Open Journal of Modelling and Simulation
Vol.04 No.01(2016), Article ID:63185,15 pages
10.4236/ojmsi.2016.41001
On the Convergence of the Dual-Pivot Quicksort Process
Mahmoud Ragab1, Beih El-Sayed El-Desouky2, Nora Nader2
1Department of Mathematies, Faculty of Science, Al Azhar University, Cairo, Egypt
2Department of Mathematics, Faculty of Science, Mansoura University, Mansoura, Egypt

Copyright © 2016 by authors and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 19 November 2015; accepted 26 January 2016; published 29 January 2016
ABSTRACT
Sorting an array of objects such as integers, bytes, floats, etc. is considered as one of the most important problems in Computer Science. Quicksort is an effective and wide studied sorting algorithm to sort an array of n distinct elements using a single pivot. Recently, a modified version of the classical Quicksort was chosen as standard sorting algorithm for Oracles Java 7 routine library due to Vladimir Yaroslavskiy. The purpose of this paper is to present the different behavior of the classical Quicksort and the Dual-pivot Quicksort in complexity. In Particular, we discuss the convergence of the Dual-pivot Quicksort process by using the contraction method. Moreover we show the distribution of the number of comparison done by the duality process converges to a unique fixed point.
Keywords:
Randomized Quicksort, Convergence, Dual-Pivot Quicksort Process, Running Time Analysis

1. Introduction
Quicksort is one of the important sorting algorithms. Hoare [1] proposed an algorithm depended on selecting an arbitrary element from the array. This element called a pivot element such that Quicksort algorithm used for parting the arrays into two sub-arrays: those smaller than the pivot and those larger than the pivot [2] .
After that Quicksort depends on recursive sorting of the two subarrays. Later Sedgewick studied several variants.
Regnier [3] studied the limiting distribution of the number of comparisons done by Quicksort algorithm when suitably normalized. It converges with uncertain unknown limit. The first accounts were computed by Hennequin who proved that this distribution is not a normal distribution. The limiting distribution is characterized by a stochastic fixed point equation [4] [5] . The cost of the Quicksort algorithm depends on the position of the selected pivot. There are many cases to choose the pivot element. The worst-case, the best-case and the average case express the performance of the algorithm. We will discuss some of them and for more details; we refer to Ragab [6] and [7] . The worst-case occurs when the pivot is the smallest (or largest) element at partitioning on array of size n, yielding one empty sub-array, one element (pivot) in the correct place and one sub-array of size n − 1. So, the two sub-arrays are lopsided so this case is defined by worst case [8] . We found the recursion depth is n − 1 levels and the complexity of Quicksort is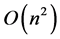 . The best case occurs when the pivot is in the median at each partition step, i.e. after each partitioning, on array of size n, yielding two sub-arrays of approximately equal size and, the pivot element in the middle position takes n data comparisons [9] . There are various methods to choose a good pivot, like choosing the First element, Last element, and Median-of-three elements (selection three elements, and find the median of these elements), and so on. In this case the Quicksort algorithm selects a pivot by random selection each time. This choice reduces probability that the worst-case ever occurs. The other method, which essential prevents the worst case from ever occurring, picks a pivot as the median of the array each time. When we chose the pivot, we compare all other elements to it and we have n − 1 comparisons to divided the array. The choosing of the pivot divided the array into one sub-array of size 0 and one sub-array of size n − 1, or into a sub-array of size 1 and other one of size n − 2, and so on up to a sub-array of size n − 1 and one of size 0. We have n possible positions and each one is equality in probability 1/n. Hennequin studied comparisons for array by using Quicksort with r pivots when r = 2, same comparisons as classic Quicksort in one partitioning. When r > 2, he found the problem is complied. Yaroslavskiy [10] introduced a new implementation of Dual-pivot Quicksort in Java 7’s runtime library. In 2012, Wild and Nabel denoted exact numbers of swaps and comparisons for Yaroslavskiy’s algorithm [10] . In this paper, our aim is to analyze the running time performance of Dual-pivot Quicksort. The limiting distribution of the normalized number of comparisons required by the Dual-pivot Quicksort algorithm is studied. It is known to be the unique fixed point of a certain distributional transformation T with zero mean and finite variance.
. The best case occurs when the pivot is in the median at each partition step, i.e. after each partitioning, on array of size n, yielding two sub-arrays of approximately equal size and, the pivot element in the middle position takes n data comparisons [9] . There are various methods to choose a good pivot, like choosing the First element, Last element, and Median-of-three elements (selection three elements, and find the median of these elements), and so on. In this case the Quicksort algorithm selects a pivot by random selection each time. This choice reduces probability that the worst-case ever occurs. The other method, which essential prevents the worst case from ever occurring, picks a pivot as the median of the array each time. When we chose the pivot, we compare all other elements to it and we have n − 1 comparisons to divided the array. The choosing of the pivot divided the array into one sub-array of size 0 and one sub-array of size n − 1, or into a sub-array of size 1 and other one of size n − 2, and so on up to a sub-array of size n − 1 and one of size 0. We have n possible positions and each one is equality in probability 1/n. Hennequin studied comparisons for array by using Quicksort with r pivots when r = 2, same comparisons as classic Quicksort in one partitioning. When r > 2, he found the problem is complied. Yaroslavskiy [10] introduced a new implementation of Dual-pivot Quicksort in Java 7’s runtime library. In 2012, Wild and Nabel denoted exact numbers of swaps and comparisons for Yaroslavskiy’s algorithm [10] . In this paper, our aim is to analyze the running time performance of Dual-pivot Quicksort. The limiting distribution of the normalized number of comparisons required by the Dual-pivot Quicksort algorithm is studied. It is known to be the unique fixed point of a certain distributional transformation T with zero mean and finite variance.
We show that using two pivot elements (or partitioning to three subarrays) is very efficient, particularly on large arrays. We propose the new Dual-pivot Quicksort scheme, faster than the known implementations, which improves this situation (see in [11] and [12] ). The implementation of the Dual-pivot Quicksort algorithm has been inspected on different inputs and primitive data types.
The new Quicksort algorithm uses partitioning a source array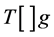 , where g is primitive array which we need to sort it. Such as int, float, byte, char, double, long and short, to three parts defined by two pivot elements p and q (and therefore, there are pointers A, B, C and left and right indices of the first and last elements respectively). The aim of this paper is to present such a version arising from an algorithm depending on the work in [13] and [14] . The Dual-pivot Quicksort is explained clearly in [15] and it works as follow:
, where g is primitive array which we need to sort it. Such as int, float, byte, char, double, long and short, to three parts defined by two pivot elements p and q (and therefore, there are pointers A, B, C and left and right indices of the first and last elements respectively). The aim of this paper is to present such a version arising from an algorithm depending on the work in [13] and [14] . The Dual-pivot Quicksort is explained clearly in [15] and it works as follow:
1) For small arrays (length < 17), use the Insertion sort algorithm [10] .
2) Choose two pivot elements p and q. We can get, for example, the first element 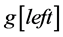 as p and the last element
as p and the last element 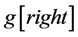 as q.
as q.
3) p must be less than q, otherwise they are swapped. So, we have the following parts.
・ Part I with indices from left + 1 to A − 1 with elements, which are less than p.
・ Part II with indices from A to B − 1 with elements, which are greater or equal to p and less or equal to q.
・ Part III with indices from C + 1 to right − 1 with elements greater than q.
・ Part IV contains the rest of the elements to be examined with indices from B to C.
4) The next element 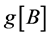 from the part IV is compared with two pivots p and q, and placed to the corresponding part I, II, or III.
from the part IV is compared with two pivots p and q, and placed to the corresponding part I, II, or III.
5) The pointers A, B, and C are changed in the corresponding directions.
6) The steps 4 - 5 are repeated while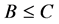 .
.
7) The pivot element p is swapped with the last element from part I, the pivot element q is swapped with the first element from part III.
8) The steps 1 - 7 are repeated recursively for every part I, part II, and part III as in Figure 1.

Figure 1. Graph explains the dual-pivot quicksort algorithm.
2. Run-Time Performance
In this section, we introduce some running time of the Dual-pivot Quicksort. An efficient procedure is described by Vasileios Iliopoulos and David B. Penman [13] , where they analyze the Dual pivot Quicksort algorithm. Their approach can be here provided and for more details we refer to [13] and [14] . First we introduce the algorithm of it and we compare between it and the classical Quicksort as follows [16] .
The following graphs show the relation between the size of array which need to sort and the time of complexity which represent by the number of comparisons and swaps as in Figure 2. We found the Dual-pivot Quicksort is faster than classical Quicksort.
3. The Dual-Pivot Quicksort Average Case Analysis
To find the distributional equation, we note the following: for the underlying process, there are two parts. The first part is partitioning and the second is the total number of comparisons to sort an array of 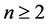 keys, when the pivot is a uniform random variable
keys, when the pivot is a uniform random variable 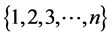 is equal to the number of comparisons to sort the sub- array of on
is equal to the number of comparisons to sort the sub- array of on 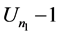 keys below the first pivot [17] .
keys below the first pivot [17] .
In addition, we need to compute the number of comparisons to sort the sub-array of 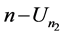 elements above the second pivot plus the number of comparisons to sort the sub-array of
elements above the second pivot plus the number of comparisons to sort the sub-array of 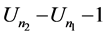 elements between the first and the second pivot.
elements between the first and the second pivot.
Plus 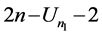 comparisons done to partition the array which come from when the all elements compare one time with the first pivot and the remain elements compare two times with the second and the first pivot. Therefore,
comparisons done to partition the array which come from when the all elements compare one time with the first pivot and the remain elements compare two times with the second and the first pivot. Therefore,

Figure 2. Comparison between the classical Quicksort and the Dual-pivot Quicksort.
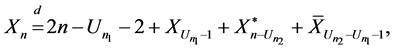 (1)
(1)
where the random variables ,
,  and
and  are identically distributed and independent of
are identically distributed and independent of  and
and . Here
. Here  refers to the equality in distribution.
refers to the equality in distribution.
The array is partitioned into three subarrays one with  keys smaller than the first pivot, a subarray of
keys smaller than the first pivot, a subarray of  keys between two pivots and the part of
keys between two pivots and the part of  elements greater than the second pivot. The algorithm is then recursively applied to each of these subarrays. The number of comparisons during the first stage is
elements greater than the second pivot. The algorithm is then recursively applied to each of these subarrays. The number of comparisons during the first stage is

where  and
and . Using [11] , the average value of
. Using [11] , the average value of  can be calculated as follow:
can be calculated as follow:

4. Expected Number of Comparisons
Here by Equation (1) and using [13] , it is easy to determine the recurrence for the expected number of comparisons due to the duality as follow:

Since the three double sums above are equal, then the recurrence becomes

setting ,
,

By initial conditions we have . Multiplying both sides by
. Multiplying both sides by , we obtain
, we obtain

We introduce a difference operator for the solution of this recurrence. The operator is defined by
 (2)
(2)
And for higher orders

Thus, we have


By definition (2),


then

Dividing by , we obtain the telescoping recurrence
, we obtain the telescoping recurrence

which yields

Multiplying by , this recurrence is transformed to a telescoping one
, this recurrence is transformed to a telescoping one

 (3)
(3)
By using maple V. Iliopoulos and D. B. Penman [13] get

And for the other sums in Equation (3):

Therefore,

Now the equation becomes


Finally, the expected number of comparisons, when two pivots are chosen is
 (4)
(4)
where  is the harmonic number defined by
is the harmonic number defined by  (see [18] and [19] ).
(see [18] and [19] ).
This is the same value of the expected number of comparisons, when one pivot chosen in the classical Quicksort [20] . Note that this result for the dual Quicksort is identical with the expected number of comparisons in [13] .
5. Varience of Comparisons
The main result of this section was obtained by [13] (see following results for explanation and notation). Now we compute the variance of the number of comparisons by Dual-pivot Quicksort. Recall that
 (5)
(5)
From Equation (1), we have

noting that the resulting subarrays are independently sorted, then we get

Letting

be the ordinary probability generating function for the number of comparisons needed to sort n keys, we obtain
 (6)
(6)
It holds that  and
and . Moreover, the second order derivative of Equation (6) evaluated at
. Moreover, the second order derivative of Equation (6) evaluated at  is recursively given by
is recursively given by

By simple manipulation of indices, the sums of the products of expected values are equal. The double sum of the product of the mean number of comparisons can be simplified as follows:

We find

The recurrence becomes

where  is the second order harmonic number defined by
is the second order harmonic number defined by  (see [17] and [18] ). Letting
(see [17] and [18] ). Letting  and subtracting
and subtracting  from
from , we get
, we get

By using the identity [4]
 (7)
(7)
It holds that

The previous equation is the same as

And our recurrence becomes

Dividing by , we obtain the telescoping recurrence
, we obtain the telescoping recurrence


which is equivalent to

Again as before, multiplying both sides by , the recurrence telescopes with solution
, the recurrence telescopes with solution

Using the well known fact that

the variance of the number of key comparisons of the Dual-pivot Quicksort is (see [17] [19] and [20] )

where  is the second order harmonic number defined by (see [18] and [19] )
is the second order harmonic number defined by (see [18] and [19] )

6. Asympototic Distribution
In this section, we show the convergence results which are essential for the main purpose.
Defining a random variables
 (8)
(8)
Equation (8) can be rewritten in the following form

and so,
 (9)
(9)
By a simple manipulation, one gets

where the cost function  is given as and it seems to be like in [6] and [7] , and given by
is given as and it seems to be like in [6] and [7] , and given by
 (10)
(10)
Now, we show the random vector  converges to a uniformly distributed random vector
converges to a uniformly distributed random vector  on
on . So,
. So,
 (11)
(11)
Here  is uniformly distributed random vector on
is uniformly distributed random vector on . The moment generating function of
. The moment generating function of
 is given by
is given by

For the random vector ,
,

Now, the random vector  has the following moment generating function
has the following moment generating function
 (12)
(12)
By the above Equation (12) the moment generating function of  is an approximation to the average value of
is an approximation to the average value of  over the interval
over the interval . The moment generating function of
. The moment generating function of  is an approximation to the average value of
is an approximation to the average value of  over the interval
over the interval  (see [8] and [9] ).
(see [8] and [9] ).
For the cost function

By using asymptotically, the expected complexity of Dual-pivot Quicksort is  given in Equation (4), it follows that
given in Equation (4), it follows that

Thus  converges to some
converges to some , defined as
, defined as

where U1 and U2 are uniformly distributed random variables on . Therefore, if we assume for moment that Yn converges in distribution to some Y, we obtain
. Therefore, if we assume for moment that Yn converges in distribution to some Y, we obtain

Here  and
and  are independent.
are independent.  and
and  have the same distribution as Y. Finally we show that
have the same distribution as Y. Finally we show that  converges in fact to the fixed point Y.
converges in fact to the fixed point Y.
Let D be the space of distribution functions F with finite second moments  and the first moment
and the first moment . We use the Wasserstein metric [4] on D.
. We use the Wasserstein metric [4] on D.

where  denotes the
denotes the  norm. Defining a map
norm. Defining a map  by
by

where  and
and  are independent .
are independent .

Here τ1 and τ2 are uniformly distributed random variables on  and C is a map defined as
and C is a map defined as . We have to refer to Roesler (see in [4] [21] and [22] ) for the main idea for the next lemma.
. We have to refer to Roesler (see in [4] [21] and [22] ) for the main idea for the next lemma.
Lemma 1
The map  is a contraction on
is a contraction on  and has a unique fixed point. Moreover, every sequence
and has a unique fixed point. Moreover, every sequence  converges in the d-metric to fixed point of T.
converges in the d-metric to fixed point of T.
Proof
Let F and G are in D




The random variables  and
and  are independent. Also
are independent. Also  and
and  are independent. Here
are independent. Here  and
and  are uniformly distributed on
are uniformly distributed on . Then
. Then

where



Taking the infimum over all possible  we obtain
we obtain

using Banach fixed point theorem completes the proof (also see [13] ).
Acknowledgments
We thank the editor and the referee for their comments.
Cite this paper
Mahmoud Ragab,Beih El-Sayed El-Desouky,Nora Nader, (2016) On the Convergence of the Dual-Pivot Quicksort Process. Open Journal of Modelling and Simulation,04,1-15. doi: 10.4236/ojmsi.2016.41001
References
- 1. Hoare, C.A.R. (1962) Quicksort. The Computer Journal, 5, 10-15. http://dx.doi.org/10.1093/comjnl/5.1.10
- 2. Rosler, U. (2001) On the Analysis of Stochastic Divide and Conquer Algorithms. Algorithmica, 29, 238-261. http://dx.doi.org/10.1007/BF02679621
- 3. Regnier, M. (1989) A Limiting Distribution for Quicksort. Informatique Théorique et Applications, 23, 335-343.
- 4. Roesler, U. (1992) A Fixed Point Theorem for Distributions. Stochastic Processes and their Applications, 42, 195-214. http://dx.doi.org/10.1016/0304-4149(92)90035-O
- 5. Roesler, U. and Rueschendorf, L. (2001) The Contraction Method for Recursive Algorithms. Algorithmica, 29, 3-33. http://dx.doi.org/10.1007/BF02679611
- 6. Ragab, M. (2011) Partial Quicksort and Weighted Branching Processes. PhD Thesis, 28-35.
- 7. Ragab, M. and Rosler, U. (2014) The Quicksort Process. Stochastic Processes and their Applications, 124, 1036-1054. http://dx.doi.org/10.1016/j.spa.2013.09.014
- 8. Fill, J.A. and Janson, S. (2001) Approximating the Limiting Quicksort Distribution. Random Structures Algorithms, 19, 376-406. http://dx.doi.org/10.1002/rsa.10007
- 9. Fill, J.A. and Janson, S. (2004) The Number of Bit Comparisons Used by Quicksort: An Average-Case Analysis. ACM-SIAM Symposium on Discrete Algorithms., New York, 300-307 (Electronic).
- 10. (2009) http://permalink.gmane.org/gmane.comp.java.openjdk.core-libs.devel/2628
- 11. Ragab, M. (2015) Partial Quicksort and Weighted Branching Process: Surveys and Analysis. LAP Lambert Academic Publishing, Germany.
- 12. Fuchs, M. (2013) A Note on the Quicksort Asymptotics. Random Structures and Algorithms.
- 13. Iliopoulos, V. and Penman, D.P. (2012) Dual Pivot Quicksort. Discrete Mathematics, Algorithms and Applications, 04, No. 3. http://dx.doi.org/10.1142/S1793830912500413
- 14. Iliopoulos, V. (2013) The Quicksort Algorithm and Related Topics. PhD Thesis. Department of Mathematical Sciences, University of Essex. http://repository.essex.ac.uk/13266
- 15. Martinez, C., Nebel, M.E. and Wild, S. (2014) Analysis of Branch Misses in Quicksort. SIAM. http://dx.doi.org/10.1137/1.9781611973761.11
- 16. Wild, S., Nebel, M.E. and Martienz, C. (2014) Analysis of Pivot Sampling in Dual-Pivot Quicksort. arXiv preprint arXiv:1412.0193.
- 17. Wild, S. (2012) Java 7’s Dual Pivot Quicksort. Master Thesis, University of Kaiserslautern, Kaiserslautern, Germany. http://www.uni-kl.de/en/home/
- 18. Choi, J. and Srivastava, H.M. (2011) Some Summation Formulas involving Harmonic Numbers and Generalized Harmonic Numbers. Mathematical and Computer Modelling, 54, 2220-2234. http://dx.doi.org/10.1016/j.mcm.2011.05.032
- 19. Wild, S., Nebel, M.E., Reitzig, R. and Laube, U. (2013) Engineering Java 7’s Dual Pivot Quicksort. Proceedings of the ALENEX 2013, New Orleans, Louisiana, USA, 7 January 2013, 55-69.
- 20. Wild, S. and Nebel, M.E. (2012) Average Case Analysis of Java 7’s Dual Pivot Quicksort . In: Epstein, L. and Ferragina, P., Eds., Algorithms—ESA 2012, Springer, Berlin/Heidelberg, 825-836. http://dx.doi.org/10.1007/978-3-642-33090-2_71
- 21. Wild, S., Nebel, M.E. and Mahmoud, M. (2014) Analysis of Quickselect Under Yaroslavskiy’s Dual-Pivoting Algorithm. Algorithmica, 78, 485-506. http://dx.doi.org/10.1007/s00453-014-9953-x
- 22. Wild, S., Nebel, M.E. and Neininger, R. (2013) Average Case and Distributional Analysis of Java 7’s Dual Pivot Quicksort. arXiv preprint arXiv:1304.0988.
Appendix
A1. The Dual-Pivot Quicksort Algorithm [15]
DUALITY -PIVOT QUICKSORT (G, left, right)
// Sort  (including end points).
(including end points).
1) If right ? left < M // i.e. the sub-array has n ≤ M elements
2) INSERTIONSORT (G, left, right)
3) Else
4) If 
5) ;
; 
6) Else
7) ;
; 
8) End If
9) ;
; ;
; 
10) While 
11) If 
12) Swap  and
and 
13) 
14) Else
15) If 
16) While  and
and  do
do  End While
End While
17) If 
18) Swap  and
and 
19) Else
20) Swap  and
and ; Swap
; Swap  and
and 
21) 
22) End if
23) 
24) End if
25) End if
26) 
27) End While
28) ;
; 
29) ;
;  // Swap pivots to final position
// Swap pivots to final position
30) ;
; 
31) DUALITY-PIVOT QUICKSORT 
32) DUALITY-PIVOT QUICKSORT 
33) DUALIY-PIVOT QUICKSORT 
34) End if
A2. The Implementation of the New Dual-Pivot
Here’s the implementation of the new Dual-Pivot (Yaroslavskiy) in java:
public main void sort(double[] g) {
sort(g, 0, g.length);
}
public main void sort(double[] g, double fromIndex, double toIndex) {
rangeCheck(g.length, fromIndex, toIndex);
Yaroslavskiy(g, fromIndex, toIndex - 1, 3);
}
private main void rangeCheck(double length, double fromIndex, double toIndex) {
if (fromIndex > toIndex) {
throw new IllegalArgumentException("fromIndex > toIndex");
}
if (fromIndex < 0) {
throw new ArrayIndexOutOfBoundsException(fromIndex);
}
if (toIndex > length) {
throw new ArrayIndexOutOfBoundsException(toIndex);
}
}
private main void swap(double[] g, double i, double j) {
int tem = g[i];
g[i] = g[j];
g[j] = tem;
}
private static void dualPivotQuicksort(double [] g, double left, double right, double div) {
double lenth = right - left;
if (lenth < 27) { // insertion sort for tiny array
for (double i = left + 1; i <= right; i++) {
for (int j = i; j > left &&g[j] < g[j - 1]; j--) {
swap(g, j, j - 1);
}
}
return;
}
int third = len / div;
// "medians"
int s1 = left + third;
int s2 = right - third;
if (s1 <= left) {
s1 = left + 1;
}
if (s2 >= right) {
s2 = right - 1;
}
if (g[s1] < g[s2]) {
swap(g, s1, left);
swap(g, s2, right);
}
else {
swap(g, s1, right);
swap(g, s2, left);
}
// chosse the pivots
double first pivot =g[left];
double second pivot = g[right];
// pointers
double less = left + 1;
double great = right - 1;
// sorting the array by the Dual pivot Quicksort
for (int k = less; k <= great; k++) {
if (g[k] < first pivot) {
swap(g, k, less++);
}
else if (g[k] > second pivot) {
until (k > great && g[great] < second pivot) {
great--;
}
swap(g, k, great--);
if (g[k] < first pivot) {
swap(g, k, less++);
}
}
}
// swaps
double Dis = great - less;
if (Dis < 13) {
div++;
}
swap(g, less - 1, left);
swap(g, great + 1, right);
// recursive the algorithm for the arrays
Yaroslavskiy(g, left, less - 2, div);
Yaroslavskiy(g, great + 2, right, div);
// subarray
if ( first pivot < second pivot) {
Yaroslavskiy(g, less, great, div);
}
}