Applied Mathematics
Vol.06 No.14(2015), Article ID:62089,9 pages
10.4236/am.2015.614195
Analysis of KCSE Performance in Nakuru County: A Generalized Estimating Equations Approach
Elvis Karanja Muchene, Nelson Onyango Owuor
School of Mathematics, College of Biological and Physical Sciences, University of Nairobi, Nairobi, Kenya

Copyright © 2015 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 28 October 2015; accepted 18 December 2015; published 21 December 2015
ABSTRACT
In Kenya, the Ministry of Education has set the pass mark for university entry examination as C plus and above. Using publicly available data for 2006-2010, differences in KCSE performance amongst the three types of schools in Kenya―boys only, girls only, and mixed schools―was assessed. A generalized estimating equations marginal model was applied in order to account for association between scores within a school in the five year period. To account for the missing data, multiple imputation was performed followed by estimation and inference. Results indicated that there was a significant difference between the three type of schools in their candidates’ odds of attaining the stipulated minimum university entry grade. However, the odds of success in KCSE did not depend on the year under review as was evident in the slope parameters which was not statistically significant. Although it was clear that same-gender schools perform better than mixed gender schools, there is need to weigh the social benefits of mixed-schools against respective performance in KCSE. This should guide the policy makers on the way forward with regards to the education policy in Nakuru County.
Keywords:
Generalized Estimating Equations, Kenya Certificate of Secondary Education, Mixed Schools

1. Introduction
In the Kenyan education system, progression to tertiary education is dependent on a standardized examination administered by the Kenya National Examinations Council (KNEC). Subsequently, candidates who successfully sit for the requisite examination papers are awarded the Kenya Certificate of Secondary Education (KCSE). The Ministry of Education guidelines stipulate that the pass mark for KCSE is a mean grade of C plus (commonly denoted C+) and above, which corresponds to a minimum of six points on a twelve point grading scale, with the twelve points corresponding to the highest possible score (A Plain). A student who scores C+ or higher is deemed eligible for direct admittance to a university program [1] .
Every year around February-March, a ceremony headed by the Minister for Education is held, where KCSE results from the preceding year are released. Until the year 2014, the release of KCSE results included ranking of the students performance individually, (best 100 candidates in each province and nationally by gender) as well as the ranking of schools based on the mean grade of the schools’ candidates. This ranking mostly stimulated fierce competition amongst schools in a bid to outperform each other in the subsequent examinations [2] . Some schools were consistent over the years in terms of their ranking while one-time-wonders were also a common occurrence [3] . However, the ranking of schools was purely based on candidates’ KCSE performance thus ignoring other factors such as the facilities available to schools, their secondary school exam entry marks [3] [4] , potential temporal variations in schools’ performance amongst others. Moreover, at face value, the ranking popularly reported by the Ministry of Education does not form a good scientific basis for comparison of performance across boys only, girls only or mixed schools.
Performance in the KCSE examination varies across the country depending on factors such as classification of a school as either national or county; the number of candidates in a school; whether the school is boys only, girls only or of mixed gender; available facilities for teaching; location of a school in terms of political stability in the region amongst a myriad of other factors. There have been few published results on statistical analyses of the KCSE performance in all examinable subjects as a whole. The available published materials have focused on factors affecting KCSE performance in mathematics in diverse regions in Kenya [5] [6] . Mburu et al. [7] performed a descriptive survey research to investigate the influence of the type of school on gender differences in KCSE performance in Kericho and Kipkelion districts in the 2010 KCSE examinations. However, they performed a descriptive analysis that did not provide a mechanism to evaluate the potential temporal effect on KCSE performance which we evaluate in this article.
To fill in this gap in literature, we assess the temporal effect of the reported performance of schools between the year 2006 and 2010 in Nakuru County. The choice of this period under review is based on the fact that the data publicly availed by the Kenyan government only covers this period. We propose to fit a marginal model, specifically the Generalized Estimating Equations (GEE) of Liang and Zeger [8] , in order to account for potential correlation between outcomes of any given school in the five year period. More specifically, the study aims to establish if there exists significant difference in overall KCSE performance between mixed schools, Boys only schools and Girls only schools in Nakuru County. In so doing, we seek to establish if performance differs significantly between boys or girls in one-gender schools compared to their counterparts in mixed schools. The outcome of this analysis will provide evidence-based insights to education policy makers as well as other relevant education stakeholders in Nakuru County government.
The paper is structured as follows; In Section 2, an overview of the dataset used in this analysis is presented. Section 3 provides an overview of the proposed statistical methodology while the results of the GEE analysis are presented in Section 4. Finally, in Section 5 we give a brief discussion of the main findings.
2. KCSE 2006-2010 Data
Longitudinal data on Kenya Certificate of Secondary Education (KCSE) performance was obtained from the Kenyan government open data website for the period 2006-20101. Although statistical analysis on a more recent review period would have been more interesting, the 2006-2010 review period was due to the fact that this is the only dataset that has been made publicly available by the Kenyan government. The study covered 237 unique schools within Nakuru district for the 5 year period with atleast one year of data available. Table 1 presents an overview of the number of schools of each type in the five-year period.
For each school, information was available on the number of students of a particular gender who attained a particular mean grade. Using the gender composition for a given school, the type of school was specified as boys’ school only, girls’ school only or a mixed gender school. The outcome of interest was defined as the proportion of students of each gender who attained a mean grade of C plus and above on a 12 point scale, where the highest score was an A plain and the lowest score was an E (1 point).
Figure 1 presents the school specific evolution profiles of the proportion of students who passed in the KCSE (attained the minimum university entry grade). The dataset had a high rate of missingness mainly attributed to the incomplete data provided by the Kenyan government. Considering the high rate of completion of secondary education in Kenya, it is highly unlikely that schools with missing data did not have candidates registered in that particular year. The missing data pattern was non-monotone which poses additional challenges in the analysis.
The average evolution profile for each gender in the three school types is shown in Figure 2. On average, the lowest proportion of students who attained the minimum university entry grade was from mixed schools with girls in this category performing even poorer than their male counterparts. There seems to be minimal temporal effect on the proportion of students who passed. The significance of the time effect will however be evaluated via appropriate statistical modelling tools.
3. Statistical Methodology
Let
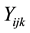 be the proportion of students who passed (attained the minimum university requirements) from school
be the proportion of students who passed (attained the minimum university requirements) from school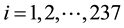 , in time
, in time
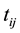 (
( for 2006-2010). Further, let
for 2006-2010). Further, let
 be the school-type and gender specific indicator for boys from boys only school, girls from girls only school, boys from mixed schools and girls from mixed schools respectively. The variable
be the school-type and gender specific indicator for boys from boys only school, girls from girls only school, boys from mixed schools and girls from mixed schools respectively. The variable
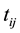 was obtained by subtracting 2006 from each year so as to ease model convergence and to ensure that the model intercepts had a meaningful interpretation (probability of success in the year 2006). The marginal model for the probability of success (attaining a C plus or higher) is denoted as:
was obtained by subtracting 2006 from each year so as to ease model convergence and to ensure that the model intercepts had a meaningful interpretation (probability of success in the year 2006). The marginal model for the probability of success (attaining a C plus or higher) is denoted as:

Table 1. Overview of the case study data.

Figure 1. School-specific profiles for the proportion of students that passed over the five year period (2006-2010). The left column panels represents data for girls while the right column panels represents data for boys.

Figure 2. Average profiles for the proportion of students that passed over the five year period (2006- 2010). Its observed that on average, boys from boys schools have a higher pass rate over the years. Girls from mixed schools have a lower pass rate compared to boys from mixed schools. Moreover, for a given school type and gender, the pass-rate seems relatively constant over the years.
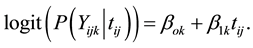 (1)
(1)
where
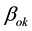 are the gender-specific intercepts for the three types of school and
are the gender-specific intercepts for the three types of school and
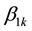 are the gender-specific linear slope coefficient for each school type.
are the gender-specific linear slope coefficient for each school type.
The generalized linear model [9] specified in (1) implies fitting a linear profile for each of the school-type and gender categories as visualized in Figure 2. The corresponding decomposition of the linear equations is shown in (2);
 (2)
(2)
Generalized estimating equations (GEE) are an extension of generalized linear models (GLMs) to account for within cluster correlation amongst outcomes of the same school in the five-year period [8] [10] . Consider the vector of ni (of possibly correlated) outcomes Yi for the ith school. The within-cluster variance is defined as;
 (3)
(3)
where
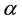 is a vector of parameters describing the within-subject correlation,
is a vector of parameters describing the within-subject correlation,
 is an over-dispersion parameter and
is an over-dispersion parameter and
 is the working correlation matrix to model the within cluster observations. The choice of a working correlation structure Ri has been a subject of debate. One of the key properties of GEE is that, provided the mean structure (1) is correctly specified, valid inference for the covariance of
is the working correlation matrix to model the within cluster observations. The choice of a working correlation structure Ri has been a subject of debate. One of the key properties of GEE is that, provided the mean structure (1) is correctly specified, valid inference for the covariance of
 is obtained even when the working correlation is misspecified [10] . While the Quasi-likelihood under independence (QIC) criterion [11] is widely used for the selection of the working correlation, the method has been shown to result in reduced relative efficiency of parameter estimates when the covariance structure is misspecified [12] . An alternative suggestion on the choice of the working correlation structure based on further modification of QIC is the correlation information criterion (CIC) [13] . As currently implemented in the SAS Macro CriteriaWorkCorr, CIC can not applied in the KCSE dataset since it requires data with monotone missingness.
is obtained even when the working correlation is misspecified [10] . While the Quasi-likelihood under independence (QIC) criterion [11] is widely used for the selection of the working correlation, the method has been shown to result in reduced relative efficiency of parameter estimates when the covariance structure is misspecified [12] . An alternative suggestion on the choice of the working correlation structure based on further modification of QIC is the correlation information criterion (CIC) [13] . As currently implemented in the SAS Macro CriteriaWorkCorr, CIC can not applied in the KCSE dataset since it requires data with monotone missingness.
Another point worth considering is the fact that, with GEE, valid inference is only obtained when the data is missing completely at random (MCAR) [14] . According to Zorn et al. [15] , valid inferences for GEE estimators can only be obtained from data which is missing completely at random. When the data is Missing at Random (MAR), GEE might result in biased estimates. For dropout missing mechanism, weighted GEE tackles the MAR problem and results in unbiased estimates [16] [17] . Nonmonotone (intermittent) missingness pattern poses additional difficulties in computing propensity scores (weights) used in weighted GEE [18] . Instead, we apply multiple imputation of missing data [19] -[21] the KCSE data. In the imputation step, five complete datasets are generated using SAS PROC MI, which are then used as input for the analysis step in a classical GEE analysis using PROC GENMOD. In fitting this model, the mean is specified as shown in (1), while an unstructured working correlation matrix is specified. The results of the five analyses are combined into one final output for inference using SAS PROC MIANAYZE.
4. Results
As a starting point, model (1) is fitted to the observed data before multiple imputation although the resulting output may be biased. Results shown in Table 2 were obtained under a Compound Symmetry (CS) working correlation matrix. This was a pragmatic choice since a model with an unstructured working correlation matrix did not attain convergence and formal covariance selection criteria such as CIC could not be applied on the data with intermittent missingness. The intra-cluster correlation coefficient for scores observed within a school was high at .
.
Since the time effects were not statistically significant, we performed contrasts only on the intercepts as shown in Table 3. From the 95% confidence intervals, all contrasts are statistically significant.
Rather than use these results for inference, multiple imputation was performed and analysis performed on the imputed datasets. Bayesian Monte-Carlo Multiple Chain (MCMC) simulation was used to impute the missing number of students who passed as well as those who failed in a given school. SAS PROC MI was applied with the fully conditional imputation method based on predictive mean matching algorithm with k = 5 closest observations used for imputation. The resulting complete dataset was then used for computing the proportion of students who passed. Four new datasets were generated during this imputation step. Figure 3 presents the individual profile plot from the first imputed dataset.
The analysis step involved fitting (1) in each of the four dataset using classical GEE fitting tools. To this end, SAS PROC GENMOD with an unstructured working correlation matrix was specified. Moreover, contrasts of
Table 2. GEE: Parameter estimates from the observed data model with compound symmetry.
Table 3. GEE: Contrasts for the intercept parameters corresponding to effect size in the year 2006.

Figure 3. Multiple imputation: Individual evolution profiles for the first imputed dataset.
interest comparing the intercepts and slope coefficient respectively for the three types of schools were specified with appropriately defined ESTIMATE statements. The final step in the analysis entailed combining the results of each imputed dataset for final inference. SAS PROC MIANALYZE achieved this easily for the final estimates of fixed effects and contrasts thereof. For the covariance matrix however, SAS output for the working correlation matrix does not include any standard errors. This renders it impossible to use MIANALYZE to account for within and between imputation variability in estimating the overall covariance matrix.
Parameter estimates for fixed effects are shown in Table 4. A slightly different parametrization of the model was adopted in order to achieve error-free estimation during the combination step. As shown in Table 4, females from mixed schools were set as the reference group, from which effects of girls only schools and males was evaluated. The odds of girls from mixed schools attaining the stipulated pass mark in 2006 were exp(−0.959) = 0.383. Compared to girls from mixed schools, boys from mixed schools had a 1.65 times higher odd of success exp(0.502). Similarly, girls from girls only school had a exp(0.667) = 1.95 odds of passing compared to girls from mixed schools, while boys in mixed schools had a 3.62 higher odds of passing compared to girls from mixed schools in the year 2006. On the other hand, temporal effects were not statistically significant since the 95% confidence intervals included zero. This therefore implies that the performance of a school was relatively constant over time.
Table 5 presents the combined results of the contrasts of interest from the four imputations while the working correlation matrices for the imputed data sets are presented in Table 6. Results for some of these contrasts were already obtained directly from the parameter estimates in Table 4. The additional contrast for boys from boys only schools versus boys in mixed schools indicates that being in boys only school results in a 2.19 times the odd of passing.
Comparing the imputation results with classical GEE without accounting for missing information, particularly for the contrasts presented in Table 3 and Table 5, there was clearly a huge difference in both the estimated contrast coefficient and the corresponding standard error. This naturally impacts on inference in that, without adjusting for missing information, we conclude that there is a higher effect of gender and type of school (based on the magnitude of the odds ratio) compared to an analysis accounting for the missing information.
Finally, the covariance matrix for measurements within a school for the five year period were obtained for each imputed dataset. However, since we could not combine the four covariance matrices directly, we present them in 5 for comparison purposes. Correlation for measurements far apart in time was lower than for measurements close in time.
Table 4. Multiple imputation: Parameter estimates for the combined datasets after multiple imputation.
Table 5. Multiple imputation: Contrasts of interest. Log (OR) 95% confidence limits (CL) not including zero are not statistically significant. Equivalently, OR 95% confidence limits (CL) not including 1 are not statistically significant.
Table 6. Multiple imputation: Working correlation matrices from the imputed datasets.
5. Discussion
The aim of this study was to gain insights on KCSE performance in Nakuru County, while focusing on the relationship between performance of boys and girls in single-gender versus mixed schools over the five year period under review. The KCSE examinations, being the only approved university entry examinations in Kenya, play a big role in moulding the future skilled workforce. Considering the need to provide equal opportunities for both boys and girls, there is need for an evaluation of the disparities that exist in the education sector so as to provide adequate remedial measures. While most of the past research on KCSE performance has focused on performance of both boys and girls in sciences and mathematics, little has been done to compare the overall performance taking into account temporal variations.
The goal of the analysis presented in this article was twofold. First, the need to evaluate performance for more than one year imposes potential correlation in the performance of a given school over time. This is accounted for by fitting a marginal generalized linear model. Secondly, it is possible that over time, different categories of schools may change, either due to a “learning effect” where schools learn from their “past mistakes” hence improve, or generally due to policy changes in the education sector amongst a myriad of other factors.
However, the results of this analysis did not reveal any significant effect of time in the performance of boys and girls in same-gender or mixed schools. Possible reason for this can be the fact that, with the classification of schools as either national, county or even local day schools, admission to these schools is based on a standardized examination (the Kenya Certificate of Primary Education, KCPE) and different schools only admit students meeting a certain threshold. This therefore implies that a school admits a relatively homogeneous lot of students every year, in terms of their academic abilities; hence, there is a limit beyond which these students exceed in terms of academic performance. Thus, national schools, which admit the best performers in KCPE, continue to register constantly higher pass-rates compared to county schools. Future analyses should therefore possibly adjust for this classification of schools in evaluating performance.
With regards to same-gender versus mixed schools, as has been shown in other unrelated studies of performance in examinations, both in Kenya and abroad, girls in mixed schools do not realize their full potential, probably due to inferiority complex while co-studying with boys. Nationally, this is even more evident from the fact that the best schools overall are mostly same gender schools. Moreover, boys in mixed schools do not achieve their full potential compared to their counterparts in boys-only schools.
From a policy formulation perspective, rather than blatantly dissolve all mixed-gender schools, an objective analysis ought to be performed on how best to bring the performance of boys and girls at par with their counterparts in same-gender schools. This is due to the fact that mixed schools provide a natural setting that students will always be exposed to in their future lives. For instance, workplaces are rarely defined as one-gender environments, family composition almost always entails interacting with both genders and even more, social interactions cannot be limited to one gender only. One possible ways to boost performance in mixed schools was what was piloted in Nakuru High School. Being a mixed school on paper, the school administration actually separated boys from girls during teaching activities. Each gender attended separate classes, albleit from the same teachers, and only integrated during co-curricular activities on a daily basis. This approach not only fostered direct competition between boys and girls, but also provided an opportunity for teachers to dedicate more resources where needed to boost girls performance. The obvious shortcoming of this approach however, is the duplication of resources and therefore the implication in terms of cost and time.
The analysis also presented a challenge with availability of appropriate records from government institutions. Although the initiative to provide an open data platform was noble, the government of Kenya has failed in updating the database with up to date information in terms of being current and complete. Multiple imputations performed in this analysis to fill in the gaps would not have been necessary, had there been complete data. Data- driven decision making is a growing trend and with the massive data being hoarded by the Kenyan government, a lot more information can be derived to guide policy formulation especially in education.
Cite this paper
Elvis KaranjaMuchene,Nelson OnyangoOwuor, (2015) Analysis of KCSE Performance in Nakuru County: A Generalized Estimating Equations Approach. Applied Mathematics,06,2217-2225. doi: 10.4236/am.2015.614195
References
- 1. Eshiwani, G. (1993) Education in Kenya since Independence. East African Educational Publishers, Nairobi.
- 2. Wanyama, I. and Njeru, E. (2004) The Sociology of Private Tuition. Discussion Paper, Institute of Policy Analysis and Research, Nairobi.
- 3. Amunga, J.K., Amadalo, M.M. and Maiyo, J.K. (2010) Ranking of Secondary Schools and Students in National Examinations: The Perception of Teachers and Students. Problems of Education in the 21st Century, 20, 10-24.
- 4. K. C. of Inquiry into the Education System of Kenya and D. Koech, Totally Integrated Quality Education and Training, TIQET: Report of the Commission of Inquiry into the Education System of Kenya. Republic of Kenya, 1999.
- 5. Mbugua, Z.K., Kibet, K., Muthaa, G.M. and Nkonke, G.R. (2012) Factors Contributing to Students Poor Performance in Mathematics at Kenya Certificate of Secondary Education in Kenya: A Case of Baringo County, Kenya. American International Journal of Contemporary Research, 2, 87-91.
- 6. Yara, P.O. and Catherine, W.W. (2011) Performance Determinants of Kenya Certificate of Secondary Education (KCSE) in Mathematics of Secondary Schools in Nyamaiya Division, Kenya. Asian Social Science, 7, 107-112.
http://dx.doi.org/10.5539/ass.v7n2p107 - 7. Mburu, D.D.N.P. (2013) Effects of the Type of School Attended on Students Academic Performance in Kericho and Kipkelion Districts, Kenya. International Journal of Humanities and Social Science, 3, 79-89.
- 8. Zeger, S.L., Liang, K.-Y. and Albert, P.S. (1988) Models for Longitudinal Data: A Generalized Estimating Equation Approach. Biometrics, 44, 1049-1060.
http://dx.doi.org/10.2307/2531734 - 9. McCullagh, P. and Nelder, J. (1989) Generalized Linear Models. 2nd Edition, Chapman & Hall/CRC Monographs on Statistics & Applied Probability. Taylor & Francis, London.
- 10. Molenberghs, G. and Verbeke, G. (2005) Models for Discrete Longitudinal Data. Springer Series in Statistics. Springer, Diepenbeek and Leuven.
- 11. Pan, W. (2011) Akaike’s Information Criterion in Generalized Estimating Equations. Biometrics, 57, 120-125.
http://dx.doi.org/10.1111/j.0006-341X.2001.00120.x - 12. Fitzmaurice, G.M. (1995) A Caveat Concerning Independence Estimating Equations with Multivariate Binary Data. Biometrics, 51, 309-317.
- 13. Hin, L. and Wang, Y. (2009) Working-Correlation-Structure Identification in Generalized Estimating Equations. Statistics in Medicine, 28, 642-658.
http://dx.doi.org/10.1002/sim.3489 - 14. Little, R.J. and Rubin, D.B. (2014) Statistical Analysis with Missing Data. 2nd Edition, John Wiley & Sons, Hoboken.
- 15. Zorn, C.J.W. (2001) Generalized Estimating Equation Models for Correlated Data: A Review with Applications. American Journal of Political Science, 45, 470-490.
http://dx.doi.org/10.2307/2669353 - 16. Robins, J.M. and Rotnitzky, A. (1995) Semiparametric Efficiency in Multivariate Regression Models with Missing Data. Journal of the American Statistical Association, 90, 122-129.
http://dx.doi.org/10.1080/01621459.1995.10476494 - 17. Preisser, J.S., Lohman, K.K. and Rathouz, P.J. (2002) Performance of Weighted Estimating Equations for Longitudinal Binary Data with Drop-Outs Missing at Random. Statistics in Medicine, 21, 3035-3054.
http://dx.doi.org/10.1002/sim.1241 - 18. Horton, N.J. and Kleinman, K.P. (2007) Much Ado about Nothing: A Comparison of Missing Data Methods and Software to Fit Incomplete Data Regression Models. The American Statistician, 61, 79-90.
http://dx.doi.org/10.1198/000313007X172556 - 19. Rubin, D.B. (1976) Inference and Missing Data. Biometrika, 63, 581-592.
http://dx.doi.org/10.1093/biomet/63.3.581 - 20. Berglund, P. and Heeringa, S. (2014) Multiple Imputation of Missing Data Using SAS®. IT Pro, SAS Institute, Cary.
- 21. Molenberghs, G., Fitzmaurice, G., Kenward, M., Tsiatis, A. and Verbeke, G. (2014) Handbook of Missing Data Methodology (Chapman & Hall/CRC Handbooks of Modern Statistical Methods), Taylor & Francis, United Kingdom.
NOTES

1https://www.opendata.go.ke/Education/KCSE-Exam-Results-2006-to-2010/ycfy-7tnf