Intelligent Control and Automation
Vol.08 No.03(2017), Article ID:77696,15 pages
10.4236/ica.2017.83011
An Improvement on Data-Driven Pole Placement for State Feedback Control and Model Identification
Pyone Ei Ei Shwe1, Shigeru Yamamoto2
1Division of Electrical Engineering and Computer Science, Graduate School of Natural Science and Technology, Kanazawa University, Kanazawa, Japan
2Faculty of Electrical and Computer Engineering, Institute of Science and Engineering, Kanazawa University, Kanazawa, Japan
Email: pyone@moccos.ec.t.kanazawa-u.ac.jp, shigeru@se.kanazawa-u.ac.jp
Copyright © 2017 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/



Received: May 25, 2017; Accepted: July 15, 2017; Published: July 18, 2017
ABSTRACT
The recently proposed data-driven pole placement method is able to make use of measurement data to simultaneously identify a state space model and derive pole placement state feedback gain. It can achieve this precisely for systems that are linear time-invariant and for which noiseless measurement datasets are available. However, for nonlinear systems, and/or when the only noisy measurement datasets available contain noise, this approach is unable to yield satisfactory results. In this study, we investigated the effect on data-dri- ven pole placement performance of introducing a prefilter to reduce the noise present in datasets. Using numerical simulations of a self-balancing robot, we demonstrated the important role that prefiltering can play in reducing the interference caused by noise.
Keywords:
Data-Driven Control, State Feedback, Pole Placement, Nonlinear Systems

1. Introduction
In state feedback pole placement, the state feedback gain must be determined for a given system such that the closed-loop poles coincide with the desired locations. This is a well-known problem, and the pole placement methods have been extensively discussed in the literature [1] [2] [3] [4] . In standard pole placement methods, a state space model is assumed to be given by a system identification technique using data from past experiments. Whereas the traditional approach combines the identification of the state space model with the standard pole placement method; an alternative approach called “data-driven pole placement” has recently been proposed [5] . In this approach, the state space model and pole placement feedback gain are identified simultaneously from the set of state measurements and control input sequences. The method proposed in [5] is based on the data-driven control framework ( [6] and references therein) such as unfalsified control [7] , virtual reference feedback tuning (VRFT) [8] [9] , or fictitious reference iterative tuning (FRIT) [10] [11] [12] [13] . In the data-driven control framework, where no explicit mathematical plant model is used, a feedback controller must be derived that satisfies the prescribed closed-loop performance and fits to known experimental data. In contrast with traditional model-based controller designs, techniques such as controller identification [14] or a combination of plant model and controller identification must be applied [15] [16] .
Many studies of data-driven control have focused on output feedback control and data-driven state feedback control [11] [12] [13] , in which the prescribed closed-loop performance is achieved by applying a closed-loop reference transfer function. Such methods can be applied to the data-driven pole placement problem by choosing a reference transfer function with the desired poles. However, the zeros of the reference transfer function cannot normally be specified, because the zeros of the plant are unknown. In contrast, the data-driven pole placement method presented in [5] requires only a state space representation of the closed- loop system to specify the prescribed closed-loop performance, as shown in Section 2. This avoids the zero assignment issue that arises in the transfer function approach used in [5] .
This data-driven pole placement method can, therefore, be applied to linear and time-invariant systems with measurable states. The method is briefly reviewed in Section 2. However, the capacity of the data-driven pole placement method to handle noise remains an open issue, though in [5] , the total least square (TLS) method [17] was claimed to be effective. Measurement noise is one of the issues which may surely face in practical applications. Therefore, to resolve this, we introduced a prefiltering technique that reduces the effect of measurement noise in Section 3. More specifically, a finite impulse response (FIR) filter is used to prefilter the data, as this makes them easier to manipulate. In Section 4, by using the numerical example of a self-balancing robot, we discuss the effect of applying this prefiltering technique, together with the least square (LS) and TLS methods, to a self-balancing robot model. We investigate the ability of the data-driven pole placement method to produce a linearized model using numerical simulations as in [18] . A nonlinear differential equation was used to represent the dynamics of a self-balancing robot there. Moreover, we evaluate the effects by two different exciting signals, the random and the chirp exciting signal, along with TLS and prefiltering. Finally, we compare all the results for the pole placement error and identification error when two exciting signals are applied.
Notation: Let and be and matrices, respectively. Then, the Kronecker product of and is a matrix, defined as follow:
(1)
where is the element of . The vectorization of then stacks the columns into a vector:
(2)
in which is the column of . The Frobenius norm of matrix is defined as
(3)
2. Data-Driven Pole Placement
In this section, we briefly review the data-driven pole placement method formulated in [5] .
Consider a discrete-time linear time-invariant system and static state feedback
(4)
(5)
where is the state vector, is the input vector, is the feedback gain, and is the external input to the closed loop system.
The data-driven pole placement problem was formulated in [5] as follows:
Problem 1. We assume that the order of the plant n is known, state n is measurable, pair is controllable but the exact value is unknown and is of full rank. Let be a self-conjugate set of n complex numbers in the unit circle. Given the input and output measurement data sequence of (4), find a state feedback gain from the observed data such that
In a conventional approach, this problem is solved in two steps: and are identified from , then is derived using the standard pole placement algorithms. In contrast, the data-driven pole placement method solves the two steps simultaneously. To achieve this, the method uses the equivalency between the closed-loop system
(6)
with the desired pole placement gain and
(7)
(8)
where with is an appropriate controllable pair. This equivalency requires the nonsingular matrix to exist. Then, we remove from (7) by using (5), to obtain
(9)
Then, using (8), we obtain
(10)
If satisfies (10),
(11)
where
(12)
(13)
(14)
In [5] , Equation (11) is cast into
(15)
(16)
and
(17)
Remark 1. The system in (7) can be interpreted as a reference model within VRFT (e.g., [8] [9] ) and FRIT (e.g., [10] [11] [12] [13] ). The idea of eliminating in (9) is also based on FRIT. In [10] [11] [12] , a similar state feedback control problem has been discussed within the FRIT framework. To apply these FRIT techniques to the data-driven pole placement problem, the desired transfer function must be specified from to , rather than . When precise values for are not available, it becomes impossible to specify the zeros of the desired transfer function.
Remark 2. To obtain the datasets in (12) by applying state feedback in (5) to the system in (4), the initial feedback gain should be based on . Hence, in Problem 1, the exact value of is assumed to be unknown.
When applying the property of Kronecker product (see for example Th.2.13 in [19] ) to the transpose of (15) to solve (15) for and , a further linear equation is derived, as follows:
(18)
where
(19)
(20)
(21)
If is nonsingular, the model coefficients can be obtained
(22)
3. Prefiltering Noisy Measurement
When the measurement of is contaminated by noise ,
(23)
Then, (10) becomes
(24)
Hence, if satisfies the above equation,
(25)
where
(26)
Then, the resulting linear equation is given as
(27)
where the effect of noise has the same structure as in (20), then
(28)
and is the equation error. Following [5] , we can solve to (27) as a TLS problem [17] , by minimizing the Frobenius norm . It is known that the TLS solution is given as
(29)
based on the singular value decomposition
(30)
where these matrices are partitioned into blocks corresponding to and .
Here, we assume that there exists such that
(31)
for all . This means that when
(32)
for the matrix
(33)
where each column has elements of 1. Therefore,
(34)
where
(35)
This multiplication by represents the prefiltering of signals via an order FIR filter.
When the systems (4) and (7) are driven by the exciting signal, we have
(36)
(37)
(38)
(39)
where
(40)
(41)
By applying to these systems, we obtain
(42)
(43)
(44)
(45)
Here, if , (34) cannot be satisfied. Hence, for all i, , that is
(46)
must be satisfied.
4. Numerical Example: Self-Balancing Robot
We next applied the data-driven pole placement method described above to the model of a self-balancing robot [21] [20] as shown in Figure 1. The robot is equipped with right and left wheels driven by direct current (DC) motors whose voltages and can be controlled. Because the motion dynamics can be decomposed by the input , the control input to the robot was represented as
(47)

Figure 1. (a) Coordinates of the self-balancing robot; (b) photo.
We assume that the pitch angle and the pitch angular velocity of the body could be measured, as well as the angles and of the right and left wheels, and their angular velocities and , respectively. We define the mean values of the right and left wheel angles and , and the yaw angle of the body as follows:
(48)
(49)
where is the radius of the wheel and is the distance between the two wheels.
4.1. Equation of Motion
The equation of motion for the self-balancing robot can be derived as
(50)
where
The symbols are explained in Table 1. The parameters used in the simulations were taken from [20] [21] .

Table 1. Parameters of the self-balancing robot [20] [21] .
4.2. Linear Model and Feedback Gain
We linearized the equations of motion (50) around equilibrium states , , , , , , and . Then, under the assumption that , , , , , and , the linearized equations of motion can be derived as
(51)
where
(52)
(53)
By defining the state vector
(54)
the linear state space model can be derived as
(55)
where
Then, the feedback can be independently designed as
(56)
Note that this can be more succinctly represented as
(57)
(58)
When the parameters in Table 1 are used and the sampling period is , the discrete-time model after discretizing (55) is
(59)
where
(60)
Here, we assume that the exact values of (60) are not available, but that uncertain values are available:
(61)
The coefficients can be derived from , with an assumed uncertainty of 10%. By applying linear quadratic optimal control theory to (61), the desired closed-loop pole locations can be chosen as
, (62)
, (63)
and the initial feedback gains needed to obtain datasets for the data-driven pole placement as
(64)
4.3. Comparison of Methods
Next, simulations were conducted and comparisons were made from the obtained results when using different methods and exciting signals.
Measurement noise was prepared with the Gaussian distribution , where , and in , , and , respectively. This is shown in Figure 2(a). We used the random exciting signal shown in Figure 3(a) and the linear chirp signal shown in Figure 3(b) with the uniform distribution and . We set the order of the prefilter (33) as . After prefiltering, the measurement noise in , , and was reduced, as shown in Figure 2(b). The prefiltered exciting signals were shown in Figure 3(b) and Figure 3(d). It can be seen that the exciting signals were not eliminated by prefilter , but that the high-frequency elements were reduced.
A closed-loop response in the presence of measurement noise by state feedback (56), with initial gain (64), is shown in Figure 4. The response to the random exciting signal and the chirp exciting signal are shown in Figure 4(a) and Figure 4(b), respectively. Of particular note is that the responses of , , and in Figure 4(b) show the high-pass filter-like gain characteristics of the transfer function from to .
For comparison, the dataset for the data-driven pole placement was chosen as where and .
To evaluate the obtained pole placement gain , we introduced an accuracy measurement that takes the largest absolute difference in value between each eigenvalue of and the corresponding ,
(65)

Figure 2. (a) Measurement noise; (b) Prefiltered measurement noise.

Figure 3. Exciting signal (a) random, (b) chirp, (c) prefiltered random, (d) prefiltered chirp.

Figure 4. Closed-loop response by an initial state feedback via (a) random exciting signal (b) chirp exciting signal .
To evaluate the obtained model , the following identification errors were used:
(66)
(67)
The eigenvalues were sorted by magnitude using the MATLAB command “sort”. This further sorts elements of equal magnitude by the phase angle on the interval . The impulse response was used to evaluate the model obtained, as follows:
(68)
where and are the impulse responses of and , respectively.
From the perspective of system control, smaller is better, particularly in the case of , , and . The following key results were contrastively found in Table 2:
1) The initial model and feedback gain were affected by uncertainty: The model errors and pole placement errors are shown in Table 2 (initial).
2) The results when using the LS method to solve linear Equation (27) for noiseless data are shown in Table 2(a). All errors were reasonably small, confirming that the data-driven method performs well when the measurement data are noiseless.
3) The results when using the LS method to solve linear Equation (27) for noisy data are shown in Table 2(b). All errors became larger when noise was added, suggesting that LS analysis is inadequate when the measurement data are contaminated by noise.
4) The results when using the TLS method to solve linear Equation (27) are shown in Table 2(c). The errors were significantly smaller than those reported in [5] , using the LS method.
5) The results when applying prefiltering (PF) and using the TLS method to
Table 2. Comparison of errors.
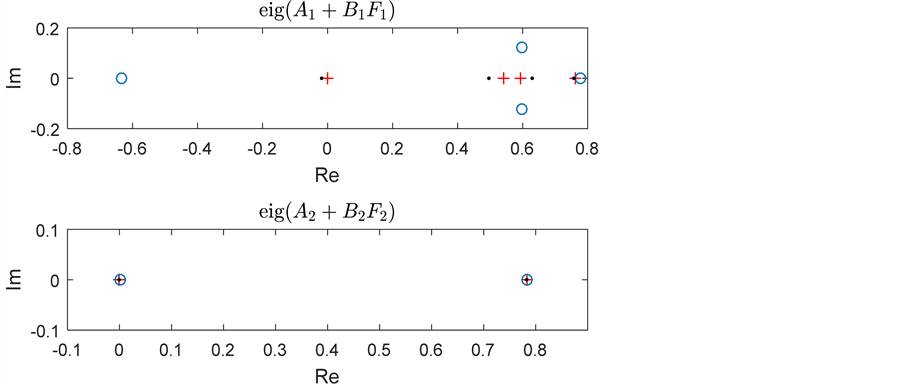
Figure 5. Comparison of pole locations (“+” indicates the desired poles, “.” those obtained by the random exciting signal and “o” those obtained by the chirp exciting signal.).
solve linear Equation (27) are shown in Table 2(d). The prefilter further reduced the errors, in particular, the pole placement error and the impulse response error .
6) The results when applying PF and using the TLS method to solve the linear Equation (27), but with as the chirp signal, are shown in Table 2(e). No significant improvement in error rates was found with respect to when using the chirp exciting signal. However, the errors with respect to became significantly worse than when a random exciting signal was used. This was assumed to be because has an unstable eigenvalue of 1.7838. We conclude that a random exciting signal is more appropriate than a chirp exciting signal when using data-driven methods.
Finally, we compare the pole locations obtained as shown in Figure 5. As can be seen, a better performance was achieved when using the random exciting signal.
5. Conclusion
In this study, we evaluated the different approaches reducing the effect of measurement noise in data-driven pole placement methods for deriving a state space model and pole placement state feedback. Using numerical simulations of a self-balancing robot, which is a nonlinear system, we demonstrated the important role that prefiltering can play in reducing the interference caused by noise. Again using numerical simulation, we compared the use of two exciting signals: a random signal and a chirp signal. The use of a random exciting signal was found to be more effective with our proposed method. Further developments are needed in the methods used to cope with noise. A method such as that used in [9] may be appropriate for use in practical applications where noise is present, and adaptive control based on real-time updating [22] is a future promising approach.
Acknowledgements
This work was partially supported by JSPS KAKENHI Grant Number 16H04385.
Cite this paper
Shwe, P.E.E. and Yamamoto, S. (2017) An Improvement on Data-Driven Pole Placement for State Feedback Control and Model Identification. Intelligent Control and Automation, 8, 139-153. http://dx.doi.org/10.4236/ica.2017.83011
References
- 1. Wonham, W.M. (1967) On Pole Assignment in Multi-input Controllable Linear Systems. IEEE Transaction on Automatic Control, 12, 660-665. https://doi.org/10.1109/TAC.1967.1098739
- 2. Ackermann, J.E. (1977) On the Synthesis of Linear Control Systems with Specified Characteristics. Automatica, 13, 89-94.
- 3. Kimura, H. (1975) Pole Assignment by Gain Output Feedback. IEEE Transaction Automatic Control, 20, 509-516. https://doi.org/10.1109/TAC.1975.1101028
- 4. Hikita, H., Koyama, S. and Miura, R. (1975) The Redundancy of Feedback Gain Matrix and the Derivation of Low Feedback Gain Matrix in Pole Assignment. The Society of Instrument and Control Engineers, 11, 556-560. (In Japanese)
- 5. Yamamoto, S., Okano, Y. and Kaneko, O. (2016) A Data-driven Pole Placement Method Simultaneously Identifying a State Space Model. Transaction of the Institute of Systems, Control and Information Engineers, 29, 275-284. (In Japanese)
- 6. Hou, Z.S. and Wang, Z. (2013) From Model-Based Control to Data-Driven Control: Survey. Classification and Perspective, Information Sciences, 235, 3-35.
- 7. Safonov, M.G. and Tsao, T.C. (1997) The Unfalsified Control Concept and Learning. IEEE Transactions on Automatic Control, 42, 843-847. https://doi.org/10.1109/9.587340
- 8. Campi, M.C., Lecchini, A. and Savaresi, S.M. (2002) Virtual Reference Feedback Tuning: A Direct Method for the Design of Feedback Controllers. Automatica, 38, 1337-1346.
- 9. Sala, A. and Esparza, A. (2005) Extensions to “Virtual Reference Feedback Tuning: A Direct Method for the Design of Feedback Controllers”. Automatica, 41, 1473-1476.
- 10. Souma, S., Kaneko, O. and Fujii, T. (2004) A New Method of a Controller Parameter Tuning Based on Input-output Data-Fictitious Reference Iterative Tuning. Proceedings of the 2nd IFAC Workshop on Adaptation and Learning in Control and Signal Processing, 37, 789-794.
- 11. Matsui, Y., Akamatsu, S., Kimura, T., Nakano, K. and Sakurama, K. (2011) Fictitious Reference Iterative Tuning for State Feedback Control of Inverted Pendulum with Inertia Rotor. SICE Annual Conference, Tokyo, 13-18 September 2011, 1087-1092.
- 12. Matsui, Y., Akamatsu, S., Kimura, T., Nakano, K. and Sakurama, K. (2014) An Application of Fictitious Reference Iterative Tuning to State Feedback, Electronics and Communications in Japan, 97, 1-11. https://doi.org/10.1002/ecj.11506
- 13. Kaneko, O. (2015) The Canonical Controller Approach to Data-Driven Update of State Feedback Gain. Proceedings of the 10th Asian Control Conference 2015 (ASCC 2015), Kota Kinabalu, 31 May-3 June 2015, 2980-2985. https://doi.org/10.1109/ASCC.2015.7244744
- 14. Van Heusden, K., Karimi, A. and Soderstrom, T. (2011) Extensions to “On Identification Methods for Direct Data-Driven Controller Tuning”. International Journal of Adaptive Control and Signal Processing, 25, 448-465. https://doi.org/10.1002/acs.1213
- 15. Kaneko, O., Miyachi, M. and Fujii, T. (2008) Simultaneous Updating of a Model and a Controller Based on the Data-Driven Fictitious Controller. 47th IEEE Conference on Decision and Control, Cancun, 9-11 December 2008, 1358-1363.
- 16. Kaneko, O., Miyachi, M. and Fujii, T. (2011) Simultaneous Updating of Model and Controller Based on Fictitious Reference Iterative Tuning. SICE Journal of Control, Measurement, and System Integration, 4, 63-70. https://doi.org/10.9746/jcmsi.4.63
- 17. Markovsky, I. and Huffel, S.V. (2007) Overview of Total Least-Squares Methods. Signal Processing, 87, 2283-2302.
- 18. Shwe, P.E.E. and Yamamoto, S. (2016) Data-Driven Method to Simultaneously Obtain a Linearized State Space Model and Pole Placement Gain. Proceedings of the 3rd Multi Symposium on Control Systems, Nagoya, 7-10 March 2016, 3B3-2.
- 19. Brewer, J. (1978) Kronecker Products and Matrix Calculus in System Theory. IEEE Transactions on Circuits and Systems, 25, 772-781. https://doi.org/10.1109/TCS.1978.1084534
- 20. ZMP Inc. Stabilization and Control of Stable Running of the Wheeled Inverted Pendulum, Development of Educational Wheeled Inverted Robot e-nuvo WHEEL ver.1.0. http://www.zmp.co.jp/e-nuvo/
- 21. Nomura, T., Kitsuka, Y., Suemitsu, H. and Matsuo, T. (2009) Adaptive Back Stepping Control for a Two-Wheeled Autonomous Robot. Proceedings of ICCAS-SICE, Fukuoka, 18-21 August 2009, 4687-4692.
- 22. Shwe, P.E.E. and Yamamoto, S. (2016) Real-Time Simultaneously Updating a Linearized State-Space Model and Pole Placement Gain. Proceedings of SICE Annual Conference, Tsukuba, 20-23 September 2016, 196-201.