Journal of Financial Risk Management
Vol.05 No.02(2016), Article ID:66636,18 pages
10.4236/jfrm.2016.52008
Are the ASISA Standards with Respect to Unit Trust Classification Representative of Homogeneous Risk Classes?
Joe Kainja
Umthombo Wealth, Johannesburg, South Africa

Copyright © 2016 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 24 March 2016; accepted 20 May 2016; published 23 May 2016
ABSTRACT
We examine the information content of South African (SA) equity unit trusts to investigate whether risk is heterogeneous between investment objective groups and homogeneous within groups because those characteristics are vital to proper investment decision making. We find risk differences within SA equity groups especially in the Equity-General and Equity-Growth. However, in the other categories, the systematic risk differences depended on the choice of benchmark. Those risk differences may have significant implications for investors. Examination of between-group risk revealed that not all the equity categories were heterogeneous. We also find that the choice of benchmark is critical when measuring and comparing performance characteristics of funds.
Keywords:
ASISA, ASISA Unit Trust Classification, Risk Homogeneity, Systematic Risk, Total Risk, JSE, Benchmark

1. Introduction
Finance theory suggests that risk and return are essential elements in selecting investments. Utility theory further suggests that the understanding of the risk and return of funds are crucial to investors in order to maximize the investor’s utility for an investment. Therefore, we investigated the risk characteristics of South African (SA) unit trusts across all equity categories.
The Association of Savings and Investments in South Africa (ASISA) is the organization responsible for classifying unit trusts in South Africa. ASISA reclassified unit trusts effective on 1 January 2013. Prior to the changes, there were 10 equity unit trust categories in South Africa, namely Equity-General, Equity-Value, Equity-Growth, Equity-Large Companies, Equity-Smaller Companies, Equity-Financials, Equity-Oil, Gas and Basic Materials (Resources), Equity-Industrials, Equity-Technology and Equity-Varied Specialist. After the reclassification, the Equity-Technology category closed; Equity-Varied Specialist became Equity-Unclassified while the two style categories: Equity-Value and Equity-Growth also closed but collapsed and combined with the Equity-General category. When presenting the groups in tables, we refer to them, respectively, as General, Value, Growth, Large, Small, Financials, Resources and Industrials; while the Equity-Technology and Equity-Varied Specialist are dropped from further reference due to lack of enough data.
These changes imply that there were and maybe there are still issues with equity unit trust categorization in South Africa. According to their standards, the objective of the ASISA classification is to facilitate the timeous and appropriate classification and reclassification of funds, to ensure that funds meet their investment mandate requirements, to ensure adherence to category and sector definition and to ensure that appropriate information on fund objectives is available to the investing public to facilitate appropriate fund comparison. The correct classification of funds is important to achieve the following objectives:
to promote investor awareness and understanding of the various fund types;
to assist investors in selecting funds;
to facilitate the comparison of funds both across and within categories;
to facilitate the analysis of different types of funds.
As stated within the ASISA standards, unit trusts are classified based on their objectives. If the activities of the unit trusts are consistent with their stated objectives, then investors may look at the objectives as signals of risk (Jin & Yang, 2004) . Generally unit trusts should reveal their characters of “selecting a risk class” or “subdividing markets” to investors by their investment objectives. Investors make decisions on the basis of the funds’ objectives, implicitly assuming that the activities of the funds are consistent with the stated objectives. However, if the stated objectives are not objectives that the funds pursue, conclusions drawn by the investors may be misleading (Kim, Shukla, & Tomas, 2000) .
Sharpe (1966) reported that mutual funds select a risk class and then invite investors with similar risk preferences to invest. He stressed that funds must remain in the same risk class so as not skew the investors’ overall risk. It is imperative that the funds with the same objective class have the same risk profile and exhibit different risk characteristics from those in a different category.
Investors should be concerned with both risk and returns of their unit trusts. Brown, Harlow and Stark (1996) showed that both winning and losing (in the previous period) investment managers tend to manipulate their risk in order to chase returns. However, if monitoring risk is efficient and funds are constrained by investment objectives, then altering risk may easily be detected because unit trusts whose risks have been altered should significantly fall outside their investment objectives and convey risk-return characteristics significantly different from their groups. Capon, Fitzsimons and Prince (1996), Goetzman and Peles (1997), Sirri and Tufano (1998) suggested that past performance affects fund selection and that funds with higher returns are likely to attract more new flows. The decision to invest in funds with higher returns may be sub-optimal if these returns are accompanied by high risk, as theory would suggest.
Unit trust data vendors such as Micropal, PlexCrown and Moneymate regularly calculate and publish figures based on the official fund classification system. If the classification were significantly flawed, then by implication, any calculations such as average returns, risk, performance rankings, and tracking errors might be misleading.
Investors, financial advisers and consultants frequently look to such publications as a guide for their investment decisions, without the need for further information, clarification or verification. If, for example, an investor was attempting to construct a style-diversified portfolio of unit trusts based on this information, he may end up with a misclassified portfolio, which could eventually skew his risk and compromise his investment strategy. Najand and Prather (1999) showed that if the risks are heterogeneous within an investment group, the practice of comparing returns is not optimal. Prather (2012) further concluded that if the risks of the funds within an investment objective group differ significantly, comparing returns alone is insufficient to make utility maximizing investment decisions.
Di Bartolomeo and Witkowski (1997), Detzel (2006) and Kim, Shukla and Tomas (2000) have shown that the stated objectives or indeed the groupings of unit trusts do not always reflect the true characteristics of the funds. Robertson, Firer and Bradfield (2000) concluded that a significant number of equity unit trusts in South African were misclassified.
We examine whether equity unit trusts in the same group are homogeneous from a risk perspective and if different groups have heterogeneous risk.
Unit Trust Investment Objectives and Risk
Theory suggests that investment objectives should provide a good proxy for investment risk. Bogle (1970) investigated the relationship between risk and return of mutual funds and concluded that the returns increased with the riskiness of the investment objective as well as with the volatility of the returns. Carlson (1970) also found that the returns of mutual funds increased with risk. McDonald (1974) examined the relationship between stated investment objectives, risk and returns and found that the stated objectives explained as much variability of returns as did the systematic or the total risk. Sharpe (1966) also confirmed this theory and reported that mutual funds select a risk class and then invite investors with similar risk preference to invest. He stressed that a fund must remain within the same risk class so that investors may arrange portfolio holdings. Sharpe’s (1992) commonly used returns based style analysis in part is based on this theory and makes this assumption.
Klemkosky (1976) conducted a statistical test over a ten-year period to investigate whether investment objective classifications resulted in groupings with homogenous within-group and heterogeneous between-group risk. This is critical, as this would enable investors to select funds based on their classification. Klemkosky found that there was a consistent relationship between risk and investment objectives and that the risk was relatively constant over time.
However, if information asymmetry concerning risk and imperfect monitoring exist, problems would arise. Investors are inclined to monitor returns?which are easily observed-while ignoring potential risk differences. This is also logical if investors believe that risk is homogenous with investment objective class, as reported by
Klemkosky (1976)
. Investors who believe in the capital asset pricing model (CAPM) and the efficient market hypothesis (EMH) would conclude that the differences in returns are either due to risk difference or due to chance. This is because the returns of a unit trust, p, are expected to equal the risk-free rate plus beta times the market (benchmark) premium, or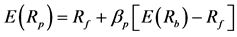 , where:
, where: 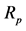 is the return of the unit trust p,
is the return of the unit trust p, 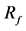 is the risk free rate (STeFI),
is the risk free rate (STeFI), 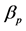 is the systematic risk of the unit trust p with respect to the benchmark b,
is the systematic risk of the unit trust p with respect to the benchmark b, 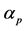 is the risk-adjusted excess return to the unit trust p, and ε is the error term.
is the risk-adjusted excess return to the unit trust p, and ε is the error term.
While early studies provided supporting evidence that investment objective classes provide a proxy for risk that is homogenous within each class, more recent research suggests that that may no longer be the case ( Christopherson, 1995; Bowen & Statman, 1997 in the United States; Jin & Yang, 2004 in China, as well as Robertson, Firer, & Bradfield, 2000 in South Africa). The test, which we conducted in this study, was to find out whether the unit trusts within a given ASISA equity classification exhibited homogeneous risk characteristics.
2. Data
Twelve and a half years of monthly total return data of South African unit trusts was obtained from InetBFA for the period (30 June 2002 to 31 December 2014). Table 1 presents the sample size of the data. Our sample started with the equity unit trusts that were available to investors as at 31 December 2012, the date before ASISA reclassified the unit trusts. The other criterion was that the unit trust had enough historical returns to provide meaningful statistical power for our results. We used 3 calendar years of historical returns as the minimum length of the time series. This followed the works of Boggle (1970, 1991) , Carlson (1970) , McDonald (1974), Klemkosky (1976) , Ippolito (1989) , Grinblatt and Titman (1989b; 1993) , Najand and Prather (1999) and Prather (2012) .
The exclusion of new unit trusts may cause “omission” bias. “Omission” bias would cause our significant tests for individual unit trusts to understate since the ANOVA methodology tests for differences between funds. In other words, we are less likely to pick up significant differences; therefore, the results would be stronger than reported when significant differences exist. In any unit trusts that may have entered into the universe did not have the requisite 3-year calendar history.
Also Brown and Brown (1987) showed that “survivorship” bias exists when extinct funds are ignored when studying performance. However, Markiel (1995) suggested that fund disappearance might be caused by funds taking big bets and losing. If the disappearance is related to a large alteration in risk that backfired then eliminating extinct funds would also bias against finding risk differences and would also strengthen the results when differences exist. This means that in cases where one is testing the existence of differences-should the results

Table 1. Number of eligible SA equity unit trusts per category at the end of the year: 2002 to 2014.
show significant differences-then there is huge margin of safety in the findings.
Following Chan (2012) , we used all of the listed unit trusts that contained at least a three-year calendar year history. In 2002, 2012 and 2014 there were 41, 78 and 85 eligible general equity unit trusts and 7, 11 and 0 eligible value equity unit trusts respectively.
We faced a new problem caused by forced closure of certain categories of equity unit trusts. Specifically, Equity-Value and Equity-Growth groups were closed as at 31 December 2012 and the unit trusts in those groups transferred to the Equity-General category. This means that if research had been started, the analyst would have had no knowledge of the two style groups. This is not the case for us as we started this work when those groups existed. To mitigate this problem, we conducted the analysis with two sets of categories: 1) with all 8 equity unit trust categories but with Growth and Value terminating on 31 December 2012; and 2) with 6 equity categories for the whole period with all the members of the previous Growth and Value groups belonging to the Equity-General group.
The Alexander Forbes Short-Term Fixed Interest (STeFI) composite index was used as the proxy for risk free rate. STeFI is the common benchmark used to measure money market funds. It is a benchmark index constructed by Alexander Forbes, calculated and published daily by the South African Futures Exchange (SAFEX). Its composition is as follows:
15% Overnight Call Deposit index based on Interbank Call rate;
30% 3 months NCD index based on 3 month NCD instruments measured at SAFEX rates;
35% 6 months NCD index based on 3 month NCD instruments measured at SAFEX rates;
20% 12 months NCD index based on 3 month NCD instruments measured at SAFEX rates.
Three separate benchmarks, representing the market, were used for all the categories namely; the FTSE/JSE All Share Index (ALSI), the FTSE/JSE Shareholder-weighted All Share Index (SWIX) and the PEER average (PEER). The ALSI is a free float market capitalization index consisting of about 165 shares. The SWIX has the same constituents but adjusts the weighting of each share to take into account the local availability by removing the proportion of shares held by non-SA residents. The ALSI and the SWIX are published daily and are official JSE indices. The PEER index was calculated using the average performance of the data of all the available equity unit trusts at the time, similar to Di Bartolomeo and Witkowski (1997) and Robertson, Firer and Bradfield (2000) .
In addition to the above three market benchmarks individual ASISA benchmark indices were used for each of the groups as follows:
ALSI for Equity-General;
FTSE/JSE Value Index (J330) for Equity-Value;
FTSE/JSE Growth Index (J331) for Equity-Growth;
FTSE/JSE Industrial Index (J257) for Equity-Industrial Companies;
FTSE/JSE Resources Index (J258) for Equity-Resource Companies;
FTSE/JSE Financials Index (J580) for Equity-Financial Companies;
FTSE/JSE Top 40 Index (J200) for Equity-Large Companies;
FTSE/JSE Mid Cap Index (J201) for Equity-Smaller Companies.
And to complete the benchmarking, a group PEER index was also computed and used for each of the categories and labeled as follows:
GENERAL-PEER for Equity-General;
VALUE-PEER for Equity-Value;
GROWTH-PEER for Equity-Growth;
INDUSTRIAL-PEER for Equity-Industrial Companies;
RESOURCES-PEER for Equity-Resource Companies;
FINANCIALS-PEER for Equity-Financial Companies;
LARGE-PEER for Equity-Large Companies;
SMALL-PEER for Equity-Smaller Companies.
We used three different indices following the findings by Brown and Brown (1987) as well as Lehmann and Modest (1987) who reported that the selection of an index can have substantial impact on performance valuation and hence using multiple indices when computing risk measures helps to ensure that the results are robust.
2.1. Computation of Returns
Monthly returns for each of the unit trusts were computed using InetBFA data using Equation (1).
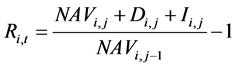 (1)
(1)
where: 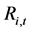 is the return of unit trust i during period t;
is the return of unit trust i during period t; 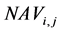 is the net asset value of unit trust i during period t;
is the net asset value of unit trust i during period t; 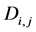 and
and 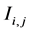 are respectively dividends and interest paid from the unit trust i during period t. The net asset value is the value after all costs and fees associated with management of the unit trust. The PEER monthly returns were the arithmetic average of all the equity returns during that month. The SWIX and ALSI returns were calculated using Equation (1).
are respectively dividends and interest paid from the unit trust i during period t. The net asset value is the value after all costs and fees associated with management of the unit trust. The PEER monthly returns were the arithmetic average of all the equity returns during that month. The SWIX and ALSI returns were calculated using Equation (1).
2.2. Determination of Systematic Risk
Systematic risk (β) was computed by using ordinary least squares regression (OLS) as in Equation 2:
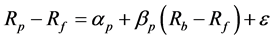 (2)
(2)
where: 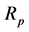 is the return of the unit trust p;
is the return of the unit trust p; 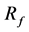 is the risk free rate (STeFI);
is the risk free rate (STeFI); 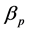 is the systematic risk of the unit trust p with respect to the benchmark b;
is the systematic risk of the unit trust p with respect to the benchmark b;  is the excess risk-adjusted return to the unit trust p; and ε is the error term. If investment objectives, as represented by the ASISA classifications, convey the risk of a particular category then the β’s for the unit trusts within each group should not differ significantly from one another for a given benchmark.
is the excess risk-adjusted return to the unit trust p; and ε is the error term. If investment objectives, as represented by the ASISA classifications, convey the risk of a particular category then the β’s for the unit trusts within each group should not differ significantly from one another for a given benchmark.
3. Methodology and Results
3.1. Homogeneity Test for Systematic Risk
To conduct statistical testing, β’s were computed for each unit trust relative to each of the three indices (SWIX, ALSI, PEER) using monthly total return databy applying the CAPM. The β’s were calculated for non-overlap- ping 12-month periods to create a distribution of β’s. This provided the distribution of β’s for each of the 8 groups?we ignored the Equity-Varied Specialist category, as there was not sufficient data.
As stated above the Equity-Growth and Equity-Value categories were closed on 31 December 2012 and their unit trusts were reclassified into the Equity-General group. To mitigate any bias caused by this we conducted the analysis in two ways:
1) First, the Equity-Growth and Equity-Value categories were separate for the period 30 June 2002 to 31 December 2012. This meant the analysis was done for 8 categories during this period and 6 categories for the period 1 January 2013 to 31 December 2014. The unit trusts from the Equity-Growth and Equity-Value categories were excluded for the last two years as they had less than 3 calendar year data.
2) For the period when Equity-Growth and Equity-Value categories were part of the Equity-General for the whole period, 30 June 2002 to 31 December 2014 only 6 categories existed. The unit trusts from the Equity-Growth and Equity-Value categories were included for the whole period as long as they had 3 calendar year data.
The β’s were compared using one way ANOVA to test the equality of β’s within each ASISA category to test if the average β for all the funds within a category are equal. Formally, ANOVA was utilized to test:


where :  represents the estimated systematic risk (β) of fund j, using benchmark i, during period t. The null hypothesis is that the average systematic risk for each fund within the ASISA category is equal vs alternative hypothesis that states that at least one
represents the estimated systematic risk (β) of fund j, using benchmark i, during period t. The null hypothesis is that the average systematic risk for each fund within the ASISA category is equal vs alternative hypothesis that states that at least one  is different.
is different.
The methodology follows
Klemkosky (1976)
,
Najand and Prather (1999)
and
Prather (2012)
. The critical value of the F statistic  is computed using Equation (3)
is computed using Equation (3)
 (3)
(3)
where:
SSE (R) and SSE (F) are the explained sum of squares for the reduced and full models respectively, while  and
and  are the degrees of freedom for the reduced and full models, respectively.
are the degrees of freedom for the reduced and full models, respectively.
The results in Table 2 show that the Equity-General and Equity-Growth categories do not convey systematic
Table 2. Homogeneity test of systematic risk of ASISA equity unit trusts for all categories?periods 30 June 2002 to 30 June 2003, 30 June 2003 to 30 June 2004…, 30 June 2013 to 30 June 2014.
***and ** imply that the computed F-value is significant at 1% and 5% respectively.
risk across all benchmarks. The Equity-Large Companies group lacks homogeneity when using the ALSI as well as the LARGE-PEER benchmark. The Equity-Financial Companies category is not homogeneous under the utilization of the overall PEER index, the FTSE/JSE Financials index, as well as the Group PEER index. The Equity-Value fails the systematic homogeneity test when utilizing the PEER benchmark.
Table 3 shows that the results for periods ended 31 December are similar to those for periods ended 30 June above showing that there is no year-end effect and that the findings are consistent regardless of starting and ending dates. From now onwards we will only present results for calendar years.
3.2. Post Hoc Test in the ANOVA
This analysis was designed to investigate which unit trusts caused the rejection in the test of the systematic risk homogeneity. We assessed if the heterogeneity was widespread or limited to selected funds. We utilized the Least Squared Difference (LSD) developed by Fisher (1935), which explores all possible pair-wise comparisons of the means of the unit trust beta’s relative to the category mean. The LSD between two means is calculates by using the formula:
 (4)
(4)
where t is the critical value in the table of the t-distribution with the degrees of freedom associated with the MSE ―mean square error―the denominator of the ANOVA F statistic and n is the sample size used to calculate the mean.
We used two-tailed t-statistic at 5% level to determine our LSD. Table 8 (in appendix) shows the statistical summary of the betas as well as the LSD level for each category. The statistics in the LSD column in the table below are as follows: 1) for the category it is the computed LSD using Equation 4; 2) while for each unit trust the measure presents the computed difference between the mean of the unit trust and that of the category mean
Table 3. Homogeneity test of systematic risk of ASISA equity unit trusts for all categories for calendar years 2003 to 2014.
***and ** imply that the computed F-value is significant at 1% and 5% respectively.
and it is used to compare with the group LSD to test the null hypothesis: the systematic risk of the unit trust is the same as that of the group mean vs. the alternative hypothesis that the systematic risk is different.
We make the following observations from Table 8 (in appendix). The null hypothesis that the Coronation Top 20 Fund (CNTF) has similar characteristics as the other unit trusts in the Equity-Large Companies category is rejected implying that CNTF is significantly different from the other funds in that category. When we removed CNFT from the sample and reran the ANOVA test and the Equity-Large Companies category displayed risk homogeneity using all the benchmarks. We hence conclude that the category is homogeneous if CNFT is removed.
The analysis of the Equity-Value category revealed that the β’s of the unit trusts were all homogeneous when using the SWIX and ALSI; however when utilizing the PEER index, three of the 11 unit trusts were significantly heterogeneous. This resulted in the ANOVA test results rejecting the null hypothesis that the unit trusts in the Equity-Value category were homogeneous. This was an interesting finding that showed that the choice of benchmark is actually crucial when comparing performance characteristics of funds. However, the results using the group PEER overrode those utilizing the overall PEER and we conclude that the unit trusts within the Equity-Value category were homogeneous.
For the Equity-Financial Companies category, the results of the LSD tests showed that the majority of the funds are different from the mean confirming that the unit trusts exhibited heterogeneous systematic risk. Similar results were observed from the Equity-General and the Equity-Growth categories. We hence conclude that there existed lack of homogeneity of systematic risk within the Equity-General, Equity-Growth and Equity-Fi- nancials categories.
To complete our work we addressed the problem of the forced closure of the Equity-Value and Equity- Growth groups whose member unit trusts were reclassified into Equity-General by repeating the analysis with the 6 equity categories for the whole period where all the members of the previous Growth and Value groups now belonged to the Equity-General group.
The findings of using the collapsed Equity-General category (Table 4 and Table 5) reveal that the unit trusts in the new group did not display homogenous systematic risk. This affirmed the earlier findings, which showed lack of homogeneity with respect to systematic risk from those three original equity categories.
Table 4. Homogeneity test of systematic risk of ASISA equity unit trusts for combined General, Value and Growth categories?periods 30 June 2002 to 30 June 2003, 30 June 2003 to 30 June 2004…, 30 June 2013 to 30 June 2014.
***and ** imply that the computed F-value is significant at 1% and 5% respectively.
Table 5. Homogeneity test of systematic risk of ASISA equity unit trusts for combined General, Value and Growth categories for calendar years 2003 to 2014.
***and ** imply that the computed F-value is significant at 1% and 5% respectively.
Another potential complication that would arise is whether the ASISA classification does a good job of capturing dimensions of risk that are not measured by β. We further investigated whether the total risk within a group was equal in light of evidence of Brown, Harlow and Starks (1996) that showed the importance of testing both systematic and total risks. These tests eliminate the choice of benchmark indices completely by examining the total variability of the unit trust returns within each category.
We utilized the Hartley test, emulating the methodology employed by Najand and Prather (1999) and Prather (2012) , to determine whether the differences in variance are significant. Formally, Hartley is used to test:


Equation (4) below was used to compute the Hartley test statistic
 (5)
(5)
where: H is the Hartley statistic;  and
and  are respectively the maximum and minimum sample variances. Critical H values are obtained from
David (1952)
.
are respectively the maximum and minimum sample variances. Critical H values are obtained from
David (1952)
.
The results in Table 6 show that the total risks within the Equity-General, Equity-Value, Equity-Growth and Equity-Financials Companies categories were not homogeneous. This concurred with the findings of the test of systematic risk and added robustness to our findings.
3.3. ASISA Equity Unit Trust Classification and the within-Group Risk Heterogeneity
The ASISA classification clearly did not fully account for some important characteristics that affect risk and hence failed to appropriately convey risk for the Equity-General, Equity-Value and Equity-Growth categories. Greer (1997) defined an asset class as a set of assets that that bear some fundamental economic similarities to each other and have characteristics that make them distinct from other assets that are not part of that class.
Table 6. Homogeneity of total risk of ASISA equity unit trusts: 30 June 2002 to 31 December 2014.
***and ** imply that the computed F-value is significant at 1% and 5% respectively.
While classification of some funds may seem to be obvious (as is the case with sector equity unit trusts: Equity-Resources, Equity-Financials and Equity-Industrials); others are not so obvious (as is the case with style- based unit trusts e.g. Equity-Value or Equity-Growth). The complication with style-based classification comes from the lack of uniqueness of defining and quantifying a style. For example, Tierney and Winston (1991) used size and P/E ratios to characterize style while Sharpe (1992) utilized factor loadings. Both studies claim to produce styles that would improve classification. In their recent South African study, Muller and Ward (2013) summed up this problem nicely by stating that there is plethora of possible style indices and factors.
On the other hand, the Equity-General unit trust category is so broad by definition that it would easily contain risk-heterogeneous funds. While some results have assumed and even showed that investment objectives and risks are related in some tractable way, our results demonstrated that this was only possible in situations where the groups had a clear, unique definition and the different groups were mutually exclusive as is the case with sector categorization. This presented a need to find ways which would reclassify the unit trusts so that there would within-sub-group risk homogeneity.
3.4. ASISA Equity Unit Trust Classification and the between-Group Risk Heterogeneity
We further investigated whether the ASISA classification provided categories with between-group risk heterogeneity. Once a target range of risk is selected, it must be mated to funds with appropriate characteristics (Sharpe, 1992) . If the classification results in mutually exclusive risk classes between groups then it means that the groups are significantly different. On the other hand if some of the groups are not significantly different then the classification does not fully distinguish risks between categories.
Following Reints and Vandenberg (1973) and Klemkosky (1976) we used the Scheffe test of contrast to investigate if the ASISA classes were statistically independent from a risk perspective. We emulated the methodology of Najand and Prather (1999) . 28 linear contrasts were examined to learn whether the equity unit groups were mutually exclusive. These contrasts take the form:
 (6)
(6)
where  is linear contrasts;
is linear contrasts;  is the population mean;
is the population mean;  is the estimated mean; r is the number of columns; s is the square root of the mean square error; N is the total number of observations and
is the estimated mean; r is the number of columns; s is the square root of the mean square error; N is the total number of observations and  is the total number of observations in each cell; and
is the total number of observations in each cell; and  is the tabled F-value.
is the tabled F-value.
We hence tested the following null hypothesis using Scheffe tests,
 : the systematic risk between the two paired categories is the same
: the systematic risk between the two paired categories is the same
vs.
 : the systematic risks of two equity categories are different.
: the systematic risks of two equity categories are different.
Table 7 shows the results of the 28 paired tests for each of the benchmarks (ALSI, PEER and SWIX). YES implies that we did not reject the null hypothesis i.e. the paired groups were homogeneous. On the other hand, NO means we reject the null implying that there is significant evidence of heterogeneity between the two groups.
Table 7. Results of Scheffe tests of betas relative to ALSI, PEER and SWIX between SA equity categories.
Table 7 above displays the findings testing whether a pair of categories had significant homogenous systematic risks relative to the respective benchmarks. The pairwise categories of Equity-General, Equity-Value and Equity-Growth did not exhibit differences in systematic risk characteristics. The results showed that the categories Equity-Large Companies and Equity-Smaller Companies were significantly heterogeneous relative to all the three benchmarks; while there was no significant heterogeneity between the categories Equity-Large Companies and Equity-Resources under all the benchmark circumstances.
The categories: Equity-Financials and Equity-Industrials; Equity-Financials and Equity-Value; Equity-Finan- cials and Equity-Growth; Equity-Financials and Equity-General as well Equity-Financials and Equity-Small did not display significant heterogeneous risks. The category Equity-Financial Companies displayed similar risk characteristics to all the other categories expect for Equity-Large Companies and Equity-Resources, the two groups that showed to have homogeneous unit trusts.
These results affirmed our earlier conclusion that the ASISA categorization did not fully convey the risks of the unit trusts. It is our intention to reclassify all these funds into objective groups that exhibit within-group homogeneity and between-group heterogeneity.
4. Conclusion
This paper examines whether the ASISA equity unit trust classification adequately represents risk to investors. This is extremely important to investors if they attempt to compare returns to select unit trusts within a category. For investors to be able to make utility maximizing decisions based on returns, investment groups must be systematically and consistently related to the level of risk faced by investors. If systematic risk is not homogeneous with an investment group, then comparison of returns is highly suspect and may be misleading.
Our findings revealed that the systematic risks within the Equity-General, the Equity-Growth and Equity-Fin- ancials Companies showed significant differences. However, the Equity-Smaller Companies, the Equity-Reso- urces and the Equity-Industrials categories convey appropriate risk across all the benchmarks that we have used. On the other hand, the systematic risks of the Equity-Value depended on the benchmarks utilized. Although the risks were not significantly different for the FTSE/JSE indices, they showed significant differences against the PEER index. The Large Companies category displayed a significant difference relative to the ALSI but further analysis revealed that the difference was only due to one fund (Coronation Top 20 Fund) and we concluded that it was the fund that was in the wrong category as opposed to the category failing to convey appropriate systematic risk.
Examination of the total risk provided confirmatory evidence that the Equity-General, the Equity-Growth, the Equity-Value and the Equity-Financials have failed to capture within-group homogeneity risk. The results provided a motivation and needed to look for objective classification techniques that would generate categories with within-group homogeneity.
The style (Equity-Growth and Equity-Value) categories have combined with Equity-General category and our findings show that the combined category displays significant within-group risk heterogeneity. In other words, the results show that the unit trusts in that group exhibit different risk characteristics.
What ASISA has essentially done is to stifle explicit style differentiation at least from the growth and value perspective. Does that mean that style investment does not exist in the South African equity unit trust industry? This would be in contradiction with a lot of research that shows that style effects―value, growth, fundamental indexation, and momentum―actually exist in the South African equity.
The analysis of between-group systematic homogeneity shows that the ASISA groups do not fully convey different risk characteristics. Specifically we found no significant difference in systematic risk characteristics between the following equity unit trust categories: Equity-Large Companies and Equity-Resources; Equity-Gen- eral and Equity-Value; Equity-General and Equity-Growth; Equity-General and Equity-Financials and Equity-Financials and Equity-Value, Equity-Financials and Equity-Growth, Equity-Financials and Equity-Industrials as well Equity-Financials and Equity-Small Companies.
We conclude that ASISA classification has failed to generate categories that have within-group homogeneity and between-group heterogeneity. This implies that comparison of unit trusts within the same group does not necessarily mean one is comparing apples with apples. The findings also show that choosing unit trusts from different categories may not always generate the anticipated risk differentials, which could skew the overall portfolio risk. It is imperative to find a methodology that would produce categories exhibiting within-group homogeneity and between-group heterogeneity.
Acknowledgements
I would like to thank Dr Larry J. Prather, John Massey Endowed Chair & Professor of Finance, South-eastern Oklahoma State University, for assisting me with the editing of the document.
Cite this paper
Joe Kainja, (2016) Are the ASISA Standards with Respect to Unit Trust Classification Representative of Homogeneous Risk Classes?. Journal of Financial Risk Management,05,63-80. doi: 10.4236/jfrm.2016.52008
References
- 1. Bogle, J. C. (1970). Mutual Fund Performance Valuation. Financial Analysts Journal, 26, 25-33.
http://dx.doi.org/10.2469/faj.v26.n6.25 - 2. Bogle, J. C. (1970). Mutual Fund Performance Valuation. Financial Analysts Journal, 26, 25-33.
http://dx.doi.org/10.2469/faj.v26.n6.25 - 3. Bogle, J. C. (1991). Performance Games. Journal of Portfolio Management, 23, 8-15.
- 4. Bowen, J. J., & Statman, M. (1997). Performance Games. Journal of Portfolio Management, 23, 8-15.
http://dx.doi.org/10.3905/jpm.23.2.8 - 5. Brown, K. C., & Brown, G. D. (1987). Does the Composition of Market Portfolio Really Matter? Journal of Portfolio Management (Winter), 13, 26-32.
http://dx.doi.org/10.3905/jpm.1987.26 - 6. Brown, K. C., Harlow, W. V., & Stark, L. T. (1996). Of Tournament and Temptations: An Analysis of Managerial Incentives in the Mutual Fund Industry. Journal of Finance, 51, 85-110.
http://dx.doi.org/10.1111/j.1540-6261.1996.tb05203.x - 7. Capon, N., Fitzsimons, G. J., & Prince, R. A. (1996). And Individual Level Analysis of the Mutual Fund Investment Decision. Journal of Financial Services Research, 10, 59-82.
http://dx.doi.org/10.1007/BF00120146 - 8. Carlson, R. S. (1970). Aggregate Performance of Mutual Funds, 1948-1967. Journal of Financial and Quantitative Analysis, 5, 1-32.
http://journals.cambridge.org/action/displayAbstract?fromPage=online&aid=6309228&fileId=S0022109000014824 - 9. Chan, C. Y. (2012). Active Fund Management and Cross-Sectional Variance of Returns. Dissertation for Master of Business Administration, Pretoria: Gordon Institute of Business Science, University of Pretoria.
- 10. Christopherson, J. A. (1995). Equity Style Classification. Journal of Portfolio Management, 21, 32-43.
http://dx.doi.org/10.3905/jpm.1995.409520 - 11. David, H. A. (1952). Upper 1% and 5% Points of the Maximum F-Ratio. Biometrika, 39, 32-43.
http://dx.doi.org/10.1093/biomet/39.3-4.422 - 12. Di Bartolomeo, D., & Witkowski, E. (1997). Mutual Fund Misclassification: Evidence Based on Style Analysis. Financial Analysts Journal, 53, 32-43.
http://dx.doi.org/10.2469/faj.v53.n5.2115 - 13. Goetzman, W., & Peles, N. (1997). Cognitive Dissonance and Mutual Fund Investors. Journal of Financial Research, 20, 145-158.
http://dx.doi.org/10.1111/j.1475-6803.1997.tb00241.x - 14. Greer, R. J. (1997). What Is an Asset Class Anyway? Journal of Portfolio Management, 23, 86-91.
http://dx.doi.org/10.3905/jpm.23.2.86 - 15. Grinblatt, M., & Titman, S. (1989b). Portfolio Performance Evaluation: Old Issues and New Insights. Review of Financial Studies, 2, 393-421.
http://dx.doi.org/10.1093/rfs/2.3.393 - 16. Grinblatt, M., & Titman, S. (1993). Performance Measurement without Benchmark: An Examination of Mutual Fund Returns. Journal of Business, 66, 47-68.
http://dx.doi.org/10.1086/296593 - 17. Ippolito, R. A. (1989). Efficiency with Costly Information: A Study of Mutual Fund Performance: 1965-1984. Quarterly Journal of Economics, 104, 1-23.
http://dx.doi.org/10.2307/2937832 - 18. Jin, X.-J., & Yang, X.-I. (2004). Empirical Study on Mutual Fund Objective Classification. Journal of Zhejiang University Science, 5, 533-538.
http://dx.doi.org/10.1631/jzus.2004.0533 - 19. Kim, M., Shukla, R., & Tomas, M. (2000). Mutual Fund Objective Classification. Journal of Economics and Business, 52, 209-203.
http://dx.doi.org/10.1016/S0148-6195(00)00022-9 - 20. Klemkosky, R. C. (1976). Additional Evidence on the Risk Level Discriminatory Power of the Weisenberger Classification. Journal of Business, 45, 48-50.
http://dx.doi.org/10.1086/295804 - 21. Lehmann, B. N., & Modest, D. M. (1987). Mutual Fund Performance Evaluation: A Comparison of Benchmark Comparisons. Journal of Finance, 42, 233-265.
http://dx.doi.org/10.1111/j.1540-6261.1987.tb02566.x - 22. Markiel, G. B. (1995). Returns from Investing in Equity Mutual Funds: 1971-1991. Journal of Finance, 50, 549-572.
http://dx.doi.org/10.1111/j.1540-6261.1995.tb04795.x - 23. McDonald, J. G. (1974). Objectives and Performance of Mutual Funds. Journal of Finance and Quantitative Analysis, 9, 311-333.
http://dx.doi.org/10.2307/2329866 - 24. Muller, C., & Ward, M. (2013). Style-Based Effects on the Johannesburg Stock Exchange: A Graphical Time-Series Approach. Investment Analyst Journal, 77, 1-16.
- 25. Najand, M., & Prather, L. J. (1999). The Risk Level Discriminatory Power of Mutual Fund Objectives: Additional Evidence. Journal of Financial Markets, 2, 307-328.
http://dx.doi.org/10.1016/S1386-4181(99)00002-6 - 26. Prather, L. J. (2012). Portfolio Risk Management Implications of Mutual Fund Investment Objective Classifications. Journal of Financial Risk Management, 1, 33-37.
http://dx.doi.org/10.4236/jfrm.2012.13006 - 27. Reints, W. W., & Vandenberg, P. A. (1973). A Comment on the Risk Taking Behaviour: Evidence from Mutual Funds. Finance and Economics Discussion Series # 96-21. Federal Reserve Board, Washington DC.
- 28. Robertson, M., Firer, C., & Bradfield, D. (2000). Identifying and Correcting Misclassified South African Equity Trusts Using Style Analysis. Investments Analyst Journal, 29, 52.
- 29. Sharpe, W. F. (1992). Asset Allocation: Management Style and Performance Measurement. Journal of Portfolio Management, 18, 7-19.
http://dx.doi.org/10.3905/jpm.1992.409394 - 30. Sharpe, W. F. (1996). Mutual Fund Performance. Journal of Business, 39, 119-138.
http://dx.doi.org/10.1086/294846 - 31. Sirri, E., & Tufano, P. (1998). Costly Search and Mutual Fund Flows. Journal of Finance, 53, 1589-1622.
http://dx.doi.org/10.1111/0022-1082.00066 - 32. Tierney, D. E., & Winston, K. (1991). Using Generic Benchmarks to Present Manager Styles. Journal of Portfolio Management, 17, 33-36.
http://dx.doi.org/10.3905/jpm.1991.409359
Appendix
Table 8. The statistical characteristics of the betas of unit trusts relative to SWIX.