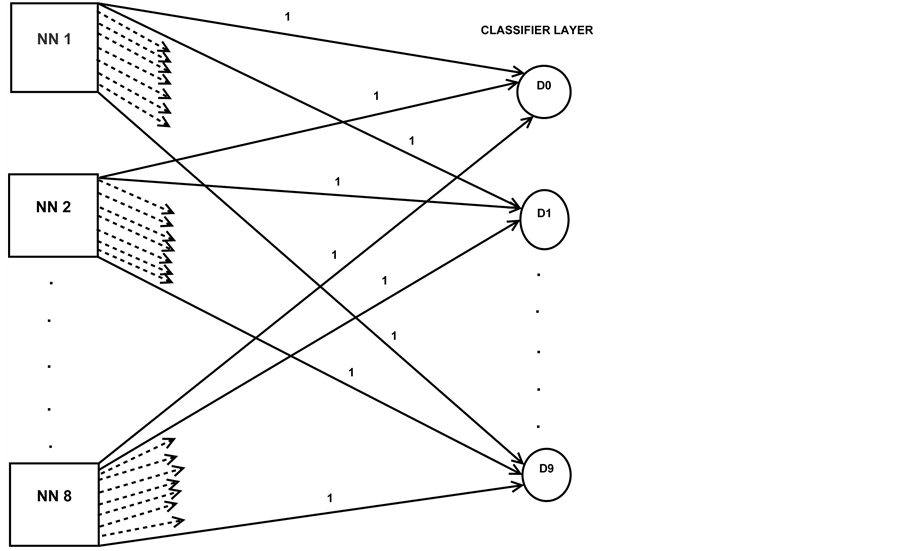
Figure 2. Ensemble neural network.
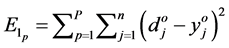 (4)
(4)

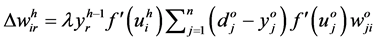 (5)
(5)
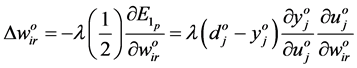
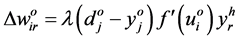 (6)
(6)
where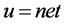 ,
, 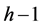 represents input layer, h represents hidden layer, n represents the number of neurons in the output layer, P represents number of patterns and weights are updated by
represents input layer, h represents hidden layer, n represents the number of neurons in the output layer, P represents number of patterns and weights are updated by
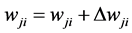 (7)
(7)
4. Proposed Work
4.1. Partitioning
Handwritten digits are represented in matrix form. Every pair of row of a digit is considered without overlapping. Matrix is compressed to its half size by applying logical OR operation on bits that occur in the same columns of selected pair of rows. Each row of a compressed matrix is considered as a new pattern. A pattern of each digit is partitioned into many individual patterns based on rows of a compressed matrix.
4.2. Clustering with Leader
Bits of each row are member of the group. Bits in each row of a digit are clustered based on distance measure. By considering all patterns of a particular digit clusters are formed for each partition of those digits separately. Similarly for every digit clusters are formed. Clustering technique with leader concept is used to group meaning- ful patterns so as to improve classification accuracy with minimum input-output operations. In this method [19] , first pattern is treated as a cluster leader. Remaining patterns are compared with the leaders of existing clusters and is assigned to member of a cluster when leader is with minimum distance. If the distance between pattern and the leader is greater than predefined distance then the pattern is a leader of a new cluster. Distance between pattern is computed by the Manhattan formula as follows:
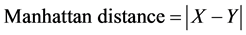 (8)
(8)
4.3. Classification
All leaders are considered for training the feedforward neural network. Standard backpropagation algorithm is used for training. Separate neural network is considered for training the cluster leaders of each partition. After training each neural network individually, the outputs are sent to the classifier layer of the proposed ensemble network. Based on the maximum value received by the neuron of the classifier layer, one of the neuron  is winner and j is the digit of the input pattern.
is winner and j is the digit of the input pattern.
5. Algorithm
Step 1. Convert 192 bits of numerals into 16 ´ 12 size matrix and treat 193rd bit as target value for the 16 rows of a digit.
Step 2. Repeat step 1 for all training patterns of the problem.
Step 3. Apply logical OR operation on bits of each column of adjacent in two rows without row overlapping. Now the size 16 ´ 12 becomes 8 ´ 12.
Step 4. Treat every resultant pattern as with 8 partitions.
Step 5. Form clusters for every partition of each digit separately.
Step 6. Train each neural network individually using standard in backpropagation algorithm by considering every leader as a pattern.
Step 7. Represent the pattern to be classified in 16 ´ 12 size matrix.
Step 8. Compress adjacent two rows using logical OR operation.
Step 9. Input first row into first neural network of ensemble network in and second row into second neural network of ensemble network and in similarly input other rows of the compressed matrix.
Step 10. Find the neuron in the classifier layer which is in “ON” state.
Step 11. Conclude the pattern belonging to the class as position of the neuron in which is in “ON” state.
6. Experimental Results
The proposed method is applied on OCR Handwritten digit data [20] having 667 patterns per class. 6670 patterns each with 193 bits are used for training and 3330 with 192 patterns are used for testing. The last bit of the pattern represent target class of the pattern. The experiment is carried out using MathLab software in the Intel Quad core system. Every pattern is converted into 16 number of patterns with single digit as target value. After compression by logical OR operation, 16 patterns reduce to 8 patterns. Clusters are formed among patterns of each partition of a digit separately. When threshold for distance measure is considered as 2, total number of clusters formed is 2216. As the compressed matrix obtained after logical OR operation is with 8 rows, 8 neural networks are considered for training. Each network is with 13 input neurons including bias, 6 hidden neurons and 10 output neurons. Classifier layer of the ensemble network is with 10 neurons as the number of arabic digits is 10. Number of hidden neurons is selected by trial and error method. The termination condition for training is fixed as 0.001 mean squared error. Number of epochs needed for every network termination is shown in Table 1. The tabulated values are the average value of 25 different runs of the experiments. The time required for convergence of each network is shown in Table 2. The network weights are initialized from the range [−1 1] randomly. The learning curve of the network for partition 3 is shown in Figure 3. Among 3330 patterns 98.6% of the patterns are recognized correctly. Table 3 shows the number of patterns classified correctly for each digit. Table 4 compares the accuracy of the proposed work with that of Ravindra Babu et al. [7] , Agrawal Monu et al., [4] and Vijaya et al., [19] .

Table 1. Number of epochs of each network.
Table 2. Training time of each network.
Table 3. Number of patterns classified on each digit.
Table 4. Comparison of classification accuracy.
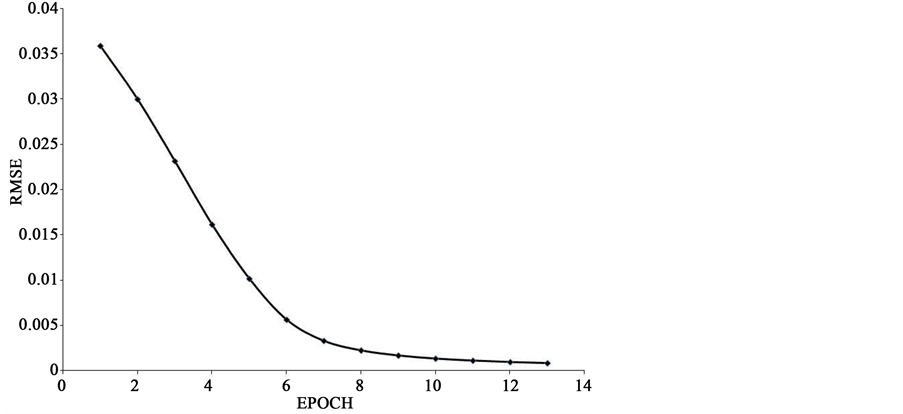
Figure 3. Learning curve.
7. Conclusion
Novelty of this work is recognition of digit through ensemble neural network. Each digit is converted into matrix form and then compressed using logical OR operation. Each row of a compressed matrix is partitioned into individual patterns. Clusters are formed for each partition of the digits using Leader algorithm. Cluster leaders are only considered for training. Ensemble neural network is with 8 neural networks as the compressed matrix has 8 rows. Training neural network consumes time but negligible time is needed for testing. This is the advantage of neural network but if we consider KNN classifier it consumes large time for classification. But another drawback of backpropagation is local minima. Reasonable time is needed to fix learning parameter value for convergence and avoiding local minima. As each partitioned pattern is trained with individual network the training is faster.
Cite this paper
KathirvalavakumarThangairulappan,PalaniappanRathinasamy, (2016) Ensemble Neural Network in Classifying Handwritten Arabic Numerals. Journal of Intelligent Learning Systems and Applications,08,1-8. doi: 10.4236/jilsa.2016.81001
References
- 1. Kodada Basappa, B. and Shivakumar, K.M. (2013) Unconstrained Handwritten Kannada Numeral Recognition. International Journal of Information and Electronics Engineering, 3, 230-232.
- 2. Mamta, G. and Ahuja, D. (2013) A Novel Approach to Recognize the Off-Line Handwritten Numerals Using MLP and SVM Classifiers. International Journal of Computer Science & Engineering Technology, 4, 953-958.
- 3. Meier, U., Ciresan, D.C., Gambardella, L.M. and Schmidhuber, J. (2011) Better Digit Recognition with a Committee of Simple Neural Nets. International Conference on Document Analysis and Recognition, 1250-1254.
http://dx.doi.org/10.1109/icdar.2011.252 - 4. Monu, A., Gupta, N., Shreelekshmi, R. and Narasimha Murty, M. (2005) Efficient Pattern Synthesis for Nearest Neighbour Classifier. Pattern Recognition, 38, 2200-2203.
http://dx.doi.org/10.1016/j.patcog.2005.03.029 - 5. Cleuziou, G. and Moreno, J.G. (2015) Kernel Methods for Point Symmetry Based Clustering. Pattern Recognition, 48, 2812-2830.
http://dx.doi.org/10.1016/j.patcog.2015.03.013 - 6. Mitra, P., Murthy, C.A. and Pal, S.K. (2002) Unsupervised Feature Selection Using Feature Similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24, 301-312.
http://dx.doi.org/10.1109/34.990133 - 7. Ravindra Babu, T., Narasimha Murty, M. and Agrawal, V.K. (2007) Classification of Run-Length Encoded Binary Data. Pattern Recognition, 40, 321-323.
http://dx.doi.org/10.1016/j.patcog.2006.05.002 - 8. Akimov, A., Kolesnikov, A. and Franti, P. (2007) Lossless Compression of Map Contours by Context Tree Modelling of Chain Codes. Pattern Recognition, 40, 944-952.
http://dx.doi.org/10.1016/j.patcog.2006.08.005 - 9. Vijaya Kumar, V., Srikrishna, A., Raveendra Babu, B. and Radhika Mani, M. (2010) Classification and Recognition of Handwritten Digits by Using Mathematical Morphology. Sadhana, 35, 419-426.
http://dx.doi.org/10.1007/s12046-010-0031-z - 10. Chen, B., Zhu, B.L. and Nakagawa, M. (2010) Effects of a Large Amount of Artificial Patterns for On-Line Handwritten Japanese Character Recognition. Proceedings of the 2nd China-Korea-Japan Joint Workshop on Pattern Recognition (CKJPR2010), Fukuoka, 90-93.
- 11. Park, H.-S. and Lee, S.-W. (1996) Off-Line Recognition of Large-Set Handwritten Characters with Multiple Hidden Markov Models. Pattern Recognition, 29, 231-244.
http://dx.doi.org/10.1016/0031-3203(95)00081-X - 12. Dhandra, B.V., Benne, R.G., Hangarge, M., Telugu, K. and Handwritten, D. (2011) Numeral Recognition with Probabilistic Neural Network: A Script Independent Approach. International Journal of Computer Applications, 26, 11-16.
- 13. Sarangi Pradeepta, K., Sahoo, A.K. and Ahmed, P. (2012) Recognition of Isolated Handwritten Oriya Numerals Using Hopfield Neural Network. International Journal of Computer Applications, 40, 36-42.
- 14. Noor Shatha, M., Mohammed Ihab, A. and George, L.E. (2011) Handwritten Arabic (Indian) Numerals Recognition Using Fourier Descriptor and Structure Base Classifier. Journal of Al-Nahrain University, 14, 215-224.
- 15. Kumar, P.D., Som, T., Yadav, S.K. and Singh, M.K. (2012) Handwritten Character Recognition Using Multiresolution Technique and Euclidean Distance Metric. Journal of Signal and Information Processing, 3, 208-214.
http://dx.doi.org/10.4236/jsip.2012.32028 - 16. Rajashekararadhya, S.V. and Vanaja Ranjan, P. (2009) Handwritten Numeral/Mixed Numerals Recognition of South-Indian Scripts: The Zone Based Feature Extraction Method. Journal of Theoretical and Applied Information Technology, 5, 63-79.
- 17. Asthana, S., Haneef, F. and Bhujade, R.K. (2011) Handwritten Multiscript Numeral Recognition Using Artificial Neural Networks. International Journal of Soft Computing and Engineering, 1, 1-5.
- 18. Fatlawi, A.A., Ling, S.H. and Lam, H.K. (2014) A Comparison of Neural Classifiers for Graffiti Recognition. Journal of Intelligence Learning Systems and Applications, 6, 94-112.
http://dx.doi.org/10.4236/jilsa.2014.62008 - 19. Vijaya, P.A., Murty, M.N. and Subramanian, D.K. (2004) Leaders-Subleaders: An Efficient Hierarchical Clustering Algorithm for Large Data Sets. Pattern Recognition Letters, 25, 505-513.
http://dx.doi.org/10.1016/j.patrec.2003.12.013 - 20. Viswanath, P., Murty, M.N. and Bhatnagar, S. (2004) Fusion of Multiple Approximate Nearest Neighbor Classifier for Fast and Efficient Classification. Information Fusion, 5, 239-250.
http://dx.doi.org/10.1016/j.inffus.2004.02.003