Open Journal of Statistics
Vol.05 No.03(2015), Article ID:55991,7 pages
10.4236/ojs.2015.53020
A New Algorithm for Generalized Least Squares Factor Analysis with a Majorization Technique
Kohei Adachi
Graduate School of Human Sciences, Osaka University, Osaka, Japan
Email: adachi@hus.osaka-u.ac.jp
Copyright © 2015 by author and Scientific Research Publishing Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received 18 January 2015; accepted 22 April 2015; published 27 April 2015
ABSTRACT
Keywords:
Exploratory Factor Analysis, Generalized Least Squares Estimation, Matrix Computations, Majorization

1. Introduction
Using
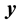 for a
for a
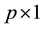
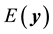
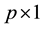
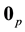 , the
, the
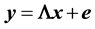 (1)
(1)
with
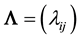 a p-
a p-
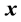 an
an
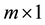 latent factor score vector,
latent factor score vector,
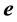 a
a
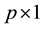 error vector, and
error vector, and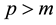 . The expectations for
. The expectations for
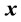 and
and
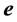 are assumed to satisfy
are assumed to satisfy
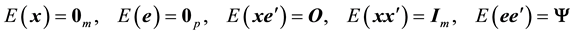 (2)
(2)
Here,
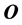 is the
is the
 matrix of zeros,
matrix of zeros,
 is the
is the
 identity matrix, and
identity matrix, and
 is the
is the
 diagonal matrix whose diagonal elements are called
diagonal matrix whose diagonal elements are called
 is modeled as
is modeled as
 (3)
(3)
[1] [2] . A main purpose of FA is to estimate the parameter matrices
 and
and
 from the inter-variable sample covariance matrix
from the inter-variable sample covariance matrix

 corresponding to (3). Some authors classify FA as exploratory (EFA) or
corresponding to (3). Some authors classify FA as exploratory (EFA) or
 is unconstrained in EFA, while some elements of
is unconstrained in EFA, while some elements of
 are constrained in CFA. In this paper, we refer to EFA simply as FA.
are constrained in CFA. In this paper, we refer to EFA simply as FA.
 to be minimized
to be minimized
 . The
. The
 and
and
 (4)
(4)
respectively,
 is
is
 and
and
 in the ML
in the ML
In all
 . They can be
. They can be
 with
with
 is
is
 underlies
underlies
 to
to . Similar dichotomization of minimization methodology is also found in [6] .
. Similar dichotomization of minimization methodology is also found in [6] .
For all of the LS, GLS, and ML
 is
is
 and the minimization of
and the minimization of

 for
for
 is ite
is ite
 decreases mono
decreases mono
 .
.
As found in the above discussion, an
 . To propose it is the
. To propose it is the
 is utilized for minimizing a
is utilized for minimizing a

 .
.
 satisfies
satisfies , with
, with

 for its latter
for its latter
 kept fixed [14] . It
kept fixed [14] . It

 into
into . As described in the
. As described in the
The MD algorithm is not the
 were
were
The remaining parts of this paper are organized as follows: the MD algorithm is detailed in the next section, and it is illustrated with a real data set in Section 3. A simulation study for assessing the algorithm is reported in Section 4, which is followed by discussions.
2. Proposed Algorithm
We propose the MD algorithm for minimizing the GLS loss function (4) over the loadings in

 and the unique variances in the diagonal matrix
and the unique variances in the diagonal matrix

 . Here, it is supposed that the sample covariance matrix
. Here, it is supposed that the sample covariance matrix
 is positive-definite and
is positive-definite and
 is of full-column rank, i.e., its rank is
is of full-column rank, i.e., its rank is
 with
with . This supposition and the covariance matrix being modeled as (3) imply that, without loss of generality, we can reparameterize
. This supposition and the covariance matrix being modeled as (3) imply that, without loss of generality, we can reparameterize
 as
as
 (5)
(5)
where
 is a
is a
 matrix satisfying
matrix satisfying
 (6)
(6)
and
 is an
is an
 positive-definite diagonal matrix. By substituting (5) into the GLS loss function (4), it is rewritten as
positive-definite diagonal matrix. By substituting (5) into the GLS loss function (4), it is rewritten as
 (7)
(7)
This function is minimized over ,
,
 , and
, and
 subject to (6) and the latter two matrices being diagonal ones, by alternately iterating the majorizing and diagonal steps described in the next subsections.
subject to (6) and the latter two matrices being diagonal ones, by alternately iterating the majorizing and diagonal steps described in the next subsections.
2.1. Majorization Step
Let us consider minimizing (7) over
 subject to (6) while
subject to (6) while
 and
and
 are kept fixed. Summarizing the parts irrelevant to
are kept fixed. Summarizing the parts irrelevant to
 in (7) into
in (7) into , the loss function (7) is rewritten as
, the loss function (7) is rewritten as
 . (8)
. (8)
Though the optimal

 . Compa
. Compa
 with
with

 ,
,
 ,
,
 ,
,
 , and
, and . T
. T
According to the formula, the update of
 by
by
 (9)
(9)
decreases the value of (8) with . Here,
. Here,
 stands for the matrix
stands for the matrix
 before the update;
before the update;
 and
and
 are the column-orthonormal matrices that are obtained from the SVD defined as
are the column-orthonormal matrices that are obtained from the SVD defined as
 (10)
(10)
with
 the diagonal matrix including the singular values of the matrix in the left-hand side, and
the diagonal matrix including the singular values of the matrix in the left-hand side, and ,
,
 , and
, and
 the largest eigenvalues of
the largest eigenvalues of ,
,
 , and
, and , respectively.
, respectively.
2.2. Diagonal Steps
In this section, we describe updating each of diagonal matrices
 and
and . First, let us consider minimizing the loss function (7) over
. First, let us consider minimizing the loss function (7) over
 with keeping
with keeping
 and
and
 fixed. Since the terms relevant to
fixed. Since the terms relevant to
 in the loss function (7) are the same as those relevant to
in the loss function (7) are the same as those relevant to , the expression (8) into which (7) is rewritten is to be noted again. By taking account of the fact that
, the expression (8) into which (7) is rewritten is to be noted again. By taking account of the fact that
 is a diagonal matrix, (8) can be rewritten as
is a diagonal matrix, (8) can be rewritten as
 (11)
(11)
Here,
 and
and
 with
with
 denoting the diagonal matrix whose diagonal elements are those of the parenthesized matrix. Further, we can rewrite (11) as
denoting the diagonal matrix whose diagonal elements are those of the parenthesized matrix. Further, we can rewrite (11) as
 with
with
 denoting the Frobenius norm. It shows that the function
denoting the Frobenius norm. It shows that the function
(11) is minimized for
 (12)
(12)
for fixed
 and
and .
.
Next, we consider minimizing (7) over
 with
with
 and
and
 fixed. Summarizing the parts irrelevant to
fixed. Summarizing the parts irrelevant to
 in (7) into
in (7) into
 and using the fact of
and using the fact of
 being a diagonal matrix, the loss function (7) can be rewritten as
being a diagonal matrix, the loss function (7) can be rewritten as
 (13)
(13)
with
 and
and . We can find that (13) is minimized for
. We can find that (13) is minimized for
 (14)
(14)
for fixed
 and
and .
.
2.3. Whole Algorithm
The results in the last two subsections show that the proposed MD algorithm can be listed as follows:
Step 1. Initialize ,
,
 , and
, and .
.
Step 2. Update
 with (9)
with (9)
 times.
times.
Step 3. Update
 with (12).
with (12).
Step 4. Update
 with (14).
with (14).
Step 5. Finish with
 set to (5) if convergence is reached; otherwise, return to Step 2.
set to (5) if convergence is reached; otherwise, return to Step 2.
It should be noted in Step 2 that the update of
 by (9) does not minimize (7) but only decreases its value, which implies that that update can be replicated (
by (9) does not minimize (7) but only decreases its value, which implies that that update can be replicated ( times) for further decreasing the value of (7). In this paper, we set
times) for further decreasing the value of (7). In this paper, we set .
.
In Step 1, the initialization is performed using the principal component analysis of sample covariance matrix . That is, the initial
. That is, the initial
 and
and
 are given by
are given by
 and
and , respectively, with
, respectively, with
 the
the
 diagonal matrix whose diagonal elements are the
diagonal matrix whose diagonal elements are the
 largest eigenvalues of
largest eigenvalues of , and the columns of
, and the columns of

 being the eigenvectors corresponding to
being the eigenvectors corresponding to . The initial
. The initial
 is set to
is set to .
.
In Step 5, we define the convergence as the decrease in the value of (7) or (4) from the previous round being less than .
.
3. Illustration
In this section, we illustrate the performance of the MD algorithm with a 190-
We carried out the MD algorithm for the

Table 1. Loadings and unique variances Y1p for personality rating data.


Figure 1. Change in the GLS loss function value as a function of the number of iteration.
As the
 post-multiplied by arbitrary orthonormal matrix satisfies (1) and (2), the loading matrix was rotated by the varimax method [21] . The solution is presented in Table 1. There, bold font is used for the loadings whose absolute values are greater than 0.35. They show that the 25 items are clearly classified into the five groups as predicted by the theory in personality psychology [20] , which demonstrates that the MD algorithm provided the reasonable solution.
post-multiplied by arbitrary orthonormal matrix satisfies (1) and (2), the loading matrix was rotated by the varimax method [21] . The solution is presented in Table 1. There, bold font is used for the loadings whose absolute values are greater than 0.35. They show that the 25 items are clearly classified into the five groups as predicted by the theory in personality psychology [20] , which demonstrates that the MD algorithm provided the reasonable solution.
4. Simulation Study
A simulation study was performed in order to assess how well parameter matrices are recovered by the proposed MD algorithm and compare it with the existing algorithms for the GLS estimation in the goodness of the recovery. We first describe the procedure for synthesizing the data to be analyzed, which is followed by results.
An n-observations × p-variables data matrix
 was synthesized according to the matrix versions of the FA model (1) and the assumptions in (2):
was synthesized according to the matrix versions of the FA model (1) and the assumptions in (2):
 (15)
(15)
 (16)
(16)
 denotes the
denotes the
 vector of ones,
vector of ones,
 is an
is an


 is
is
 to
to
 , and
, and
 is an
is an

 ,
,
 , and
, and

 ,
,
 , and
, and ,
,
Step 1. Draw
 from
from ,
,
 from
from , and
, and
 from
from , with
, with
 denoting the discrete uniform distribution defined for the integers within the range
denoting the discrete uniform distribution defined for the integers within the range .
.
Step 2. Draw each loading in
 from
from
 and each unique variance in
and each unique variance in
 from
from
 with
with
 denoting the uniform distribution over the range
denoting the uniform distribution over the range .
.
Step 3. Draw each elements of
 in (15) from
in (15) from
 which is followed by centering
which is followed by centering
 and post- multiplying it by the matrix that allows the resulting
and post- multiplying it by the matrix that allows the resulting
 to satisfy (16).
to satisfy (16).
Step 4. Form
 with (15) and obtain the covariance matrix
with (15) and obtain the covariance matrix .
.
In Step 3 we have used a uniform distribution for , rather than the normal distribution typically used for such a matrix, as a feature of the GLS estimation is that it does not need the normality assumption required in the ML estimation. We replicated the above steps to have 2000 sets of
, rather than the normal distribution typically used for such a matrix, as a feature of the GLS estimation is that it does not need the normality assumption required in the ML estimation. We replicated the above steps to have 2000 sets of . For them, the MD and the existing algorithms were carried out, where the latter are the two gradient algorithms [9] [10] , as described in Section 1. We refer to the ones in [9] and [10] as the Newton-Raphson (NR) and Gauss-Newton (GN) algorithms, respectively. In the NR one, we obtained the gradient vector in [9] , Equation (32), by pre-multiplying the vector of first derivatives by the Moore Penrose inverse of the corresponding Hessian matrix. Also in the NR and GN algorithms, we used the same initialization and definition of convergence as in Section 2.3.
. For them, the MD and the existing algorithms were carried out, where the latter are the two gradient algorithms [9] [10] , as described in Section 1. We refer to the ones in [9] and [10] as the Newton-Raphson (NR) and Gauss-Newton (GN) algorithms, respectively. In the NR one, we obtained the gradient vector in [9] , Equation (32), by pre-multiplying the vector of first derivatives by the Moore Penrose inverse of the corresponding Hessian matrix. Also in the NR and GN algorithms, we used the same initialization and definition of convergence as in Section 2.3.
Let us express the true
 simply as
simply as
 and use
and use
 for the solution given by the NR, GN, or MD algorithm. For assessing the recovery of the loading matrix, the averaged absolute difference (AAD) of the elements in
for the solution given by the NR, GN, or MD algorithm. For assessing the recovery of the loading matrix, the averaged absolute difference (AAD) of the elements in
 to the corresponding estimates, i.e.,
to the corresponding estimates, i.e.,
 , (17)
, (17)
can be used with
 denoting the
denoting the
 norm. Here, it should be noted that
norm. Here, it should be noted that
 has rotational freedom and must be rotated so that the resulting
has rotational freedom and must be rotated so that the resulting
 is optimally matched to
is optimally matched to . Such a rotated
. Such a rotated
 can be obtained by the orthogonal Procrustes method [22] with
can be obtained by the orthogonal Procrustes method [22] with
 a target matrix. The loading matrix
a target matrix. The loading matrix
 in (17) thus stands for the one rotated by the Procrustes method. The recovery of unique variances can also be assessed with the AAD index
in (17) thus stands for the one rotated by the Procrustes method. The recovery of unique variances can also be assessed with the AAD index , where the unique variances are uniquely determined, thus the additional procedure as for
, where the unique variances are uniquely determined, thus the additional procedure as for
 is unnecessary. Smaller values of those AAD indices stand for better recovery.
is unnecessary. Smaller values of those AAD indices stand for better recovery.
The
Table 2. Statistics for the differences between the true parameter values and their estimated counterparts.
s
5. Discussion
We proposed the majorizing-diagonal (MD) algorithm for the GLS estimation in FA. In the algorithm, the loading matrix is reparameterized as the product of a column-orthonormal matrix and a diagonal one, and the former one is updated with Kiers and ten Berge’s [18]
One of the tasks remaining for the MD algorithm is to study its mathematical properties as have been done for the algorithms in the other estimation procedures. For example, it has been found that the EM algorithm for the ML estimation [12] can never give an improper solution under a certain condition [23] , where the improper solution refers to the one including a negative unique variance. Whether such special features are possessed by the MD algorithm is considered to be found by studying the properties of the matrix update formulas in the algorithm.
References
- Harman, H.H. (1976) Modern Factor Analysis. 3rd Edition, The University of Chicago Press, Chicago.
- Mulaik, S.A. (2010)
- Yanai, H. and Ichikawa, M. (2007)
- Anderson, T.W. and Rubin, H. (1956) Statistical Inference in Factor Analysis. In: Neyman, J., Ed., Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Vol. 5, University of California Press, Berkeley, 111-150.
- Lange, K. (2010) Numerical Analysis for Statisticians. 2nd Edition, Springer, New York.
- ten Berge, J.M.F. (1993) Least Squares Optimization in Multivariate Analysis. DSWO Press, Leiden.
- Jöreskog, K.G. (1967) Some Contributions to Maximum Likelihood Factor Analysis. Psychometrika, 32, 443-482. http://dx.doi.org/10.1007/BF02289658
- Jennrich, R.I. and Robinson, S.M. (1969) A Newton-Raphson Algorithm for Maximum Likelihood Factor Analysis. Psychometrika, 34, 111-123. http://dx.doi.org/10.1007/BF02290176
- Jöreskog, K.G. and Goldberger, A.S. (1972) Factor Analysis by Generalized Least Squares. Psychometrika, 37, 243- 250. http://dx.doi.org/10.1007/BF02306782.
- Lee, S.Y. (1978) The Gauss-Newton Algorithm for the Weighted Least Squares Factor Analysis. Journal of the Royal Statistical Society: Series D (The Statistician), 27, 103-114. http://dx.doi.org/10.2307/2987906
- Harman, H.H. and Jones, W.H. (1966) Factor Analysis by Minimizing Residuals (Minres). Psychomerika, 31, 351-369. http://dx.doi.org/10.1007/BF02289468
- Rubin, D.B. and Thayer, D.T. (1982) EM Algorithms for ML Factor Analysis. Psychometrika, 47, 69-76. http://dx.doi.org/10.1007/BF02293851
- Dempster, A.P., Laird, N.M. and Rubin, D.B. (1977) Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B, 39, 1-38.
- Groenen, P.J.F. (1993) The Majorization Approach to Multidimensional Scaling: Some Problems and Extensions. DSWO Press, Leiden.
- Unkel, S. and
- Unkel, S. and
- Adachi, K. (2012) Some Contributions to Data-Fitting Factor Analysis with Empirical Comparisons to Covariance- Fitting Factor Analysis. Journal of the Japanese Society of Computational Statistics, 25, 25-38. http://dx.doi.org/10.5183/jjscs.1106001_197
- Kiers, H.A.L. and ten Berge, J.M.F. (1992) Minimization of a Class of Matrix Trace Functions by Means of Refined Majorization. Psychometrika, 57, 371-382. http://dx.doi.org/10.1007/BF02295425
- Kiers, H.A.L. (1990) Majorization as a Tool for Optimizing a Class of Matrix Functions. Psychometrika, 55, 417-428. http://dx.doi.org/10.1007/BF02294758
-
- Kaiser, H.F. (1958) The Varimax Criterion for Analytic Rotation in Factor Analysis. Psychometrika, 23, 187-200. http://dx.doi.org/10.1007/BF02289233
- Gower, J.C. and Dijksterhuis, G.B. (2004) Procrustes Problems. Oxford University Press, Oxford. http://dx.doi.org/10.1093/acprof:oso/9780198510581.001.0001
- Adachi, K. (2013) Factor Analysis with EM Algorithm Never Gives Improper Solutions When Sample Covariance and Initial Parameter Matrices Are Proper. Psychometrika, 78, 380-394. http://dx.doi.org/10.1007/s11336-012-9299-8