Journal of Biomedical Science and Engineering
Vol.09 No.05(2016), Article ID:65626,10 pages
10.4236/jbise.2016.95019
Detection of Ventricular Fibrillation Using Random Forest Classifier
Anurag Verma1, Xiaodai Dong2
1Department of Electronics & Electrical Communication Engineering, Indian Institute of Technology-Kharagpur, Kharagpur, India
2Department of Electrical and Computer Engineering, University of Victoria, Victoria, Canada

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 26 February 2016; accepted 16 April 2016; published 19 April 2016
ABSTRACT
Early warning and detection of ventricular fibrillation is crucial to the successful treatment of this life-threatening condition. In this paper, a ventricular fibrillation classification algorithm using a machine learning method, random forest, is proposed. A total of 17 previously defined ECG feature metrics were extracted from fixed length segments of the echocardiogram (ECG). Three annotated public domain ECG databases (Creighton University Ventricular Tachycardia database, MIT-BIH Arrhythmia Database and MIT-BIH Malignant Ventricular Arrhythmia Database) were used for evaluation of the proposed method. Window sizes 3 s, 5 s and 8 s for overlapping and non-overlap- ping segmentation methodologies were tested. An accuracy (Acc) of 97.17%, sensitivity (Se) of 95.17% and specificity (Sp) of 97.32% were obtained with 8 s window size for overlapping segments. The results were benchmarked against recent reported results and were found to outperform them with lower complexity.
Keywords:
Machine Learning, Random Forests (RF), Ventricular Fibrillation (VF) Detection

1. Introduction
Wearable health-monitoring systems have attracted much attention due to their high potential in healthcare as cost-effective solutions for real-time healthcare monitoring, early detection of diseases, and improving treatment of various medical conditions [1] . While these systems show much promise for increasing the quality of living, for practical usage, there are several challenges that need to be overcome, specifically, in areas such as reliability, multifunctionality, energy efficiency and minimizing obtrusiveness [1] .
Ventricular fibrillation (VF) is one of the most serious life-threatening cardiac arrhythmia diseases. VF is the most commonly identified arrhythmia in cardiac arrest patients [2] . VF carries high risk since it usually ends in death within minutes unless prompt corrective measures are instituted. Once a patient has suffered a VF attack, accurate detection and quick first aid treatment are essential for improving the chance of survival. Weaver et al. [3] report that the survival rate of a patient, who experiences a VF attack outside the hospital, varies from 7% to 70%, depending on how quickly the patient receives first aid. Thus, solving the problem of a quick and reliable detection is an emergent research topic.
The different types of defibrillators available for VF treatment include implantable cardioverter defibrillator (ICDs) and automated external defibrillators (AEDs). In such devices, the specificity is more important than sensitivity, since no patient should be defibrillated due to an error of analysis which might cause cardiac arrest. Therefore, a low number of false positive decisions should be achieved, even if this increases the number of false negative decisions. However, in case of ambulatory ECG monitoring devices which do not involve the use of defibrillators, specificity can be kept lower as compared to in case of AEDs, so that sensitivity is higher and more VF events are desirably identified during monitoring and there is no risk of an erroneous defibrillation associated in such devices.
Amann et al. in [4] reviewed ten VF detection algorithms and compared their performances under equal conditions using open, published annotated databases. Among the ten algorithms, the signal comparison algorithm (SCA) achieved the best performance withan accuracy (Acc) of 96.2%, a sensitivity (Se) of 71.2%, and specificity (Sp) of 98.5%. Amann’s results showed that no algorithm achieved its values for Se or Sp claimed in the original papers because the original researchers made a preselection of the signals by hand.
Some studies have shown that the combination of ECG features extracted from different algorithms may enhance the performance of VF detection [5] - [8] . Jekova extracted a set of ten parameters of the ECG signals and employed discriminant analysis to select variables [5] . Four parameters were selected by this approach and the best performance achieved had a Se of 94.1% and a Sp of 93.8%.
The study in this paper aims to build a high-performance VF detector by combining 17 previously defined ECG parameters using random forest classifier. The simplicity of random forest classifier coupled with its ability to produce better results than most classifiers in general serves as a motivation behind its use. In this context, the objective is two-fold: to determine an effective way of using the public domain ECG databases for studies and to assess the performance of the proposed detection algorithm over previously defined methods.
2. Feature Construction
2.1. ECG Database
We used the complete ECG signal recording files from the MITDB, the CUDB, and the VFDB, which are available at the PhysioNet repository [9] . The CUDB [10] contains 35 Holter records of 8-min length from patients who experienced episodes of sustained ventricular flutter (VFL), VT and VF. Each record is sampled at 250 Hz and includes only two rhythm annotations, namely, VF and non-VF. The VFDB [11] contains 22 files of 30-min length, two channels per file, sampled at 250 Hz. As the CUDB, the VFDB includes patients who experienced episodes of sustained VT, VFL, and VF. In this database, annotation labels contain 15 different rhythms, including VT, VF, VFL, normal sinus rhythm (NSR), among other rhythms. The MITDB [12] contains 38 Holter recording files (instead of 44, since some were not accessible) of slightly over 30-min length, two channels per file, sampled at 360 Hz. The MITDB includes 15 rhythm labels differentiating between VT, VFL, NSR, among other rhythms. For both VFDB and MITDB, the annotations were modified to either VF or non-VF. The different sampling rate in MITDB was not an issue since the features were extracted for each database individually. In order to avoid redundancy, only the first channel was used when two channels were available in the signal. The reference beat annotations available with the signals were used to determine the onset and ending points of the VF portions of the signal. The non-VF portions of the signals were marked as normal for our purposes. This was later made use of during the signal segmentation process.
2.2. Preprocessing
All ECG signals were preprocessed using the filtering process proposed in [13] , which included: 1) a first order high-pass Butterworth filter with 1-Hz cut-off frequency to suppress baseline drift, 2) a second order low-pass Butterworth filter with 30 Hz cut-off frequency to reduce high frequency noise, and 3) a notch filter to eliminate power line interference at 60 Hz.
2.3. Segmentation Methodology
There are two possible ways to segment the signals. While few researchers in the past (like in [13] ) decided to use non-overlapping segments, others (like in [14] ) have used overlapping segments. In order to decide which is better, we analysed the classifier performance for both methods.
As noted in [14] , preselection of signals should not be done as it more precisely replicates the point of view when one proceeds in real time. During preselection, the signals in VF and non VF category are first separated and then segmented. This way, the non-VF segments do not contain any portions of the signal which may be classified as VF category. But in real-time applications, the designed algorithm must be able to identify the occurrence of VF as soon as it occurs, which means that there may be segments to be analysed, which occur just at the onset of VF, that contain little portion of signal which may be classified as VF. This is essentially the motivation behind the decision to compare classifier performance for overlapping and non-overlapping segmentation methodologies.
In this study, the signals were segmented using shifting windows of fixed lengths. The shift in the window was fixed to one second in case of overlapping segments and to the length of the window in case of non-over- lapping segments. If any portion of the window fell inside the VF portion of the signal, the segment was marked as VF. Window lengths 3 s, 5 s and 8 s were analysed in order to determine the most suitable window length. Table 1 shows the number of segments extracted for each segmentation methodology, for each window size.
2.4. VF Metrics
Each preprocessed ECG signal is divided in fixed length segments. For each segment, a set of previously defined parameters were computed. The general flow-chart of the method for ECG feature extraction is presented in Figure 1.
2.4.1. Complexity Measure (Complexity) [15]
To compute the complexity measure, a binary sequence is first generated from the ECG segment using a threshold value. The mean value xm of the data points in the selected window is calculated and subtracted from each signal sample. The positive peak value Vp and the negative peak value Vn of the signal thus obtained are noted. The number of data points xi (of mean subtracted signal) having values in the interval [0 < xi < 0.1Vp] is denoted Pc and the number of data points xi in the interval [0.1Vn < xi < 0] by Nc. If (Pc + Nc) < 0.4n, where n is the number of samples in the selected window, the threshold is selected to be Td = 0; else if Pc < Nc, then Td = 0.2Vp, otherwise Td = 0.2Vn. The ECG segment is then converted into a sequence (Binary_s), whose point si is assigned 0 if xi < Td or 1 otherwise.
The complexity measure c(n) is then computed using the following procedure: Let S and Q represent two strings and SQ represent their concatenation. SQp is the string SQ without its last element. At the beginning, c(n) = 1, S = s1, Q = s2, SQp = s1. After a number of operations, S = s1, s2, ∙∙∙, sr and Q = sr+1. If Q is a substring of SQp, S does not change and Q becomes Q = sr+1, sr+2, ∙∙∙, etc. until obtaining Q, which is not a substring of SQp. S is renewed to be S combined with Q (S = s1, s2, ∙∙∙, sr, sr+1, ∙∙∙, sr+i), Q = sr+i+1, and c(n) = c(n) + 1. The aforementioned procedures are repeated until Q is the last character.
Generally, a larger value of complexity measure is observed in cases of VF whereas smaller values are observed for NSR.

Table 1. Number of segments extracted for each window size for each segmentation methodology.

Figure 1. General flow-chart of the method for ECG feature extraction.
2.4.2. VF-Filter Leakage (Leakage) [16]
It is a measure of the residue after applying a narrow-band elimination filter centered at the mean signal frequency of the considered ECG signal segment. Since ventricular fibrillation is a signal similar to a sinusoid, the idea is to find its predominant frequency and move such signal by a sample number equivalent to a half period to try and minimize the sum of the signal and its shifted copy. Thus, a VF signal will have a low value of Leakage.
2.4.3. Spectral Analysis [17]
First spectral moment normalized (FSMN) represents a characterization of the way in which the amplitude spectrum around the reference frequency F.
A1 is the ratio of the area contained within the band delimited by the origin of the frequencies, and half the reference frequency as contrasted with the total area of the first 20 harmonics. It is a descriptor crucial in discriminating between fibrillations and imitative artefacts, given the regularity presented by the spectra of the former. In general, high values of this parameter are indicative of artefacts.
A2 is the ratio of the area contained in the range 0.7F to 1.4F (F being the reference frequency), and the total area considered. It provides information about the relative distribution of area around the reference frequency. It is high in the VF category.
A3 is the ratio of the area contained around the second to the eighth harmonic, and the total area considered. To estimate this parameter, for each harmonic we compute the area contained in a band of 0.6F in width, centered on the harmonic. This descriptor is related to the repetition of peaks at frequencies which are multiples of the reference frequency. The parameter’s value is high in the case of records with dominant sinus rhythm and is very low in the case of VF and imitative artefacts.
2.4.4. Extended Time Delay Algorithm (Time Delay) [18]
It is an extension to the time delay algorithm [28] , using 3D phase space plot to address the weaknesses of the time delay algorithm for VF detection. The phase space plot of the signal and its delayed version by 0.5 seconds (found to be optimal in [29] ) is constructed and divided into a 40 × 40 grid. The number of times each box in the grid is visited is then added for all boxes and used as a metric.
2.4.5. Bandpass Filter and Auxiliary Counts [19]
An integer coefficient recursive digital filter with central frequency at 14.6 Hz and bandwidth from 13 Hz to 16.5 Hz (−3 dB) is applied on the ECG data. The filter equation, valid for 250 Hz sampling frequency is given by:
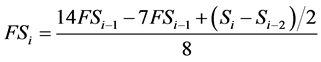 (1)
(1)
where Si is the signal sample with index i and FSi is the filtered signal sample with index i. Three auxiliary parameters are calculated from the absolute values of the digital integer-coefficient filter output (FS), named Count1, Count2, and Count3. Each parameter represents the number of signal samples with amplitude values within a certain amplitude range, calculated for a specific window.
1) Count1-Range: 0.5 max(|FS|) to max(|FS|);
2) Count2-Range: mean(|FS|) to max(|FS|);
3) Count3-Range: mean(|FS|) − MD to mean(|FS|) + MD,
where max (|FS|), mean (|FS|), and mean deviation (MD) are computed for every 1 s time interval.
2.4.6. Covariance Calculation (CovarBin) [5]
It measures the variance of the corresponding binary sequence (Binary_s) of ECG segment (computed in section 2.4.1).
2.4.7. Frequency Calculation (FreqBin) [5]
It is calculated by counting the number of binary sequence (Binary_s) transitions between “0” and “1” and dividing it to the window length (e.g., 5 s), thus, obtaining the transitions for 1 s.
2.4.8. Area Calculation (AreaBin) [5]
It is realized by summing the values of the binary sequence (Binary_s) samples. AreaBin is equal to the max(a,b) where a refers to the sum of the binary sequence (Binary_s) sample values and b refers to the sum of the inverted binary sequence sample values.
2.4.9. Kurtosis (Kurtosis) [20]
Kurtosis is a measure of the combined sizes of the two tails of the distribution of the data points of the signal. It measures the amount of probability in the tails. That is, data sets with high kurtosis tend to have heavy tails, or outliers. It is calculated as the fourth standardized moment of the ECG
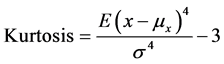 (2)
(2)
where E{.} is the mathematical expectation operator, μx and σ are, respectively, the mean and standard deviation of the ECG segment x.
2.4.10. Threshold Crossing Sample Count (TCSC) [21]
It refers to the number of samples that cross a given threshold Vo within a 3 s ECG interval. Decision is made on every Le-second ECG episode (Le > 3) by averaging Le 2 consecutive values of N obtained from Le 2 consecutive 3-s data segments with 1-s step. As explained in [21] , the value of Vo is suitably selected to be 0.2 after a number of empirical studies. It must be noted that TCSC is different from Count1, Count2 and Count3 as they represent the number of samples in certain amplitude ranges in a signal filtered though a band pass filter with bandwidth 13 Hz to 16.5 Hz.
2.4.11. Hilbert Transform (HILB) [21]
It measures the sparsity of the phase-space plot representation when considering the original ECG signal segment and its HILB signal. The phase-space plot is divided into a 40 × 40 grid and the number of boxes visited by the signal is counted.
2.4.12. Sample Entropy (SpEn) [22]
It is a measure of similarity within an ECG signal segment. It is calculated as the negative natural logarithm of an estimate of the conditional probability that subseries (epochs) of length m that match pointwise within a tolerance r also match at the next point. The values of m and r used were 2 and 0.2 respectively. A lower value of SpEn indicates more self-similarity. Thus, VF/VT rhythms are characterized by higher values of SpEn.
3. Choice of Classifier
The random forest [23] is composed of an collection of decision trees. In a decision tree, an input is entered at the top and as it traverses down the tree, the data gets bucketed into smaller and smaller sets. The random forest classifier considers an ensemble of such decision trees.
When the k-fold cross validation method is used, the entire data set is divided into k folds and k-1 folds are considered as the training set for one of the k iterations. In each iteration, an ensemble (of size say T) of decision trees is created. The procedure for construction of each decision tree in the ensemble is as follows:
1) Sample 2/3rd of the training cases at random with replacement from the training set to create a subset of the data
2) At each node:
a) For some number m (a parameter of the classifier), m feature variables are selected at random from all the feature variables. In general, m is chosen as the rounded value of logarithm of number of features considered.
b) The feature variable that provides the best split, according to some objective function, is used to do a binary split on that node.
c) At the next node, choose another m variables at random from all predictor variables and do the same.
When a new input from the testing set (the remaining/left out fold of data set out of k folds) is entered into the model, it is run down all of the trees. The result for that input is decided on the basis of a voting majority (when decision threshold is set as 0.5) of all of the terminal nodes that are reached.
4. Results
We used the Random Forest classifier in WEKA software [24] for our study. The number of decision trees (T), number of attributes selected in random selection (m) and depth of decision trees (d) were varied to optimize the classifier. No pruning was applied to adjust the depth of the tree. Once the probabilistic model had been generated, the probability threshold for class distinction was varied to tune the classifier.
The feature data sets from all the databases were extracted and combined to be used as input to the classifier. Then a 10-fold cross validation scheme was used to evaluate the performance. This approach was repeated for different window lengths, for overlapping as well as non-overlapping segmentation methods. This resulted in three random forest models for overlapping segments (for window lengths 3 s, 5 s and 8 s). Correspondingly, three models for non-overlapping segmentation were also generated.
We used the Sensitivity (Se), Specificity (Sp), Accuracy (Acc), and Area under the Receiver Operating Characteristic curve (AUC) to evaluate the performance of the algorithm. Since the dataset is unbalanced, a weight w is used to generate balanced accuracy (AcB) [13] as follows:
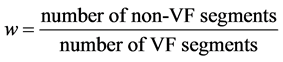 (3)
(3)
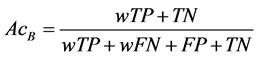 (4)
(4)
In addition, we used the balanced error rate (BER) [25] as the metric to compare our results with the previous results in [26] .
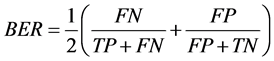 (5)
(5)
With the idea of use of the algorithm in ambulatory ECG monitoring devices in mind, the decision threshold for the probabilistic model generated in our study was tuned to increase the sensitivity above 95%. The results for the same models were also noted when they were tuned to produce a specificity above 95%.
Table 2 and Table 3 show the performance of random forest classifier for different window sizes with different segmentation methodologies while keeping specificity greater than 95%. Table 4 shows the performance of random forest classifier for different window sizes (for overlapping segmentation) while keeping sensitivity greater than 95%.
Figure 2 shows a comparison of ROCs for classifiers using features from overlapping segments of 8 s with
Table 2. Ten-fold cross validation results for non-overlapping segmentation for Sp > 95%.
Table 3. Ten-fold cross validation results for overlapping segmentation for Sp > 95%.
Table 4. Ten-fold cross validation results for overlapping segmentation for Se > 95%.

Figure 2. ROC curves for overlapping segments of 8 s showing variation with number of trees considered in forest.
different number of decision trees considered in random forest.
Figure 3 shows a comparison of ROCs for classifiers using features from overlapping segments of 3 s, 5 s and 8 s with 1000 decision trees considered in random forest.
From our results in Table 2 and Table 3, we can conclude that it is better to use overlapping segments to train the classifier as this consciously allows it to distinguish between vectors which lie closer to each other in feature space. Also we see that the best results are obtained for a window size of 8 s. The results are better than those obtained in [26] . A comparison has been shown in Table 5. It should thus be emphasized that the segmentation methodology and the segment length should be carefully chosen as they alone can improve the performance.

Figure 3. ROC curves for overlapping segments with different lengths considering 1000 decision trees in random forest.
Table 5. Performance comparison with previous methods.
5. Discussions and Conclusions
The method proposed in this study was found to outperform the recent reported results in [26] as can be seen in Table 5. In [26] , the authors had used 13 previously defined feature metrics and used support vector machine (SVM) classifier in contrast to the present study, where we have used 17 feature metrics and RF classifier.
The results also show that it is better to use overlapping segments to train the classifier as compared non- overlapping segments which have been used in past studies. This would allow us to use the public domain ECG databases in a more effective way.
The random forest classifier used in this study is known to be efficient in handling large datasets [23] . They were found to be very convenient to train. The default values of parameters (number of attributes selected in random selection = 5 and max. depth of decision trees = unlimited) worked well enough and we only varied the number of trees in ensemble to optimize the results. This is easily achieved since the performance generally improves with the number of trees to an extent, as is evident from Figure 2. However, it is important to recognize that random forests are a predictive modelling tool, not a descriptive tool. The results of its learning are incomprehensible. Compared to a single decision tree, or to a set of rules, they don’t give a lot of insight.
It is not logical to compare the results with those obtained in [13] since the ECG databases used in that study were different. As shown in [14] , the performance of an algorithm is different on different databases, thus reflecting the distinct nature of different databases. References [26] and [27] also emphasized the need for building a public ECG signal database in order to compare machine learning strategies. To overcome the problem in the present situation, [18] suggested that there could be dataset specific studies/results to enhance the validity of VF detection problems.
For analyzing the best window length, we only evaluated 3 s, 5 s and 8 s. 8 s was chosen based on the previous studies [27] [28] . Clearly, from Figure 3, we can conclude that 8 s segments give the best results in our case.
It is worth noting that the ability to vary the decision threshold for the probabilistic model generated may allow for the use of algorithm in ambulatory ECG monitoring devices.
In [26] , the authors had indicated that for VF detection problems, if the performance is to be maximized then the classification model could not be simplified, i.e., feature space dimension cannot be reduced. However, the study was for SVM classifier and a similar study can be performed for RF classifier in future works.
Cite this paper
Anurag Verma,Xiaodai Dong, (2016) Detection of Ventricular Fibrillation Using Random Forest Classifier. Journal of Biomedical Science and Engineering,09,259-268. doi: 10.4236/jbise.2016.95019
References
- 1. Pantelopoulos, A. and Bourbakis, N.G. (2010) A Survey on Wearable Sensor-Based Systems for Health Monitoring and Prognosis. IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews, 40, 1-12.
http://dx.doi.org/10.1109/TSMCC.2009.2032660 - 2. Koplan, B.A. and Stevenson, W.G. (2009) Ventricular Tachy-cardia and Sudden Cardiac Death. Mayo Clinic Proceedings, 84, 289-297.
http://dx.doi.org/10.4065/84.3.289 - 3. Weaver, W.D. (1986) Considerations for Improving Survival from Out-of-Hospital Cardiac Arrest. Annals of Emergency Medicine, 15, 1181-1186.
http://dx.doi.org/10.1016/S0196-0644(86)80862-9 - 4. Amann, A., Tratnig, R. and Unterkofler, K. (2005) Reliability of Old and New Ventricular Fibrillation Detection Algorithms for Automated External Defibrillators. Biomedical Engineering Online, 4, 60.
http://dx.doi.org/10.1186/1475-925X-4-60 - 5. Jekova, I. (2007) Shock Advisory Tool: Detection of Life-Threatening Cardiac Arrhythmias and Shock Success Prediction by Means of a Common Parameter Set. Biomedical Signal Processing and Control, 2, 25-33.
http://dx.doi.org/10.1016/j.bspc.2007.01.002 - 6. Clayton, R.H. (1994) Recognition of Ventricular Fibrillation Using Neural Networks. Medical & Biological Engineering & Computing, 32, 217-220.
http://dx.doi.org/10.1007/BF02518922 - 7. Moraes, J. (2002) Ventricular Fibrillation Detection Using Leakage/Complexity Measure Method. Computers in Cardiology, 29, 213-216.
http://dx.doi.org/10.1109/CIC.2002.1166745 - 8. Jekova, I. and Mitev, P. (2002) Detection of Ventricular Fibrillation and Tachycardia from the Surface ECG by a Set of Parameters Acquired from Four Methods. Physiological Measurement, 23, 629-634.
http://dx.doi.org/10.1088/0967-3334/23/4/303 - 9. Goldberger, A.L., et al. (2000) Physiobank, Physiotoolkit, and Physionet Components of a New Research Resource for Complex Physiologic Signals. Circulation, 101, e215-e220.
http://dx.doi.org/10.1161/01.cir.101.23.e215 - 10. Nolle, F.M. (1986) CREI-GARD: A New Concept in Computerized Arrhythmia Monitoring Systems. Computers in Cardiology, 13, 515-518.
- 11. Greenwald, S.D. (1986) Development and Analysis of a Ventricular Fibrillation Detector. M.S. Thesis, MIT Dept. of Electrical Engineering and Computer Science, Cambridge, MA.
- 12. Moody, G.B. and Mark, R.G. (2001) The Impact of the MIT-BIH Arrhythmia Database. IEEE Engineering in Medicine and Biology Magazine, 20, 45-50.
http://dx.doi.org/10.1109/51.932724 - 13. Li, Q. (2014) Ventricular Fibrillation and Tachycardia Classification Using a Machine Learning Approach. IEEE Transactions on Biomedical Engineering, 61, 1607-1613.
http://dx.doi.org/10.1109/TBME.2013.2275000 - 14. Amann, A. (2007) Detecting Ventricular Fibrillation by Time-Delay Methods. IEEE Transactions on Biomedical Engineering, 54, 174-177.
http://dx.doi.org/10.1109/TBME.2006.880909 - 15. Zhang, X.S. (1999) Detecting Ventricular Tachycardia and Fibrillation by Complexity Measure. IEEE Transactions on Biomedical Engineering, 46, 548-555.
http://dx.doi.org/10.1109/10.759055 - 16. Kuo, S. and Dillman, R. (1978) Computer Detection of Ventricular Fibrillation. IEEE Computers in Cardiology, 347- 349.
- 17. Barro, S. (1989) Algorithmic Sequential Decision Making in a Frequency Domain for Life Threatening Ventricular Arrhythmias and Imitative Artifacts: A Diagnostic System. Journal of Biomedical Engineering, 11, 320-328.
http://dx.doi.org/10.1016/0141-5425(89)90067-8 - 18. Kim, J. and Chu, C.H. (2014) ETD: An Extended Time Delay Algorithm for Ventricular Fibrillation Detection. Proceedings of the Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, 26-30 August 2014, 6479-6482.
- 19. Jekova, I. and Krasteva, V. (2004) Real Time Detection of Ventricular Fibrillation and Tachycardia. Physiological Measurement, 25, 1167-1178.
http://dx.doi.org/10.1088/0967-3334/25/5/007 - 20. Li, Q. (2008) Robust Heart Rate Estimation from Multiple Asynchronous Noisy Sources Using Signal Quality Indices and a Kalman Filter. Physiological Measurement, 29, 15-32.
http://dx.doi.org/10.1088/0967-3334/29/1/002 - 21. Arafat, M.A., Chowdhury, A.W. and Hasan, M.K. (2011) A Simple Time Domain Algorithm for the Detection of Ventricular Fibrillation in Electrocardiogram. Signal, Image and Video Processing, 5, 1-10.
http://dx.doi.org/10.1007/s11760-009-0136-1 - 22. Li, H. (2009) Detecting Ventricular Fibrillation by Fast Algorithm of Dynamic Sample Entropy. Proceedings of the IEEE International Conference on Robotics and Biomimetics, Guilin, 19-23 December 2009, 1105-1110.
http://dx.doi.org/10.1109/robio.2009.5420764 - 23. Breiman, L. (2001) Random Forests. Machine Learning, 45, 5-32.
http://dx.doi.org/10.1023/A:1010933404324 - 24. Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P. and Witten, I.H. (2009) The WEKA Data Mining Software: An Update. ACM SIGKDD Explorations Newsletter, 11, 10-18.
http://dx.doi.org/10.1145/1656274.1656278 - 25. Guyon, I., Gunn, S., Nikravesh, M. and Zadeh, L.A. (Eds.) (2008) Feature Extraction: Foundations and Applications. Springer, Vol. 207.
- 26. Alonso-Atienza, F., Morgado, E., Fernandez-Martinez, L., Garcia-Alberola, A. and Rojo-Alvarez, J.L. (2014) Detection of Life-Threatening Arrhythmias Using Feature Selection and Support Vector Machines. IEEE Transactions on Bio-medical Engineering, 61, 832-840.
http://dx.doi.org/10.1109/TBME.2013.2290800 - 27. Jekova, I. (2000) Comparison of Five Algorithms for the Detection of Ventricular Fibrillation from the Surface ECG. Physiological Measurement, 21, 429-439.
http://dx.doi.org/10.1088/0967-3334/21/4/301 - 28. Thakor, N.V. (1990) Ventricular Tachycardia and Fibrillation Detection by a Sequential Hypothesis Testing Algorithm. IEEE Transactions on Biomedical Engineering, 37, 837-843.
http://dx.doi.org/10.1109/10.58594 - 29. Kim, J.Y. and Chu, C.H. (2014) Analysis of Energy Consumption for Wearable ECG Devices. IEEE SENSORS 2014 Proceedings, Valencia, 2-5 November 2014, 962-965.
http://dx.doi.org/10.1109/ICSENS.2014.6985162