Journal of Financial Risk Management
Vol.04 No.03(2015), Article ID:59341,12 pages
10.4236/jfrm.2015.43010
Operational Risk Modelling in Insurance and Banking
Ognjen Vukovic
Department for Finance, University of Liechtenstein, Vaduz, Liechtenstein
Email: ognjen.vukovic@uni.li, oggyvukovich@gmail.com
Copyright © 2015 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 20 June 2015; accepted 29 August 2015; published 1 September 2015
ABSTRACT
The author of the presented paper is trying to develop and implement the model that can mimic the state of the art models of operational risk in insurance. It implements generalized Pareto distribution and Monte Carlo simulation and tries to mimic and construct operational risk models in insurance. At the same time, it compares lognormal, Weibull and loglogistic distribution and their application in insurance industry. It is known that operational risk models in insurance are characterized by extreme tails, therefore the following analysis should be conducted: the body of distribution should be analyzed separately from the tail of the distribution. Afterwards the convolution method can be used to put together the annual loss distribution by combining the body and tail of the distribution. Monte Carlo method of convolution is utilized. Loss frequency in operational risk in insurance and overall loss distribution based on copula function, in that manner using student-t copula and Monte Carlo method are analysed. The aforementioned approach repre- sents another aspect of observing operational risk models in insurance. This paper introduces: 1) Tools needed for operational risk models; 2) Application of R code in operational risk modeling;3) Distributions used in operational risk models, specializing in insurance; 4) Construction of opera- tional risk models.
Keywords:
Insurance, Operational Risk, Monte Carlo, Statistical Distributions, Modeling, Copula, Convolution, Loss Frequency, Severity

1. Introduction
Operational risk is defined according to Basel II (Nicolas & Firzli, 2011) as well as according to European Solvency II which adopted for insurance industry is defined in the following way (Nicolas & Firzli, 2011) .
Operational risk is the risk of change in value caused by the fact that actual losses, incurred for inadequate or failed internal processes, people and systems, or from external events (including legal risk), and differs from the expected losses.
In order to analyse operational risk in insurance, Solvency II Directive (Mittnik, 2011) must be discussed. Solvency II Directive is an EU Directive that codifies and harmonises the EU insurance regulation. This concerns the amount of capital that EU insurance companies must hold to reduce the risk of insolvency. Solvency II (Mittnik, 2011) is called “Basel for insurers” (Nicolas & Firzli, 2011) . Solvency II is somewhat similar to the banking regulations of Basel II. The proposed Solvency II framework has three main areas (pillars) (Accords, 2006) :
・ Pillar 1―quantitative requirements
・ Pillar 2―requirements for the governance and risk management of insurers and their supervision
・ Pillar 3―disclosure and transparency requirements
In order to analyse the operational risk in insurance (CEA―Groupe Consultatif, 2005) , the attention towards pillar 2 and pillar 1 should be directed. Ernst &Young reports that most of the insurance companies in 2016 will manage to implement the Solvency II requirement until January 2016 (PWC Financial Services Regulatory Practice, 2014) . One of the major new features of Solvency II is that insurance companies must now devote a portion of their equity to covering their exposure to operational risks. There are approaches to calculate the capital requirement: a standard and more advance approach. The advanced approach uses an internal model of risk that corresponds to the company’s real situation. Quantitative impact study (QIS 5) has encouraged insurance companies to adopt the internal model by structuring the standard approach such that it uses up much more equity (Solvency―European Commission, 2012) . In order to analyse the operational risk in this frame, the following assumption will be made: risk will be divided between frequency and severity risk (Doerig, 2000) . They will be modeled by Loss Distribution approach (Power, 2005) . Severity risk represents the risk of large but rare losses. Bayesian networks are used to model severity risk.
1.1. Bayesian Networks
Bayesian networks are defined as a probabilistic graphical model that represents a set of random variables and their conditional dependencies via a directed acyclic graph (DAG). For example, a Bayesian network could represent the probabilistic relationships between the cause and result. If we are aware of the causes, the probabilities of results can be calculated.
In order to define the Bayesian network, the following definition will be used. 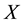 is a Bayesian network with respect to
is a Bayesian network with respect to 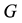 if its joint probability density function (with respect to a product measure) can be written as a product of the individual density functions, conditional on their parent variables:
if its joint probability density function (with respect to a product measure) can be written as a product of the individual density functions, conditional on their parent variables:
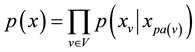 (1)
(1)
where  is the set of parents of
is the set of parents of .
.
The probability of any member of a joint distribution can be calculated from the conditional probabilities using the chain rule, taking into consideration at the same topological ordering of X.
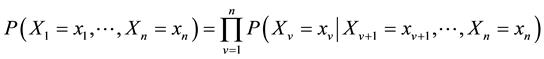 (2)
(2)
Equation (2) can be written as:
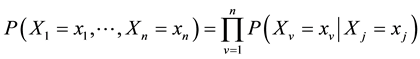 (3)
(3)
(for each  which is a parent of
which is a parent of ).
).
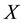 is a Bayesian network with respect to
is a Bayesian network with respect to  if it satisfies the local Markov property, each variable is conditionally independent of its non-descendants given its parent variables.
if it satisfies the local Markov property, each variable is conditionally independent of its non-descendants given its parent variables.
 (4)
(4)
where 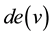 is the set of descendants and
is the set of descendants and 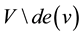 is the set of non-descendants of
is the set of non-descendants of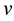 .
.
The aforementioned thing can also be expressed in terms similar to the first definition, as:
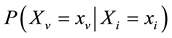 (5)
(5)
For each  which is not a descendant of
which is not a descendant of  is
is
 For each
For each  which is a parent of
which is a parent of .
.
Note that the set of parents is a subset of the set of non-descendants because the graph is acyclic.
1.2. Developing Bayesian Networks
To develop a Bayesian network, we often first develop a  (directed acyclic graph)
(directed acyclic graph)  such that we believe
such that we believe  satisfies the local Markov property with respect to
satisfies the local Markov property with respect to . Sometimes this is done by creating a casual
. Sometimes this is done by creating a casual . We then ascertain the conditional probability distribution of each variable given its parents in
. We then ascertain the conditional probability distribution of each variable given its parents in . In many cases and in particular in the case where the variables are discrete, we define the joint distribution of
. In many cases and in particular in the case where the variables are discrete, we define the joint distribution of  to be the product of these conditional distributions, then X is a Bayesian network with respect to
to be the product of these conditional distributions, then X is a Bayesian network with respect to .
.
In order to model loss severity, since it can be difficult to model operational risk losses of a risk class using only one probability distribution, we analyse severity at two levels: body and tail of the distribution delimited by a high threshold value .
.
The central body can be modeled by using a parametric distribution. One of the distributions that can be used is lognormal. Body is usually estimated on internal data, since the sample size is sufficient below the threshold .
.
Figure 1 demonstrates the body of the distribution, it is assumed that the body of the distribution embraces lognormal value, therefore we assume the lognormal distribution. In order to analyse the tail, it can be modeled applying extreme value theory
(Embrechts, Kluppelberg, & Mikosch, 1997)
the distribution above the threshold, we are talking about Generalized Pareto distribution (GPD). Tail is usually estimated on internal data integrated with external data and scenario generated data above . Data are real scarce above threshold
. Data are real scarce above threshold .
.
Generalized Pareto distribution is used to capture the tail of severity distribution. Figure 2 shows the Genera-

Figure 1. Lognormal distribution.

Figure 2. Generalized Pareto distribution.
lized Pareto distribution, its density as well as its cumulative function.
The commonly used approach to quantify operational risk is the Loss Distribution Approach
(Embrechts, Kluppelberg, & Mikosch, 1997)
where frequency and severity of operational risk losses are modeled separately. The yearly potential loss  is based on the sum of the yearly losses
is based on the sum of the yearly losses  related to the
related to the  risk classes.
risk classes.
The yearly potential loss  related to risk class
related to risk class , is affected by two sources of uncertainty:
, is affected by two sources of uncertainty:
・ The number of losses  in one year time horizon
in one year time horizon
・ The impact of each single loss 
If the following procedure is to be applied to mathematical modeling of operational risk in insurance, the only thing that should be changed is the distribution that it is to be used. Therefore, the methods of copula and convolution will be explained as well as the possible distribution that could be applied in insurance.
1.3. Convolution
In mathematics, convolution is a mathematical operation on two functions  and
and , producing a third function that is typically viewed as a modified version of one of the original functions, giving the area overlap between the two functions as a function of the amount that one of the original functions is translated
(Bracewell, 1986; Damelin & Miller, 2011)
. Convolution is presented in the following manner:
, producing a third function that is typically viewed as a modified version of one of the original functions, giving the area overlap between the two functions as a function of the amount that one of the original functions is translated
(Bracewell, 1986; Damelin & Miller, 2011)
. Convolution is presented in the following manner:
It is defined as the integral of the product of the two functions after one is reversed and shifted. It is a particular kind of integral transform:
 (6)
(6)
Although the symbol  is used above, it need not represent the time domain. However formula can be interpreted as a weighted average of the function
is used above, it need not represent the time domain. However formula can be interpreted as a weighted average of the function  at the moment
at the moment  where the weighting is given by
where the weighting is given by  simply shifted by amount
simply shifted by amount . As
. As  changes, the weighting function emphasizes different part of the input function
(Bracewell, 1986; Damelin & Miller, 2011)
.
changes, the weighting function emphasizes different part of the input function
(Bracewell, 1986; Damelin & Miller, 2011)
.
1.4. Copula
A copula is a multivariate probability distribution for which the marginal probability distribution of each variable is uniform. Copulas are used to describe the dependence between random variables.
One important theorem for copulas is Sklar’s theorem. We will now define the copula:
Copula
(Nelsen, 1999)
is a multivariate distribution function,  , with marginal functions distributed uniformly in [0,1] (U(0,1)) such that
, with marginal functions distributed uniformly in [0,1] (U(0,1)) such that
1) 
2)  has marginal functions
has marginal functions  such that
such that 

Sklar’s theorem (Sklar, 1959) provides the theoretical foundation for the application of copula. Sklar’s theorem states that every multivariate cumulative distribution function
 (7)
(7)
Of a random vector  with marginal
with marginal  and it can be written as:
and it can be written as:
 (8)
(8)
where  is copula.
is copula.
The copula that will be used is Gaussian copula and Gumbel copula. They will be presented shortly.
The Gaussian copula:
Gaussian copula
(Nelsen, 1999)
is a distribution over the unit cube . It is constructed from a multivariate normal distribution over
. It is constructed from a multivariate normal distribution over  using the probability integral form.
using the probability integral form.
The Gaussian copula for , it can be written with parameter matrix
, it can be written with parameter matrix  can be written as:
can be written as:
 (9)
(9)
where  is the inverse cumulative distribution function of a standard normal and
is the inverse cumulative distribution function of a standard normal and  is the joint cumulative distribution function of a multivariate normal distribution with mean vector zero and covariance matrix equal to the correlation matrix
is the joint cumulative distribution function of a multivariate normal distribution with mean vector zero and covariance matrix equal to the correlation matrix .
.
The density matrix can be written as
 (10)
(10)
where  is the identity matrix.
is the identity matrix.
Other famous copulas are Archimedean copulas.
1.5. Archimedean Copulas
Archimedean copulas (Nelsen, 1999) are an associative class of copulas. Archimedean copulas are popular because they allow modeling dependence in arbitrarily high dimensions with only one parameter, governing the strength of dependence.
A copula  is called Archimedean if it admits the representation
is called Archimedean if it admits the representation
 (11)
(11)
where  is a continuous, strictly decreasing and convex function such that
is a continuous, strictly decreasing and convex function such that .
.  is a parameter within some parameter space
is a parameter within some parameter space .
.  is the so-called generator function and
is the so-called generator function and  is the pseudo-inverse defined by:
is the pseudo-inverse defined by:
 (12)
(12)
Moreover, the above formula for C yields a copula for  if and only if
if and only if  is d-monotone on
is d-monotone on . That is, if it is
. That is, if it is  times differentiable and the derivatives satisfy
times differentiable and the derivatives satisfy
 (13)
(13)
for all  and
and  and
and  is nonincreasing and convex.
is nonincreasing and convex.
The copula that we will also introduce is Gumbel copula.
It has the following bivariate form:
 (14)
(14)
After giving the definition of two most important techniques of aggregating operational risk, we will introduce the distributions that we will be using as well as the definition of value at risk and expected shortfall.
1.6. Statistical Distributions
To analyse severity in that sense pertaining to body of the distribution, following distributions can be used, given their densities:
Lognormal distribution density (Hazewinkel, 2001) :
 (15)
(15)
Weibull density distribution:
The probability density function of a Weibull random variable (Hazewinkel, 2001) is:
 (16)
(16)
where k > 0 is the shape parameter and λ > 0 is the scale parameter of the distribution. Its complementary cumulative distribution function is a stretched exponential function. The Weibull distribution is related to a number of other probability distributions; in particular, it interpolates between the exponential distribution (k = 1)
and the Rayleigh distribution (k = 2 and )
)
Loglogistic probability density function is defined in the following way:
 (17)
(17)
The parameter  is a scale parameter and is also the median of the distribution. The parameter
is a scale parameter and is also the median of the distribution. The parameter  is a shape parameter. The distribution is unimodal when
is a shape parameter. The distribution is unimodal when  and its dispersion decreases as
and its dispersion decreases as  increases.
increases.
The following functions are shown in the graphs below:
Figure 3 shows probability density functions of Loglogistic, Weibull and lognormal distributions.
At the same time, we will introduce Champernowne distribution (Hazewinkel, 2001) that we will also be using, its probability density function is given in the graph below:
 (18)
(18)
where  are positive parameters, and n is the normalizing constant, which depends on the parameters.
are positive parameters, and n is the normalizing constant, which depends on the parameters.
 (a)
(a)
 (b) (c)
(b) (c)
Figure 3. Loglogistic, Weibull and lognormal probability density functions respectively.
When obtaining copula, Monte Carlo method will be used, so we will introduce it shortly.
One is interested in the expectation of a response function  applied to some random vector
applied to some random vector
 . If we denoted the cumulative distribution function of this random vector with
. If we denoted the cumulative distribution function of this random vector with , the quantity of interest can thus be written as:
, the quantity of interest can thus be written as:
 (19)
(19)
If  is given by a copula model, example:
is given by a copula model, example:
 (20)
(20)
Then expectation can be written as:
 (21)
(21)
In case the copula  is absolutely continuous,
is absolutely continuous,  has density c, the equation can be written as
has density c, the equation can be written as
 (22)
(22)
If copula and margins are known (or if they have been estimated), then the following Monte Carlo algorithm can be used:
1) Draw a sample  of size n from the copula C
of size n from the copula C
2) By applying the inverse marginal cdf’s, produce a sample of  by setting
by setting

3) Approximate  by its empirical value:
by its empirical value:
 (23)
(23)
1.7. VAR and Expected Shortfall
After having introduced all the necessary tools for operational risk model in insurance, we will just provide the VAR and expected shortfall definition (Longin, 1997) and then we are going to present the modeling results.
 (24)
(24)
Confidence level , the VaR
(Longin, 1997)
of the portfolio at the confidence level
, the VaR
(Longin, 1997)
of the portfolio at the confidence level  is given by the smallest number
is given by the smallest number  such that the probability that the loss
such that the probability that the loss  exceeds
exceeds  is at most
is at most . Mathematically, if
. Mathematically, if  is the loss of a portfolio, then
is the loss of a portfolio, then  is the level
is the level  quantile.
quantile.
In order to model tails, Generalized Pareto distribution will be used.
The standard cumulative distribution function (cdf) of the GPD is defined by
 (25)
(25)
where the support is  for
for  and
and  for
for .
.
 (26)
(26)
Expected shortfall
Expected shortfall is defined as
 (27)
(27)
Or equivalently can be written as:
 (28)
(28)
where
 (29)
(29)
is the lower  and
and  is the indicator function.
is the indicator function.
2. Experimental Results
After having introduced all the necessary tools, the experimental results will be presented. As we are considering operational risk models in insurance, we will use the following tools. The procedure is the following. As we don’t have enough data, we will use random number generator, let it simulate the events, but at the same defining that extreme events don’t occur frequently. Afterwards we will implement the distribution for body and tail of the severity of distribution. Frequency of events was modeled by using Poisson distribution. A standard choice to estimate annual frequency of operational risk loss is performed by using Poisson distribution. On the basis of extreme value theory, the distribution function of loss data above a high threshold  is supposed to follow a Generalized Pareto distribution. Lognormal distribution will be used for modeling body of severity distribution. Afterwards, we use the convolution method using frequency and severity distribution and we obtain annual loss distribution. Convolution is performed by using Monte-Carlo method.
is supposed to follow a Generalized Pareto distribution. Lognormal distribution will be used for modeling body of severity distribution. Afterwards, we use the convolution method using frequency and severity distribution and we obtain annual loss distribution. Convolution is performed by using Monte-Carlo method.
Following steps are performed:
1) Extract one random number  from frequency distribution
from frequency distribution
2) Extract  random numbers
random numbers  from severity distribution
from severity distribution
3) Obtain a possible figure of yearly op. loss 
Repeat  times and we obtain annual loss distribution. In order to obtain overall annual loss distribution, we use the following procedure:
times and we obtain annual loss distribution. In order to obtain overall annual loss distribution, we use the following procedure:
・ Extract one random value  from copula function
from copula function
・ Extract n random numbers from loss distributions related to  risk classes
risk classes
・ Sum yearly losses to obtain overall annual loss distribution
If the real data is used, then to estimate the parameters maximum likelihood, method of moments, probability weighted method of moments should be used.
The simulation results are given below:

The body of distribution is considered to be lognormal. The first fit value is the mean and the other one is standard deviation. The gradient of the function demonstrates where the function is 0.
In Figure 4, optimisation values are given for different theta 1 and theta 2 that represent optimal values. Goodness of fit can also be performed, if the real data is used. Figure 7 shows negative log-likelihood method for fitting log-normal distribution. In that direction, Kolmogorov-Smirnov and Anderson-Darling test statistics are used, but this is left for further research.
To estimate the tail of the severity distribution, we have to set a high threshold : the parameters are estimated on excess over threshold using probability weighted moments, maximum likelihood method etc. Mean excess function is defined in the following way:
: the parameters are estimated on excess over threshold using probability weighted moments, maximum likelihood method etc. Mean excess function is defined in the following way:
 (30)
(30)
What should be noticed is that if the mean excess function for Generalized Pareto distribution is a linear function of u, if the empirical mean excess function is a straight line above a threshold, it is an indication that the excess over  follows a generalized Pareto distribution, which is shown in the Figure 8.
follows a generalized Pareto distribution, which is shown in the Figure 8.
It is obvious that Figure 5 demonstrates that the tail of severity distribution is following Generalized Pareto distribution. QQ plots of the Generalized Pareto distribution using maximum likelihood method and probability weighted method of moments.
Q-Q plots in Figure 6 demonstrate that the tail of severity distribution is characterised by generalized Pareto distribution. Results are the following. Using the aforementioned methods, the following results are obtained:


Figure 4. Neg-log likelihood for fitting log-normal distribution with random number generator.

Figure 5. Mean excess function.
To analyse the loss frequency, we assume Poisson process and obtain the following results:
Figure 7 shows loss frequency distribution for Poisson case.
After having introduced the severity and loss frequency distribution, we use the convolution method to obtain annual loss distribution. The code will be given in the appendix, so that the calculation can be performed.
The annual loss distributions are obtained in Figure 8.
Figure 8 shows annual loss distribution as a result of convolution method, it is the combination of lognormal and generalized Pareto distribution.
It is the combination of lognormal and generalized Pareto distribution, therefore because they differ and vary from sample to sample, the copula method should be used to obtain overall annual loss distribution (Hazewinkel, 2001) .
Using Student t-copula, overall loss distribution is calculated and code that can be replicated is given, together with the VaR (Longin, 1997) results which are shown in Figure 9.
The code given in appendix demonstrates how to calculate VaR and copula for overall loss distribution. At the same time, some results are given for Value at Risk, expected loss and capital requirements. The given calculations and results demonstrate how to model risk in insurance by using lognormal and generalized Pareto distribution. At the same time distribution can be changed depending of the situation. This approach introduces modeling of operational risk in insurance and financial institutions and represents a review of the state of art techniques.
3. Conclusion
This paper introduces the state of the art techniques in operational risk modeling. It begins by presenting Solvency II and Basel II criteria. Afterwards it introduces statistical and mathematical techniques. Consequently, it presents modeling techniques by introducing Generalized Pareto distribution which is used in operational risk models in insurance and banking. The aforementioned paper represents a review in operational risk models in

 (a) (b)
(a) (b)
Figure 6. QQ plots with maximum likelihood method and probability weighted moments.

Figure 7. Loss frequency distribution Results: lambda Sample 532 > lambda 791.7354.

Figure 8. Annual loss distribution.

Figure 9. Copula method for obtaining overall annual loss distribution.
insurance. It introduces techniques that can be used in modeling operational risk in insurance and banking, and it can be immediately applied. Hopefully, this review will provide further research in risk models and provide new ideas that can be applied to operational risk in whole.
Acknowledgements and Declaration of Interest Section
The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the paper. I would like to thank my family for the immense support.
Cite this paper
OgnjenVukovic, (2015) Operational Risk Modelling in Insurance and Banking. Journal of Financial Risk Management,04,111-123. doi: 10.4236/jfrm.2015.43010
References
- 1. (2012). Solvency—European Commission. Ec.europa.eu.
- 2. Accords, B. (2006). Basel II: Revised International Capital Framework.
- 3. Bracewell, R. (1986). The Fourier Transform and Its Applications (2nd ed.). New York: McGraw-Hill.
- 4. CEA—Groupe Consultatif (2005). Solvency II Glossary—European Commission.
- 5. Damelin, S., & Miller, W. (2011). The Mathematics of Signal Processing. Cambridge: Cambridge University Press.
http://dx.doi.org/10.1017/CBO9781139003896 - 6. Doerig, H. U. (2000). Operational Risks in Financial Services: An Old Challenge in a New Environment. Switzerland: Credit Suisse Group.
- 7. Embrechts, P., Kluppelberg, C., & Mikosch, T. (1997). Modelling Extremal Events. Berlin: Springer.
http://dx.doi.org/10.1007/978-3-642-33483-2 - 8. Hazewinkel, M. (Ed.) (2001). Probability Distribution. Encyclopedia of Mathematics. Berlin: Springer.
- 9. Longin, F. (1997). From Value at Risk to Stress Testing: The Extreme Value Approach. Ceressec Working Paper, Paris: ESSEC.
- 10. Mittnik, S. (2011). Solvency II Calibrations: Where Curiosity Meets Spuriosity. Munich: Center for Quantitative Risk Analysis (CEQURA), Department of Statistics, University of Munich.
- 11. Nelsen, R. B. (1999). An Introduction to Copulas. New York: Springer.
http://dx.doi.org/10.1007/978-1-4757-3076-0 - 12. Nicolas, M., & Firzli, J. (2011). A Critique of the Basel Committee on Banking Supervision. Paris: Revue Analyse Financière.
- 13. Power, M. (2005). The Invention of Operational Risk. Review of International Political Economy, 12, 577-599.
- 14. PWC Financial Services Regulatory Practice (2014). Operational Risk Capital: Nowhere to Hide.
http://www.pwc.com/us/en/financial-services/regulatory-services/publications/operational-risk-capital.jhtml - 15. Sklar, A. (1959). Fonctions de rpartition n dimensions et leurs marges (pp. 229-231). Paris: Publications de l’Institut de Statistique de l’Universit de Paris.
Appendix
Convolution Method Code in R to Obtain Overall Annual Loss Distribution
install.packages(‘evir’)
library(evir)
# Quantile function of lognormal-GPD severity distribution
qlnorm.gpd = function(p, theta, theta.gpd, u)
{
Fu = plnorm(u, meanlog=theta[1], sdlog=theta[2])
x = ifelse(p
qlnorm( p=p, meanlog=theta[1], sdlog=theta[2] ),
qgpd( p=(p - Fu) / (1 - Fu) , xi=theta.gpd[1], mu=theta.gpd[2], beta=theta.gpd[3]) )
return(x)
}
# Random sampling function of lognormal-GPD severity distribution
rlnorm.gpd = function(n, theta, theta.gpd, u)
{ r = qlnorm.gpd(runif(n), theta, theta.gpd, u)}
set.seed(1000)
nSim = 10000# Number of simulated annual losses
H = 1500 # Threshold body-tail
lambda = 791.7354 # Parameter of Poisson body
theta1 = 2.5 # Parameter mu of lognormal (body)
theta2 = 2 # Parameter sigma of lognormal (body)
theta1.tail = 0.5 # Shape parameter of GPD (tail)
theta2.tail = H # Location parameter of GPD (tail)
theta3.tail = 1000 # Scale parameter of GPD (tail)
sj = rep(0,nSim) # Annual loss distribution inizialization
freq = rpois(nSim, lambda) # Random sampling from Poisson
for(i in 1:nSim) # Convolution with Monte Carlo method
sj[i] = sum(rlnorm.gpd(n=freq[i], theta=c(theta1,theta2), theta.gpd=c(theta1.tail, theta2.tail, theta3.tail), u=H))
sj[i]
Code to Calculate Overall Loss Distribution with VAR Results
>library(QRM)
>set.seed(1000)
>nSim = 1000000 # Number of simulated overall annual losses
>s1 = rlnorm(n=nSim, meanlog=4.5, sdlog=2.3) # Loss distribution risk class 1
>s2 = rlnorm(n=nSim, meanlog=5, sdlog=2.5) # Loss distribution risk class 2
>VaR.s1 = quantile(s1, 0.999) # VaR risk class 1
>VaR.s2 = quantile(s2, 0.999) # VaR risk class 2
>corr = 0.6 # Correlation among risk classes
>corrMatrix = matrix(data=c(1,corr,corr,1), nrow=2) # correlation matrix
>dof = 5 # degrees of freedom
>simCopulaT = rcopula.t(n=nSim, df=dof, Sigma=corrMatrix) # Simulations from Student-t copula
>s = quantile(s1, simCopulaT[,1]) + quantile(s2, simCopulaT[,2]) # overall annual loss distribution
>VaR.s = quantile(s, 0.999)
>divEff = (VaR.s1+VaR.s-VaR.s)/(VaR.s1+VaR.s) # diversification effect
>EL = quantile(s, 0.5) # Expected loss
>capReq = VaR.s - EL # Capital requirement
>VaR.s1; VaR.s2; VaR.s; divEff; EL; capReq
99.9%
111300.8
99.9%
339577.2
99.9%
410748.6
99.9%
0.2131997
50%
355.3662
99.9%
410393.2